

Prueba ahora el modelo liberado por Meta AI en la lucha del NLP open source
Introducción
La carrera por llegar a desarrollar una inteligencia artificial que sea capaz de generalizar para cualquier tarea incluso para aquellas para las que no ha sido entrenada, es comparable a la carrera por la conquista lunar. Este tipo de IA, con capacidad igual o superior a la mente humana se conoce como AGI (Artificial General Inteligence) o Inteligencia Artificial General, también llamada Inteligencia Artificial Fuerte, siendo la actual la débil, puesto que solo completa tareas para las que ha sido entrenada. Se le dice general a aquella que es capaz, como he dicho antes, de completar tareas para las que no ha sido entrenada.
Con este fin empresas como Open AI o Google Deepmind dan pequeños pasos hacia ese objetivo, destinando recursos a sus productos como ChatGPT o Alphafold, respectivamente. Pero ahora hay un nuevo actor en la ecuación: Marck Zuckerberg junto con su empresa, Meta AI, responsables de liberar de forma open source su modelo de lenguaje más avanzado LLaMA-2.
Índice
Conoce a la LLaMA
Se conoce como LLaMA a Large Language Model Meta AI. Lanzada la primera versión en Febrero de 2023 como reacción a otros modelos de lenguaje como ChatGPT, lanzado en Noviembre de 2022 que, como se ha visto, se ha comido el mercado de este sector de asistentes conversacionales basados en inteligencia artificial.
LLaMA se publica como un modelo fundacional sobre el que mejorarlo y aplicarlo a tareas como la conversación. De la misma forma que Open AI publicó su modelo fundacional GPT, en sus diferentes versiones (2,3 ,3.5 y 4) que sirvieron para alimentar ChatGPT.
Desde Meta aseguran que han desarrollado un modelo fundacional de última generación para ayudar a los investigadores a avanzar en su trabajo en este sector de la IA y el NLP. LLaMA, a diferencia de otros, es un modelo más pequeño en cuanto a parámetros se refiere. Meta afirma que modelos más pequeños pueden aportar mayor rendimiento reduciendo drásticamente los costes de computación.
![]()
También aseveran que el tamaño de este modelo será beneficioso para otros miembros o grupos de investigación que no tengan acceso a grandes infraestructuras, lo que, según la compañía, democratiza el acceso al campo de la IA y del NLP en concreto. Este facilidad de acceso, mejorará la capacidad de los modelos así como nuestro entendimiento sobre su funcionamiento a la par que puede mejorar problemas existentes en los mismos, como el sesgo, cualquier tipo, o la generación incorrecta de información.
En Meta han entrenado varios modelos LLaMA. LLaMA 65B, LLaMA 33B con 1,4 billones (americanos) de tokens. Los tokens son unidades de palabras con significado, si no te resulta familiar este concepto, puedes aprender más en este tutorial introductorio al procesamiento de lenguaje natural. También tienen un modelo de 7B entrenado con 1 billón de tokens. Donde 65, 33 y 7 hacen referencia a los miles de millones de parámetros que se han usado para entrenar.
En un primer momento, el modelo se liberó bajo una licencia que no permitía el uso comercial del mismo, para mantener la integridad y evitar usos indebidos aseguraban.
Funcionamiento
Toma una secuencia de palabras como entrada y el modelo intenta predecir la siguiente palabra para generar texto coherente y de forma recursiva. Afirman que para su modelo eligieron texto de las 20 lenguas con más hablantes, poniendo el foco en los alfabetos latinos y cirílicos.
Como otros modelos y como modelo fundacional, comparte ventajas y desventajas con otros modelos o enfoque parecidos. No está exento de sesgos ni de generación incorrecta de texto, sin embargo, no está entrenado para una tarea específica, por lo que permite la extensión o el re-entrenamiento del modelo para otras tareas. Lo que le ofrece generalización de tareas.
Entrenamiento
Según el paper, han adoptado la arquitectura estándar basada en Transformers con una cantidad enorme de datos con un optimizador estándar. Como Adam, un algoritmo de optimización que se utiliza para mejorar el entrenamiento de red mediante la actualización de los pesos y sesgos de la red. Es de los más usados y conocidos por su eficiencia computacional y se potencial de aplicación a varios problemas. El objetivo de estos optimizadores es minimizar la función de pérdida de la red para aumentar el rendimiento de las predicciones.

Las diferencias con otros modelos, especificadas en el paper son:
- Pre-normalización. Aplican una función normalización o estandarización basada en RMSNorm (Root Mean Square Layer Normalization) en cada entrada de sub-capa transformer en lugar de aplicarlo a la salida. Este enfoque está inspirado en GPT-3.
- Uso de la función de activación SwiGLU. Reemplazo de la función ReLU, no lineal, por la llamada SwiGLU para mejorar el rendimiento. Enfoque inspirado en PaLM, el modelo de lenguaje de Google.
- Embeddings rotatorios. En lugar de usar Embeddings de posición fija, usan un enfoque rotatorio. Puesto que mejora la generalización, ya hablamos acerca de los embeddings en el mismo tutorial que he mencionado arriba sobre procesamiento de lenguaje natural. Este enfoque de embeddings rotatorios está basado en GPT-Neo.
Datos
Han utilizado una mezcla de fuentes de datos para el entrenamiento. Algunas de estas fuentes son: CommonCrawl con 3.3 TeraBytes, C4 o Colossal Clean Crawled Corpus una versión depurada de CommonCrawl con 783 GB, Github 328 GB, Wikipedia 83 GB o Arxiv 83 GB.
Aseguran que no han usado datos provenientes de las empresas que forman el grupo Meta (WhatsApp, instagram o Facebook):
«Does not include data from Meta’s products or services. We made an effort to remove data from certain sites known to contain a high volume of personal information about private individuals»
Una vez más, lo que ha mejorado el rendimiento de LLaMA-2 frente a LLaMA-1 ha sido la calidad de los datos de entrada así como el pre-procesado de los mismos. Afirman que han realizado una limpieza de datos más robusta así como un aumento del 40% de los tokens de entrenamiento y el aumento del contexto. Todo ello para mejorar la capacidad de inferencia de los modelos bajo LLaMA-2. En general, han aumentado hasta los 70 mil millones de parámetros para su modelo más grande frente a los 65 del modelo anterior.
Fine-tuning
Una vez han obtenido un modelo fundacional, es hora de usarlo para una tarea específica, en este caso para conversación realista con un humanos, lo que han llamado LLaMA-2-Chat. En el paper de LLaMA-2, especifican que este modelo es el resultado de meses de investigación así como de diversas técnicas incluyendo el ajuste o tuning de instrucciones o el RLHF, también conocido como Reinforcement Learning from Human Feedback.
Esto es que el modelo sigue un aprendizaje por refuerzo en base al feedback humano. El modelo va mejorando su entrenamiento tomando como referente correcciones humanas, no solo correcciones provenientes de la actualización de los pesos y sesgos a través de funciones de optimización como Adam.

Por encima de todo, esta técnica de aprendizaje por refuerzo humano aporta al modelo un mejor alineamiento con las preferencias humanas. En este proceso, son los humanos los que eligen qué salida del modelo les parece más correcta. Gracias a este feedback, el modelo puede ser entrenado por refuerzo o por recompensa para aprender estas preferencias que han definido los humanos y extraer patrones de ellas que luego puedan aplicar y automatizar.
Han incluido una técnica novedosa en este modelo respecto a los anteriores, que han bautizado como Ghost Attention. Puesto que la arquitectura Transformer original aporta esta capacidad a los modelos, la de atención, lo que ha sido crucial en la precisión y rendimiento de los algoritmos actuales de procesamiento de lenguaje natural.
Según ellos es un método sencillo que hackea los datos sobre los que se aplica fine-tuning para ayudar a centrar la atención en un proceso o conversación de varios temas, permite controlar mejor el diálogo.
Cómo usarlo
Desde que Meta, publicó el paper «Llama 2: Open Foundation and Fine-Tuned Chat Models» el 28 de julio e 2023, está disponible de forma open-source para toda la comunidad, lo que implica que también es posible usarlo con fines comerciales, a diferencia del modelo anterior.

Para poder usarlo o descargar el modelo, podremos hacerlo a través de Hugging Face, la plataforma líder en inteligencia artificial que ofrece bibliotecas y modelos de lenguaje avanzados para procesamiento de lenguaje y texto. Si quieres saber más acerca de esta plataforma puedes hacerlo a través de este tutorial.
En este enlace podrás acceder a la página oficial de Hugging Face de Meta en relación a LLaMA. Como verás, antes de poder usarlo, deberás registrarte en la web oficial de Meta para que te concedan acceso. Una vez hayas introducido tus datos, te llegará un email en el que especifican los primeros pasos con el modelo.
Además, también te llegará un email de Hugging Face concediéndote acceso al modelo a través de su plataforma.
Ahora sí, acedemos de nuevo al espacio de Hugging Face, veremos que nos habrán concedido acceso. 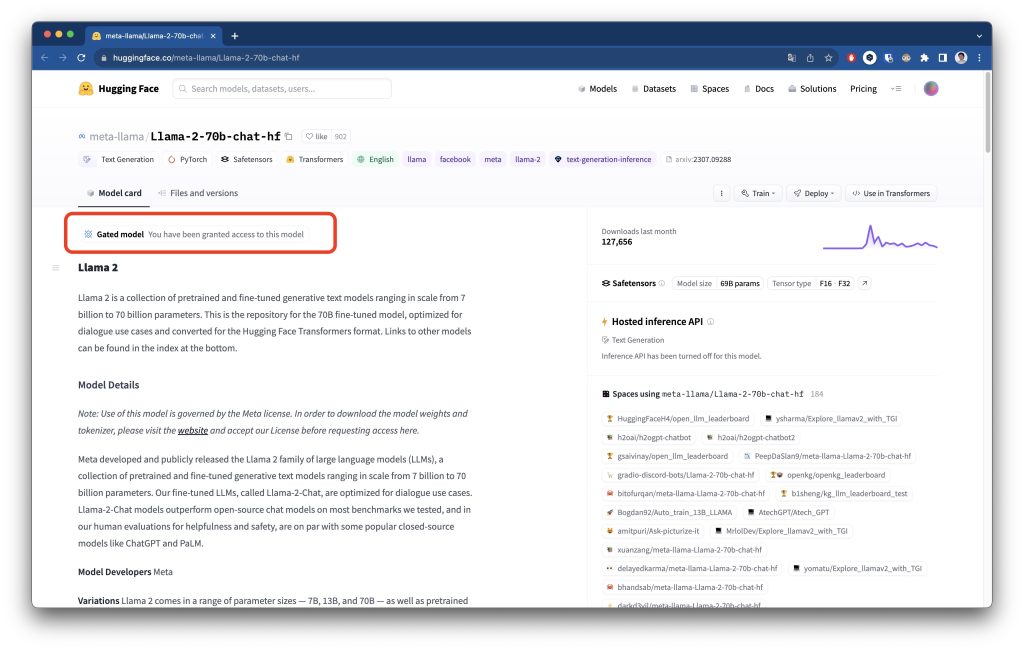
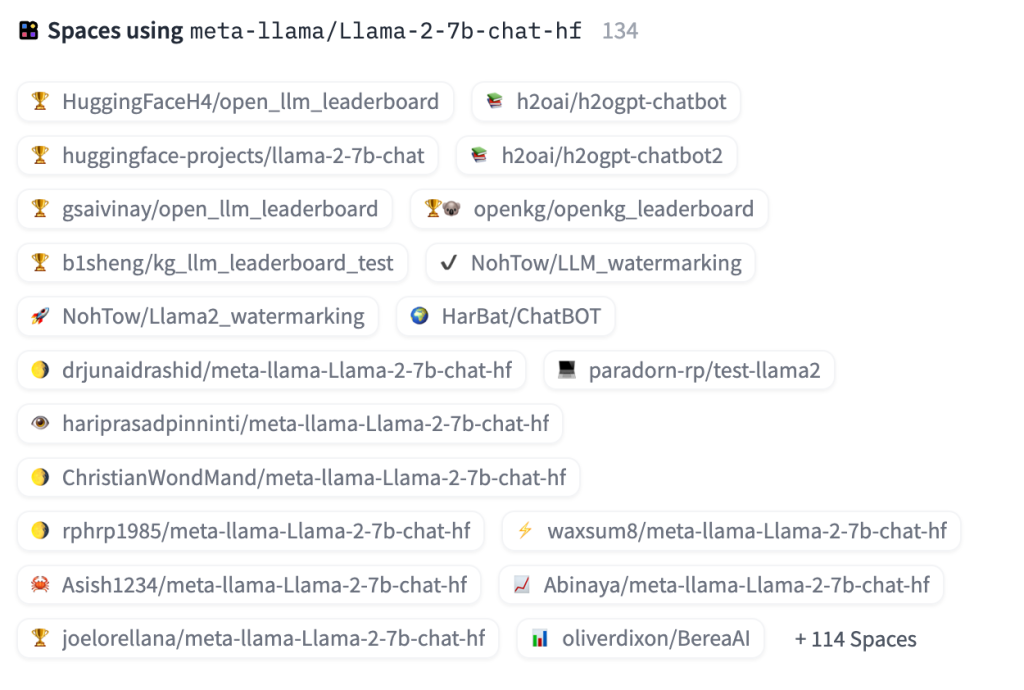
Como se puede ver en la parte inferior a derecha, hay mucho Espacios de Hugging Face que ya lo implementan. Así podemos usar cualquiera de ellos para probarlo, esto es posible gracias a su naturaleza open source. Por ello las personas interesadas en mejorarlo u entrenarlo para otras tareas más específicas, pueden hacerlo. Lo que facilita el avance y el desarrollo de esta campo con la potencia de la comunidad. Así lo especifican en la misma página:

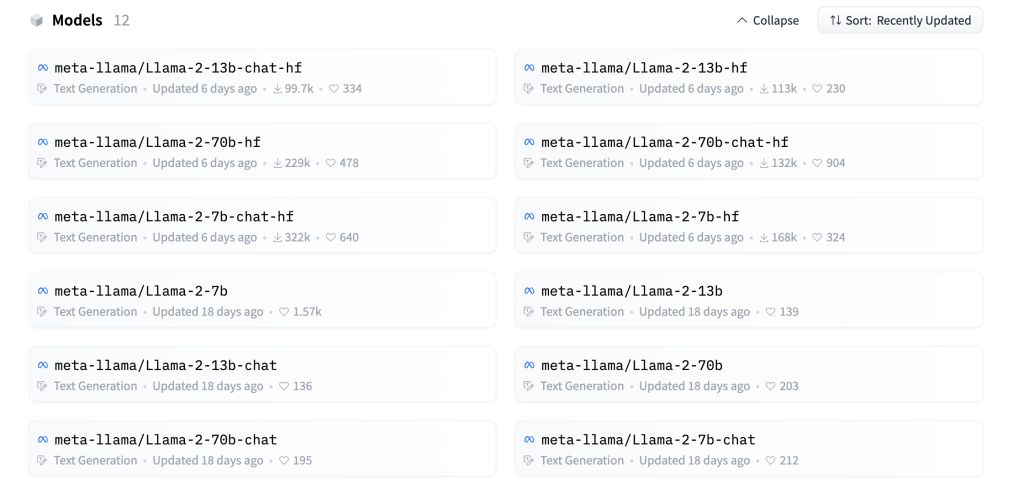
En este caso, usan Llama-2-7b-chat-hf que actualmente es el modelo con más descargas en el momento de escribir este tutorial, agosto de 2023, con 321,568 descargas. Este concretamente es el modelo de 7 mil millones de parámetros mejorado y optimizado para casos de uso de diálogo y convertido para el formato Hugging Face Transformers (por eso se ha llamado –chat-hf).

Una vez nos han concedido acceso, podremos hacer total uso del modelo. Descargar los pesos, y el modelo en sus diferentes versiones:
Vamos a probar el modelo mencionado antes con más descargas, Llama-2-7b-chat-hf. Para ello acedemos a uno de los espacios que lo usen, en este caso voy a usar huggingface-projects/llama-2-7b-chat:
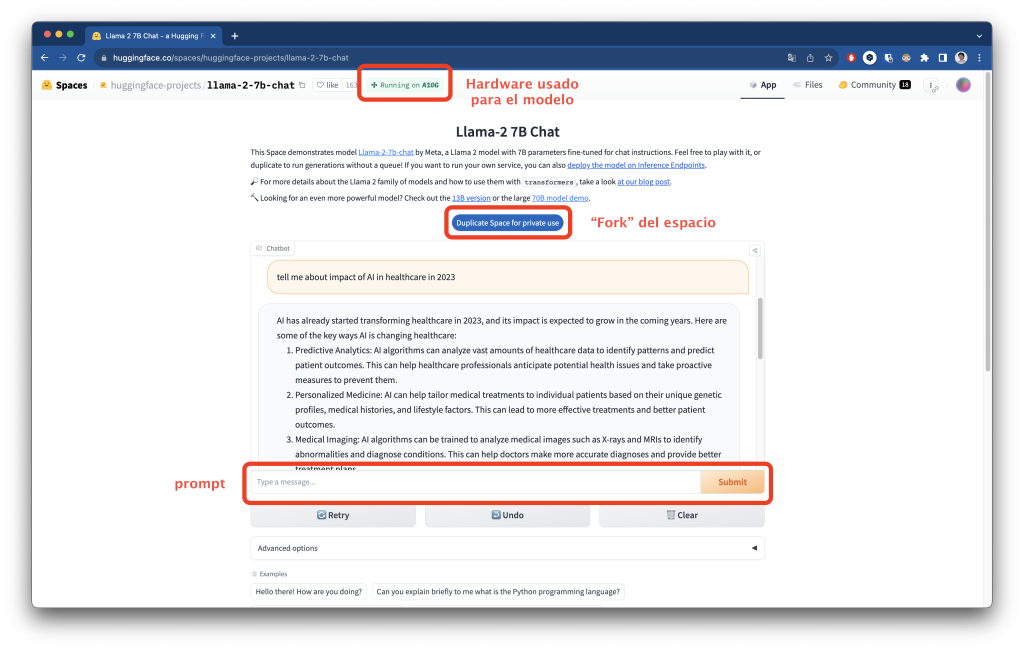
En la imagen podemos ver las distintas partes de la interfaz de uso del modelo para este espacio. En la parte superior, vemos que Hugging Face nos ofrece de forma gratuita el hardware necesario para ejecutar el modelo. Un poco más abajo nos ofrece duplicar el espacio para uso privado, lo que equivaldría a un fork de un repositorio de Github, donde podremos hacer los cambios que queramos. Por último y más importante, vemos la ventana de chat y la caja de texto donde introducir el prompt. En este caso le he preguntado sobre el impacto de la IA en el ámbito de la salud.
También se pueden hacer otro tipo de preguntas como a cualquier otro LLM (Large Language Model):
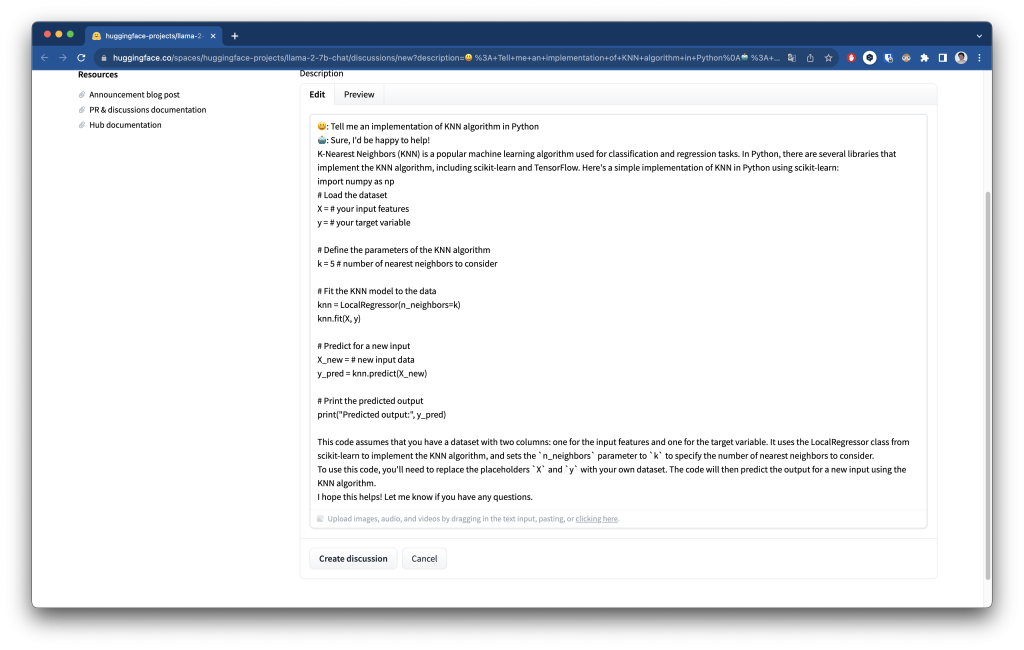
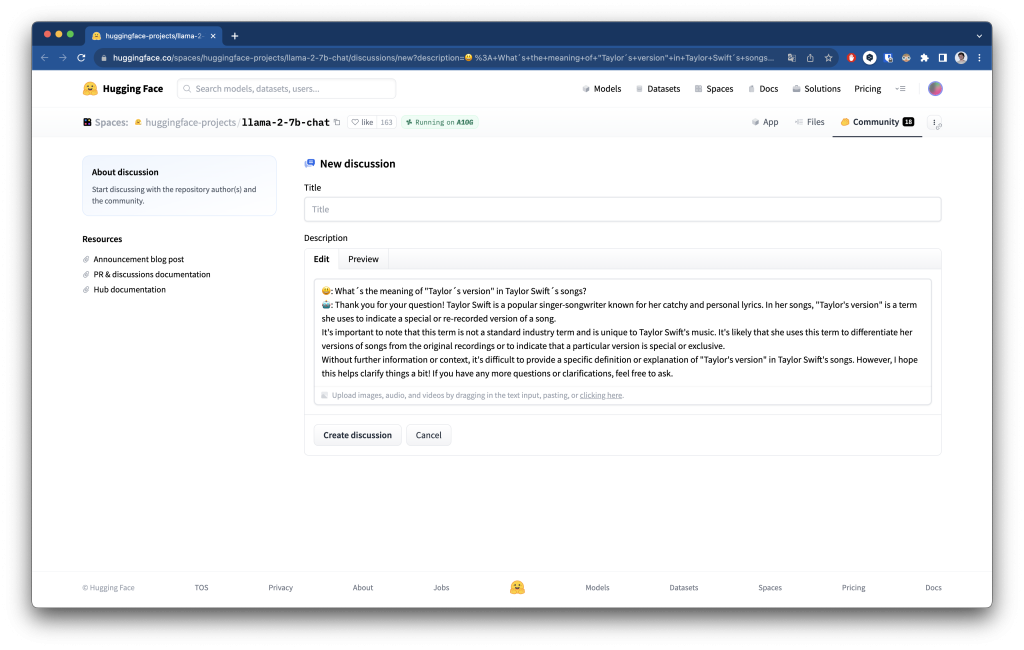
Otros tutoriales
Ahora como siempre, eres tú quién debe usar todo el potencial de estas herramientas para lo que te imagines. Si necesitas inspiración aquí tienes otros tutoriales sobre IA generativa:
- Tu cara donde te imagines: Fine-tuning de Stable Diffusion ¡Gratis! (I)
- Adobe Firefly: La nueva era de Adobe con IA (II)
- Kaiber: animaciones a golpe de prompt (III)
- Texto a vídeo con Gen-2 de Runway (IV)
- NLTK: tus primeros pasos con Procesamiento del Lenguaje Natural

