

Introducción
Las tecnologías del habla, son aquellas que buscan asimilar el habla humana (imperfectas), dando paso a los sistemas de diálogo hablado (SDH) que las usan como medio de comunicación con el usuario. En la actualidad existen diferentes tecnologías del habla, como lo son:
- El reconocimiento automático del habla.
- La síntesis de voz mejor conocida por “Texto a Voz”.
- La autentificación del locutor.
- La identificación del lenguaje.
- El entendimiento del lenguaje natural, entre otras.
Para efectos del presente artículo se describen las tecnologías del habla más comúnmente empleadas por los sistemas de diálogo hablado como lo son “El reconocimiento automático del habla” y “La síntesis de voz”. De igual forma se describirán las limitaciones, errores y desafíos a los que se enfrentan estas tecnologías.
1. El Reconocimiento Automático del habla
El reconocimiento automático del habla (Automatic Speech Recognition: ASR) soportado por computadora, busca reconocer las palabras producidas por el usuario para realizar una alguna tarea específica. Mediante la información análoga de un canal de audio que percibe el habla humana, el audio es transferido al ASR para que este realice una transcripción digital de la señal y la interprete (ver [1] para mayor información sobre este proceso). Dicho de otra forma, la computadora capta el habla producida por el usuario y la analiza para procesarla y generar un resultado que se aproxime a lo hablado por el usuario. Para llevar a cabo el reconocimiento automático del habla, es necesario emplear un conjunto de técnicas que nos permitan obtener una aproximación fiable de la palabra o frase pronunciada por el usuario.
En la figura 1, se muestran los principales componentes de un sistema de reconocimiento automático del habla, en esta figura se aprecia que el habla obtenida del usuario es transformada en una señal digitalizada (normalmente dividida en frecuencias de voz de 10 a 20 milisegundos cada una) y analizada para obtener un conjunto de métricas que permitan la búsqueda de la palabra más adecuada. Esta búsqueda emplea modelos acústicos, léxicos y de lenguaje que se asocian al comportamiento de un lenguaje y son soportados por un conjunto de datos de voz previamente empleados para entrenamiento [2].
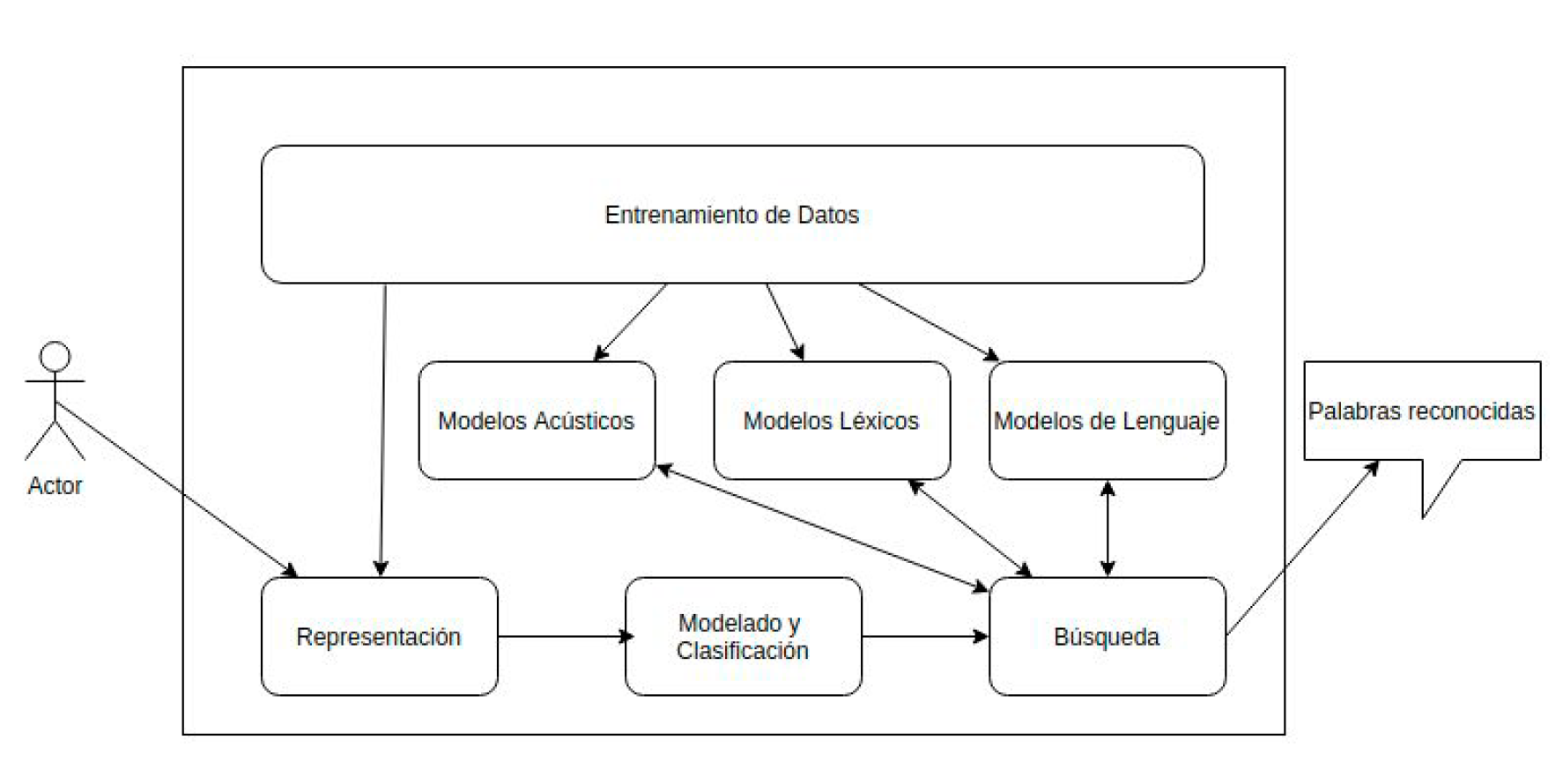
Figura 1. Componentes de un sistema típico de reconocimiento automático del habla.
Cabe hacer mención, que un ASR puede estar especializado para el trabajo con un solo usuario (dependencia del locutor) o para diferentes tipos de usuarios (independencia del locutor), estos sistemas ASRs son descritos a continuación.
1.1 Dependencia del locutor
En la dependencia del locutor se requiere de un proceso de entrenamiento con la voz del usuario final. Durante el entrenamiento el sistema solicita al usuario que haga la pronunciación de una serie de frases o palabras para un posterior almacenamiento de información auditiva, la cual es resultado del análisis de su voz. Una vez terminado el entrenamiento, el usuario puede hablar de manera libre, continúa y espontánea para que el reconocedor procese su habla y devuelva un resultado aproximado a las palabras que el usuario pronunció. Un ejemplo de sistemas populares que emplean dependencia del locutor son el sistema Dragon Dictate de la compañía Nuance. Estos sistemas permiten al usuario realizar el dictado de algún documento en las aplicaciones de MS Office o con las aplicaciones de un sistema operativo como lo es el escritorio de MS Windows.
Una evaluación comparativa entre ASRs comerciales en español como lo son ViaVoice de IBM, Dragon Naturally Speaking de Nuance, FreeSpeech de Phillips Speech Product y Voice Xpress Professional de L&H fue realizada por los laboratorios de PC Magazine (PC Labs). Sus resultados argumentan que el reconocimiento del habla con dependencia del locutor llega a alcanzar desde 95% hasta 98% de precisión en el proceso del reconocimiento del habla [3].
1.2 Independencia del locutor.
En la independencia del locutor, el ASR analiza el habla humana para reconocer las palabras dichas sin tener una especialización particular en alguna persona, es decir, puede reconocer el habla de diferentes personas. En este proceso no existe un entrenamiento especializado por cada usuario.
Un ejemplo de sistemas que emplean independencia del locutor son los servicios de reservaciones de aviones o trenes que hacen uso del reconocimiento de voz. Estos sistemas atienden a diferentes tipos de personas las cuales tienen diferentes formas o estilos de hablar ante el sistema.
Víctor Zue, director asociado de los laboratorios del MIT y considerado como uno de los pioneros en la investigación de las tecnologías del habla, argumenta: “El alto desempeño en el reconocimiento del habla independiente del locutor es posible. Los sistemas de reconocimiento del habla comerciales están ahora disponibles, pero la tasa de errores es aún más alta que 10 veces la de los humanos, aún para tareas simples” [4].
1.3 Errores en el reconocimiento automático del habla
El reconocimiento automático del habla no es perfecto y pueden ocurrir errores durante la realización de sus tareas. En el trabajo expuesto en [1]se muestran los diferentes tipos de errores que pueden ocurrir durante el proceso de reconocimiento del habla, estos errores se describen en la tabla 1.
|
Error |
Descripción del error |
|
Borrado |
La palabra o frase es ignorada cuando la persona habló en voz baja y el reconocedor la trato como ruido proveniente del ambiente. |
|
Inserción |
El ruido proveniente del ambiente o un sonido producido por el usuario de manera no intencional como un suspiro, llegó a ser interpretado por el reconocedor como una palabra pronunciada. |
|
Rechazo |
El usuario habló pero el reconocedor no fue capaz de reconocer lo dicho por el usuario. |
|
Sustitución |
El reconocedor regresa un resultado diferente al que dijo el usuario. |
Tabla 1. Errores comunes ocurridos en el proceso de reconocimiento automático del habla.
1.4 Limitaciones en el reconocimiento automático del habla
Las personas cuando hablamos cometemos errores, los reconocedores automáticos del habla comenten más, ya que este “intenta” hacer un reconocimiento de las palabras pronunciadas por el usuario. El desempeño de un reconocedor se define en función de la exactitud de sus resultados. Para conocer la exactitud del desempeño del reconocedor, a cada una de las palabras se les asocia un nivel de confianza respectivo. Este nivel de confianza es un indicativo de la probabilidad con que la palabra fue reconocida, por ejemplo un 83% de exactitud.
La siguiente lista muestra un conjunto de factores que intervienen en el desempeño de un reconocedor automático del habla [1].
-
-
- La exactitud en el reconocimiento del habla es normalmente mejor en ambientes donde no existe mucho ruido.
- La calidad del hardware empleado para captar el habla del usuario puede mejorar el proceso de reconocimiento del habla.
- Cuando los usuarios hablan de forma clara y concisa se obtienen mejores resultados.
- Cuando los sistemas emplean gramáticas simples (poco confusas y complejas) se obtienen mejores resultados.
- La acentuación de las palabras y la forma en que las personas hablan son un factor que influye durante el reconocimiento del habla.
- Las palabras que suenan acústicamente similar son más difíciles de distinguir.
-
Solo algunos de estos factores como 2 y 4 pueden ser solucionados ya sea en el desarrollo del sistema o en la elección de las herramientas de soporte como el hardware. Sin embargo, se debe considerar que existen factores humanos como la acentuación de las palabras, el estado de ánimo, entre otros, que afectan al desempeño de esta tecnología.
1.5 Desafíos en el reconocimiento automático del habla
La labor por mejorar el reconocimiento del habla automático es una tarea que requiere de un esfuerzo que afronte constantemente los desafíos que esta tecnología presenta para lograr un desempeño apropiado. La siguiente lista describe un conjunto de desafíos a los que se enfrenta esta tecnología del habla [7].
-
- Variabilidad de los patrones del habla: Diferentes personas hablan el mismo idioma y la pronunciación de las palabras difiere una de otra. Interpretar la variabilidad del habla de una persona a otra ha conducido al desarrollo de un análisis de patrones complejo. Comprender las diferentes pausas, las tasas del discurso y los cambios en el volumen se ha vuelto una tarea compleja y difícil.
-
- Poder de procesamiento: A mediados de los 80’s una nueva técnica conocida como Modelos de Markov Ocultos mejoraron la habilidad de asociar las relaciones entre palabras. Esto provocó una tecnología de cómputo intensivo que eventualmente condujo al desarrollo de poderosas aplicaciones que emplearon el reconocimiento del habla. El buen desempeño del reconocimiento del habla en tiempo real requiere mucho poder de procesamiento para los sistemas de diálogo hablado.
- Ruido de fondo: Dado que las personas hacen acceso a los sistemas de diálogo hablado desde un teléfono, el ruido de fondo como el viento, la música, los murmullos, entre otros, han sido un factor que afecta al desempeño del reconocedor.
- Reconocimiento del habla continua: los sistemas que necesitan procesar el habla continua requieren de un alto poder de procesamiento. Dado que el usuario habla de una manera natural y continua, es difícil distinguir qué sonidos están asociados a determinadas palabras.
- Gramáticas: El buen trabajo en el desarrollo de las gramáticas promueve un buen desempeño para el reconocedor automático del habla, sin embargo, existen problemas con las palabras que están fuera del contexto del reconocedor. En el trabajo realizado en [6] se muestran un conjunto de técnicas que afrontan este problema para el idioma en español.
Los desafíos presentados anteriormente nos proporcionan un enfoque de la necesidad de una investigación y trabajo arduo a realizar para mejorar el desempeño de esta tecnología del habla.
2. La síntesis de voz
La síntesis de voz es el proceso por el cual la computadora produce habla a partir de un texto conformado por un conjunto de caracteres, al proceso de síntesis de voz se le conoce como “Texto A Voz” (Text To Speech: TTS). Para generar la voz por parte de la computadora, se realiza un análisis minucioso del texto a sintetizar, esto se hace con el fin de generar una correcta pronunciación y acentuación adecuada de cada una de las palabras a reproducir de manera auditiva al usuario (prosodia). En la figura 2, se muestra la configuración estándar de un sistema TTS, en los sistemas que emplean variantes de este estándar, la síntesis ha logrado una calidad de habla buena, congruente, fácil de entender al usuario y de uso práctico para los fines que persigue la síntesis de voz [2].
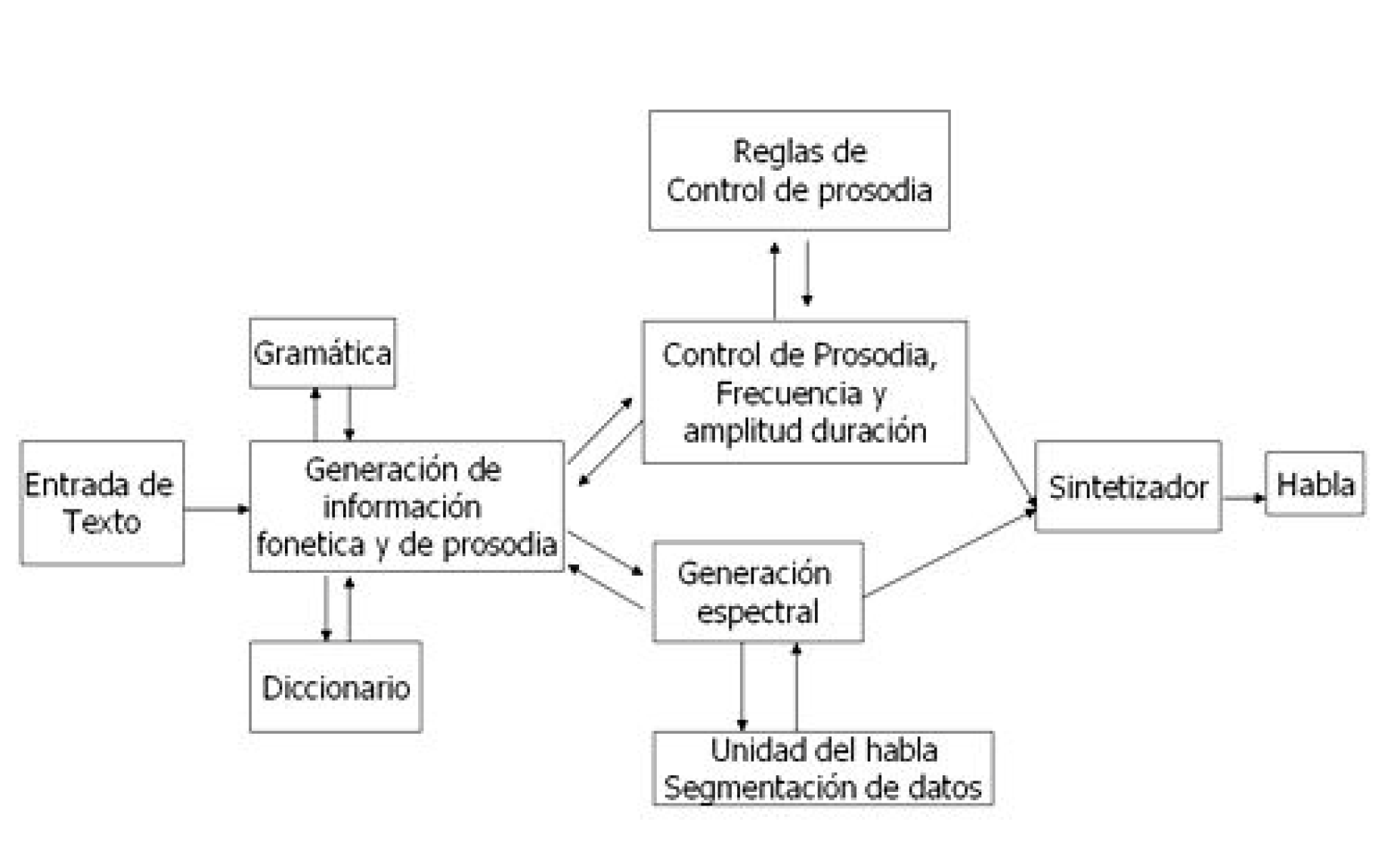
Figura 2. Configuración estándar de un sistema TTS.
Para llevar a cabo el proceso de síntesis, es necesario realizar un procesamiento detallado del texto a sintetizar, en el trabajo descrito en [7] se detalla el proceso por el cual el texto llega a convertirse en voz:
- Análisis estructural: En este proceso se realiza un análisis del texto para determinar dónde inician y terminan las palabras o frases. En la mayoría de los lenguajes, la puntuación y formateo de datos son procesados mediante este análisis.
- Pre-procesamiento de texto: Este proceso involucra un análisis del texto para construcciones especiales del lenguaje como lo son los acrónimos, fechas, números, direcciones de correo, etc.
- Conversión texto a fonema: En este proceso cada palabra es convertida en un fonema, el cual es la unidad mínima y básica del sonido del habla.
- Análisis prosódico: Este análisis consiste en el procesamiento de la estructura de la oración, palabras y fonemas. Esto involucra el pausado, el ritmo, el tiempo, el énfasis con que las palabras deben ser pronunciadas.
- Producción: Finalmente, la información de los fonemas y la prosodia son usadas para producir el habla auditiva. Existen diferentes técnicas para producir habla como la concatenación de fragmentos de audio o mediante una síntesis formante, la cual emplea técnicas de procesamiento de señales teniendo como soporte el sonido de los fonemas y el efecto de la prosodia.
2.1 Errores en la síntesis de voz
Los errores de la síntesis de voz ocurren normalmente durante el proceso de síntesis. A continuación, se muestran algunos de los errores más comunes que pueden ocurrir durante el proceso de síntesis [7]:
-
- Análisis estructural: La puntuación y el formateo de los datos no son siempre consistentes. Por ejemplo, los puntos en la palabra “D.E.A.” pueden ser confundidos como el final de una oración.
- Pre-procesamiento de texto: No siempre es posible que el sintetizador reconozca todos los acrónimos, formatos de fechas, o direcciones de correo electrónico de manera fiable.
- Conversión texto a fonema: Los sintetizadores pueden generar fonemas a partir de palabras confusas las cuales no llegan a ser claras al usuario, ejemplo de estas son apellidos, nombres de personas o empresas, marcas de productos, entre otros.
- Análisis prosódico: Los sintetizadores no siempre pueden producir una oración clara y entendible al usuario. Por lo que es necesario considerar la existencia de palabras que necesiten énfasis, pausas entre palabras o la modificación de la velocidad del sintetizador al generar el habla.
- Producción: el habla generada por los sintetizadores normalmente llega a sonar artificial por lo que se llega a crear un ambiente de confusión y esfuerzo por entender la voz sintetizada por parte del usuario.
2.2 Limitantes en la síntesis de voz
La síntesis de voz aún requiere de un mayor trabajo e investigación. Existen limitantes que afectan su desempeño y calidad de audio. El trabajo expuesto en [7], se proporciona información sobre un conjunto de limitantes a los que se enfrenta la síntesis de voz, que de manera breve se describen aquí:
-
- Las voces sintetizadas no son lo suficientemente expresivas. Aún no pueden simular las emociones humanas, tales como la alegría, la tristeza, o el enojo.
- Actualmente las voces sintetizadas en su mayoría son masculinas o femeninas de personajes maduros. Por lo que la existencia de voces de niños, viejos o jóvenes es escasa.
- Es necesario realizar investigaciones que satisfagan el manejo de estilos formales e informales del habla así como las variaciones de los dialectos. Por lo que se requiere de un estudio detallado de estos estilos del lenguaje, así como de sus dialectos y modelos sociolingüísticos.
2.3 Desafíos en la síntesis de voz
La síntesis de voz aún no es perfecta y el audio con que se genera aún requiere de una mayor calidad. Actualmente existe la necesidad de un trabajo arduo para obtener una buena calidad de síntesis de voz en la prosodia. Los sintetizadores actuales llegan a ser muy artificiales en las voces que estos producen, y cuando las personas escuchan estos tipos de voces se distraen o se sorprenden al escucharlas, lo cual afecta la comprensión y percepción de la calidad del habla [1 y 8].
3. Resumen
En el presente artículo se presentaron las tecnologías del habla haciendo un principal énfasis en sus errores, limitantes y desafíos a las que estas se enfrentan. Las tecnologías del habla, aún no son perfectas y requieren de un esfuerzo y trabajo arduo en investigación para mejorar el desempeño de estas. El empleo de estas tecnologías son de gran beneficio para la humanidad, ya que permiten que diferentes tipos de personas puedan acceder a diferentes tipos de recursos de una computadora, y de esta manera beneficiarse al incrementar su productividad personal.
4. Referencias
[ 1 ] Robert D. Rodman. “Computer Speech Technology”, Artech House Publishers. 1999. (pp 101, 140, 213).
[ 2 ] R. A. Cole, J. Mariani, H. Uszkoreit, A. Zaenen and V. Zue. “Survey State of the Art in Human Language Technology”. Cambridge University Press, 1996.
[ 3 ] PC Labs, “Tecnología de reconocimiento de voz”. PC Magazine en español, Marzo del 2000. (página 81).
[ 4 ] Victor Zue, “Beyond Recognition, to Understanding”, Speech Technology Magazine, October November 1998.
5 ] Converse, “The Benefits of a Conversational Voice User Interface in a Voice Portal”. International Engineering Consortium (IEC). 2002.
[ 6 ] Cuayahuitl, Kirschning y Serridge. “Técnicas para mejorar el reconocimiento de voz en presencia de habla fuera del vocabulario”. Universidad de las Américas Puebla, primavera del 2000.
[ 7 ] Sun Microsystems. “Java Speech Programmer Guide Version 1.0”, October 26 de 1998. (pp 9, 10, 11 y 16)
[ 8 ] Kéller, E., & Zéller-Keller, “Challenges and New Uses for Speech Synthesis”. Dundee, Scotland, August 2000.
Otras ligas de interés
Google’s SpecAugment achieves state-of-the-art speech recognition without a language
model.
State-of-the-art Speech Recognition With Sequence-to-Sequence Models
State-of-the-art Speech Recognition With Sequence-to-Sequence Models
Amazon Alexa
https://developer.amazon.com/en-US/alexa/alexa-skills-kit/asr
Speech Synthesis Evaluation — State-of-the-Art Assessment and Suggestion for a Novel Research Program
Best Text to Speech APIs

