

Natural Language ToolKit, donde se unen el procesamiento del lenguaje natural y Python. No te lo pierdas.
Introducción
Con este paquete de Python aprenderás la bases del procesamiento del lenguaje natural con sus sencillas funciones. Como separar las palabras o frases en unidades con significado llamados Tokens. Aprenderás cómo las máquinas y los modelos entienden las palabras a través del concepto de embeddings. Y verás aplicaciones prácticas muy interesantes y prometedoras en el campo del procesamiento de historias clínicas electrónicas o la clasificación de las notas médicas de los profesionales sanitarios.
Índice
Natural Language Processing (NLP)
Gracias al absoluto éxito de ChatGPT en sus inicios (noviembre 2022) y sus sucesores (Bard o Bing Chat) se ha popularizado el término de Procesamiento de Lenguaje Natural (PLN) o Natural Language Processing (NLP). La mayoría habréis oído hablar de término últimamente, se trata de una rama de la inteligencia artificial que trata de resolver el problema de la comprensión profunda y precisa del lenguaje humano así cómo poder generarlo de forma coherente y en el contexto correspondiente.
Se ha vuelto tan popular este concepto debido a que los chatbots conversacionales impulsados por IA, como los mencionados anteriormente, han conseguido una aproximación muy buena para resolver este problema y otros asociados a la tarea de hacer comprender a las máquinas el lenguaje de los humanos, que va más allá de simples ceros y unos.
Algunos de los problemas que resuelven estos modelos de procesamiento de lenguaje natural se exponen a continuación.
La ambigüedad de lenguaje humano es claramente un desafío para los modelos de NLP, puesto que el significado de muchas frases o expresiones dependen en gran medida del contexto en el que se digan. Por tanto, aprender a tener el contexto de la conversación en cuenta es otro de los desafíos que estos modelos deben resolver.

El análisis sintáctico y gramatical también es una tarea que deben aprender. Tiene una complejidad añadida puesto que para cada lenguaje, las reglas gramaticales son diferentes por lo que dificulta entender el contexto de las frases.
Entre estas reglas, también es importante tener en cuenta que el problema de las correferencias. Según la RAE, es la relación entre dos o más elementos lingüísticos cuyo referente es común. Por ejemplo, la que se da entre le y a tu padre en Le doy la carta a tu padre. Ambas referencias son a la misma persona. Para nosotros no supone ningún problema ya que lo hemos aprendido durante nuestra vida, sin embargo para los grandes modelos de lenguaje es un desafío poder identificar y resolver estas correferencias, de nuevo para poder entender el contexto.
Dado que son modelos basados en machine learning, tienen todos los problemas inherentes a este tipo de inteligencia artificial. Primero, los datos de entrenamiento y la posible escasez de los mismos etiquetados es otro de los problemas a los que se enfrentan, y poder así transformar datos no estructurados como son los de lenguaje humano a datos estructurados donde los modelos puedan extraer patrones.
Por supuesto, dado que el objetivo es resolver las dudas y las preguntas de los usuarios de forma coherente, lógica y correcta, también es crucial que el texto generado por estas herramientas deben tener algunas cortapisas para no promover comportamientos violentos o discriminatorios.
Por ello, la ética y el control del entrenamiento será un tema crucial durante el entrenamiento de este tipo de modelos, así como tener muy en cuenta los posibles sesgos que se traduzcan del mundo real a las máquinas. Esto es importante para no generar instrucciones que puedan dañar a otras personas, como por ejemplo pasos para construir explosivos o generar contenido discriminatorio (machista, racista, homófobo etc…)

En definitiva, el mayor problema de que los modelos comprendan y generen lenguaje humano está en el contexto. Ya que, en general, en todos los idiomas el lenguaje está en constante evolución para ser muy eficiente. Esto conlleva a que se creen contracciones o reutilizaciones de las mismas palabras para significados diferentes dependiendo de la situación en la que se utilicen. Aspectos como por ejemplo, la ironía, el sarcasmo, las metáforas o el humor son un claro desafío.
Estructura del lenguaje
Una vez hemos visto esta serie de problemas que deben enfrentar los modelos para comprender el lenguaje humano, ahora vamos a ver un poco más en profundidad la estructura del lenguaje desde un punto vista lingüístico, para conocer más acerca de cómo tendrán que implementarlo.
Las características intrínsecas al lenguaje hacen que se agrupen de diferentes formas. Como la morfología que se refiere a la forma y estructura interna de las palabras. En cambio, el léxico se encarga de la segmentación del texto y las palabras en grupos significativos como palabras, veremos más adelante la importancia del léxico en la aplicación del NLP.
La sintaxis al conjunto de reglas para formar oraciones. En el de la semántica, se refiere a las relaciones existentes entra las oraciones para construir un significado superior. Y también muy importante en este aspecto, la pragmática, una rama de la lingüística que se enfoca en el estudio del uso del lenguaje en el contexto de la comunicación.
Análisis léxico
En el contexto de la algoritmia, se conoce como «divide y vencerás» a la técnica de resolución de problemas que consiste en descomponer un problema grande y complejo en subproblemas más pequeños, resolver cada subproblema de forma independiente y luego combinar las soluciones para obtener la solución del problema original. En este caso sería aplicable al NLP y al léxico.
Como en todo previo entrenamiento de modelo, los datos de entrada se deben pre-procesar. En este caso el primer enfoque a llevar a cabo en la aplicación o en el entrenamiento de modelos de NLP, suele ser este, dividir el texto en unidades básicas que más tarde puedan ser analizadas morfológicamente.
Este proceso de división o segmentación puede ser por frases, separar las distintas frases de un texto. Por ejemplo, las separadas por algún signo de puntuación. Pero también puede hacerse dividiendo las frases de un texto por palabras, tomando como separador un espacio en blanco, algún signo de puntuación o un salto de línea o retorno de carro.
Tokenización
Estas unidades básicas se conocen como tokens. Sin embargo, se debe decidir qué se considera como token a través de un proceso de tokenización. Básicamente se centra en separar el texto o las frases en unidades de procesamiento semántico, es decir con significado.
En resumen, se puede definir la tokenización como el proceso de división de un texto en unidades más pequeñas llamadas «tokens», que pueden ser palabras, subpalabras o caracteres. Esta división ayuda a estructurar el texto y facilita su procesamiento posterior por modelos y algoritmos de NLP. Es un primer paso de transformación de datos no estructurados a estructurados.

Puesto que no todo en todo en un texto tiene significado:
- Lastvistasrdesdelamontaññanossonbruenas
- Las vistas desde la montaña no son buenas
- Hola, este es tu regalo, es nuevo ¿Te gusta?
La primera frase no tiene ningún significado, la segunda si, por lo que podrá tokenizarse sin problema. Y la tercera también es correcta, pero tiene muchos signos de puntación que no tienen en el mismo significado que una palabra. Estos tokens tendrán que ser identificados y descartados. Por lo tanto, este proceso es crucial para facilitar y liberar de carga computacional a los modelos. Gracias a bibliotecas y lenguajes como Python y NLTK podemos realizar este proceso de forma fácil y sencilla.
NLTK ¡en acción!
Vamos a ver ejemplos prácticos sobre cómo utliizar Natural Language ToolKit. Usaré el formato Jupyter Notebook (.ipynb) dentro de Pycharm, el IDE para Python de la familia JetBrains. Pero también se puede usar Google Colab o cualquier otro editor.
Lo primero que debemos hacer en caso de que no lo tengamos ya es descargar obviamente Python y Jupyter Notebook. Python se puede descargar desde la web oficial, yo estoy usando la versión 3.11.3.
También habrá que descargar Jupyter Notebook, a través de la terminal con pip, el gestor de paquetes de Python:
pip install notebookEn caso de no tener pip instalado, lo puedes hacer así:
Descargar el archivo get-pip.py, en la misma ubicación que Pyton, con los requisitos necesarios para descargar pip:
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
Ahora ya podemos descargarlo:
python3 get-pip.py
Y comprobamos que todo se ha descargado correctamente:

Ahora abirmos Pycharm y creamos un nuevo proyecto con un archivo .ipynb:

Tenemos una vista como esta, una celda de independiente propia de los notebooks de Jupyter en la que ejecutar código Python:

A partir de aquí ya podemos utilizar las herramientas que nos provee NLTK. Solo tenemos que importarlo y usar las que necesitemos. Ya que en Python trabajamos con entornos virtuales, antes de importarlo, debemos instalarlo con pip:
python3 -m pip install nltk==3.5
Punkt
Es el tokenizador de NLTK, el algoritmo que lleva a cabo la tokenización de las palabras que pases por parámetro. Divide el texto en frases a través de un modelo no supervisado, esto es que no necesita datos etiquetados para su entrenamiento, obtendrá patrones de los propios datos. Es entrenable para reconocer abreviaturas o frases que comiencen con las mismas palabras.
Ahora ya podemos importarlo y descargar los componentes, entre ellos punkt.
import nltk
nltk.download("punkt")
from nltk.tokenize from sent_tokenize, word_tokenize
Probemos sent_tokenize (sentences_tokenize), nos permite tokenizar algunas frases que ha generado ChatGPT:
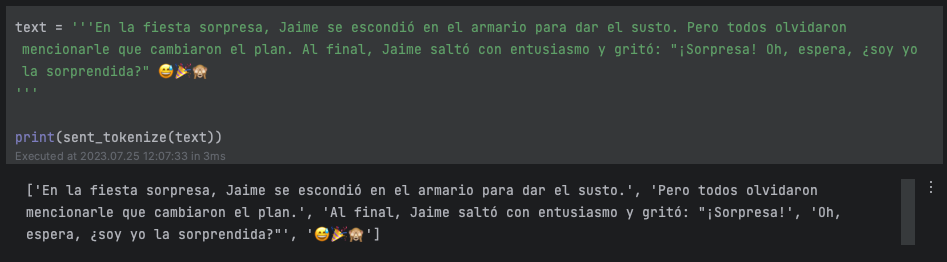
Como vemos le introducimos un texto y la función nos devuelve una lista con las 3 frases que componen el texto y además los emojis como una parte distinta.
Ahora probemos a tokenizar palabras con word_tokenize:


Vemos dos ejemplos en los que se separan las palabras, en el caso del texto en inglés, nltk entiende que «it´s» es una contracción y lo separa en it y `s.
Sin embargo, en los lenguajes en general hay muchas palabras que no tienen ningún significado y que simplemente sirven para conectar y no aportan mucho contexto, por lo que los algoritmos las deben obviar para así obtener un mejor rendimiento y mejor entendimiento del lenguaje.
NLTK veremos la lista que ofrece para español y para inglés:
from nltk.corpus import stopwords
spanish_sw = set(stopwords.words('spanish))
print(spanish_sw)

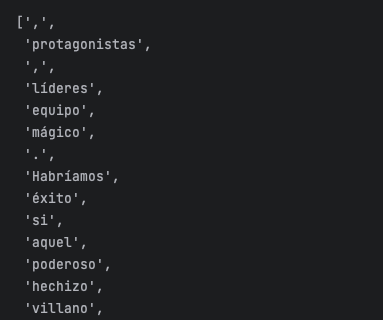
Todas estas palabras se pueden usar para filtrar textos y obtener información relevante. Primero le pedimos a ChatGPT un texto de ejemplo: 
Ahora lo procesamos con NLTK:
filtered_text = []
text_with_sw = '''
vosotras, las protagonistas, seréis las líderes del equipo mágico.
Habríamos tenido éxito si no fuera por aquel poderoso hechizo que tenía el villano.
Muchos estaban preocupados, pero confío en que habré encontrado la solución a tiempo.
Sentido tiene que haberles guiado hacia esta misión crucial.
Si estéis listas para enfrentar los desafíos, seríais capaces de superar cualquier obstáculo.
Tendrías que recordar que no se puede subestimar el poder que se oculta dentro de cada uno.
'''
words = word_tokenize(text_with_sw)
for word in words:
if word not in spanish_sw:
filtered_text.append(word)
print(filtered_text)
Lematización
Una vez hemos visto el análisis léxico, el siguiente paso es el análisis morfológico. Esto es el estudio de la estructura interna de las palabras, en este contexto vamos a ver como llevar a cabo la lematización.
Es el proceso lingüístico y de procesamiento de lenguaje natural que consiste en reducir las palabras a su forma base o raíz, conocida como «lema». El lema es la forma más básica y genérica de una palabra como el infinitivo en el caso de los verbos. Por ejemplo, «corriendo», «corre», «corrió» y «correrá» se reducirían todas a su lema «correr». Este proceso es muy importante en las técnicas de NLP.
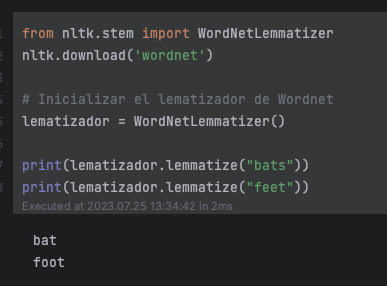
Importamos WordNetLemmatize, que será el lematizador que se encargue de tranformar las palabras a su forma más básica, a través de la función lemmatize. También tendremos que descargar Wordnet, la mayor base de datos léxica en inglés de la Universidad de Princeton. Esto es necesario porque la función lemmatize hace uso de ella. Por ello, únicamente podremos usar palabras en inglés.
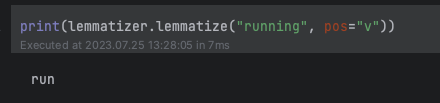
Vemos que ha lematizado bats y feet a sus formas básicas bat y foot. La función lemmatize por defecto espera sustantivos, en el caso de querer pasar verbos u otros debemos indicarlo, en el segundo parámetro pos (Part Of Speech):
print(lemmatizer.lemmatize("running", pos="v"))
En el caso de que queramos lematizar frases o textos, primero debemos tokenizarlos y etiquetar cada palabra según las categorías que define Wordnet: ADJ, VERB, NOUN y ADVERB principalmente. Aquí están todas las opciones. Y después procesar cada palabra con el lematizador. Antes que nada, descargamos nltk.download(‘universal_tagset’) en el entorno de Python, creamos una sencilla función para saber clasificar según las categorías de Wordnet y creamos un texto que queramos lematizar.
from nltk.corpus import wordnet
nltk.download('universal_tagset')
def get_wordnet_pos(word):
if word.startswith('ADJ'):
return wordnet.ADJ
elif word.startswith('V'):
return wordnet.VERB
elif word.startswith('N'):
return wordnet.NOUN
elif word.startswith('ADV'):
return wordnet.ADV
else:
return wordnet.NOUN
texto = "Luis´s dogs aren´t sitting calmly on the white mats"
texto_tokenizado = nltk.word_tokenize(texto)
texto_tokenizado
Primero, tokenizamos el texto con word_tokenize:
![texto tokenizado a ['Luis´s', 'dogs', 'aren´t', 'sitting', 'calmly', 'on', 'the', 'white', 'mats']](https://www.adictosaltrabajo.com/wp-content/uploads/2023/07/Captura-de-pantalla-2023-07-25-a-las-14.20.35.png)
palabras_etiquetadas = nltk.pos_tag(texto_tokenizado, tagset="universal") palabras_etiquetadas
![palabras etiquetadas [('Luis´s', 'NOUN'), ('dogs', 'NOUN'), ('aren´t', 'VERB'), ('sitting', 'VERB'), ('calmly', 'NOUN'), ('on', 'ADP'), ('the', 'DET'), ('white', 'ADJ'), ('mats', 'NOUN')]](https://www.adictosaltrabajo.com/wp-content/uploads/2023/07/Captura-de-pantalla-2023-07-25-a-las-14.25.17.png)
Se recorre la lista de palabras_etiquetadas por cada dupla en cada posición, obtenemos el token y la POS (Part Of Speech) de cada palabra del texto inicial. Estos parámetros se le proporcionan a lemmatize para poder llevar a cabo la lematización de cada palabra. Cada resultado se va almacenando en la lista lemas mediante list comprehension, como he mencionado antes.
lematizador = WordNetLemmatizer() lemas = [lematizador.lemmatize(palabra, get_wordnet_pos(etiqueta)) for palabra, etiqueta in palabras_etiquetadas] lemas
A partir de este texto inicial, obtenemos los lemas de cada palabra:

![Texto lematizado ['Luis´s', 'dog', 'aren´t', 'sit', 'calmly', 'on', 'the', 'white', 'mat']](https://www.adictosaltrabajo.com/wp-content/uploads/2023/07/Captura-de-pantalla-2023-07-25-a-las-14.33.33.png)
Embeddings
En el campo del Deep Learning y las redes neuronales sólo se puede trabajar con números que es lo único que entienden los modelos y en definitiva los ordenadores. Por lo que tenemos un problema si queremos que aprendan texto. Ya que si intentamos introducer palabras o letras en una red neuronal para que aprenda las relaciones entre ellas, las va a escupir como si de algo envenenado se tratase.
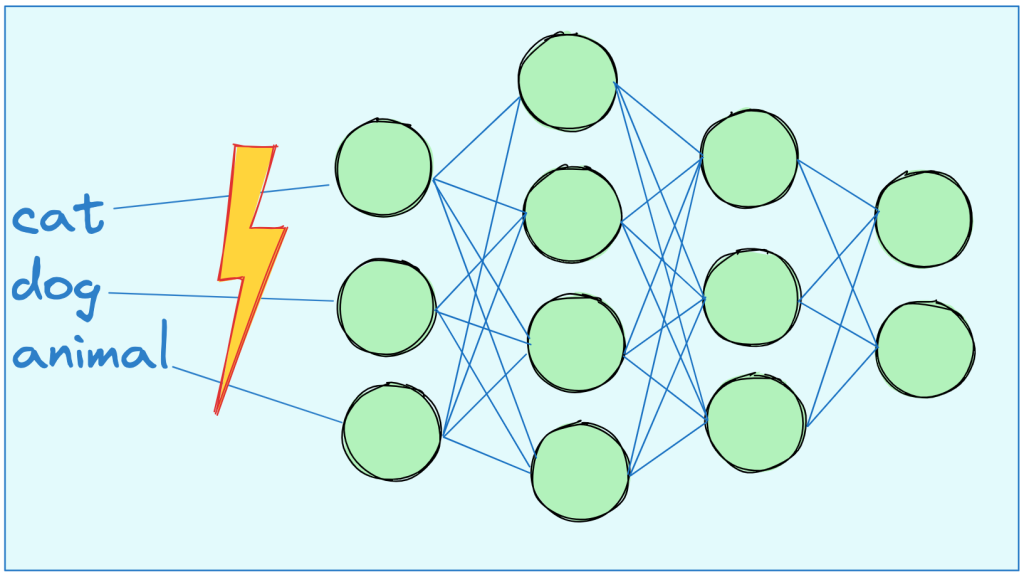
Por ello tenemos que buscar una forma de codificar las palabras a números que son el tipo de dato que acepta la red neuronal. Aquí es donde entran los embeddings.
Es una técnica de representación de palabras en vectores matemáticos. Cada palabra del lenguaje está representada por un vector, lo que permite hacer operaciones con ellos. Así podemos obtener la cercanía conceptual de las palabras en base a sus cercanía matemática en base de vector.
No buscan asignar un valor matemático a cada palabra, sino una representación contextual. Para que así la distancia entre cat y car sea muy grande, a pesar de ser palabras muy parecidas y que la distancia entre cat y dog sea pequeña puesto que pertenecen al campo semántico de los animales, a pesar de ser palabras muy distintas.
Este campo es muy extenso y queda fuera de este tutorial. Pero son imprescindibles para que los modelos puedan entender las palabras y poder aprender las relaciones sobre ellas. A través de como se ubicarían en un espacio vectorial y la distancia relativa entre los vectores permitiría agruparlas.
One-hot encoding
Es la representación más común de palabras como vectores. Tomando como vocabulario un conjunto de 3 palabras (perro, gato, periquito), para cada palabra, su forma vectorial se vería reflejada como todo ceros salvo una posición con un 1. Asumiendo que las posiciones pertenecen a una única palabra, es decir, en la primera posición solo puede representarse un 1 como perro y así sucesivamente.
![ejemplo de one-hot encoding en la que perro gato y periquito se representarían [1,0,0], [0,1,0] y [0, 0, 1] respectivamente](https://www.adictosaltrabajo.com/wp-content/uploads/2023/07/Captura-de-pantalla-2023-07-26-a-las-15.41.05-1024x759.png)
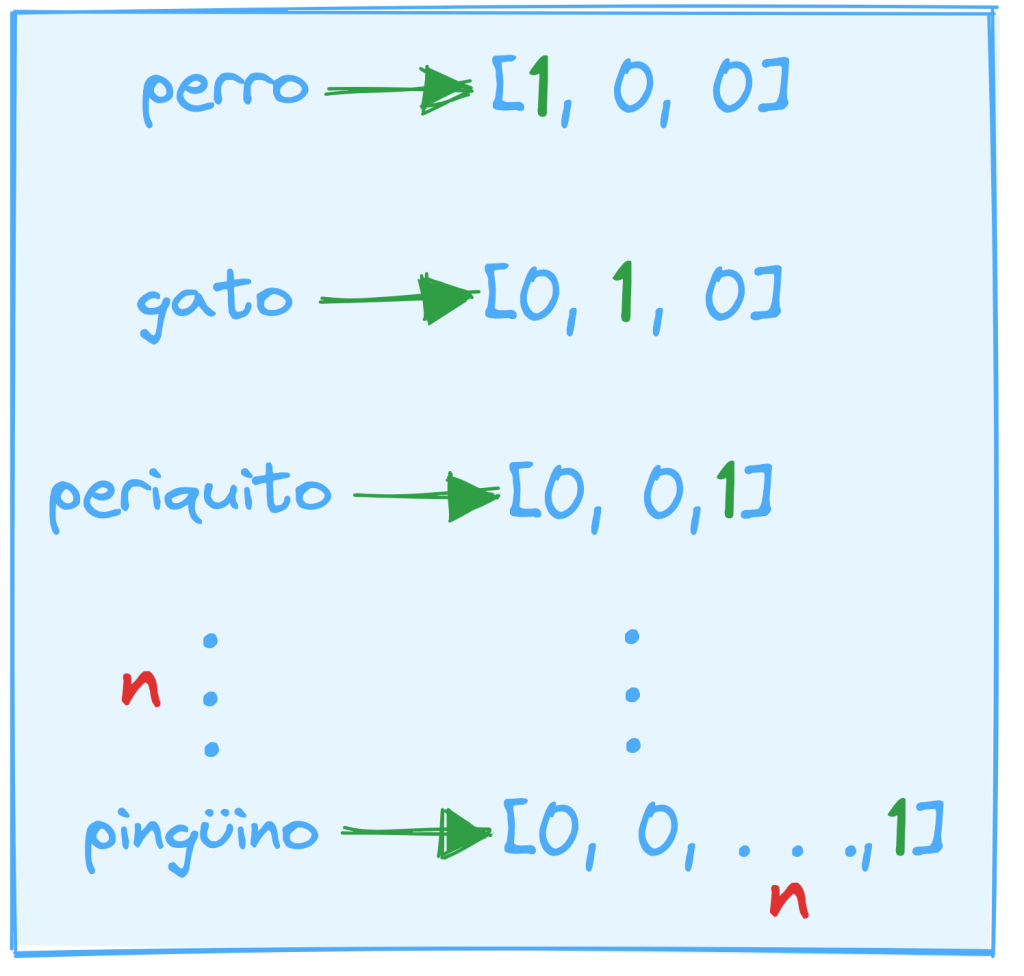
Esta técnica tiene el problema de que se manejan dimensiones muy grandes, por tanto una forma de reducir la dimensionalidad es usar los vectores como entrada de una red neuronal con un número de neuronas significativamente inferior al número de vectores de entrada.
Como siempre en el mundo del deep learning y el entrenamiento de modelos partir de cero es muy costoso y largo. Por ello, en la práctica, se usa la técnica de transfer learning para aprovechar el entrenamiento de un embedding para otra tarea parecida pero relacionada.
Una red entrenada para reconocer imágenes de medios de transporte, puede ser reutilizada para crear otra red que clasifique perros o gatos. La red ya ha aprendido a reconocer imágenes, solo hay que hacer reajustar qué tipo de imágenes queremos que reconozca.
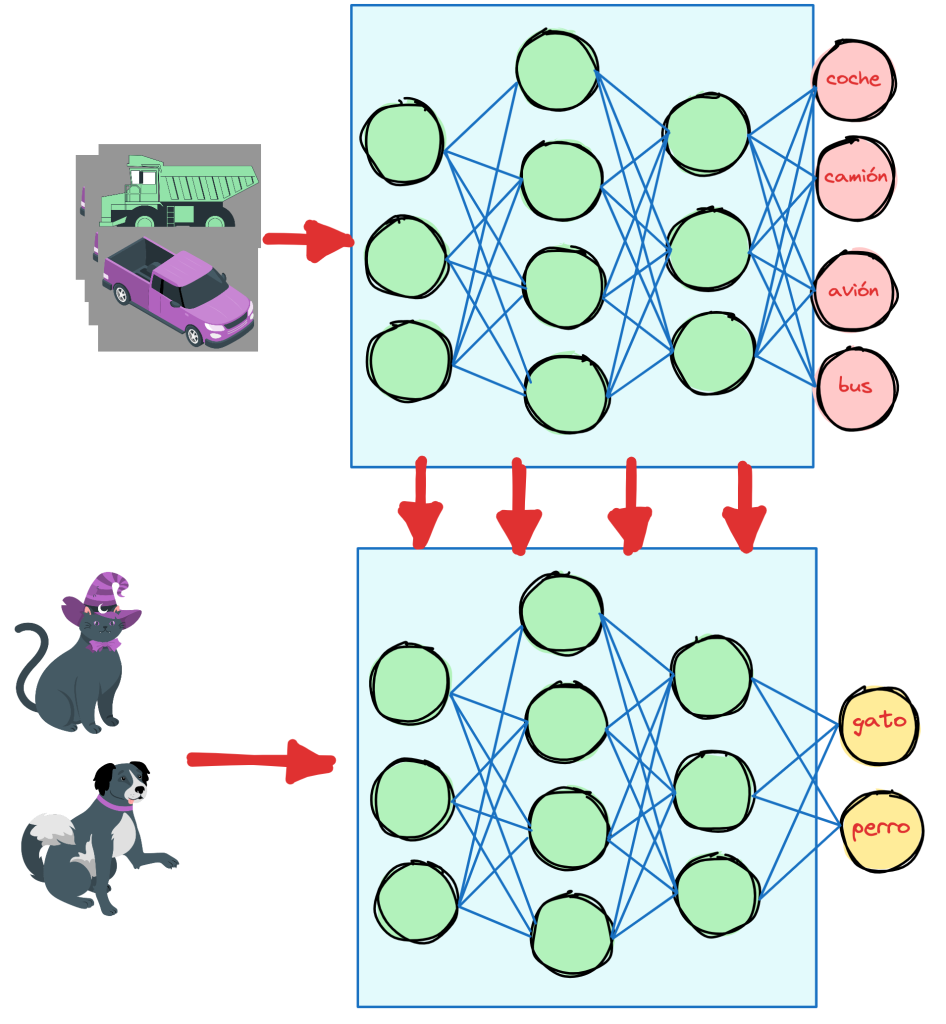
En el caso de los embedding es lo mismo, en este caso el modelo base es Word2Vec, desarrollado por Google en 2013. Que es capaz de detectar sinónimos o sugerir palabras adicionales para una frase sin terminar. Este modelo ha sido muy influyente en el campo del NLP y en los avances en el mismo.
Visualización de vectores
Gracias a una herramienta conocida como Embedding Projector, nos permite ver e interactuar con la nube de palabras que contiene Word2Vec:
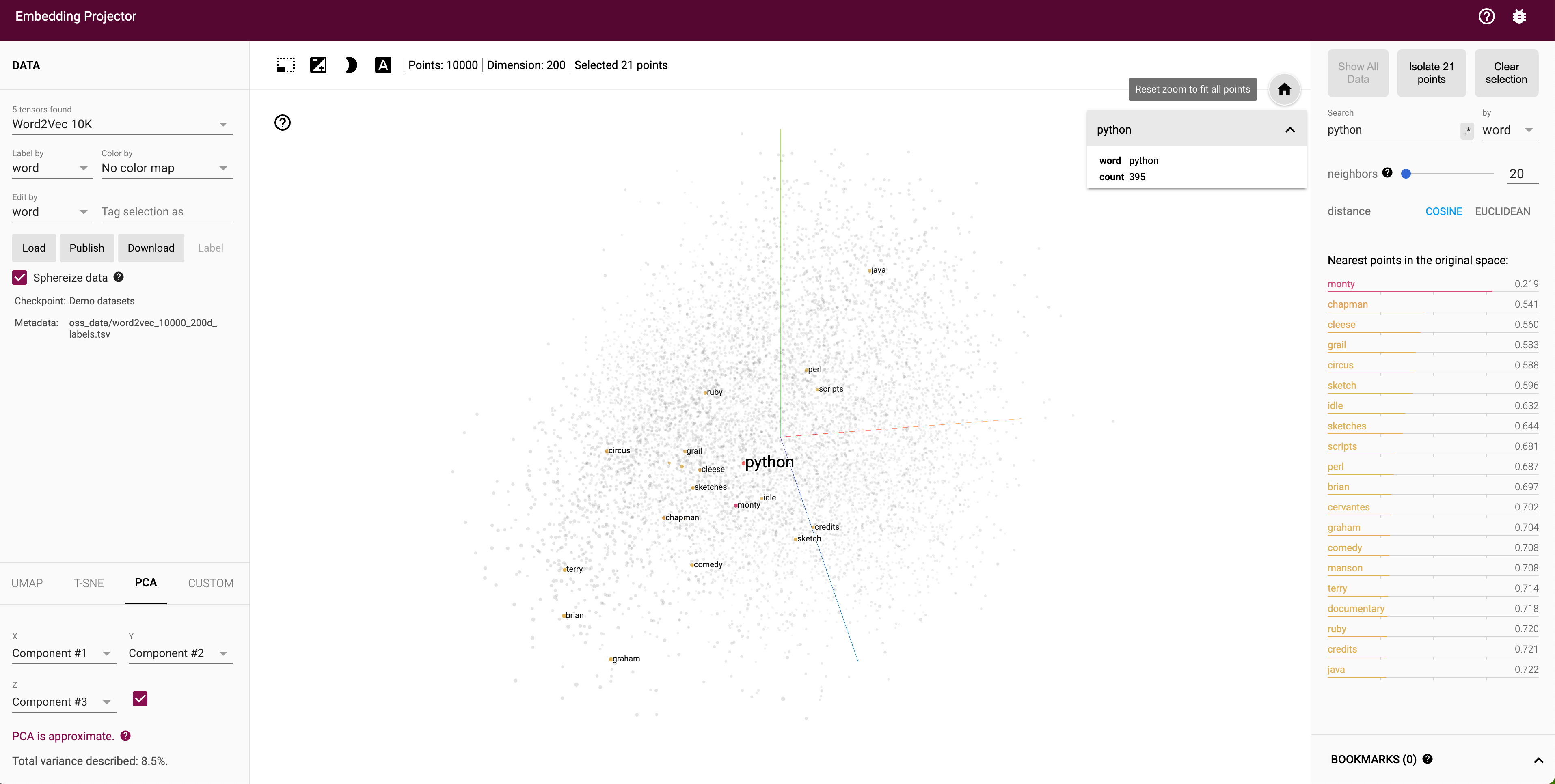
Aplicaciones
La lista es inmensa en cuanto a aplicaciones prácticas de las técnicas de NLP a la vida cotidiana. Pero me gustaría remarcar el potencial que tienen para ayudar al diagnóstico clínico y a la mejora de la calidad asistencial de los hospitales y centros de salud.
La historia clínica electrónica (HCE) es el registro que almacena toda la información de la relación paciente-sistema hospitalario, incluye todos los datos de pruebas clínicas a lo largo de la vida, citas, diagnósticos previos, enfermedades y tratamientos anteriores, intervenciones quirúrgicas etc.
Este tipo de texto es un candidato perfecto para aplicar técnicas de NLP. En concreto, se podrían usar técnicas de clasificación de enfermedades comunes o extracción de patrones comunes en pacientes distintos. Otra de las aplicaciones podría ser con las notas de los médicos, que debido a la cantidad de pacientes que reciben al día y a la presión que están sometidos, no les permite poder escribir descripciones detalladas de cada uno que acude a la consulta y en ocasiones pueden cometer errores ortográficos o usar expresiones poco comunes, lo que no facilita su procesamiento por técnicas de NLP.

Por ello, suelen usar abreviaturas o palabras clave sin mucha conexión aparente. Se conocen como texto libre, puesto que no sigue ninguna regla de escritura ni de puntuación. Pero es donde los médicos escriben su razonamiento para la conclusión del diagnóstico del paciente. De ahí que esta información sea tan valiosa a pesar de estar tan poco estructurada. Ahora mismo hay algunas herramientas que facilitan este proceso de clasificación de texto clínico como CTakes, de Apache.
Un sistema de procesamiento del lenguaje natural para la extracción de información del texto libre clínico de la historia clínica electrónica. Está entrenado específicamente para el dominio clínico y crea anotaciones lingüísticas, semánticas ricas y detalladas. Proveen varios ejemplos en su web.
Por último, este tipo de herramientas se entrenan con grandes corpus clinicos. Son datasets especialmente desarrollados con terminología clínica. Algunos de los más conocidos son The BioScope Corpus o The THYME Corpus.
Referencias
- DotCSV – INTRO al Natural Language Processing (NLP) #1 – ¡De PALABRAS a VECTORES!
- The coding train – 12.1: What is word2vec? – Programming with Text
- https://medium.com/escueladeinteligenciaartificial/procesamiento-de-texto-para-nlp-1-tokenizaci%C3%B3n-4d533f3f6c9b
- https://www.nltk.org/
- https://blog.devgenius.io/coreference-resolution-nlp-python-584c2ec50f5d#:~:text=Coreference%20resolution%20is%20the%20task,%2C%20subject%20etc…)
- https://platform.openai.com/docs/guides/embeddings/what-are-embeddings


Gracias por el paso a paso del NLTK, muy dinámico y visual la explicación