
Llega por fin el último tutorial de una serie que ha explorado con bastante detalle las características y posibilidades
de la plataforma ELK (Elasticserach, Logstash y Kibana).
En este caso se trata de ver cómo utilizar Kibana para analizar los logs de la aplicación Spring Boot ejecutada como
parte del primer tutorial.
Anteriormente se explicó cómo administrar Elastisearch.
Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Instalación y configuración
- 4. Explotación de datos
- 5. Gráficos y dashboards
- 6. Conclusiones
- 7. Referencias
1. Introducción
Kibana es una aplicación web que facilita la explotación visual de información almacenada en una base de datos Elasticsearch.
Aunque su popularidad está vinculada a la de Logstash como sistema de recogida y análisis de logs, lo cierto es que
Kibana es de propósito general y puede representar cualquier conjunto de datos con tablas y gráficas bastante ricas.
Después de este tutorial conocerás los elementos con los que trabaja Kibana y serás capaz de componer un
dashboard con la complejidad y riqueza que desees.
El ejemplo utilizado perseguirá el objetivo de extraer la información más útil e interesante de los mensajes de log
de una aplicación Spring Boot y presentarla de una manera intuitiva sin perder detalle.
2. Entorno
Los detalles del entorno se pueden consultar en la
introducción a la plataforma ELK.
3. Instalación y configuración
3.1. Con Ansible
Siguiendo con el ejemplo de la serie de tutoriales, la instalación y configuración de Kibana forma parte del entorno
virtual montado con Vagrant y Ansible.
El rol de Ansible responsable de Kibana se llama kibana como no podía ser de otra manera.
Sus opciones de configuración son tan simples que realmente no es necesario tocar nada excepto cuando Elasticsearch
esté desplegado en un servidor separado, ya que la dirección por defecto es http://localhost:9200.
En ese caso, la URL deberá indicarse en la propiedad elasticsearch del diccionario kibana en el fichero
ansible/environments/tutorial/group_vars/stats, por ejemplo:
ansible/environments/tutorial/group_vars/stats (fragmento)
# Kibana
kibana:
elasticsearch: "http://elasticsearch-server:9200"
version: 4.4
plugins:
- {name: kibana/timelion, shortname: timelion }
Después de realizar cualquier cambio hay que decirle a Vagrant que vuelva a provisionar la máquina virtual:
Terminal
$ vagrant provision statsserver
3.2. Instalación manual
La empresa detrás de Kibana publica en esta página
repositorios para las distribuciones Linux más populares.
La aplicación es autocontenida y no depende de ningún paquete externo (internamente corre sobre Node.js).
Para configurar Kibana manualmente simplemente hay que editar el fichero /opt/kibana/config/kibana.yml
y reiniciar el servicio.
Los ajustes de configuración están bien documentados en el mismo fichero y no es necesario entrar en detalle aquí.
3.3. Acceso y configuración
La aplicación web está publicada por defecto en el puerto 5601, así que para acceder al entorno virtual montado
en esta serie de tutoriales simplemente habrá que apuntar el navegador a http://localhost:5601.
Un inciso: si Kibana se queda aparentemente colgado cargando datos, hay que entrar al servidor, eliminar el
directorio /opt/kibana/optimize/bundles y reiniciar el servicio. En el caso de Ubuntu los comandos serían estos:
Terminal
$ sudo rm /opt/kibana/optimize/bundles $ sudo service kibana restart
Según se vio en el primer tutorial,
la primera vez que se entra a Kibana nos pedirá definir sobre qué datos de Elasticsearch queremos hacer las consultas.
Esto se hace creando uno o más patrones de índices (index patterns), que en el caso que nos ocupa es
simplemente el valor por defecto: logstash-*
Además, debemos marcar el checkbox que indica que los datos consisten en eventos ordenados en el tiempo y
seleccionar el campo que contiene la marca de tiempo de cada documento (@timestamp en este ejemplo).
En cualquier momento se puede volver a esta pantalla de configuración a través de la pestaña Indices de
la opción de menú Settings:
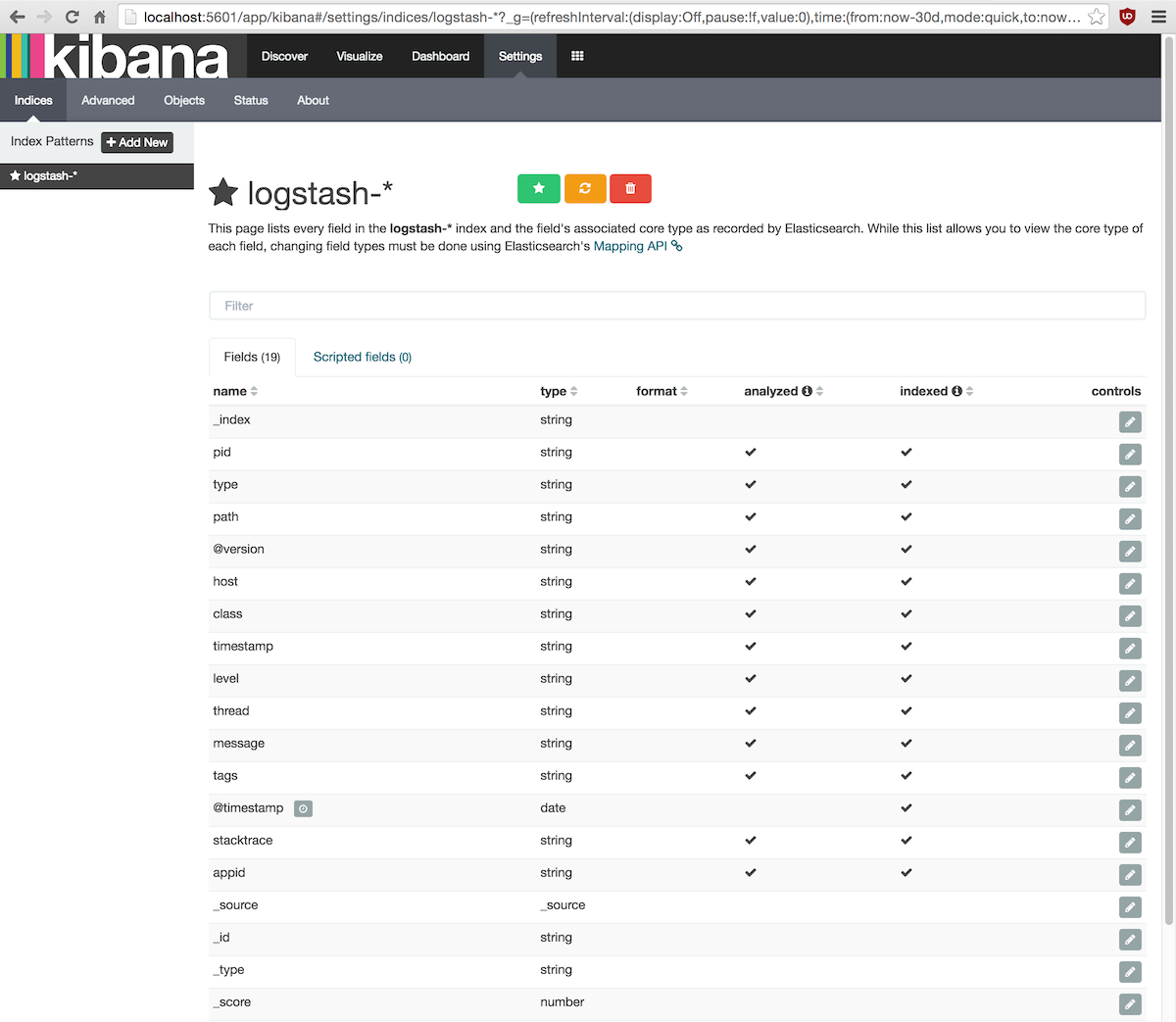
Para cada patrón de índice se mostrarán los campos conocidos de los documentos almacenados.
Si los campos listados no se corresponden con los datos reales será necesario pulsar el botón amarillo de recarga.
Esto ocurrirá si en algún momento cambia la estructura de los documentos indexados, es decir, si se añaden o modifican campos.
Como se verá más adelante, la otra pestaña de configuración interesante es Objects; el resto no vale la pena tocarlas.
4. Explotación de datos
El menú Discover de Kibana da acceso a la consola de ejecución de consultas sobre Elasticsearch, cuyos
elementos principales son los siguientes:

En primer lugar debemos ajustar el intervalo de tiempo que nos interesa haciendo clic sobre el botón de la ventana
temporal en la esquina superior derecha. El intervalo se puede establecer de manera rápida a partir de una lista
predefinida, de manera relativa o de manera absoluta.
Después introduciremos un filtro en el formulario de búsqueda para extraer los documentos que cumplan esa condición
de filtrado (más sobre esto en el siguiente apartado).
El panel de campos y el propio listado de resultados son interactivos y nos permiten inspeccionar los datos con más
detalle, seleccionar las columnas que nos interesan y/o aplicar filtros adicionales.
Kibana también nos ofrece guardar y recuperar búsquedas mediante los iconos del panel de herramientas.
4.1. Expresiones de búsqueda
La expresión de búsqueda se pasa tal cual a Elasticsearch que a su vez delega en Apache Lucene.
Estas expresiones consisten en cadenas de texto y/o filtros de campos que se pueden encadenar con los operadores
lógicos AND, OR y NOT en mayúsculas o sus alias &&, || y !
respectivamente. También se pueden usar paréntesis para cambiar la precedencia por defecto.
Los filtros de campos tienen el formato básico: campo:condición
donde campo es el nombre del campo a filtrar y condición es el criterio de filtrado que se quiere aplicar.
Aquí van unos cuantos ejemplos representativos:
- amount:>100, aquellos documentos cuyo campo amount es mayor que 100.
- level:WARN, el campo level es igual a la cadena WARN.
- quality:[0.8 TO 1], el valor de quality está dentro del intervalo 0.8 a 1, ambos incluidos.
- quality:{0.8 TO 1}, igual que el anterior pero el intervalo es abierto, o sea excluyendo los extremos.
- level:(WARN OR ERROR), el campo level tiene el valor WARN o ERROR.
- class:*LogItemProcessor, el valor de class termina con la cadena LogItemProcessor.
El asterisco se puede poner en cualquier parte de la cadena. - host:appssserver?, coge los documentos cuyo host es appsserver seguido de algún otro caracter,
por ejemplo appsserver1 o appsserver2.
Un último ejemplo que combina lo dicho, para buscar los mensajes problemáticos generados por la clase LogItemProcessor:
class:*LogItemProcessor AND level:(WARN OR ERROR)
4.2. Análisis de datos crudos
Kibana también ofrece algunas opciones para analizar los resultados, entre las que destacan la agregación por un campo,
la selección de columnas y el filtrado rápido por valores concretos.
Por ejemplo, si queremos saber cómo se reparten los mensajes de log de nivel ERROR o WARN entre las
clases de nuestra aplicación haríamos lo siguiente:
- Introducir la expresión de búsqueda: level:(WARN OR ERROR)
- En el panel de la izquierda titulado Available fields, seleccionar el campo class para desplegar una
vista rápida del reparto de clases que han generado mensajes de esos niveles.
Se mostrará algo parecido a esto:
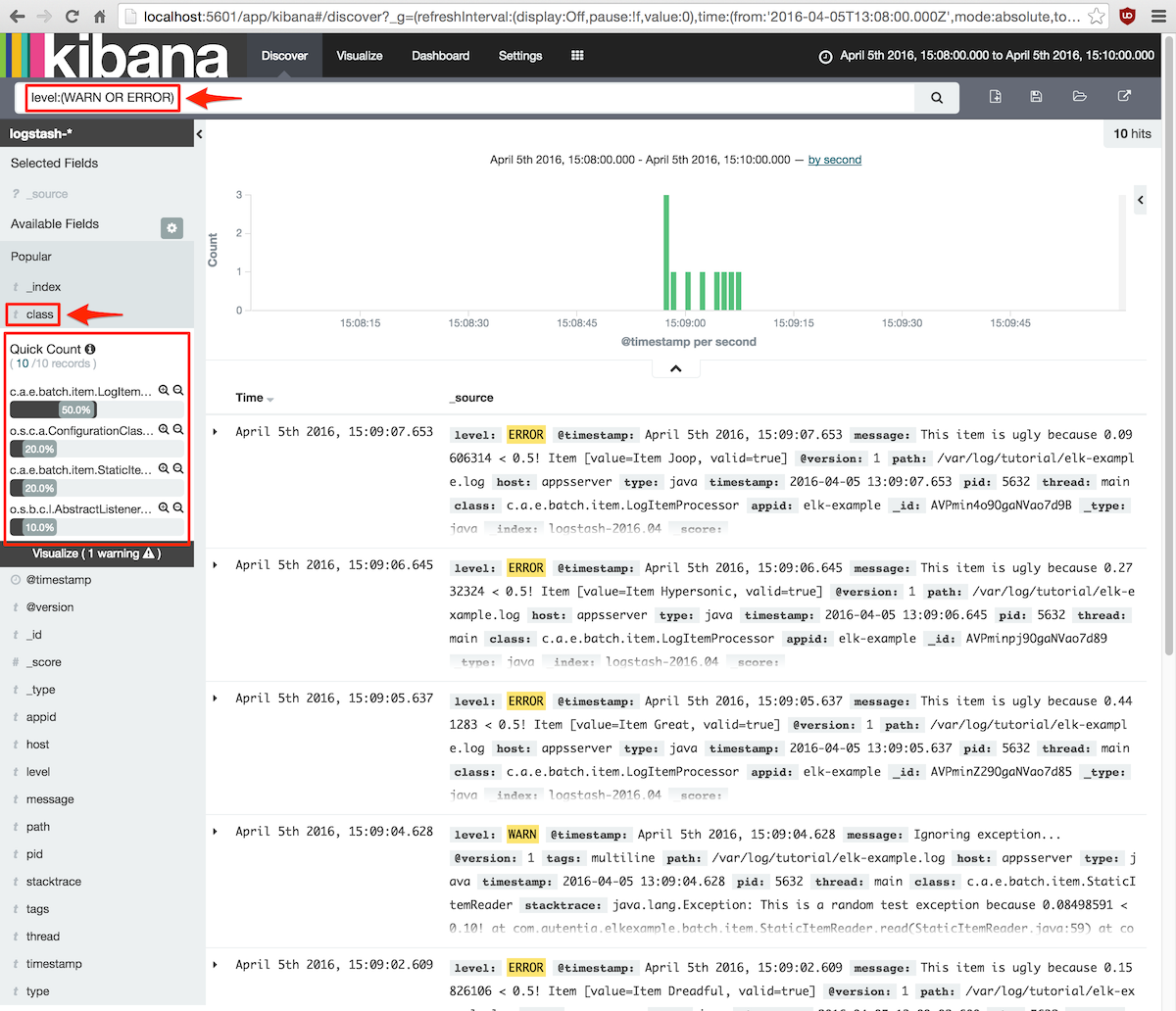
Además, si hacemos clic sobre el pequeño botón add que aparece a la derecha del campo class en el panel
de Available fields, el listado mostrará únicamente esta columna.
5. Gráficos y dashboards
La presentación visual de información en Kibana se basa en gráficos (visualization) agrupados en paneles
que componen un cuadro de mandos o dashboard.
El primer paso antes de ponernos a montar un dashboard es definir qué información debe mostrarse y en qué formato.
El objetivo es conocer lo que interesa de un vistazo rápido y poder indagar en los detalles si es necesario.
Una vez tenemos claro a dónde queremos llegar, desde la pantalla Discover hay que componer los filtros de
búsqueda con los que recuperar los documentos necesarios.
La búsqueda se guardará con un nombre para usarla en el paso siguiente.
A continuación se diseñarán los gráficos desde la pantalla Visualize para guardarlos con un nombre
que facilite añadirlos al dashboard más adelante.
Por último, desde la pantalla Dashboard iremos añadiendo las visualizaciones y colocándolas según nos interese.
El propio dashboard se guardará para poder consultarlo en cualquier momento.
5.1. Un caso práctico
A lo largo de este capítulo vamos a montar un dashboard con los eventos de log de la aplicación Spring Boot del
primer tutorial.
Para tener una serie de datos decente para visualizar he ejecutado la aplicación durante 1000 segundos y después
he fijado la ventana temporal de Kibana al intervalo durante el que ha ocurrido esa ejecución.
La información más relevante que deseamos conocer acerca de estos eventos de log es la siguiente:
- Cuántos eventos se generan a lo largo del tiempo y qué nivel tienen (cómo de críticos son).
- Ver fácilmente qué clases Java están generando mensajes de log problemáticos (WARN y ERROR).
- Ver información detallada sobre el número de eventos de cada nivel que produce cada clase Java.
De estas tres informaciones, sólo la segunda trabaja con un subconjunto de documentos, en concreto, con los mensajes
cuyo level es WARN o ERROR.
Así, hay que ir a la pantalla Discover e introducir el filtro level:(WARN OR ERROR) y guardarlo con un
nombre representativo:
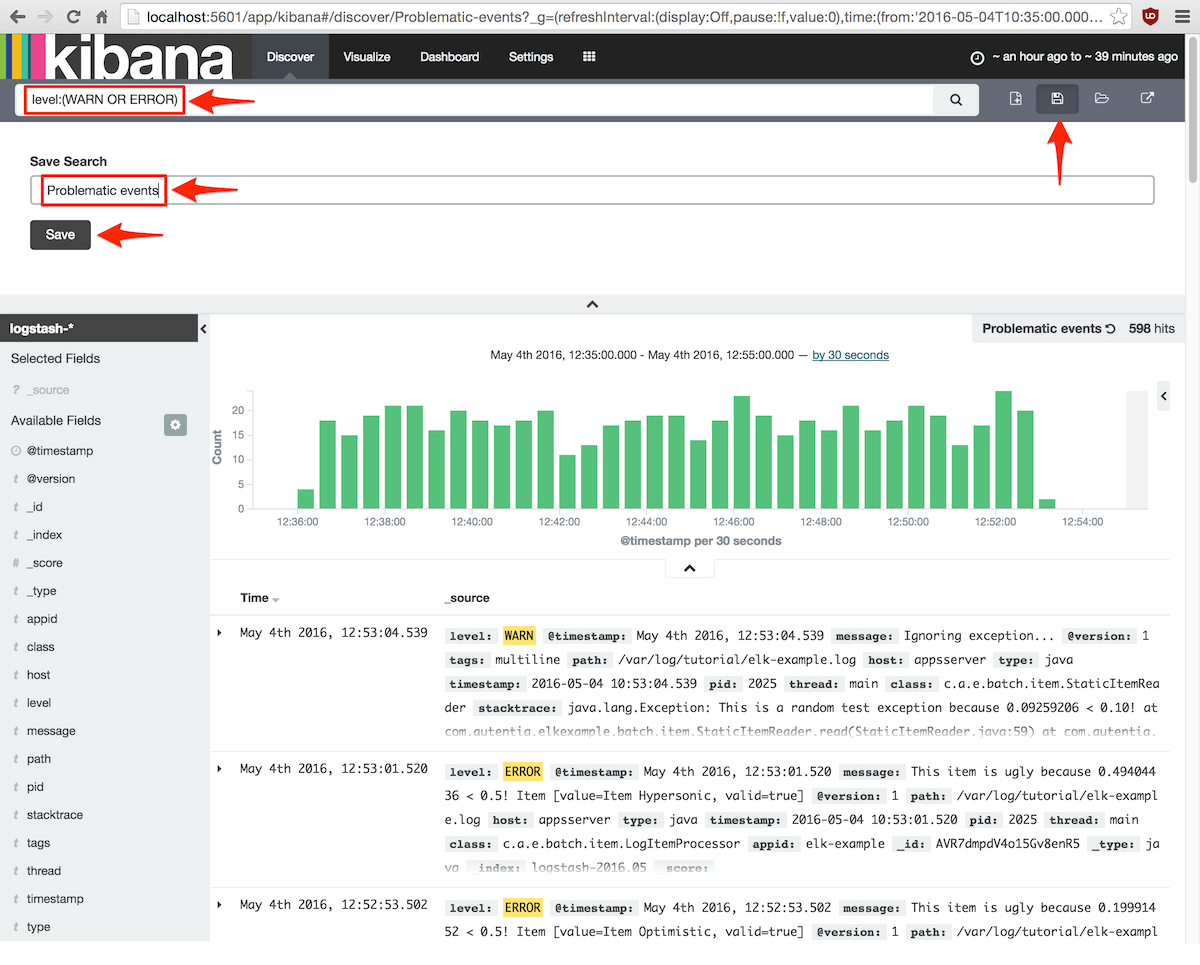
5.2. Gráficos
Los gráficos se definen en la pantalla Visualize.
5.2.1. Funciones de agregación
Todos ellos trabajan con funciones de agregación de Elasticsearch, así que antes de continuar hay que hacer una
pequeña introducción a ellas.
Para lo que nos interesa, existen dos tipos de agregraciones en Elasticsearch: metrics y buckets.
Las metrics calculan uno o varios valores a partir de un campo del conjunto de documentos seleccionado.
Es decir, el resultado de una metric suele ser un número y entre ellas están las habituales
count, sum, max, min, avg, etc.
Las agregaciones bucket sirven para seleccionar y agrupar documentos de muchas maneras y es un concepto
similar a la cláusula GROUP BY de SQL.
Un bucket funciona tomando los documentos seleccionados y aplicando un filtrado, agrupación o clasificación
según algún criterio. Por lo tanto, su resultado es uno o más conjuntos de documentos.
Lo más interesante es que a ese resultado se le puede aplicar a su vez otras agregaciones, ya sean de tipo
bucket o metric.
Ahora podemos continuar con los gráficos diciendo que todos aquellos que representan datos bidimensionales utilizan
buckets para el eje X y metrics en el eje Y.
Además, podemos representar varios conjuntos de datos en la misma gráfica utilizando buckets dentro de buckets.
La tarta por su parte consta de un bucket que determina cuáles son las porciones y una metric para fijar el tamaño de cada porción.
5.2.2. El histograma múltiple
Esto se verá más claro con la primera gráfica del caso práctico: un histograma con todos los eventos de log
distinguiendo su nivel.
Pulsar el botón New Visualization en la barra de herramientas para crear un nuevo gráfico, seleccionar
Area chart y pulsar From a new search puesto que nos interesa trabajar con todos los datos.
En el panel de la izquierda se puede ver que el eje Y por defecto ya tiene una metric count,
así que no hay que hacer nada.
El eje X debe ser un histograma, así que añadiremos un bucket de tipo X-Axis con una agregación Date histogram.
Si ejecutamos la gráfica pulsando el botón verde de la parte superior del panel aparecerá la gráfica de histograma
sin distinguir niveles:
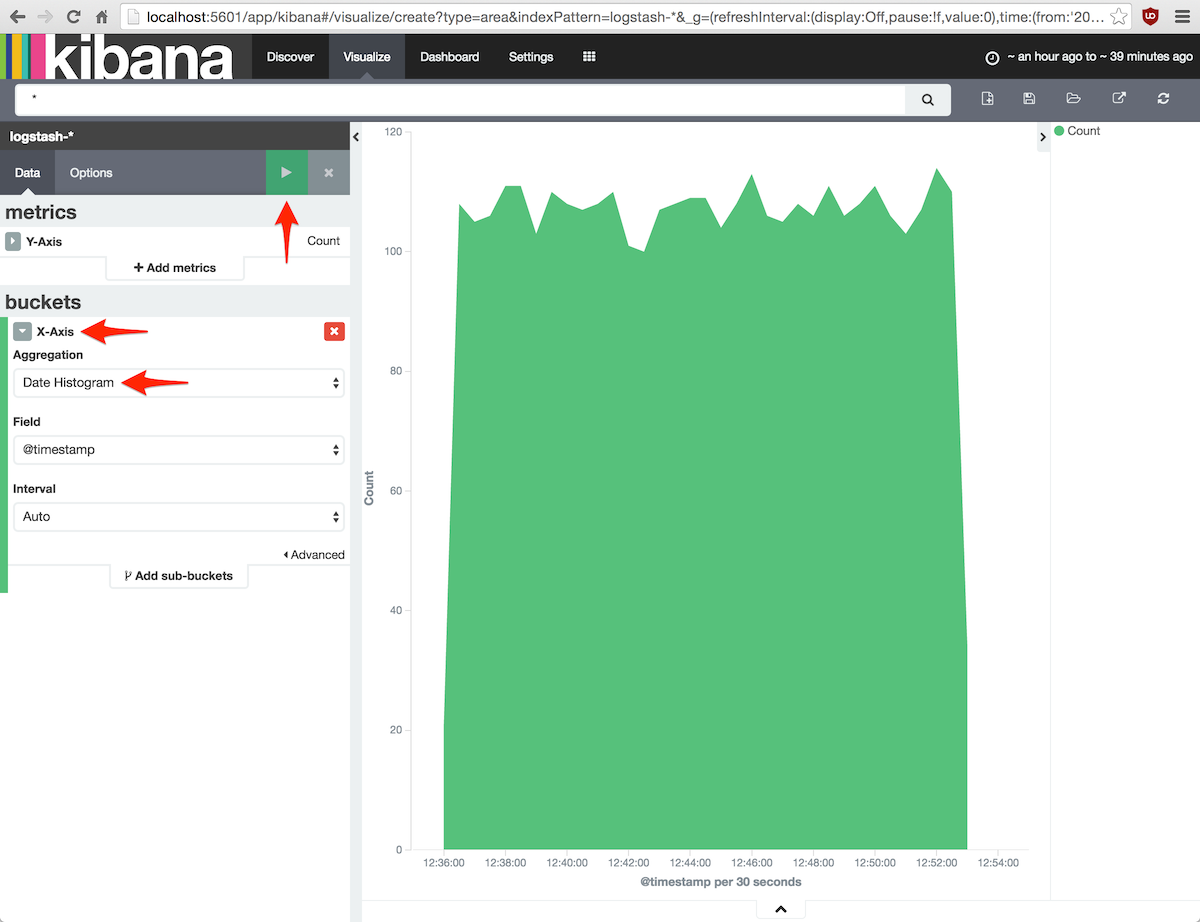
Para separar por niveles hay que añadir un sub-bucket Split Area que visualiza varios grupos en la misma área.
La función de agregación será terms sobre el campo level.raw (siempre se deben utilizar los subcampos raw):

Al pulsar el botón verde se podrá ver el resultado esperado, así que ya sólo falta grabar la gráfica pulsando el botón
Save Visualization en la barra de herramientas.
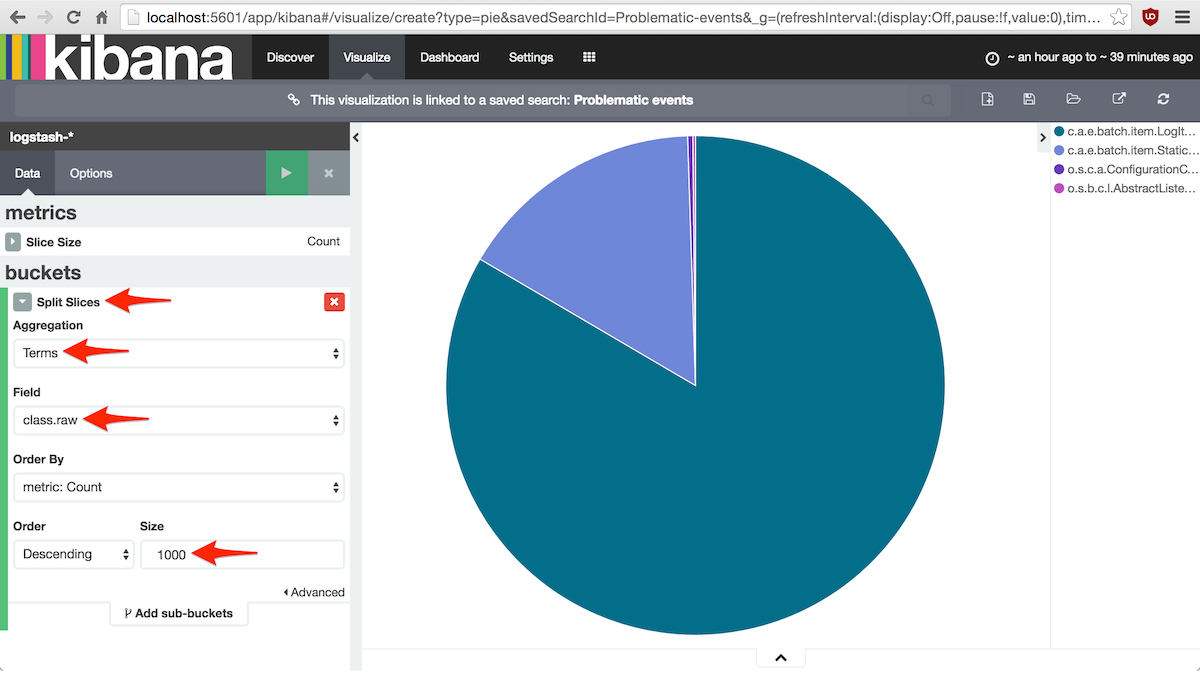
5.2.3. La tarta de problemas
Seguiremos unos pasos similares para definir una gráfica de tarta con las clases que más problemas han generado.
Ahora, tras pulsar el botón New Visualization, hay que seleccionar Pie chart y a continuación
From a saved search ya que se van a tener en cuenta solamente los eventos devueltos por la consulta Problematic events.
De nuevo, Kibana supone que lo que vamos a hacer es contar cosas, así que la metric por defecto es count.
En cuanto a los grupos de documentos, el bucket debe ser un Split Slices porque queremos todo sobre la misma tarta.
La función de agregación será terms sobre el campo class.raw, es decir, queremos un grupo por cada clase Java.
Antes de terminar hay que cambiar el parámetro Size a un valor muy grande (1000 por ejemplo) porque por defecto
solamente se muestran los 5 grupos más grandes.
Pulsar el botón verde para ver la gráfica y guardarla con el botón Save Visualization de la barra de herramientas:
5.2.4. Las barras conflictivas
El dashboard ofrecerá una vista alternativa en forma de diagrama de barras de las clases más problemáticas.
El proceso para definir esta gráfica es casi idéntico al del diagrama de tarta, excepto que el tipo de visualización
es Vertical bar chart lógicamente.
Recordar que el conjunto de datos de partida es la consulta Problematic events.
Aquí el eje X consistirá en un bucket de tipo X-Axis con agregación terms sobre el campo class.raw.
También hay que cambiar el número máximo de elementos a algo muy grande (como 1000) para que muestre todos los datos.
Ya solamente falta pulsar el botón verde para actualizar la gráfica y pulsar el botón Save Visualization de la
barra de herramientas para guardarla con un nombre representativo:

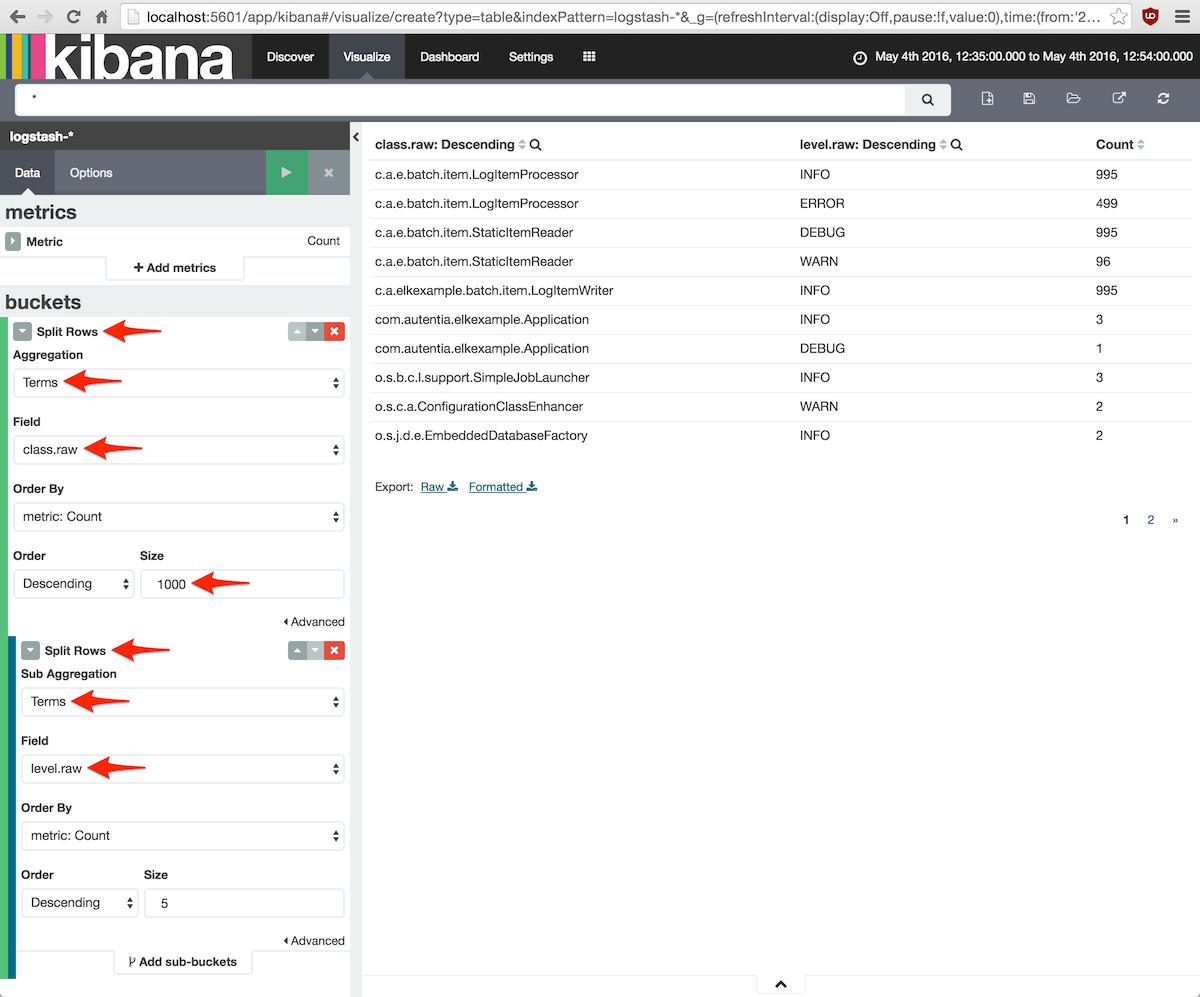
5.2.5. La tabla de detalles
La última visualización es una tabla que muestra el número de mensajes de cada nivel producidos por cada clase Java,
así que tras pulsar New Visualization en la barra de herramientas, seleccionaremos Data table.
Como estamos interesados en todos los niveles de log debe elegirse From a new search.
Como siempre, el eje Y está preconfigurado para contar elementos, que es justamente lo que queremos hacer.
En el eje X añadiremos un Split Rows para agrupar por clases Java, así que la agregación bucket será
terms sobre el campo class.raw.
Estamos interesados en todas las clases, por lo que el parámetro Size debe ser un número alto como 1000.
También queremos romper los datos por nivel del mensaje. Para conseguirlo hay que añadir un sub-bucket
de tipo Split Rows con función de agregación terms del campo level.raw.
Tras pulsar el botón verde para actualizar la gráfica, se mostrará una tabla con tres columnas:
clase Java, nivel y número de elementos.
Ya solamente falta guardarla con el botón Save Visualization de la barra de herramientas:
5.3. Dashboards
Él último paso del proceso es juntar todas las gráficas en un bonito dashboard.
Esto se hará desde la pantalla Dashboard y pulsando sobre el botón New Dashboard en la barra de herramientas.
El propio Kibana nos sugiere ir pulsando el botón + (Add Visualization) para ir añadiendo gráficas, así que ¡adelante!
Los paneles de cada gráfica se pueden mover y redimensionar a nuestro gusto.
Tras algunos experimentos yo me quedo con esta distribución bastante clásica:
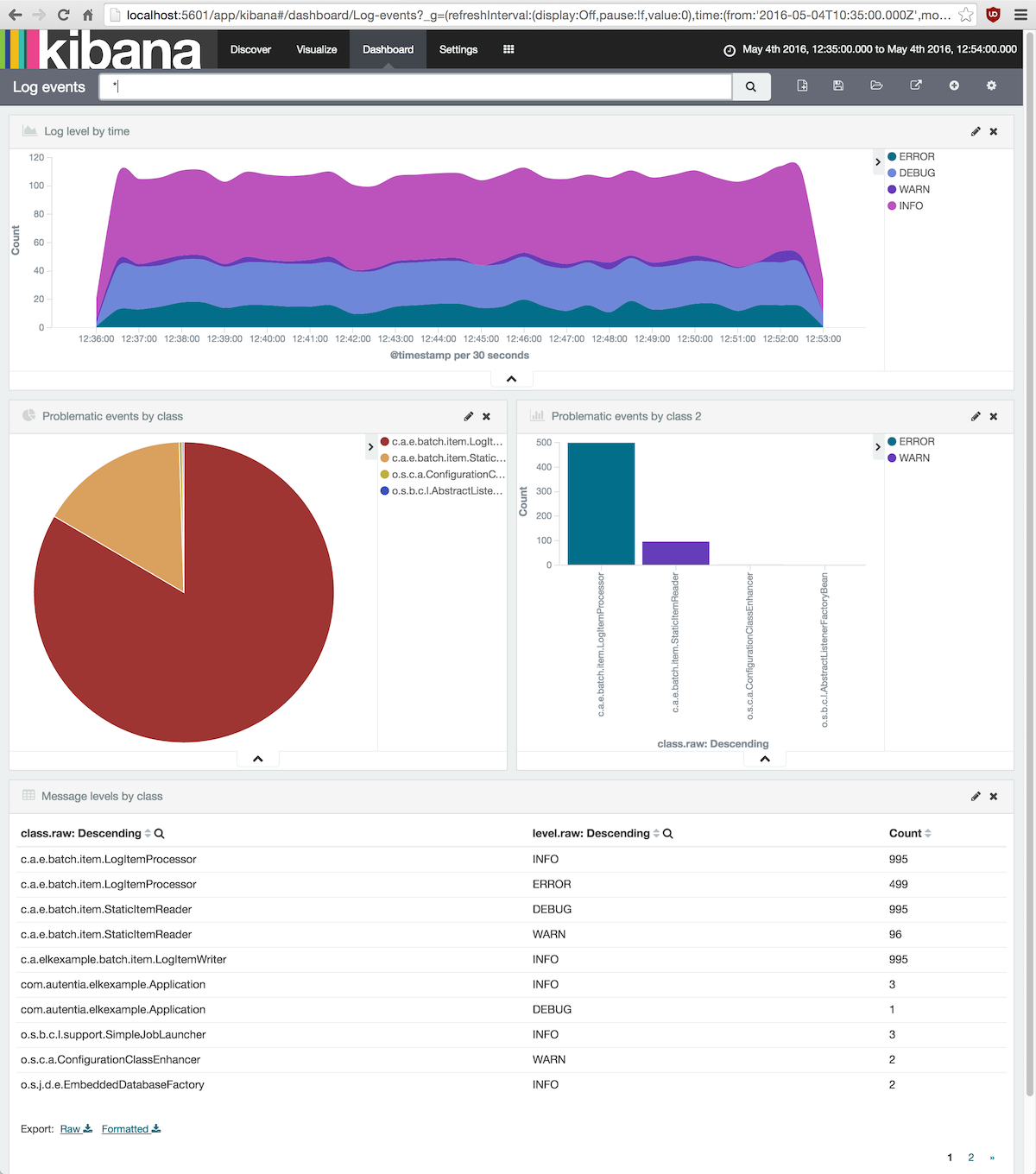
No olvides guardar tu obra de arte con un nombre interesante.
6. Conclusiones
Kibana es una herramienta muy flexible y con bastantes posibilidades, pero no hay que perder de vista que su utilidad
real dependerá en gran medida de los datos de partida.
Concretamente, hay que asegurarse que la aplicación genera mensajes de log en los puntos y momentos que realmente
aportan información de interés (muchas veces no es así) y también que cada mensaje lleva asociado datos que nos
permitan agrupar, clasificar y filtrar los mensajes para hacernos una idea clara de qué está pasando
(por ejemplo, identificar la sesión del usuario).
Por otro lado, como es lógico este tutorial no ha profundizado en otros aspectos interesantes de esta aplicación
como el plugin Timelion para representación de series temporales.
Y no olvidar que para poder aprovechar Timelion y el propio Kibana al máximo hay que dominar los lenguajes de
consultas de Elasticsearch y Apache Lucene.
En el apartado de referencias se dejan un par de enlaces sobre estos temas.

