

0. Índice de contenidos.
- Introducción
- Entorno
- Creación de base de datos
- Creación de tablas.
- Carga de datos.
- Consulta de datos.
6.1 Consultas sencillas.
6.2 Consultas de dificultad intermedia.
6.3 Consultas más complejas.
6.3.1 Consulta sobre propiedades multivalor fechadas. - Conclusiones.
1. Introducción
En los últimos meses la palabra IA y, especialmente ChatGPT se encuentra en boca de todo el mundo, desde apocalípticos que piensan que provocará el fin del mundo con máquinas dominando a humanos, hasta gente que lo ve como una oportunidad para mejorar la productividad en sus trabajos, pasando por equidistantes que lo ven como la enésima moda pasajera.
En este tutorial vamos a intentar sacar provecho de las oportunidades que nos ofrece a día de hoy ChatGPT para facilitarnos esos trabajos en ocasiones repetitivos y tediosos de escritura de SQLs.
Para utilizar ChatGPT debemos tener cuenta en (https://openai.com/). En caso de no tenerla, nos podemos registrar desde la pagina principal de OpenAI y utilizar cualquiera de los mecanismos de login rápido que ofrecen.
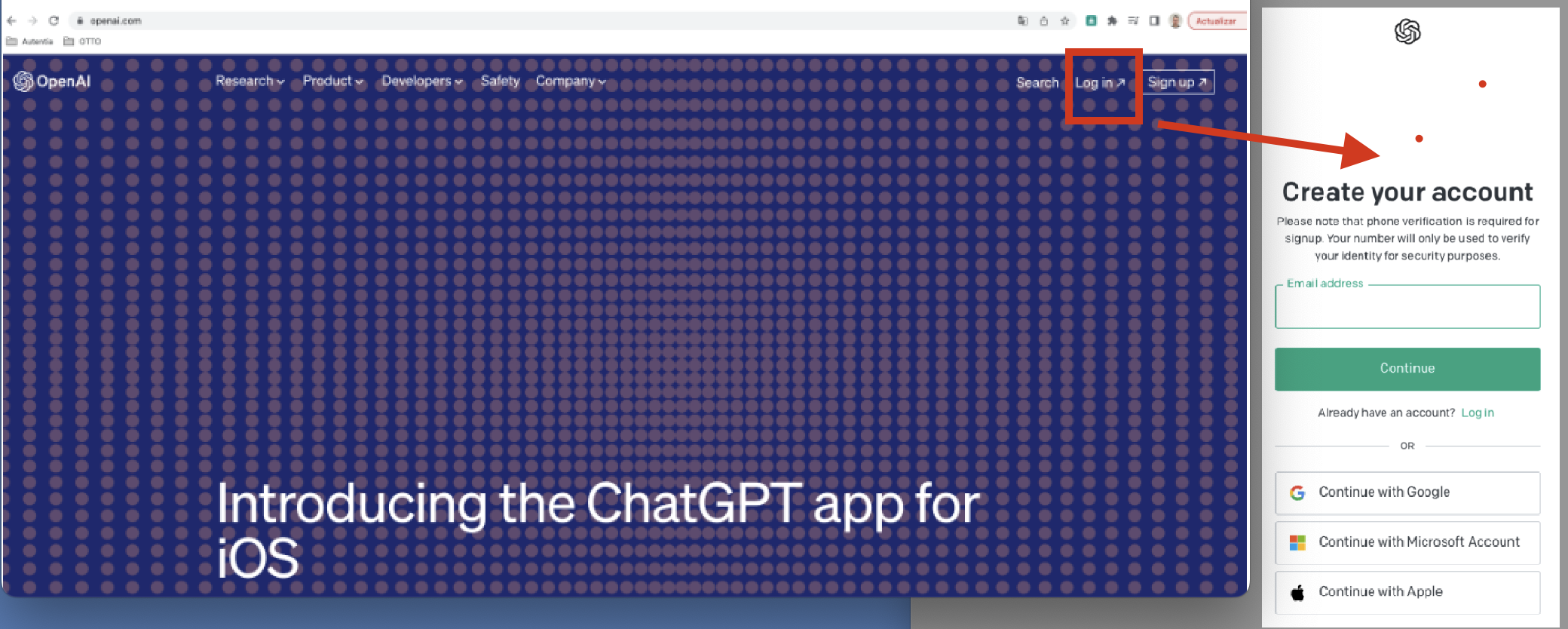
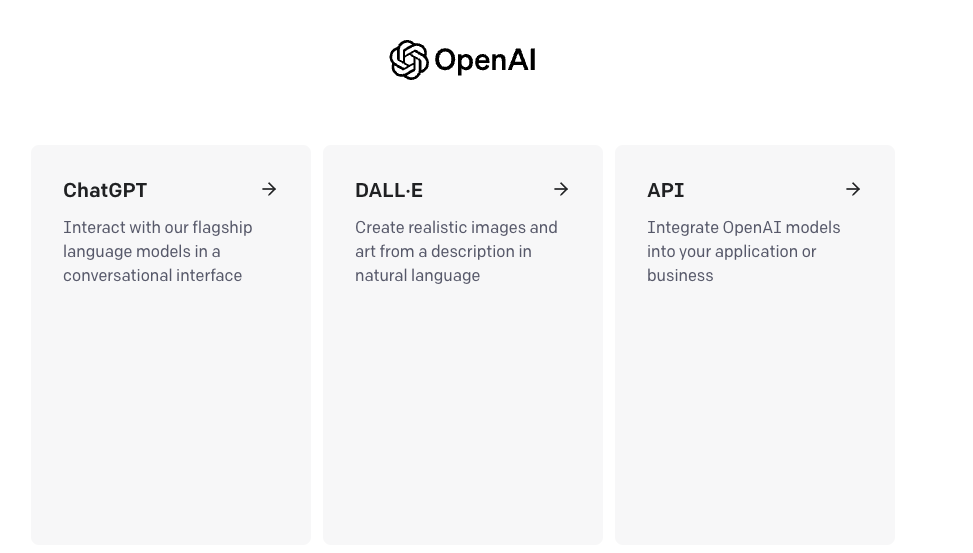
Una vez estamos logueados, debemos indicar con qué modelo queremos interactuar, en nuestro caso con ChatGPT
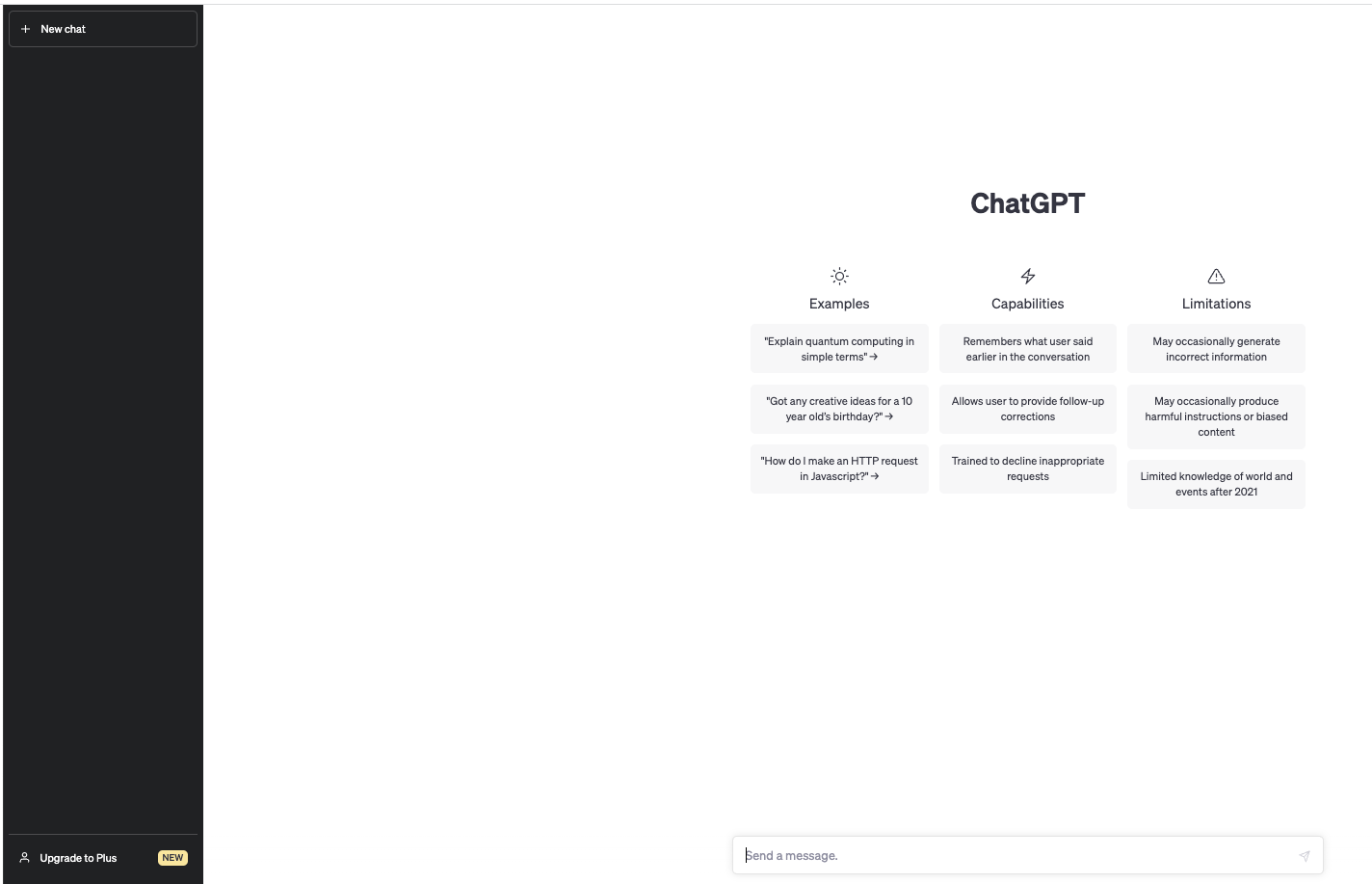
Somos redirigidos a una pantalla donde tenemos un prompt disponible para comenzar a realizarle preguntas.
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 13′ (Apple M1 Pro, 32GB DDR4).
- Sistema Operativo: Mac OS Ventura 13.3.1
3. Creación base de datos
Tomaremos como base de datos para este tutorial PostgreSQL 15, levantamos un contenedor Docker con una base de datos llamada ia-test y password pass y nos conectamos a ella.
[crayon-65438d30c42d8785442749/]
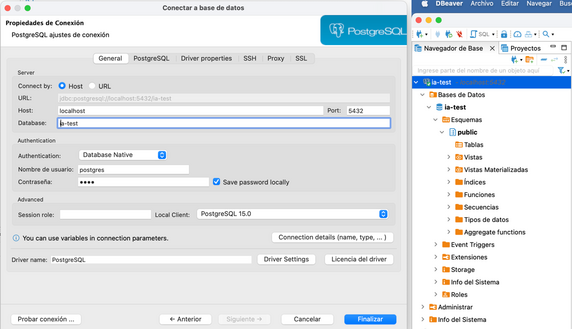
E informamos a ChatGPT que ésta será la base de datos que debe utilizar.
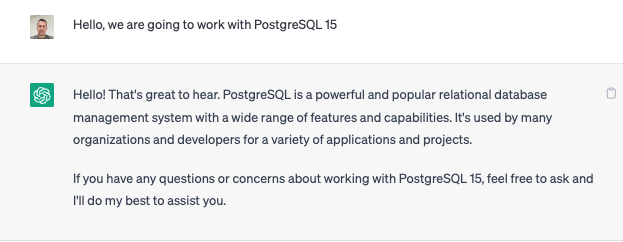
4. Creación de tablas
Vamos a comenzar con un ejemplo sencillo, le indicamos que queremos persistir información acerca de personas y sus vehículos.
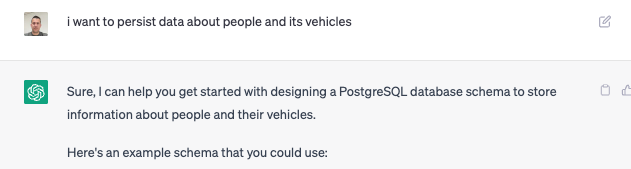
[crayon-65438d30c42eb151245452/]
Lo primero que nos llama la atención es que toma decisiones sobre los campos que debe de tener cada tabla, su tipo y su obligatoriedad, vamos a detallarle qué campos queremos en cada tabla y por otro lado darle unas premisas que debe de tener siempre en cuenta (id generados mediante secuencia y creación de índice en todas las foregins)
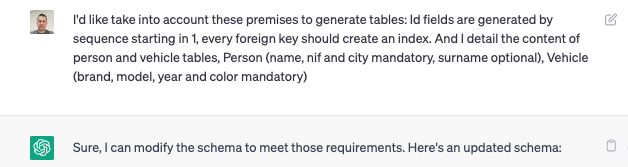
[crayon-65438d30c42f0104831493/]
Tras indicarle cómo queremos que nos genere las tablas, ChatGPT nos genera un nuevo script teniendo en cuenta nuestras premisas. Cabe destacar que es capaz de inferir que el campo nif debe ser único.
También vemos que genera un índice adicional para las PKs que no es necesario, en este caso deberíamos indicarle que esta práctica no es necesaria para que la tenga en cuenta para futuras creaciones.
Ejecutamos los scripts que nos ha generado en nuestra base de datos local con el fin de comenzar a explotar información.
5. Carga de de datos
Con las tablas ya creadas, le vamos a pedir que nos genere un script para popular ambas tablas, con 5 personas y 25 vehículos.
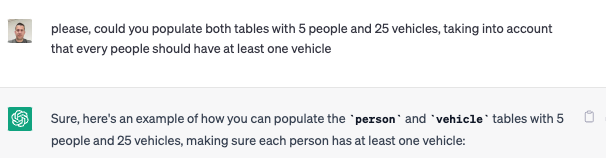
[crayon-65438d30c42f5542722801/]
Como curiosidad, es capaz de detectar el formato de un NIF, pero los valores que genera no son válidos. Incluso si le indicamos una url donde puede generar valores de ejemplo continúa generando valores erróneos.
Este ejemplo es muy sencillo, pero abre la puerta a indicarle a ChatGPT cuál es nuestro modelo de datos a partir de un script de creación de tablas y pedirle que genere scripts para popular ciertas tablas de cara a lanzar tests de integración o construir juegos de datos para entornos de prueba. Cuanta más información le demos en el prompt, más podremos afinar la carga de datos y más tiempo nos ahorraremos escribiendo scripts.
6. Consulta de datos
Una vez que tenemos nuestras dos tablas con datos vamos a comenzar a generar consultas, desde las más sencillas hasta consultas más tediosas que requieren bastante esfuerzo y tiempo por nuestra parte.
6.1 Consultas sencillas
Consultas para obtener todas las personas y vehículos ordenadas por atributos, sin problema 😉
[crayon-65438d30c42fa670078291/]
Vamos a complicar la consulta para obtener cuántos vehículos existen de cada color en cada ciudad.

[crayon-65438d30c42ff758235052/]
6.2 Consultas de dificultad intermedia
Le preguntamos ahora por las ciudades que tienen algún vehículo blanco pero no tienen ningún vehículo negro a partir de 2018:
[crayon-65438d30c4302970302742/]
Vamos un paso más allá y queremos conocer el número de vehículos posteriores a 2015 por ciudad y color, y para cada registro conocer el año más antiguo de un vehículo de ese color en cualquier ciudad:
[crayon-65438d30c4306517928239/]
6.3 Consultas más complejas
Por último vamos a pedirle que nos muestre por cada año entre el más antiguo y moderno de los años de los vehículos, el numero de vehículos agrupados por color que existen en cada ciudad, excluyendo aquellas ciudades que no tengan vehículos para ese año. Esta ya es una consulta que nos llevaría un buen rato escribirla y aquí la tenemos de forma inmediata:

[crayon-65438d30c430a425222049/]
6.3.1 Consulta sobre propiedades multivalor fechadas
Vamos a plantearle una nueva situación para explotar propiedades multivalor fechadas, hemos creado una tabla en la que almacenar las certificaciones asociadas a las personas de la tabla person de los ejemplos anteriores.
[crayon-65438d30c430e647732548/]
El campo start_day indica la fecha a partir de la cual se asocia la certificación a la persona, y el campo active indica si la certificación está activa o no, por ejemplo, pensemos que la persona con id 1 se certifica el 1 de enero de 2020 en Java 1.8, siendo una certificación que se debe renovar anualmente y no lo hace hasta el 3 de marzo de 2023, se representaría de la siguiente forma:
[crayon-65438d30c4316913454142/]
Le pedimos que nos genere una consulta para obtener las certificaciones activas para una persona a una fecha dada y el resultado no es el esperado, no es capaz de darse cuenta que tiene que quedarse con las certificaciones cuyo último cambio de estado anterior a la fecha dada sea al estado activo:

[crayon-65438d30c431a983005296/]
Le explicamos cómo funciona la tabla con un ejemplo y volvemos a solicitar que nos genere la consulta, en este caso sí lo hace correctamente
[crayon-65438d30c431e689213898/]
Este ejemplo demuestra que son necesarios ciertos conocimientos para validar el resultado devuelto por ChatGPT y pone de manifiesto la necesidad de definir buenos promts para obtener los resultados esperados. El rol de prompt engineering cada vez cobrará más protagonismo.
7. Conclusiones
Hemos visto cómo ChatGPT nos puede ahorrar tiempo y esfuerzo cómo desarrolladores a la hora de trabajar con base de datos, cuánto más claro y detallado sea el input más preciso será el resultado. Las posibilidades que aparecen son enormes:
- Generar todas las tablas del modelo de datos a partir de una definición funcional donde se encuentre detallada cada tabla con sus características.
- Obtener consultas para complicados informes a partir una definición en lenguaje natural.
- Construir juegos de datos en tiempo record con distintas casuísticas para cubrir todas las posibilidades en entornos de testing (integración, end to end, QA …)
Pero, ¿y qué ocurre con perfiles no técnicos? Aquí las ventajas son aún mayores, aparece la posibilidad de que una persona sin conocimiento de SQL pueda obtener datos y generar informes más o menos complejos, simplemente pidiéndole a ChatGPT que le genere las consultas SQL apropiadas dándole como input la definición del modelo de datos. ¿Cuántas llamadas y/o emails se ahorrarían entre Negocio y Desarrollo?
Podemos ir más allá y pensar en un plugin de ChatGPT para nuestro cliente de base de datos o IDE, que se conecte a la base de datos y no tengamos que darle input acerca del modelo de datos, simplemente pedirle consultas en lenguaje natural, ¿os animáis a desarrollarlo?

