
En este primer tutorial de la serie de IAs generativas, aprenderás a usar este modelo para crear imágenes artificiales con tu cara.
Índice
Introducción
Hoy comienza una serie de tutoriales de inteligencias artificiales generativas. Comenzaremos en esta primera entrega realizando un fine-tuning del modelo Stable Diffusion, open source. Lo que nos permite modificarlo y refinarlo para adaptarlo a nuestras necesidades. En este caso me usaré para entrenar el modelo. Veamos cómo.
¿Qué es?
A estas alturas si no conoces ChatGPT, el producto de OpenAI, es porque has estado viviendo debajo de una piedra. Pero igual no conoces tanto modelos open source de generación de texto, como Open Assistant. Una iniciativa de código abierto con el objetivo de crear una IA conversacional fruto de la comunidad y no de una empresa. Esto tiene el beneficio de usar una técnica conocida como RLHF (Reinforcement learning from human feedback o Aprendizaje por Refuerzo con Retroalimientación Humana) . En este caso, es un proyecto organizado por LAION (Large-scale Artificial Intelligence Open Network) para toda la comunidad.
Con este mismo objetivo nació Stable Diffusion. De hecho, este modelo fue el que impulsó Open Assistant. Un modelo open source text-to-image, generación de imágenes realistas en base a una descripción de texto en lenguaje natural.
Stability.ai
Empresa responsable del desarrollo y despliegue del modelo Stable Diffusion. Creada en 2021, actualmente han formado una comunidad de +200.000 developers. Tienen un fuerte espíritu open source lo que permite que la fuerza de la comunidad se una frente a grandes desafíos abiertos de la inteligencia artificial como el procesamiento del lenguaje natural, entendimiento y procesamiento de audio, generación de imágenes, aplicaciones al campo de la investigación científica etc.
“Our mission is to build the foundation to activate humanity’s potential.”
Emad Mostaque, CEO & Founder Stability AI
Según el sitio oficial, tienen un acuerdo con AWS (Amazon Web Services) que les provee del quinto mayor supercomputador del mundo, el Ezra-1 UltraCluster. Y no fue hasta tan sólo agosto de 2022 cuando lanzaron la primera versión de Stable Diffusion con resultados tan espectaculares como estos:


Modelos de difusión
Como todo en este ámbito que trata imitar la realidad como es la inteligencia artificial, Stable Diffusion se basa en los conocidos como modelos de difusión. Aprovechan un fenómeno que se da en la física para potenciar este modelo. En este caso, deben su origen a la termodinámica. En física, se puede definir un proceso de difusión como el proceso natural de dispersión de sustancias desde una región de mayor concentración hacia una de menor, impulsado por el movimiento aleatorio de las partículas.

Aplicando estos conceptos a la informática se puede decir que se basa en añadir ruido a una imagen hasta completamente difuminarla siendo capaces de realizar el proceso inverso. En general, en teoría de la información este movimiento de sustancias equivale a la pérdida de información causada por la intervención gradual del ruido. Puedes saber más aquí.
Pre-procesado
A partir de aquí empezamos el primer paso para poder generar imágenes increíbles personalizadas con tu cara. Pero antes debes saber un par de cosas si no las sabes ya. Para todo modelo de IA es necesario, antes del entrenamiento del modelo, elegir los datos con los que va a ser entrenado. No sólo eso, también hay que determinar si los datos elegidos son apropiados para el modelo que pretendemos entrenar. Puesto que si la arquitectura de un modelo está definida para aceptar imágenes de 200×200, es obvio que sería absurdo entrenar el modelo con imágenes de otras dimensiones. O si el modelo está pensado para tareas de predicción de texto que se entrene con imágenes no tendría sentido. A este proceso de pensar y transformar los datos de entrada del modelo para que se adapten a la arquitectura del mismo se conoce como pre-procesado de datos.
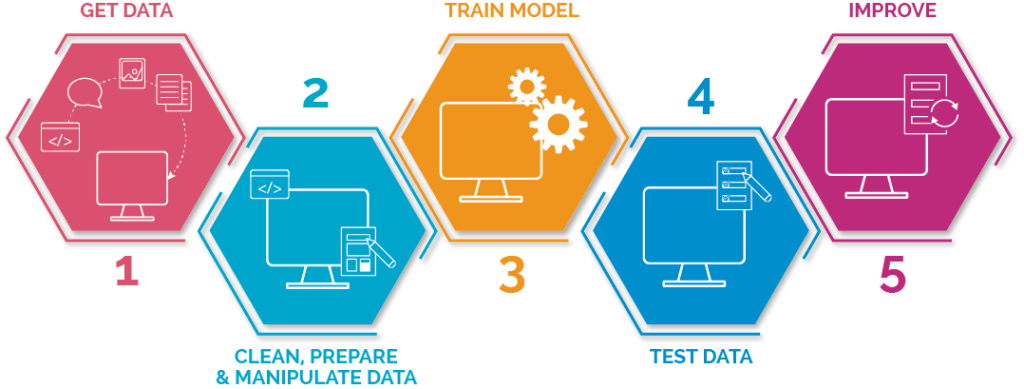
En este caso, vamos a usar Stable Diffusion. Por su naturaleza open source, el modelo es público por lo que se pueden modificar los parámetros de entrenamiento así como los datos de entrada. Con el objetivo de que el modelo aprenda nuestra cara y posteriormente podamos ser capaces de pedirle en lenguaje natural que genere imágenes con nuestra cara hasta donde nuestra imaginación nos lo permita (y las limitaciones del modelo).
Para este caso he usado imágenes mías. He utilizado alrededor de 25 imágenes de mi cara en varios escenarios para que el modelo generalice lo máximo posible sin que el modelo tenga overfitting. Esto es que el modelo entiende tan bien las imágenes que se las aprende «de memoria». Se aprende el conjunto entero de entrenamiento pero falla estrepitosamente cuando se le muestra una imagen de la misma persona pero distinta a las que ha visto durante el entrenamiento.
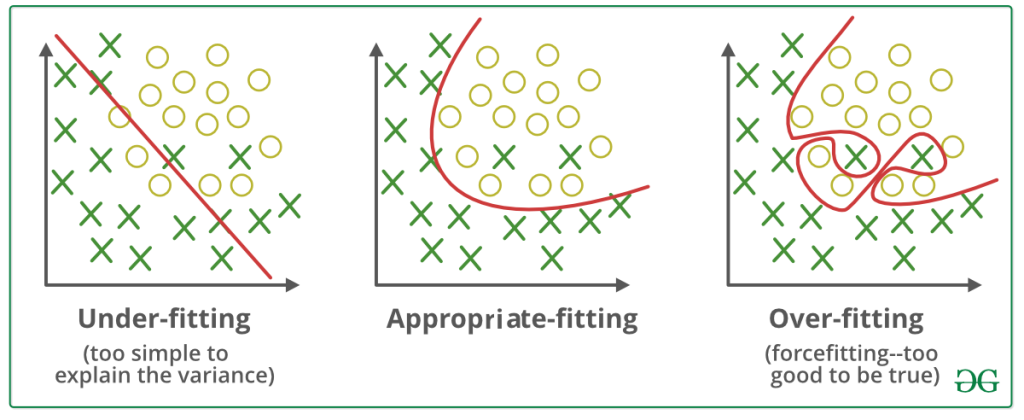
Fine-Tuning
Una vez que ya tenemos las imágenes formateadas como el modelo requiere, llega el momento de enseñárselas para que las aprenda. Normalmente, si quisiéramos entrenar un modelo con nuestra cara, tendríamos que diseñar una arquitectura de capas, funciones de activación etc. En definitiva, hacerlo por nuestra cuenta e ir refinando los hiper-parámetros para que el modelo cumpla con su función, generar imágenes con nuestra cara en las situaciones que le pidamos.
Ahora bien, nos ahorraríamos mucho tiempo si existiera un modelo que ya esté entrenado para generar caras en cualquier situación y solo tuviera que aprender la que nosotros quisiéramos. Bien pues estamos de suerte. Este modelo se llama Stable Diffusion y es del que hemos estado hablando hasta ahora. Gracias a su naturaleza de código abierto, es posible retocar los parámetros con los que fue entrenado inicialmente, incluso añadir otros datos al conjunto de entrenamiento.
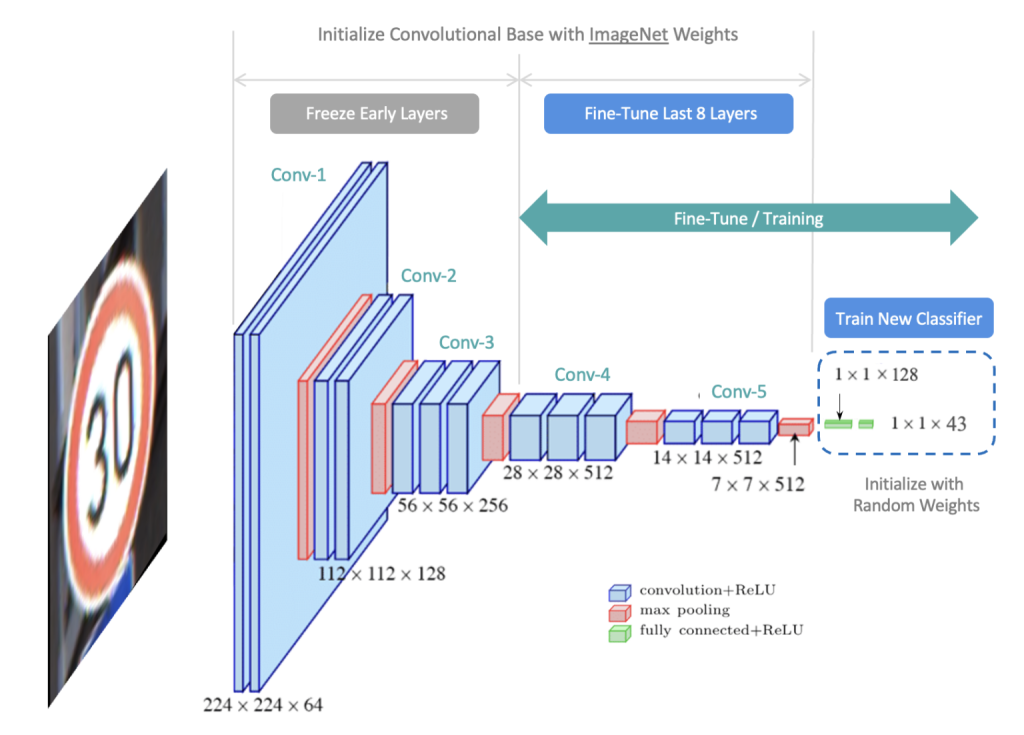
En esta técnica en la que se toma un modelo previamente entrenado en una tarea relacionada y se ajusta para que aprenda y desempeñe mejor la nueva tarea se conoce como fine-tuning.
Tu cara
Ahora vamos a ver cómo usar el colab notebook (si no te suena lo que son, en este artículo puedes introducirte a ellos) disponible aquí, para aplicarlo a nuestro caso particular. Nos ofrece una serie de pasos que debemos seguir:
Lo primero de todo, descargamos el archivo .ipynb del repositorio y lo cargamos en nuestro Drive para poder abrirlo como un cuaderno de Google Colab.
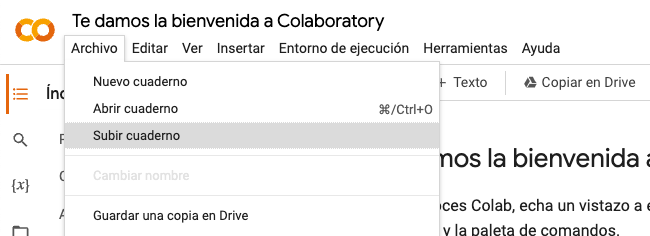
Ahí subiremos el archivo de tipo .ipynb y ya podremos editarlo.
Recomiendo instalar estas dependencias junto con la configuración de acceso a Drive:
!pip install wget --quiet
!pip install pyngrok --quiet
!pip install accelerate --quiet
!pip install TensorRT --quiet
!pip install gradio==3.23 --quiet
En la siguiente celda elegimos el modelo que queremos usar, en este caso usaremos V2.1-512px ya que nuestras imágenes las hemos ajustado a un tamaño de 512×512.
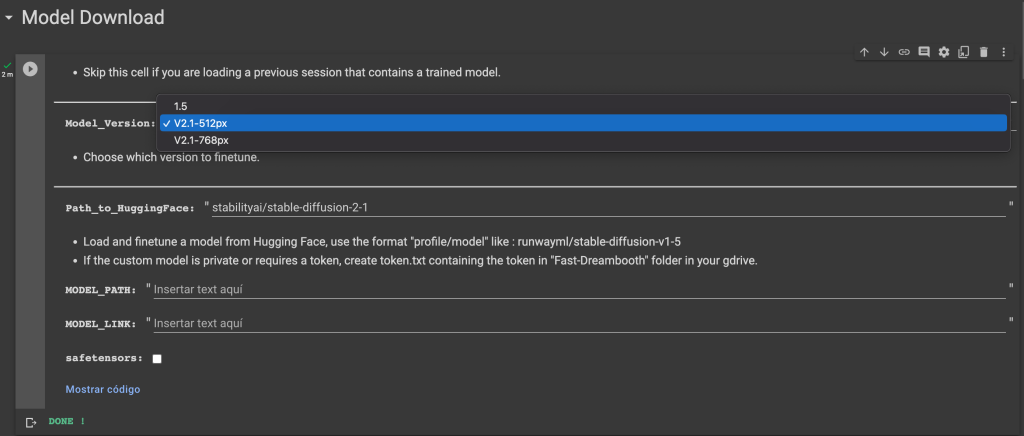
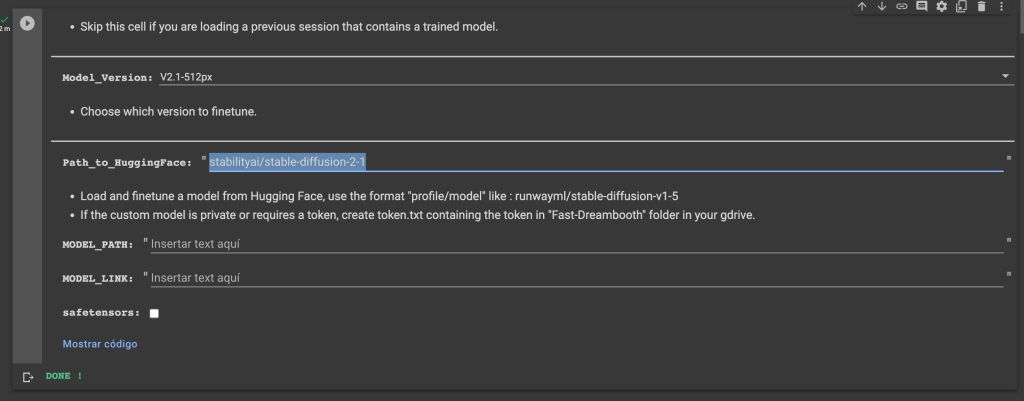
Antes de ejecutarlo debemos proporcionar el modelo base a refinar desde Hugging Face (si no conoces esta plataforma, aquí tienes un tutorial acerca de ello). Usaremos el que coincida con el que hemos seleccionado en Model_Version. En este caso stable-diffusion-2-1 de stability.ai, aquí puedes encontrarlo.
A continuación tenemos que decirle al modelo quién tiene que aprender, hay que definir el token, para luego poder pedir que genere una imagen de esa persona y que el modelo sepa quién es. Esto se define en Session_name donde ponemos el nombre/token que queramos. 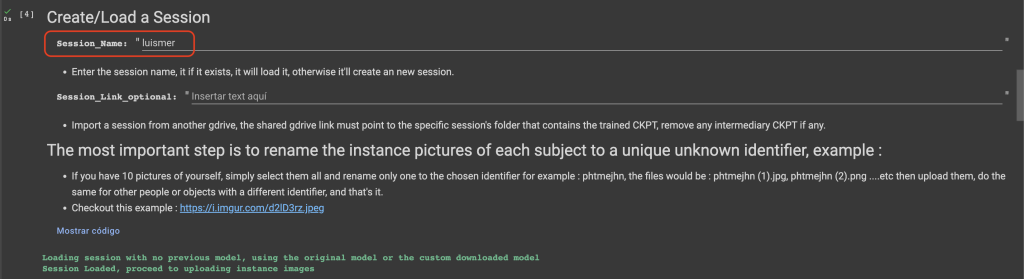
Una vez se ha ejecutado correctamente la celda, podemos pasar a cargar las imágenes con nuestra cara para que el modelo la aprenda:
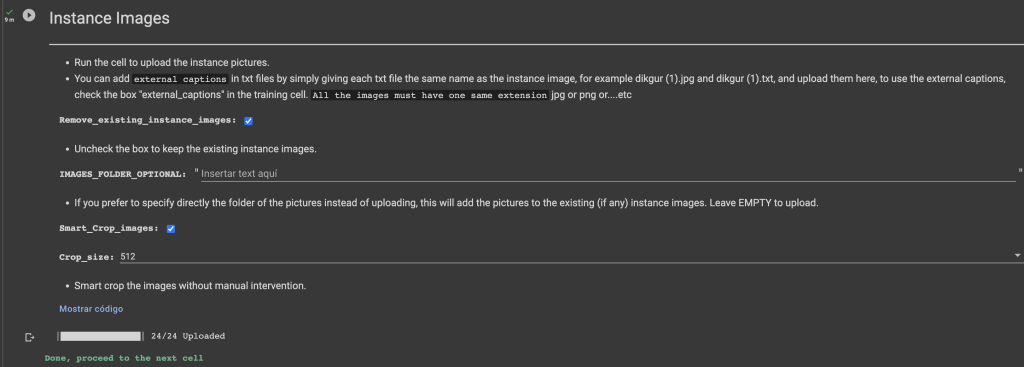
Ahora que tenemos todas las imágenes cargadas, procedemos a entrenar el modelo con estas nuevas imágenes, en este caso vamos a usar Dreambooth. Es método para personalizar modelos text-to-image como Stable Diffusion, dado solo unas pocas imágenes de un sujeto. Permite que el modelo genere imágenes contextualizadas del sujeto en diferentes escenas, poses y vistas. DreamBooth se utiliza para darle una nueva capa de entrenamiento o un añadido a esa IA para que pueda reconocer objetos concretos.
Para entrenar se dejan los parámetros por defecto y se ejecuta la celda:

Si todo va bien, nos aparecerá este grafismos indicando que se está entrenando el modelo:
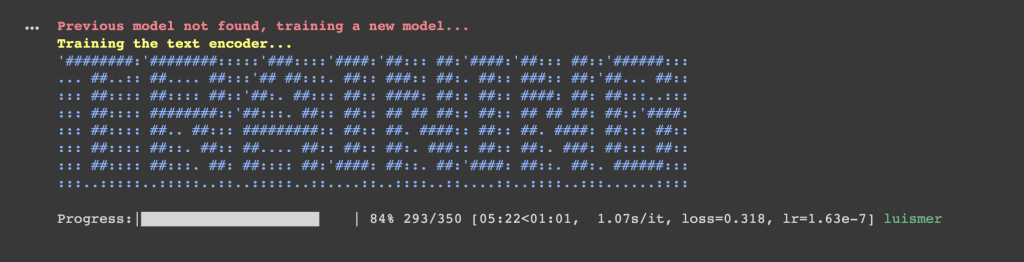
El entrenamiento irá avanzando según los parámetros que hayamos definido en la celda:
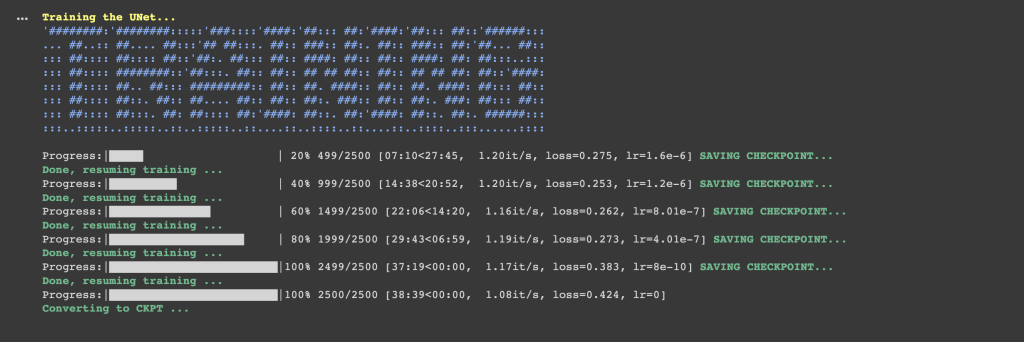
Si el entrenamiento ha finalizado con éxito, se guardará el archivo .ckpt en la sesión activa, esto es la ubicación en Drive del notebook que estamos usando, la ubicación habitual es dentro de /content/gdrive/MyDrive/Fast-Dreambooth/Sessions. El archivo .ckpt guarda los parámetros del modelo en un momento determinado para poder ser usado más tarde sin tener que entrenar el modelo cada vez que queremos usarlo.

Ha llegado el momento de probar el rendimiento del modelo, en la siguiente celda, se puede usar una interfaz gráfica basada en Gradio, para visualizar el modelo. Para ello ejecutamos la celda y nos pedirá la ubicación del archivo .ckpt:
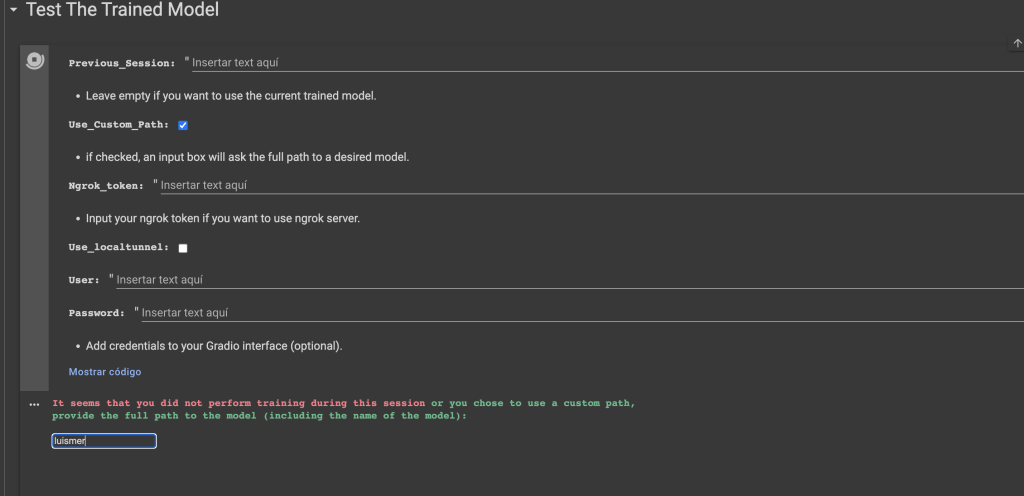
Cuando haya cargado el archivo, nos indicará que se ha podido conectar sin problema y nos dará una URL pública a través de la cual acceder a la interfaz gráfica de Gradio.
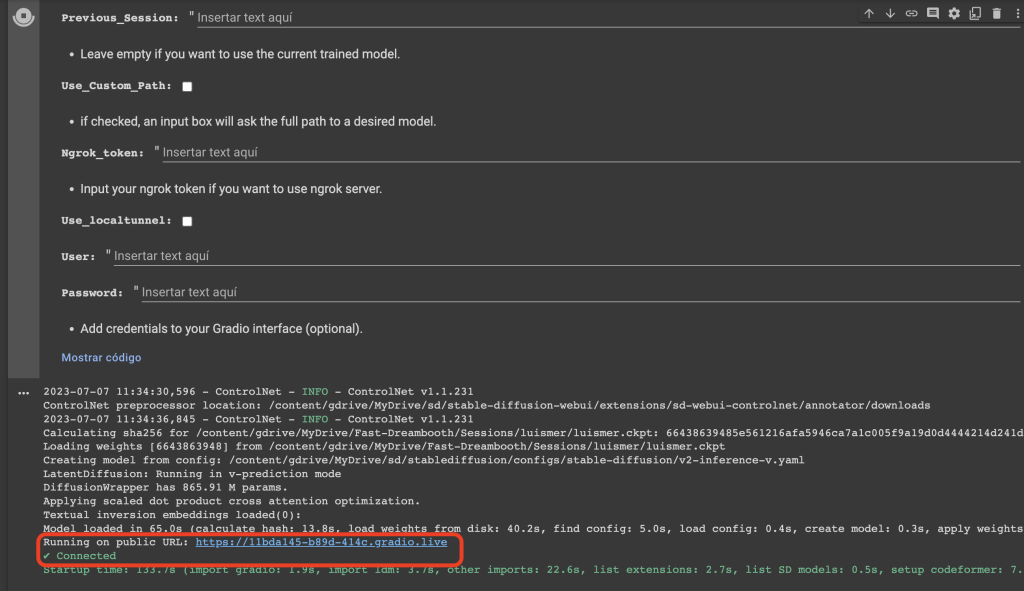
Al pulsar el enlace nos llevará a esta pantalla:
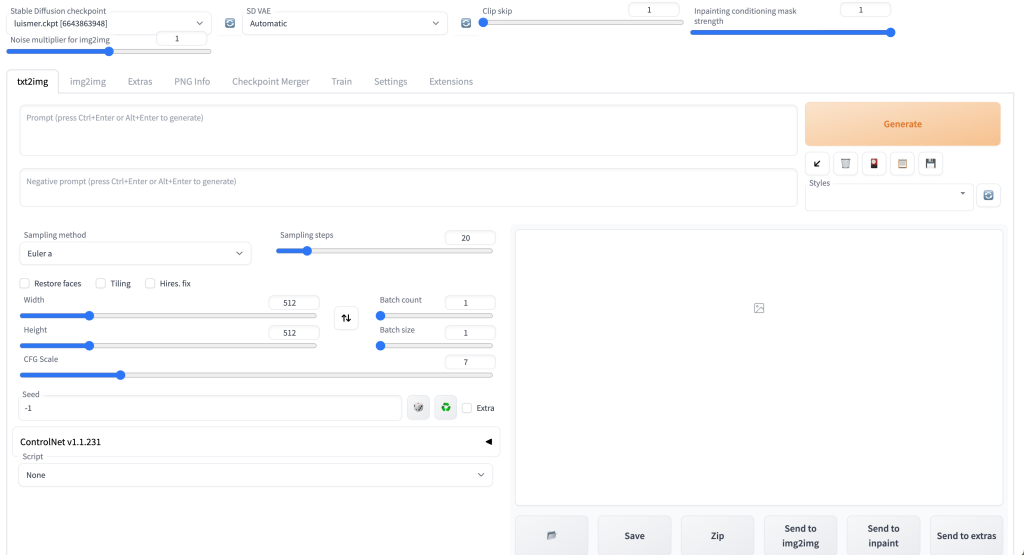
Resultados
Imagen original, del conjunto de 25 imágenes de entrenamiento:

Aquí se muestran algunas imágenes generadas con el modelo refinado:












En algunas ocasiones el modelo no genera la cara pero si el resto del cuerpo:














La calidad de las imágenes de entrenamiento es crucial para el rendimiento del modelo. por tanto, se podrá mejorar la calidad de las imágenes generadas a la par que se mejoran las imágenes de entrada. Una de las posibles mejoras es usar imágenes en las que se te vea mejor la cara, se te diferencia claramente del fondo, vistas con ropa distinta en cada foto. Todo con el objetivo de que el modelo aprenda lo mejor posible tu cara.
¡Te toca!
Ahora solo queda que des rienda suelta a tu imaginación! Y no olvides que la serie de tutoriales de IAs generativas continúa! No te lo pierda y súbete al tren de las IAs generativas con estas paradas:
- Tu cara donde te imagines: Fine-tuning de Stable Diffusion ¡Gratis! (I)
- Adobe Firefly: La nueva era de Adobe con IA (II)
- Kaiber: animaciones a golpe de prompt (III)
- Texto a vídeo con Gen-2 de Runway (IV)
Referencias
- https://www.youtube.com/watch?v=rgKBjRLvjLs&t=408s&ab_channel=DotCSV
- https://github.com/TheLastBen/fast-stable-diffusion
- https://twitter.com/DotCSV/status/1585318671408254977
- https://towardsdatascience.com/diffusion-models-made-easy-8414298ce4da
- https://learnopencv.com/fine-tuning-pre-trained-models-tensorflow-keras/
- https://www.tensorflow.org/guide/checkpoint?hl=es-419
- https://www.gradio.app/docs/interface


Pregunta: Cómo se instalan las dependencias ?
!pip install wget –quiet
!pip install pyngrok –quiet
!pip install accelerate –quiet
!pip install TensorRT –quiet
!pip install gradio==3.23 –quiet
Muchas gracias.
Muchas gracias