
Este es el primer tutorial de una serie de cuatro que explicará cómo instalar, configurar y explotar la plataforma
Elasticsearch, Logstash y Kibana, un sistema centralizado de recogida y análisis de logs de aplicaciones.
Por en medio se usarán las herramientas Vagrant y Ansible para la creación y provisionamiento de las máquinas virtuales.
Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Objetivo del tutorial
- 4. Creación de las máquinas virtuales
- 5. Uso de la plataforma
- 6. Conclusiones
- 7. Referencias
1. Introducción
Una de las cuestiones a resolver cuando nuestra aplicación está lista para desplegar en producción es cómo
monitorizar su funcionamiento para poder actuar de manera rápida y efectiva ante cualquier incidencia.
Hay muchas soluciones en el mercado para cubrir esta necesidad, tanto de pago como libres, pero una de las más
populares es la plataforma Elasticsearch, Logstash y Kibana, conocida como ELK.
Lo que distingue a ELK sobre otras alternativas es principalmente:
- Potencia: mucha funcionalidad que se puede aprovechar fácilmente.
Por ejemplo, Kibana no está limitado a gráficas de series temporales y puede manejar cualquier conjunto de datos. - Escalabilidad: los clusters de Elasticsearch pueden manejar terabytes de datos sin ningún problema.
- Flexibilidad: configuración muy abierta y flexible que se adapta a cualquier necesidad y entorno.
- Apertura: plugins y APIs para extender casi cualquier aspecto de la plataforma.
- Y por si todo esto no fuera suficiente, licencia comercial con soporte, hosting y productos relacionados.
Para poner en marcha una plataforma de este tipo hacen falta los siguientes elementos:
- Un agente de recogida de logs en nuestras aplicaciones.
De esto se encarga el demonio Logstash, aunque como se verá más adelante, hay otras opciones. - Una base de datos donde almacenar, indexar y buscar los eventos de log de las aplicaciones.
Para esto se utiliza Elasticsearch. - Una aplicación frontend donde los usuarios puedan consultar los eventos más interesantes y estar
informados de cualquier incidencia. Esta es la función de Kibana.
Otros elementos opcionales pero no menos útiles son:
- Un sistema de monitorización y control de la propia plataforma ELK.
Aunque hay soluciones más completas, nos limitaremos a monitorizar Elasticsearch con el plugin Kopf. - Una herramienta de alertas automáticas para informar de problemas graves por múltiples canales.
Por el momento no hay ninguna alternativa libre para esta funcionalidad, aunque Elastic ofrece el plugin de pago Watcher. - Sistema de control de accesos con autenticación y autorización basada en roles y conjuntos de datos.
Elastic vende licencias de su propio producto Shield aunque existen plugins libres alternativos y la opción
básica de un proxy inverso Apache o Nginx.
Montar este entorno es relativamente complejo. Además idealmente debe poder extenderse fácilmente a múltiples
aplicaciones en un CPD y escalar a un cluster con múltiples nodos conforme vayan aumentando las necesidades de sistemas.
Por esta razón, todas las tareas de instalación y configuración serán automatizadas con Ansible
sobre dos máquinas virtuales VirtualBox generadas con Vagrant.
Se suponen unos conocimientos mínimos de Ansible y Vagrant que puedes adquirir en
este tutorial.
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware anfitrión: Portátil MacBook Pro Retina 15′ (2.5 Ghz Intel Core i7, 16GB DDR3)
- Hardware huesped: dos servidores con 2,5 GB RAM y 2 CPUs
- Sistema operativo anfitrión: Mac OS Yosemite 10.10
- Sistema operativo huesped: Ubuntu Server 14.04.4 LTS 64 bits
- Elasticsearch 2.2.1
- Logstash 2.2.2
- Kibana 4.4.2
- Ansible 2.0.1
- Vagrant 1.8.1
- VirtualBox 5.0.14
- Maven 3.3.9
3. Objetivo del tutorial
Nuestro punto de partida es una aplicación Spring Boot llamada elk-example-app que está lista para ser
desplegada en nuestro servidor de «producción» appsserver.
Para el caso que nos ocupa esta aplicación simplemente genera mensajes de log durante un tiempo de manera pseudo-aleatoria.
El objetivo del tutorial es añadir a nuestro «CPD de producción» un servidor llamado statsserver en el que
se registrarán los eventos de log de la aplicación para luego poder consultarlos y analizarlos.
En el siguiente diagrama se puede ver cómo va a quedar el entorno al final de este tutorial:
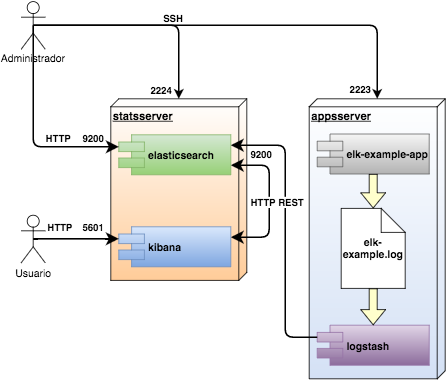
Las máquinas virtuales appsserver y statssserver estarán accesibles por SSH en los puertos 2223 y 2224 respectivamente.
La interfaz HTTP (REST y de administración) de Elasticsearch estará disponible en el puerto 9200 del servidor statsserver.
La interfaz web de Kibana podrá utilizarse desde el puerto 5601 en statsserver.
La aplicación escribe los mensajes de log en el fichero /var/log/tutorial/elk-example.log, de donde los lee Logstash
para enviarlos a Elasticsearch en forma de registros JSON sobre HTTP REST.
Por su parte, Kibana accederá a Elasticsearch para ejecutar las consultas solicitadas por el usuario.
El propio Kibana guarda la configuración de búsquedas, visualizaciones y paneles en Elasticsearch.
4. Creación de las máquinas virtuales
4.1. Requisitos
El equipo anfitrión se encarga de crear las máquinas virtuales y provisionarlas, así que en primer lugar es
necesario instalar VirtualBox,
Vagrant y
Ansible.
En el caso OSX se ha utilizado Homebrew tal y como se explica en
este tutorial:
Terminal
$ brew cask install virtualbox $ brew cask install vagrant $ brew install ansible
Por otro lado, el resto de materiales del tutorial se encuentran publicados en este repositorio de GitHub:
https://github.com/dav-garcia/elk-tutorial.

Se pueden descargar como paquete ZIP o clonando el repositorio git con la URL que aparece en la caja de texto:
Terminal
$ git clone https://github.com/dav-garcia/elk-tutorial.git
4.2. Generando las máquinas virtuales
El fichero Vagrantfile del repositorio elk-tutorial define dos máquinas virtuales Ubuntu Server 14.04
de 64 bits.
Ambas máquinas dispondrán de 2 CPUs y 2,5 GB de memoria RAM cada una, suficiente para este tutorial:
Vagrantfile (fragmento)
config.vm.provider "virtualbox" do |vb|
vb.memory = "2560"
vb.cpus = "2"
end
El resto del fichero son dos bloques de declaraciones que especifican para cada máquina virtual qué puertos se van
a pasar a través de NAT y el provisionamiento de software con Ansible.
El reenvío de puertos por NAT facilita la comunicación con las máquinas virtuales desde el anfitrión
y entre ellas del siguiente modo:
- Los puertos reenviados estarán disponibles en el localhost del anfitrión; por eso hay que asegurarse que
no hay ningún servicio de la máquina real con esos mismos puertos (de ahí el uso de 2223 y 2224 para SSH). - En VirtualBox, una máquina virtual puede salir al anfitrión mediante la dirección 10.0.2.2
(lógicamente localhost accede a la propia máquina virtual).
En cuanto a Ansible, todos los servidores utilizan el mismo playbook (stats.yml), así que para distinguir
entre servidor de aplicaciones y servidor de estadísticas se utiliza el concepto de grupo de hosts.
En concreto, el playbook define dos grupos:
- stats es el modelo de los servidores de estadísticas y por tanto se le asignan los roles de Ansible java8,
elasticsearch y kibana. - apps es el grupo de hosts que modela los servidores de aplicaciones, con lo que sus roles son java8,
appdeploy y logstash.
ansible/stats.yml
---
- hosts: stats
sudo: yes
gather_facts: yes
roles:
- java8
- elasticsearch
- kibana
- hosts: apps
sudo: yes
gather_facts: yes
roles:
- java8
- logstash
- appdeploy
Por otro lado se ha definido un inventario con dos máquinas cuyos nombres son los que aparecen en el
Vagrantfile, y cada una asignada a un grupo distinto: statsserver en el grupo stats y
appsserver en apps.
Esto está indicado en el fichero ansible/environments/tutorial/inventory:
ansible/environments/tutorial/inventory
[apps] appsserver [stats] statsserver
Con todo esto en mente, para poner en marcha las máquinas virtuales, desde el directorio elk-tutorial donde se
encuentra el Vagrantfile, ejecutaremos:
Terminal
$ vagrant up
La primera vez que lo hagamos se crearán las máquinas virtuales y se provisionarán automáticamente, así que más vale
armarse de paciencia.
Para abrir una shell en una de las máquinas virtuales podemos ejecutar el siguiente comando, reemplazando
nombre-servidor por statsserver o appsserver según deseemos:
Terminal
$ vagrant ssh nombre-servidor;
Cuando terminemos de jugar con nuestras máquinas virutales y deseemos detenerlas, el comando a ejecutar será:
Terminal
$ vagrant halt
Por último, para destruir las máquinas virtuales por completo debemos escribir el comando:
Terminal
$ vagrant destroy
4.3. Personalizando las máquinas virtuales
La manera correcta de cambiar la configuración de ELK es a través de las variables de los roles de Ansible.
De esta manera podremos replicar y recrear la nueva configuración tantas veces como sea necesario.
Las variables de roles tienen asignados valores por defecto en el fichero defaults/main.yml de cada uno de
los roles de Ansible (es decir, appdeploy, elasticsearch, kibana y logstash).
A modo de ejemplo, la configuración por defecto de Elasticsearch está en este fichero:
ansible/roles/elasticsearch/defaults/main.yml
---
# Define custom settings in a dictionary called "elasticsearch".
_es_default:
version: 2.2.0
user: elasticsearch
group: elasticsearch
nofile: 32000
cluster_name: ""
node_name: "{{ ansible_fqdn }}"
is_node_master: yes
is_node_data: yes
index_number_of_shards: 5
index_number_of_replicas: 1
bootstrap_mlockall: yes
http_host: _local_
network_host: _local_
http_publish_host: ""
http_publish_port: 0
transport_publish_host: ""
transport_publish_port: 0
unicast_nodes: []
minimum_master_nodes: 1
java_opts: ""
# Taken from rack-roles elasticsearch:
# Use 40% of memory for heap, ES will also use large amount of
# direct memory allocation, hopefully ending with a total around 50%
# of the whole available system memory.
java_heap_size: "{{ (ansible_memtotal_mb * 0.4) | round | int }}m"
path_conf: /etc/elasticsearch
path_data: /var/lib/elasticsearch
path_home: /usr/share/elasticsearch
path_logs: /var/log/elasticsearch
path_plugins: /usr/share/elasticsearch/plugins
plugins:
- { name: head, path: mobz/elasticsearch-head}
# Combines default and custom settings.
_es_combined: "{{ _es_default | combine(elasticsearch) }}"
Para sobreescribir cualquier valor por defecto del diccionario _es_default se debe definir un diccionario
elasticsearch en las variables del grupo de hosts stats (que es donde se despliega Elasticsearch).
En este tutorial ese fichero es ansible/environments/tutorial/group_vars/stats y contiene lo siguiente:
ansible/environments/tutorial/group_vars/stats (fragmento)
# ElasticSearch
elasticsearch:
version: 2.2.0
cluster_name: "tutorial-stats"
index_number_of_shards: 1
index_number_of_replicas: 1
minimum_master_nodes: 1
http_host: "0.0.0.0"
network_host: "0.0.0.0"
http_publish_host: "10.0.2.2"
http_publish_port: "{{ es_http_port }}"
transport_publish_host: "10.0.2.2"
transport_publish_port: "{{ es_transport_port }}"
unicast_nodes: "{{ es_unicast_nodes }}"
plugins:
- { name: "kopf", path: "lmenezes/elasticsearch-kopf/2.0" }
Para aplicar los cambios realizados en estos ficheros, ejecutaremos el
siguiente comando:
Terminal
$ vagrant provision
5. Uso de la plataforma
5.1. Lanzando la aplicación de ejemplo
Los roles de Ansible se aseguran de que los servicios ELK estén activos y preparados para ser utilizados.
Lo único que resta por hacer es ejecutar la aplicación de ejemplo desde la línea de comandos para que genere
mensajes de log durante unos segundos, por ejemplo 10:
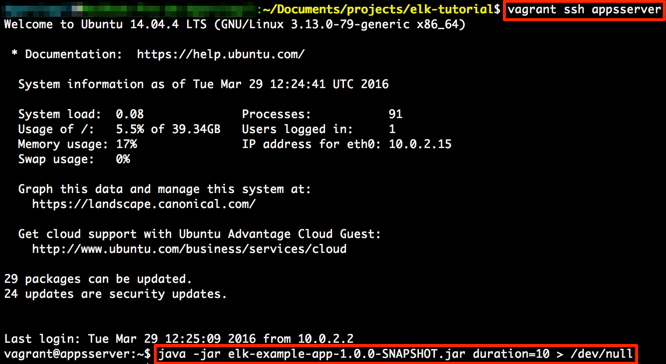
La redirección a /dev/null es para evitar que se vuelque todo el log por consola.
El código fuente de esta aplicación está en el directorio elk-example-app del repositorio
elk-tutorial.
De todas formas, la cuestión de cómo configurar el logging en Spring Boot está desarrollada en
este otro tutorial.
Al compilar con Maven, se genera un nuevo jar en el subdirectorio elk-example-app/target que debe llevarse
al directorio ansible para que Ansible lo despliegue la próxima vez que se fuerce un provisionamiento.
Los comandos para realizar todos estos pasos son:
Terminal
$ cd elk-example-app $ mvn clean install $ cd .. $ cp elk-example-app/target/elk-example-app-1.0.0-SNAPSHOT.jar ansible $ vagrant provision appsserver
5.2. Comprobando los resultados
Ahora vamos a ver los resultados de esta primera ejecución suponiendo que todo ha ido bien.
Más adelante explicaré cómo diagnosticar problemas en cualquiera de los puntos de la cadena.
En primer lugar, abrir una pestaña del navegador y entrar a
http://localhost:9200/_plugin/kopf.
Este es el cuadro de mandos del plugin Kopf para monitorizar y controlar el cluster de Elasticsearch.
Hacer clic en el check * special (1) para ver también los índices «especiales»:

Aunque ahora no es el momento de entrar en detalle, lo que se muestra aquí es una tabla donde:
- Cada fila es un nodo del cluster, más una fila especial para shards que no están asignadas
a ningún nodo. - Cada columna es un índice de Elasticsearch.
Un índice es una partición de toda la base de datos, un concepto similar a las particiones en bases de datos
relacionales clásicas. - Cada celda indica las shards de un índice en un nodo.
Una shard es una instancia de Lucene dentro de Elasticsearch, es decir, es un motor de búsqueda
autocontenido con sus datos, metadatos e índices.
Las shards pueden ser primarias o réplicas, es decir, las que se consideran «fuente» de los datos y las
que se consideran copias.
En segundo lugar, abrir otra pestaña en el navegador para entrar a Kibana en
http://localhost:5601/.
Tras unos segundos de carga, se mostrará un formulario para configurar los índices sobre los que busca Kibana:
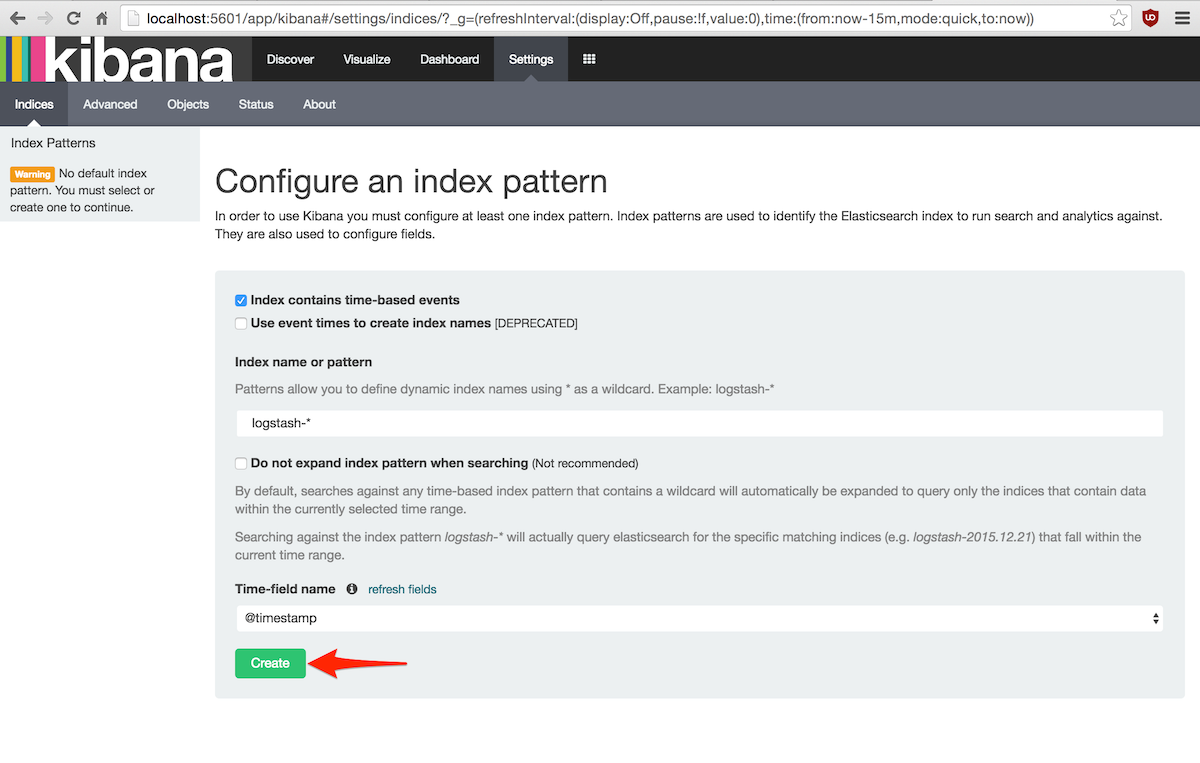
Salvo casos excepcionales, se pueden aceptar los valores por defecto y pulsar el botón Create,
lo que nos llevará a la pantalla de personalización de los campos de búsqueda:
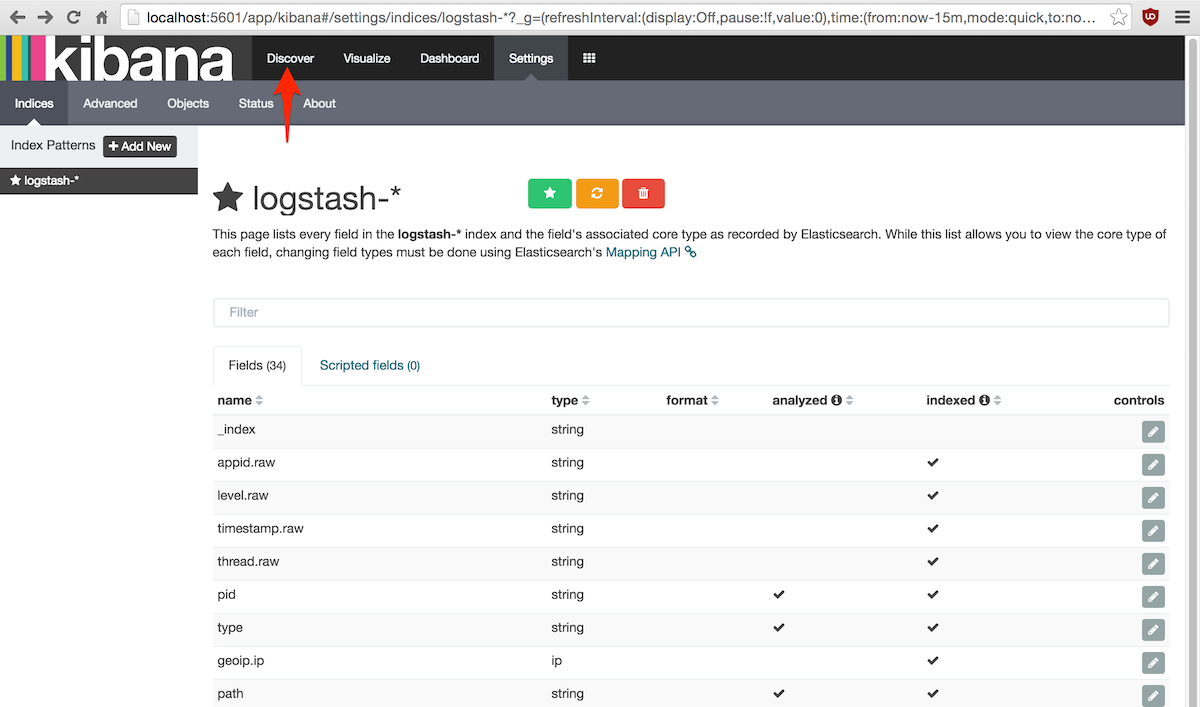
Aquí tampoco es necesario cambiar nada porque Logstash ya envía los mensajes de log procesados y estructurados
y Elasticsearch es capaz de inferir el tipo de los campos de tipos primitivos.
Estos ajustes también son útiles para personalizar el formato de visualización de campos en Kibana, por ejemplo
para limitar el número de decimales en los números en coma flotante.
Pulsar el enlace Discover para continuar.
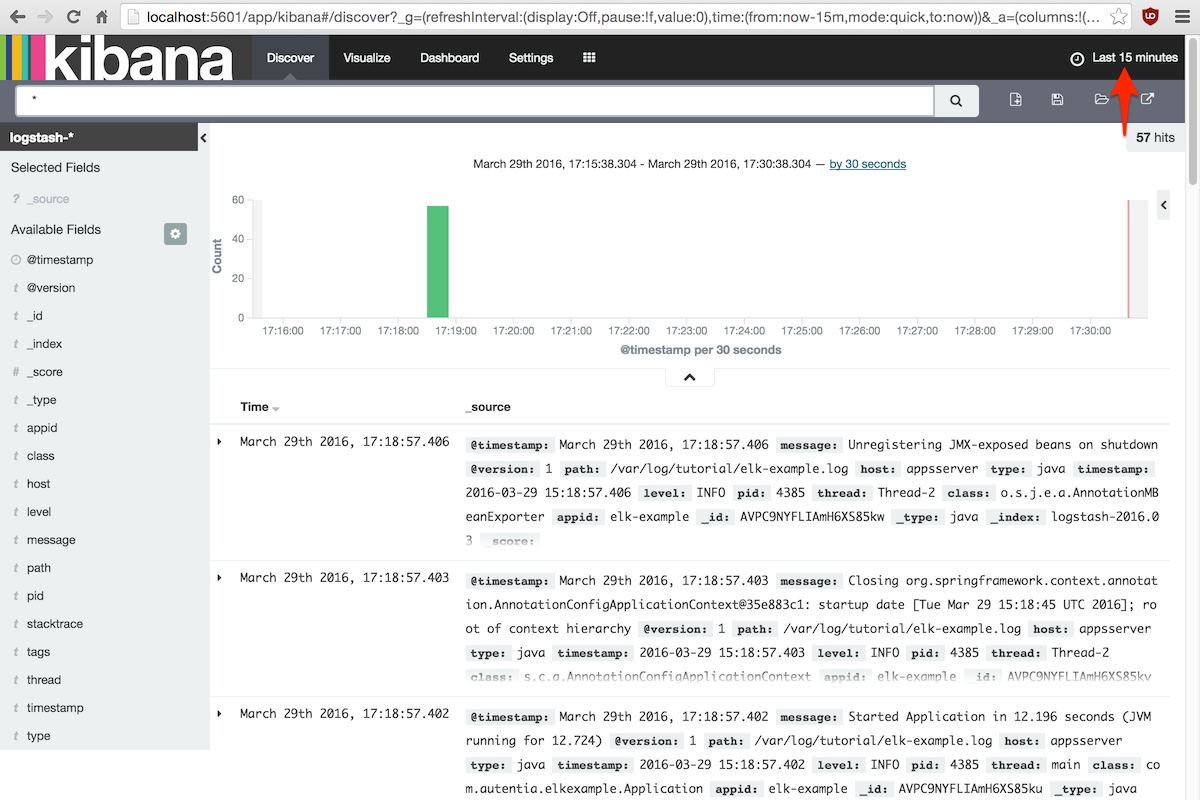
Tener en cuenta que Kibana no muestra todos los datos desde el principio de los tiempos, sino una ventana
que por defecto está fijada a los últimos 15 minutos.
Para cambiar la ventana temporal, pulsar el control Last 15 minutes y elegir el intervalo de tiempo
que más convenga.
Por descontado, se puede abrir cualquier evento para ver sus campos, añadir un valor de campo a un filtro,
añadir o quitar una columna del listado, etc:
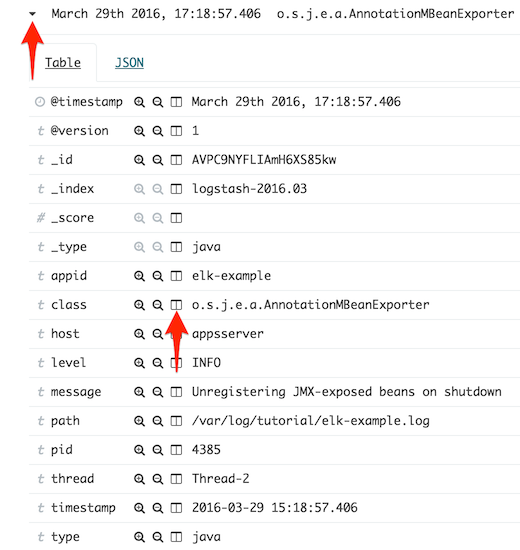
También se puede realizar una búsqueda introduciendo un filtro en la caja de texto principal, por ejemplo
para ver solamente los mensajes de nivel WARN:
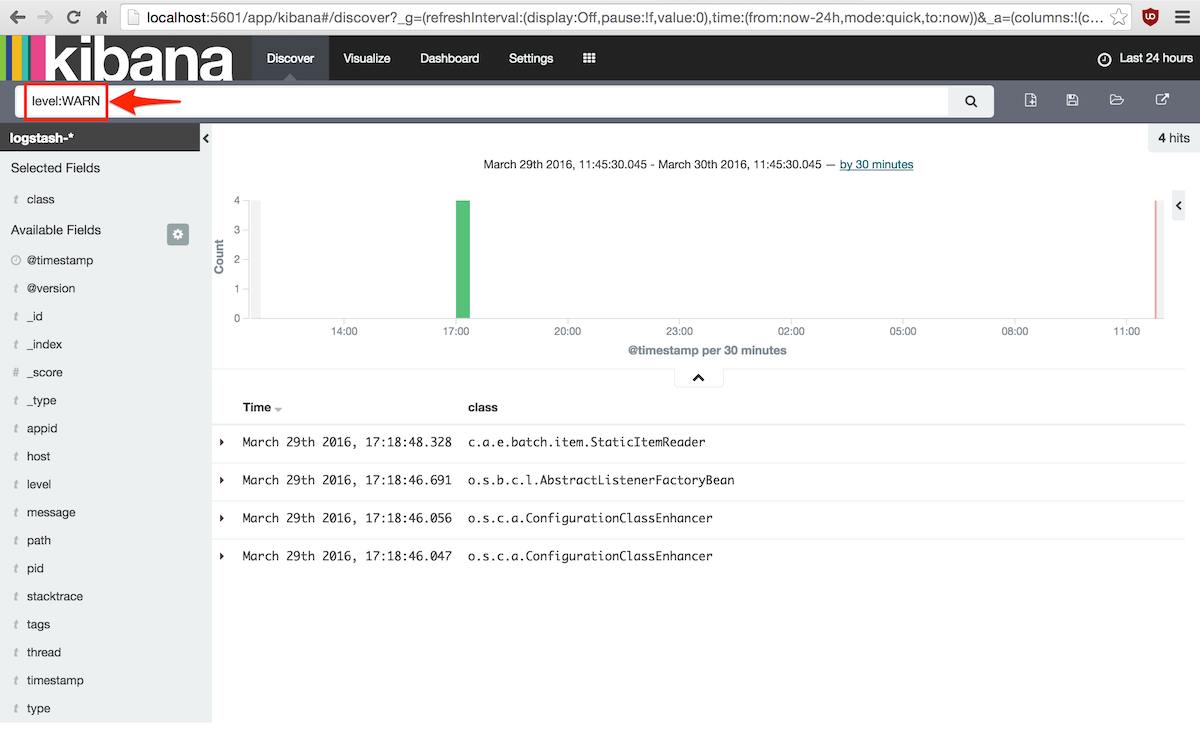
5.3. Siguiendo el proceso
Para conocer mejor el funcionamiento de la plataforma ELK, vamos a seguir todos los pasos del proceso de transmisión y
transformación de un mensaje de log.
Los detalles concretos de configuración de cada componente se explicarán en otros tutoriales de la serie.
El evento de log elegido ha quedado registrado en el fichero /var/log/tutorial/elk-example.log
de la máquina virtual appsserver como un warning de una excepción controlada por la aplicación:
/var/log/tutorial/elk-example.log (fragmento)
2016-03-29 15:18:48.328 WARN 4385 --- [main] c.a.e.batch.item.StaticItemReader : Ignoring exception...
java.lang.Exception: This is a random test exception because 0.012084067 < 0.10!
at com.autentia.elkexample.batch.item.StaticItemReader.read(StaticItemReader.java:59)
at com.autentia.elkexample.batch.item.StaticItemReader.read(StaticItemReader.java:15)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
... líneas omitidas por brevedad ...
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:54)
at java.lang.Thread.run(Thread.java:745)
Logstash consiste en un pipeline con tres fases: entradas, filtros y salidas.
En cada fase se pueden definir todos los componentes que se deseen, de modo que Logstash lee líneas de texto
de todas las entradas, las pasa por los filtros de manera secuencial y envía los resultados a las salidas.
En este tutorial Logstash se configura en el fichero ansible/environments/tutorial/group_vars/apps.
Primero se define un canal de entrada que extrae las líneas escritas en todos los ficheros de log
del directorio /var/log/tutorial.
A continuación las pasa por los filtros grok, date y mutate.
Y por último envía el resultado a la base de datos Elasticsearch.
En el ejemplo que estamos siguiendo, el filtro grok extrae campos del evento de log mediante una expresión regular:
- date = 2016-03-29 15:18:48.328
- level = WARN
- pid = 4385
- Y así sucesivamente con cada elemento.
El filtro date fija el formato de la fecha y el campo que debe utilizarse para ubicar el evento en el tiempo.
Por último, los filtros mutate realizan un poco de limpieza y extraen el campo appid a partir del
nombre del fichero de log (elk-example en este caso).
Elasticsearch recibe un objeto JSON con todos los campos del evento de log, pero eso no es todo.
Logstash también debe indicar en qué indice se guardará el mensaje (por meses según el patrón
logstash-%{+YYYY.MM}) y cuál es el mapping al que se ajustan dichos objetos, es decir,
la plantilla que determina la estructura de los objetos.
En el extremo final de la cadena, Kibana viene configurado para extraer datos de todos los índices que cumplan
el patrón glob logstash-*.
Por ejemplo podemos buscar el evento por fecha introduciendo la búsqueda exacta:
timestamp.raw:»2016-03-29 15:18:48.328″
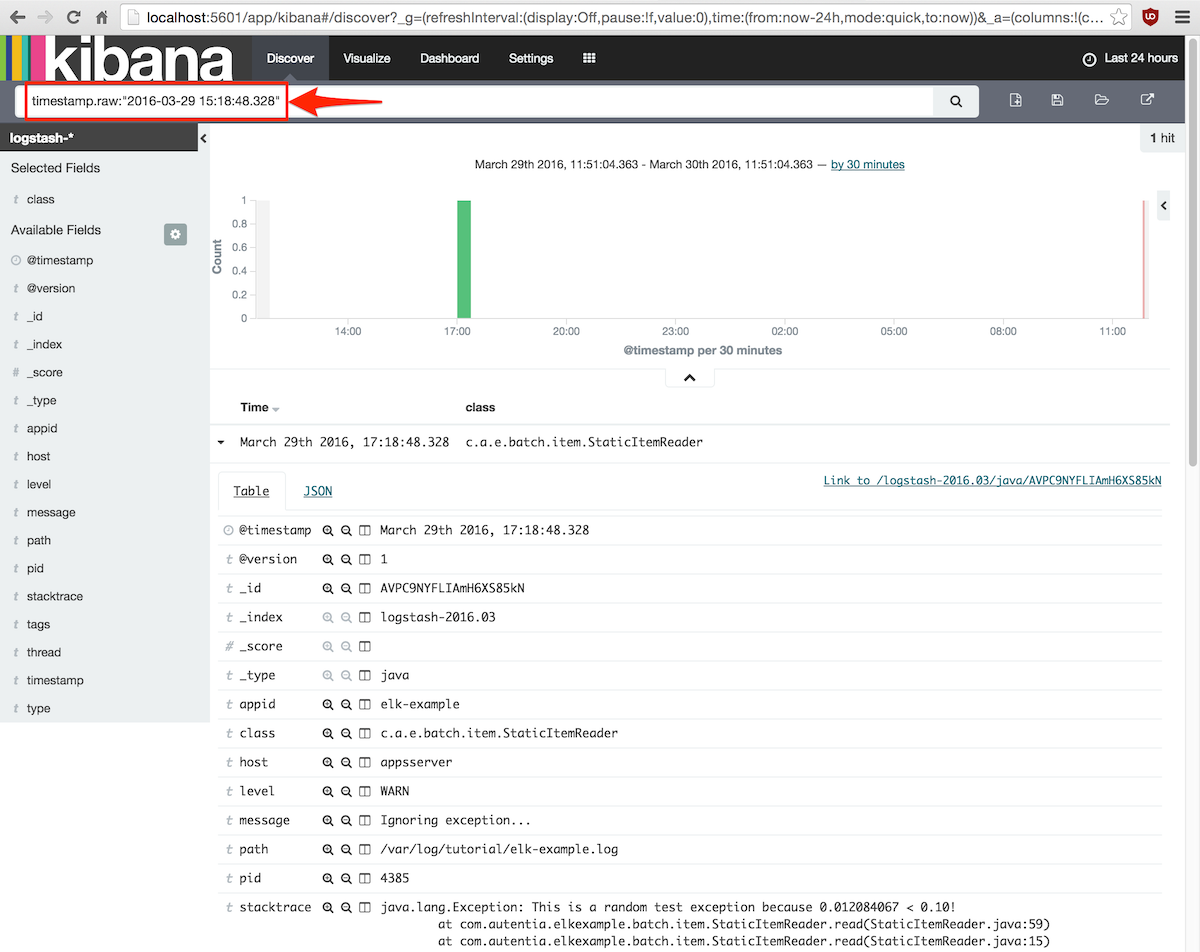
6. Conclusiones
Esta introducción a la plataforma ELK servirá de base para profundizar en cada uno de sus elementos en los
tres siguientes tutoriales de la serie.
También espero que haya servido para mostrar las posibilidades y potencial como mecanismo para el registro
de datos de carácter general (no sólo eventos temporales) y su posterior consulta directa o en forma
de tablas y gráficos de agregados.


muchas gracias, ojalá publiquen más tutoriales, estaría bueno ver casos de uso de ELK + machine learning..
[…] aplicaciones, deberíamos de ver la serie de tutoriales de mi compañero David donde habla de la monitorización de logs con Elasticsearch, Logstash y Kibana. Este tipo de monitorización es complementaria y específica de nuestra aplicación, mientras que […]
Hola, buen día.
Me gustaría saber si existe forma de monitorear las acciones de los usuarios en kibana.
Muchas gracias por el apoyo, un saludo.
Hola,
Kibana de por sí no ofrece ninguna medida de seguridad, ni siquiera autenticación.
Todas las características de seguridad forman parte de la suscripción de X-Pack (que ofrece muchas más cosas interesantes):
https://www.elastic.co/guide/en/kibana/current/xpack-security-audit-logging.html
https://www.elastic.co/subscriptions
Una alternativa es poner un proxy inverso frente a Kibana y ElasticSearch y configurar ahí la autenticación y autorización en base a patrones de paths. La auditoría serían los logs de peticiones a través de ese frontal.
Nginx es una muy buena opción.