
Primeros pasos con Lucene
Cuando trabajamos con proyectos serios, ya sea en C++, Java, C# u otros, existen numerosas problemáticas que
hay que afrontar: Login único (SSOn), reportes, motores de búsquedas, workflow, etc. Existen soluciones comunes para todas estas problemáticas y os voy a
recomendar que siempre echéis un vistazo a un Web maravilloso
www.java-source.net (por lo menos te
los pone todos juntitos)
Hoy, vamos a a abordar el problema de las búsquedas avanzadas en nuestro
sistema (a través de la indexación paramétrica combinada con la extracción de
textos planos ) y para ello vamos a usaer una de las herramientas más extendidas: Lucene. Aunque hay decenas de tutoriales en Internet
sobre Lucene (aunque hay poco de la versión 2.0), una de las cosas que siempre
hay que tener a mano son buenos libros: Uno de ellos es
http://www.lucenebook.com/ .
Este mini-tutorial (recordad que los tutoriales son capturas según hacemos
nuestro trabajo en www.autentia.com
o autoformación/investigación y no son un objetivo en si mismo) habla de las
herramientas y requiere de algunos conocimientos teóricos. Podéis visitar este
otro tutorial que seguro que os encantará
http://ict.udlap.mx/people/carlos/is346/admon08.html .
Descarga de Lucene
Lo primero que debemos hacer es descargarnos el producto. Con esto debemos
ser cuidadosos ya que la versión a elegir es importante. Pronto descubriréis que
estar siempre a la última tiene su coste.
Vamos a empezar con Lucene 2.0
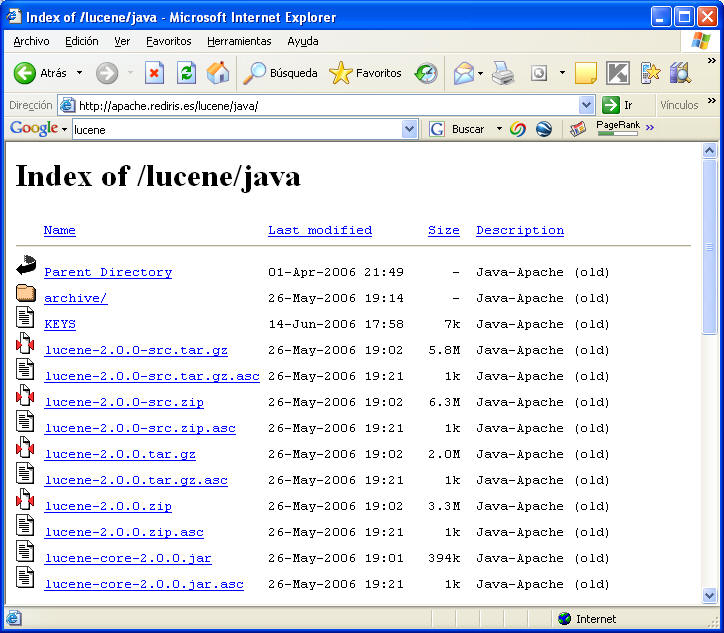
Elegimos el fichero deseado.
Arrancamos NetBeans 5 y creamos un nuevo proyecto en el que realizaremos las
pruebas básicas.
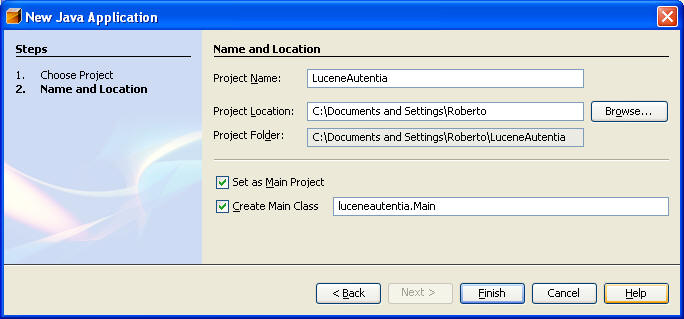
Elegimos una aplicación Java en en Wizard de NetBeans
Asignamos el nombre de proyecto: LuceneAutentia
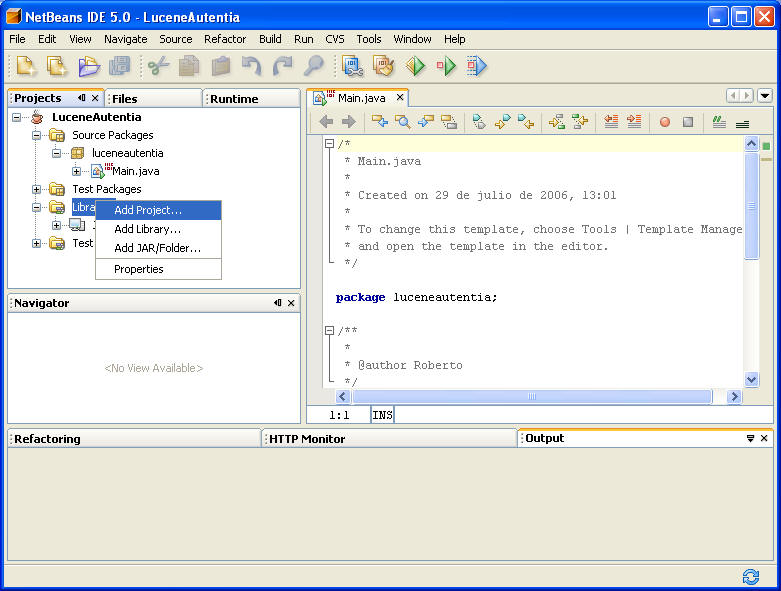
Añadimos los ficheros jar de lucene al proyecto. Ojo, que casi todas las
consultas que me hace la gente en
www.adictosaltrabajo.com, son por esta misma causa: problemas con el
classpath
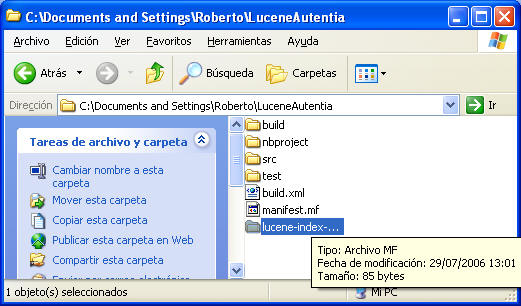
Creamos un directorio que servirá de repositorio para la
indexación
Y ahora escribimos nuestra aplicación (ojo que es para Lucene 2.0 y os puede
chocar un poco la parte en azul)
| /* * Created on 29 de julio de 2006, 13:01 * * Roberto Canales Mora * www.adictosaltrabajo.com */ package luceneautentia; import java.io.IOException; /** public Main() { public static void main(String[] args) { gestorLucene ejemplo = new gestorLucene(); Document persona1 = ejemplo.crearDocumento(«Carlos»,»Autentia»,»www.autentia.com»,»655991172″); try } } } class gestorLucene void indexar(Document documento) throws Exception Analyzer analizador = new StandardAnalyzer();
Document crearDocumento( String nombre, String empresa, String Document document = new Document(); return document; } |
Usaremos Luke – Lucene Index Toolkit
Para asegurarnos si ha funcionado o no, vamos a descargarnos
un monitor que nos permita navegar (e incluso consultar y modificar) la
información indexada: Luke – Lucene Index Toolkit
Para arrancarlo (una vez descargado), hacemos doble-click en
el jar (si estamos en entorno Windows) o ejecutamos la siguiente línea de
parámetros.
java -jar lukeall.jar
El aspecto es bastante intuitivo, si estamos acostumbrados
a distintos productos de administración de bases de datos.
Elegimos el directorio de indexación:
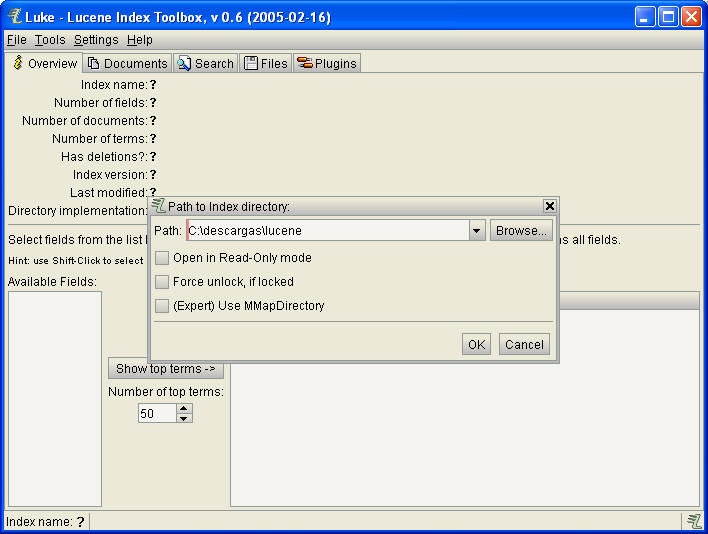
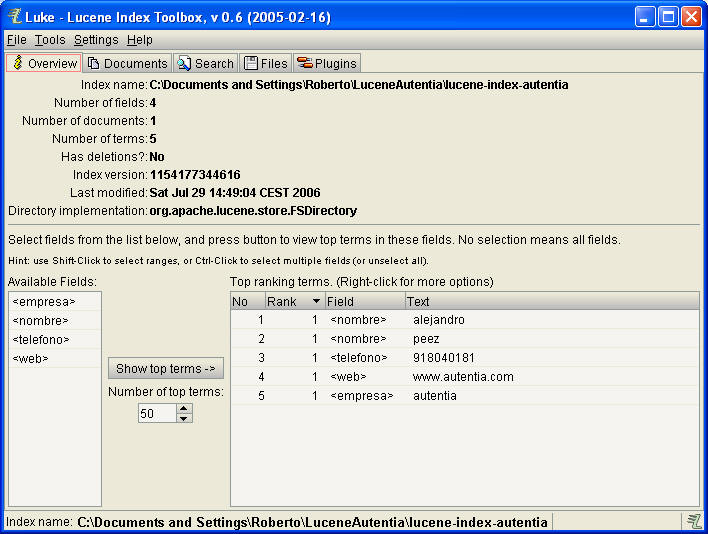
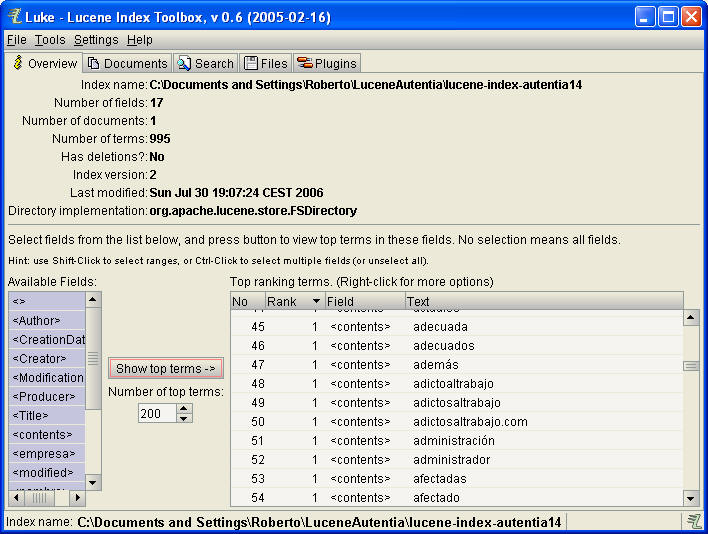
Y comprobamos que los datos se han indexado correctamente. Luke es una
herramienta estupenda para entender (a través de prueba y error) los distintos
tipos de almacenamiento, indexación y descomposición de campos.
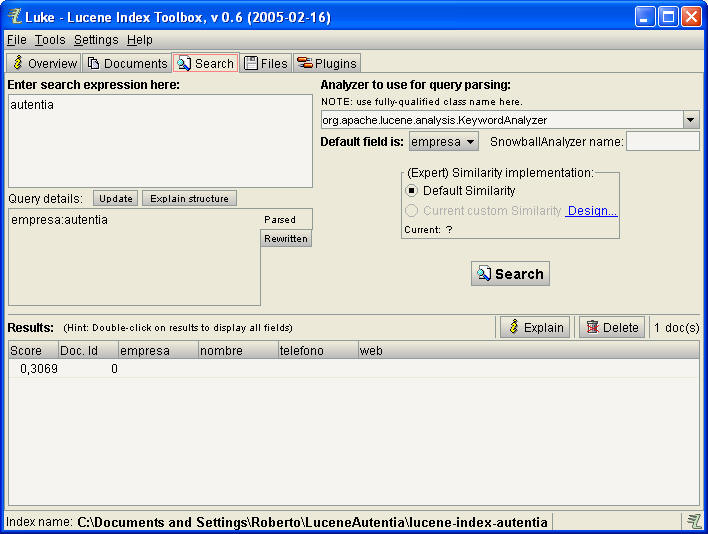
Realizamos una sencilla consulta para ver si recuperamos los elementos
deseados (abajo)
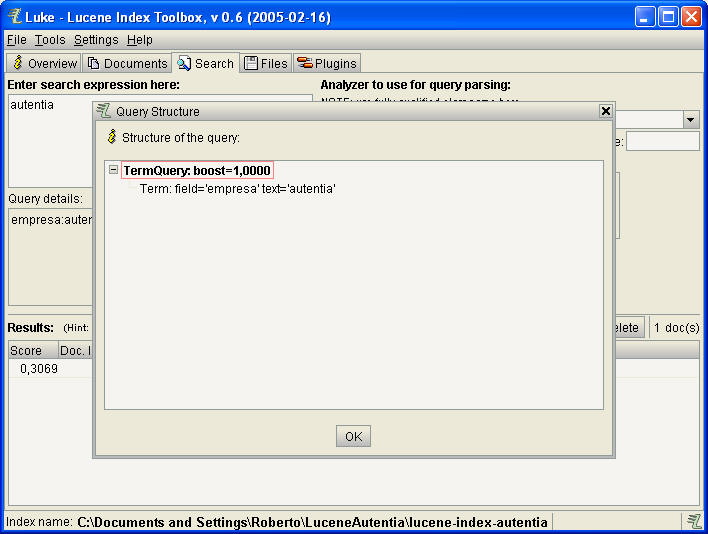
E incluso podemos examinar la estructura de la consulta, fundamental para
escribir nuestros código Java cliente.
Indexación de un PDF
Ahora, vamos a hacer una pequeña mejora, que consiste en
indexar, junto a nuestra información viva, el contenido de un fichero PDF (que
no sea una imagen escaneada de texto, claro).
Para ello usaremos una de las APIs más extendidas PDFBOX (recordar
que ya tenemos otros tutoriales que hablan del tema)
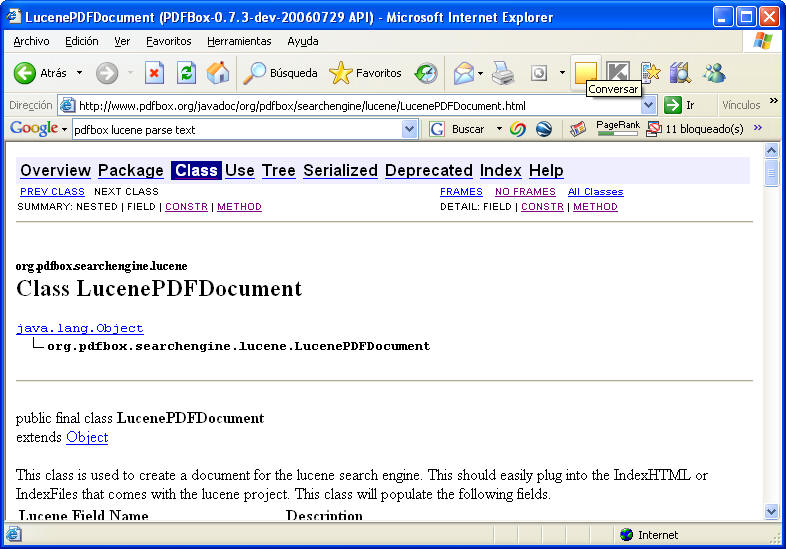
Veremos que hay unas clases, que ya incorporan la integración con Lucene, es
sorprendente lo que se lo curra la gente.
Si intentamos integrar con nuestro programa que usa la versión 2.0 de Lucene.
| try { document = LucenePDFDocument.getDocument(new File(«c:\\chumano.pdf»)); //Document document = new Document(); |
Nos aparece el siguiente error, claramente predecible, ya
que si elegimos estar a la última, hay algunos problemas que tenemos que
pagar … Los productos tardan un tiempo en dar el salto de una versión a
otra. PDFBox está utilizando internamente una versión anterior del jar de
Lucene.
| Exception in thread «main» java.lang.NoSuchMethodError: org.apache.lucene.document.Field.UnIndexed(Ljava/lang/String;Ljava/lang/String;)Lorg/apache/lucene/document/Field; at org.pdfbox.searchengine.lucene.LucenePDFDocument.getDocument(LucenePDFDocument.java:167) at luceneautentia.gestorLucene.crearDocumento(Main.java:82) at luceneautentia.Main.main(Main.java:39) Java Result: 1 BUILD SUCCESSFUL (total time: 3 seconds) |
Los cambios son mínimos (en nuestro caso) y se producen a la
hora de dar de alta objetos. En versiones más antiguas de lucene tenemos que
usar los siguiente métodos:
| Keyword: El dato es almacenado e indexado pero no particionado. Esto interesa cuando el dato es relevante pero no interesa particionarlo, por ejemplo, una fecha. Text: El campo es guardado, indexado y particionado. Este campo no debe ser utilizado con textos muy grandes porque se guardará el original y las partes. UnStored: El dato no es almacenado pero si indexado y particionado. Adecuado para grandes textos. UnIndexed: El dato es almacenado pero no indexado ni particionado. Este es el caso de una URL, nos interesa tenerla a mano pero no indexarla o partirla |
Nos bajamos un jar anterior 1.4.x y rehacemos un poquito el
código
| /* * Roberto Canales Mora * www.adictosaltrabajo.com */ package luceneautentia; import java.io.IOException; /** public Main() { public static void main(String[] args) { gestorLucene ejemplo = new gestorLucene(); Document persona1 = ejemplo.crearDocumento(«Carlos try } } } class gestorLucene void indexar(Document documento) throws Exception Analyzer analizador = new StandardAnalyzer();
Document crearDocumento( String nombre, String empresa, String try document = //Document document = new Document(); } } return document; |
Volvemos a arranca Luke y veremos que, efectivamente el PDF está indexado.
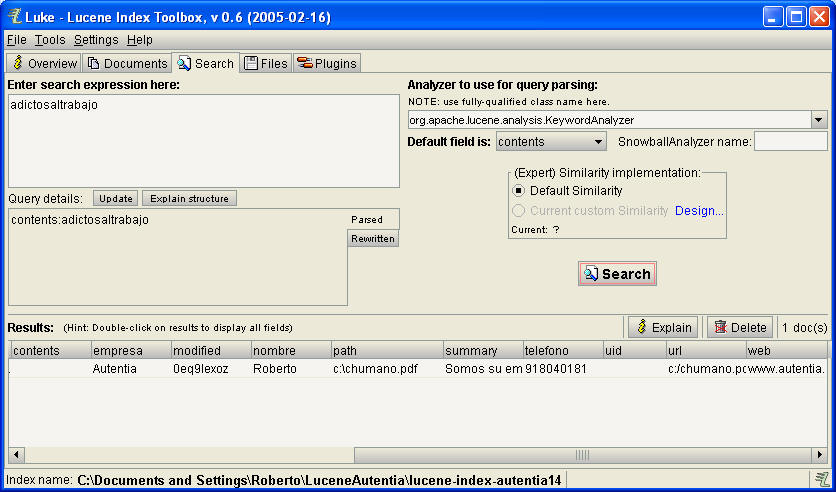
Y podemos recuperar los documentos por los textos que contienen
los pdfs, con una consulta simple (la misma que haríamos desde Java)
Deberes avanzados
Para realizar una buena indexación, es necesario ser consciente del lenguaje
de los documento. En nuestro caso es el Español. Os dejo un par de enlaces a
seguir:
http://www.mail-archive.com/lucene-user@jakarta.apache.org/msg09151.html
package spanishfilestemmer; import org …
Lius
Bueno, es bastante posible que muchas de las cosas que queramos
hacer, ya estén inventadas, os recomiendo que os reviséis algunos otros
proyectos relacionados con el mundo de los buscadores …
Conclusiones
Cada día es mayor el número de datos a manejar. Cuanto mayor es la
información, más difícil es encontrarla (no confundir información con
conocimiento). Integrad un motor de búsqueda en vuestras vidas (desarrollos).
Recordad una cosa: El que conoce como funciona un producto, posee un valor
táctico. El que además entiende por qué funcionan los productos, posee un valor
estratégico. El personal de www.autentia.com
compartimos el conocimiento táctico pensando en que un buen estratega
considerará que es más barato llamarnos para temas avanzados que invertir las
mismas horas y cometer los mismos errores que nosotros …. despistando los
objetivos de negocio (necesidades de cliente).

