
Primeros pasos con Apache Kafka
0. Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Instalación.
- 4. Producer.
- 5. Consumer.
- 6. KafkaLog4jAppender.
- 7. Referencias.
- 8. Conclusiones.
1. Introducción.
Apache Kafka es un sistema de almacenamiento publicador/subscriptor distribuido, particionado y replicado. Estas características, añadidas a que es muy rápido en lecturas y escrituras lo convierten en una herramienta excelente para comunicar streams de información que se generan a gran velocidad y que deben ser gestionados por uno o varias aplicaciones. Se destacan las siguientes características:
- Funciona como un servicio de mensajería, categoriza los mensajes en topics.
- Los procesos que publican se denominan brokers y los subscriptores son los consumidores de los topics.
- Utiliza un protocolo propio basado en TCP y Apache Zookeeper para almacenar el estado de los brokers. Cada broker mantiene un conjunto de particiones (primaria y secundaria) de cada topic.
- Se pueden programar productores/consumidores en diferentes lenguajes: Java, Scala, Python, Ruby, C++ …
- Escalable y tolerante a fallos.
- Se puede utilizar para servicios de mensajería (tipo ActiveMQ o RabbitMQ), procesamiento de streams, web tracking, trazas operacionales, etc.
- Escrito en Scala.
- Creado por LinkedIn.
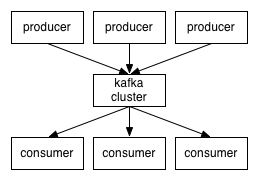
En este tutorial vamos a ver una instalación básica en una máquina, crearemos un productor y un consumidor de topics y configuraremos un appender de logs propio de Kafka que podría servirnos para un sistema de trazas operacionales.
Puedes descargarte el código del tutorial desde aquí.
2. Entorno.
El tutorial se ha realizado con el siguiente entorno:
- MacBook Pro 15′ (2.4 GHz Intel Core i5, 8GB DDR3 SDRAM).
- Sistema Operativo: Mac OS Mavericks 10.9.5
- Oracle Java SDK 1.7.0_60
- Apache Kafka 0.8.1.1
3. Instalación
Lo primero será descargarnos la última versión desde la página web oficial, actualmente es la 0.8.1.1.
Una vez descomprimido kafka, lo movemos al directorio que más nos guste, por ejemplo a /opt/kafka:
$ tar -xvf kafka_2.10-0.8.1.tgz $ mv kafka_2.10-0.8.1 /opt $ cd /opt $ mv kafka_2_10-0.8.1 kafka
Tendremos que dar permisos de ejecución a los scripts dentro del directorio bin
$ cd bin $ sudo chmod +x *
Kafka necesitar Zookeeper para trabajar. Por defecto con la distribución viene uno para pruebas que arrancar una única instancia. Lo arrancamos a través del script de arranque zookeeper-server-start.sh
bin/zookeeper-server-start.sh config/zookeeper.properties
jalonso@MacBook-Pro-Juan-Alonso:/opt/kafka$ bin/zookeeper-server-start.sh config/zookeeper.properties [2014-10-06 18:23:58,321] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) [2014-10-06 18:23:58,343] WARN Either no config or no quorum defined in config, running in standalone mode (org.apache.zookeeper.server.quorum.QuorumPeerMain) [2014-10-06 18:23:58,530] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) [2014-10-06 18:23:58,531] INFO Starting server (org.apache.zookeeper.server.ZooKeeperServerMain) [2014-10-06 18:23:58,568] INFO Server environment:zookeeper.version=3.3.3-1203054, built on 11/17/2011 05:47 GMT (org.apache.zookeeper.server.ZooKeeperServer) [2014-10-06 18:23:58,568] INFO Server environment:host.name=192.168.1.35 (org.apache.zookeeper.server.ZooKeeperServer) [2014-10-06 18:23:58,568] INFO Server environment:java.version=1.7.0_65 (org.apache.zookeeper.server.ZooKeeperServer) [2014-10-06 18:23:58,568] INFO Server environment:java.vendor=Oracle Corporation (org.apache.zookeeper.server.ZooKeeperServer) ... [2014-10-06 18:23:58,711] INFO Snapshotting: 0 (org.apache.zookeeper.server.persistence.FileTxnSnapLog)
En otra consola arrancamos el servidor de Kafka:
bin/kafka-server-start.sh config/server.properties
jalonso@MacBook-Pro-Juan-Alonso:/opt/kafka$ bin/kafka-server-start.sh config/server.properties [2014-10-06 18:24:46,305] INFO Verifying properties (kafka.utils.VerifiableProperties) [2014-10-06 18:24:46,459] INFO Property broker.id is overridden to 0 (kafka.utils.VerifiableProperties) [2014-10-06 18:24:46,459] INFO Property log.cleaner.enable is overridden to false (kafka.utils.VerifiableProperties) [2014-10-06 18:24:46,459] INFO Property log.dirs is overridden to /tmp/kafka-logs (kafka.utils.VerifiableProperties) ... [2014-10-06 18:24:46,555] INFO [Kafka Server 0], starting (kafka.server.KafkaServer) [2014-10-06 18:24:46,558] INFO [Kafka Server 0], Connecting to zookeeper on localhost:2181 (kafka.server.KafkaServer) [2014-10-06 18:24:46,575] INFO Starting ZkClient event thread. (org.I0Itec.zkclient.ZkEventThread) ...
Tanto la configuración de zookeeper como de kafka está en el directorio config donde se configuran los puertos de escucha, directorio de almacenamiento por defecto, número de particiones por defecto, etc.
Zookeeper escucha en el puerto 2181 y almacena por defecto los datos en /tmp/zookeeper. Kafka escuha en el puerto 9092.
4. Producer.
Kafka dispone de un API Java para construir productores y consumidores de mensajes. El productor es muy sencillo, únicamente se indica el servidor donde está corriendo Kafka y el topic por el que escribimos los mensajes:
package com.autentia.tutoriales;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class KafkaProducer {
private static final String KAFKA_SERVER = "localhost:9092";
private final Producer<String, String> producer;
public KafkaProducer() {
final Properties props = new Properties();
props.put("metadata.broker.list", KAFKA_SERVER);
props.put("serializer.class", "kafka.serializer.StringEncoder");
producer = new Producer<String, String>(new ProducerConfig(props));
}
public void send(String topic, String message) {
producer.send(new KeyedMessage<String, String>(topic, message));
}
public void close() {
producer.close();
}
public static void main(String[] args) {
new KafkaProducer().send("test", "esto es un test");
}
}
5. Consumer.
Para ver de forma rápida si el producer está escribiendo en el topic indicado y le llega este mensaje a Kafka podemos arrancar un consumer por línea de comandos:
$ bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test esto es un test
Ahora vamos a construirnos un Consumer mediante el API que nos proporciona Kafka.
package com.autentia.tutoriales;
import java.nio.ByteBuffer;
import java.util.HashMap;
import java.util.Map;
import kafka.api.FetchRequest;
import kafka.api.FetchRequestBuilder;
import kafka.api.PartitionOffsetRequestInfo;
import kafka.common.TopicAndPartition;
import kafka.javaapi.FetchResponse;
import kafka.javaapi.OffsetRequest;
import kafka.javaapi.consumer.SimpleConsumer;
import kafka.message.MessageAndOffset;
import org.apache.log4j.Logger;
public class KafkaConsumer {
private static final Logger log = Logger.getLogger(KafkaConsumer.class);
private static final int FETCH_SIZE = 100000;
private static final int MAX_NUM_OFFSETS = 1;
private static final int BUFFER_SIZE = 64 * 1024;
private static final int TIMEOUT = 100000;
private static final int PARTITION = 1;
private static final int PORT = 9092;
private static final String TOPIC = "test";
private static final String BROKER = "localhost";
private static final String CLIENT = "testClient";
private final SimpleConsumer consumer;
public KafkaConsumer() {
this.consumer = new SimpleConsumer(BROKER, PORT, TIMEOUT, BUFFER_SIZE, CLIENT);
}
public void run() throws Exception {
long readOffset = getLastOffset(consumer, kafka.api.OffsetRequest.EarliestTime());
//consumer never stops
while (true) {
final FetchRequest req = new FetchRequestBuilder().clientId(CLIENT).addFetch(TOPIC, PARTITION, readOffset, FETCH_SIZE) .build();
final FetchResponse fetchResponse = consumer.fetch(req);
for (MessageAndOffset messageAndOffset : fetchResponse.messageSet(TOPIC, PARTITION)) {
long currentOffset = messageAndOffset.offset();
if (currentOffset < readOffset) {
continue;
}
readOffset = messageAndOffset.nextOffset();
final ByteBuffer payload = messageAndOffset.message().payload();
final byte[] bytes = new byte[payload.limit()];
payload.get(bytes);
log.info("[" + messageAndOffset.offset() + "]: " + new String(bytes, "UTF-8"));
}
}
}
public static long getLastOffset(SimpleConsumer consumer, long whichTime) {
final TopicAndPartition topicAndPartition = new TopicAndPartition(TOPIC, PARTITION);
final Map<TopicAndPartition, PartitionOffsetRequestInfo> requestInfo = new HashMap<TopicAndPartition, PartitionOffsetRequestInfo>();
requestInfo.put(topicAndPartition, new PartitionOffsetRequestInfo(whichTime, MAX_NUM_OFFSETS));
final OffsetRequest offsetRequest = new OffsetRequest(requestInfo, kafka.api.OffsetRequest.CurrentVersion(), CLIENT);
return consumer.getOffsetsBefore(offsetRequest).offsets(TOPIC, PARTITION)[0];
}
public static void main(String args[]) {
try {
new KafkaConsumer().run();
} catch (Exception e) {
log.error("Error:" + e);
}
}
}
Levantamos el Producer con el mensaje enviado para el topic ‘test’ y lo que va saliendo por el log del consumer es el mensaje que nos llega por estar suscritos al topic.
Creamos el consumer indicando el host y puerto donde está arrancado el broker. También se configuran parámetros para indiar un timeout, el tamaño del buffer y un identificador para el consumer.
La gran velocidad en lecturas que tiene Kafka se debe a que los topics se leen a partir de un puntero que marca el offset donde empiezan los mensajes. Es responsabilidad del consumer el mantenimiento de este offset.
La salida del consumer por consola devuelve lo mismo que por línea de comandos:
2014-10-09 23:55:26,989 INFO com.autentia.tutoriales.KafkaConsumer.run(KafkaConsumer.java:64) - [0]: esto es un test
6. KafkaLog4jAppender.
Dada la velocidad con la que se escribe en Kafka, un posible caso de uso sería enviar a Kafka las trazas operacionales de nuestra aplicación. De esta forma podriamos configurar consumers de logs que fueran procesándolos para detectar problemas.
Kafka ya dispone de un Log4jAppender que nos hace todo el trabajo del productor de logs, únicamente tendríamos que configurarlo en nuestro log4j.properties:
log4j.rootLogger=INFO, KAFKA, stdout log4j.appender.KAFKA=kafka.producer.KafkaLog4jAppender log4j.appender.KAFKA.layout=org.apache.log4j.PatternLayout log4j.appender.KAFKA.layout.ConversionPattern=%-5p: %c - %m%n log4j.appender.KAFKA.Topic=logs log4j.appender.KAFKA.BrokerList=localhost:9092 log4j.appender.KAFKA.ProducerType=async log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target=System.out log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%-5p: %c - %m%n log4j.logger.com.autentia.tutoriales=INFO
Si lanzamos la clase KafkaConsumer vemos cómo en el topic ‘logs’ aparecen los logs de info que envía.
[0]: esto es un test Fetching metadata from broker id:0,host:localhost,port:9092 with correlation id 0 for 1 topic(s) Set(logs) Connected to localhost:9092 for producing Disconnecting from localhost:9092 Connected to localhost:9092 for producing
7. Referencias.
- http://kafka.apache.org/07/quickstart.html
- http://www.slideshare.net/miguno/apache-kafka-08-basic-training-verisign
8. Conclusiones.
Son muchos las compañias (LinkedIn, Twitter, Netflix, Square, Spotify, Pinterest, Uber, Tumblr y muchos más) las que utilizan Apache Kafka para analizar tráfico de sus aplicaciones, como parte de su infraestructura de procesamiento de datos, monitorización en tiempo real, como bus de eventos, etc.
En próximos tutoriales lo configuraremos para trabajar con Twitter y Storm.
Puedes descargarte el código del tutorial desde aquí.
Espero que te haya sido de ayuda.
Un saludo.
Juan


Muchas gracias, sencillo y preciso.
[…] ejemplo el sistema de almacenamiento distribuido Apache Kafka (como podemos ver en los tutoriales Primeros pasos con Apache Kafka ó Monitorización de Apache […]
Muchas gracias! Estupendo para los que estamos aterrizando con este nuevo producto!
Genial! muchas gracias.
¿Y porque no utilizar directamente JMS?
Por que Kafka trabaja en clustered y ademas con streaming.
Tienes un error garrafal en el inicio.
«chmod +x» da permisos para ejecutar.
Bash interpreta * como todo, eso significa que directorios arriba y directorios abajo, a todo le diste permisos para ejecutarse.
Eso es una idea muy mala y probablemente te cause problemas. Debes seleccionar solo los ejecutables que kafka instala.
Saludos
Gracias es realmente util.
Muy bueno! Mucho mejor la página oficial. Gracias tío.
Citando el ejemplo, que mencionas sobre el consumidor de logs, esto lo podria aplicar para un servidor de aplicaciones, por ejemplo JBoss, procesando los logs con Kafka?.
Un saludo, y gracias por el conocimiento.
Hola Juan,
Muchas gracias por el artículo.
Con el ánimo de mejorar, debo decirte que hay una imprecisión al principio.
Apache Kafka no es un sistema de almacenamiento.
Saludos
Genial! Gracias por el articulo.
En mi caso, estoy mirando de utilizar esta herramienta para comunicación entre llamadas de micro-servicios. Creéis que podría ser una buena solución o quizás debería enfocar más a Rabbitmq?
Gracias