

0. Índice de contenidos.
- 1. Introducción.
- 2. Despliegue en cloud.
- 3. Bajo una arquitectura de microservicios.
- 4. Tareas efímeras.
- 5. De la ejecución de tareas batch….
- 6. … a la ejecución de tareas efímeras como microservicios
- 7. Conclusiones.
1. Introducción.
Cuando historificamos un proceso, dentro del análisis del ámbito de un proyecto, no podemos olvidarnos de que hay ciertas funcionalidades que no responden necesariamente
a las acciones de un usuario con el sistema, son tareas que tienen como sujeto al propio sistema.
Así podemos hablar de historias de usuario del tipo «Yo como sistema… » o «Yo como miembro del departamento… «, son tareas que no tienen que ver específicamente con la interacción de un usuario final con el sistema o más bien, que se producen con cierta periodicidad y que vienen desencadenadas por la calendarización de las mismas.
En este tutorial vamos a ver qué estrategia podemos seguir para desarrollarlas y ejecutarlas cuando hemos elegido una arquitectura de microservicios desplegados
además sobre una infraestructura en cloud.
Para ello iremos de delante a atrás en la definición y veremos:
- primero el concepto de cloud,
- después un breve repaso sobre una arquitectura de microservicios,
- para terminar viendo a qué nos referimos con tareas asíncronas y cómo desarrollarlas y ejecutarlas en este entorno.
2. Despliegue en cloud.
¿Qué es eso de tareas efímeras en cloud? Si desplegando en cloud, per se, ya nos encontramos en un entorno de despliegue efímero, de hecho esa es la gracia,
poder desplegar según las necesidades del servicio, un número de instancias tal de los mismos que den soporte a la demanda creciente, sin disponer del hierro necesario para ello en tu casa.
El término en cloud hace referencia precisamente a eso, cloud es todo aquello que no tenemos en casa; aquello que está en «la nube». El termino en la nube viene de los diagramas de sistema en los que precisamente se representaba todo «lo de fuera» como una nube.
Entonces ahora se dice que desplegamos nuestros sistemas de información en la nube, que en realidad es en las máquinas de otros, esto es, están distribuidas entre los datacenters
de nuestros proveedores de servicios cloud: Amazon, Microsoft, IBM; y lo interesante además es que pueden estar desplegadas por regiones alrededor del mundo,
de modo tal que demos servicio a nuestros clientes como si fuesen servicios locales de la región desde la que se conectan.
Esto añade también alta disponibilidad pudiendo ser tolerantes a caídas o degradación del servicio de una región.
Todo el negocio de la nube nace del tiempo ocioso de los datacenters de los grandes como Amazon, que siendo muy simplistas, empezó a alquilar las máquinas que les sobraba cuando no tenía que asumir en pico de consumo de servicios como el del Black Friday o las campañas de navidad. «Tengo máquinas ahí paradas pues las alquilo como servicios», y de ahí surge un nuevo modelo de negocio.
Esto junto con la creciente disponibilidad de servicios de virtualización y el uso de servicios de virtualización ligeros como sistemas de contenedores y orquestación de contenedores,
ha producido que el despliegue en cloud sea una alternativa muy factible sobre todo para pequeñas o medianas empresas y startups, para las que montar sus sistemas en cloud les hace:
- no tener que hacer una inversión física, en hierro, montando un datacenter local
- o tener la relación de dependencia con un departamento de infraestructura tradicional, ni depender de tediosos procesos del departamento de compras.
Todo ello ha terminado provocando que ahora nuestros artefactos de despliegue, el producto resultado de nuestro desarrollo, aquello que empaquetamos ya no sea un war o un jar a desplegar en un servidor de aplicaciones, hablando en términos de java. Sino una imagen de docker basada en una imagen base, que contendrá una aplicación autoejecutable.
En todo esto hay muchos matices y niveles de servicio en la nube (SaaS, PaaS, IaaS…) y muchos tipos de clouds (públicas, privadas, híbridas) y servicios de la propia nube que nos
pueden hacer estar más acoplado o menos con nuestro proveedor de cloud. Imaginad un par de servicios de AWS como pueden ser Cognito o un bucket de S3, si por lo que fuese tuviésemos la necesidad de desplegar nuestros sistemas de información en Azure tendríamos que ver cómo de compatible son nuestras piezas de autenticación o almacenamiento con los servicios correspondientes de Active Directory o Blob Storage de Azure. Imaginad también que tenemos la necesidad de ser multi-cloud y toda nuestra infraestructura como código preparada para desplegarse pero estamos acoplados con ciertos servicios de nuestro proveedor de cloud.
El mensaje aquí podría ser:
- efectivamente y si, desplegando en cloud ya estamos en un entorno efímero.
- El cloud es un nuevo paradigma que vino para quedarse, donde también se requiere de perfiles especializados en ese «nuevo» modo de despliegue,
- y cuidado con el uso de los servicios del cloud, para no acoplarnos en demasía con el proveedor.
3. Bajo una arquitectura de microservicios
Llevamos ya también unos años hablando de construir nuestras aplicaciones, nuestros sistemas de información, en base a pequeñas piezas de código, con menores dependencias,
que nos permitan ser más ágiles a la hora de reaccionar frente a cambios. El objetivo de los microservicios es tener mayor independencia a nivel de equipo de desarrollo
para dar un tiempo de respuesta más corto frente a las nuevas necesidades de negocio. En vez de entregar un gran paquete de software, para promocionar entre entornos,
debe contener toda la funcionalidad en bloque, con todo lo que ello implica a nivel de sincronización de distintos equipos de desarrollo. Se trata de entregar pequeñas piezas
que se comuniquen entre sí, pero sean independientes en el despliegue.
La idea principal de los microservicios es que deben responder a necesidades de negocio y ser verticales de dominio; deben responder al end2end de una necesidad de negocio y
ser independientes en el despliegue, de modo que, frente a una nueva regla de negocio se pueda desplegar en producción de manera independiente.
Para ello deben responder al principio de responsabilidad única, deben implementar una única cosa y hacerlo bien; solo deben cambiar por un único motivo.
Enganchando con la parte de cloud, el objetivo también es que si esa funcionalidad de negocio requiere de un tráfico más intenso y tiene que dar soporte a un número elevado de peticiones, esa parte pueda escalar de manera independiente al resto. Imaginad el servicio de posición global de una app bancaria frente al servicio de transferencias o la consulta de disponibilidad de vuelos en comparación al servicio de booking, está claro cuál de los dos necesitará escalar más.
Todo tiene sus pros y sus contras y no es que yo sea un talibán de las arquitecturas orientadas a microservicios ni tampoco piense que nunca están justificadas, es cierto que donde en una arquitectura tradicional tienes un único artefacto los costes operacionales son mucho menores que en un entorno de microservicios y lidiar con conceptos como los de consistencia eventual, trazabilidad y transaccionalidad distribuida, no es sencillo.
Todo depende de nuestro problema de negocio, de las características del proyecto y del cliente; por ejemplo validar un modelo de negocio o arrancar una startup desde el principio
incrementando los costes operacionales de base, con una arquitectura orientada a microservicios, pues quizás no es la mejor idea, quizás podemos empezar con un único artefacto bien modularizado aplicando los principios de alta cohesión y bajo acoplamiento y cuando esté implementado, después de un MVP, ahí podamos partir convenientemente el monolito.
Volviendo sobre la idea de que una arquitectura de microservicios se basa en tener verticales de negocio independientes también es cierto que eso muy pocas veces se consigue de verdad porque lo normal es encontrarte lo que llamamos monolitos distribuidos. Si todas las líneas de dependencias que trazamos entre nuestros microservicios son llamadas síncronas entre dominios, al final tenemos las mismas dependencias que podríamos tener en una aplicación cualquiera donde hay llamadas locales pero convertidas en llamadas síncronas por la red, incrementando las dependencias entre los distintos dominios y teniendo que lidiar con estrategias de circuit breaker, para compensar las posibles pérdidas de servicio de una pata de tu dominio.
El mensaje aquí podría ser:
- como siempre, “la potencia sin control no sirve de nada”. Podemos quedarnos con la aproximación más simplista de una arquitectura orientada a microservicios
que lo que terminaremos teniendo es un monolito en red - o, peor aún, si tenemos un monolito que partir mal modularizado, no invertir el tiempo necesario para pensar con qué dominios trabajamos y la mejor forma de independizarlos y terminar con la misma basura que teníamos antes, pero ahora esparcida a través de la red.
4. Tareas efímeras.
La definición de efímero es aquello que tiene una duración indeterminada pero corta; literalmente significa que dura un solo día.
Históricamente, dentro de los procesos de negocio, siempre se ha distinguido entre procesos continuos o transaccionales y ejecución de procesos batch, que se caracterizan por la falta de interacción de un usuario para su ejecución; como anticipábamos en la introducción, son procesos que nacen no de una petición de un cliente, sino de la propia calendarización de la ejecución del proceso.
Antes incluso se distinguía el online y el batch por la indisponibilidad del online durante la ventana de tiempo de ejecución de este último, porque se estaban ejecutando los procesos batch o procesos por lotes que se caracterizaban y se siguen caracterizando por tratar con gran cantidad de información.
Durante la ejecución de los procesos batch hay que tener en cuenta si se usa la misma base de datos que el proceso online y qué tipo de operaciones se realizan
para evaluar si este último se puede ver afectado de alguna manera:
- por rendimiento,
- por bloqueos,
- por la propia integridad de los datos, en función del tipo de transaccionalidad que use el batch.
Todo ello hacía que antes se fijasen unas ventanas de tiempo de mantenimiento, en las que el online no estaba disponible, eso ahora negocio lo vería inviable aunque a día de hoy siguen existiendo sistemas con esas restricciones que de manera nocturna impiden la operativa y el uso normal de sus servicios.
¿Qué ejemplos podemos poner de procesos batch? Pues infinidad de ellos, pero he intentado catalogarlos de la siguiente forma:
- Procesos de negocio calendarizados: como pueden ser la generación de facturas mensuales el pago de intereses mensual de cuentas, borrado de datos por fechas de expiración.
- Generación de informes o documentos: movimientos de cuentas o extractos mensuales, aunque quizás ahora la parte de informes no aplique con la posibilidad de acceso a información en tiempo real, sobre todo los de accesos a informes de ventas,
estadísticas de uso, si tenemos la posibilidad de acceso a dicha información directamente online. - Envío de notificaciones: como puede ser el vencimiento de un pago de una cuota, el concepto de carrito abandonado donde se envía un email, incluso con un descuento
para retomar la compra de un producto añadido al carrito pero no consolidado… - Una última que podrían ser las integraciones con terceros que por ser lo último no es lo menos importante, bien con proveedores de servicios o con administraciones
públicas por procesos regulatorios, tenemos que enviar información de nuestros sistemas y también recibir con una periodicidad dada y acorde a un protocolo de comunicaciones y un contrato.
Lo ideal es que esos sistemas de terceros estuviesen apificados de manera que esa comunicación se pudiere realizar online, pero la realidad es que esas integraciones se realizan normalmente vía transferencia de ficheros, por SFTP, Web Services y otros protocolos como EDITRAN. Se trata de procesos de ETL donde- en la ida extraemos la información de nuestro sistema, la convertimos al lenguaje y especificaciones del contrato de comunicaciones y terminamos generando un fichero con el formato acordado.
- En la vuelta extraemos la información del fichero recibido, la traducimos a nuestro lenguaje de dominio y la cargamos en nuestros sistemas.
Ya sé que no es lo mismo definir, analizar y desarrollar un API REST que un proceso batch, no sé si sonará mejor nombrarlas como tareas efímeras, engañándonos a nosotros mismos,
por darle un nombre no tan «boomer», el caso es que, independientemente del nombre es una funcionalidad de negocio que hay que implementar y como decimos en Autentia,
“No hay trabajo indigno”, pues se hace y ya está, porque además es igual de importante o más para el negocio que cualquier otro proceso.
4.1. Requisitos.
Para respaldar la idea de la importancia de desarrollar correctamente y con cabeza este tipo de tareas, vamos a hablar de qué requisitos debemos tener en cuenta al desarrollar un proceso batch.
Si cuando estamos desarrollando un API REST debemos tener en cuenta ciertos aspectos transversales como: idempotencia, seguridad, versionado, retrocompatibilidad o transaccionalidad, cuando desarrollamos un proceso batch debemos tener en cuenta los siguientes:
- Reintentable:
- Imagina que estamos procesando 10k notificaciones y falla el envío de la 9990, ¿qué hacemos con el proceso? Lo volvemos a lanzar, pero ¿y empezaría desde el principio.
- Imagina ahora que estamos generando los extractos mensuales de 500k clientes, cuando dura la ejecución de ese proceso y, si falla ¿cómo controlamos donde ocurrió el fallo para que lanzándolo de nuevo continúe en la posición en la que se quedó.
- Concurrencia:
- ¿cómo controlamos que el proceso de generación de intereses no se ejecute dos veces produciendo intereses duplicados en las cuentas?
- ¿Cómo controlamos que no se notifique dos veces a un cliente de su falta de saldo?
- Trazabilidad: debería tener los mismos requisitos que el online, usando incluso los mismos sistemas de trazabilidad para que las consultas de la actividad del batch se pueda cruzar con las del online.
- Auditoria: de qué herramientas vamos a dotar al equipo de operaciones para disponer ya no solo de un calendario de planificaciones, sino de una monitorización de la actividad o falta de actividad de una tarea planificada.
- En cuanto a la monitorización a nivel de sistemas deberíamos tener el mismo control o mayor que tenemos con los procesos online y conocer el consumo de recursos y posibles problemas de rendimiento de la ejecución de los procesos batch.
5. De la ejecución de tareas batch…
Espero que ahora estemos todos en la misma página y entendamos el problema de negocio, técnico y de operaciones, pero antes de ver cómo desarrollar y montar este tipo de tareas en un entorno cloud, vamos a dar un repaso de cómo los hemos hecho, tradicionalmente, en el pasado.
Hay que pensar en el futuro sin olvidar el pasado para no volver a cometer los mismos errores. Cuando nos planteamos la mejor manera de hacer algo en un «nuevo entorno», está bien pensar primero en cómo se venía haciendo eso mismo en el pasado.
Para ello vamos a ir evolucionando el término desde las tradicionales tareas batch a lo que podríamos nombrar ahora, para ser más cool, como tareas efímeras a medida que nos acerquemos hacia un entorno de microservicios.
5.1. Procesos batch a nivel de sistema operativo.
Lo normal cuando no existía la nube es que, teniendo nuestra máquina en un datacenter, con alta disponibilidad o no, tuviésemos nuestro proceso batch ejecutándose como un proceso a parte haciendo uso, en el caso más simplista, del cron del sistema operativo en el que se ejecutan los procesos.
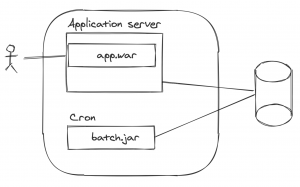
Tenemos nuestra aplicación corriendo en un servidor de aplicaciones y en la misma máquina o en otra dedicada o en un activo/pasivo y en el pasivo se lanzan los procesos batch que tenemos corriendo en nuestro proceso batch.
El proceso batch necesita acceso a los secretos de la base de datos, ahí tenemos un tema de seguridad de quién da acceso a esos secretos al proceso batch.
El tema de la monitorización y trazabilidad de las ejecuciones se basaría en el propio cron del SO. ¿Dónde consultamos las trazas del proceso? ¿Cómo llevamos a cabo la monitorización del mismo?
Ha llovido solo un poco desde que escribí sobre como hacer uso del plugin de Maven Assembly para empaquetar y distribuir un proceso batch autoejecutable. En aquella época, esa era una manera controlada de empaquetar y distribuir las versiones de nuestros procesos batch.
5.2. Procesos batch en una herramienta de planificación.
De ahí se podía evolucionar hacia un sistema dedicado a la ejecución de procesos batch, donde en el mejor de los casos hay un equipo de planificación que se encarga de la coordinación de las ventanas de tiempo de los procesos batch y la gestión de sus dependencias, porque lo normal es que existan procesos que unos dependan de otros y condicionen sus ejecuciones.
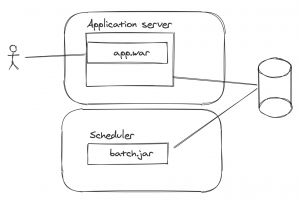
Aquí estamos hablando de aplicaciones comerciales como control-M, tras la que hay un equipo de operaciones que planifica y supervisa la correcta ejecución de los procesos y bajo las instrucciones del equipo de desarrollo realiza las operaciones correspondientes cuando existe un fallo en la ejecución.
Lo normal es también que el proceso batch lo desarrolle el mismo equipo que la vertical de negocio y la interacción con el dominio sea a través de la base de datos.
Aquí el tema de la monitorización y trazabilidad lo controlamos a través de la herramienta de scheduling y la auditoría y monitorización es a través del equipo de planificación.
5.3. Procesos batch integrados en la propia aplicación.
Podemos encontrarnos también con un escenario como el siguiente en el que los procesos batch se lanzan en las propias aplicaciones, de modo tal que si tenemos varias instancias
de un mismo proceso hay una sincronización a nivel de base de datos de qué nodo del cluster está ejecutando un proceso para no haya concurrencia.
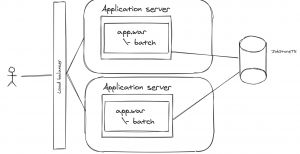
Esto podría ser también un activo/pasivo y que en el pasivo se ejecutasen los procesos batch para no afectar al activo.
Aquí con el tema de la monitorización y auditoría tendríamos los mismos problemas que en el primer escenario, ¿si falla el proceso cómo lo relanzamos? Si hay dependencias entre procesos ¿cómo los controlamos?
¿Cómo atendemos a la monitorización de cuánto consume el proceso batch?
Tenemos que pensar si tiene sentido mantener esta misma arquitectura cuando hablamos de un proceso de integración con un proveedor, escribiendo un fichero posicional y ejecutarlo consumiendo los recursos del online.
Ya podemos ir viendo que quizás dependiendo de la naturaleza del propio proceso batch quizás siga teniendo sentido mantener un esquema como este o no, en una arquitectura de microservicios.
Históricamente y en términos del ecosistema de desarrollo java, el estándar de facto para el desarrollo de procesos calendarizados ha sido por mucho tiempo Quartz y su soporte para la ejecución de tareas en cluster a través del soporte de semáforos en una base de datos compartida.
Dentro del ecosistema de Spring contamos con el soporte de Spring batch para el desarrollo de este tipo de procesos, también con el soporte de persistencia en base de datos para la ejecución de tareas en cluster y con una herramienta de monitorización de procesos llamada Spring Batch Admin, deprecada desde finales de 2017.
5.4. ¿Tareas batch en los microservicios?
Vamos a movernos ya hacía un entorno de microservicios donde además tenemos dependencias síncronas a través de APIs REST entre los distintos dominios.
Y la pregunta es, ¿a qué nivel ejecutamos los procesos batch?, ¿en una instancia concreta de un contenedor que ya de por sí es efímera?
Imaginad que en el dominio de payments tenemos que lanzar la generación de facturas mensuales, ¿quién se encarga de ello?, ¿el propio microservicio de payments?
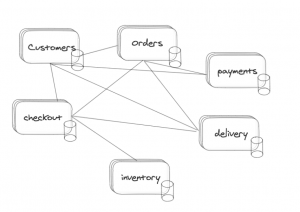
La primera pregunta es cómo asegurar que el proceso se ejecuta una única vez y en un solo nodo; y la respuesta podría estar en la sincronización a través de la base de datos usando como hemos visto Quartz, Spring Batch o un semáforo como ShedLock, pero entonces nuestro microservicio ya estaría accediendo a un repositorio de persistencia que ya no es estrictamente el suyo propio.
Además, si ejecutamos el proceso a nivel de pod, el pod puede llegar a escalar por uso de cpu o de memoria, podríamos decir que perfecto ¿no?, para eso está preparado el cluster de k8s, tenemos una instancia de nuestro microservicio de payments y una vez al mes cuando toca generar las facturas mensuales a las 02:00 de la mañana se ejecuta el proceso batch que hace escalar el pod a 2 y tenemos una segunda instancia dedicada al online mientras que la primera termina con el proceso batch.
Mientras se ejecuta el proceso batch ¿estamos seguros que la parte online de la aplicación está respondiendo?, ¿cuánto afecta el batch al online durante esa ventana de ejecución?
Si pensamos en la integración con terceros y en la generación o consumo de ficheros, ¿tiene sentido que un microservicio desde una instancia del online genere un fichero y, aún más, que se conecte a un sftp o un canal EDITRAN para el envío y recepción del mismo?
Es más, ¿cómo nos aseguramos que por el número de dependencias síncronas que tiene un microservicio, con la carga que provoca esa generación de facturas no termina afectando al escalado de otros pods como una reacción en cadena? Si para la generación de facturas necesitamos consultar la información del cliente, esta estará en el microservicio de clientes, ¿cómo le afectará ese proceso batch?, ¿podría convertirse en una reacción en cadena?
Pero lo más importante, el microservicio seguiría respondiendo al principio de responsabilidad única, ahora vamos a tener que gestionar su ciclo de vida no solo porque cambie el módulo de pagos sino también porque cambie el modelo de las facturas. También vamos a tener un proceso latente en el online, incrementando el tamaño de los despliegues y complicando su mantenimiento, “simplemente” para ejecutarse una vez al mes.
Y ¿qué ocurre con la monitorización, auditoría y gestión de errores?, ¿qué herramienta le damos a operaciones para controlar la ejecución de los procesos batch?, ¿quién controla las ventanas de tiempos y cómo gestionamos las dependencias para decidir que si el proceso de facturación no se ha completado no se lance el proceso de contabilidad?
Ahora imaginad que nuestra arquitectura de microservicios no está tan acoplada en red, no hay tantas dependencias síncronas entre los microservicios y que disponemos de una arquitectura dirigida por eventos en la que cada dominio sí es realmente independiente del otro porque dispone de una proyección del dominio que necesita para operar como una copia local de su propio dominio.
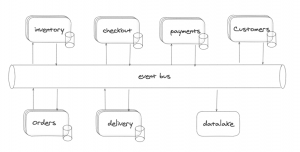
Esto es, cuando el dominio de pagos necesita generar las facturas no le pide al dominio de clientes la información personal de los mismos, sino que tiene una copia local de esos datos, dentro de su propio dominio, para ser realmente independiente.
Lo más interesante es que toda esa sincronización de datos se realiza en segundo plano a través de un bus de eventos que permitiría también que todos los eventos del event journal
se consumiesen desde un datalake en el que teniendo la información agregada, además de servir a propósitos de business intelligence, permitiesen la ejecución de los procesos batch
necesarios desde ahí, desde el informacional.
La realidad es que tanto teniendo este tipo de arquitectura orientada por eventos, como una arquitectura más síncrona, los procesos que se ejecutan en el datalake como sistema
informacional no deberían afectar al operacional y los procesos batch de negocio, no de reporting, deberían ejecutarse en el lugar más cercano al maestro de los datos que es el propio microservicio. Además de que el desarrollo de ese proceso batch debería realizarlo el propio equipo de desarrollo que ha desarrollado el vertical de negocio y conoce su problemática y su lenguaje de dominio.
6. …a la ejecución de tareas efímeras como microservicios.
¿Cuál puede ser la propuesta entonces? Podríamos ejecutar los procesos batch de manera independiente, con un artefacto propio, como si se tratase de cualquier otro microservicio
de negocio dentro del cluster como un proceso más, usando la misma tecnología de desarrollo que usamos para los microservicios, pero de un modo especial, porque tiene una duración limitada.
Pero, una vez decidimos que nuestros procesos batch puede que se ejecuten en el mismo cluster, bueno en un namespace, con unas características específicas para la ejecución de estos procesos, ¿qué tipo de interacción vamos a tener entre los procesos batch y los microservicios del dominio?
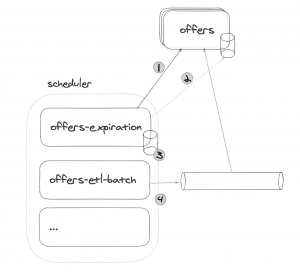
Básicamente, la pregunta ahora es: el proceso batch, siendo del mismo dominio, ¿lo entendemos como un proceso más y podría tener acceso directo al repositorio de persistencia o entendemos que el dominio del microservicio debería encapsular el repositorio de persistencia como un detalle de su implementación y el proceso batch debería acceder a la información del dominio a través de su api? o incluso, ¿podríamos entender que el propio batch podría llegar a tener su propia base de datos?, llevando al extremo el concepto de microservicio.
Salvando este último caso, va a depender de la naturaleza del proceso batch y en cualquier caso, deberíamos no caer en el error de ejecutar un proceso batch sin tener en cuenta
que podemos estar ejecutándolo ahora para una docena de datos de prueba y que en producción podemos tener la necesidad de lanzarlo para miles o millones de registros.
Entonces siempre que necesitemos acceder a información del dominio, lo haremos por lotes, de forma paginada:
- Si lo hacemos a través de una conexión directa a base de datos ya estamos acoplando el modelo de persistencia a dos artefactos distintos y asumimos que el proceso batch
tiene acceso a detalles de su implementación, aunque solo necesite acceder a una parte específica del modelo de datos. Sin duda, esta es la opción más efectiva en cuanto a
rendimiento pero la que más acopla, cualquier cambio en el modelo aunque debería ser siempre retrocompatible (ya hablaremos en otro momento de la gestión de versionado en base de datos en un entorno de microservicios). Afecta también al proceso batch. - Si lo hacemos a través de apis estamos totalmente desacoplados en cuanto a repositorio y solo nos vincula un contrato de servicios, como al resto de clientes; solo debemos tener en cuenta la criticidad del proceso batch y si afecta sensiblemente el rendimiento a la ejecución del mismo, puesto que la serialización/deserialización de la información en red y el rendimiento de acceder a esa información, puede ser un condicionante en la ejecución de un proceso batch dentro de una ventana de tiempo o nos podría obligar a escalar la ejecución del proceso batch teniendo en cuenta parámetros de concurrencia en su ejecución.
La respuesta es que no hay respuesta, depende de la interpretación que le demos al ámbito del dominio del proceso batch y a los condicionantes técnicos y de negocio. Yo entiendo que ambos escenarios podrían ser válidos e incluso un tercero en el que el proceso batch tiene su propia base de datos alimentada por la información de los eventos de dominio y alimentando el dominio a través de eventos de callback, dentro de un proceso de envío y recepción de información de un proveedor en modo ETL.
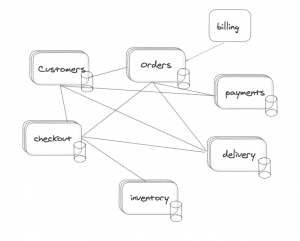
Siguiendo el esquema inicial de una arquitectura orientada a microservicios podríamos tener esta tarea asociada al proceso de facturación de pedidos. Ojo y cuidado con las relaciones síncronas y las reacciones en cadena.
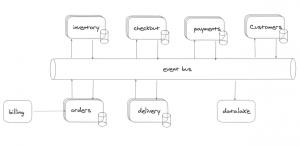
Con menor impacto en el sistema podríamos tener el siguiente esquema en una arquitectura dirigida por eventos donde solo afectaría la ejecución al dominio de payments.
6.1. Ejecución de tareas en cloud.
Pero si en un cluster en cloud lanzamos pods, ¿también se pueden ejecutar jobs? Efectivamente.
Partiendo del siguiente yaml, podríamos desplegar en k8s un contenedor basado en una imagen de perl lanzando un job que calcula el número pi hasta 2000 decimales.
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
Ejecutando el siguiente comando:
kubectl apply -f job.yaml
El único requisito del artefacto autoejecutable a desplegar del job, es que finalice, esto es, que no mantenga la ejecución per se, sino que se detenga automáticamente al finalizar la tarea a ejecutar.
Al igual que podemos lanzar jobs, también podemos planificarlos con el soporte de un cronjob: un cronjob ejecuta tareas Jobs a intervalos regulares.
Un objeto CronJob es como una línea de un archivo crontab (tabla cron). Ejecuta un trabajo de forma periódica según un horario programado escrito en formato Cron.
Así el siguiente yaml nos serviría para crear un CronJob sobre una plantilla de un job basada en una imagen con un bash para imprimir la fecha y lanzar un mensaje por la consola que se ejecutará cada minuto.
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
Para crearlo bastaría con ejecutar el siguiente comando:
kubectl create -f cronjob.yaml
Para monitorizar la ejecución de los jobs podemos lanzar el siguiente comando:
kubectl get jobs --watch
Y para ver los logs del proceso, como con cualquier otro pod.
7. Conclusiones.
En este tutorial hemos entrado, a bajo nivel, en la parte conceptual de cómo desarrollar y desplegar tareas batch, digo… efímeras, en un entorno de microservicios. Nos falta entrar en el detalle técnico de cómo llevar a la realidad tales conceptos, pero eso, será objeto de futuras entradas.
Cualquier solución técnica que diseñemos debería tener en cuenta los requisitos iniciales que planteábamos para un entorno cloud, tratando de no acoplarnos al proveedor de cloud
con el uso de servicios propietarios del mismo.
En el siguiente tutorial intentaremos dar una solución técnica «cloud agnostic» 😉
Stay tuned !
Jose

