

Este tutorial es el tercero de una cadena de tutoriales relacionados con TensorFlow:
- Instalación de TensorFlow y entorno de desarrollo Python en Mac.
- Revisión de ejemplos de TensorFlow.
Si has llegado a este tutorial quiero recordarte que soy novato en el aprendizaje automático y que simplemente estoy compartiendo el camino que estoy siguiendo y aquellas cosas que creo relevantes/interesantes. Son básicamente unos primeros apuntes compartidos (en vez de guardármelos para mí solo) así que sentiros libres de corregir lo que os parezca impreciso.
Puedes empezar la linea de tutoriales que estoy haciendo desde el inicio.
Una de las cosas más difíciles es ¿por dónde empezar? Yo te diría que si eres técnico, hay una charla de hace un par de años de Ricardo Guerrero que no tiene desperdicio.
También Google tiene un curso que es una maravilla (y en castellano).
De este curso de Google voy a compartiros algunas slides e ideas clave o (lo que yo entiendo). Veréis que en este mundo hay un poco de lío entre palabras en inglés, en castellano, sinónimos y palabras que se usan como sinónimos pero no lo son realmente (siendo más precisos, que inicialmente tampoco hace tanta falta)… Todo a su tiempo.
Bueno, vamos a ello.
Cuando una máquina quiere aprender, simula el comportamiento de los humanos: hacemos experimentos y comprobamos los resultados, adaptando las teorías y ajustando el error.
Hay dos tipos principales de aprendizaje, el supervisado y el no supervisado. En el supervisado, alimentamos en sistema con unas muestras que nos permiten entrenar un modelo y le decimos lo que tiene que obtener. Por ejemplo, le damos una lista de coches con atributos: precio, año, marca, modelo, kilómetros, estado de la pintura, extras, zona, etc. y le decimos si es una buena compra o mala. De este modo, si alimentamos miles de datos de operaciones consideradas buenas o malas, cuando le pidamos al sistema que evalúe una nueva operación de compra de un nuevo vehículo nos dirá si, en base a ese aprendizaje, cree que lo debemos comprar o no.
En el aprendizaje no supervisado funciona de un modo un poco diferente: lo que hacemos es dejar al sistema que procese un conjunto muy grande de datos y los agrupe en conjuntos y luego, nosotros catalogamos los conjuntos que ha encontrado. Pongamos que en una red de ordenadores hay entradas y salidas de datos a unas horas de oficina (correo electrónico, navegación web, etc.) Ahora bien, un hacker puede intentar acceder a horas distintas o por puertos no típicos: un ataque. Si todo ese tráfico de red lo alimentas en un sistema no supervisado puede encontrar conjuntos normales y otros anormales por sí mismo. Eso sí, tú tendrás que etiquetar a posteriori el significado para un humano de ese grupo.
El curso de google se centra en aprendizaje automático supervisado. A partir de entradas (atributos, mejor procesados o incluso combinados) y salidas pre-establecidas (etiquetas) tratamos de predecir resultados (si el nuevo elemento pertenece a una etiqueta).
Creamos un modelo y le ponemos etiquetas (los valores que queremos predecir), por ejemplo: spam o no spam.
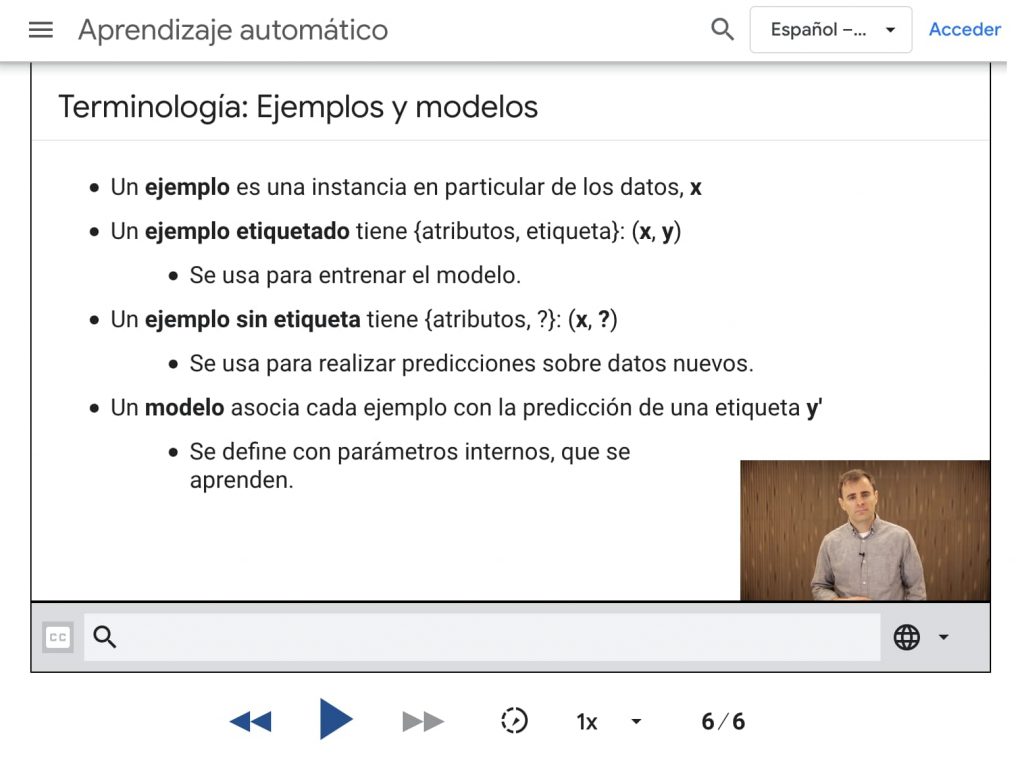
Utilizamos atributos para representar datos: por ejemplo un correo electrónico puede ser un dato etiquetado en el que tengamos el valor del atributo y su etiqueta.
Un ejemplo etiquetado: labeled examples: {features, label}: (x, y)
También pueden haber ejemplos no etiquetados: unlabeled examples: {features, ?}: (x, ?)
El modelo define la relación entre atributo y etiqueta. Hay peligros como construir modelos que están sobre-entrenados sobre una muestra muy concreta y luego no son capaces de adaptarse a nuevas muestras.
Una de las primera diferenciaciones que se hace es: regresión frente a clasificación.
En una clasificación obtenemos un conjuntos de salidas limitadas: por ejemplo, podemos usar una foto de una flor y decirnos cuál de las entrenadas es (etiquetas predefinidas).
La regresión no devuelve un conjunto finito de valores sino que proporciona un valor numérico, por tanto, con decimales y continuo (infinito), por ejemplo: cuál es el precio que debería tener una vivienda en base a sus atributos.

Un modelo será más bueno o malo en base a la exactitud que presenten las predicciones vs. la realidad contrastable por un humano.
Podemos imaginarnos que tenemos un conjunto de muestras numéricas donde hay una relación entre X e Y. La relación entre X e Y más simple puede ser una recta: X = M1 * X1 + B.
A partir de un conjunto de datos podemos extraer una recta que se aproxima a la relación entre X y Y. En algunos valores de X, Y tendría desviaciones, que será la perdida. La perdida es la diferencia entre la predicción y el valor real.
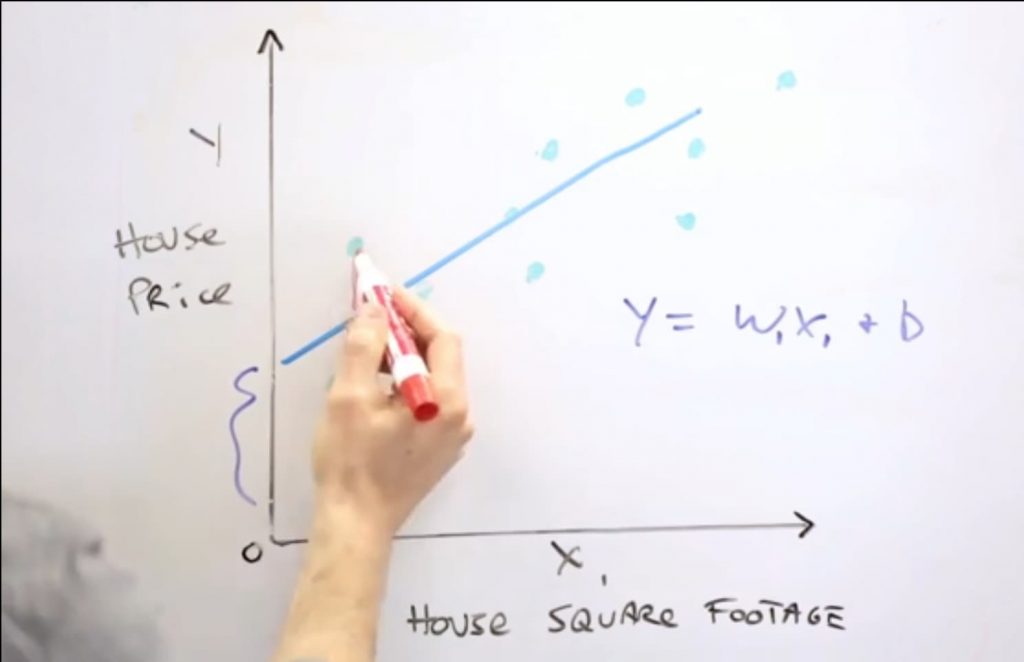 Se habla de w y no de m (como pendiente de la curva) por ser aprendizaje automático, los subíndices representan las posibles dimensiones.
Se habla de w y no de m (como pendiente de la curva) por ser aprendizaje automático, los subíndices representan las posibles dimensiones.
Es posible que haya múltiples dimensiones en el problema. Pongamos el caso de las casa: en base a metros, ubicación, antigüedad, etc. saldrán un espacio de precios.
El cerebro humano será incapaz de hacer los cálculos para considerar tantas variables pero un ordenador sí podrá hacerlo y más si tiene coprocesadores (ahora GPUs especializados) que le ayuden en tipos específicos de cálculos.
Una ejemplo interesante puede ser que un oncólogo (que siempre será necesario) se apoye en un sistema de aprendizaje automático donde se le ha alimentado con millones de mamografías que han prosperado en tumores malignos y otras que no. El sistema podría ser un asistente perfecto, sobre todo para, tal vez, incidir en pruebas cuando haya discordancias entre el resultado del modelo y el criterio propio del doctor (también con el riesgo de sobre-entrenamiento por muestras demasiado preliminares). Por tanto, uno de los elementos a tener en cuenta es precisamente eso, el error entre predicciones y realidades.
Podemos representar la función de pérdida de muchos modos. Uno de ellos es L2, que es el cuadrado de la pérdida.
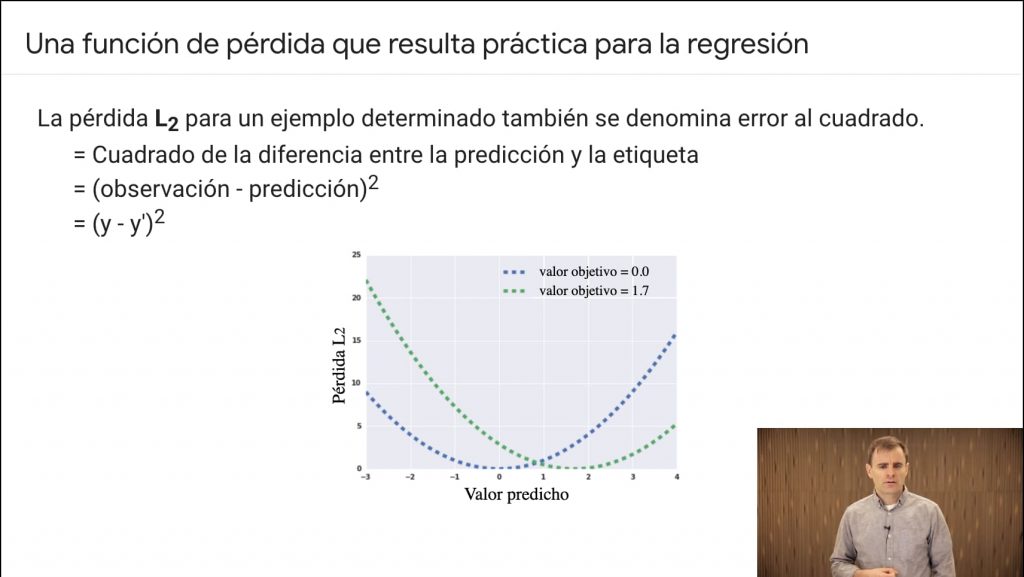
Aunque lo importante es representar la perdida completa (acumulada de todas las muestras) y no solo en un punto. Así que se representa el sumatorio del error.

Uno de los modelos más sencillos para empezar a hacer un entrenamiento y mejorar la función de pérdida es la regresión lineal.
El objetivo es reducir la perdida (y se puede utilizar un algoritmo de descenso de gradiente). Hay que elegir el conjunto de los parámetros que la minimicen. Hay que elegir una dirección en el espacio de parámetros sobre la que avanzar. Se establecen unos hiper-parámetros para que cada conjunto tenga una pérdida menor que el conjunto anterior.
Calculamos gradiente, la derivada de la función de pérdida respecto a los parámetros.

Se empieza en un punto donde se calcula el gradiente de función de pérdida para esos parámetros del modelo.
Se da un paso de gradiente para obtener una nueva pérdida hasta pasar el punto mínimo local, donde el gradiente es negativo y nos dice que hay que volver.
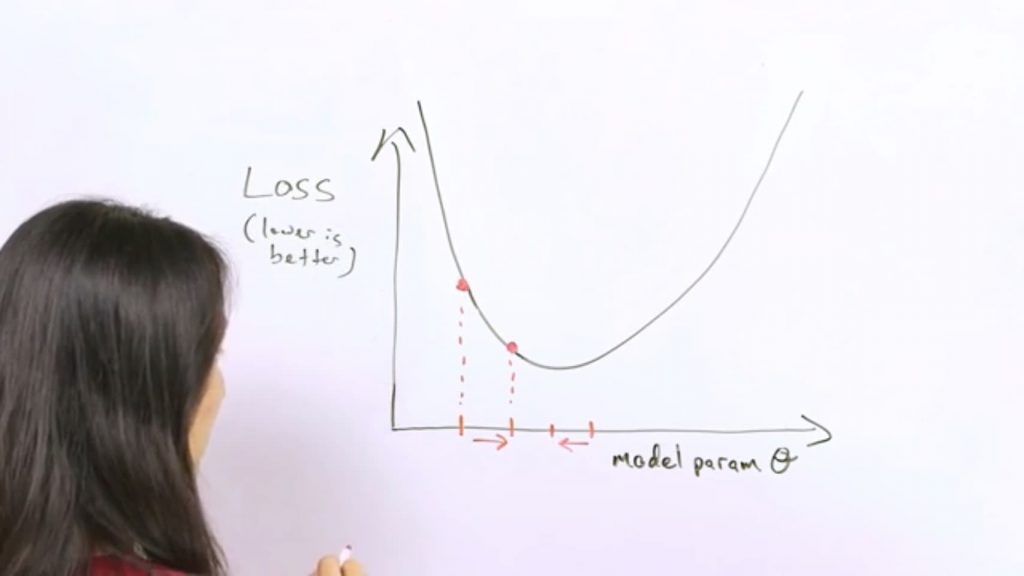
Lo grande que debe ser el incremento se determina por la tasa de aprendizaje, hiper-parámetro modificable.
Si el escalón es muy grande podemos pasar al otro extremo y que el error sea mayor que antes, lo que implica bajar la tasa de aprendizaje en una dimensión.
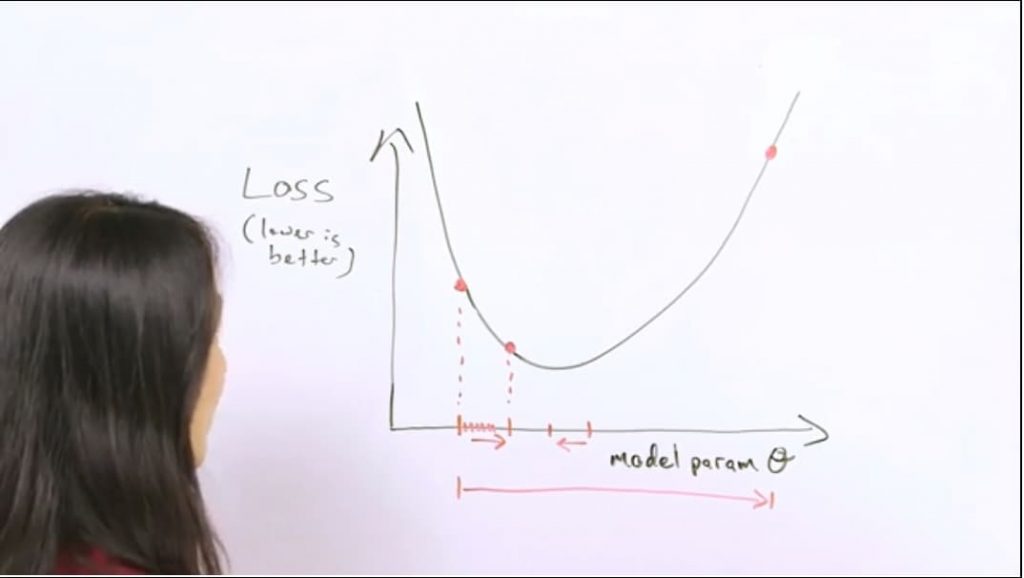
Hay problemas donde el problema no es convexo (un tazón), las redes neuronales son notoriamente no convexas y el punto de comienzo importa (se parece a una w o, peor todavía, a caja de huevos).
Por tanto, necesitamos conocer el problema, los datos que tenemos e indicar los hiper-parámetros para que el modelo sea eficiente.

Para dar los pasos se puede elegir toda la muestra, una parte reducida o una solución mixta (lotes, descenso de gradiente de minilote).

Un lote es la cantidad total de ejemplos que utilizas para calcular la gradiente en una sola iteración.
Es importante separar varios conjuntos de datos: los datos de entrenamiento, datos ampliados para verificación y datos de test.
El problema es que si utilizamos todos los datos disponibles para realizar el modelo, este se adaptará muy bien a ellos y la tasa de error sobre un dato del conjunto sería prácticamente cero.
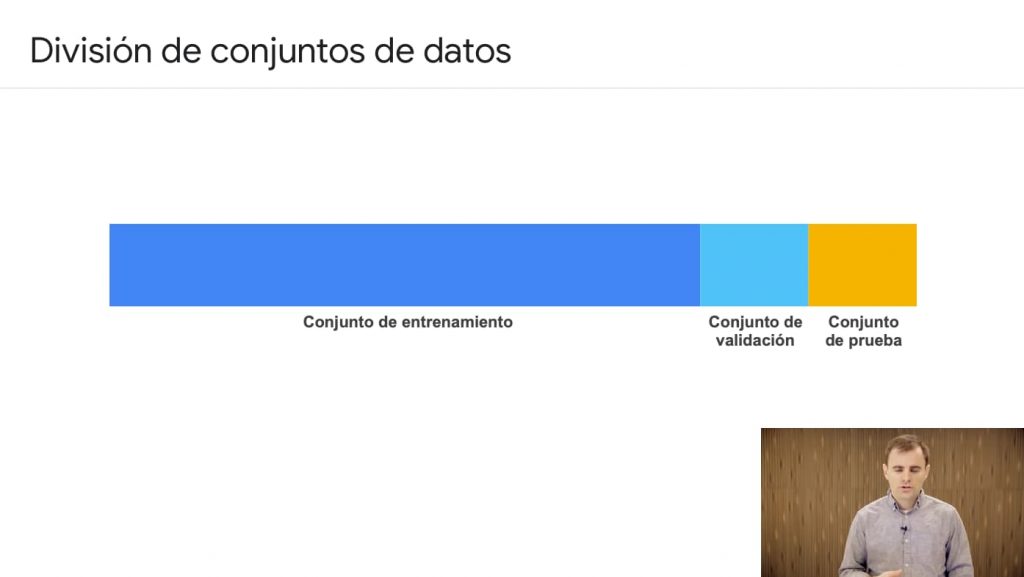
Incluso es conveniente tener un tercer conjunto de datos de validación para reservar los datos de prueba.
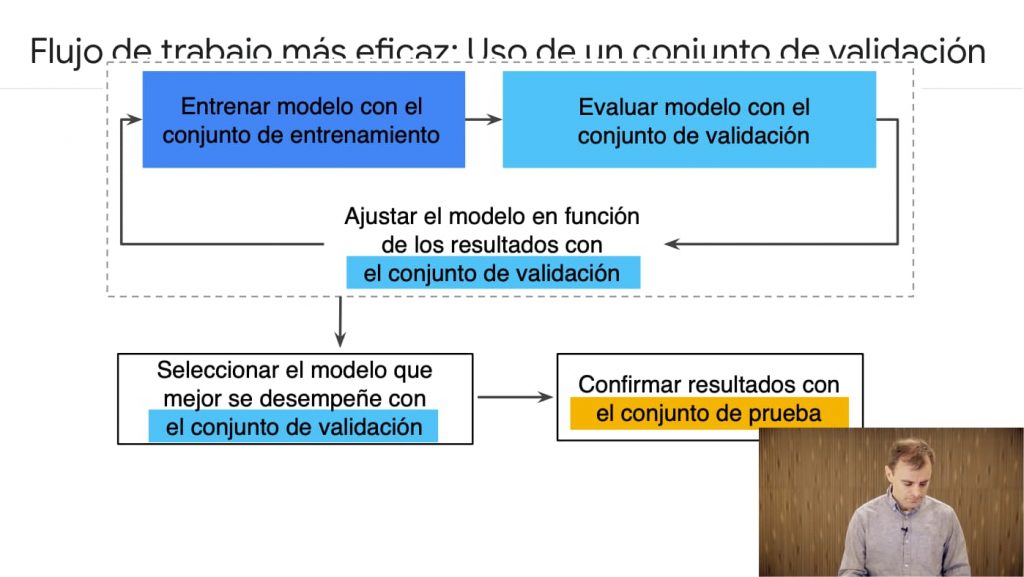
Por tanto es importante no contaminar el modelo inicial.
 Parece que la primera parte del curso es bastante interesante y nos ayuda a entender cómo funciona el aprendizaje a automático. Os invito, antes de seguir a consultar el glosario para ver el conjunto de términos disponibles y marcar aquellos que ya vais entendiendo y aquellos que no.
Parece que la primera parte del curso es bastante interesante y nos ayuda a entender cómo funciona el aprendizaje a automático. Os invito, antes de seguir a consultar el glosario para ver el conjunto de términos disponibles y marcar aquellos que ya vais entendiendo y aquellos que no.
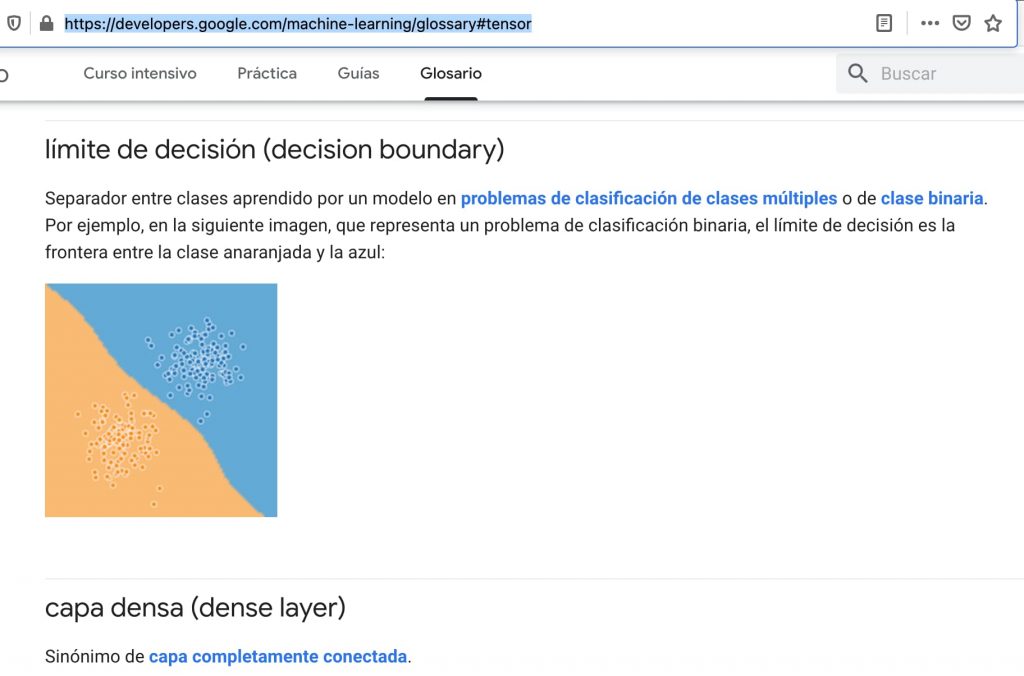
Cuando veas en ejemplos de código parámetros de configuración busca en el glosario, que puede ser muy útil. Por ejemplo te ayudará a entender el significado de softmax.

Uno de los videos que más me ha gustado para entender cómo funciona por dentro el motor del aprendizaje automático ha sido este de Luis Serrano.
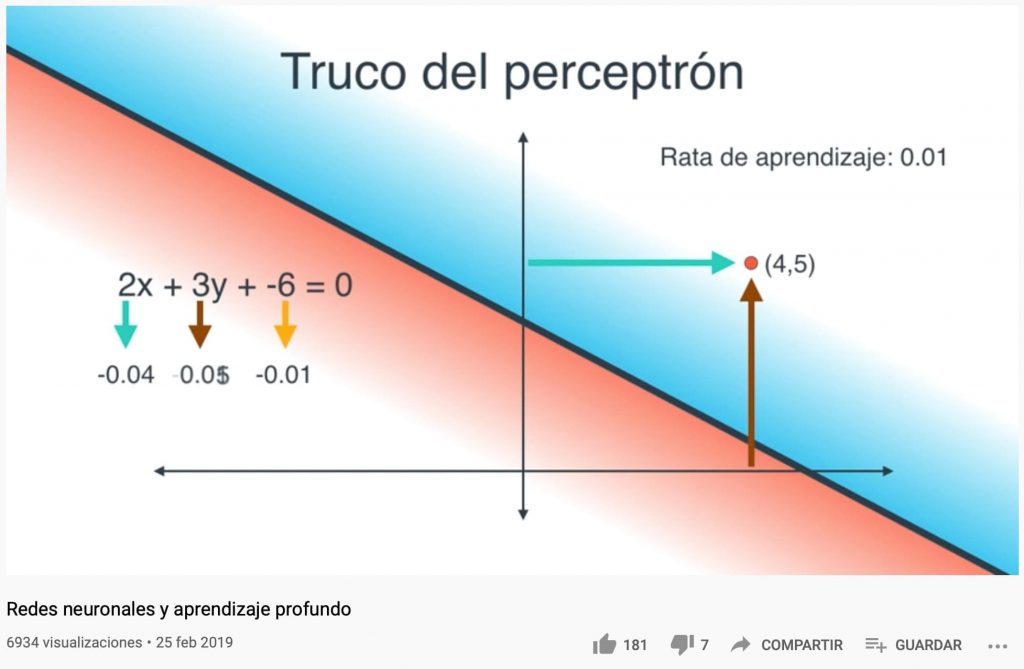
Sobre todo es interesante ver la relación que hay entre las capas de entrada, las de salida y las capas ocultas y cómo se consiguen adaptaciones al modelo.
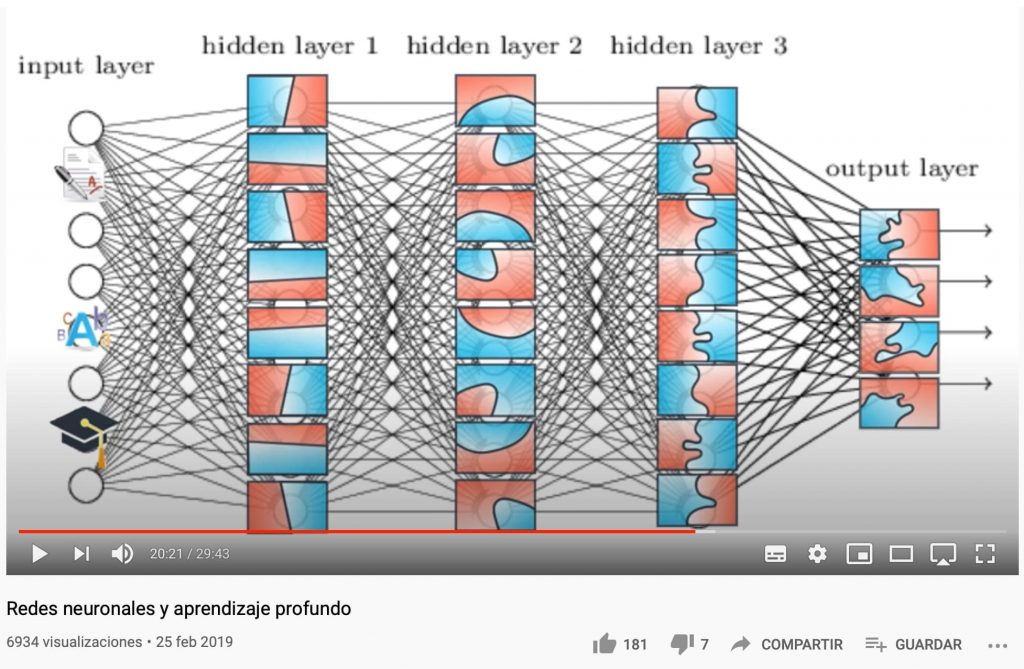
Hay veces que los problemas son no lineales por lo que se pueden crear atributos sintéticos o compuestos, como el producto de dos atributos (ver este vídeo).
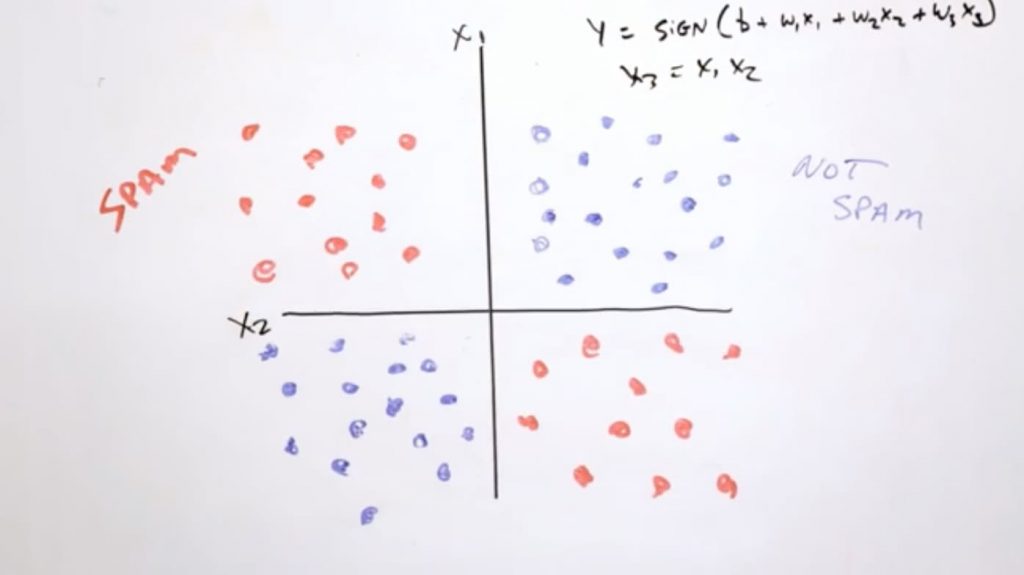
Los datos realmente, no suelen venir muy limpios. Siempre hará falta realizar una “ingeniería de atributos” que es lo que se lleva el 75% del tiempo en el aprendizaje automático.
Es importante saber los datos con los que contamos y usar una buenas prácticas para saber si los datos son útiles o no. Podemos, por ejemplo, tener la antigüedad de una casa como un valor en microsegundos parece absurdo, tendría mas sentido representar el año de construcción.

Parece lógico representar visualmente los datos, como histogramas, para ver lo que nos aporta. De modo que se puede discretizar los valores.
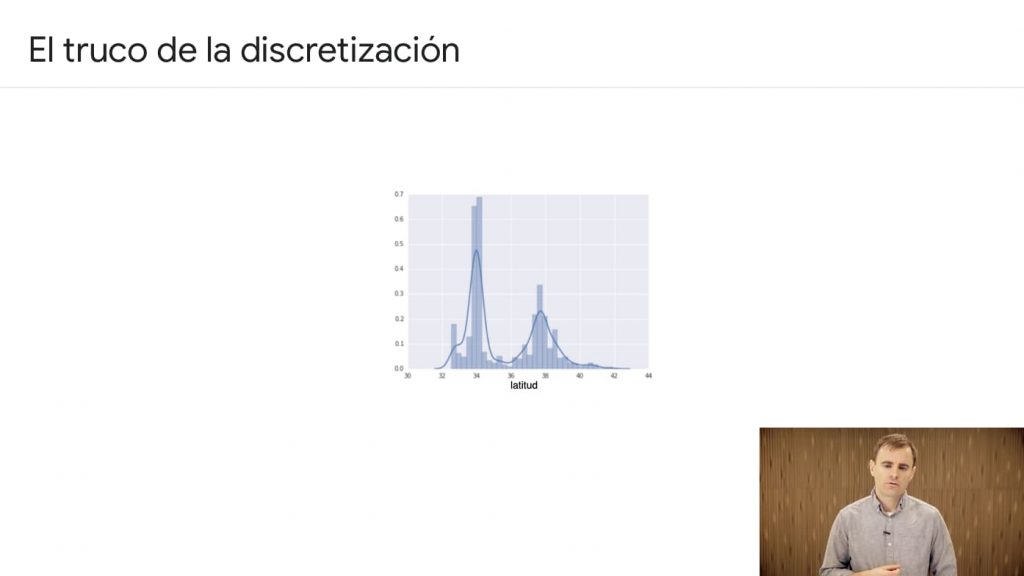
Por ejemplo, si vivimos en Torrejón de Ardoz, mi pueblo, no tiene sentido representar la calle sino el barrio o área.
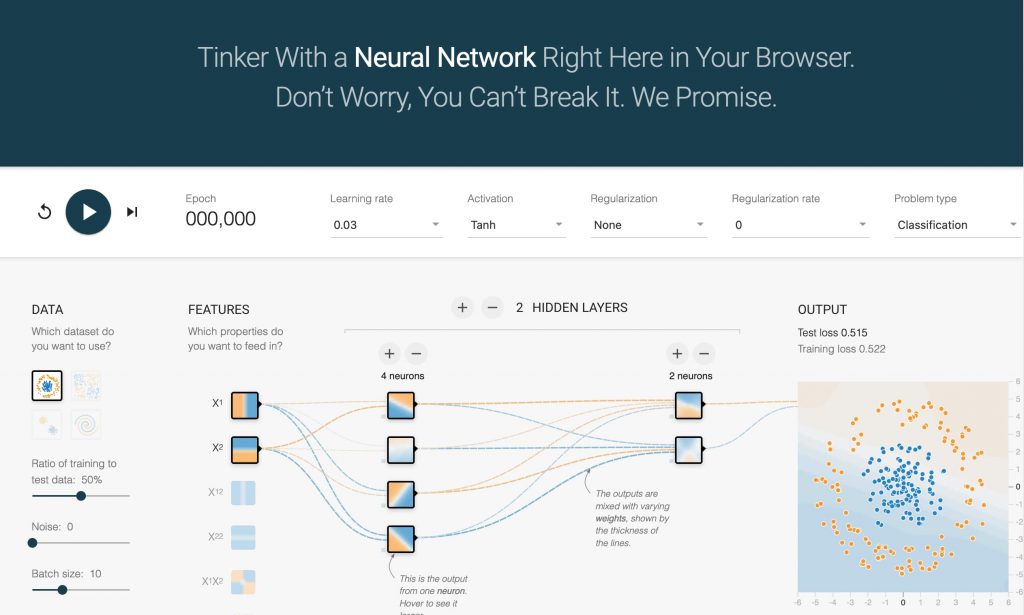
Una vez visto, podemos entender mejor el ejemplo de playground.tensorflow.org y jugar para comprender cómo mejorar la predicción en base al la tasa de aprendizaje, número de neuronas, número de capas ocultas, etc.
Bueno, está yo creo que bien para un tutorial, seguiremos con la teoría y la práctica, pero ya tenemos un universo de conceptos suficiente.

