

Sigo con una colección de tutoriales sobre aprendizaje automático con TensorFlow que, os recuerdo, podéis empezar en estos enlaces:
- Instalación de TensorFlow y entorno de desarrollo Python en Mac.
- Revisión de ejemplos de TensorFlow.
- Principios de aprendizaje automático supervisado.
- Primeros pasos con Python: los tipos de datos básicos.
Hay multitud de recursos y libros sobre aprendizaje automático con TensorFlow. Esto es al mismo tiempo una bendición y un castigo porque es necesario “curar” contenidos y elegir una muestra para conseguir nuestro objetivo sin perder demasiado tiempo.
Una de las primeras frustraciones que he tenido es no saber muy bien qué es lo que está pasando por debajo. Para minimizarlo vamos a utilizar una herramienta que se llama TensorBoard, que nos va a permitir ver gráficamente los resultados, parámetros y otras cosas internas del proceso de entrenamiento.
El ejemplo más sencillo para empezar, a mí me parece que se este, que trabaja con escalares porque muestra un ejemplo de regresión lineal conceptualmente comprensible.
Nuestro objetivo va a ser entender el ejemplo y alterarlo para representar visualmente el proceso y, posteriormente, adaptarlo para que falle a propósito, que es como creo que se aprende.
Lo vamos a ejecutar con Colab.
Si lo deseamos podemos crear una copia local en nuestra cuenta de google.
Podemos encontrarlo (al final) en la lista de herramientas de la cuenta de Google (cuadraditos) de nuestra cuenta personal en la sección de Colaboratory.
Mirad en recientes, la lista de nuestros ficheros. Por cierto, si modificáis vuestra copia, le tenéis que ir dando a guardar, que no es como los documentos de Google que se guardan solos (lo he aprendido dolorosamente). También os recomendaría cambiarle el nombre para no confundiros entre el original, el que usas u otras instancias.
Antes de tocar nada vamos a tratar de entender el documento base y el código implicado. Se carga la extensión de Tensorboard y las librerías. Se verifica la versión.
# Load the TensorBoard notebook extension.
%load_ext tensorboard
from datetime import datetime
from packaging import version
import tensorflow as tf
from tensorflow import keras
import numpy as np
print("TensorFlow version: ", tf.__version__)
assert version.parse(tf.__version__).release[0] >= 2, \
"This notebook requires TensorFlow 2.0 or above."
Ahora se elige un tamaño de muestra y se determina el porcentaje de datos de entrenamiento (subconjunto), que es el 80%.
Se crea un espacio lineal de variables de -1 a 1 y se desordenan las muestras (con shuffle).
A partir de una ecuación lineal y un ruido aleatorio dentro de un rango se genera un conjunto de salidas respecto a nuestra x.
Y se crean los arrays de elementos de entrenamiento y prueba.
data_size = 1000 # 80% of the data is for training. train_pct = 0.8 train_size = int(data_size * train_pct) # Create some input data between -1 and 1 and randomize it. x = np.linspace(-1, 1, data_size) np.random.shuffle(x) # Generate the output data. # y = 0.5x + 2 + noise y = 0.5 * x + 2 + np.random.normal(0, 0.05, (data_size, )) # Split into test and train pairs. x_train, y_train = x[:train_size], y[:train_size] x_test, y_test = x[train_size:], y[train_size:]
Se define el modelo y compila. Calculamos cómo se acomoda el modelo a los datos.
Se han definido 100 iteraciones (epochs=100).
Adicionalmente, se establecen los logs y callbacks de TensorBoard.
logdir = "logs/scalars/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir)
model = keras.models.Sequential([
keras.layers.Dense(16, input_dim=1),
keras.layers.Dense(1),
])
model.compile(
loss='mse', # keras.losses.mean_squared_error
optimizer=keras.optimizers.SGD(lr=0.2),
)
print("Training ... With default parameters, this takes less than 10 seconds.")
training_history = model.fit(
x_train, # input
y_train, # output
batch_size=train_size,
verbose=0, # Suppress chatty output; use Tensorboard instead
epochs=100,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback],
)
print("Average test loss: ", np.average(training_history.history['loss']))
Se lanza TensorBoard:
%tensorboard --logdir logs/scalars
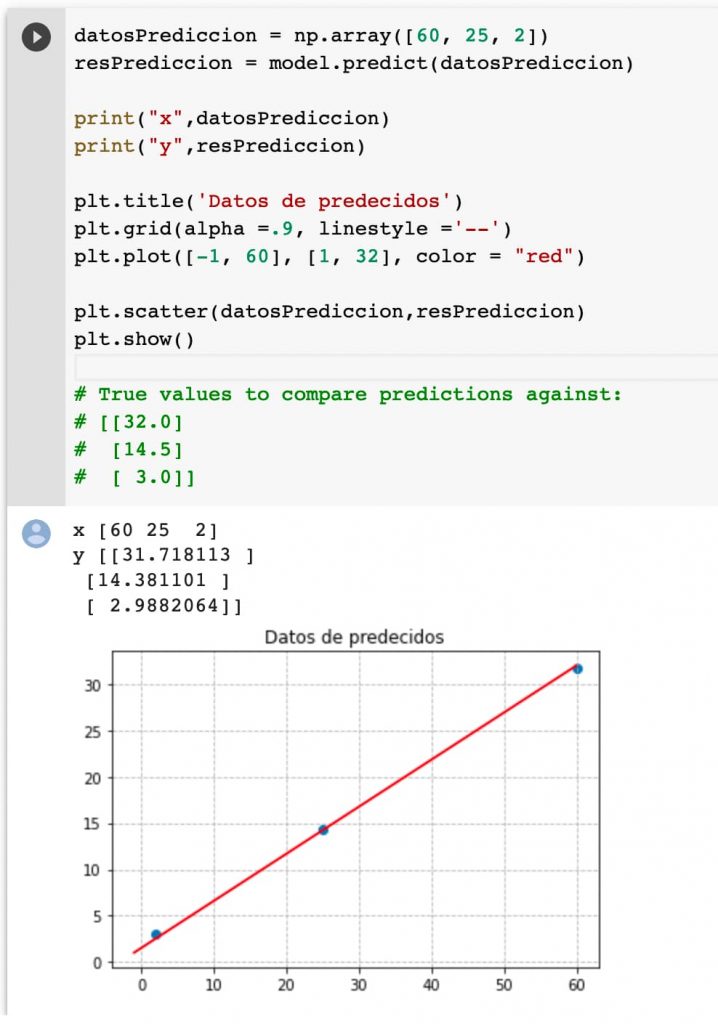
Y se predice otro conjunto de datos en base al modelo. Es curioso que la dimensión es muy diferente, cosa no importante en una línea pero sí es relevante para otros ejemplos que haremos.
print(model.predict([60, 25, 2])) # True values to compare predictions against: # [[32.0] # [14.5] # [ 3.0]] [[32.234306 ] [14.5974245] [ 3.0074697]]
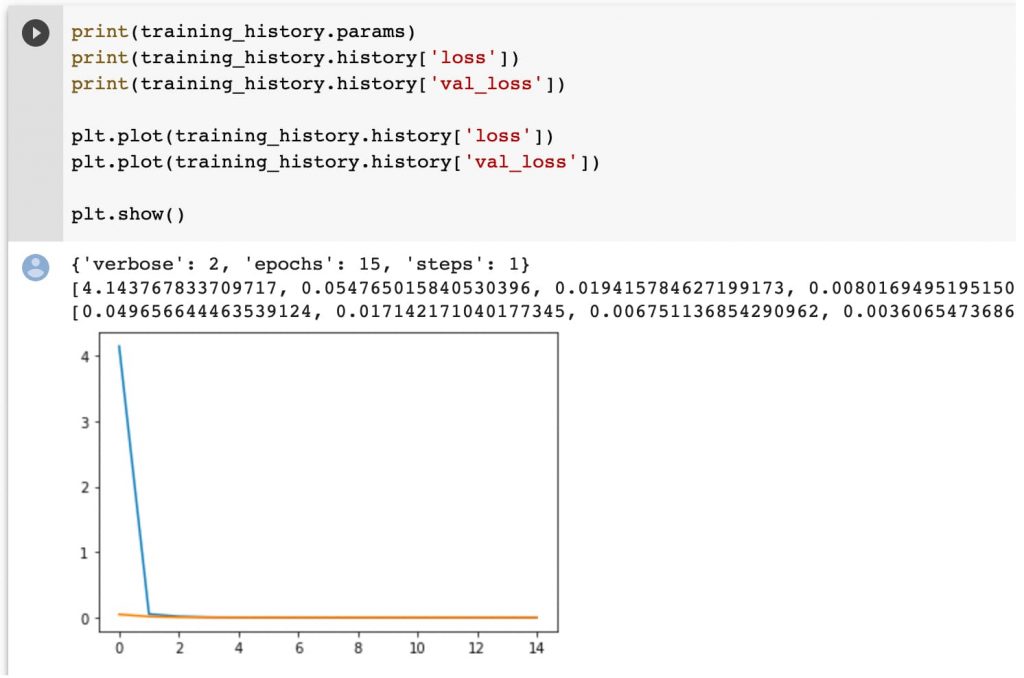
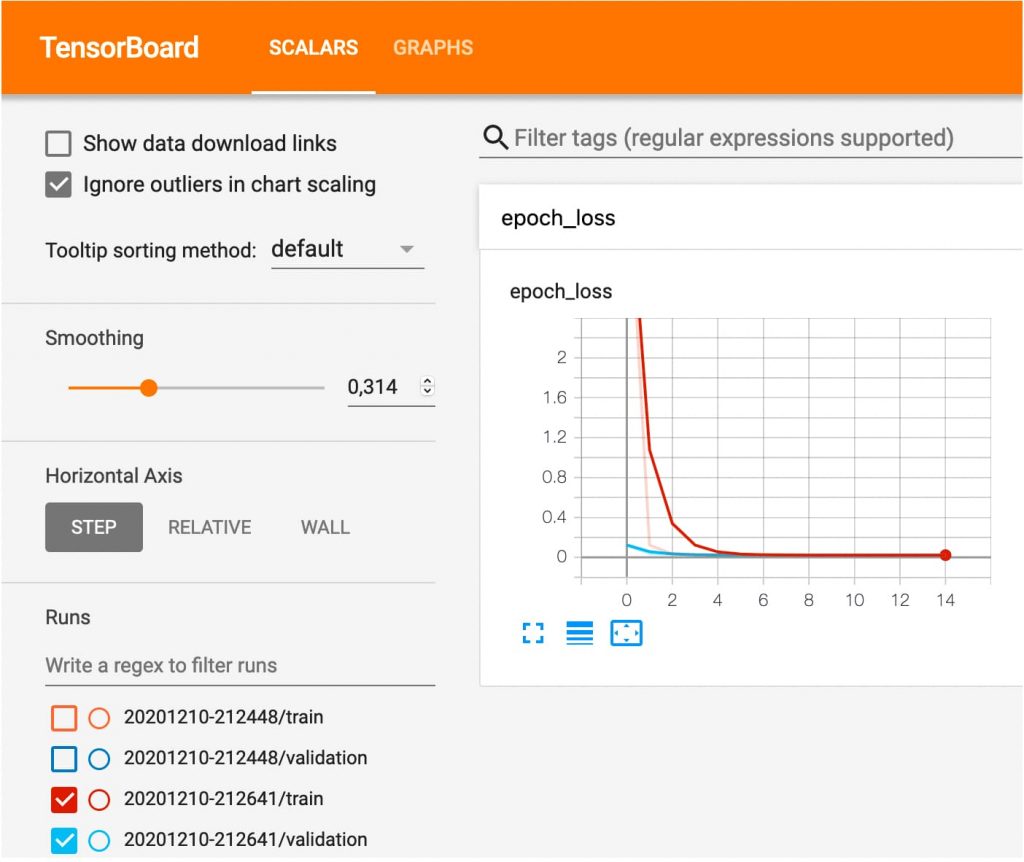
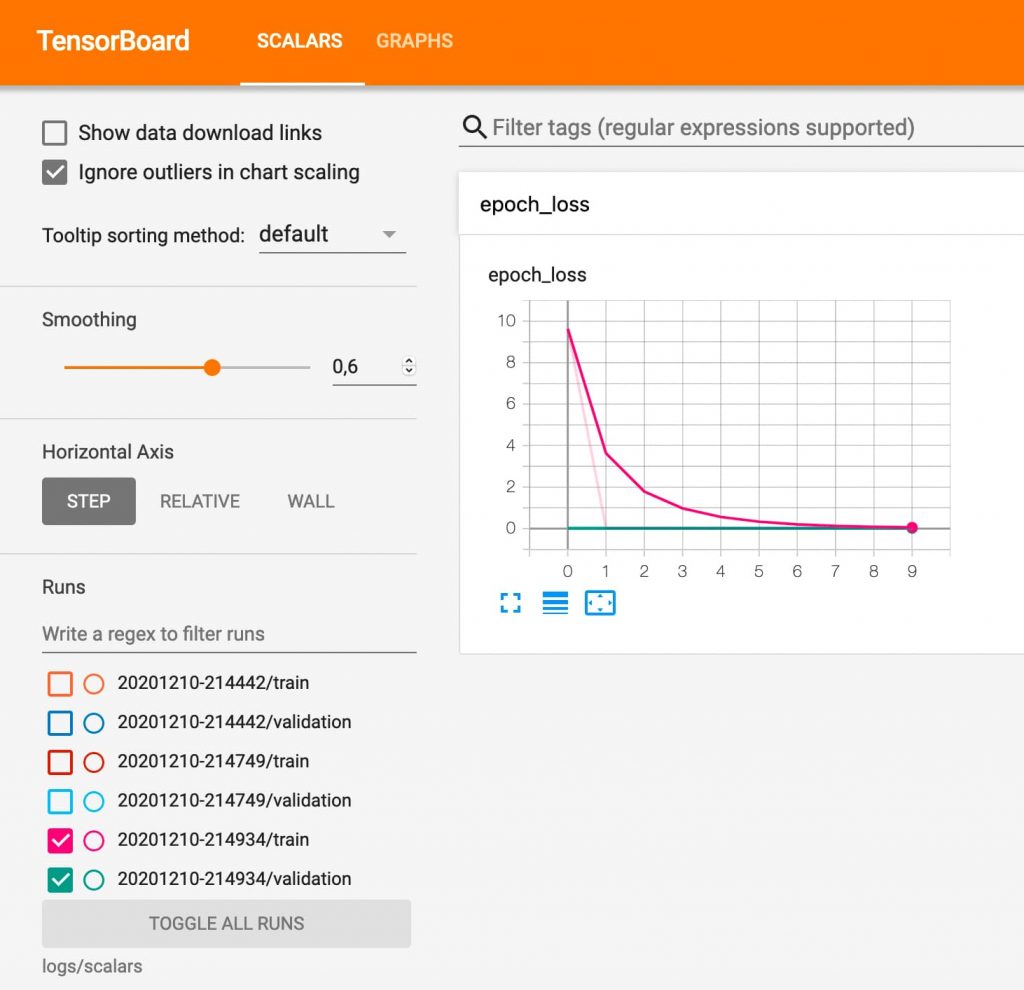
Y la gracia es que podemos ver en TensorBoard cómo evoluciona la perdida en cada intento o ciclo de entrenamiento (epoch).
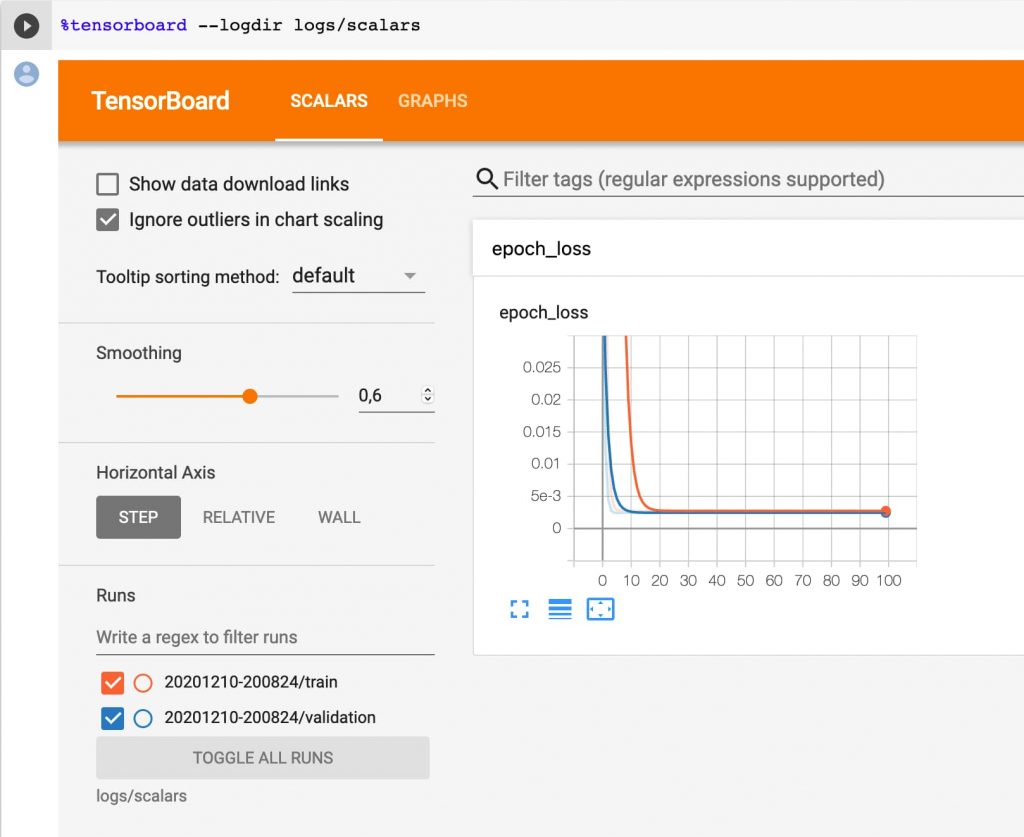
Podemos ver que a partir del la iteración 10 el modelo no mejora. Loss es relativo al error de los datos de entrenamiento y val_loss de validación.
Ojo que he cambiado el parámetro verbose a 1 para que muestre mejor los resultados.
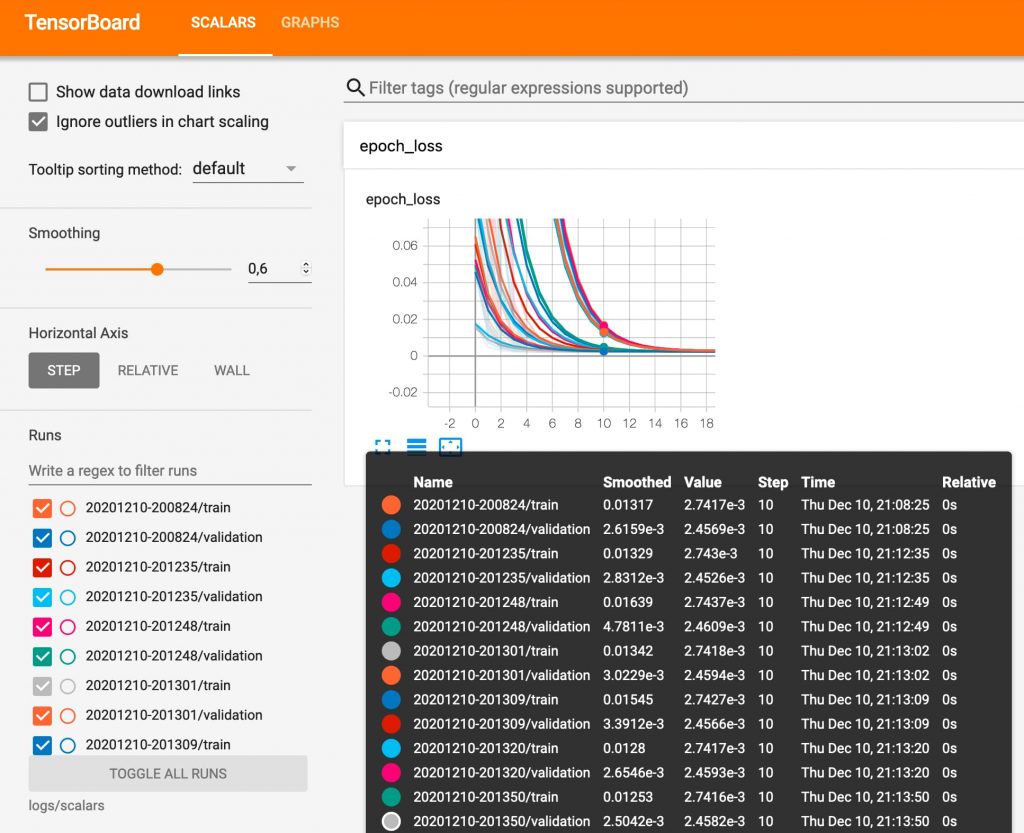
Podemos hacer zoom para visualizar los datos. En la sección izquierda inferior podemos seleccionar la muestra que queremos visualizar. Así podemos comparar los resultados de cada intento para afinar el modelo.
También se puede ver cómo afectan variaciones de los datos: os dejo este enlace que parece interesante.

Vamos a añadir a nuestro libro (notebook colab) unas pocas líneas para ver los datos del intento (recordar que en cada prueba se generan conjuntos de datos aleatoriamente).
Tenemos que importar la librería myplot:
import matplotlib.pyplot as plt
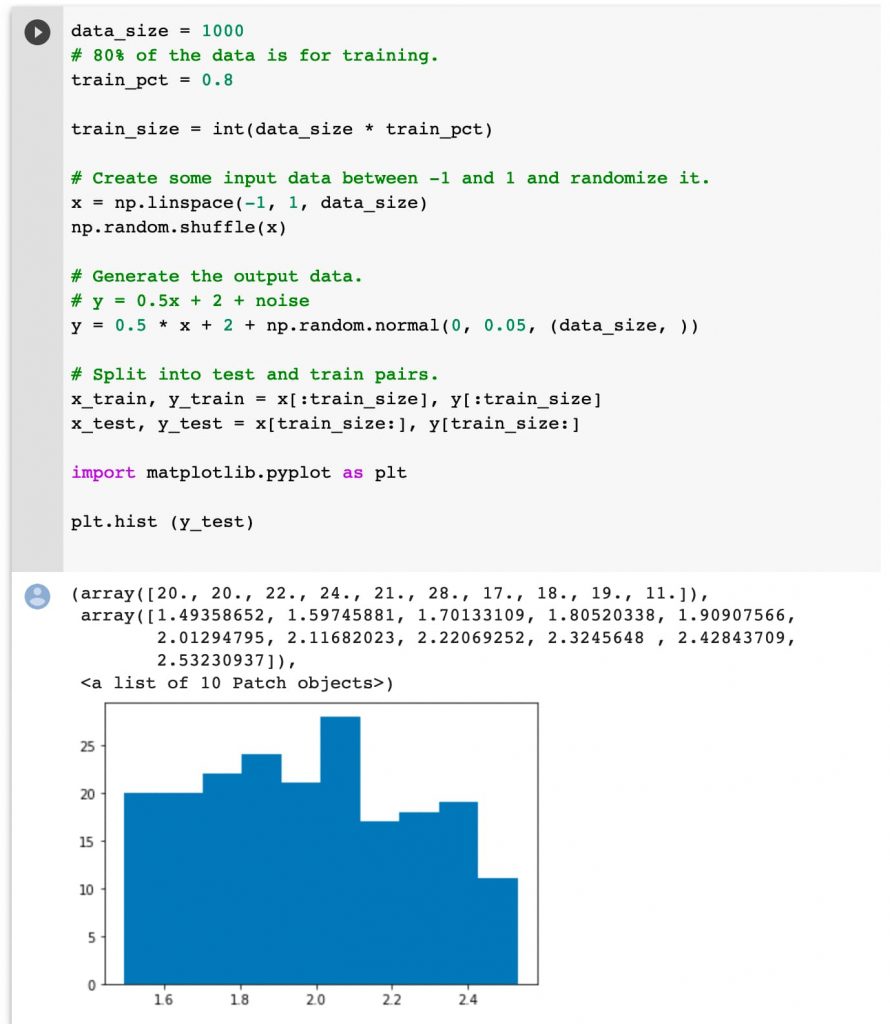
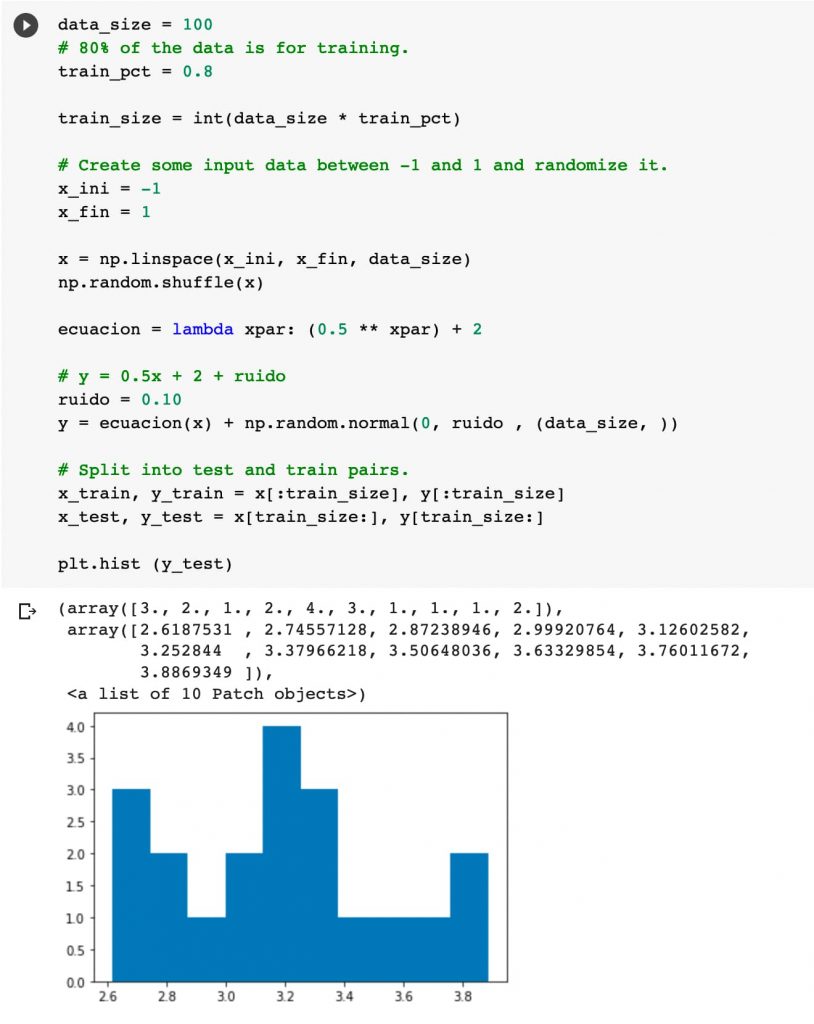
Pintar un histograma es muy sencillo y nos será útil para visualizar la distribución de los datos (volvemos a recordar que se generan aleatoriamente).
En este ejemplo no importa demasiado pero en otros puede ser significativo para reducir la complejidad de los datos.
plt.hist (y_test)
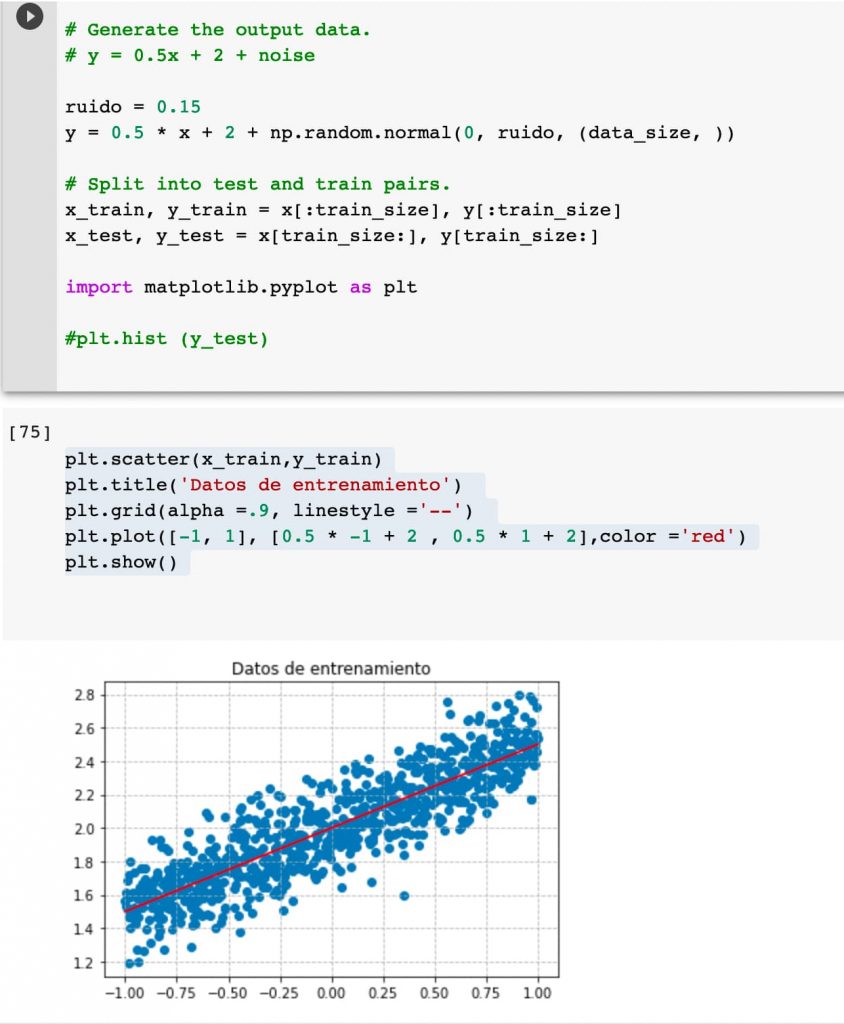
Vamos a representar los datos de entrenamiento gráficamente. Es tremendamente sencillo ya que con la función scatter podemos pintar arrays de puntos x e y.
plt.scatter(x_train,y_train)
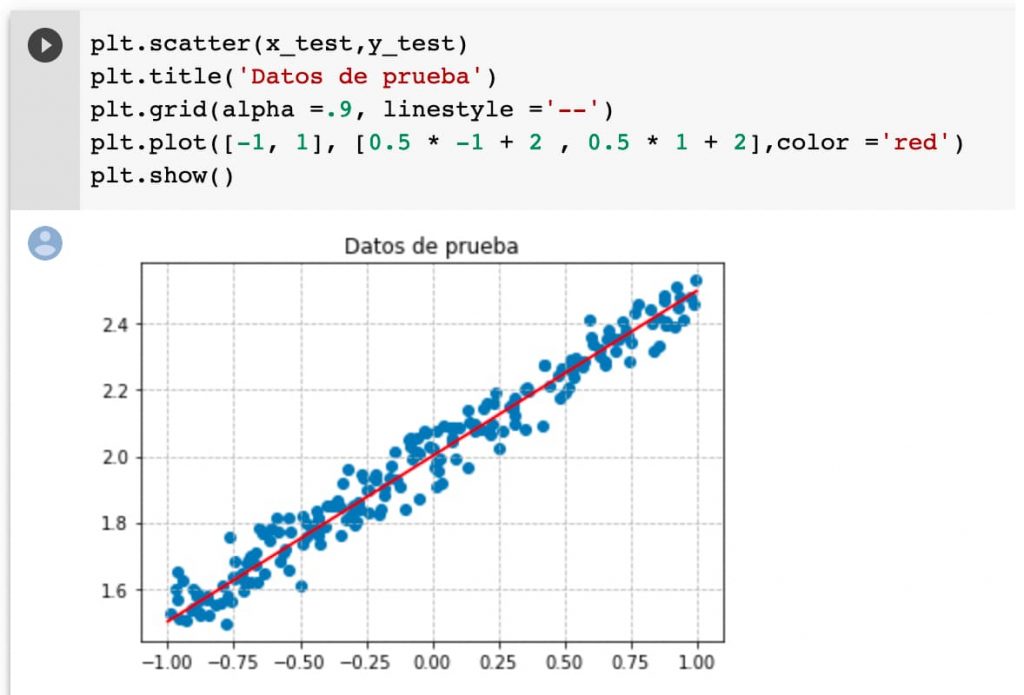
Vamos a repetir con los datos de prueba:
plt.scatter(x_test,y_test)
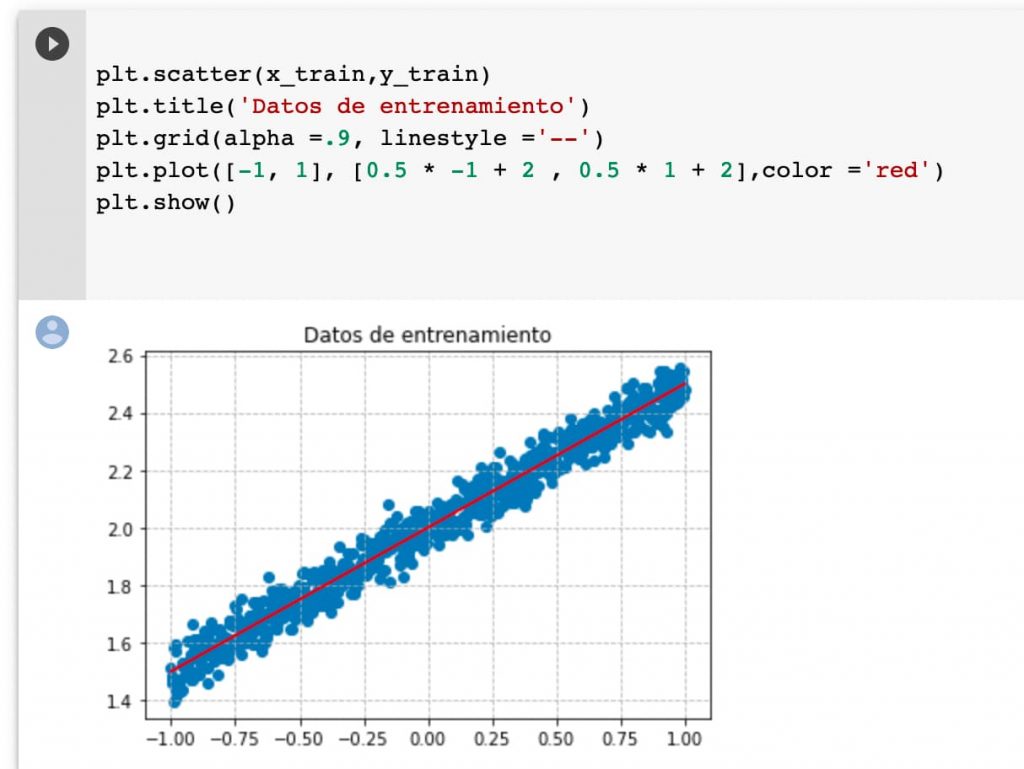
Podemos pintar una línea base para hacernos mejor a la idea de cómo se han distribuido los datos. Recordad que solamente es una referencia porque en cada generación los datos son aleatorios y el conjunto de datos podría acomodarse mejor a otra recta.
plt.scatter(x_train,y_train)
plt.title('Datos de entrenamiento')
plt.grid(alpha =.9, linestyle ='--')
plt.plot([-1, 1], [0.5 * -1 + 2 , 0.5 * 1 + 2],color ='red')
plt.show()
Este es el resultado obtenido. Pintamos también una rejilla para ayudarnos a tener una buena referencia.
Os aconsejo mirar el tutorial para hacer cosillas interesantes con la librería de gráficas en https://matplotlib.org/tutorials/introductory/pyplot.html
Hay un montón de ejemplos directamente utilizables.
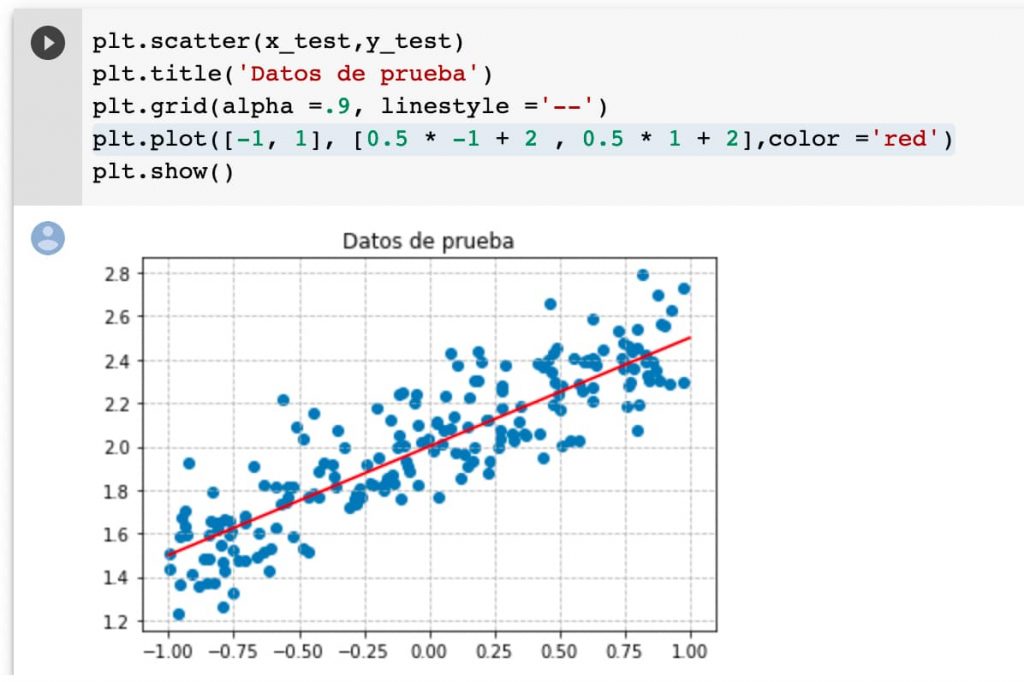
Podemos pintar en «plan chapucero» copiando y pegando (un poco más adelante mejoraremos un poquito las cosas con funciones) las líneas de referencia en los datos de prueba también.
También podemos navegar por el objeto con la historia de la ejecución, sin necesidad de usar Tensorboard (obviamente perdiendo el modo interactivo). No parece mala idea consultar la documentación.
Vamos a visualizar los datos de la predicción respecto al modelo entrenado y la gráfica de referencia.

Como podemos comprobar, lo hace bastante bien.
Vamos a intentar hacer algunas variaciones sencillas del modelo para ver como afecta al proceso de aprendizaje.
Si alteramos la variable que representa el ruido, incrementándola, el modelo no está ya tan claro. En base a la muestra que se tomase, podría ya no acertar tanto.
Visualicemos de nuevo los datos.
Los datos de prueba se ven igualmente afectados:
Vemos cómo afecta a los valores de pérdida. No parece muy relevante.
Representamos visualmente los datos de salida: no lo hace nada mal tampoco.
datosPrediccion = np.array([60, 25, 2])
resPrediccion = model.predict(datosPrediccion)
print("x",datosPrediccion)
print("y",resPrediccion)
plt.title('Datos de predecidos')
plt.grid(alpha =.9, linestyle ='--')
plt.plot([-1, 60], [1, 32], color = "red")
plt.scatter(datosPrediccion,resPrediccion) plt.show()
Vamos hacer unos cambios más significativos en el código.
La ecuación la vamos a convertir en una función landa para poder complicar un poco los ejemplos. Así, si cambiamos la ecuación no nos preocupamos de las partes de código a las que afecta (gráficas de referencia).
La gracia es ser capaz de provocar el fallo. Es decir, entrenar el modelo con una muestra de datos y darnos cuenta que los datos posteriores de predicción, no proporcionan los datos deseados.
Bajamos el tamaño de la muestra a 100 para poder ver la representación más clara.
data_size = 100 # 80% of the data is for training. train_pct = 0.8 train_size = int(data_size * train_pct) # Create some input data between -1 and 1 and randomize it. x_ini = -1 x_fin = 1 x = np.linspace(x_ini, x_fin, data_size) np.random.shuffle(x) ecuacion = lambda xpar: (0.5 * xpar) + 2 # y = 0.5x + 2 + ruido ruido = 0.10 y = ecuacion(x) + np.random.normal(0, ruido , (data_size, )) # Split into test and train pairs. x_train, y_train = x[:train_size], y[:train_size] x_test, y_test = x[train_size:], y[train_size:] plt.hist (y_test)
Ahora vamos a hacer una pequeña trampa ya que vamos a utilizar una potencia.
ecuacion = lambda xpar: (0.5 ** xpar) + 2
Dejamos de chapucear y convertimos la función de pintado en algo más genérico.
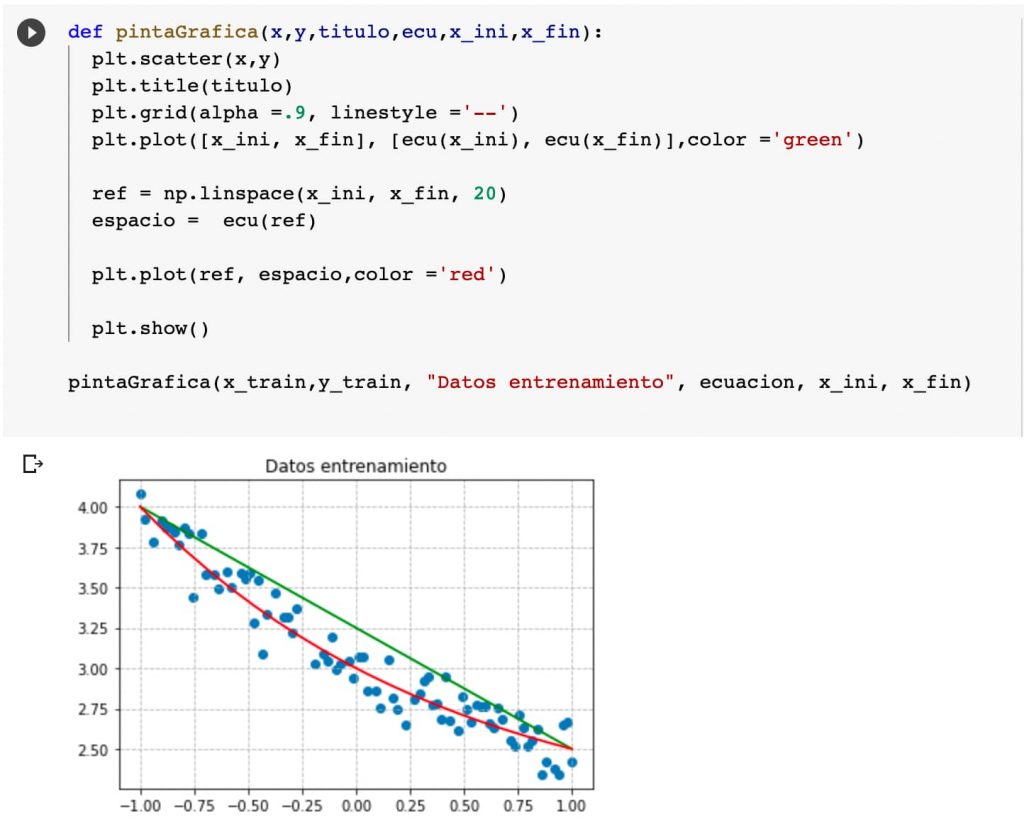
Para pintar la línea de referencia vamos a crear un espacio lineal con 20 muestras, lo que hará que nos valga para rectas y curvas más complejas.
def pintaGrafica(x,y,titulo,ecu,x_ini,x_fin): plt.scatter(x,y) plt.title(titulo) plt.grid(alpha =.9, linestyle ='--') plt.plot([x_ini, x_fin], [ecu(x_ini), ecu(x_fin)],color ='green') ref = np.linspace(x_ini, x_fin, 20) espacio = ecu(ref) plt.plot(ref, espacio,color ='red') plt.show() pintaGrafica(x_train,y_train, "Datos entrenamiento", ecuacion, x_ini, x_fin)
Con eso vamos a tener una linea recta (verde) y también una gráfica que representa la ecuación de referencia.
Podemos ver el resultado en TensorBoard.
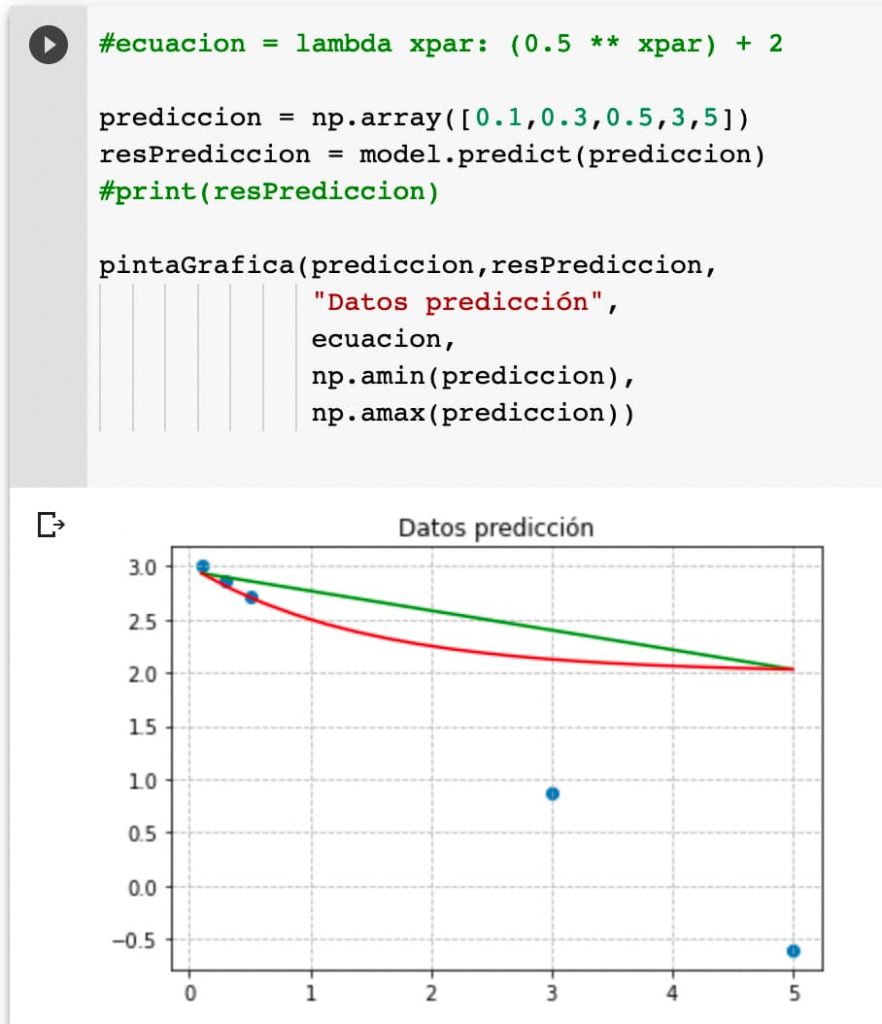
Ahora vamos a introducir unos datos a predecir:
#ecuacion = lambda xpar: (0.5 ** xpar) + 2
prediccion = np.array([0.1,0.3,0.5,3,5])
resPrediccion = model.predict(prediccion)
#print(resPrediccion)
pintaGrafica(prediccion,resPrediccion,
"Datos predicción",
ecuacion,
np.amin(prediccion),
np.amax(prediccion))
Y comprobamos la predicción. La gráfica es muy ilustrativa mostrando que en rangos ajenos a los entrenados el modelo no lo predice bien.
La verdad es que da gusto la facilidad con la que se pueden hacer cambios con los notebooks Jupyter en Colab y las capacidades de operación de Python en línea.
Ahora tenemos que continuar profundizando con las modificaciones de valores. La gracia es predecir lo que crees que va a pasar antes de que pase e ir entendiendo los distintos parámetros de entrenamiento.
Recordemos que la clave está aquí:
model = keras.models.Sequential([
keras.layers.Dense(16, input_dim=1),
keras.layers.Dense(1),
])
Y tenemos que saber más sobre las opciones disponibles.

