

0. Índice de contenidos.
- 1. Introducción.
- 2. Arquitectura.
- 3. Lenguaje de dominio.
- 4. Gestión y ejecución de tareas batch.
- 5. CI/CD.
- 6. Monitorización.
- 7. Conclusiones.
1. Introducción.
Spring Cloud Data Flow es una herramienta del ecosistema de Spring Cloud que nos permite el procesamiento de datos, bien en tiempo real a través de streaming o en batch a través de tareas programadas, gracias al despliegue de microservicios en una plataforma cloud, como puede ser kubernetes.
El objetivo es que los microservicios encargados del procesamiento de datos hagan una sola cosa y la hagan bien, dentro de una cadena de responsabilidades, formando parte de un pipeline. Así bien, haciendo uso de microservicios ya disponibles, out of the box o de desarrollos propios, podemos tratar información dentro de un flujo de integración en nuestro sistema o hacia sistemas de terceros. En la parte de analítica de datos en tiempo real lo podríamos comparar con Apache Airflow dentro del ecosistema de python.
Spring Cloud Data Flow es una aplicación desarrollada con Spring Boot bajo la arquitectura de Spring Cloud con la que podemos:
- Hacer un despliegue en local para probar la integración de los procesos batch bien como una aplicación normal o dockerizada, usando un repositorio de maven como fuente origen de los artefactos para los despliegues.
- Desplegarla en cloud bajo un cluster de kubernetes, como un servicio con Helm o como una aplicación más, que interactuará con api de kubernetes para gestionar el despliegue de tareas programadas como cron-jobs, usando un docker registry como fuente origen de las imágenes para desplegar los jobs como contenedores.
- Dispone de una cli o un dashboard web con lo que acceder a toda la funcionalidad que proporciona desde el punto de vista del gestor de tareas, de los desarrolladores o del equipo de planificación.
- Integrarla con un servidor de Oauth para gestionar la seguridad y el control de accesos, con un registro de quíen ejecutó qué y cuándo.
- Y, entre otras muchas más funcionalidades, también permite su integración con un pipeline de integración continua, de modo tal que gracias a su API REST podemos registrar aplicaciones y versiones de las mismas, dar de alta tareas y planificar su ejecución programada.
Con Spring Cloud Data Flow podemos hacer uso de la parte de procesamiento batch de manera independiente a la de streaming, de modo tal que no tenemos que montar todo lo necesario para streaming si solo vamos a explotar la parte de ejecución de tareas, como es el objetivo de este tutorial.
En la parte estríctamente de ejecución de procesos batch, Spring Cloud Data Flow es el sustituto del deprecado Spring Batch Admin, de hecho tiene como modelo de persistencia el mismo repositorio de Spring Batch al que han añadido la parte de persistencia de Spring Cloud Tasks.
Lo más interesante de la arquitectura de Spring Cloud Data Flow es que es cloud agnostic, a día de hoy proporciona un soporte oficial para Kubernetes y Cloud Foundry pero existen proyectos de la comunidad para otras plataformas como HashiCorp Nomad, Red Hat OpenShift y Apache Mesos.
Si en el anterior tutorial sobre ejecución de tareas efímeras en una arquitectura de microservicios en cloud planteamos la posibilidad de ejecutar tareas batch como microservicios, en este tutorial vamos a ver cómo Spring Cloud Data Flow puede ser una buena alternativa para gestionarlo.
2. Arquitectura.
Como comentaba Spring Cloud Data Flow tiene dos patas:
- Procesamiento en tiempo real de streaming de datos a través de Spring Cloud Stream, donde podemos realizar procesos de ETL en tiempo real basados en la ejecución de tareas dentro de un pipeline donde cada paso es una aplicación independiente dentro del cluster y la comunicación entre ellas se realiza a través de eventos.
- Procesado de información vía procesos batch, desarrollando bajo el paraguas de Spring Cloud Task y Spring Cloud Batch, como microservicios efímeros que tienen que devolver un resultado en su ejecución para su monitorización. Es el propio proceso batch, gracias a recibir en su ejecución la cadena de conexión con la base de datos, quién va dejando trazabilidad de su ejecución en el repositorio común tanto al proceso batch como al propio Spring Data Flow.
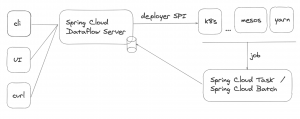
La arquitectura de Spring Cloud Data Flow proporciona de varios clientes (API, GUI y CLI),
se despliega como un microservicio más pero con privilegios para acceder al cluster del cloud correspondiente, de modo que puede ejecutar despliegues o planificar jobs. De ello se encarga el módulo de SPI (Service Provider Interface) que proporciona soporte estándar para k8s y Cloud Foundry, de fábrica, pero como comentábamos hay otras implementaciones de la comunidad.
En realidad Spring Cloud Data Flow, en la parte batch, no es más que un registro de tareas y su calendarización y un monitor de ejecución, quien ejecuta las tareas no es el Data Flow, este “habla” con el api de kubernetes para lanzar un job o dar de alta un cronjob, quien lo ejecuta es el cluster que lanzará un job y es el propio job, al lanzarse quién va persistiendo el estado de su ejecución en la propia base de datos del Data Flow, de modo que mantiene el estado de la ejecución a través de dicha base de datos: si el job no consigue lanzarse, no tendremos fechas de ejecución y si no consigue terminar, no tendremos registro de la fecha de finalización del mismo.
Basándose en la información que se registra en la base de datos, manteniéndose el estado de las ejecuciones, si se produce una segunda ejecución de un proceso batch porque la primera falló, es capaz de reengancharse en un puntero donde se quedó el proceso anteriormente.
La regla es que no puede ejecutarse un mismo proceso con los mismos parámetros de entrada, para evitar duplicidades en las ejecuciones; aunque para reenganchar un proceso batch tenemos que ser conscientes de tal posibilidad y dejar el proceso preparado para que los propios steps que se ejecutan dentro de un job sean reentrantes o no, dependiendo de la naturaleza del propio step.
3. Lenguaje de dominio.
En el siguiente esquema podemos ver el lenguaje de dominio del propio Data Flow, donde tenemos:
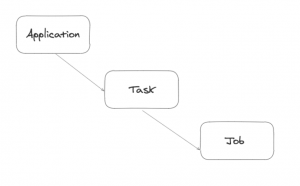
- Aplicaciones que se registran con un número de versión y permiten la gestión del versionado de las mismas, las aplicaciones apuntan a un artefacto que depende del
modo de despliegue del Data Flow puede ser incluso un jar aunque en un entorno cloud, lo normal será que referencien a una imagen de docker en un docker registry.
Estas aplicaciones son de distintas tipologías, para la ejecución de tareas batch son de tipo task aunque si son susceptibles de formar parte de un pipeline, pueden ser también de tipo source, processor y sink,
respondiendo a los pasos de un proceso de ETL, - esas aplicaciones se pueden añadir a tareas o ejecutarlas como tareas aisladas
- y las instancias de esas tareas lanzan jobs y los jobs a su vez se dividen en steps.
En el siguiente esquema podemos ver cómo está montado el lenguaje de dominio de las tareas batch que se ejecutan. Tienen un lanzador que ejecuta los jobs y estos tienen steps como antes dijimos, que van dejando información en la base de datos del Data Flow, común a todos los procesos batch a través de un JobsRepository, los que estéis familiarizados con Spring Data conoceréis la terminología.
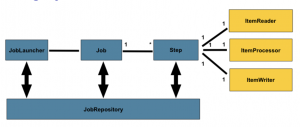
En ningún caso, desarrollando un proceso batch necesitaremos conocer internamente estos componentes; solo nos tenemos que preocupar de configurar los jobs y programar los steps que formen parte del proceso batch, en el caso de un proceso batch de ETL pues tendríamos un reader un processor y un writer; además, Spring Batch proporciona múltiples implementaciones para leer o escribir un fichero posicional, un csv, un xml…
y para acceder a servicios vía a api rest o web service, como estemos haciendo actualmente en los microservicios.
Resulta especialmente interesante la posibilidad de usar Spring Integration como flujo de entrada de mensajes hacia la ejecución de jobs, podemos configurar, por ejemplo,
un flujo de integración teniendo como fuente un directorio remoto de un sftp, de este modo, por cada fichero que encuentre en ese directorio recibiremos un mensaje en modo de fichero y podemos configurar el arranque de un job que tenga como parámetro de entrada dicho fichero. A un flujo de integración se le pueden configurar transformes, de modo que en un solo paso, podemos descomprimir, desencriptar, transformar el mensaje, el fichero, al formato de entrada esperado en el job.
4. Gestión y ejecución de tareas batch.
A continuación, podemos ver una captura de la vista del registro de aplicaciones dentro del Data Flow y estas son todas las que provee de fábrica para construir pipelines de procesamiento de datos en tiempo real. En nuestro caso ,aquí será donde podremos registrar nuestras aplicaciones por entorno o donde aparecerán registradas automáticamente si lo integramos en nuestro ciclo de construcción, como veremos más adelante.
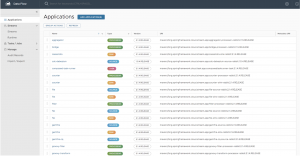
Ves que aparecen catalogadas como source, processor y sink, estas serían las tareas de un pipeline de streaming. Y luego, tenemos unas Task que son las que nos interesarían ahora a nosotros.
A continuación un detalle de las aplicaciones de tipo task.
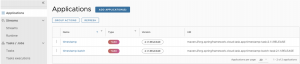
Y aquí podemos ver cómo crear una nueva task simple en base a una aplicación de tipo task. Solo tiene un nodo de inicio y un nodo fin.
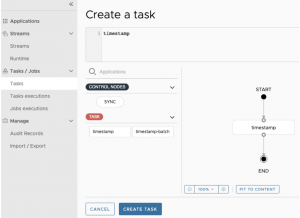
Una vez tenemos generada la task podemos lanzarla y para ello, tenemos la posibilidad de pasarle argumentos a la ejecución del propio job o redefinir properties que tengamos prevista su posibilidad de sobrescritura por entorno.
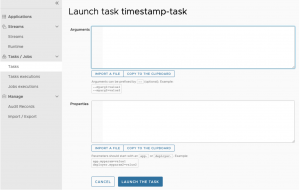
Una vez lanzada la tarea tenemos acceso tanto a la monitorización de la ejecución de la misma, como de los posibles jobs que se originen dentro de una task, lo normal quizás es que la relación sea de 1 a 1, pero en ejemplos como el que os comentaba donde usamos un flujo de Spring Integration para conectarnos con un directorio remoto vía sftp y por cada fichero que descarguemos se ejecute un job independiente, tendremos una relación de 1 a N.

Junto al acceso a la monitorización de los jobs que se han ejecutado podemos acceder también al detalle de ejecución de los steps de un job, pudiendo conocer así el tiempo de ejecución de los mismos y el número de registros, de modo que queda constancia desde un punto de vista de auditoría también, de si tenemos un proceso batch con un proveedor, cuántos registros se han tratado en un día en concreto para la transmisión de una información concreta.
Si el step falla aparecería en pantalla un extracto de la pila de la excepción del proceso ahí directamente y con ello, el equipo de operaciones puede tomar decisiones, junto con la documentación asociada al proceso batch, como relanzar el proceso o no.
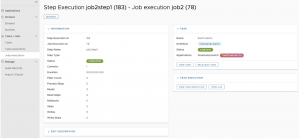
Desde mi punto de vista, en una arquitectura de microservicios una herramienta así es la que necesita nuestro departamento de operaciones, para que, cuando por lo que sea falla el batch de envío de información al proveedor que sea un viernes a las 11 de la noche, alguien pueda monitorizar qué ha fallado y pueda pasar información incluso al equipo de desarrollo del error.
Por último, podemos registrar una calendarización de la tarea asociando una «cron expression» a través de la siguiente interfaz. Esa programación se queda almacenada en la base de datos del Data Flow que, a través del módulo SPI correspondiente a nuestro cloud, también creará el cronjob correspondiente, hablando en términos de k8s.
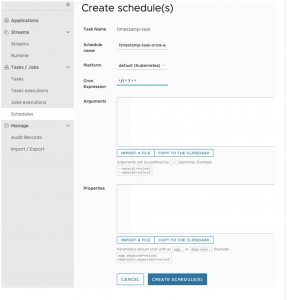
Luego de registrada, además de «constar» en el Data Flow, podremos comprobar que efectivamente se ha registrado accediendo con el cliente de nuestro cluster para comprobarlo, así en k8s:
kubectl get cj
5. CI/CD.
No podemos plantear el uso de una herramienta como Spring Cloud Data Flow, que nos va a servir de gestor de tareas batch y monitorización de operaciones en un ámbito transaccional, sin pensar en cómo van a integrarse los pipelines de construcción de nuestros procesos batch dentro del proceso de promoción entre entornos de los artefactos.
En una instalación local o de andar por casa, o incluso en entornos previos, podemos dar de alta manualmente, las versiones de las aplicaciones, sus tareas asociadas y lanzar tanto las tareas a mano como calendarizarlas, bien desde la GUI o haciendo uso de la CLI.
Pero, como decimos, lo ideal es tener integrados todos esos pasos dentro del pipeline de construcción con un esquema como el siguiente:
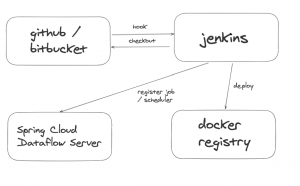
Nuestro servidor de integración continua recoge el código del repo y genera una build que construye un artefacto, igual que los microservicios, una imagen de docker del proceso batch que se sube al docker registry y es el propio servidor de integración continua el que registra la nueva versión de la aplicación, la task y, en su caso, la planificación también
automática de cuándo tiene que lanzarse el job, conforme a una expresión del cron; y todo ello se puede hacer haciendo uso del API del Data Flow debidamente securizada.
En el caso de registrar el scheduler automáticamente, es el Data Flow el que habla con el api de k8s para dar de alta el cronjob correspondiente a la image de docker del proceso batch.
De este modo, por cada build, tendríamos registrada la versión correspondiente en el Data Flow del entorno de integración para su ejecución en las pruebas de UAT o incluso directamente, su calendarización. Y para entornos productivos estará integrado con la promoción entre entornos de los mismos artefactos contra la instancia del Data Flow de los correspondientes entornos.
6. Monitorización.
Así como los microservicios los podemos monitorizar de forma activa con Prometheus siendo procesos de larga duración, los procesos batch al tener una duración indeterminada, al ser procesos efímeros, Spring Cloud Task tiene una integración con una pieza intermedia, que es el push gateway que hace de proxy para Prometheus de modo tal, que es el push gateway quien está atendiendo a las peticiones de Prometheus y los los procesos batch quien envían las métricas al gateway.
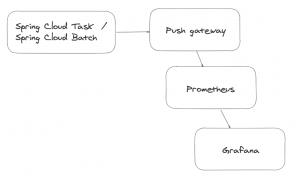
De este modo, podemos seguir usando las mismas herramientas de monitorización que usamos habitualmente para los microservicios y tener alertas y monitorización basándonos por ejemplo en Grafana.
Si las métricas y las trazas las empujásemos a sistemas como un BELK, lo haríamos de la misma forma que lo estemos haciendo actualmente en los microservicios.
7. Conclusiones.
En este tutorial no hemos visto más que una introducción a la parte de gestión y ejecución de tareas batch como microservicios en cloud con el soporte de Spring Cloud Data Flow.
En próximos tutoriales, veremos ejemplos más prácticos de cómo instalar la herramienta y hacer uso de la misma con un despliegue de las tareas tanto en modo local, como en un cluster de k8s.
Mientras tanto podéis ver la charla en la que introduje a la ejecución de tareas efímeras en un entorno de microservicios en cloud y a Spring Cloud Data Flow como solución técnica.
Stay tuned!
Jose

