

En este artículo aprenderemos sobre compilación a nativo con Quarkus, a mejorar nuestros test RestAssured extrayendo el response a un DTO, haremos una pequeña introducción al continuous testing en Quarkus y cómo hacer depuración remota.
Índice de contenidos
- 1. Continuación de servicios REST con Quarkus
- 2. Actualización. Method PUT
- 3. Borrado. Method DELETE
- 4. Obtener elemento. Method GET
- 5. Modo de desarrollador. Continuous Testing y web
- 6. Compilación a nativo
- 7. Conclusiones
- Enlaces y referencias
1. Continuación de servicios REST con Quarkus
En el artículo anterior hicimos el método POST, pero nos quedaban pendientes el resto de los verbos del API REST.
Habíamos empezado un diseño del proyecto mediante TDD. Enunciemos los test que debería pasar nuestro proyecto según el comportamiento que esperamos, y vayamos completándolos:
- cuando_POST_de_un_elemento_nuevo_entonces_lo_crea_y_OK_200()
- cuando_POST_de_un_elemento_que_ya_existe_entonces_no_lo_persiste_y_OK_201()
- cuando_POST_de_un_elemento_sin_symbol_entonces_error_400()
- cuando_PUT_de_un_elemento_nuevo_entonces_NO_lo_crea_y_ERROR_400()
- cuando_PUT_de_un_elemento_existente_entonces_lo_actualiza_y_OK_201()
- cuando_DELETE_de_un_elemento_existente_entonces_lo_borra_y_OK_200()
- cuando_DELETE_de_un_elemento_que_NO_existe_entonces_no_borro_nada_pero_OK_200()
- cuando_GET_de_un_simbolo_que_existe_entonces_devuelve_el_elemento_y_OK_200()
- cuando_GET_de_un_simbolo_que_NO_existe_entonces_ERROR_404()
Los que cubren el POST ya los tenemos hechos. Vayamos a por los siguientes.
2. Actualización. Method PUT
Si intentamos actualizar un elemento que no existe, debería dar error.
Lo primero es crear el payload del elemento. Como es nuevo, no existen tenemos que entrenar el findBySymbol() para que cuando lo busque no encuentre nada.
En esas condiciones podemos aseverar que el PUT de ese elemento nuevo devolverá un error 400 y que nunca se transformará el DTO en una entity.
@Test
void cuando_PUT_de_un_elemento_nuevo_entonces_NO_lo_crea_y_ERROR_400() {
ElementDto hydrogenDto = createHydrogen();
when(ElementEntity.findBySymbol("H")).thenReturn(null);
given()
.when()
.header("Content-Type", "application/json")
.body(hydrogenDto)
.put(BASE_PATH)
.then()
.statusCode(400);
verify(mapper,never()).toEntity(any());
}
Si corremos el test fallará por muchos motivos.
1. No estamos exponiendo el método PUT en el resource.
2. El resource no invoca a ningún método del service que haga la actualización en caso de ser necesaria.
Creemos estos métodos.
public class ElementResource {
[...]
@PUT
public Response update(@Valid ElementDto dto) {
return service.update(dto);
}
}
Y en el service:
public class ElementService {
[...]
public Response update(@Valid ElementDto dto) {
ElementEntity entity = ElementEntity.findBySymbol(dto.symbol);
return Response.status(400).build();
}
El return del service ya devuelve el statusCode 400. Realmente no usa para nada el findBySymbol(). Ya se deja ver, que en el siguiente test, si vamos a utilizarlo… Que es el caso en el que sí existe el elemento a actualizar. Pero no nos adelantemos. En el TDD hay que ir paso a paso. Corremos el test y ahora sí, ahora pasa.
Vamos a por el siguiente test:
@Test
void cuando_PUT_de_un_elemento_existente_entonces_lo_actualiza_y_OK_201() {
ElementDto hydrogenDto = createHydrogen();
ElementEntity hydrogenEntity = spyHydrogenEntity();
doNothing().when(hydrogenEntity).update();
when(ElementEntity.findBySymbol("H")).thenReturn(hydrogenEntity);
given()
.when()
.header("Content-Type", "application/json")
.body(hydrogenDto)
.put(BASE_PATH)
.then()
.statusCode(201);
verify(hydrogenEntity,times(1)).update();
}
El comportamiento debe ser el siguiente: cuando recibo un PUT con un payload con un elemento (dto), al buscar si existe encuentro un elemento (entity) y lo que hago es actualizar la entidad. Para ello me creo un spy de la entidad, entreno el findBySymbol() para que cuando busque por el symbol del dto, encuentre el spy. Y hago algunas aseveraciones: que el PUT devuelve un 201 y que se pasa una vez por el método update del spy. Parece un test bastante completo. Lo ejecutamos y como debe ser, falla. No devuelve un estatusCode 201. El método update() que hemos empezado a pergeñar antes se nos ha quedado cojo.
Ahora cuando busque el elemento que debe actualizar, si lo encuentra, debe actualizarlo con la información del dto, y devolver el response correspondiente.
public Response update(@Valid ElementDto dto) {
ElementEntity entity = ElementEntity.findBySymbol(dto.symbol);
if (entity != null) {
entity.atomicMass = dto.atomicMass;
entity.atomicNumber = dto.atomicNumber;
entity.electronConfiguration = dto.electronConfiguration;
entity.group = dto.group;
entity.period = dto.period;
entity.name = dto.name;
entity.update();
return Response.status(201).build();
}
return Response.status(400).build();
}
Ahora sí, pasan los test.
3. Borrado. Method DELETE
El borrado es un método idempotente. Si borramos dos veces, debe dar el mismo resultado. Por eso el DELETE de un elemento existente como uno no existente devuelve 200 OK.
Como es algo similar al punto anterior, los test quedarían:
@Test
void cuando_DELETE_de_un_elemento_existente_entonces_lo_borra_y_OK_200() {
ElementDto hydrogenDto = createHydrogen();
ElementEntity hydrogenEntity = spyHydrogenEntity();
doNothing().when(hydrogenEntity).delete();
when(ElementEntity.findBySymbol("H")).thenReturn(hydrogenEntity);
given()
.when()
.header("Content-Type", "application/json")
.body(hydrogenDto)
.delete(BASE_PATH)
.then()
.statusCode(200);
verify(hydrogenEntity,times(1)).delete();
}
@Test
void cuando_DELETE_de_un_elemento_que_NO_existe_entonces_no_borro_nada_pero_OK_200() {
ElementDto hydrogenDto = createHydrogen();
when(ElementEntity.findBySymbol("H")).thenReturn(null);
given()
.when()
.header("Content-Type", "application/json")
.body(hydrogenDto)
.delete(BASE_PATH)
.then()
.statusCode(200);
}
Y el endpoint quedaría así:
@DELETE
public Response delete(@Valid ElementDto dto) {
return service.delete(dto);
}
Y el método del servicio así:
public Response delete(@Valid ElementDto dto) {
ElementEntity entity = ElementEntity.findBySymbol(dto.symbol);
if (entity != null) {
entity.delete();
}
return Response.ok().build();
}
Los test pasan.
4. Obtener elemento. Method GET
Esto ya es similar todo. Sólo cabe mención especial el test del GET, porque vamos a usar la estrategia RestAssured para extraer el response a un DTO. Y eso aún no lo hemos visto.
@Test
void cuando_GET_de_un_simbolo_que_existe_entonces_devuelve_el_elemento_y_OK_200() {
ElementEntity hydrogenEntity = spyHydrogenEntity();
when(ElementEntity.findBySymbol("H")).thenReturn(hydrogenEntity);
when(mapper.toDto(hydrogenEntity)).thenReturn(createHydrogen());
ElementDto dto = given()
.when()
.header("Content-Type", "application/json")
.get(BASE_PATH + "/H")
.then()
.statusCode(200)
.extract()
.body()
.as(ElementDto.class);
assertEquals(dto.name, hydrogenEntity.name);
assertEquals(dto.atomicMass, hydrogenEntity.atomicMass);
assertEquals(dto.atomicNumber, hydrogenEntity.atomicNumber);
assertEquals(dto.electronConfiguration, hydrogenEntity.electronConfiguration);
assertEquals(dto.group, hydrogenEntity.group);
assertEquals(dto.period, hydrogenEntity.period);
}
Devuelve un 200 OK, y el body del response lo extraemos como un ElementDto a una variable sobre la que aseveramos que ciertas propiedades son las que esperamos.
El endpoint también es algo especial, pues le pasamos el símbolo del elemento, y lo recuperamos como un PathParam:
@GET
@Path("/{symbol}")
public Response get(@PathParam("symbol") String symbol) {
return service.get(symbol);
}
Pero el servicio tampoco es que tenga mucho misterio.
public Response get(String symbol) {
ElementEntity entity = ElementEntity.findBySymbol(symbol);
if (entity != null) {
ElementDto dto = mapper.toDto(entity);
return Response.ok().entity(dto).build();
}
return Response.status(404).build();
}
Sólo que en este caso, el response sí tiene un entity.
5. Modo de desarrollador. Continuous Testing y web
Si levantamos el mongo y volvemos al modo de desarrollador con el comando mvn quarkus:dev vemos que nuestra aplicación se levanta la aplicación en el puerto 8080.
Desde la terminal nos muestra algunos atajos de teclado, y podemos habilitar el continuous testing, para que se pasen los test cuando vayamos haciendo cambios sobre el código.
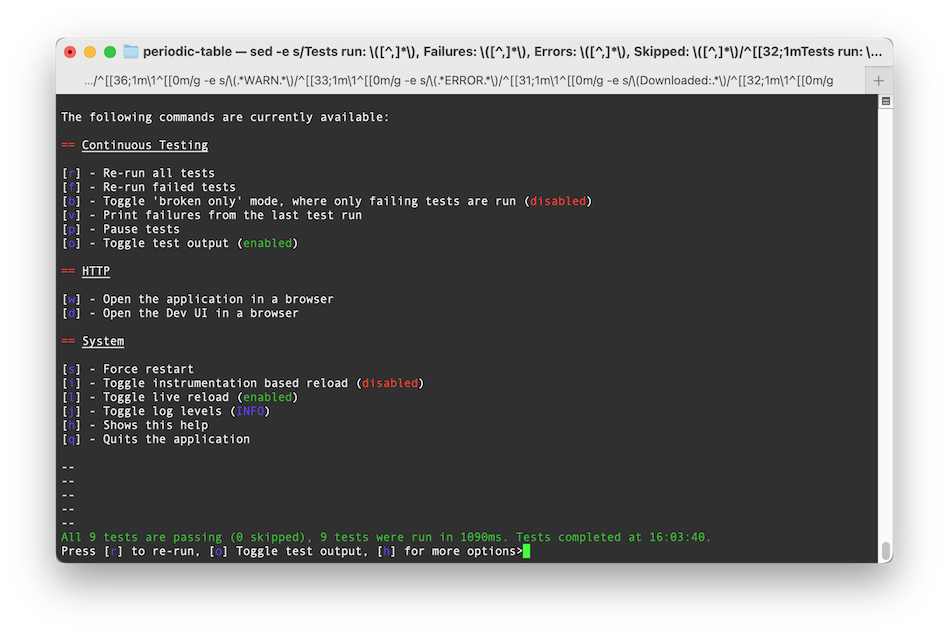
Podemos correrlos a mano bajo demanda cuando queramos sólo con pulsar la «r». Muy cómodo.
Lo cierto es que hemos hecho test, pero no hemos visto el servicio funcionando.
Vamos a lanzar un POST, a ver si es verdad que funciona. Podemos hacerlo desde POSTMAN o desde una terminal:
curl --location --request POST 'http://localhost:8080/element' \
--header 'Content-Type: application/json' \
--data-raw '{
"symbol":"H",
"name":"hydrogen",
"group":1,
"period":1,
"atomicNumber":1,
"atomicMass":1.008,
"electronConfiguration":"1s1"
}'
En la terminal de quarkus vemos que podemos abrir un navegador con la «w». Si ahora ponemos en la barra de direcciones http://localhost:8080/element/H nos devolverá la info del hidrógeno. También podemos hacerlo desde terminal.
curl --location --request GET 'http://localhost:8080/element/H'
{"symbol":"H","name":"hydrogen","group":1,"period":1,"atomicNumber":1,"atomicMass":1.008,"electronConfiguration":"1s1"
Y el puerto de depuración es el 5005. Eso quiere decir, que si queremos depurar nuestra aplicación con nuestro IDE favorito, en mi caso Eclipse, deberemos configurar la depuración como una aplicación java remota en el puerto 5005.
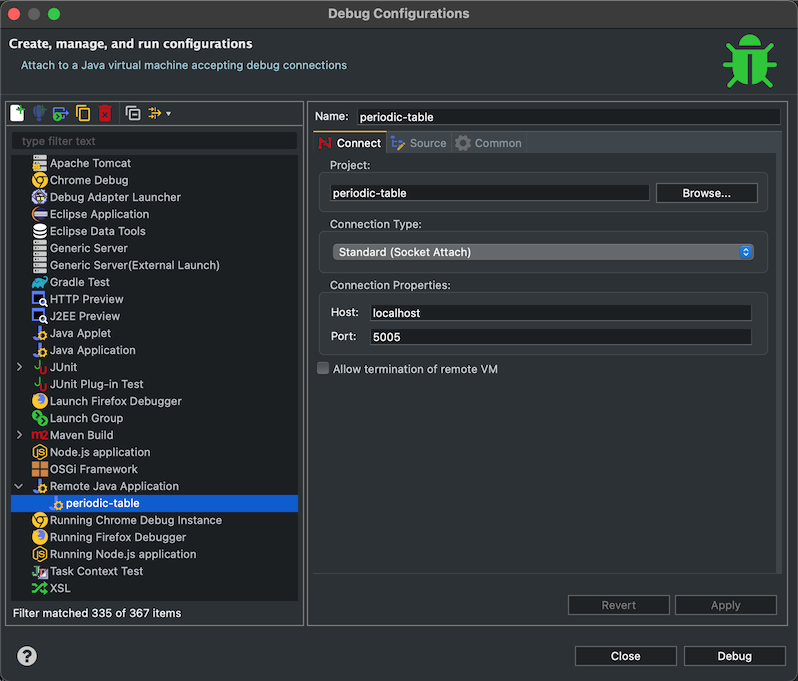
Con esto tenemos casi todo lo necesario para trabajar con quarkus en nuestro día a día.
Si queréis profundizar en el concepto de Prueba Continua con Qurkus podéis ver el siguiente video:
https://www.youtube.com/watch?v=rUyiTzbezjw
6. Compilación a nativo
Sin duda, la compilación a nativo es uno de los mayores atractivos de Quarkus. Usando GraalVM o Mandrel, en lugar de usar la JVM para correr el bytecode generado podremos compilar a nativo, es decir, generar un programa ejecutable para la máquina en la que compilemos. Pensando en desplegar en la nube, podremos compilar a nativo en la imagen de los contenedores que se desplieguen. ¿Y qué ventajas nos supone esto? Pues muchas…
Un programa nativo consume muchos menos recursos que su misma versión en JVM, pero muchos menos. Y puesto que en estos sistemas se paga por consumo de recursos, pues cuanto menos, mejor… Además, tiene una ventaja adicional, y son los tiempos en que se levanta el programa. En nativo son casi instantáneos. De forma que se puede ajustar mucho más los recursos, pues sabemos que el autoescalado horizontal, levantará instancias de nuestros contenedores, y puesto que se levantarán muy rápido, pues no tenemos que estar pensando en tiempos de contingencia.
Vale, y ¿cómo se hace la compilación a nativo? En mi caso, yo tengo instalado GraalVM 21.3.0 para java 11.
Mi JAVA_HOME apunta a donde tengo instalado GraalVM. Previamente he ejecutado:
sudo $JAVA_HOME/bin/gu install native-image
Con esto ya estoy preparado para compilar imágenes nativas. En mi proyecto ejecuto el comando de maven:
mvn package -Pnative
El resultado es el siguiente: ha tardado 2 minutos y 21 segundos y ha llegado a usar 6 GB de RAM… La compilación nativa es exigente.
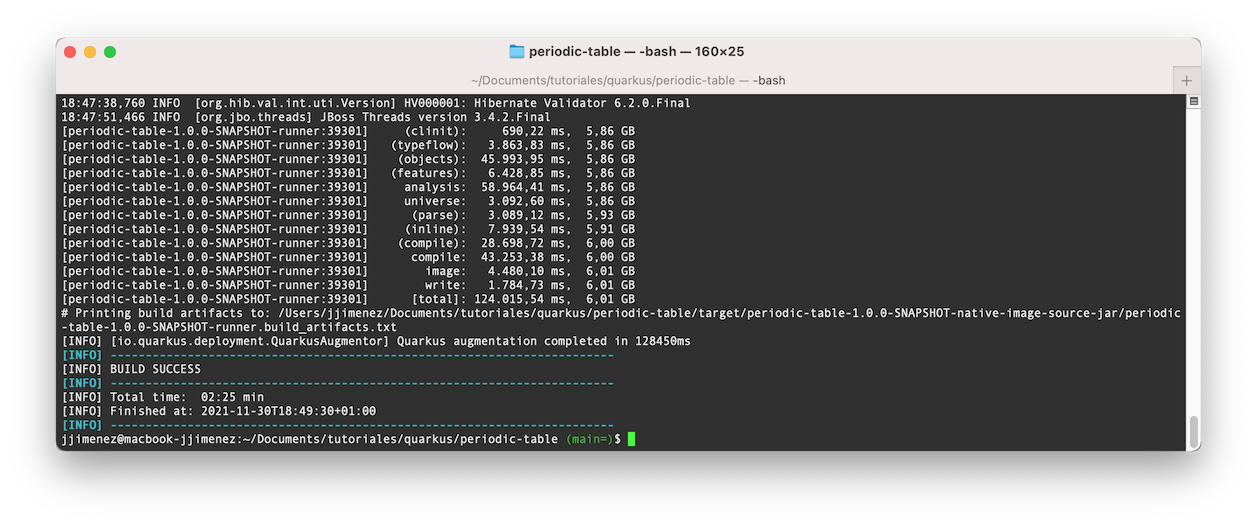
Vamos a levantar esta imagen nativa:
./target/periodic-table-1.0.0-SNAPSHOT-runner
En algún caso nos puede interesar crear una imagen nativa para un contenedor específico.
mvn package -Pnative -Dquarkus.native.container-build=true -Dquarkus.native.container-runtime=podman
Hay algunas consideraciones que debemos que tener al compilar a nativo y es que las librerías que usemos estén preparadas. Las que vienen con el ecosistema de Quarkus lo están, y las más habituales como lombok, MapStructs, etc… también. Pero puede que alguna a la que tengamos cierta querencia, no lo esté. Cuidadín con esto y tenedlo en mente desde el principio, que depender de librerías de terceros y luego querer hacer compilación a nativo puede ser un verdadero quebradero de cabeza, y quitar las dependencias de esa librería puede resultar un engorro…
Otro tema son las herramientas de serialización/deserialización. A veces, estas herramientas usen reflexión, y podemos tener un problema. Un caso donde me lo he encontrado que es muy frecuente es cuando inyectamos el objectMapper de Jackson. Se solventa anotando la clase con un @RegisterForReflection.
Otro caso típico es en Panache, con las entidades que tienen una clave compuesta. Hay que anotar las propiedades con un @Id e indicar en la clase cual es la clave compuesta con un @IdClass referenciando a la clase que forma la clave compuesta. Yo suelo usar una clase interna dentro de la entidad a la que llamo de forma homónima IdClass. Bueno, pues esa clase interna también hay que anotarla con un @RegisterForReflection.
En general, pocos problemas más te vas a encontrar.
7. Conclusiones
Ha sido un artículo breve, no obstante, hemos aprendido a:
- Mejorar nuestros test RestAssured extrayendo el response a un DTO
- Una pequeña introducción al continuous testing en Quarkus
- Cómo hacer depuración remota
- Y también hemos visto como compilar a nativo con GraalVM
Pocos puntos, pero intenso.
Enlaces y referencias
- El código fuente de este tutorial en GitHub
https://github.com/eContento/periodic-table - Guía de Pruebas Continuas
- Guía de cómo construir una aplicación nativa
- Truquillos para escribir aplicaciones nativas con Quarkus

