

0. Índice de contenidos.
- Introducción.
- Entorno.
- Creación API Key.
- Creación base de datos.
- Instalación del plugin en DBeaver.
- Consulta de datos.
6.1 Consultas sencillas.
6.2 Consultas de dificultad intermedia.
6.3 Consulta más compleja. - Debug consultas a ChatGPT.
- Conclusiones.
1. Introducción
En nuestro anterior tutorial dedicado a investigar las posibilidades que nos brinda ChatGPT a la hora de trabajar con bases de datos, habíamos visto que nos podía facilitar enormemente la creación de consultas SQL. Para ello era necesario darle el contexto del modelo de datos con el que ibamos a trabajar y partir de ahí ya podíamos comenzar a explotar los datos.
En este tutorial vamos integrar el plugin de ChatGPT que la gente de DBeaver ha desarrollado para integrarlo en su producto .
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 13′ (Apple M1 Pro, 32GB DDR4).
- Sistema Operativo: Mac OS Ventura 13.3.1
3. Creación API Key
En primer lugar necesitamos crear un API Key para poder consumir los servicios de ChatGPT, para ello nos debemos loguear con nuestra cuenta de OpenAI y en el apartado User / API Keys crear una nueva clave https://platform.openai.com/account/api-keys. Recomendamos crear claves distintas para cada servicio que necesite acceder al API de ChatGPT, de esta forma podemos gestionarlas de forma independiente y revocar una clave sin afectar al resto de servicios.
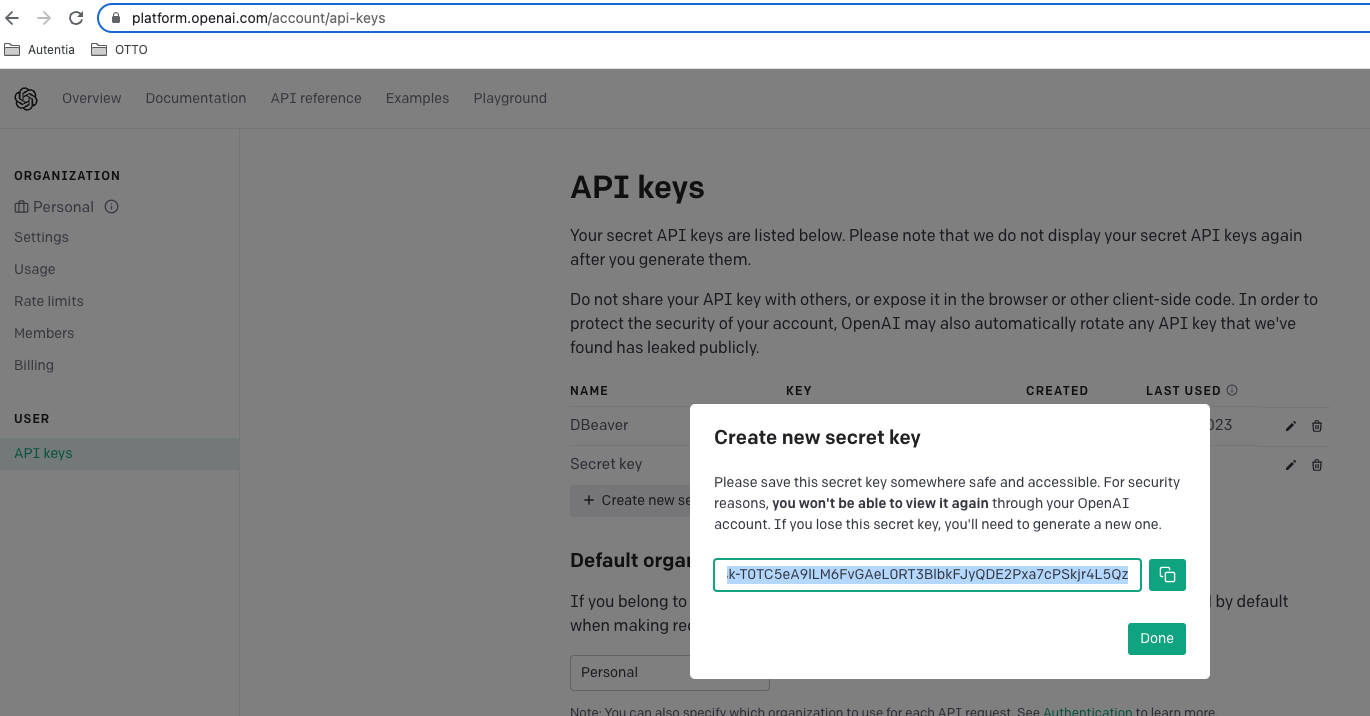
El uso de ChatGPT a través de su API no es gratuito, por lo que deberemos de tener saldo en nuestra cuenta. En el siguiente enlace podemos configurar nuestros medios de pago para realizar las recargas https://platform.openai.com/account/billing/overview
4. Creación base de datos
Repetiremos los pasos del tutorial anterior para levantar un contenedor Docker con una base de datos PostgreSQL, y a continuación ejecutaremos los scripts para crear las dos tablas con las que vamos a realizar los ejemplos (person y vehicle) y el script para popularlas.
docker run --name postgres-ia-test -e POSTGRES_DB=ia-test -e POSTGRES_PASSWORD=pass -d -p5432:5432 postgres:15.2-alpine3.17CREATE SEQUENCE person_id_seq START 1;
CREATE TABLE person (
id INTEGER PRIMARY KEY DEFAULT nextval('person_id_seq'),
name TEXT NOT NULL,
surname TEXT,
nif TEXT NOT NULL,
city TEXT NOT NULL,
UNIQUE (nif)
);
CREATE INDEX person_id_idx ON person(id);
CREATE SEQUENCE vehicle_id_seq START 1;
CREATE TABLE vehicle (
id INTEGER PRIMARY KEY DEFAULT nextval('vehicle_id_seq'),
brand TEXT NOT NULL,
model TEXT NOT NULL,
year INTEGER NOT NULL,
color TEXT NOT NULL,
person_id INTEGER NOT NULL REFERENCES person(id) ON DELETE CASCADE
);
CREATE INDEX vehicle_person_id_idx ON vehicle(person_id);
CREATE INDEX vehicle_id_idx ON vehicle(id);
-- Insert 5 people
INSERT INTO person (name, surname, nif, city) VALUES
('John', 'Doe', '12345678A', 'New York'),
('Jane', 'Doe', '23456789B', 'London'),
('Bob', 'Smith', '34567890C', 'Paris'),
('Alice', 'Jones', '45678901D', 'Berlin'),
('Mike', 'Johnson', '56789012E', 'Tokyo');
-- Insert 25 vehicles, making sure each person has at least one vehicle
INSERT INTO vehicle (brand, model, year, color, person_id) VALUES
('Honda', 'Civic', 2010, 'Blue', 1),
('Toyota', 'Corolla', 2012, 'Red', 2),
('Ford', 'Mustang', 2018, 'Black', 3),
('Chevrolet', 'Camaro', 2016, 'Yellow', 4),
('BMW', 'M3', 2014, 'White', 5),
('Mercedes-Benz', 'S-Class', 2020, 'Silver', 1),
('Audi', 'A4', 2015, 'Gray', 2),
('Volkswagen', 'Golf', 2013, 'Green', 3),
('Nissan', 'Altima', 2011, 'Orange', 4),
('Subaru', 'Impreza', 2009, 'Purple', 5),
('Mazda', 'MX-5', 2017, 'Brown', 1),
('Hyundai', 'Sonata', 2019, 'Beige', 2),
('Kia', 'Optima', 2013, 'Bronze', 3),
('Volvo', 'XC90', 2016, 'Copper', 4),
('Tesla', 'Model S', 2021, 'Red', 5),
('Jeep', 'Wrangler', 2015, 'Green', 1),
('Porsche', '911', 2019, 'White', 2),
('Lamborghini', 'Aventador', 2018, 'Yellow', 3),
('Ferrari', '488', 2016, 'Black', 4),
('Bugatti', 'Chiron', 2020, 'Blue', 5),
('Rolls-Royce', 'Phantom', 2017, 'Silver', 1),
('Bentley', 'Continental GT', 2015, 'Brown', 2),
('Maserati', 'Quattroporte', 2014, 'Gray', 3),
('Aston Martin', 'DB11', 2018, 'Purple', 4),
('McLaren', '720S', 2021, 'Orange', 5);
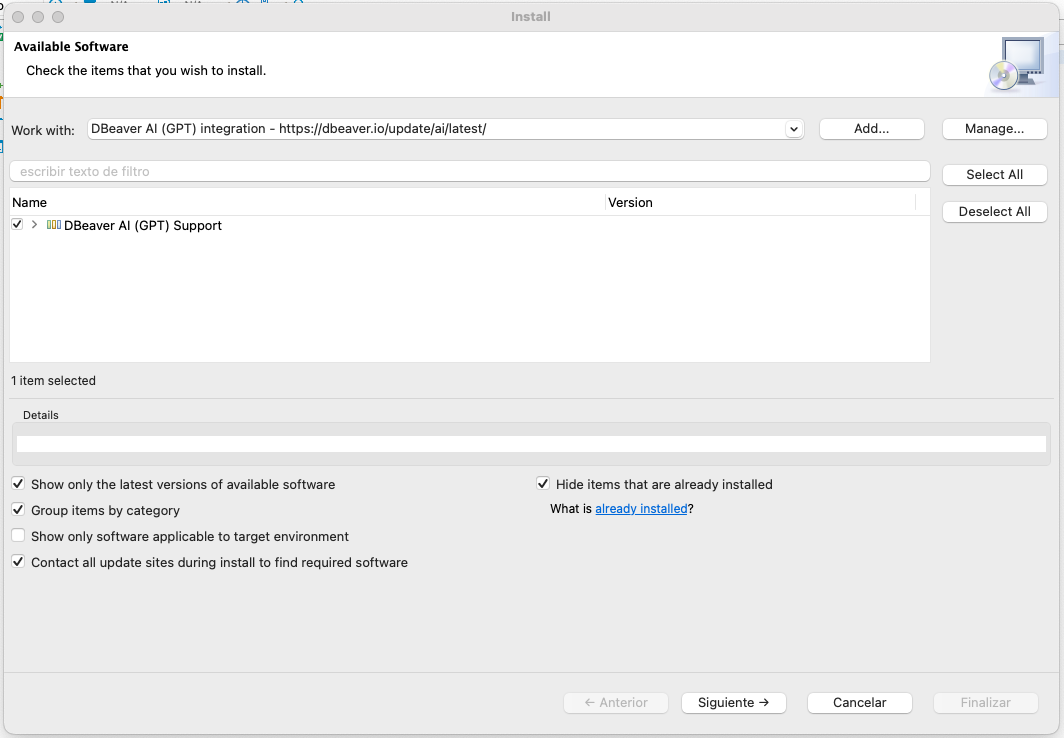
5. Instalación del plugin en DBeaver
DBeaver trabaja con un sistema de plugins similar al de Eclipse, en este caso instalaremos el plugin DBeaver AI (GPT) integration a través de la opción Help / Install new software
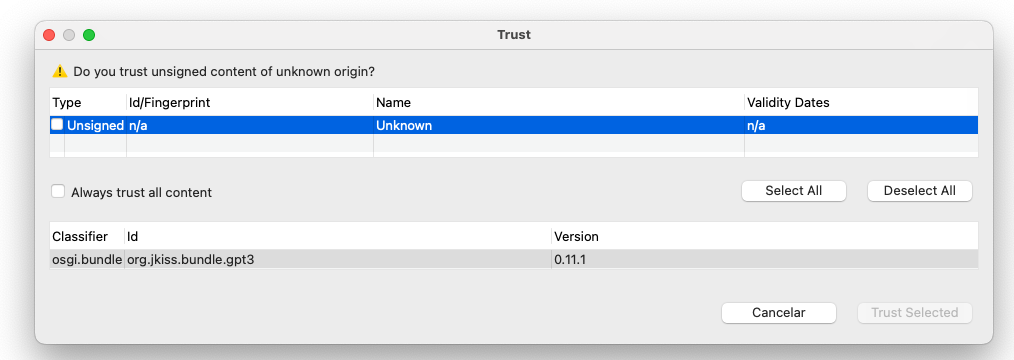
El plugin viene sin firmar y debemos confiar en él para poder instalarlo.
Ya estamos en situación de comenzar a utilizar ChatGPT desde DBeaver, en el editor de consultas SQL tendremos un nuevo icono disponible:
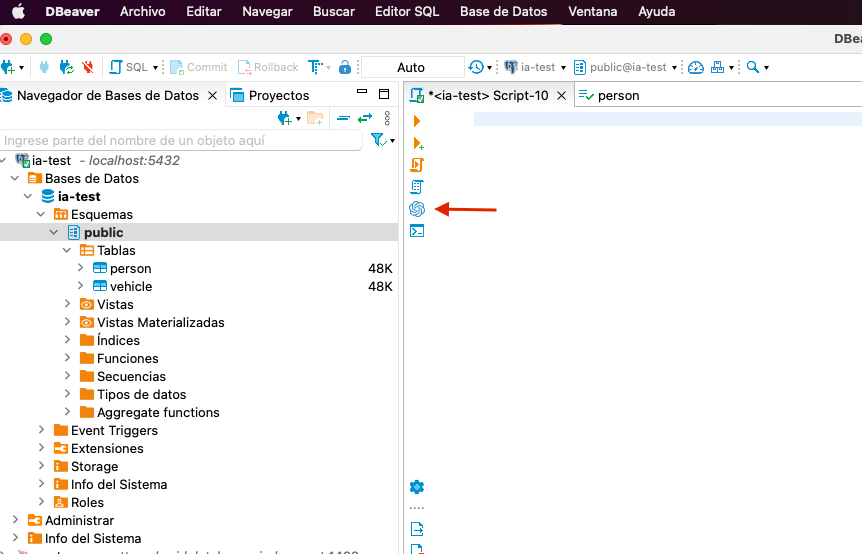
Antes de comenzar a utilizarlo debemos configurarlo, pulsaremos en el nuevo icono para interactuar con ChatGPT y nos aparece una ventana modal donde debemos pinchar en la rueda de configuración para irnos a nueva nueva modal donde configuramos el plugin.
Establecemos el API Token generado en el punto anterior.
En modelo seleccionamos gpt-3.5-turbo (el recomendado para generar SQL) y configuramos una temperatura en torno a 0.7.
A mayor temperatura más creativo es ChatGPT a la hora de interpretar los datos de entrada, a menor temperatura más rígido es, y necesita una definición de tablas mucho más precisa.
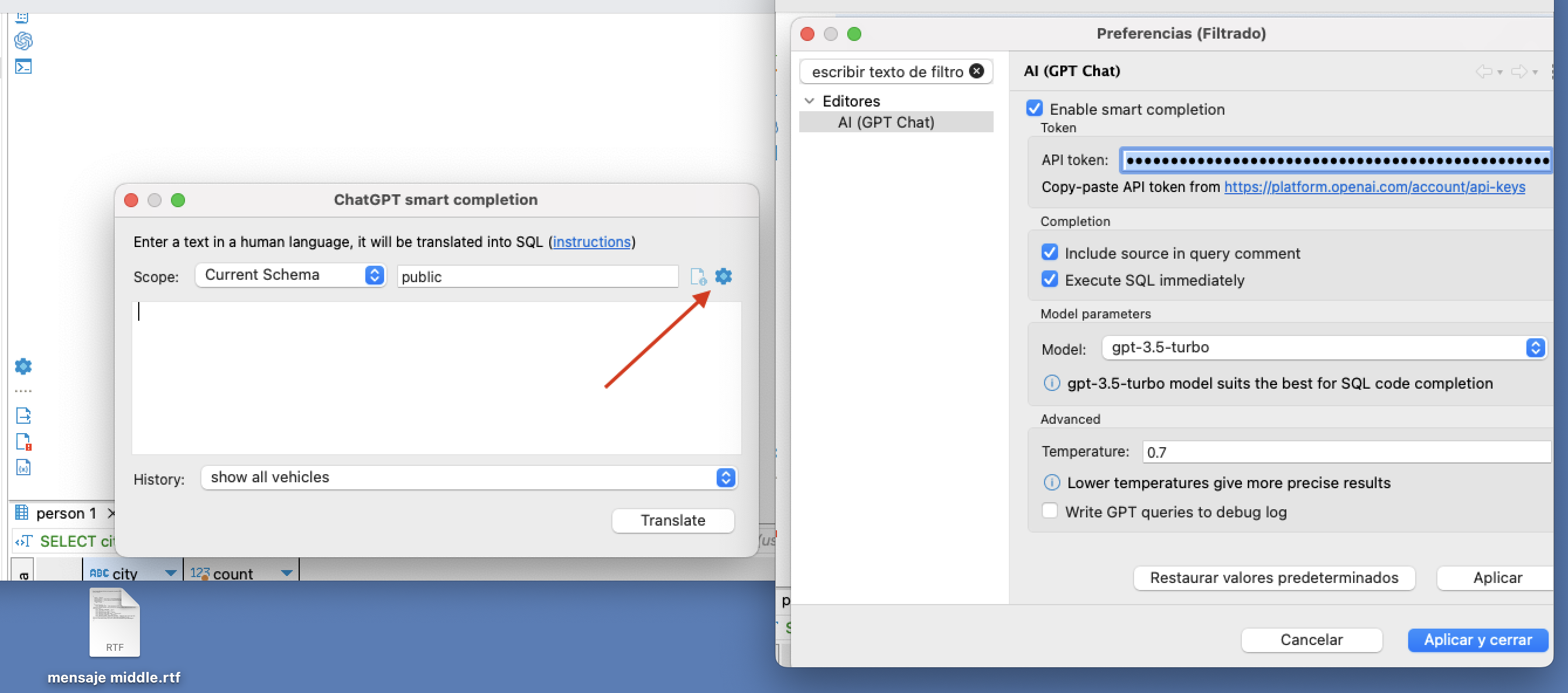
En nuestro caso activamos los dos checks del apartado Completion en la configuración del plugin:
- Ejecutar la consulta SQL una vez sea generada
- Mostrar como comentario en la consulta generada el texto en lenguaje natural con el que solicitamos a ChatGPT que nos genere la consulta
6. Consulta de datos
El plugin para DBeaver ofrece varias opciones de configuración a nivel de scope para definir el origen de datos, en nuestro caso el que mejor funciona y mejor contexto envía a ChatGPT es Current Schema y seleccionar public que es el esquema con el que trabajamos.
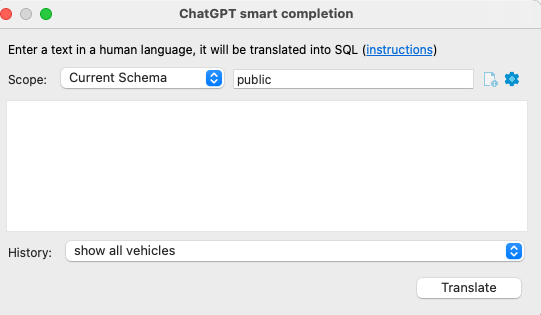
Para realizar las consultas a base de datos vamos a utilizar el mismo juego de datos del tutorial anterior y le pediremos a ChatGPT que genere las mismas consultas con el fin de comparar resultados. En cada SQL generada mostramos como comentario el texto en lenguaje natural con el que solicitamos a ChatGPT que nos genere la consulta.
6.1 Consultas sencillas
Le pedimos las consultas para obtener todas las personas y vehículos ordenados por atributos:
-- show all people ordered by name and surname
SELECT id, name, surname, nif, city
FROM person
ORDER BY name, surname;
-- show all vehicles ordered by brand, model and color
SELECT *
FROM vehicle
ORDER BY brand, model, color;
Ambas consultas son generadas correctamente, como curiosidad en uno de los casos hace uso del comodín para devolver todos los campos y en otro detalla uno a uno los campos a obtener.
Ahora preguntaremos por el número de vehículos de cada color que hay en cada ciudad:
-- show me how many vehicles by color are in each city
SELECT person.city, vehicle.color, count(vehicle.id) AS num_vehicles
FROM public.person
INNER JOIN public.vehicle ON person.id = vehicle.person_id
GROUP BY person.city, vehicle.color;
La consulta que nos devuelve funciona correctamente. Curiosamente, en esta consulta hace uso del nombre del esquema para acceder a la tabla person, en las consultas anteriores no lo hacía.
6.2 Consultas de dificultad intermedia
Le preguntamos ahora por las ciudades que tienen algún vehículo blanco pero no tienen ningún vehículo negro a partir de 2018:
-- show me the cities that have white vehicles but haven't any black vehicle after 2018 year
SELECT DISTINCT city
FROM person
INNER JOIN vehicle ON person.id = vehicle.person_id
WHERE color = 'white'
AND city NOT IN (
SELECT DISTINCT city
FROM person
INNER JOIN vehicle ON person.id = vehicle.person_id
WHERE color = 'black'
AND year > 2018
);
De nuevo la consulta generada es correcta, pero si comparamos con la obtenida en el tutorial anterior preguntando a ChatGPT directamente vemos que es distinta. No tiene mayor importancia, pero nos plantea la duda de por qué genera distintos resultados ante el mismo input:
SELECT DISTINCT p.city
FROM person p
INNER JOIN vehicle v1 ON p.id = v1.person_id AND v1.color = 'white'
LEFT JOIN vehicle v2 ON p.id = v2.person_id AND v2.color = 'black' AND v2.year > 2018
WHERE v2.person_id IS NULL;
Vamos un paso más allá y le pedimos el número de vehículos posteriores a 2015 por ciudad y color, y para cada registro conocer el año más antiguo de un vehículo de ese color en cualquier ciudad:
-- show me how many vehicles of each color newer than 2015 are in each city, and for each city and color show older year of any vehicle with this color
SELECT city, color, COUNT(*) as vehicle_count, MAX(year) as oldest_vehicle_year
FROM vehicle
JOIN person ON vehicle.person_id = person.id
WHERE year > 2015
GROUP BY city, color;
En este caso la consulta no es correcta, por un lado está obteniendo el máximo del año cuando debe buscar el año más antiguo y por otro está restringiendo la consulta del año a los resultados filtrados (year > 2015) y agrupados (por ciudad y color). Realizamos varios intentos formulando la petición de diversos modos, pero en ninguno de ellos ha sido capaz de generar la consulta correcta, algo que sí había hecho ChatGPT al consultarle preguntarle a través de prompt. Esto nos hace pensar que el plugin de DBeaver no envía suficiente contexto al API de ChatGPT. La consulta correcta generada en el tutorial anterior es:
SELECT p.city, v.color, COUNT(*) AS num_vehicles, MIN(v2.year) AS oldest_vehicle
FROM person p
INNER JOIN vehicle v ON p.id = v.person_id
LEFT JOIN vehicle v2 ON v.color = v2.color
WHERE v.year > 2015 AND v2.year > 0
GROUP BY p.city, v.color;
6.3 Consulta más compleja
Por último vamos a pedirle que nos genere una consulta más compleja donde queremos obtener por cada año entre el más antiguo y moderno de los años de los vehículos, el número de vehículos agrupados por color que existen en cada ciudad, excluyendo aquellas ciudades que no tengan vehículos para ese año.
-- show me for every year between older and newer of any vehicle, how many vehicles are there in every city with its colors, excluding cities without data
SELECT vehicle.year, vehicle.color, person.city, COUNT(*)
FROM vehicle
INNER JOIN person ON vehicle.person_id = person.id
WHERE person.city IS NOT NULL
GROUP BY vehicle.year, vehicle.color, person.city
ORDER BY vehicle.year, person.city, COUNT(*) DESC;
Esta consulta es correcta, pero si la comparamos con la del tutorial anterior tiene múltiples diferencias. Al trabajar con el prompt parece que hace un parseo del texto de entrada y lo interpreta de forma lineal, en primer lugar obtiene los años entre el más antiguo y más moderno, a continuación obtiene el número de vehículos por ciudad, año y color y finalmente cruza todos esos datos:
WITH years AS (
SELECT generate_series(
(SELECT MIN(year) FROM vehicle),
(SELECT MAX(year) FROM vehicle)
) AS year
),
city_years AS (
SELECT p.city, v.year, v.color, COUNT(*) AS num_vehicles
FROM person p
INNER JOIN vehicle v ON p.id = v.person_id
GROUP BY p.city, v.year, v.color
),
city_years_filled AS (
SELECT y.year, c.city, COALESCE(cy.color, '') AS color, COALESCE(cy.num_vehicles, 0) AS num_vehicles
FROM years y
CROSS JOIN (SELECT DISTINCT city FROM person) c
LEFT JOIN city_years cy ON y.year = cy.year AND c.city = cy.city
WHERE cy.num_vehicles IS NOT NULL
)
SELECT year, city, color, num_vehicles
FROM city_years_filled
ORDER BY year, city, color;
7. Debug consultas a ChatGPT
El plugin de ChatGPT para DBeaver permite activar un modo debug para generar log con las llamadas que se realizan al API de ChatGPT. Activarlo es tan sencillo como marcar la casilla Write GPT queries to debug log en la pantalla de configuración del plugin.
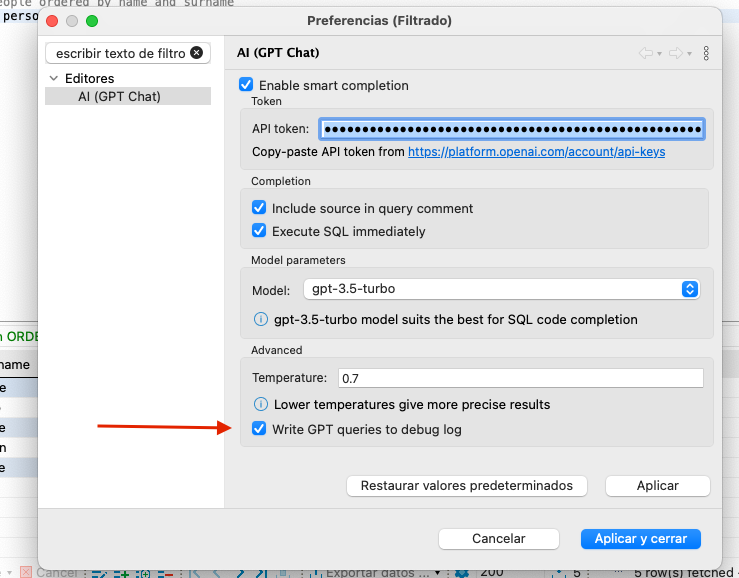
Para acceder a los ficheros de logs debemos acceder a las siguientes rutas en función de nuestro sistema operativo, tal como se indica en https://dbeaver.com/docs/wiki/Log-files/:
- En Windows %APPDATA%DBeaverDataworkspace6.metadata
- En Linux $XDG_DATA_HOME/DBeaverData/workspace6/.metadata
- En MacOS open path ~/Library/DBeaverData/workspace6/.metadata
Visualizamos el contenido del fichero dbeaver-debug.log
> cat dbeaver-debug.log
> Start DBeaver AI Model [org.jkiss.dbeaver.model.ai 1.0.7.202305071722]
> Start DBeaver SQL editor AI integration [org.jkiss.dbeaver.ui.editors.sql.ai 1.0.7.202305071722]
2023-05-18 17:51:46.419 - Load objects from information_schema
2023-05-18 17:51:46.420 - Load TableCache
2023-05-18 17:51:46.453 - Load objects from pg_catalog
2023-05-18 17:51:46.453 - Load TableCache
2023-05-18 17:51:46.468 - Load objects from public
2023-05-18 17:51:46.468 - Load TableCache
2023-05-18 17:51:46.623 - Chat GPT request:
### PostgreSQL SQL tables, with their properties:
#
# person(id,name,surname,nif,city);
# vehicle(id,brand,model,year,color,person_id);
#
# Current schema is public
#
###show all people ordered by name and surname
SELECT
autentia@MacBook-Pro-de-Diego-Gonzalez .metadata %
Vemos que el plugin diversa información al API de ChatGPT:
- PostgreSQL (es el motor de base de datos que ChatGPT debe utilizar)
- Nombre de las tablas existente en el esquema y para cada una de ellas el nombre de sus campos, pero NO envía información alguna sobre foreigns, índices, tipos de datos… En la versión de pago de DBeaver sí permite configurar el envío de estos datos.
- Nombre del esquema de trabajo
- Texto con el que solicitamos la consulta
En nuestro tutorial donde trabajabamos directamente con el promt de ChatGPT le dábamos como contexto un DDL con la definición completa de las tablas de base de datos, el plugin de DBeaver envía datos con mucha menos definición, de ahí vienen las diferencias que hemos visto a la hora de generar determinadas consultas en los ejemplos anterior y la imposibilidad de generar correctamente una de ellas.
8. Conclusiones
Esta primera versión del plugin no es tan eficiente como el uso de ChatGPT directamente a través de su promt, pero puede ser de gran ayuda para la generación de consultas, especialmente para gente con conocimientos técnicos. A la vista de las pruebas realizadas, las consultas devueltas por el plugin no deben ser tomadas como correctas al 100%, sino que es necesario que alguien con conocimientos de SQL las revise y las adapte si es necesario (obtenemos una mejora de productividad al disponer de una consulta de partida).
Entendemos que el uso del API de ChatGPT tiene limitaciones en cuanto al tamaño del input, de ahí que la información que envía el plugin no sea un DDL de la base de datos, penalizando la efectividad de la herramienta. Imaginamos que a medida que ChatGPT evolucione, estos detalles mejoren y la experiencia de usuario sea más satisfactoria.
Debemos recordar que el uso de este plugin no es gratuito y necesitamos de saldo en nuestra cuenta de OpenAI, por las pruebas realizadas el consumo es mínimo, pero es un detalle a tener en cuenta si pretendemos integrar el plugin en el día a día de un departamento de desarrollo.

