

0. Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Instalación para impacientes…
- 4. Nuestra primera task… chispas.
- 5. Feature flags.
- 6. Conclusiones.
1. Introducción.
En este tutorial vamos a ver cómo hacer nuestras primeras pruebas con Spring Cloud Data Flow (SCDF) en nuestra máquina local, sin entrar aún ni en el despliegue en la nube ni, como consecuencia, en el despliegue de contenedores. Veremos simplemente, cómo montar el servicio en local haciendo uso de un repositorio de Maven y desplegando batches como procesos locales.
Tampoco veremos la parte de streaming, eso lo dejaremos para futuros tutoriales; seguimos en la línea de tutoriales anteriores, donde la idea es hacer uso de la parte de procesamiento de datos masivos en batch. Podéis encontrar las referencias a los tutoriales previos a continuación:
- Ejecución de tareas efímeras en una arquitectura de microservicios en cloud.
- Spring Cloud Data Flow: introducción.
2. Entorno.
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 15′ (2.3 GHz Intel Core i9, 32GB DDR4).
- Sistema Operativo: Mac OS Mojave 10.14.6
- OpenJDK: 12.0.2
- Spring Cloud Data Flow 2.7.0
3. Instalación para impacientes…
Para los más impacientes, la forma más rápida de disponer de SCDF en tú máquina local y hacer las primeras pruebas es descargarse el bundle:
wget https://repo.spring.io/release/org/springframework/cloud/spring-cloud-dataflow-server/2.7.0/spring-cloud-dataflow-server-2.7.0.jar
Y, a continuación, ejecutarlo como un proceso java, sin más:
java -jar spring-cloud-dataflow-server-2.7.0.jar
Podréis comprobar en la salida por consola, el correcto arranque del servicio y acceder al dashboard web a través de la siguiente url Spring Cloud Data Flow Dashboard URL.
También en esa salida por consola podréis comprobar como en esta primera ejecución en local y por defecto:
- que no está preparado para k8s:
INFO 35580 --- [ main] o.s.c.d.a.l.ProfileApplicationListener : Setting property 'spring.cloud.kubernetes.enabled' to false.
- que haremos estas primeras pruebas con una base de datos H2, también local y en memoria, con lo que, cuando termine el proceso java perderemos todos los datos; recordar que esa base de datos sirve para el registro de las aplicaciones, tareas y el estado de la ejecución de las mismas:
INFO 35580 --- [ main] o.s.c.d.s.config.web.WebConfiguration : Starting H2 Server with URL: jdbc:h2:tcp://localhost:19092/mem:dataflow
- que está habilitado únicamente el despliegue local:
INFO 35580 --- [ main] .s.c.d.s.s.LauncherInitializationService : Added 'Local' platform account 'default' into Task Launcher repository.
Lo primero que veréis al acceder al dashboard es la sección de aplicaciones vacía, como se muestra a continuación:
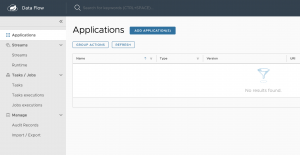
Vamos a probar a añadir alguna aplicación predefinida, seleccionando la siguiente opción, en la que se usa un repositorio de Maven público para realizar la descarga del artefacto a desplegar, en esta nuestra primera ejecución local.
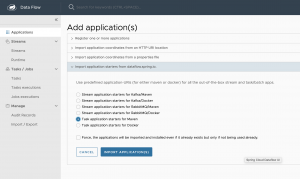
Una vez importados tendremos las siguientes aplicaciones disponibles.
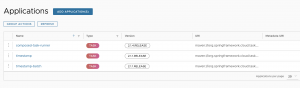
Haremos nuestra primera prueba con la app de Timestamp batch que está preparada para imprimir la fecha actual en el log, no hace más que eso en su ejecución, como un proceso batch.
Existe una tarea de timestamp que está pensada para su ejecución dentro de un flujo de streaming de datos, esta, por ahora, no la vamos a usar.
Podéis apreciar que se muestra asociado a la aplicación tanto el número de versión como la URI donde se encuentra el artefacto, que será usado por el módulo SPI de SCDF para ejecutar la tarea, en este caso en local.
4. Tu primera tarea… chispas.
Una vez tenemos nuestra primera aplicación, aunque insulsa, vamos a ver cómo configurar una tarea asociada a la misma.
Para ello, desde la sección de tareas, que estará vacía, pulsamos sobre «crear tarea».
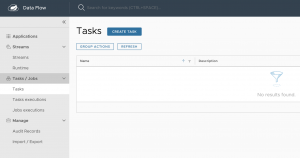
Se mostrará una interfaz como la siguiente en la que a la izquierda aparecerán todas las aplicaciones de distintos tipos que están previamente registradas.
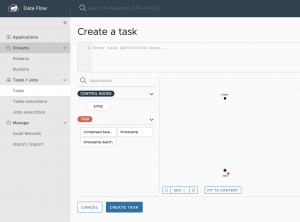
Para crear una tarea basada en una aplicación, no tenemos más que arrastrarla hacia el editor visual de la derecha y conectar el punto de inicio y fin del flujo. También podríamos escribir en la parte superior en un lenguaje DSL el flujo de ejecución de las tareas, pero para este primer uso, basta con dejarlo como en la imagen y pulsar sobre crear tarea.
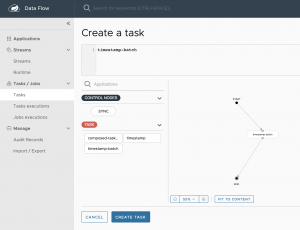
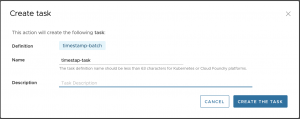
Se mostrará una ventana emergente como la siguiente, en la que podremos darle un nombre y una descripción a la tarea:
Tras pulsar sobre crear la tarea, podremos visualizarla en el listado, como sigue:

Las tareas no tienen versiones, son las aplicaciones en las que se basan las que se versionan.
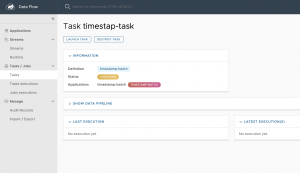
A continuación vamos a acceder al detalle de la tarea, desde el cuál podemos comprobar como se encuentra en estado «desconocido» puesto que aún no se ha ejecutado nunca, ese estado se mapea con el estado de la última ejecución de la tarea:
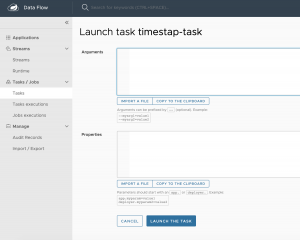
Desde esa misma pantalla de detalle de la tarea podemos pulsar sobre ejecutar tarea y acceder a una ventana como la siguiente, desde la cual podemos ejecutarla, redefiniendo:
- argumentos: esto es, parámetros que preparemos para su sobrescritura desde las ejecuciones, como nombres o prefijos de ficheros a leer, fechas de ejecuciones para buscar ficheros por patrones… cualquier parametrización de la tarea que sea susceptible o necesaria desde el punto de vista de operaciones.
- Properties: de la propia configuración de entorno de la task, propiedades de Spring Boot o de la propia Task de Spring Cloud.
En este primera ejecución podríamos configurar el patrón de la fecha que mostrará la task, que es lo que podría recibir la misma como podéis ver aquí: TimestampBatchTaskProperties.java.
Tras pulsar sobre «ejecutar la tarea» podréis ver en la consola de la ejecución del proceso del dataflow una salida como la siguiente:
INFO 35580 --- [nio-9393-exec-1] o.s.c.d.spi.local.LocalTaskLauncher : Preparing to run an application from org.springframework.cloud.task.app:timestamp-batch-task:jar:2.1.1.RELEASE. This may take some time if the artifact must be downloaded from a remote host. INFO 35580 --- [nio-9393-exec-1] o.s.c.d.spi.local.LocalTaskLauncher : Command to be executed: /Library/Java/JavaVirtualMachines/jdk-12.0.2.jdk/Contents/Home/bin/java -jar /Users/me/.m2/repository/org/springframework/cloud/task/app/timestamp-batch-task/2.1.1.RELEASE/timestamp-batch-task-2.1.1.RELEASE.jar --spring.cloud.task.executionid=1 INFO 35580 --- [nio-9393-exec-1] o.s.c.d.spi.local.LocalTaskLauncher : launching task timestap-task-870b8abe-124a-41c5-af3d-92a4083e20d5 Logs will be in /var/folders/ry/_wxnyd790y54698sywc8g_f00000gn/T/473279423941107/timestap-task-870b8abe-124a-41c5-af3d-92a4083e20d5
Y accediendo al directorio que se indica podemos encontrar un fichero stdout.log con la salida por consola del proceso de la propia task en el que podremos encontrar dos trazas en concreto con algo similar a lo siguiente:
INFO 35816 --- [ main] s.c.t.a.t.b.TimestampBatchTaskProperties : Job1 was run with date 2020-12-28 17:20:24.458 INFO 35816 --- [ main] s.c.t.a.t.b.TimestampBatchTaskProperties : Job2 was run with date 2020-12-28 17:20:24.489
Que es el resultado de la ejecución del código de la aplicación de la tarea que hemos lanzado, lo podéis consultar aquí:
TimestampBatchTaskConfiguration.java
No es más que una prueba dentro ahora de nuestro sandbox de una ejecución de una tarea que lanza dos jobs de prueba.
Una vez lanzados, ahora en el listado de tareas, aparecerá como completada.

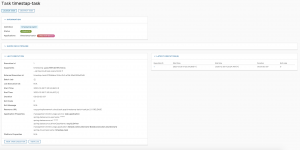
Accediendo de nuevo al detalle de la misma podemos ver los pormenores de la ejecución, con un listado a la derecha de todas las ejecuciones de la tarea:
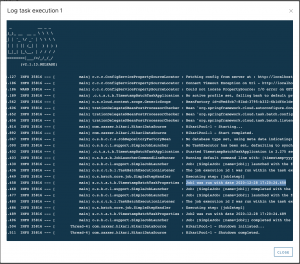
Información, abajo a la izquierda, de la última ejecución, desde la que podemos acceder incluso a los logs:
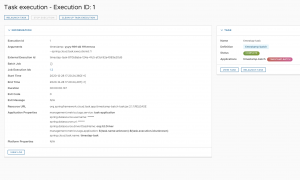
Podemos acceder en detalle a la ejecución de esa tarea número 1:
Y desde el detalle de la tarea al listado de los jobs que se han ejecutado dentro de la misma, también pulsando sobre el enlace de cada uno de ellos en la sección «Job Executions Ids».

Desde el detalle de los jobs, se puede acceder al detalle de los steps, en este caso, solo tiene uno:
![]()
Pero nos sirve para ver el nivel de detalle de la información que tenemos en la ejecución de cada step:
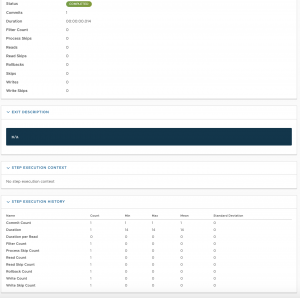
Recuerdo que el dataflow dispone de toda esta información porque las task comparten la base de datos del propio dataflow para ir alimentando dicha información y mantener el estado de su ejecución; se puede ver un poco más arriba como en las properties de la ejecución de las tareas, el dataflow le pasa la cadena de conexión, usuario y contraseña necesarios a las aplicaciones que ejecutan las tasks para poder acceder a dicha base de datos.
Por último, y ya saliendo a la sección de «Audit records», podemos ver cómo se quedan registradas todas las acciones que vamos lanzando desde el dashboard a modo de proceso de auditoría
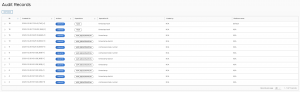
Teniendo la integración con Spring Security y autenticando a nuestros operadores en el acceso al SCDF en la columna «Created by» deberían aparecer las acciones nominativas.
5. Feature flags.
La propia arquitectura de SCDF está diseñada en base a componentes que podemos habilitar o deshabilitar, de tal modo que podemos arrancar el servidor con la parte de procesamiento de streamings deshabilitada, como sigue:
java -jar spring-cloud-dataflow-server-2.7.0.jar --spring.cloud.dataflow.features.streams-enabled=false
De este modo, no aparecerán visibles si quiera en la interfaz las opciones de streaming y no tendremos los posibles errores en la consola que habréis podido ver si habéis seguido el tutorial.
6. Conclusiones.
Sirva este tutorial para tener una primera toma de contacto, insisto que solo en la parte batch de Spring Cloud Data Flow.
Lo siguiente sería ver cómo usar SCDF dentro de un cluster de k8s, lejos de la «simplista» ejecución de tareas locales; pero la operativa de cómo trabajar de modo operador, con tareas manuales sería la misma independiente de la plataforma y del modo de despliegue de las tareas.
Recordad también que lo ideal es tener el pipeline de despliegue de las tareas batch integrado con el api de SCDF de modo que la promoción entre entornos y la configuración de versiones de las aplicaciones, tareas, ejecución y calendarización esté totalmente controlada e integrada en el pipeline de construcción.
Stay tuned!
Jose

