
Framework para indexación
de documentos en Lucene: LIUS
Introducción
En este
tutorial, complementario del de Extracción
de texto de documentos Office desde Java,
vamos a ver como usar el framework LIUS (Lucene Index Update and
Search) para indexar documentos en el motor de busqueda textual
Lucene, de la Fundación Apache. El framework LIUS ha sido
desarrollado por autores franceses y está disponible en
Sourceforge, bajo licencia LGPL.
La
URL del proyecto es http://sourceforge.net/projects/lius/.
Este
tutorial asume que el lector conoce Lucene y lo ha usado alguna vez.
Si no es así, consultar el tutorial Primeros
pasos con Lucene.
Opinión
del autor sobre el framework
La
idea del framework en si es algo lógico, puesto que cualquiera
que haya usado Lucene alguna vez se habrá encontrado con la
misma carencia: Lucene es solo un motor de busqueda, pero nos falta
algo más para indexar y para manipular el motor de forma más
sencilla. En ese sentido, esta librería agrega una fina capa
por encima de Lucene para organizar el trabajo de extraer datos de
distintos tipos de documentos y mapear esos datos a campos de Lucene.
Además, el framework permite manipular mediante configuracion
XML que campos se crean, de que tipo, que analizadores se deben usar,
etc. En otras palabras: LIUS ofrece más comodidad a la hora de
configurar Lucene y decidir qué, cómo y dónde
indexamos.
Aunque
la idea es muy buena, se notan algunos fallos en el diseño y
la programación del framework que disminuyen su calidad y
pueden afectar a su mantenibilidad futura. No obstante, estos fallos
no nos deben preocupar como usuarios del framework porque la interfaz
entre el usuario y el framework está bien definida.
Entre
estos problemas detectados se dan:
-
Uso
pobre de interfaces y clases abstractas -
Uso
de constantes a pelo en el código -
Pésima
documentación (y además parte de ella sólo en
francés) -
Poco
uso de tipos de datos (muchas cosas se manejan directamente como
java.lang.Object)
Descripción
del framework
LIUS
se compone de una librería propia y de otras de terceros que
se usan para extraer texto de distintos tipos de documentos. En el
momento de escribir este tutorial, Lius es capaz de indexar los
siguientes tipos de documentos:
-
DOC
(MS Word 6.0/96/97/2000/XP): usando la librería Textmining de
Apache (http://www.textmining.org). -
XLS
(MS Excel 95/97/2000/XP/2003): usando la librería JExcelAPI
(http://jexcelapi.sourceforge.net/). -
PPT
(MS PowerPoint 95/97/2000/XP/2003): usando la librería POI de
Apache (http://poi.apache.org). -
RTF:
usando las rutinas de Java de manipulación de Rich Text
Format (javax.swing.text.rtf). -
PDF:
usando la librería PDFBox (http://www.pdfbox.org). -
XML:
usando el parser XML de Java (org.w3c.dom). -
HTML:
usando las librerías Jtidy (http://jtidy.sourceforge.net)
y NekoHTML (http://people.apache.org/~andyc/neko/doc/html). -
TXT:
usando un parser propio. -
SXW/ODT,
SXC/ODS, SXI/ODP (OpenOffice 1/2): usando el parser
de
XML de Java (org.w3c.dom). -
ZIP:
usando el procesador de ZIP de Java (java.util.zip). -
MP3:
usando las librerias de audio de Java (javax.sound.sampled). -
VCF
(VCard): usando un parser propio. -
Latex:
usando un parser propio. -
Java
Beans: usando reflexión.
Además,
LIUS se basa en ficheros XML de configuración que permiten
describir como se debe configurar Lucene para indexar y/o buscar en
los documentos. Lo normal es tener un solo fichero XML, pero se
pueden usar más para, por ejemplo, definir distintas formas de
indexar o buscar. En el fichero de configuración se puede
especificar:
-
El
analizador que debe usar Lucene. -
Los
parametros de creación del indice. -
Qué
datos se deben extraer de cada tipo de documento y a que campos de
Lucene se deben mapear. Por ejemplo, podemos decir que el contenido
de los PDFs lo meta en un campo de Lucene llamado content,
el
titulo en otro llamado title,
y el autor en el campo writer. -
Cómo
se deben configurar los campos de Lucene en los que se introducen
los datos. Por ejemplo, tenemos los siguientes tipos de campo:-
Text:
campo de texto almacenado y tokenizado. -
TextReader:
campo de tipo stream. -
Keyword:
campo de texto almacenado y no tokenizado. -
concatDate:
campo tipo fecha almacenado y no tokenizado. -
UnIndexed:
campo de texto almacenado y no indexado. -
UnStored:
campo de texto no almacenado y tokenizado.
-
-
Qué
boost
(peso) se
debe aplicar a cada campo y al documento entero. -
Qué
tipo de búsqueda se quiere emplear. De momento hay
disponibles:-
queryTerm: búsqueda por un
solo campo. -
rangeQuery: búsqueda de
rango por un solo campo. -
queryParser: usar el parser de
consultas de Lucene sobre un solo campo. -
multiFieldQueryParser: usar el
parser de consultas de Lucene sobre varios campos.
-
-
Qué
campos debe devolver la búsqueda y como formatearlos (si se
deben fragmentar o no y si se deben resaltar los términos
buscados).
Un
ejemplo
Para
el ejemplo vamos a hacer un programa que indexe todos los ficheros
contenidos en un directorio. Para ello primero debemos descargar el
proyecto Lius de http://sourceforge.net/projects/lius/.
Una vez descargado el fichero Lius-1.0.zip
lo
descomprimimos, con lo que obtendremos la siguiente estructura de
directorios:
-
classes
-
Config
-
doc
-
ExempleFiles
-
legal
-
lib
-
src
Ahora
crearemos un proyecto Java con nuestro editor favorito y le
añadiremos como librerías todos los JARs contenidos en
el directorio lib
de
Lius, así como el Lius-1.0.jar,
en el directorio principal. A continuación copiaremos los
ficheros log4j.properties
y
liusConfig.xml
del
directorio Config
de
Lius al directorio config
de
nuestro proyecto. Por último, copiamos los documentos del
directorio ExempleFiles/testFiles
a
un directorio llamado docs
dentro
de nuestro proyecto.
Ahora
creamos una clase Java que contenga el main()
con
el siguiente código:
-
package com.autentia.tutorial.lius; import java.io.File; import java.util.Collection; import java.util.List; import lius.LiusLogger; import lius.config.LiusConfig; import lius.config.LiusConfigBuilder; import lius.config.LiusDocumentProperty; import lius.config.LiusField; import lius.index.Indexer; import lius.index.IndexerFactory; import lius.search.LiusHit; import lius.search.LiusHitList; import lius.search.SearchIndex; /** * * @author ivan */ public class Lius { // Directorio donde se creara el índice de Lucene private final String indexDir = "index"; // Localización del fichero de configuración de LOG4J private final String log4jFile = "config/log4j.properties"; // Localización del fichero de configuración de Lius private final String configFile = "config/liusConfig.xml"; private LiusConfig config; /** * @param args the command line arguments */ public static void main( String[] args ) { try { new Lius( ).run( ); } catch( Throwable t ) { t.printStackTrace( ); } } /** * */ private void run( ) throws Exception { // Inicializamos LOG4J LiusLogger.setLoggerConfigFile( log4jFile ); // Leemos el fichero de configuración de Lius config = LiusConfigBuilder.getSingletonInstance( ). getLiusConfig( configFile ); // Recorremos los ficheros del directorio docs File filesDir = new File( "docs" ); File[] files = filesDir.listFiles(); for( File file : files ) { // Indexamos el fichero index(file); } } // Método para indexar ficheros private void index( File file ) { log( "-------------------------------------------------" ); log( "FILE: " + file.getName( ) ); Indexer indexer = IndexerFactory.getIndexer( file, config ); debug( indexer ); indexer = IndexerFactory.getIndexer( file, config ); indexer.index( indexDir ); } // Metodo para volcar información de depuración por pantalla private void log( String msg ) { System.out.println( msg ); } // Metodo para volcar la información obtenida de un indexador private void debug( Indexer indexer ) { log( "INDEXER: " + indexer.getClass( ).getName( ) ); log( "FIELDS: " ); Collection c = indexer.getPopulatedLiusFields( ); for( Object o : c ) { if( o instanceof LiusField ) { // Campo Lucene LiusField o2 = (LiusField) o; log( " FIELD: " + o2.getGet( ) + "." + o2.getGetMethod( ) + " <" + o2.getName( ) + "> = " + o2.getValue( ) ); } else if( o instanceof LiusDocumentProperty ) { // Valor boost para el documento Lucene LiusDocumentProperty o2 = (LiusDocumentProperty) o; log( " BOOST: " + o2.getBoost( ) ); } else { // Otros datos log( " " + o ); } } } }
Y la ejecutamos, con lo que nos creará un índice de
Lucene en el directorio index.
Ahora podemos ver los contenidos de ese ínidice con la
herramienta Luke, que podemos descargar de
http://www.getopt.org/luke/.
Esta aplicación visual permite manipular el índice y
ver los contenidos internos. Al arrancarla y abrir el indice creado
debemos ver lo siguiente:
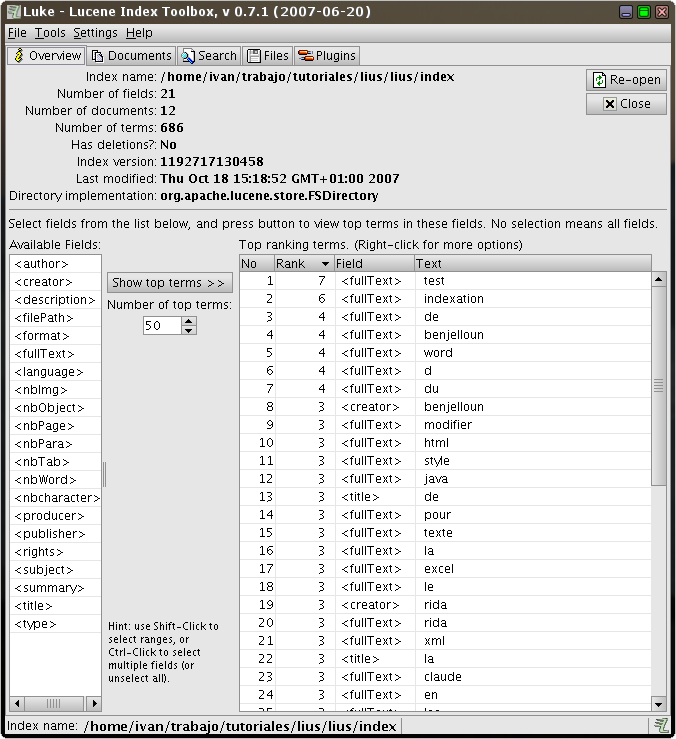
Si pulsamos en la pestaña
podremos ver los documentos Lucene que ha creado Lius (debería
haber un documento Lucene por cada documento binario indexado del
directorio docs). En
la siguiente imagen se muestra el resultado de la indexación
del documento testPDF.pdf:
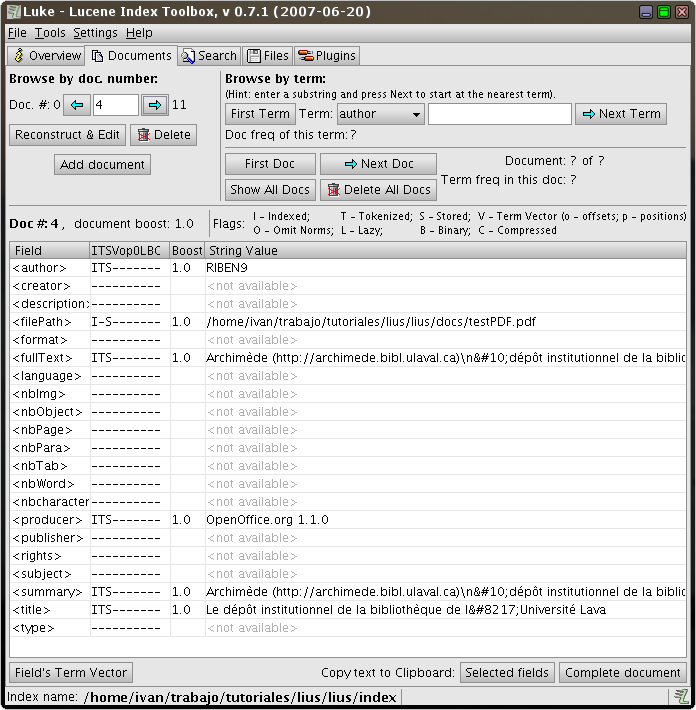
Como es fácil
adivinar, los campos Lucene creados para este PDF han sido definidos
en el fichero liusConfig.xml y
su contenido extraido del fichero PDF en si. La parte que configura
esta extracción es:
Donde
podemos ver como se mapean los campos que extrae la clase
lius.index.pdf.PdfIndexer
de
los ficheros PDF (atributo get)
a los campos de Lucene (atributo name)
y, ademas, como se deben almacenar (atributo type).
Referencía
de extractores y campos que proveen
En
este capítulo se listan los extractores disponibles y los
campos que proveen para ser mapeados a campos de Lucene.
|
Extractor |
Campos |
Observaciones |
|
lius.index.application.TexIndexer |
documentclass title author content abstract |
|
|
lius.index.application.VCardIndexer |
name title nickname birthday notes phone homephone workphone cellphone categories address homeaddress workaddress url organization |
Hay que cambiar la clase y el Hay que modificar las siguientes <indexer class="lius.index.application.VCardIndexer">
<mime>text/x-vcard</mime>
<mime>text/directory</mime>
...
</indexer>
|
|
lius.index.audio.MP3Indexer |
channels channelsmode version samplingrate layer emphasis nominalbitrate duration location size copyright crc original vbr track year genre title artist album comments |
|
|
lius.index.excel.ExcelIndexer |
content |
|
|
lius.index.html.JTidyHtmlIndexer |
content [nodo por nombre de etiqueta] |
Ejemplos de nombre de etiqueta: Estos nodos tienen que ser de tipo HTML que contengan texto |
|
lius.index.html.NekoHtmlIndexer |
[nodos denominados por una expresion XPath] |
Ejemplo: “//*” recupera todo el documento |
|
lius.index.javaobject.BeanIndexer |
Indexador propio que mapea getters a campos de Lucene. |
Ejemplo de uso: BeanIndexer idx = new BeanIndexer(); idx.setUp(configurationObject); idx.setObjectToIndex(unObjetoJavaBean); idx.index(“directorioDelIndiceLucene”); |
|
lius.index.mixedindexing.MixedIndexer |
Este indexador analiza todos los ficheros contenidos en un |
Ejemplo de uso: MixedIndexer idx = new MixedIndexer();
idx.setUp(configurationObject);
idx.setMixedContentsObj(new File("directorioAIndexar"));
idx.index(“directorioDelIndiceLucene”);
|
|
lius.index.msword.WordIndexer |
content |
|
|
lius.index.openoffice.OOIndexer2 |
[nodos denominados por una expresion XPath] |
Hay que saberse la especificacion En el fichero de configuración liusConfig.xml se |
|
lius.index.pdf.PdfIndexer |
content title author creator summary keywords producer subject trapped creationDate modificationDate |
|
|
lius.index.powerpoint.PPTIndexer |
content |
|
|
lius.index.rtf.RTFIndexer |
content |
|
|
lius.index.txt.TXTIndexer |
content |
|
|
lius.index.xml.XMLFileIndexer |
[nodos denominados por una expresion XPath] |
A la hora de configurar las reglas de mapeo XML-Lucene en el |
|
lius.index.zip.ZIPIndexer |
|
Este indexador analiza todos los ficheros contenidos en un |
Cómo buscar en el índice
Finalmente, veremos como está configurada la búsqueda
en el fichero liusConfig.xml por defecto y como se usan las
clases de búsqueda de Lius. Ni que decir tiene que no es
obligatorio usar estas clases, pero algo de ayuda si que aportan,
haciendo más fácil buscar y presentar los resultados.
Además, se pueden configurar los resultados de las busquedas
en el fichero de configuración sin necesidad de tocar el
código.
Primeramente veremos como está configurada la búsqueda
en el liusConfig.xml de
ejemplo:
-
<search> <multiFieldQueryParser> <searchFields sep=",">title,subject,creator,description,publisher,contributor,fullText</searchFields> </multiFieldQueryParser> </search> <searchResult> <fieldsToDisplay setHighlighter="true"> <luceneField name="title" label="title"/> <luceneField name="subject" label="subject"/> <luceneField name="creator" label="creator"/> <luceneField name="fullText" label="full text" setFragmenter="15"/> </fieldsToDisplay> </searchResult>
Se distinguen dos apartados:
-
search: define que
parser hay que usar para procesar la sentencia de búsqueda de
Lucene (multiFieldQueryParser)
y sobre que campos buscar (searchFields). -
searchResult: define
que campos se devuelven en la búsqueda (fieldsToDisplay)
y si se usan “highlighters” o “fragmenters”. El
“highlighter” rodea los términos buscados por <span
class=»liusHit»></span> de
forma que se pueda mostrar directamente en una página HTML,
redefiniendo el estilo liusHist para
que muestre el texto resaltado en el color que queramos. El
“fragmenter” permite no mostrar el texto entero del campo, sino
sólo unas pocas palabras alrededor de los términos
buscados (para campos muy largos). Los trozos omitidos por el
“fragmenter” se sustituyen por puntos suspensivos.
Para realizar una búsqueda
usamos el siguiente código (se puede sustituir el metodo run()
de la clase de arriba por éste):
-
private void run( ) throws Exception { LiusLogger.setLoggerConfigFile( log4jFile ); config = LiusConfigBuilder.getSingletonInstance( ). getLiusConfig( configFile ); // Buscamos la cadena "institutionnel" en los campos configurados en liusConfig.xml LiusHitList ls = SearchIndex.search( "institutionnel", indexDir, configFile ); System.out.println( "Numero de documentos hallados = " + ls.size( ) ); for( int i = 0; i < ls.size( ); i++ ) { LiusHit lh = (LiusHit) ls.get(i); System.out.println( "--- Documento "+i+" ---" ); System.out.println( "Puntuacion = " + lh.getScore( ) ); System.out.println( "Identificador = " + lh.getDocId( ) ); List liusHitFields = lh.getLiusFields( ); for( int j = 0; j < liusHitFields.size( ); j++ ) { LiusField lf = (LiusField) liusHitFields.get(j); String name = lf.getLabel( ); String[] values = lf.getValues( ); System.out.print( name + " : " ); for( int k = 0; k < values.length; k++ ) { System.out.println( "\t" + values[k] ); } } System.out.println( "---------------------" ); } }
Como vemos, el fichero
liusConfig.xml sólo
permite una búsqueda, sin embargo, dado que el responsable de
cargar la configuración es el usuario de Lius, se pueden crear
varios ficheros con configuraciones para distintas búsquedas y
cargar uno u otro al buscar.
Conclusiones
Como hemos dicho al principio, Lucene es un excelente motor de
búsqueda textual, pero sólo eso. Cualquiera que haya
usado Lucene sabrá que, además de Lucene, se necesita
código que transforme nuestros datos a campos de Lucene. Por
hacer una analogia con los buscadores web Lucene sería como el
motor de busqueda y Lius como los bots que navegan la red procesando
sus contenidos para introducirlos en la base de datos del motor de
búsqueda.
Así pues, desde Autentia recomendamos (y de hecho usamos en
nuestros proyectos) este framework para proyectos basados en Lucene.
Por un lado organiza bastante el código y, por otro, es
fácilmente extensible y modificable al ser de código
abierto.
Por último, remarcar que, aunque este framework está
orientado a la indexación en Lucene, no debemos perder de
vista que también puede ser util para otros proyectos en los
que se necesite extraer texto de documentos binarios.


Excelente Informacion lamentable que sea la unica informacion que encontre en la red sobre este Framework si conocen algun sitio donde encontrar tutoriales ya que soy nuevo en java se los agradeceria mucho. De antemano Gracias! …