

En esta entrada vamos a ver qué son las bases de datos espaciales, para qué se utilizan y diferentes ejemplos con PostGIS para entender su funcionamiento.
Índice de contenidos.
- ¿Qué son las bases de datos espaciales? ¿Cómo surgieron?
- Nosotros vamos a trabajar con PostGIS
- ¿Cómo funcionan?
- Hora de un ejemplo práctico
- Conclusiones
- Imágenes
¿Qué son las bases de datos espaciales? ¿Cómo surgieron?
La necesidad de trabajar con datos en espacios de coordenadas no es nueva. Hace ya años desde que surgió el concepto de GIS (Sistema de Información Geográfica en inglés o SIG) y comenzaron a implementarse los primeros. A grandes rasgos, un GIS es un sistema software que permite el procesamiento y la analítica de datos geoespaciales.
En los inicios se utilizaron ficheros con formatos concretos (a destacar los Shapefiles) que los GIS podían leer y analizar. Las desventajas son claras: se necesita un software a medida, el acceso concurrente es problema si hay escrituras y los tratamientos complejos, como por ejemplo relacionar datos entre sí, son muy tediosos de hacer a mano.
Con el tiempo empezaron a utilizarse bases de datos relacionales para guardar estos datos. Lo único que se hacía era almacenar los datos con tipos convencionales sin ningún tratamiento especial, por ejemplo columnas numéricas para latitud y longitud. Se seguía necesitando software especial para interpretar y procesar correctamente esta información. Sin embargo, es cierto que se mitigaron algunos problemas. Desde entonces, en la mayoría de casos, los ficheros han quedado relegados a una forma de importar y exportar los datos.
Pero lo que había hasta entonces no era suficiente así que se dio un paso más y llegaron las bases de datos espaciales. De forma resumida son aquellas desarrolladas con el uso de datos basados en coordenadas en mente. Lo novedoso es que estos datos no son tratados de la forma tradicional. Existen tipos, funciones y mecanismos de optimización internos creados expresamente para facilitar su procesamiento. De esta forma podemos trabajar sin problemas con puntos, líneas o áreas en un sistema de coordenadas.
Nosotros vamos a trabajar con PostGIS
Actualmente hay bastantes alternativas en el mercado de las bases de datos espaciales. Tenemos tanto aquellas creadas desde cero con este propósito como extensiones de otras ya existentes. Tanto relacionales como NoSQL, aunque por lo general las relacionales están más maduras en este aspecto.
Obviamente se deberá escoger una u otra en función de las necesidades específicas. No es mi objetivo aquí hacer un estudio de cada una, simplemente aprender los conceptos. Por lo tanto voy a elegir PostGIS, que es una de las más usadas y normalmente la primera opción que se viene a la mente al hablar de este tipo de tecnología.
Se trata de una extensión de PostgreSQL que le permite usar tipos, funciones e índices espaciales. De esta forma tenemos toda la potencia de la base de datos original más la flexibilidad de estas herramientas, incorporando casi todo lo que hacen el resto de alternativas y lo hace de forma nativa. Además implementa el estándar OGC SFSQL (que vamos a ver más adelante), lo que facilita la interacción con otros sistemas.
¿Cómo funcionan?
Ya con la introducción hecha, vamos a ver cómo funcionan las bases de datos espaciales, tomando PostGIS como ejemplo. Lo que veremos es particular de esta base de datos, pero las ideas son generalizables a las demás. Mi objetivo es dejar los conceptos básicos claros para poder aprender cualquier alternativa sin demasiado esfuerzo. Y además de paso que podáis manejaros mínimamente con PostGIS.
Como ya hemos dicho, las principales características de las base de datos espaciales que las diferencian de las tradicionales son los tipos, las funciones y los índices. A continuación vamos a entrar en detalle cada uno.
Tipos
Lo primero que siempre se menciona de las bases de datos espaciales es que permiten almacenar nuevos tipos. Al fin y al cabo una base de datos sirve principalmente para eso: guardar datos.
Con las bases de datos espaciales también surgieron otros estándares. Uno de ellos es Simple Features, promovido por el Consorcio Geoespacial Abierto (más conocido por sus siglas en inglés OGC, de Open Geospatial Consortium). Concretamente a nosotros la parte que nos afecta es el Simple Features for SQL o SFSQL. En este estándar se define el modelo de los tipos de datos espaciales más comunes en dos dimensiones. Además también especifica los dos formatos principales para representarlos: Well-Known Text (WKT) y Well-Known Binary (WKB).
Esta es la jerarquía de tipos que se definen en el estándar, en la que todos ellos extienden del tipo Geometry:
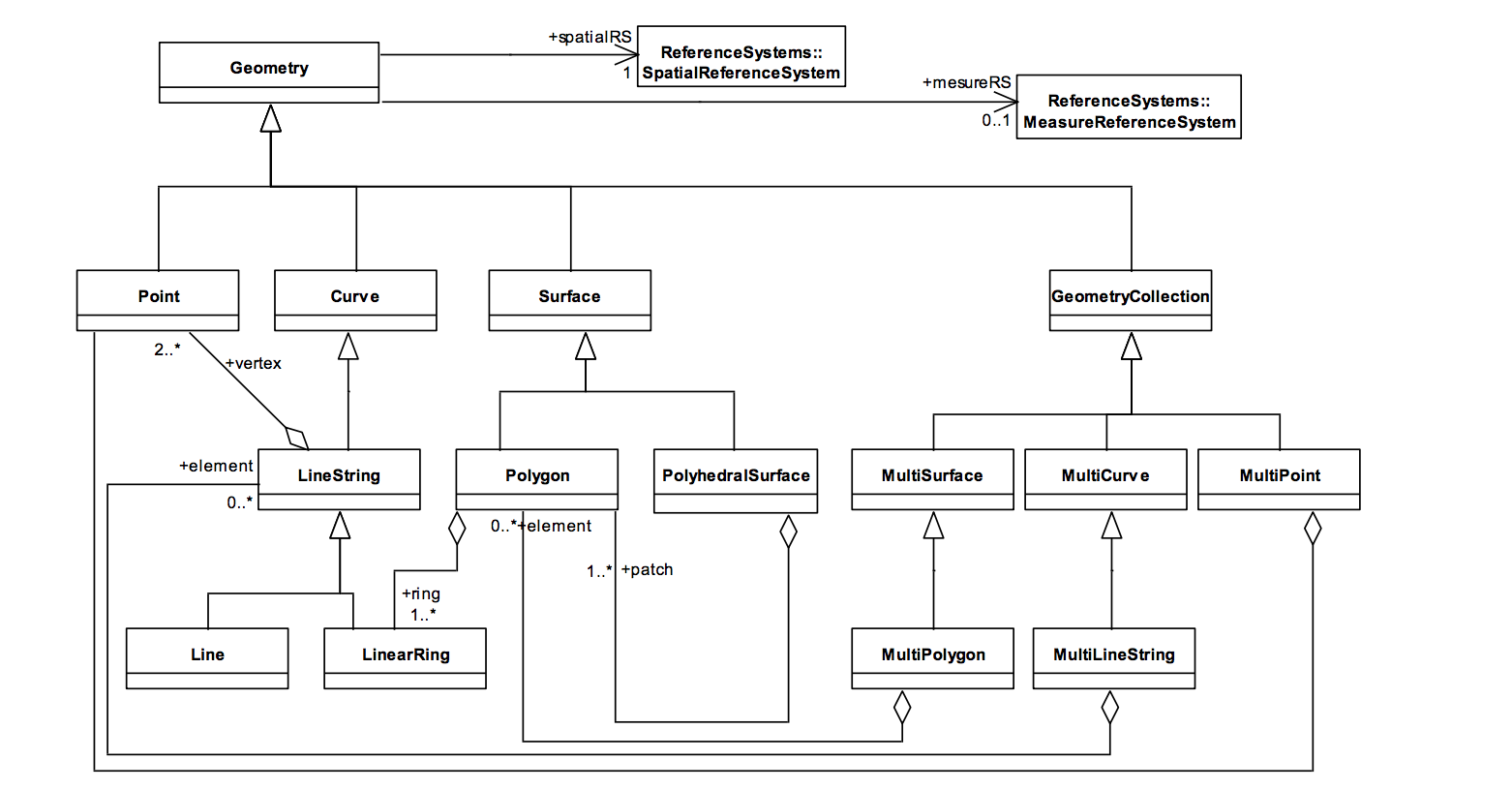
PostGIS implementa SFSQL, pero además lo amplía con con SQL/MM. De esta forma añade soporte para datos de hasta 4 dimensiones (3DM, 3DZ y 4D) a todos los tipos de datos que definen las Simple Features.
A modo de resumen, los tipos de datos más importantes que utiliza PostGIS, junto con su representación en WKT, son:
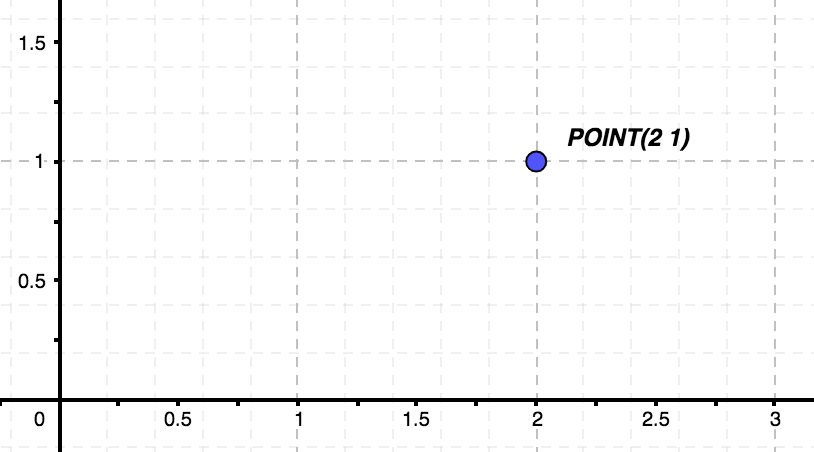
- Punto: representa un punto en un espacio de N dimensiones.
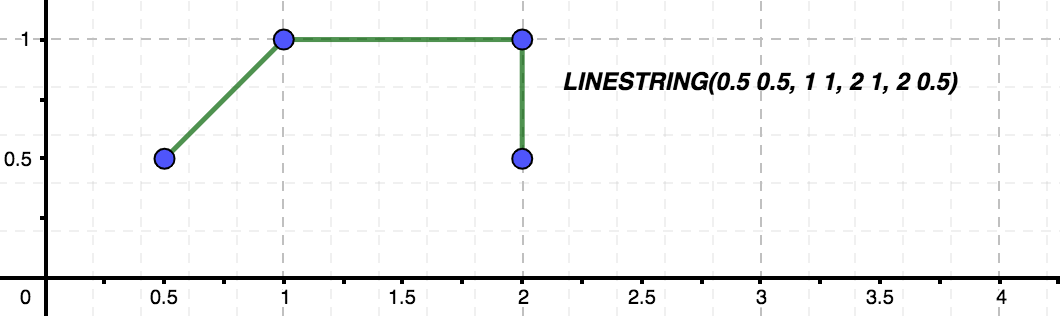
- Multilínea: representa una línea compuesta de varios segmentos rectos, por lo que se definirá con varios puntos. Pueden ser abiertas o cerradas.
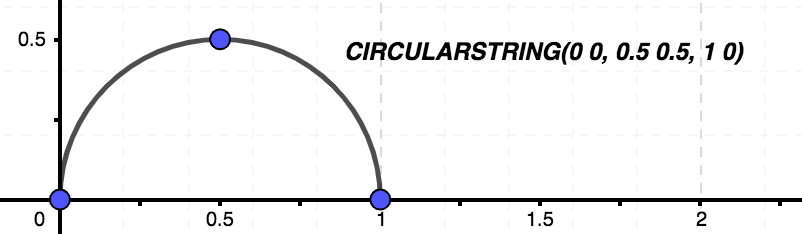
- Curva: representa lo mismo que la multilínea pero en lugar de tener segmentos rectos son curvas representadas por los puntos de origen, destino y uno intermedio para dar curvatura.
- Polígono: representa un polígono cerrado, que puede estar completo o tener agujeros en su interior. Se representa como un conjunto de multilíneas cerradas, siendo la primera el polígono principal y las demás los agujeros que pueda tener.

- Colecciones: tenemos tanto la colección genérica GeometryCollection que puede almacenar cualquier tipo de datos de tipo Geometry como los específicos MultiPoint, MultiLineString y MultiPolygon.

Como vimos, todos extienden de Geometry, que es el padre y puede usarse para tipar una columna de una tabla y tener polimorfismo. Al usar estos tipos, estamos trabajando sobre un espacio de coordenadas cartesianas. La característica más importante para nosotros es que una distancia de una unidad sobre el eje X va a medir siempre lo mismo da igual en qué posición del eje Y estemos.
Pero además, también podemos trabajar con espacios esféricos. Para entender la diferencia pensemos en dos meridianos cualesquiera de la Tierra (las líneas que van de norte a sur). La distancia entre ambos siempre será constante si lo medimos en grados, que es como se expresa un par de coordenadas en una esfera. Sin embargo, se van acercando los unos a los otros hasta converger en los polos. Aunque la distancia en grados sea la misma, la distancia real en kilómetros es distinta según la latitud. Nuestros dos meridianos estarán más separados a la altura del Mediterráneo que por la zona de Islandia, por ejemplo.
Así como tenemos los tipos de datos Geometry para coordenadas cartesianas, también están los tipos de datos Geography para trabajar en espacios con coordenadas esféricas. Tratar con ellos es bastante más pesado internamente pero sus cálculos son mucho más precisos en determinadas circunstancias, por lo que puede llegar a ser interesante usarlos. De todos modos no voy a entrar más en detalle para no hacer la entrada demasiado extensa.
Funciones
Ahora que ya tenemos los datos, es importante también poder tratarlos. Para ello disponemos de una serie de funciones especialmente diseñadas y que en PostGIS se agrupan en varios tipos. Vamos a ver algunos ejemplos para que sepáis lo básico que se puede hacer, pero os recomiendo leer la documentación para poder verlas todas o conocer más en detalle alguna de ellas.
En cada grupo hay sentencias SQL de ejemplo con las que poder ver algunas funciones en acción. Si queréis, podéis leer el principio del punto “Preparación del entorno” del ejemplo práctico para levantar una instancia de PostGIS y crear una base de datos con la extensión en la que podréis ejecutar todos los ejemplos propuestos.
Funciones de salida
Es común querer ver los datos de nuestras tablas en una forma que podamos entender o exportarlos para tratarlos en otros lados. Estas funciones nos permiten, a partir de un tipo de dato geométrico, obtener su representación en una variedad bastante amplia de formatos: binario, texto, GeoJSON, GML, SVG… Digamos que un equivalente del día a día sería la serialización de un objeto en memoria a JSON.
SELECT ST_AsText('POINT(0 0)'); -- Muestra nuestro punto en WTK (Well-Known Text).
SELECT ST_AsEWKT('010100000000000000000000000000000000000000'); -- Lo mismo que antes, pero en este caso hemos pasado cómo se representa el punto si lo obtenemos de la tabla directamente.
SELECT ST_AsGeoJSON('LINESTRING(1 2 3, 4 5 6)'); -- Muestra esta multilínea de un espacio de tres dimensiones en formato GeoJSON.
SELECT ST_AsSVG('POLYGON((0 0,0 1,1 1,1 0,0 0))'); -- Muestra el polígono como un path data de SVG, que es el formato en el que se especifica cómo se dibuja una imagen SVG. Para más información podéis consultar https://www.w3.org/TR/SVG/paths.html#PathDataBNF
SELECT ST_AsBinary('POLYGON((0 0,0 1,1 1,1 0,0 0))'::geometry); -- Devuelve la representación en binario del polígono (Well-Known Binary).
Funciones de construcción
Como su nombre indica, permiten crear objetos geométricos a partir de una entrada, que puede estar representada en una amplia variedad de formatos. Si las funciones de salida eran la serialización entonces las de construcción serían las de deserialización.
Si intentásemos mostrar directamente el resultado de cualquier consulta que devuelva un objeto geométrico solo veríamos el chorro de número y letras que es su representación interna en base de datos pero que nosotros no podemos entender. Así que en los ejemplos de ahora en adelante siempre que una función nos devuelva un objeto geométrico usaremos la función ST_AsText para convertirlo en algo entendible a simple vista.
SELECT ST_AsEWKT(ST_GeomFromText('LINESTRING(0 0, 1 1, 1 2, 3 2)')); -- Crea una multilínea que pasa por los puntos (0, 0), (1, 1), (1, 2) y (3, 2).SELECT ST_AsText(ST_GeomFromGeoJSON('{"type":"LineString","coordinates":[[0,0],[1,1],[1,2],[3,2]]}')); -- Crea la misma línea pero expresando la entrada en formato GeoJSON.
SELECT ST_AsEWKT(ST_LineFromMultiPoint('MULTIPOINT(0 0, 1 1, 1 2, 3 2)')); -- Misma línea pero a partir de un conjunto de puntos.
Funciones de acceso
Nos permiten obtener datos de un objeto concreto, como el tipo de geometría, el número de puntos que tiene, la longitud, el área… Muchas de estas funciones no sirven para todos los tipos de datos, por ejemplo tiene sentido saber si una multilínea es cerrada (si su origen y destino es el mismo) pero no aplica a un único punto que siempre se considera como cerrado.
SELECT GeometryType('POINT(1 2 3)'::geometry); -- Devuelve el tipo concreto de geometría que es. En este caso un punto.SELECT ST_Dimension('GEOMETRYCOLLECTION(LINESTRING(1 1,0 0),POINT(0 0))'); -- Devuelve la dimensión de la geometría. Los puntos tienen dimensión 0, las líneas 1, los polígonos 2 y las colecciones tienen la mayor dimensión entre todos sus componentes.
SELECT ST_IsClosed('LINESTRING(0 0, 1 1)'); -- Devuelve si la multilínea es cerrada.
SELECT ST_AsText(ST_ExteriorRing('POLYGON((1 1, 2 5, 7 5, 7 1, 1 1), (3 3, 3 4, 5 4, 4 3, 3 3))')); -- Devuelve el anillo exterior del polígono.
Funciones de edición
A veces en vez de crear nuevos datos desde cero podemos querer basarnos en alguno ya existente y modificarlo para que se ajuste a nuestras necesidades. Los casos más típicos son los de rotar o escalar una figura.
SELECT ST_AsText(ST_Rotate('LINESTRING (50 160, 50 50, 100 50)', pi()/2)); -- Rota la multilínea que le hemos pasado en 90 grados en sentido antihorario.SELECT ST_AsText(ST_Scale('LINESTRING(1 2 3, 1 1 1)', 1, 2, 3)); -- Escala la multilínea para que mantenga sus coordenadas en el eje X, se duplique en el Y y se triplique en el eje Z.
SELECT ST_AsText(ST_AddPoint('LINESTRING(0 0 1, 1 1 1)', 'POINT (1 2 3)')); -- Añade un nuevo punto a una multilínea.
SELECT ST_AsText(ST_Force2D('LINESTRING(0 0 1, 1 1 1)')); -- Fuerza la geometría a tener solo dos coordenadas, lo que permite adaptarse al estándar de OGC.
Funciones de medidas y relaciones
Algunas de las funciones más importantes que tenemos nos permiten relacionar los datos con su entorno, tanto con medidas individuales como con otros elementos.
SELECT ST_Distance('POINT (1 1)', 'LINESTRING(0 0, 2 0)'); -- Calcula la distancia en dos dimensiones entre dos elementos.SELECT ST_3DDistance('POINT (1 1 1)', 'LINESTRING(0 0 0, 2 0 0)'); -- Calcula la distancia pero esta vez en un espacio de 3 dimensiones.
SELECT ST_Within('POINT(2 2)'::geometry, 'LINESTRING(1 1, 3 3)'::geometry); -- Determina si todos los puntos del primer elemento se encuentran dentro del segundo.
SELECT ST_Equals('LINESTRING(0 0, 10 10)', 'LINESTRING(0 0, 5 5, 10 10)'); -- Determinar si dos elementos son iguales, es decir, si se se cumple que el primero está dentro del segundo y el segundo dentro del primero. Esto quiere decir que, como en el ejemplo, no es necesario que estén creados igual.
SELECT ST_Length('LINESTRING(0 0, 1 0, 1 1)'); -- Devuelve la longitud total de una multilínea.
Funciones de procesamiento geométrico
Por último vamos a ver funciones que, a grandes rasgos, permiten crear figuras a partir de propiedades de uno o más elementos.
SELECT ST_AsText(ST_Buffer('POINT(100 90)', 50)); -- Devuelve el área que representa todos los puntos que están a una distancia de 50 unidades del punto.
SELECT ST_AsText(ST_Union('POLYGON((1 2, 2 4, 8 5, 9 4, 9 2, 1 2))'::geometry, 'POLYGON((8 4, 8 6, 10 6, 10 4, 8 4))'::geometry)); -- Devuelve el polígono fruto de la unión de los dos parámetros.
Índices
La última, pero no la menos importante, de las características de una base de datos espacial es que implementa índices enfocados especialmente a tratar con estos datos. Hay bastantes (Quadtree, Grid, Octree…) y cada base de datos utiliza el suyo. En concreto aquí vamos a ver R-Tree porque es el utilizado por PostGIS (y algunos otros sistemas como Oracle Spatial) y por tanto el que se va a utilizar por debajo en nuestro ejemplo.
El funcionamiento tradicional de una cláusula where es comprobar uno por uno todos los registros para ver si cumplen una cierta condición. Sin embargo, los índices permiten organizar los datos de una cierta forma (por ejemplo ordenados ascendentemente) para encontrar el grupo de posibles candidatos para los que la cláusula se va a cumplir. En lugar de comprobar todos los registros solo se hace con los que es probable que sean válidos. Esto es posible gracias a que los tipos tradicionales (números, cadenas de caracteres y fechas) son fáciles de ordenar y comparar unos con otros. Pero no es tan trivial con datos espaciales. ¿Cómo se define si un punto es mayor que otro? ¿Y un área? ¿Y si un punto está dentro de un polígono? Se necesita una aproximación diferente para organizar estos datos.
Los árboles R (o R trees) son la estructura de datos en la que se apoya PostGIS para crear y mantener sus índices. Se basa en dos conceptos: usar rectángulos delimitadores de superficie mínima (Minimum Bounding Rectangle o MBR en inglés) y agrupar los objetos cercanos en áreas cada vez más pequeñas. Ahora hablaremos de cómo se estructuran estos árboles, pero primero veamos de qué sirven los rectángulos y qué se busca.
Pongamos que tenemos el siguiente ejemplo, con las líneas y el cuadrado verdes inicialmente en nuestra base de datos. Queremos buscar todos los objetos que están en contacto con un segundo polígono azul, también en la imagen.
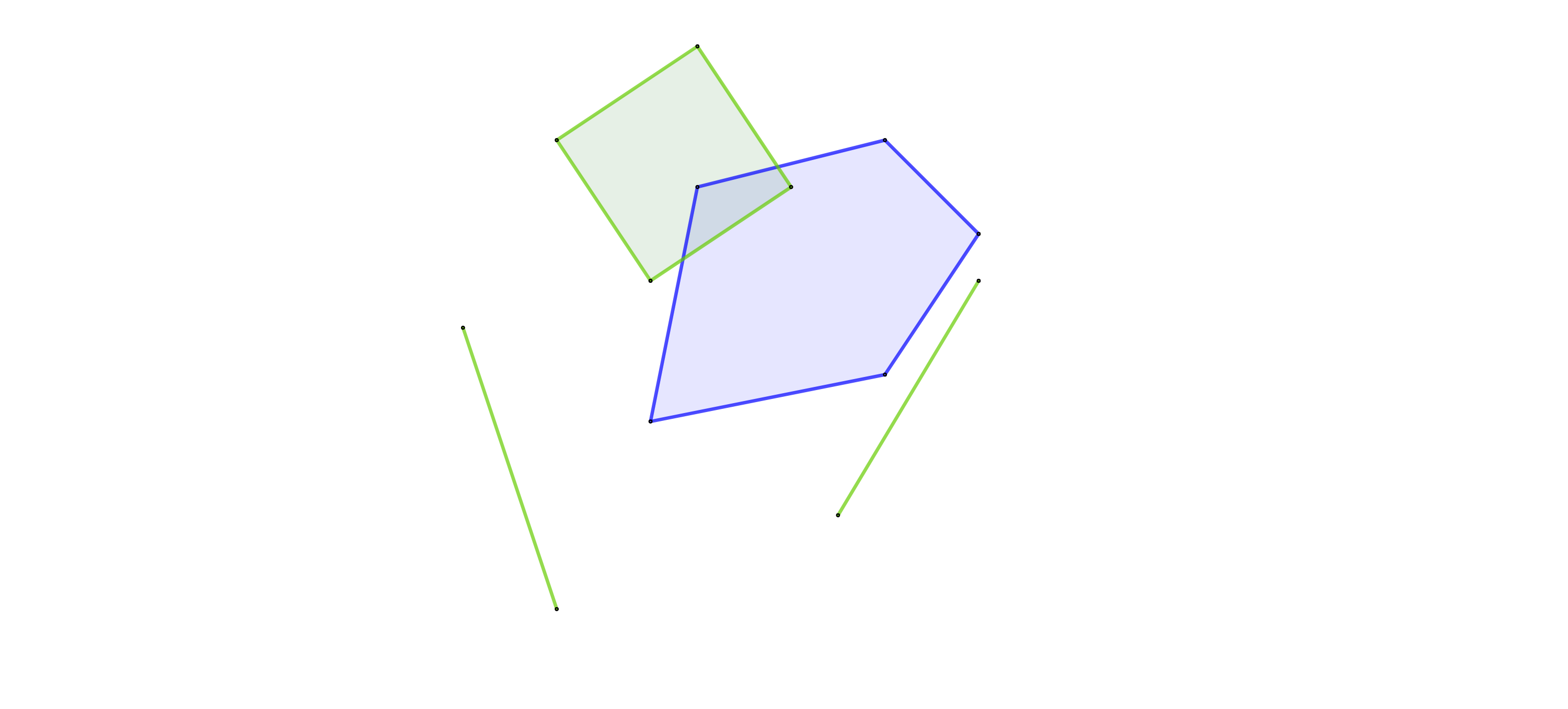
Sin índices tendríamos que comprobar uno por uno todos los objetos. Sin embargo, este tipo de cálculos con polígonos y líneas sin una forma predefinida con la que optimizar son bastante costosos. Por este motivo se rodea cada elemento con su MBR. Nos quedaría algo así:
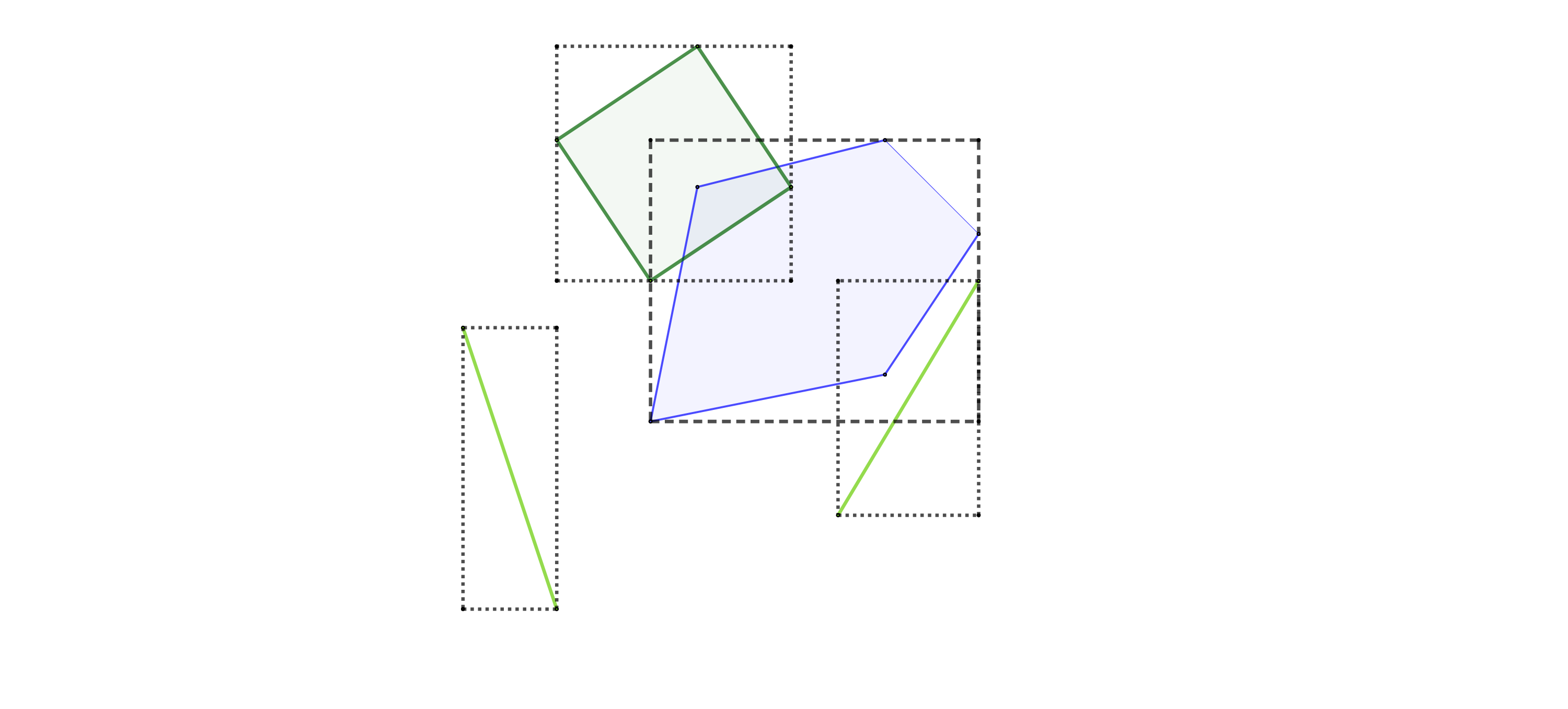
Ahora ya podemos aligerar los cálculos. Es muy sencillo saber si dos rectángulos se superponen en algún punto y computacionalmente no lleva nada de tiempo. Sabemos a ciencia cierta que si dos rectángulos no se están tocando es imposible que sus contenidos lo estén haciendo. Así hacemos un primer filtrado para, de una manera rápida, quitarnos todos los datos que sabemos que no cumplirán la condición sin necesidad de un análisis exhaustivo. En nuestro ejemplo vemos que la línea de la izquierda es completamente imposible que se tope con el polígono azul. De lo que no podemos afirmar nada es de la línea a la derecha y el cuadrado verde. Aquí ya sí que se hará una comprobación real en la que se calculan todos los puntos de posible contacto.
Esto es, de forma simplificada lo que hace el árbol R. Con un primer filtro se descartan todos los objetos que se sabe de antemano que no van a cumplir la cláusula que se está buscando. A continuación se mira en detalle cada uno de los elementos no descartados, pero con un poco de suerte el porcentaje de estos elementos será muy bajo.
Pero, ¿cómo hace el filtrado para saber con cuáles se queda? ¿Comprueba los rectángulos de cada elemento uno por uno? Para nada. De hecho no necesitaríamos ninguna estructura especial de datos si este fuese el caso. Un árbol R (la R viene de rectángulo) se trata de un árbol balanceado de búsqueda que divide el espacio en rectángulos cada vez más pequeños que agrupan todos los objetos dentro de ellos y que pueden llegar a superponerse. Creo que lo mejor es tener primero una imagen en mente y luego lo explicamos.
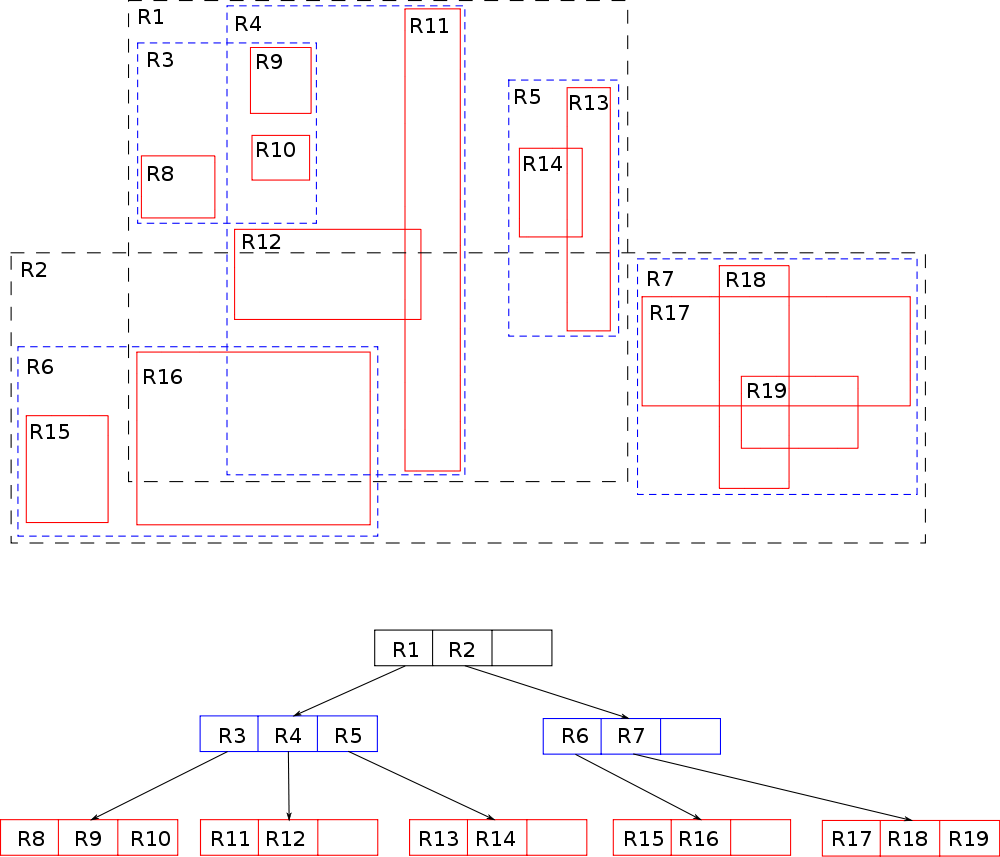
En esta imagen tenemos varios objetos, representados ya por su MBR en rojo. Esos son los elementos a indexar y sobre los que haremos las consultas finales. El área entera que los engloba a todos está representada por el nodo raíz, que divide este área en R1 y R2. Estos rectángulos cada uno está representado por un nodo intermedio que a su vez los divide en áreas más pequeñas. El proceso se sigue hasta que se llega a los nodos hojas, que ya contienen los MBR de los elementos reales.
Al estar organizados de esta manera se pueden descartar áreas enteras hasta quedarnos con el subconjunto más pequeño posible de elementos para los que es posible que se cumpla la cláusula. Vamos a verlo con un ejemplo.
Digamos que vamos a buscar todos los elementos que tocan en algún punto a la línea verde de la imagen.
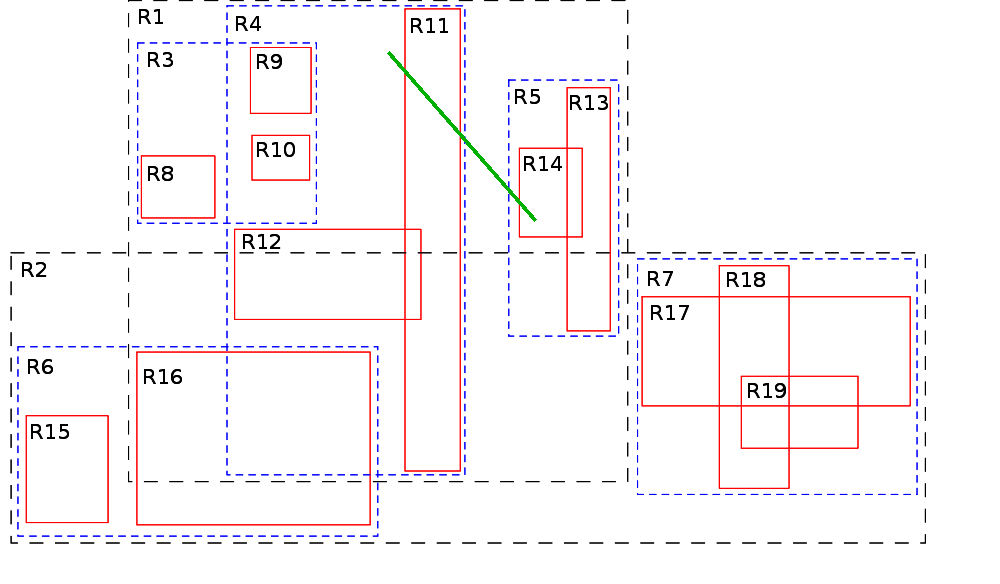
Lo primero que se hará es, obviamente, enmarcar nuestra línea en su MBR.
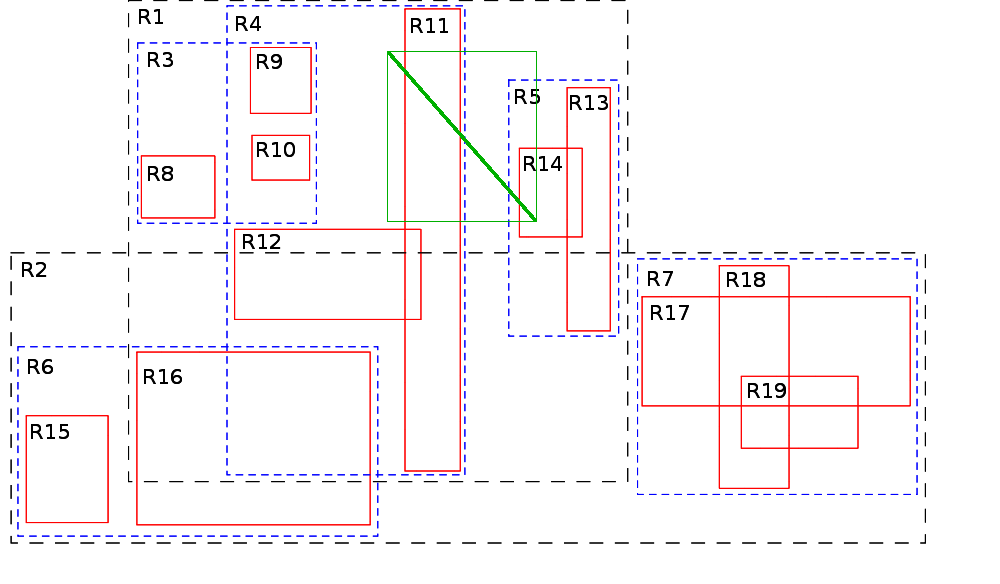
A continuación empezamos a recorrer el árbol y comprobamos el nodo raíz. Vemos que el MBR de la línea verde está dentro de R1, pero no de R2. Descartamos de un solo golpe todos los elementos que están en R2. A continuación nos vamos al nodo de R1 y comprobamos que en concreto solamente está en contacto con R4 y R5, pero no con R3 . Comprobamos en detalle los elementos de estos nodos, que ya son hojas, y descartamos todo menos R11 y R14. De una forma muy poco costosa computacionalmente hemos reducido en gran medida el grupo de objetos a comprobar. De 12 elementos que tenemos en nuestra tabla solamente es necesario que hagamos cálculos pesados con 2 de ellos, lo que sin duda es nos va a ahorrar mucho tiempo.
Cómo se generan exactamente los rectángulos a partir de un conjunto de datos dado y cómo se actualizan cuando se insertan nuevos o se borra alguno ya existente depende del algoritmo concreto que se esté usando. Algunos favorecen la velocidad de construcción o modificación mientras que otros buscan que las distintas áreas se solapen lo menos posible. Además hay variantes de este tipo de índices como el R* tree que, por ejemplo, tienen mejoras a la hora de la inserción.
Hora de un ejemplo práctico
Ya tenemos las nociones básicas de qué es una base de datos espacial y cómo trabajar con ella. Vamos a ver un ejemplo para afianzar los conceptos.
Nos encontramos en una torre de control marítima en Australia. La finalidad principal de la torre consiste en monitorizar un área a su alrededor, que está dividida en varias regiones, en la que viven familias de delfines. Por lo general las familias viven en una región, pero hay veces que alguno de sus miembros sale a explorar a otras regiones e incluso se adentra fuera del área que llegamos a monitorizar. Además las familias viajan entre regiones y es frecuente que decidan cambiar con el tiempo. Sin embargo, se puede saber que están ocupando una región en particular porque al menos la mitad de la familia siempre se queda en ella mientras el resto de miembros están fuera.
El sistema es un poco antiguo, por lo que por el momento los datos que se están guardando en la plataforma se cargan de forma periódica de un fichero que contiene todo. Es decir, sólo se almacena una fotografía del estado en un momento exacto del tiempo.
Preparación del entorno
No quiero centrarme en cómo instalar PostGIS, así que para nuestro ejemplo he optado por utilizar esta imagen de Docker en la que ya tenemos un PostgreSQL con PostGIS preparado. En ese mismo enlace hay instrucciones para levantar la imagen y conectarse a ella.
Definimos las tablas
Una vez estemos dentro de nuestra imagen lo primero que tenemos que hacer es crearnos una nueva base de datos y decir que utilice la extensión de PostGIS. Para ello ejecutamos las siguientes instrucciones:
CREATE DATABASE sea_tower; -- Creamos una nueva base de datos.
\c sea_tower; -- Nos conectamos a ella.
CREATE EXTENSION postgis; -- Decimos que tiene que utilizar la extensión de PostGIS.
SELECT PostGIS_Full_Version(); -- Comprobamos que PostGIS está funcionando.
El siguiente paso es preparar las tablas con las que vamos a trabajar. En concreto los datos que tendremos son:
- Una tabla de regiones en la que tenemos el identificador numérico de la región, un nombre en clave, el polígono que representa dicha región y el nombre de la familia que está actualmente asentada en ella (o null si no hay ninguna).
- Una tabla de delfines en la que almacenamos su identificador, la familia a la que pertenece, el último punto en el que se le detectó y el movimiento que ha seguido desde que empezaron las mediciones.
La definición de las tablas será la siguiente:
CREATE TABLE Regions ( id SERIAL PRIMARY KEY, name VARCHAR(20) NOT NULL, area GEOMETRY NOT NULL, settled_family VARCHAR(20) ); CREATE TABLE Dolphins ( id SERIAL PRIMARY KEY, family_name VARCHAR(20) NOT NULL, last_position GEOMETRY NOT NULL, movement GEOMETRY NOT NULL );
Veréis que hemos creado las columnas como GEOMETRY en lugar de como puntos, líneas o polígonos. Para especificar correctamente el subtipo concreto se debe añadir la columna a la tabla después de haberla creado llamando a la función AddGeometryColumn. A esta función se le pasa la tabla y el tipo de dato que será la nueva columna, pero como introduce el concepto de SRID que no he comentado aquí he preferido crear las columnas con el tipo genérico y no liar a nadie.
Cargamos el estado inicial
Con las tablas ya creadas es hora de cargar una serie de datos que reflejarán el estado actual del área marítima controlada por la torre. Esta es una imagen representativa de nuestros datos para poder tener un contexto gráfico en mente mientras estemos trabajando:
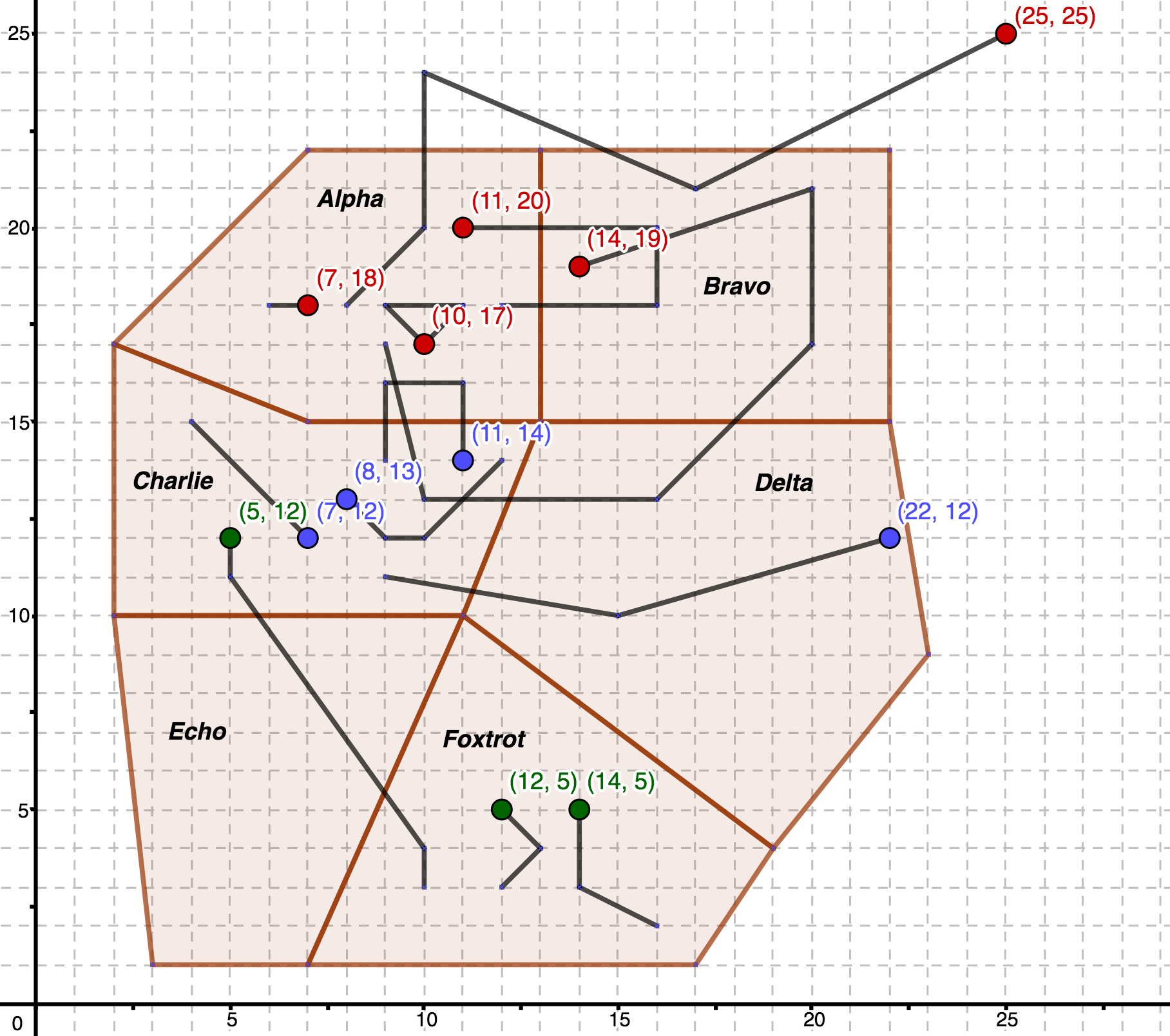
En este diagrama tenemos las 5 regiones con las que vamos a trabajar y los datos de los delfines. Los delfines rojos pertenecen a la familia de los Javadelphis, los azules son los Lagenonaut y los verdes los Delphinuspring. Además a cada delfín le tenemos asociado su histórico de movimientos, que es la línea negra que llega a ellos.
Estos son los datos con los que vamos a trabajar, por lo que tenemos que inicializar nuestras tablas para que reflejen lo mismo. Estas son las regiones que se están monitorizando:
INSERT INTO Regions (name, area, settled_family) VALUES
('Alpha', 'POLYGON((2 17, 7 22, 13 22, 13 15, 7 15, 2 17))', 'Javadelphis'),
('Bravo', 'POLYGON((13 22, 22 22, 22 15, 13 15, 13 22))', null),
('Charlie', 'POLYGON((2 10, 2 17, 7 15, 13 15, 11 10, 2 10))', 'Lagenonaut'),
('Delta', 'POLYGON((11 10, 13 15, 22 15, 23 10, 19 4, 11 10))', null),
('Echo', 'POLYGON((2 10, 11 10, 7 1, 3 1, 2 10))', null),
('Foxtrot', 'POLYGON((11 10, 19 4, 17 1, 7 1, 11 10))', 'Delphinuspring');
Así mismo, los delfines que cuya actividad estamos estudiando vendrían dados por estos datos:
INSERT INTO Dolphins (family_name, last_position, movement) VALUES
('Javadelphis', 'POINT(7 18)', 'LINESTRING(6 18, 7 18)'),
('Javadelphis', 'POINT(11 20)', 'LINESTRING(12 18, 16 18, 16 20, 11 20)'),
('Javadelphis', 'POINT(10 17)', 'LINESTRING(10 17, 9 18, 11 18, 10 17)'),
('Javadelphis', 'POINT(14 19)', 'LINESTRING(9 17, 10 13, 16 13, 20 17, 20 21, 14 19)'),
('Javadelphis', 'POINT(25 25)', 'LINESTRING(8 18, 10 20, 10 24, 17 21, 25 25)'),
('Lagenonaut', 'POINT(7 12)', 'LINESTRING(4 15, 7 12)'),
('Lagenonaut', 'POINT(8 13)', 'LINESTRING(12 14, 10 12, 9 12, 8 13)'),
('Lagenonaut', 'POINT(11 14)', 'LINESTRING(9 14, 9 16, 11 16, 11 14)'),
('Lagenonaut', 'POINT(22 12)', 'LINESTRING(9 11, 15 10, 22 12)'),
('Delphinuspring', 'POINT(12 5)', 'LINESTRING(12 3, 13 4, 12 5)'),
('Delphinuspring', 'POINT(14 5)', 'LINESTRING(16 2, 14 3, 14 5)'),
('Delphinuspring', 'POINT(5 12)', 'LINESTRING(10 3, 10 4, 5 11, 5 12)');
Hora de trabajar
Inicialmente el sistema de control ofrecerá un breve resumen que permita saber de un vistazo si todo está yendo correctamente. El primero de los datos que se muestran es una gráfica indicando, para cada región el número de delfines que hay en ese momento en ella. Esto no es ningún problema con lo que hemos aprendido y podríamos solucionarlo con una consulta similar a la siguiente:
SELECT r.id AS region_id, r.name AS region_name, COUNT(d.id) AS number_of_dolphins FROM Regions r LEFT JOIN Dolphins d ON ST_Within(d.last_position, r.area) GROUP BY r.id;
Además de esto también se muestra, para cada familia el número de delfines que la componen y cuál es la región en la que está asentada, junto con la distancia media entre los delfines de una misma familia. El listado aparece en orden descendente por esta distancia. En este caso la consulta es ligeramente más compleja por tener que juntar distintos datos pero esta podría ser una forma de obtener lo que se nos pide. Quizá no sea la más elegante ni la más óptima pero permite entender el proceso sin demasiadas dificultades.
SELECT families.family_name, number_of_dolphins, region_name, average_distance FROM (SELECT family_name, COUNT(*) AS number_of_dolphins FROM Dolphins GROUP by family_name) AS families JOIN (SELECT settled_family, name AS region_name from Regions) AS regions ON families.family_name = regions.settled_family JOIN ( SELECT family_name, avg(distance) AS average_distance FROM ( SELECT ST_Distance(a.last_position, b.last_position) AS distance, a.family_name AS family_name FROM Dolphins a JOIN Dolphins b ON a.family_name = b.family_name AND a.id < b.id ) AS familiar_dolphins GROUP BY family_name ) AS average_distances ON families.family_name = average_distances.family_name ORDER BY average_distance DESC;
Además de esto también tienen una serie de alertas que les avisa cuando los delfines tienen comportamientos extraños. Por un lado son capaces de saber cuándo un delfín ha salido fuera del área controlada. Esto se consigue con la siguiente consulta, que nos devuelve los delfines que cuya última posición conocida no está dentro de la unión de las áreas de todas las regiones:
SELECT id, family_name, ST_AsText(last_position) as last_position FROM Dolphins WHERE NOT ST_Within(last_position, (SELECT ST_Union(area) FROM Regions));
Por otro lado también es interesante saber qué regiones han sido menos visitadas por los delfines, puesto que eso podría suponer que hay algo raro y un equipo de investigación debería ir lo antes posible a comprobarlo. Para lograrlo sería suficiente con una consulta similar a esta, en la que por tener más datos para el ejemplo estamos mostrando las distintas regiones con el número de delfines que las han cruzado pero se podría limitar al primer resultado:
SELECT r.name, COUNT(d.id) as number_of_dolphins FROM Regions r LEFT JOIN Dolphins d ON ST_Intersects(r.area, d.movement) GROUP BY r.name ORDER BY number_of_dolphins;
La última de las alertas que tienen les indica cuándo un delfín se ha alejado demasiado de los demás. Los delfines son bastante sociables y no suelen viajar solos, así que esto también podría ser una mala señal. La aproximación que yo propongo utiliza la función ST_Buffer para fines didácticos, pero también podría calcularse la distancia mínima entre los distintos delfines y seguir en esa dirección.
SELECT a.id, a.family_name AS family_name, ST_AsText(a.last_position) AS last_position FROM Dolphins a LEFT JOIN Dolphins b ON a.id != b.id AND ST_Within(b.last_position, ST_Buffer(a.last_position, 9)) WHERE b.id IS NULL; -- Cálculo de la distancia mínima SELECT first_id, min(distance) FROM ( SELECT a.id AS first_id, b.id, ST_Distance(a.last_position, b.last_position) AS distance FROM Dolphins a JOIN Dolphins b ON a.id != b.id) AS distances GROUP BY first_id;
Una vez hemos entendido el sistema nos avisan de que por fin van a empezar a recibir datos de la última posición conocida de cada delfín en tiempo casi real. Nos piden que, para empezar, cuando nos llegue un nuevo dato actualicemos tanto la posición actual como el registro de movimientos de cada delfín. Un simple update con una de las funciones que ya hemos visto debería ser suficiente para lograr nuestro cometido:
UPDATE Dolphins SET last_position = 'POINT(18 18)', movement = ST_AddPoint(movement, 'POINT(18 18)') WHERE id = 5;
Para dejar coherentes todos los datos, deberíamos ser capaces de actualizar también las regiones en caso de que una familia se haya trasladado a otra. Puesto que la complejidad en este caso está más orientada a SQL puro y duro y no vamos a ver nada nuevo de PostGIS os lo dejo a vosotros si os apetece resolverlo.
Conclusiones
Soy consciente de que hemos visto muchas cosas y ahora mismo debéis tener la cabeza a punto de echar humo, pero ya estamos terminando.
Me gustaría que al terminar de leer esto tengáis al menos los conceptos claros y sepáis que este tipo de bases de datos existen. Las bases de datos espaciales son bastante desconocidas por norma general, en gran parte debido a que tienen usos muy concretos y no solemos necesitarlas. Sin embargo, tienen una potencia enorme y abren todo un abanico de posibilidades en cuanto al almacenamiento y tratamiento de los datos. Ya no solo en el aspecto funcional, puesto que llegado el caso podríamos simularlo nosotros a mano con una base de datos normal y código externo, sino por la facilidad para trabajar con ellas y las optimizaciones que implementan a la hora de trabajar con los datos espaciales. Fijaos que, estando yo lejos de ser un experto, hemos montado en un momento un ejemplo bastante curioso con el que trabajar mano a mano con esta tecnología.
Espero que hayáis aprendido algo nuevo y quizá os haya picado el gusanillo para investigar algo más. Por mi parte, y si veo que ha gustado, quizá en el futuro haga un par más de entradas profundizando en temas que he tenido que dejar de lado en esta ocasión.
Imágenes
- Jerarquía de tipos geométricos: versión 1.2.1 de la especificación de SFSQL
- Ejemplo de árbol R
- Imagen del globo terráqueo
- El resto de imágenes son de mi autoría, gran parte generadas gracias a GeoGebra

