
")
Introducción
En el vertiginoso mundo de la inteligencia artificial, la clave para llevar a cabo proyectos exitosos radica en la implementación eficaz de MLOps, la sinergia perfecta entre Machine Learning y Operaciones. Esta disciplina revoluciona la manera en que los modelos son desarrollados, desplegados y gestionados. En este panorama, SageMaker de AWS emerge como el faro guía, ofreciendo un ecosistema completo y escalable que simplifica cada etapa del ciclo de vida de un modelo de aprendizaje automático.
Desde la rápida experimentación con algoritmos de vanguardia hasta la implementación en producción sin problemas, SageMaker se erige como el compañero indispensable. Con características de automatización, monitoreo en tiempo real y capacidad de autoescalado, proporciona una ventaja competitiva que acelera la transformación de datos en información valiosa. Descubre cómo esta poderosa combinación de MLOps y SageMaker de AWS está redefiniendo la forma en que el mundo aborda la inteligencia artificial. ¡Es el momento de impulsar tu proyecto hacia un nivel superior!
Índice
MLOps
Como comenté en el anterior tutorial sobre MLOps, es una abreviatura que hace referencia a Machine Learning Operations, una metodología que se basa en aplicar los principios de DevOps, usados en el desarrollo de software tradicional (no basado en inteligencia artificial) a los sistemas basados en machine learning. La sinergia perfecta entre Machine Learning y Operaciones.
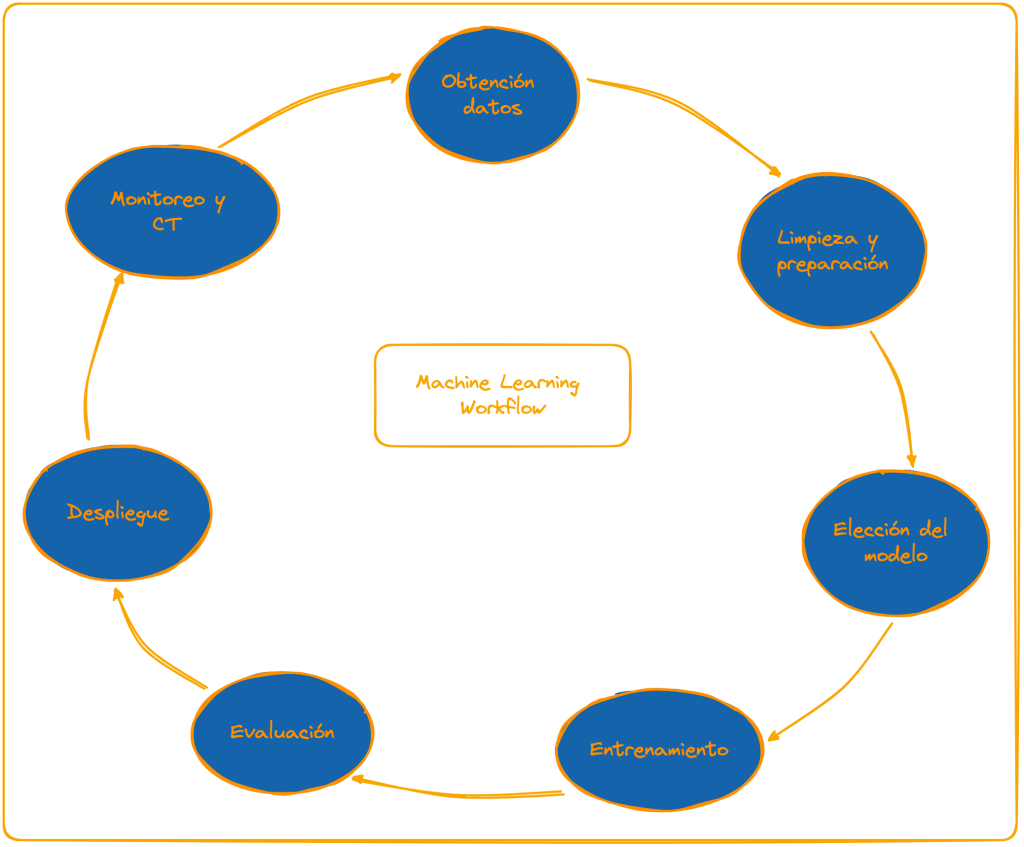
En este caso se hace uso de prácticas ya conocidas como colaboración entre equipos, romper barreras entre equipos (de desarrollo y operaciones), fomentar la automatización de procesos, sistemas de control de versiones, implementación de pipelines de integración continua y entrega o despliegue continuo (CI/CD).
Pero también se usan nuevas prácticas propios del dominio del machine learning. Como por ejemplo la monitorización del rendimiento de modelos así como otras métricas que se consideren necesarias, gestión del concept drift (fenómeno que ocurre durante el despligue de un modelo en el que la evolución de los datos actuales en producción invalidan los que se usaron durante el entrenamiento) o conceptos nuevos, como el entrenamiento continuo (CT) siguiendo la tónica de CI/CD de DevOps tradicional.
¿Qué es SageMaker?
SageMaker, también mencionado en el tutorial sobre MLOps, es una colección de servicios de machine learning totalmente gestionados, esto quiere decir que ofrece una solución end-to-end de desarrollo, despliegue y monitoreo de modelos de machine learning.
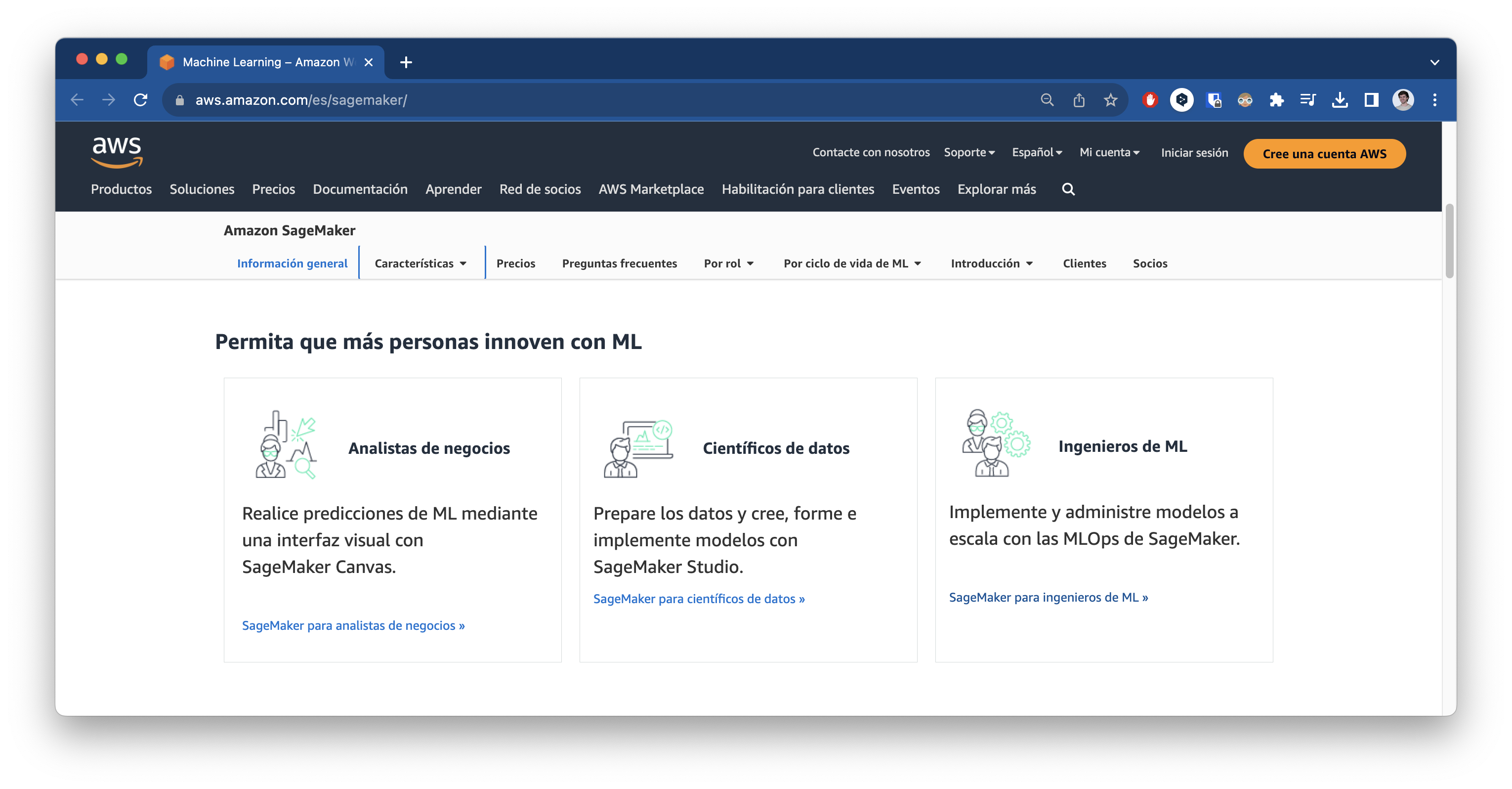
Proporciona una enorme variedad de modelos así como de herramientas dentro del dominio del ML. Otra de las ventajas es que está enfocado en varios perfiles distintos incluidos perfiles de negocio o analistas de negocio que no necesariamente tienen que saber el detalle de la programación sino que provee una interface no-code para machine learning. Este es el abanico de perfiles que AWS piensa que es el público objetivo:
SageMaker Studio
TL;DR Si quieres saber directamente cómo usarlo, ve a esta sección.
Según AWS, es un IDE con un interfaz web desde la que se puede acceder a herramientas diseñadas específicamente para realizar todos los pasos involucrados en el ML, desde la preparación de los datos hasta la creación, el entrenamiento y la implantación de modelos.

Permite realizar todas las tareas del workflow de machine learning (pre-procesado, entrenamiento y modelos, despliegue y monitoreo) en pocos clicks:
Pre-procesado de datos
En concreto ofrece 3 herramientas: Data Wrangler, para juntar y preparar los datos a usar, Feature Store, donde poder aplicar técnicas de ingeniería o selección de características en la que mantener un repositorio de las mismas y Clusters, herramienta de preparación de grandes volúmenes de datos del orden de petabytes.
Data Wrangler
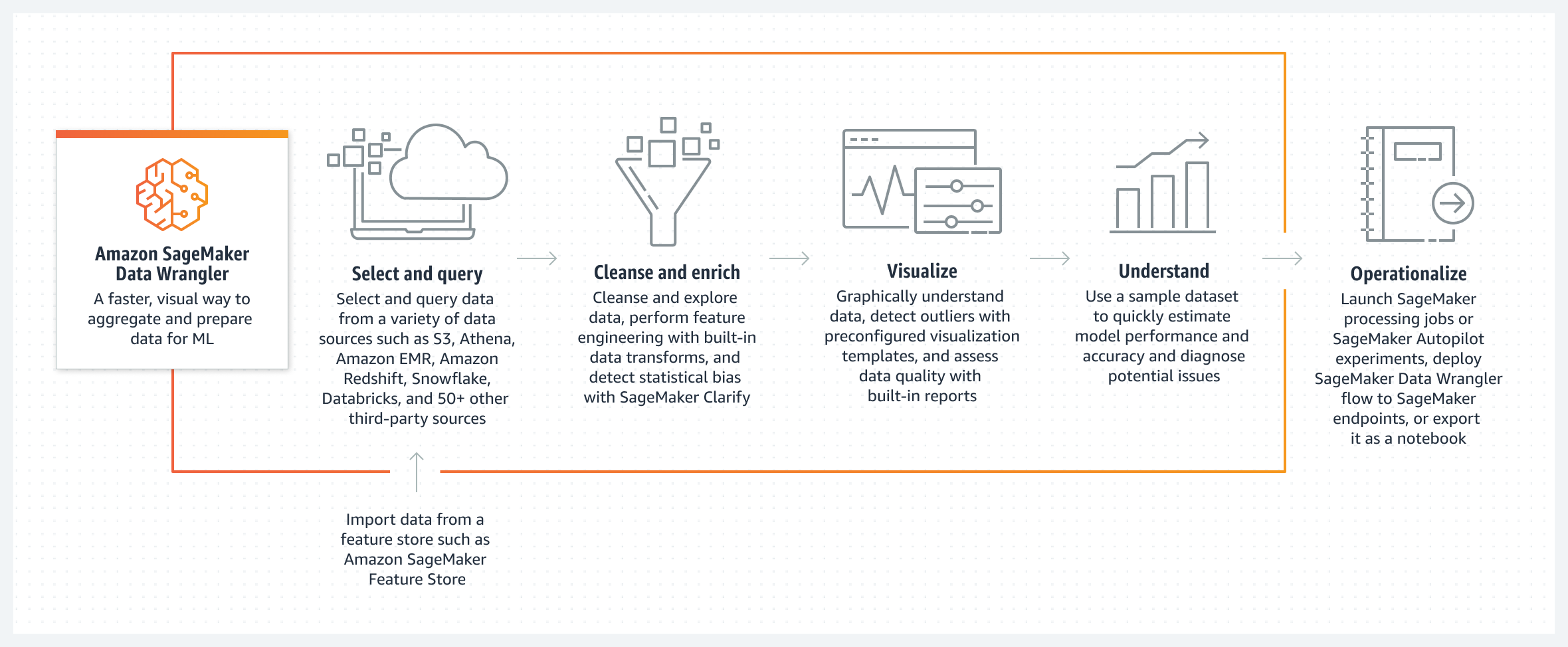
Como la descripción indica, es un herramienta visual de preparación de datos que facilita y agiliza la fase de limpieza y preparación de datos para la analítica y el aprendizaje automático. Acepta, por supuesto, fuentes de datos de AWS como Amazon S3, Athena o EMR (Amazon Elastic MapReduce) o Redshift, también de Snowflake o Databricks y de aplicaciones SaaS como Salesforce, SAP o Google Analytics). Permite explorar los datos utilizando SQL y obtener gráficos y visualizaciones interesantes.
Por supuesto también ofrece herramientas para rellenar valores omitidos, detectar valores atípicos y transformar datos de series temporales.
Este sería el flujo normal de funcionamiento, según la web oficial:
Feature Store
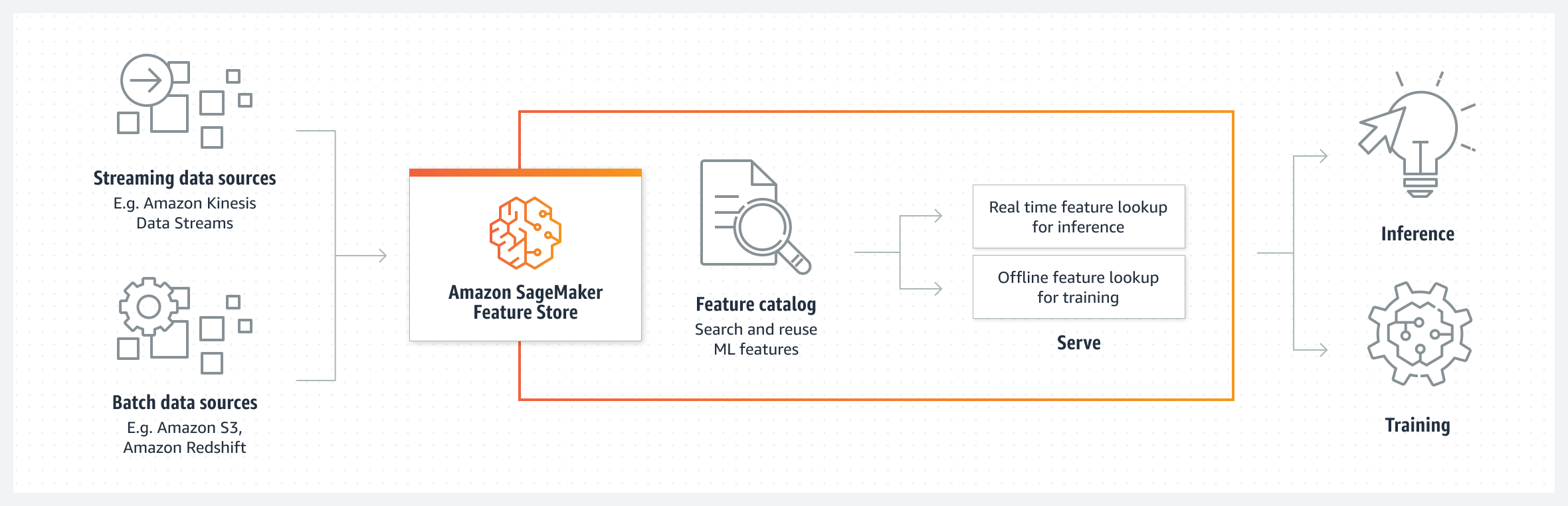
Repositorio para almacenar, compartir y gestionar características de modelos de aprendizaje automático (ML). Las características es lo que define la entrada de modelo, así si se quiere predecir el valor de una casa en determinado barrio dentro de unos años, la predicción no será la misma para una casa grande que para una casa pequeña o el número de habitaciones. Estas características son muy importantes a la hora de entrenar los modelos para luego realizar inferencias correctamente.
Sin embargo, no todas las características de una casa son igual de determinantes a la hora de predecir el valor de la misma. No tendrá el peso en el precio que la casa tenga 200 metros cuadrados que el número de puertas que tenga. Por ello, es primordial que el modelo aprenda estas jerarquías, con el objetivo de poder realizar predicciones en base a representaciones fidedignas de la realidad.
Dentro de Feature Store, podremos llevar a cabo este proceso de selección de características o ingeniería de características tan importante en el proceso de machine learning. También los equipos podrán compartir y reutilizar las más importantes dentro de la plataforma, dentro de un catálogo de características o feature catalog.
Este es un resumen del funcionamiento del servicio según AWS:
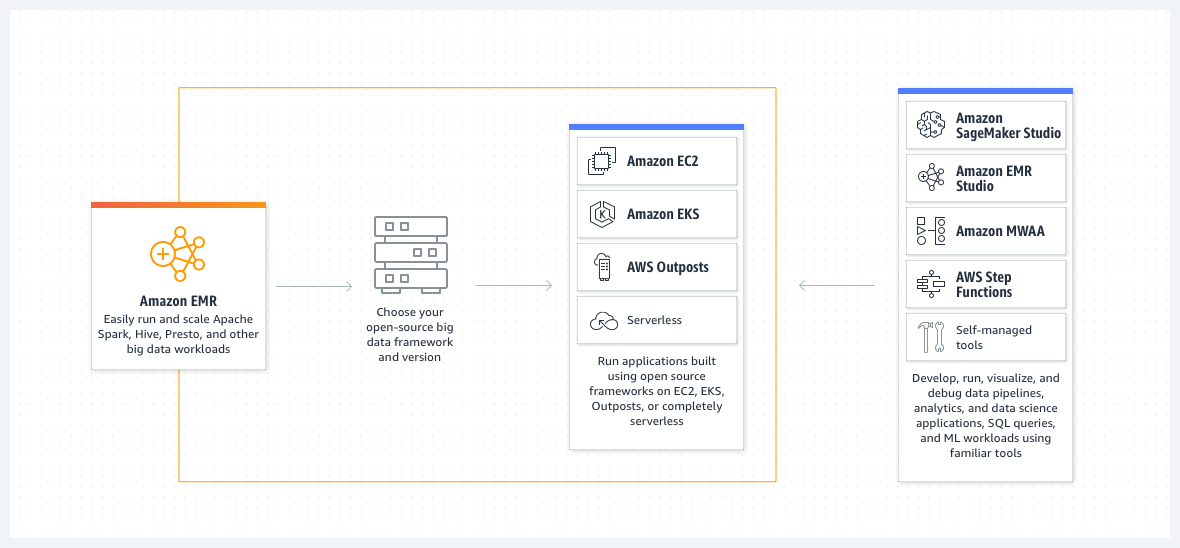
Clusters
Dado que AWS SageMaker Studio viene por defecto configurado con Amazon EMR (Elastic MapReduce*), plataforma que simplifica la ejecución de frameworks de analítica de big data como Apache Hadoop y Apache Spark, en AWS para procesar y analizar grandes cantidades de datos.
* MapReduce es un modelo de programación diseñado para procesar grande volúmenes de datos bajo la computación distribuida. Es una forma eficiente de aplicar algoritmos paralelizables en distintas máquinas agrupadas en clusters. También ofrece varias ventajas en cuanto a escalabilidad, tolerancia a fallos y análisis de datos. Apache Hadoop es la implementación open-source de este modelo.
En esta sección podrás crear y gestionar clústeres de Amazon EMR desde SageMaker. Con el objetivo de llevar a cabo análisis detallados de los datos como análisis estadísticos para descubrir correleciones, patrones ocultos o tendencias existen en los datos que puedan ser de interés. AWS ofrece este servicio para su implementación de pipelines análisis en tiempo real y escalables de diferentes fuentes de datos con alta disponibilidad y tolerancia a fallos.
AutoML
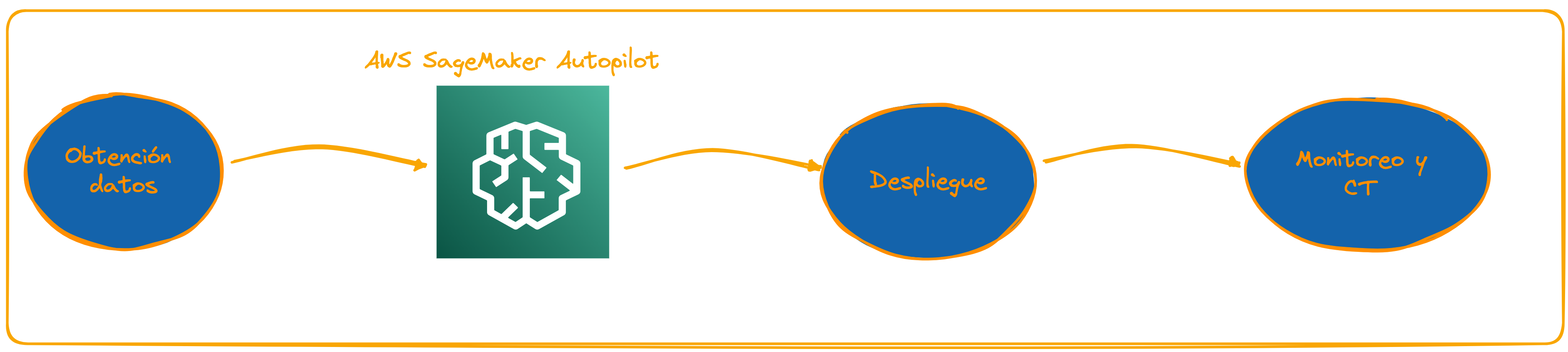
Este servicio que ofrece AWS, a través de su IDE SageMaker Studio, es precisamente lo que su nombre indica. Machine learning automático, eliminando el tedioso proceso del que llevamos hablando hasta ahora, el descrito en la sección de MLOps.
Con este servicio el gráfico se simplificaría así:
El concepto de Machine Learning Automático se tomó en serio cuando Google Brain, en 2017, publicó un artículo llamado Using Machine Learning to Explore Neural Network Architecture en el que investigaron con éxito cómo usar machine learning para explorar otros tipos de arquitecturas de redes neuronales.
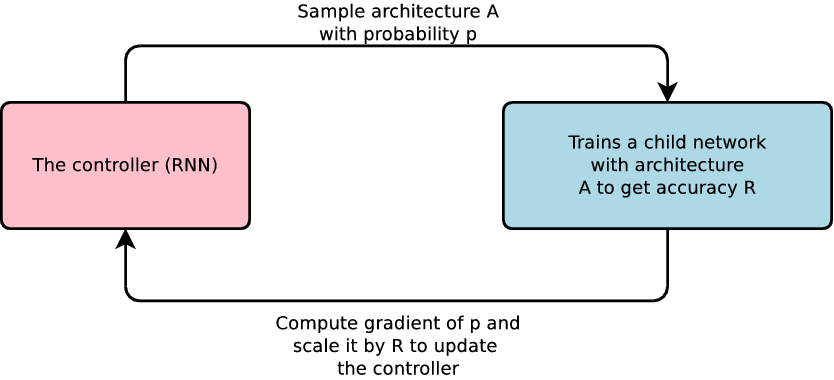
Según el artículo, su propuesta es una red neuronal controladora sugiere diseños de modelos «hijos» que se entrenan y evalúan en tareas específicas. La retroalimentación guía a la red para mejorar sus sugerencias. Repiten este proceso muchas veces, lo que permite a la red aprender a favorecer diseños que logran alta precisión en datos de validación y evitar diseños que no funcionan bien.
El potencial beneficio que ofrecen este tipo de sistemas es democratizar el acceso al machine learning. Puesto que como se ve en la imagen, no es necesaria una amplia experiencia ni conocimiento experto en el campo del machine learning para entrenar modelos que cubren una necesidad de negocio.
Por supuesto Google tiene su implementación de AutoML dentro de su plataforma de MLOps llamada Vertex AI. Si no lo conoces, también está mencionado en el anterior tutorial.
Pero en este caso vamos a ver la implementación de AWS dentro de SageMaker Studio.
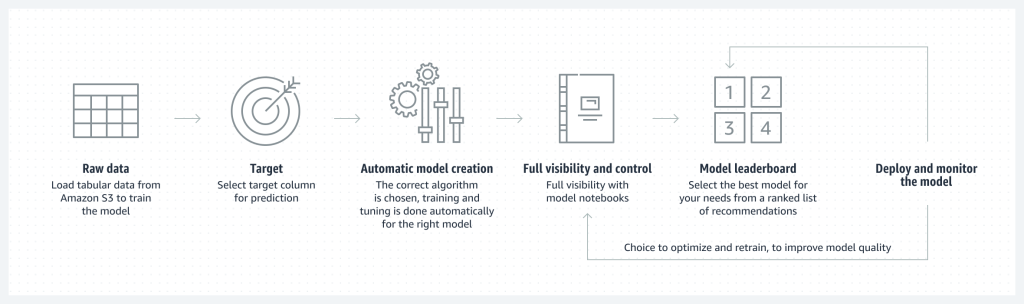
Models
Área de SageMaker enfocada en todo lo relacionado con los modelos en sí. Almacenamiento, búsqueda, control de versiones, optimizaciones, compilación etc. La compilación en el contexto del machine learning se define el optimizador, como Adam, la función de pérdida o las métricas que se evaluaran después del entrenamiento con el objetivo de dilucidar el rendimiento del mismo.
SageMaker divide esta sección en Model registry, dedicada a la gestión de versiones, búsqueda y almacenamiento e Inference compiler donde se enfoca en la optimización de los modelos ya entrenados.
Model registry
Según AWS, podrás almacenar y catalogar aquí tus modelos. También podrás instanciar nuevas versiones de modelos y registrar metadatos importantes de modelos en SageMaker Studio. A medida que los modelos vayan evolucionando, podrás gestionar su estado de aprobación en un pipeline de despliegue, automatizando el proceso CI/CD.
También podrás usar grupos de modelos, agrupaciones de modelos para resolver una tarea concreta. Por ejemplo, probar varios enfoques para completar una tarea de NLP o de computer vision, usando diferentes arquitecturas de redes neuronales, diferentes métricas e incluso diferentes estrategias de entrenamiento así cómo de pre-procesado de datos. Todo ello con un sistema de control de versiones integrado, lo que facilitará la colaboración con el resto de equipos de la organización. Todo ello se puede integrar en diferentes Collections.
Inference compiler
La inferencia se define como el proceso por el cual se derivan unas conclusiones a partir de unas premisas o hipótesis iniciales. En el caso del machine learning, es el proceso que consiste en utilizar un modelo de aprendizaje automático entrenado (premisas) para efectuar predicciones (conclusiones).
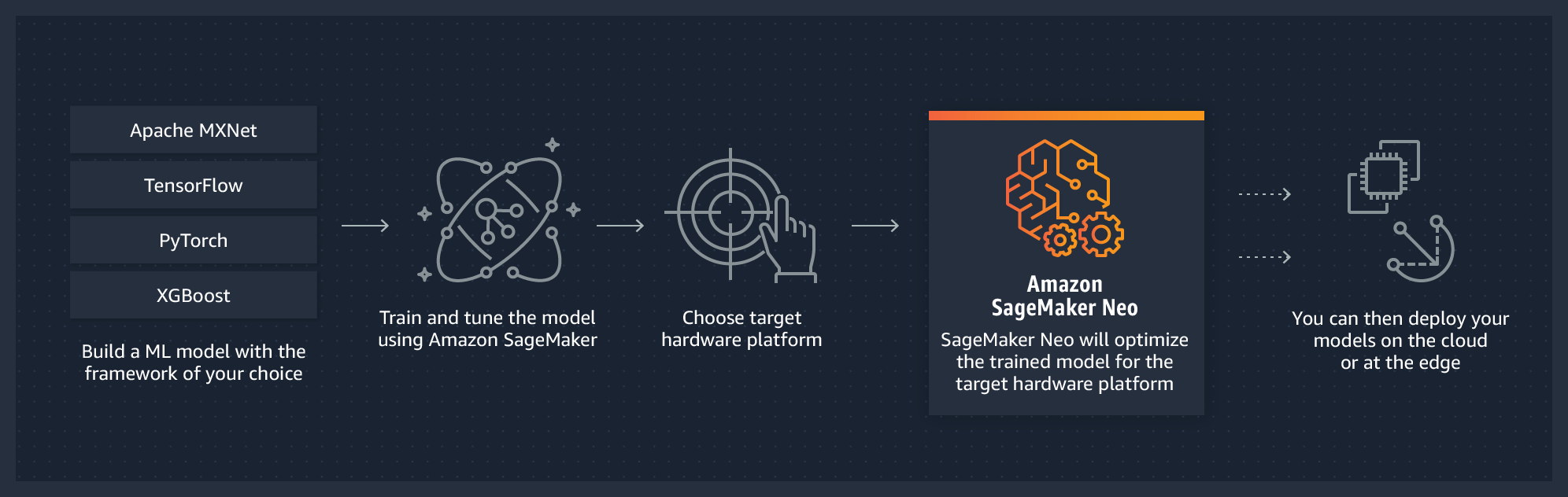
Inference compiler, según AWS, admite la compilación y el despliegue para dos plataformas principales: en la nube y edge computing (acercar el procesamiento lo más cerca posible de donde los datos están siendo generados). Optimiza automáticamente los modelos entrenados con Kerasm, Tensorflow o Pytorch, entre otros, para la inferencia en máquinas Android, Linux y Windows.
El servicio encargado de optimizarlo se conoce como AWS SageMaker Neo. Según AWS, optimiza automáticamente los modelos de aprendizaje automático para que las inferencias que se realicen en las instancias en la nube y en los dispositivos de edge computing, se lleven a cabo más rápido y sin ninguna pérdida de precisión.
Deployments
Área de SageMaker Studio dedicada a la gestión del despliegue de los modelos. Donde automatizarlos, gestionar los recursos, los pipelines, el ciclo de vida, optimizar los costes y el rendimiento de la inferencia de los modelos, y gestionar el ciclo de vida de los modelos desplegados.
Para poder llevar a cabo estas tareas dentro del Studio, AWS ofrece 3 secciones: Projects, Inference recommender y Endpoints
Projects
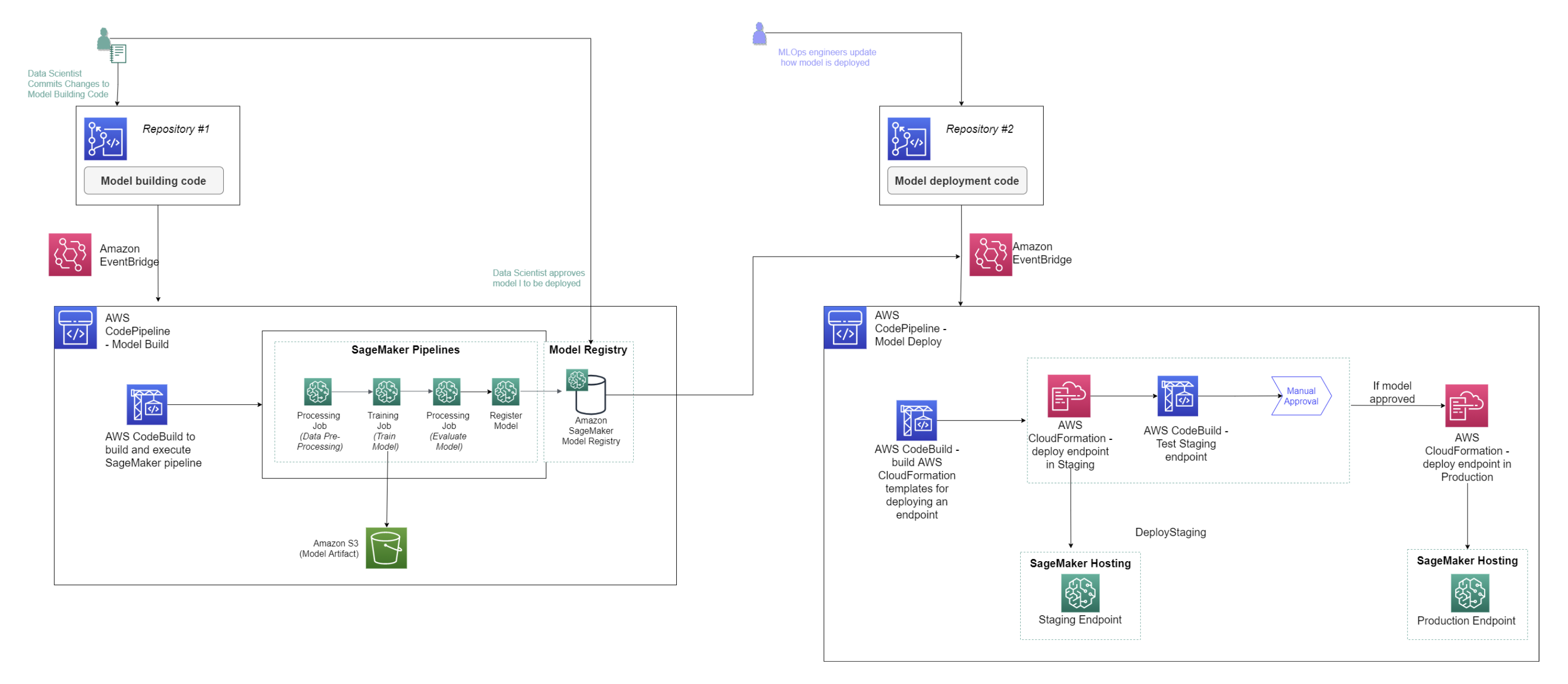
Es el área de SageMaker donde crear entornos completos de MLOps para una organización. Esta zona concentra la gestión de los recursos más importantes en único lugar para las soluciones end-to-end de ML.
Todo ello permite orquestar las fases del ciclo de vida de proceso de machine learning típico: preparación de datos e ingeniería de características, entrenamiento, evaluación, despliegue, monitoreo y actualización de modelos.
Es una herramienta que permite estandarizar prácticas de desarrollo de modelos de forma escalable que garantiza la consistencia del código así como un estricto sistema de control de versiones, ventajas que un Notebook de Jupyter o de Colab al uso no permiten.
Ofrece varias plantillas para empezar de forma sencilla un workflow que luego es fácilmente personalizable. Puedes saber más sobre qué son y cuándo son necesarios aquí.
Inference recommender
Función de Amazon SageMaker que reduce el tiempo necesario para poner los modelos de ML en producción mediante la automatización de las pruebas de carga y el ajuste o fine tuning de modelos en las instancias de ML de SageMaker. Te ayuda a seleccionar el mejor tipo de instancia y configuración
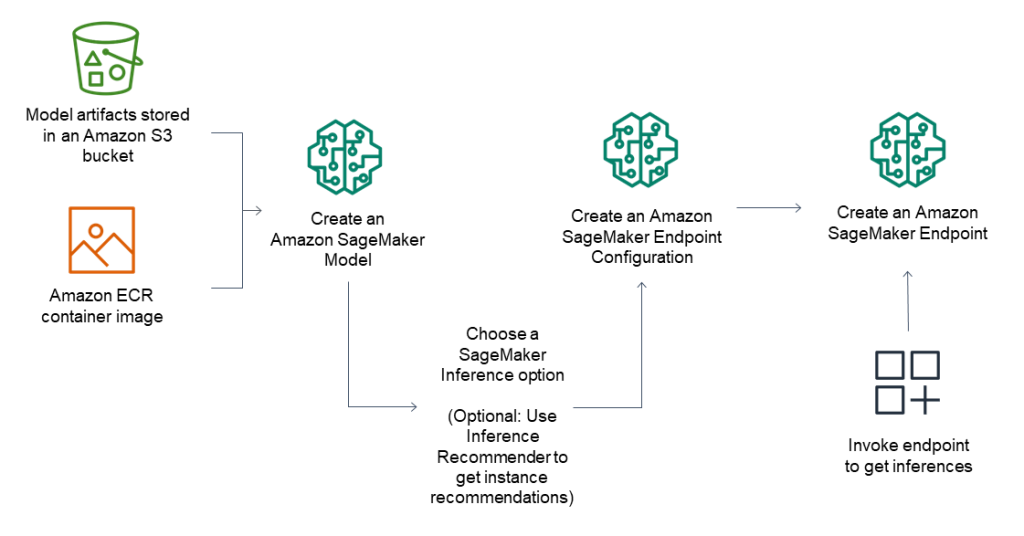
Endpoints
Provee infraestructura y opciones para el despliegue según las necesidades de tus modelos de inferencia. Permite crear endpoints en alta disponibilidad para obtener inferencias o predicciones de los modelos desplegados con baja latencia y alto rendimiento. Esta herramienta está muy relacionada con la anterior, como se puede ver en la imagen.
JumpStart
El centro de inicio rápido de machine learning de SageMaker. Donde puedes encontrar modelos open-source para completar tareas típicas de ML como NLP (Natural Language Processing), computer vision o reconocimiento de audio. Te provee de modelos pre-entrenados ejecutables en infraestructura de AWS directamente desde JumpStart. También ofrece una forma de acceder a través del SDK de Python. Puedes saber más sobre ello aquí.
JumpStart se divide en dos áreas: Models, notebooks & solutions y Launched JumpStart assets.
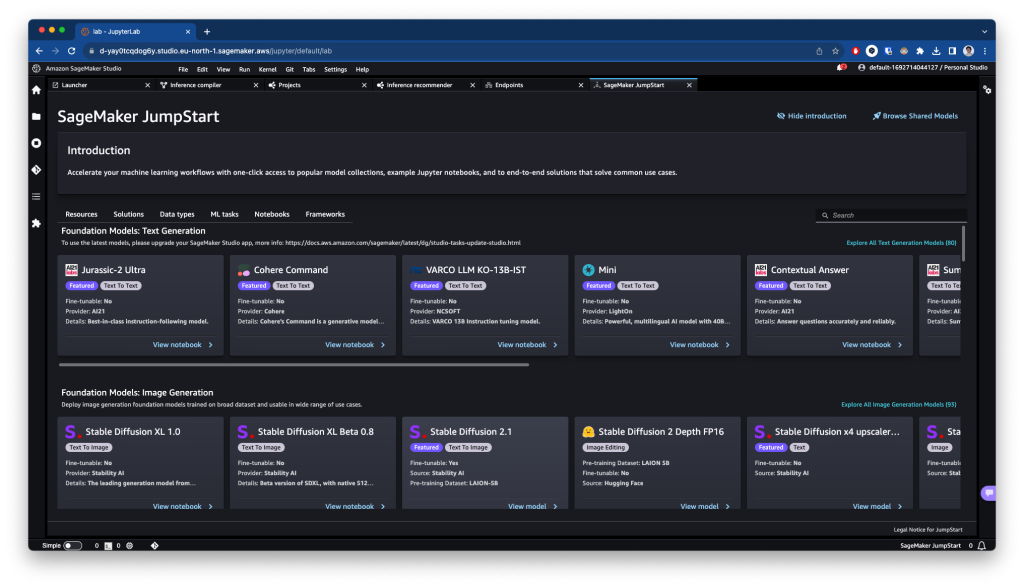
Models, notebooks & solutions
Es la sección principal, donde podrás acceder a estos modelos, tanto fundacionales en áreas como la generación de imágenes o texto como a modelos a los que aplicar fine-tuning. También podrás acceder a soluciones end-to-end listas para usar y desplegar.
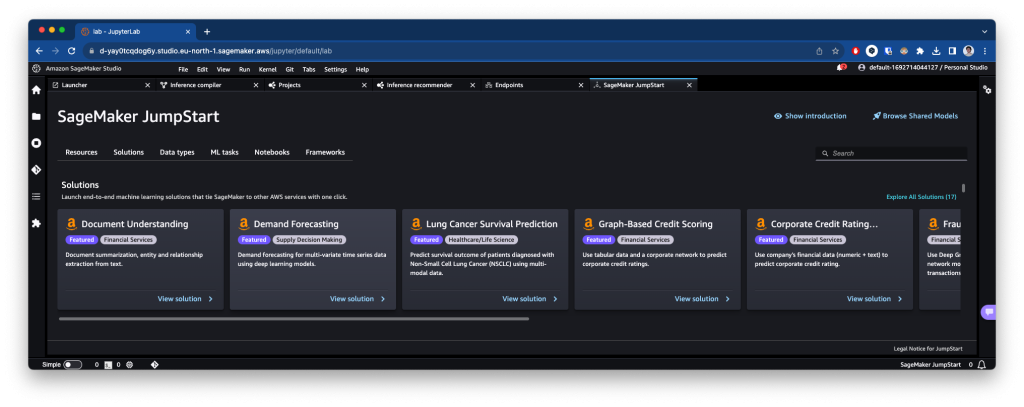
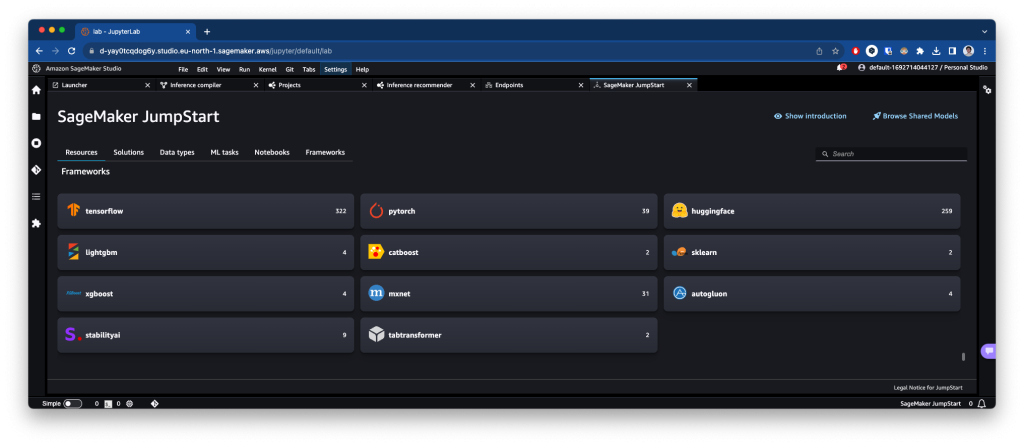
¿Cómo usarlo?
Para acceder a ello debemos ir a la consola de AWS y buscar el servicio o directamente desde la web oficial, nos redirigirá a la pantalla de inicio de sesión de nuestra cuenta AWS, e iniciar sesión o crear una cuenta nueva en caso de no tenerla, aquí puedes hacerlo.
Una vez hayamos accedido correctamente, veremos una pantalla como esta:
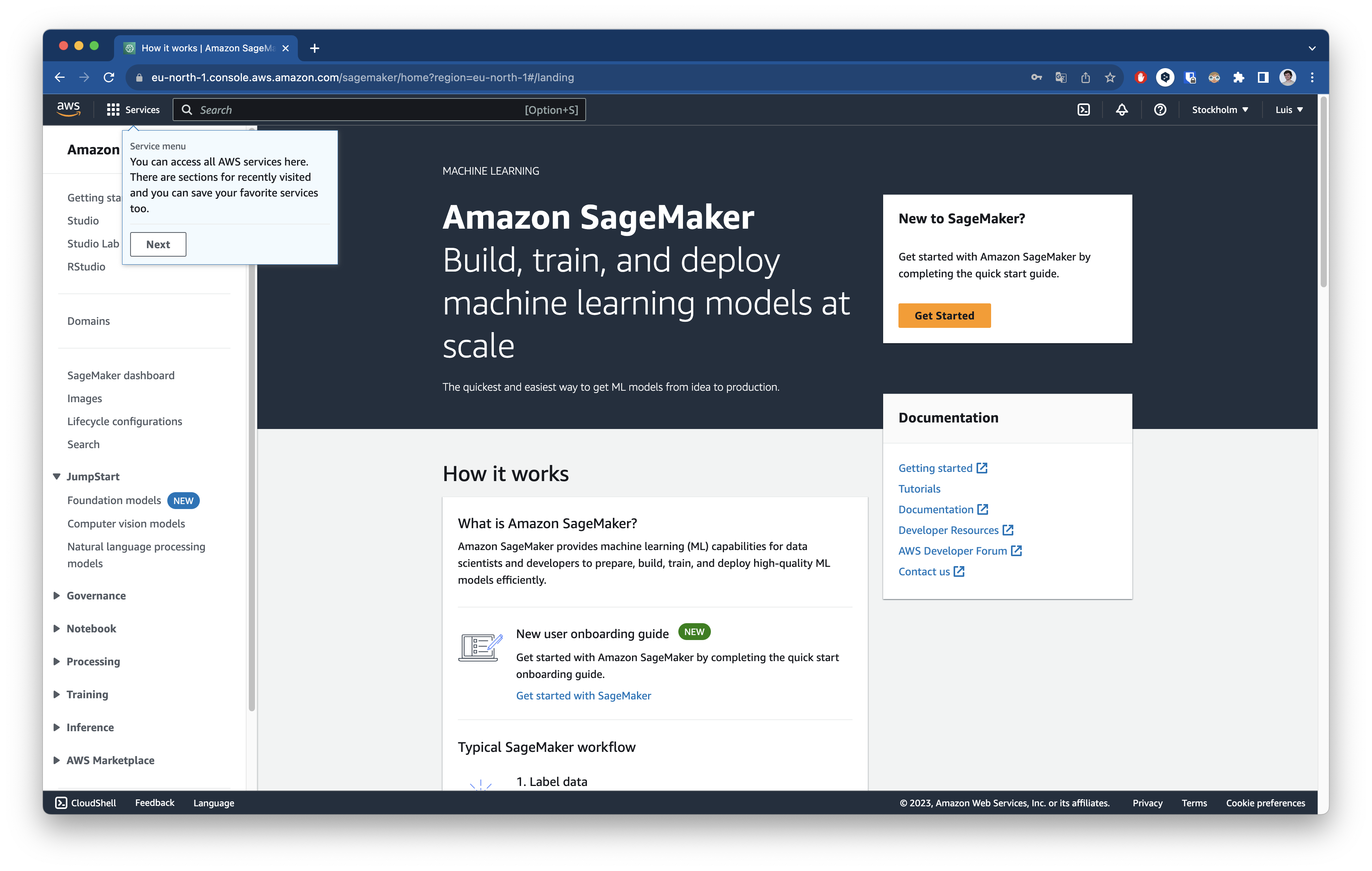
Vemos que en la columna izquierda todas las opciones que tenemos disponibles para usar. Guías de comienzo rápido, acceso a la interfaz de SageMaker Studio, sección de JumpStart que veremos más adelante, gobernanza del dato, acceso a notebooks de Jupyter, entrenamiento, inferencia etc.
Se puede preparar, entrenar y desplegar un modelo desde esta interfaz sin problema, pero SageMaker Studio está pensado para aumentar la productividad y la eficiencia. Para acceder ello debemos pulsar en la parte superior izquierda en Studio y veremos la siguiente pantalla.
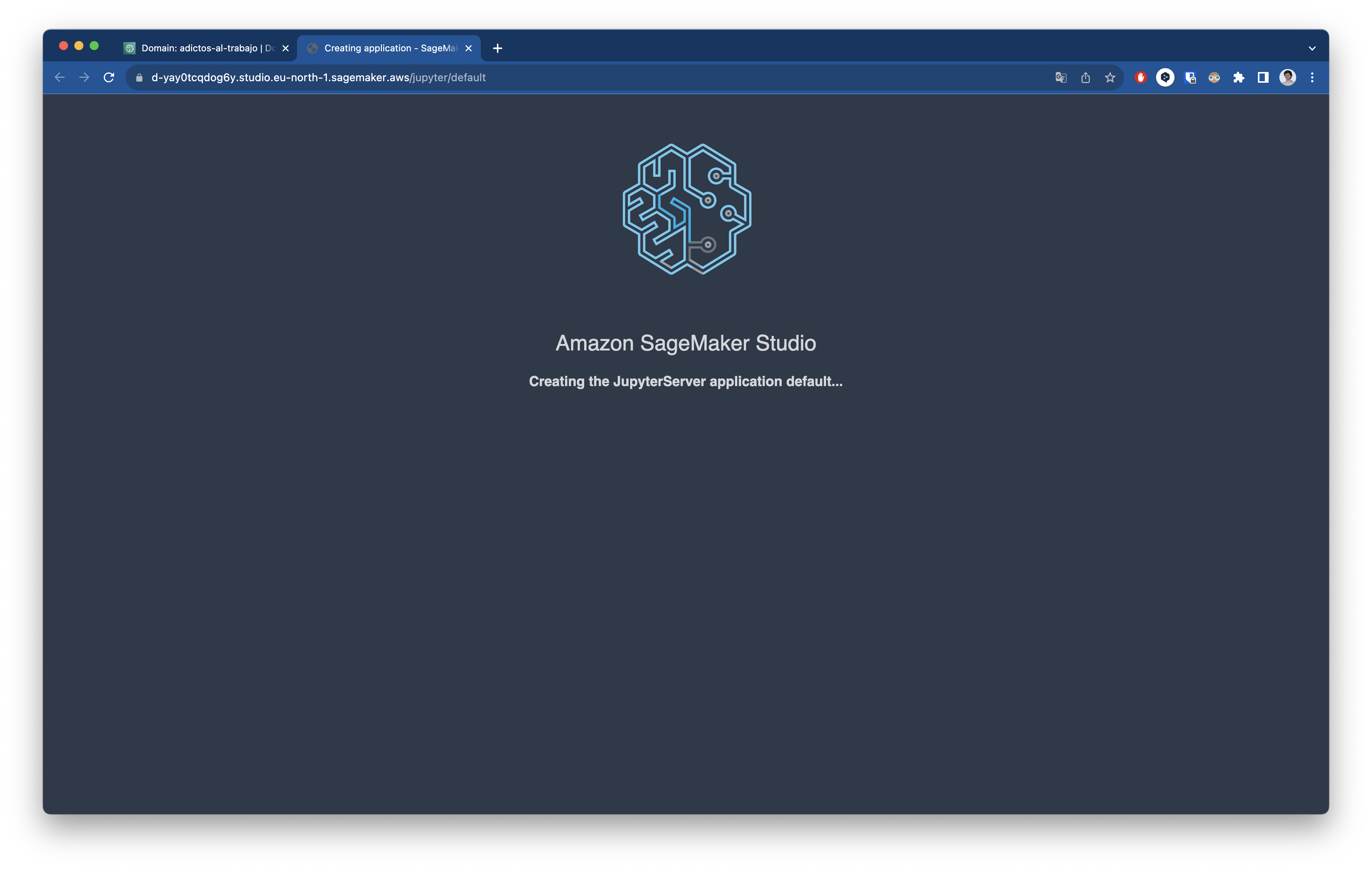
A partir de aquí podrás disfrutar de todas las herramientas que ofrece este servicio de AWS.
Precios
En la web oficial, ofrecen una variedad de enorme de precios y modelos de facturación. Te permite pagar de forma muy flexible y completamente personalizada.
Ofrece una versión gratuita en la que puedes usar el servicio con una serie de limitaciones pero es bastante laxo para las primeras pruebas. Luego ofrece una lista completa de ejemplo de precios o ejemplos de casos de uso de SageMaker, para que te puedas hacer una idea bastante precisa de cuánto te va a costar. Aquí puedes comprobarlo.
Más tutoriales
- ¿DevOps? Eso es cosa del pasado, conoce MLOps
- Med-PaLM 2: Tu nuevo médico de Google
- LLaMA-2: NLP open-source de la mano de Meta AI
- NLTK: tus primeros pasos con Procesamiento del Lenguaje Natural
- Figma, la solución definitiva para el diseño UI/UX
Referencias
- https://docs.aws.amazon.com/es_es/sagemaker/latest/dg/whatis.html#how-it-works
- https://aws.amazon.com/es/sagemaker/neo/
- https://cloud.google.com/learn/what-is-data-governance?hl=es
- https://sagemaker.readthedocs.io/en/stable/overview.html#use-sagemaker-jumpstart-algorithms-with-pretrained-models
- https://aws.amazon.com/es/sagemaker/data-wrangler/?sagemaker-data-wrangler-whats-new.sort-by=item.additionalFields.postDateTime&sagemaker-data-wrangler-whats-new.sort-order=desc

