

Conoce la metodología que te permitirá automatizar el ciclo de vida de tus modelos de machine learning
Introducción
Con el auge de las soluciones que nos aporta el machine learning y los beneficios que ellas aportan a las organizaciones, surgió la necesidad hace unos años de buenas prácticas o simplemente prácticas generalizadas que la industria debía seguir con el objetivo de mejorar la gestión del ciclo de vida los modelos basados en machine learning.
El éxito de la metodología DevOps, hizo que se adoptaran muchas prácticas incluidas en ella pero teniendo en cuenta las peculiaridades intrínsecas a la aplicación y mantenimiento de estos modelos de machine learning a la vida real de las organizaciones.
Índice
- ¿Qué es?
- DevOps vs MLOps
- Concept Drift, una carrera contra el tiempo
- CI/CD conocen a CT
- Herramientas
- Más tutoriales
- Referencias
¿Qué es?
Como su nombre indica es una práctica en el desarrollo de sistemas de machine learning (ML) que busca aplicar los principios de la metodología DevOps a este tipo de sistemas.
Estos se basan en unificar el desarollo de los modelos y las operaciones en el contexto de los sistemas de aprendizaje automático. Entre ellos, destacan los usados en la metodología DevOps más tradicional. Como la colaboración entre equipos de la organización, concretamente entre los equipos de desarrollo y operaciones. Fomentar la automatización, con el objetivo de no realizar tareas repetitivas que puedan ocasionar fallos humanos o pérdidas de tiempo innecesarias. Hacer uso de la infraestructura como código con este mismo objetivo de agilizar los procesos involucrados con el aprovisionamiento de la infraestructura.
Otro de los principios importantes es la implementación de un sistema de control de versiones y gestión de cambios. Así como una cultura latente en la organización de aprendizaje y mejora continua. Teniendo siempre como mayor prioridad un enfoque en el cliente y sus necesidades, así como entregar el máximo el valor.
Todos estos principios de la cultura DevOps son aplicables al mundo de desarrollo de modelos de inteligencia artificial y machine learning. Como se puede ver en la imagen, el MLOps trata de hacer uso de estas prácticas junto con las relacionadas con los datos y el proceso natural de ML. Vemos que es la unión de los procesos de DevOps junto con DataML.
DevOps vs MLOps
Aunque ambas comparten la misma filosofía, hay diferencias significativas entre ellas. En cuanto a la formación de los equipos de trabajo, suelen estar formados en su mayoría de personas investigadoras en el campo del aprendizaje automático o expertas en la ciencia de datos, lo que conlleva a que no suelan ser expertos en los principios de la ingeniería de software, con los potenciales inconvenientes que ello conlleva debido a los problemas inherentes al desarrollo de software.
En cuanto al desarrollo en sí de los modelos de machine learning, se diferencia del desarrollo más tradicional en que el nivel de experimentación y de prueba y error es mucho más alto que en otras disciplinas del desarrollo de software. Esto se debe a varios factores como la falta de arquitecturas de software como la hexagonal o el desconocimiento todavía latente de los modelos y su explicabilidad.
Por ello, en la mayoría de ocasiones el desafío en el desarrollo de modelos no es tanto la reproducibilidad de los fallos y el saber por qué ha fallado, sino por qué ha tenido éxito esa configuración usada. Esto no quiere decir que en el desarrollo tradicional no nos preguntemos por qué funcionan las cosas, pero debería ser menos frecuente que en el contexto del desarrollo de modelos de IA.
La implementación de los modelos de machine learning se vuelve compleja en el momento que sea necesario volver a entrenar el modelo una vez desplegado. Debido a ello, se deberán implementar pipelines que permitan reentrenar el modelo y redesplegarlo de forma automática.
Concept Drift, una carrera contra el tiempo
Por último y no menos importante, en el momento de poner en producción el modelo es cuando y como se verá afectado el rendimiento real del modelo. En un desarrollo tradicional hay que tener implementadas pruebas automáticas así como pipelines de despliegue automatizados para minimizar los errores e impedir que estos lleguen a los usuario finales. Aunque implementar estas medidas no nos asegura la no existencia de fallos en nuestra aplicación o en el rendimiento de la misma, sí que nos da cierta seguridad de que no va a haber grandes errores puesto que se ha probado antes.
Sin embargo, en el contexto de los modelos de machine learning en producción, la problemática viene determinada, como siempre, por los datos. Debido a que, de momento, funcionan en gran medida como una caja negra con dificultadas para explicar sus decisiones, el abanico de fallos respecto a un desarrollo convencional es más amplio. Aquí es donde entra lo que se conoce como concept drift o giro de concepto.
Se conoce como concept drift al fenómeno que ocurre durante el despligue de un modelo en el que la evolución de los datos actuales en producción invalidan los que se usaron durante el entrenamiento. Los conceptos que el modelo aprendió con esos datos en ese momento, ya no son válidos debido al inexorable paso del tiempo. Es un problema grave que afecta directamente al rendimiento, la precisión y la eficacia del modelo desplegado, puesto que está haciendo suposiciones o predicciones sobre datos anticuados que no representan la realidad actual.
La solución a este problema consiste en reentrenar el modelo con nuevos datos actualizados y desplegar el nuevo modelo sin interferir en la producción, de ahí la necesidad del concepto de continuous training o entrenamiento continuo (CT).
CI/CD conocen a CT
En el contexto del MLOps, también se aplican los conceptos de integración continua y entrega continua. En este contexto, la integración continua (CI) también se hace uso de la integración frecuente de cambios en el código fuente, con el objetivo de detectar errores de forma prematura. En concreto, se hacen uso de prácticas como integración de código, trabajando de forma común sobre un mismo repositorio. Las pruebas automatizadas no solo tratan de probar y validar el código, por ejemplo en Python sino también hacen validaciones de datos y modelos con pruebas de regresión o evaluación de métricas del modelo. Con el objetivo de minimizar el concept drift, también se hace integración continua de nuevos datos para actualizar y mejorar el rendimiento del modelo.
En cuanto a la entrega continua o despliegue continuo (CD), también tiene similitudes aplicables al MLOps. También hay prácticas que automatizan y simplifican la implementación y el despliegue de modelos de ML en producción. Entre ellas destacan el despliegue automatizado usando lo que se conoce como pipeline de entrenamiento de ML. Esto es un flujo de trabajo automatizado que incluye todas las etapas del proceso de desarrollo y entrenamiento, desde la preparación de datos hasta la evaluación de las métricas y el despliegue pasando por la monitorización y mantenimiento. Como en DevOps, la correcta implementación de estas técnicas, mejorará la eficiencia, mantenibilidad y reproducibilidad de los modelos de ML.
El increíble avance que ha tenido el machine learning, el deep learning y la inteligencia artificial ha sido determinante para muchos avances en la academia, que antes eran o irresolubles o muy difíciles de resolver con la programación o las técnicas de análisis de datos clásicas. Pero sin una aplicación práctica de estas novedosas técnicas de predicción de datos solo será útiles y serán responsables de verdaderas innovaciones que impacten en la vida de las personas si se aplican el mundo real y a los procesos que le afectan. En definitiva, democratizando su acceso y su uso por más gente, beneficiará al conjunto de la sociedad, este acceso se tiene a través de estas herramientas, con las que aplicar las técnicas al negocio:
MLFlow
MLFlow quizá la plataforma de MLOps open-source más popular para gestionar el ciclo de vida de los proyectos de machine learning. Su filosofía se basa en poner el mínimo de restricciones posibles para así interferir lo menos posible en tu flujo de trabajo. Aseguran, que está diseñado para funcionar con cualquier librería de ML, por ello se requieren cambios mínimos para integrarse con el código existente.
En la documentación oficial aseguran que trabajar con modelos de machine learning en entornos de producción es desafiante por varios motivos: Debido a la inherente naturaleza experimental en el desarrollo de estos modelos, es difícil rastrear los experimentos así como los parámetros o datos usados para un resultado particular. Como he comentado antes, también es desafiante la reproducibilidad del código. Aunque estén los modelos perfectamente versionados, hay veces que es necesario capturar el entorno entero de ejecución de un modelo, lo que dificulta la colaboración.
Otro de los problemas a la hora de poner en producción estos modelos, es la falta de un estándar a la hora de empaquetarlos y desplegarlos. Esto es debido a que cada librería opta por un enfoque y una extensión concreta según la que se use. Esto se une a que no hay una forma estandarizada de gestionar las versiones de los modelos ni de los entornos previos a producción.
Por todos estos problemas, MLflow ofrece 4 componentes: MLFlow Tracking, Projects, Models y Registry
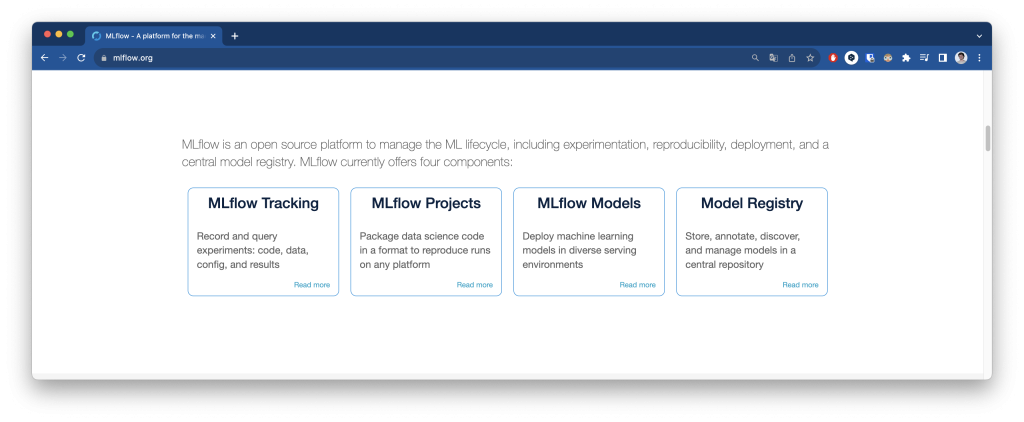
Estos componentes como, MLfLow Tracking, solucionan el problema del rastreo de parámetros, versiones, métricas, etc. Permite tener logs de los experimentos para luego consultarlos desde los lenguajes de progrmación y APIs. Puedes saber más aquí.
MLflow projects ofrece un formato para empaquetar y reusar el código relativo a la ciencia de datos, con el objetivo de ser reproducible. Permite configurar los entornos del proyecto, desde un entorno virtual de Python, Docker, Conda o tu propio sistema. Puedes saber más aquí.
MLflow models plantea un formato y un empaquetado para los modelos de machine learning. Define una convención que luego pueda usarse por otras herramientas. Puedes saber más aquí.
MLflow Model Registy es una solución al almacenaje de modelos centralizado. Ofrece un conjunto de APIs y una IU para poder gestionar el ciclo de vida. Lleva un control sobre qué experimento y ejecución produjo el modelo. Así como un pipeline con versionado de modelos para las transiciones entre entornos, desde los entornos previos al de producción como al propio entorno de producción. Puedes saber más aquí.
Amazon Web Services – SageMaker
Debido a la gran demanda de computación que necesitan estos modelos, la mayoría se alojan en entornos cloud, con todas las ventajas de autoescalado y rendimiento que ofrecen. Entre ellas AWS, ofrece una amplísima colección de servicios bajo lo que han llamado SageMaker.
![]()
Según la documentación oficial, SageMaker es un servicio, o colección de ellos, de machine learning totalmente gestionado, esto quiere decir que ofrece una solución end-to-end de desarrollo, despliegue y monitoreo de modelos de machine learning. Algunas de las funcionalidades más importantes son:
- Integrated Development Environment (IDE): Ofrece la posibilidad de usar Jupyter Notebooks directamente desde la plataforma con visualización y análisis de datos.
- Escalable. Permite usar la infraestructura de AWS para usar hardware optimizado, reduciendo los tiempos de entrenamiento.
- 1-click. Permite implementar modelos en producción y generación de endpoints.
También permite usar técnicas de pre-procesado de datos, etiquetado automático de datasets, uso de modelos pre-entrenado, monitorización y administración así como la automatización de pipelines. Puedes saber más en la página oficial, en la documentación y en la sección de precios por el uso del servicio así como el por el uso de la infraestructura.
Google Cloud – Vertex AI
La opción de Google para la aplicación de MLOps se llama Vertex AI. Dentro de esta solución ofrecen lo que han llamado Model Garden. Donde puedes elegir cualquier modelo base listo para usarlo y aplicarlo a tu caso de uso particular. Ofrecen algunos modelos entrenado por Google que puedes aplicar a tus necesidades.

Algunos de ellos son:
- PaLM para texto o para chat. Ya hablé de ello en este otro tutorial. El modelo fundacional de Google.
- Imagen. El modelo de texto a imagen.
- Codey como asistente de programación.
- Chirp para generar texto a partir de voz.
También podrás usar otros modelos de código abierto como BERT y podrás usar más modelos a través de sus APIs.
Ayuda a gestionar las complejidades asociadas a la aplicación de MLOps con pipelines de entrenamiento gracias a Vertex AI Pipelines o Vertex AI Feature Store.
Puedes saber más en este vídeo o en su página oficial.
Azure Machine Learning
La plataforma de servicios en la nube de Microsoft, ofrece Azure Machine Learning. En la página oficial, lo definen como un servicio de inteligencia artificial de nivel empresarial para el ciclo de vida de aprendizaje automático de un extremo a otro.
 La propuesta de Microsoft te ofrece gestionar el ciclo de vida de un proyecto de machine learning. Ofrecen una prueba gratuita de 12 meses para sus servicios y muchos de ellos siguen siendo gratuitos después de esta prueba. Algunos lo son hasta un límite mensual y otros lo son sin límite mensual.
La propuesta de Microsoft te ofrece gestionar el ciclo de vida de un proyecto de machine learning. Ofrecen una prueba gratuita de 12 meses para sus servicios y muchos de ellos siguen siendo gratuitos después de esta prueba. Algunos lo son hasta un límite mensual y otros lo son sin límite mensual.
En general, la plataforma ofrece soporte para:
- Pre-procesado de datos. Hay herramientas que permiten el etiquetado de datos, motores de análisis, así como acceso grandes datasets de entrenamiento.
- Creación y entrenamiento de modelos. Podrás usar Notebooks colaborativos, ajuste automático de modelos, interfaz drag & drop, entorno de CPU y GPU escalables, así como compatibilidad con bibliotecas open source más conocidas, TensorFlow, Keras, PyTorch.
- Validación e implementación de modelos. Acceso a pipelines de CI/CD y a entornos híbridos.
- Administración y supervisión. Análisis de errores, auditoría, seguridad, control del desfase de los datos de entrenamiento, monitoreo y control de costes.
Todo ello respaldado por la infraestructura de IA de Azure:
Resumiendo
MLOps se refiere a Machine Learning Operations y como su nombre puede indicar, es una metodología que buscar adaptar las prácticas de DevOps al aprendizaje automático. Tiene como objetivo agilizar y automatizar, gestionar y monitorizar el proceso de pasar a producción modelos de ML que alimenten sistemas de recomendación u otros sistemas que se basen en ML.
A la hora de aplicar esta metodología, igual que con DevOps, hay que tener en cuenta no solo aspectos técnicos sino organizativos de la compañía sobre la que se va a aplicar. Así como familiarizarse con conceptos como el concept drift (desfase de los datos de entrenamiento por el paso del tiempo) o Continuous Training (CT), el entrenamiento constante de los modelos para que el rendimiento no se vea afectado con el paso del tiempo.
Y por último, hemos visto que hay varias herramientas que podemos usar para aplicar MLOps en las organizaciones. Estas pueden ser open-source como MLFlow o no como las opciones que nos ofrecen los proveedores en la nube más conocidos como SageMaker de AWS, Vertex de Google Cloud o Azure Machine Learning de Microsoft.
También puedes ver esta charla de Databricks sobre MLOps en el Data + AI Summit 2022:
Más tutoriales
- LLaMA-2: NLP open-source de la mano de Meta AI
- NLTK: tus primeros pasos con Procesamiento del Lenguaje Natural
- Med-PaLM 2: Tu nuevo médico de Google
- Tu cara donde te imagines: Fine-tuning de Stable Diffusion ¡Gratis! (I)
- Kaiber: animaciones a golpe de prompt (III)
Referencias
- https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning?hl=es-419
- https://azure.microsoft.com/mediahandler/files/resourcefiles/gigaom-Delivering-on-the-Vision-of-MLOps/Delivering%20on%20the%20Vision%20of%20MLOps.pdf
- https://learn.microsoft.com/es-es/azure/cloud-adoption-framework/ready/azure-best-practices/ai-machine-learning-mlops#seven-principles-of-machine-learning-operations
- https://www.forbes.com/sites/forbestechcouncil/2019/04/03/why-machine-learning-models-crash-and-burn-in-production/
- https://www.seldon.io/machine-learning-concept-drift
- https://code.likeagirl.io/what-is-vertex-ai-9d26415933ef
- https://www.databricks.com/glossary/mlops
- https://azure.microsoft.com/mediahandler/files/resourcefiles/mlops-with-azureml/MLOps%20with%20Azure%20Machine%20Learning.pdf

