

Introducción
Hoy probamos el nuevo modelo de Runway, que se definen como una empresa de investigación aplicada a la IA dando forma a la próxima era del arte, el entretenimiento y la creatividad humana. Han desarrollado la nueva versión de su modelo generativo, Gen-1. En este tutorial veremos cómo usar Gen-2, cuya principal novedad que ofrece es la generación de vídeo a partir de únicamente texto, no es necesario ninguna imagen de entrada. Este es uno de los ejemplos que proveen:
Generated greenery. Made with the new Image to Video mode in Gen-2. pic.twitter.com/Souui3kk87
— Runway (@runwayml) July 26, 2023
Índice
¿Qué es?
Un sistema de inteligencia artificial multimodal desarrollado por Runway que puede generar vídeos a partir de texto, de otras imágenes o de otros videos.
Es una mejora de su anterior modelo Gen-1. Cuya característica principal era generar vídeos a partir de otros vídeos. Ambos se basan en lo que se conoce como modelos de difusión y en concreto en Latent Diffusion Models o Modelos de Difusión Latente, como ya comenté en el tutorial acerca de Stable Diffusion.
¿Cómo funciona?
Se basa en modelos de difusión latentes o Latent Diffusion Models.
Latent Diffusion Models
Los modelos de difusión ofrecen un objetivo de entrenamiento robusto y escalable y suelen requerir menos parámetros que sus homólogos basados en transformers para procesamiento de lenguaje natural. Han demostrado gran capacidad para la generación de imágenes, sin embargo todavía no ofrecen grandes resultados en cuanto a generación de vídeo. Aquí es donde entran los Latent Diffusion Models.
Representan una innovación el sentido de la cantidad de computación necesaria para generar imágenes. Utilizan redes neuronales preentrenadas en imágenes estáticas a las que agregan una dimensión temporal para generar videos. También aplican capas de alineación temporal para asegurar la coherencia temporal en los resultados.
Prrimero entrenan un modelo de compresión para convertir las imágenes de entrada en un espacio latente de menor dimensión donde se pueden reconstruir fielmente. Esto reduce la demanda computacional necesaria para generar contenidos de alta resolución y permite aprovechar grandes conjuntos de datos.
Un espacio latente es una representación simplificada de datos comprimidos en la que puntos de datos similares están más juntos en el espacio. Esto permite a los modelos generativos aprender las características importantes de los datos y sintetizar nuevos datos a partir de estas características.
¿Cómo usarlo?
Deberás acceder a la web de Runway y crear una cuenta, también disponen de aplicación móvil.
 Una vez hayamos creado la cuenta, debemos elegir un plan de pago o la versión gratuita. En el momento de escribir este tutorial, estos son los precios, pero puedes consultarlos aquí.
Una vez hayamos creado la cuenta, debemos elegir un plan de pago o la versión gratuita. En el momento de escribir este tutorial, estos son los precios, pero puedes consultarlos aquí.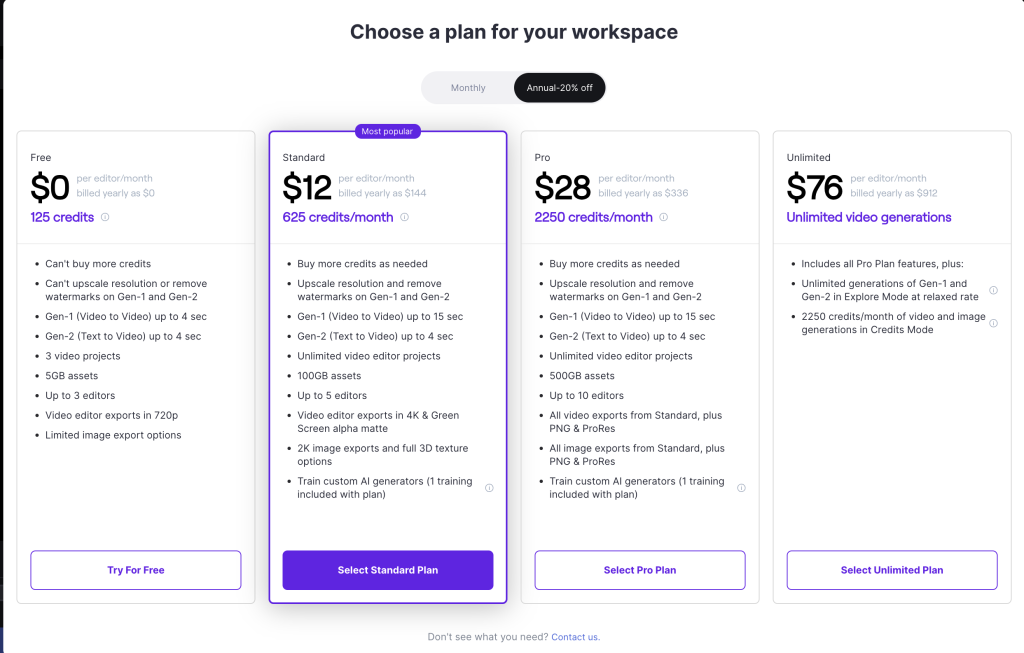
Ahora podrás acceder al panel de creación de activos multimedia:
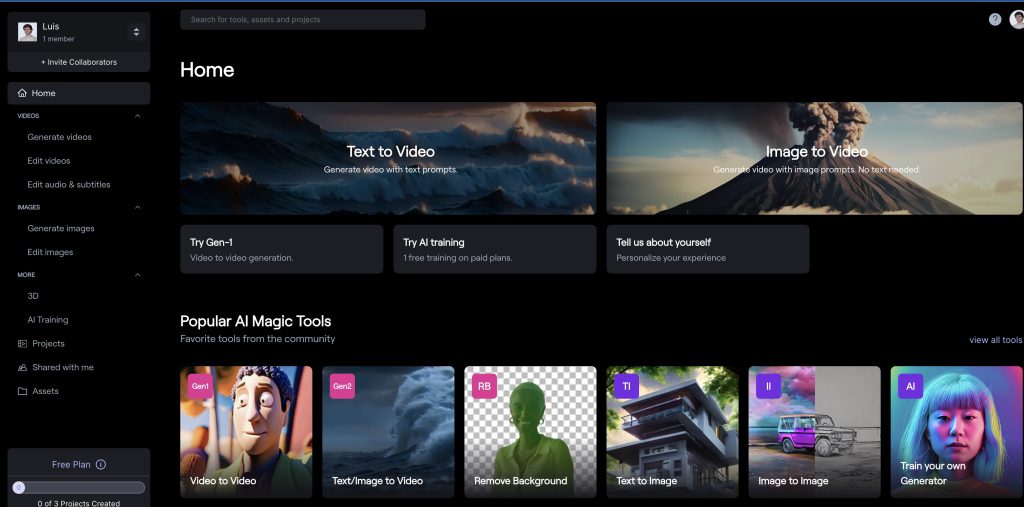
En este tutorial vamos a ver cómo utilizar las herramientas Text-to-video, image-to-video, text-to-3D-animations y cómo usar nuestra cara para que el modelo lo genere, a diferencia de lo que hicimos con Stable Diffusion, este modelo permite añadir tu cara al entrenamiento de forma mucho más sencilla. De ahí que este herramienta sea de pago.
Text-to-video
Como otras herramientas, simplemente con introducir la descripción del video que queremos, el prompt, nos permitirá ver una previsualización. Debido a que cada segundo de video generado corresponde a 5 créditos, podemos elegir entre 4 opciones previas gratuitamente.
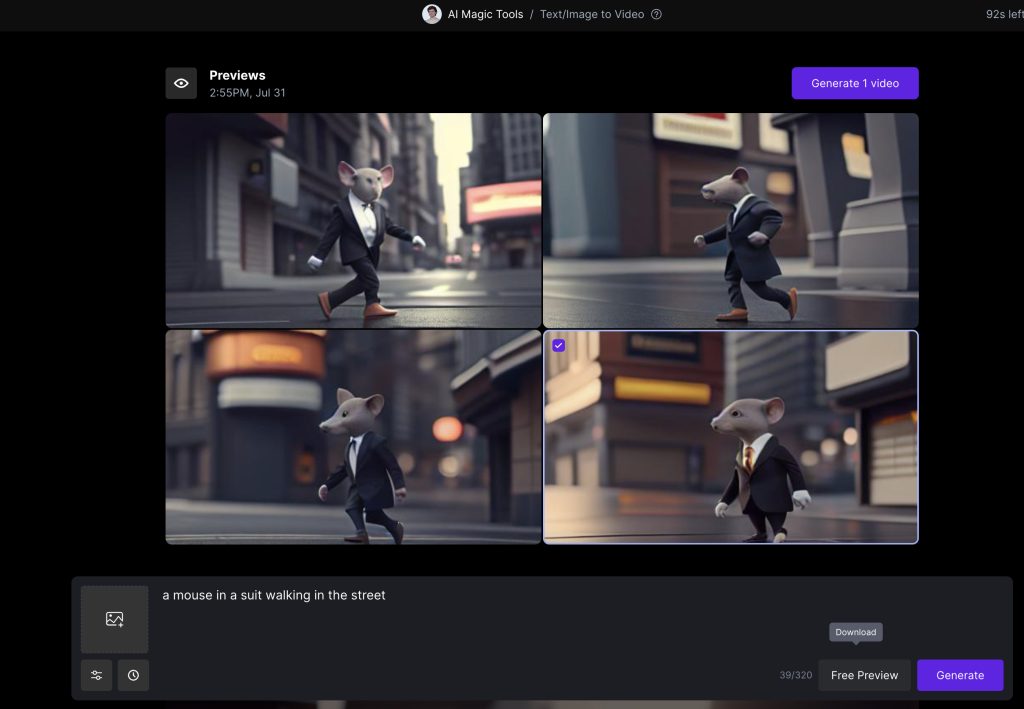
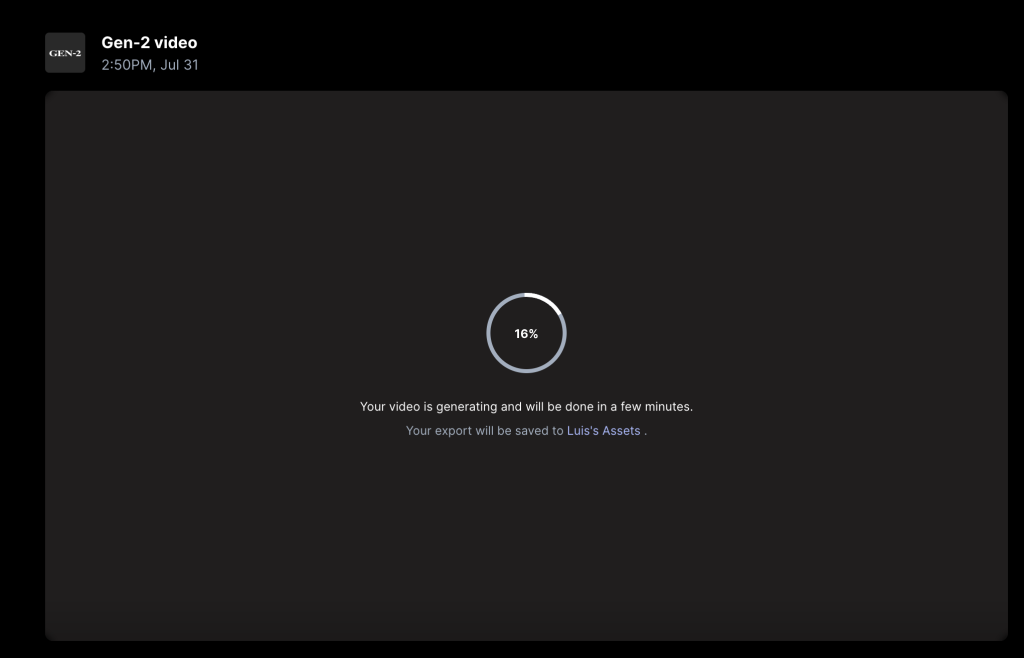
Y este es el resultado:
Image-to-video
En este caso, como en otra ocasiones, vamos a partir de una imagen para que el modelo genere el video como considere. He usado esta imagen, obtenida de la web FreeImages.

Primero debemos pinchar en la parte izquierda de la caja de texto del prompt para subir la imagen:
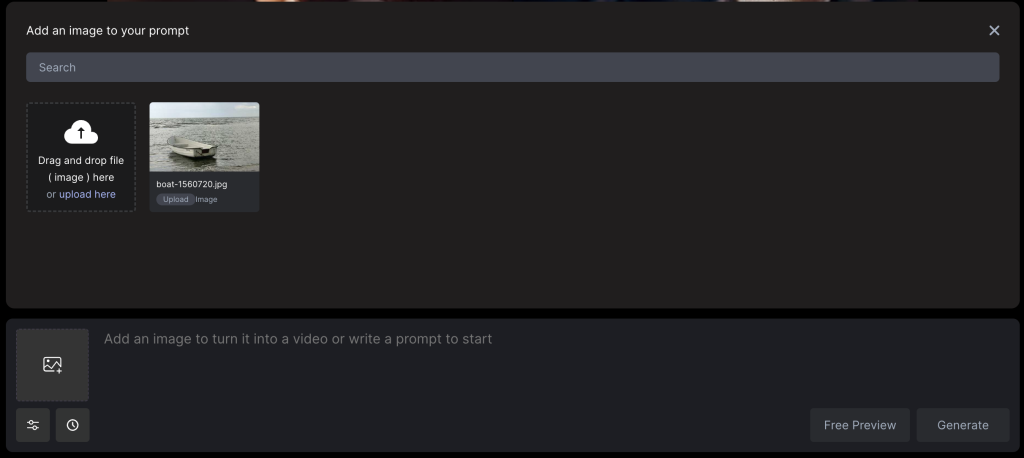
Una vez subida, se verá así y solo habrá que darle a generar:

Y este sería el resultado:
Vemos como respeta la imagen original así como las olas que genera el barco. Abajo a la derecha vemos que han introducido la marca de agua de Runway, puesto que estamos usando la versión gratuita.
Expand image
Ahora vamos a ver como usar la herramienta de expansión de imágenes de Runway gracias a Gen-2. Esta característica es muy parecida a la que ofrece Adobe Firefly, si no lo conoces, puedes saber más sobre ello en este tutorial.
Lo primero es entrar el dashboard, y buscar entre las AI Magic Tools la de expansión de imágenes (Expand Image):
Usamos la imagen que queramos, en este caso yo usaré el barco. Y como se puede ver, en la parte derecha, hay un panel de configuración. Podemos ajustar la expansión, la relación de aspecto, incluso añadir un prompt.
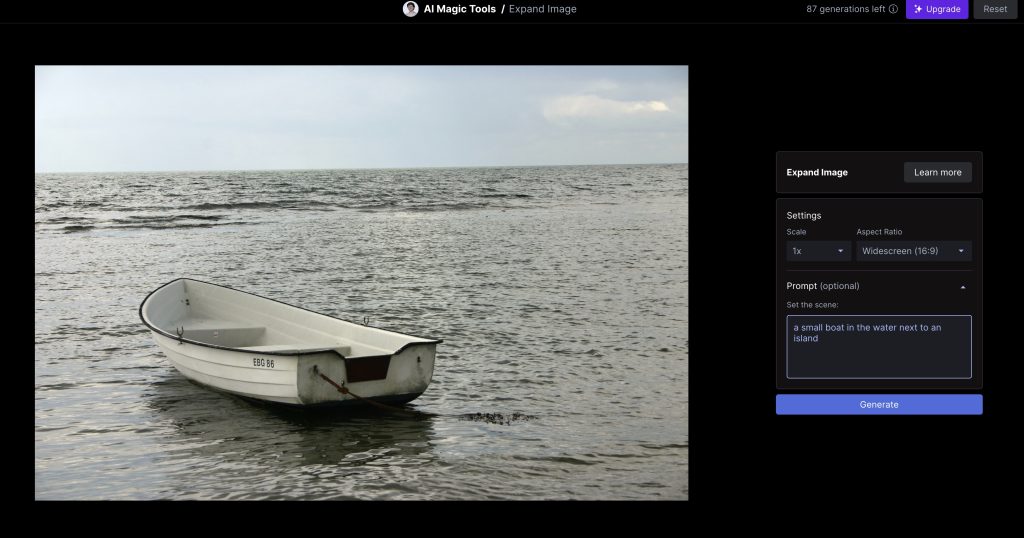
Esperamos a que se procese y se genere la expansión.
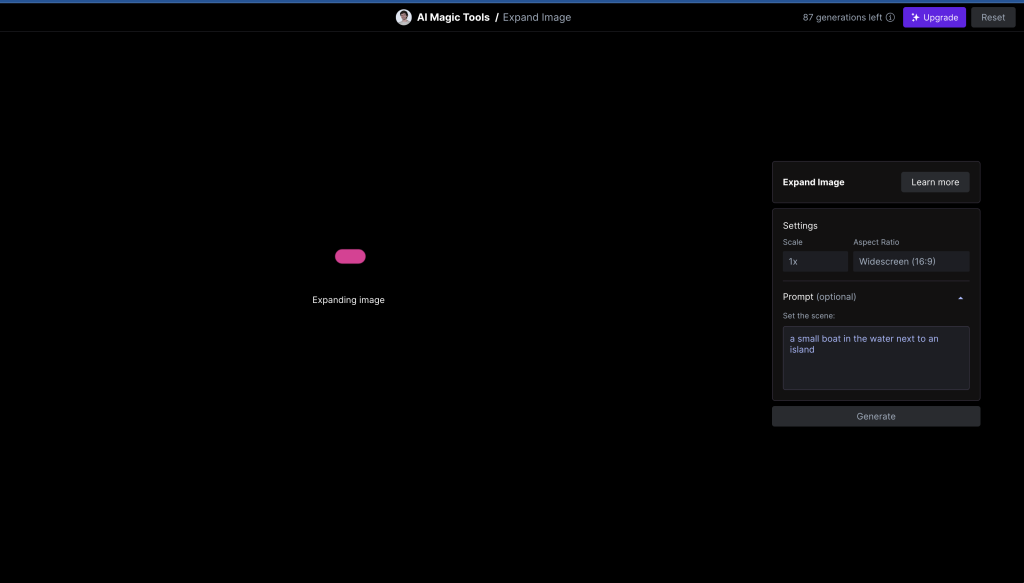
Y obtenemos este resultado, de ampliar el mar.

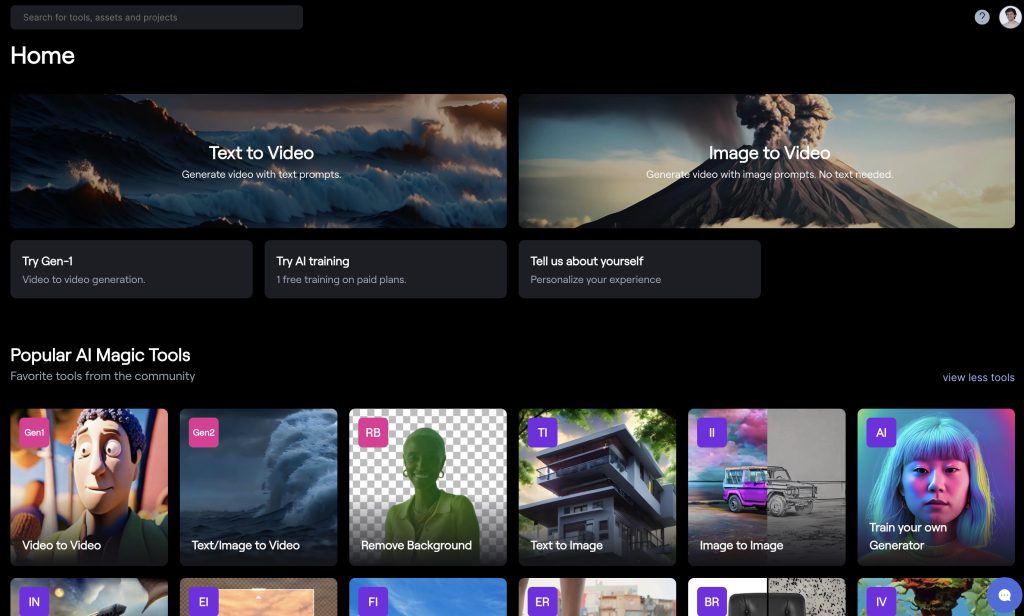
AI Generator
Esta herramienta que nos ofrece Runway, nos permite entrenar al modelo con las imágenes que queramos, en concreto con nuestra cara, el animal que queramos u otro objeto cualquiera. Para acceder a ella lo haremos desde el dashboard, como en ocasiones anteriores, en este caso lo vemos en la parte inferior derecha: «Train your own Generator».
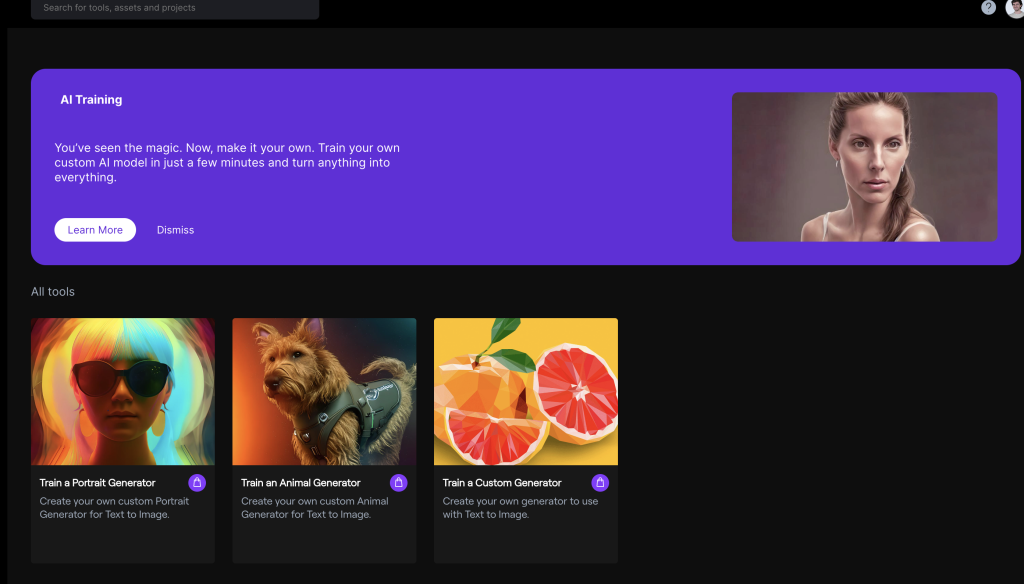
En la imagen de abajo vemos las posibles opciones para entrenar al modelo, como he mencionado antes, podemos generar imágenes de nuestra cara, de un animal o de cualquier otra cosa que nos imaginemos y que hayamos plasmado en un conjunto de fotos.
Cabe mencionar que esta opción solo está disponible con algún plan de pago activo. Revisa aquí la lista de planes que ofrece Runway para poder usar la herramienta, yo he usado el plan Standard que te permite un entrenamiento con AI Generator.
Seleccionamos la primera opción, «Train a Portrait Generator» y como en otras ocasiones, subimos las imágenes de nuestra cara correspondientes.
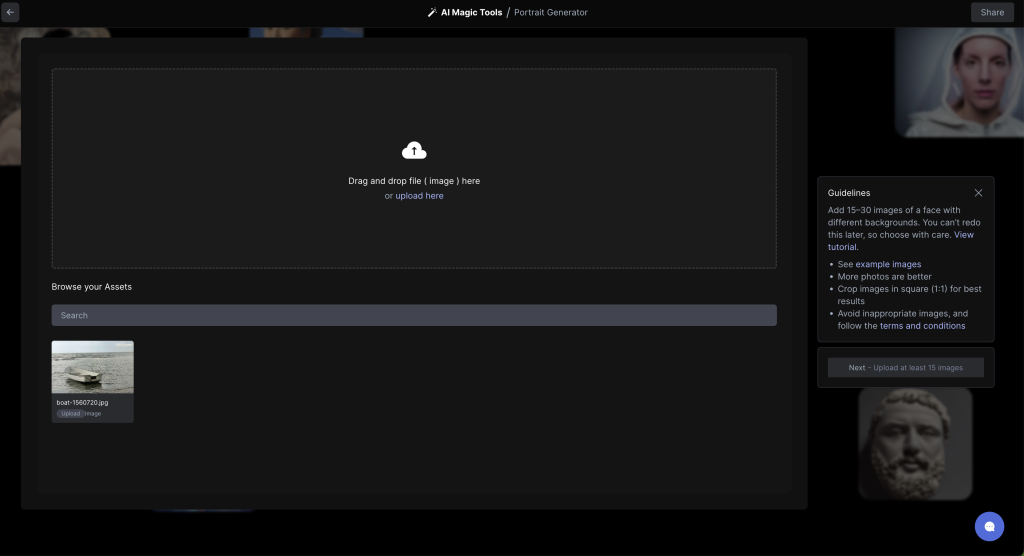
Es importante destacara que nos indican una serie de recomendaciones que debemos seguir con el objetivo de conseguir resultados más realistas y fieles a la realidad.
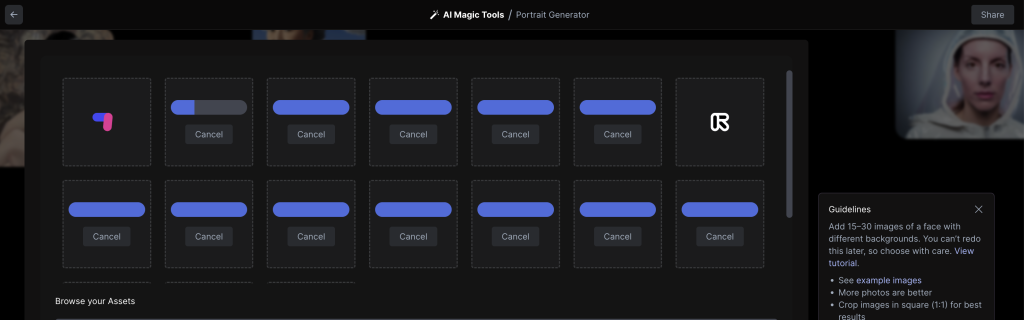
Esperamos a que se suban todas las imágenes, como indican, al menos 15 imágenes son necesarias.
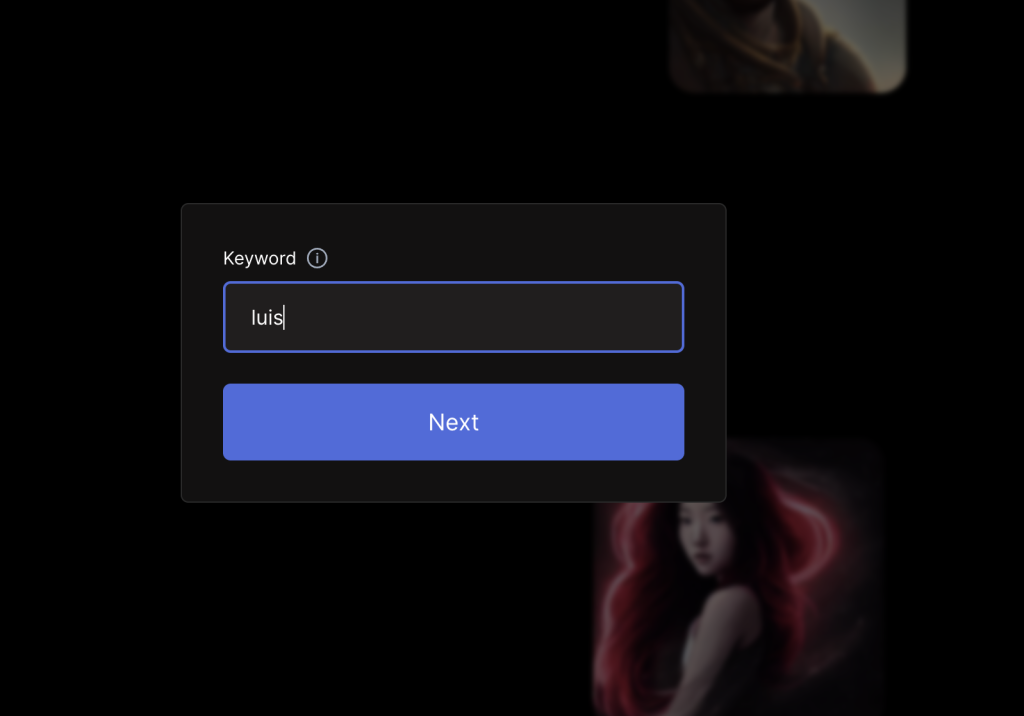
Una vez se han subido y pulsamos en el botón de Generate, debemos indicar al modelo quién somos, para que cuando queramos introducir un prompt con nuestro nombre el modelo sepa a qué nos estamos refiriendo
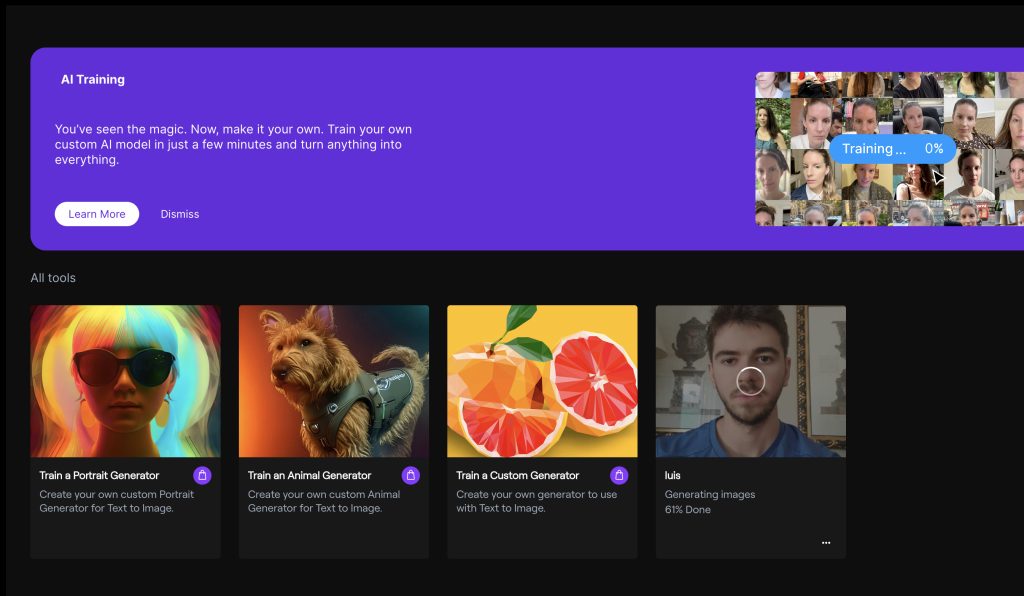
A partir de aquí, solo queda esperar a que se complete el entrenamiento. Podemos ver el progreso del mismo en el dashboard de AI Generator, como vemos en la parte inferior derecha, hasta ahora lleva un 61% completado:
Una vez completado nos llegará un correo electrónico o lo veremos en el dashboard. Este es el resultado, estas imágenes las ha generado el modelo sin indicarle ningún prompt:
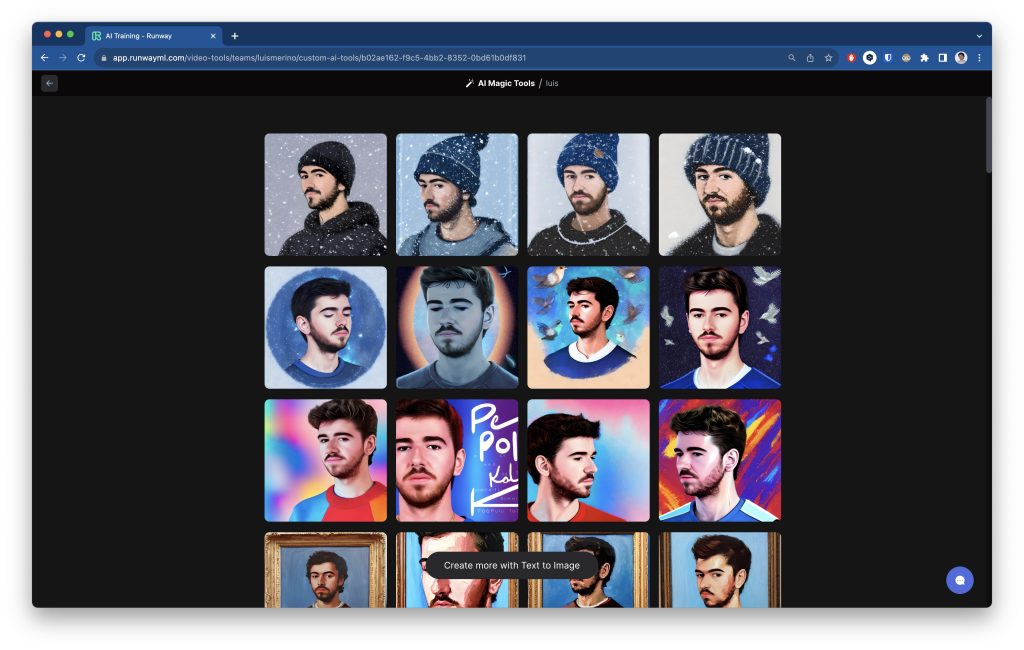
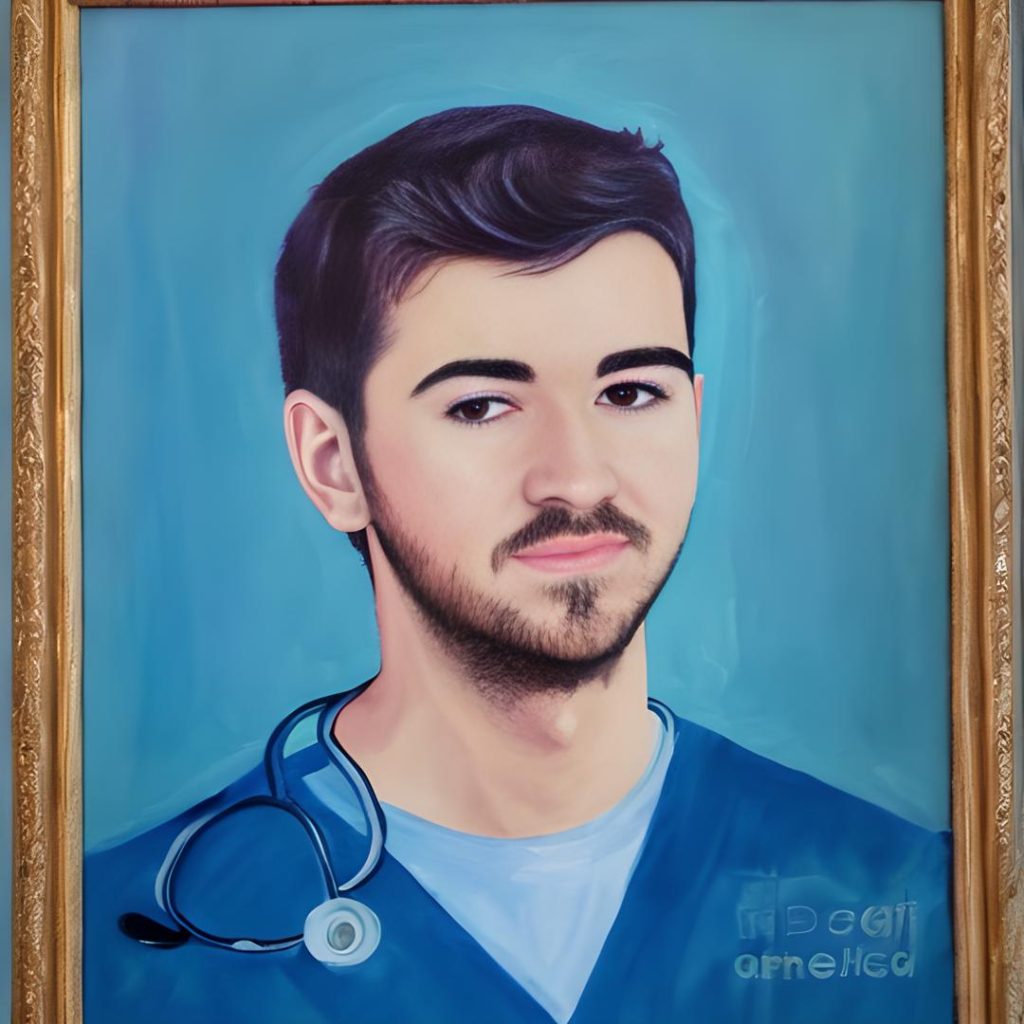





Pero sin duda, una vez el modelo ha aprendido mi cara, podemos pedirle nuevas imágenes con el prompt que queramos:
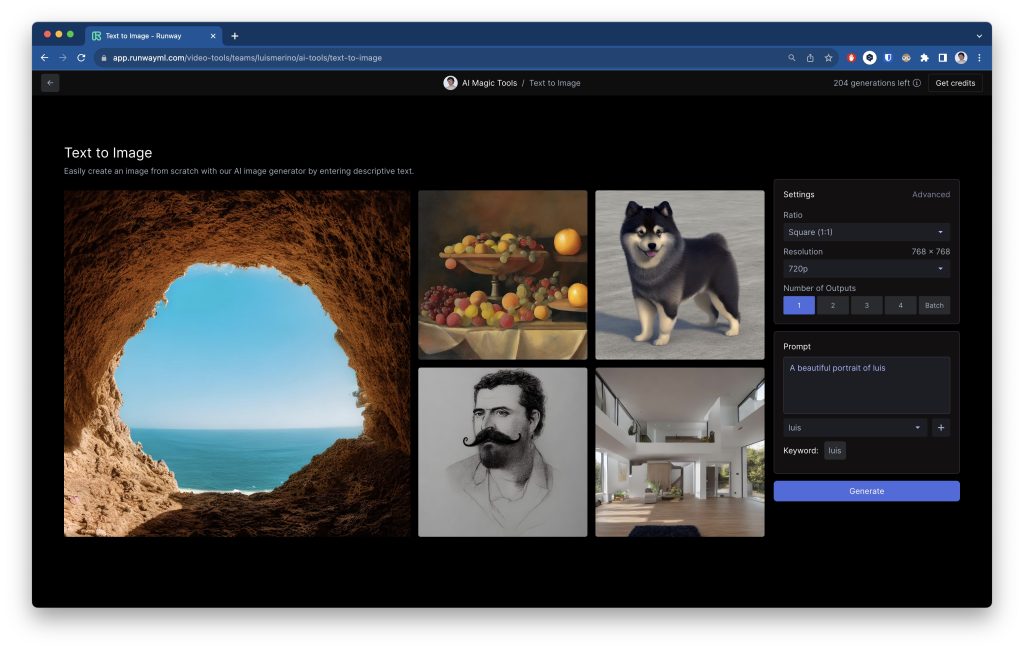
Vemos que a la derecha está el panel de configuración, donde la keyword abajo a la derecha, arriba del botón de Generate, es luis. Ahora el modelo sabrá quién soy y podrá generarme.
En este caso le he pedido una foto mía con bigote:

Flying free
Como pasa con todas estas herramientas generativas, el poder lo tienes tú. Solo tienes que imaginarlo y gracias a esta nuevas técnicas y tecnologías, podemos verlo hecho realidad. Hoy hemos visto cómo usar Gen-2 gracias a que Runway nos lo ofrece, pero como ya hemos visto en otras ediciones de tutoriales de IAs generativas, la dificultad no es técnica. La dificultad está en dejar volar tu imaginación y verlo en la realidad con tus propios ojos. Así que ya sabes fly free.
Bonus track
Ahora que tenemos imágenes generadas de mí mismo gracias a este modelo, vamos a usar su opción más novedosa para usar esas mismas imágenes y convertirlas a vídeo:
Otro ejemplo con mi versión astronauta en la que vemos cómo cobra vida:
Sin duda los resultados son muy buenos y llamativos. Te toca probar a ver qué te sale a ti! =D
Más tutoriales
El tren de las IAs generativas continúa después de haber parado en estas estaciones:
- Tu cara donde te imagines: Fine-tuning de Stable Diffusion ¡Gratis! (I)
- Adobe Firefly: La nueva era de Adobe con IA (II)
- Kaiber: animaciones a golpe de prompt (III)
- Texto a vídeo con Gen-2 de Runway (IV)
Referencias
- Structure and Content-Guided Video Synthesis with Diffusion Models
- Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
- https://research.runwayml.com/gen1
- https://help.runwayml.com/hc/en-us/articles/18760362014995-Gen-2-Prompting-Modes
- https://medium.com/@emreakcol/title-quick-guide-to-gen-2-exploring-the-early-beta-and-prompt-engineering-bb03e5192cba

