
Existen muchas opciones para conectar microservicios entre sí, las comunicaciones no tienen porque ser todas síncronas
mediante invocaciones directas haciendo uso del servicio de descubrimiento; también podemos realizar invocaciones
asíncronas haciendo uso de brokers de mensajería.
Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Configuración.
- 4. Publicación de un evento.
- 5. Consumo de un evento.
- 6. Integración del productor y el consumidor.
- 7. Referencias.
- 8. Conclusiones.
1. Introducción.
Spring Cloud Stream es un proyecto de Spring Cloud construido sobre la base de Spring Boot y Spring Integration que
nos facilita la creación de microservicios bajo los patrones de message-driven y event-driven.
El hecho de estar construido sobre la base de Spring Boot hace que sea muy sencilla su configuración mediante el
soporte de starters, anotaciones y propiedades de configuración susceptibles de elevarse a un servicio de configuración
centralizada y es el soporte de Spring Integration el que proporciona la conectividad con brokers de mensajería.
El patrón message-driven, en el entorno de microservicios, introduce el concepto de comunicación asíncrona
entre microservicios dirigida por el envío de mensajes; un mensaje es un dato que se envía a un destino específico.
El patrón event-driven, sobre la base del patrón anterior y usando el mismo canal de comunicaciones,
se orienta al envío de eventos; un evento es una señal emitida por un componente al alcanzar un determinado estado.
Sobre la base de estos principios se construyen patrones como CQRS y Sagas que, en un entorno de microservicios
nos ayudan a mantener, eventualmente, consistente la información, mediante la generación de eventos de
dominio (conceptos de DDD).
En este tutorial haremos una introducción al proyecto Spring Cloud Stream, como candidato para implementar dichos
patrones en un entorno de microservicios, abstrayéndonos totalmente de la capa de transporte y sin necesidad de conocer
detalles sobre el protocolo de comunicación.
Se presuponen conocimientos de Spring Boot y Spring Cloud, puesto que no se generará ninguno de los proyectos
en los que se basan las pruebas desde cero.
2. Entorno.
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 15′ (2.5 GHz Intel Core i7, 16GB DDR3).
- Sistema Operativo: Mac OS Sierra 10.12.5
- Oracle Java: 1.8.0_25
- Spring Cloud Ditmars.SR3
- Spring Boot 1.5.9.RELEASE
3. Configuración.
Se recomienda la configuración mediante el sistema de gestión de dependencias de maven y, para ello, lo primero es
incluir las siguientes dependencias en nuestro pom.xml
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-dependencies</artifactId>
<version>Ditmars.SR3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
</dependencies>
En cuanto incluimos la dependencia de Spring Cloud Stream, que arrastra de forma transitiva la de Spring Cloud Stream
Binder, cualquier aplicación Spring Boot con la anotación @EnableBinding intentará engancharse al broker
de mensajería externo que encuentre en el classpath (Rabbit MQ, Apache Kafka,…).
A continuación definiremos los canales de comunicaciones en el fichero de configuración de nuestras aplicaciones (application.yml) y aquí vamos
a hacer una distinción entre el productor de los eventos (command) y el consumidor de los mismos (query).
Esta sería la configuración del productor (command):
spring:
cloud:
stream:
bindings:
output:
destination: queue.orders.events
binder: local_rabbit
binders:
local_rabbit:
type: rabbit
environment:
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
virtual-host: /
A continuación la configuración del consumer (query):
spring:
cloud:
stream:
bindings:
input:
destination: queue.orders.events
binder: local_rabbit
binders:
local_rabbit:
type: rabbit
environment:
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
virtual-host: /
La diferencia está en la semántica del canal, en este segundo usamos «input» en vez de «output».
Por último, antes de comenzar con nuestra emisión de eventos, vamos a incluir las dependencias necesarias para poder
ejecutar tests de integración, como sigue:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-test-support</artifactId>
<scope>test</scope>
</dependency>
4. Publicación de un evento (command).
Para publicar un evento lo primero es definir la estructura de datos del evento a emitir, en nuestro caso vamos a
publicar un evento de generación de un pedido, con la información del pedido creado:
@Builder
@Getter
public class OrderCreationEvent implements Serializable{
private Order order;
}
En este punto debemos tomar una decisión, ¿compartimos estructuras de los datos de los eventos entre
microservicios?. Si añadimos a la estructura de los eventos tipos complejos como en este ejemplo, se convertirá
en un problema de dependencias y no queremos hacer que nuestros microservicios dependan de una única estructura
de dominio con lo que, pensadlo primero, la estructura de datos de los eventos debería tener su propia estructura
de datos independiente del dominio de negocio de cada microservicio. No deberíamos incluir en el evento
objetos específicos de dominio como, en el ejemplo, el pedido.
A continuación, vamos a añadir a nuestra configuración la anotación @EnableBinding(Processor.class)
para realizar un binding con el stream correspondiente (por defecto con Processor.class tendremos los canales «output» e «input»
que ya hemos definido en el application.yml).
package com.autentia.training.microservices.spring.cloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.feign.EnableFeignClients;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.autentia.training.microservices.spring.cloud.order.repository.OrderRepository;
import com.autentia.training.microservices.spring.cloud.product.consumer.ProductConsumerFallBack;
import com.autentia.training.microservices.spring.cloud.service.OrderResourceService;
@SpringBootApplication
@EnableDiscoveryClient
@EnableCircuitBreaker
@EnableFeignClients
@Configuration
@EnableBinding(Processor.class)
public class OrdersCommandApplication {
public static void main(String[] args) {
SpringApplication.run(OrdersApplication.class, args);
}
@Bean
public OrderResourceService orderService(OrderRepository orderRepository, Source pipe){
return new OrderResourceService(orderRepository, pipe);
}
}
Podemos configurar una fuente (Source.class), un destino (Sink.class) o ambos (Producer.class), lo único que estamos
haciendo es declarar como canales «input» y/o «output», según el caso.
Lo siguiente es publicar el evento y lo vamos a enviar en nuestro servicio de negocio justo después de persistir la entidad;
para ello debemos recibir la inyección del repositorio (Spring Data) y la fuente para poder realizar el envío.
package com.autentia.training.microservices.spring.cloud.service;
import java.time.LocalDateTime;
import java.util.List;
import java.util.stream.Collectors;
import javax.transaction.Transactional;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.integration.support.MessageBuilder;
import com.autentia.training.microservices.spring.cloud.event.OrderCreationEvent;
import com.autentia.training.microservices.spring.cloud.order.domain.Order;
import com.autentia.training.microservices.spring.cloud.order.domain.OrderLine;
import com.autentia.training.microservices.spring.cloud.order.repository.OrderRepository;
import com.autentia.training.microservices.spring.cloud.order.vo.OrderResource;
@Transactional
public class OrderResourceService {
private OrderRepository orderRepository;
private Source pipe;
public OrderResourceService(OrderRepository orderRepository, Source pipe) {
this.orderRepository = orderRepository;
this.pipe = pipe;
}
public Order create(OrderResource orderResource) {
final Order orderCreated = orderRepository.save(mapOrder(orderResource));
pipe.output().send(MessageBuilder.withPayload(OrderCreationEvent.builder().order(orderCreated).build()).build());
return orderCreated;
}
private Order mapOrder(OrderResource orderResource) {
final List lines = orderResource.getLines().stream()
.map(line -> OrderLine.builder().build())
.collect(Collectors.toList());
return Order.builder().createdAt(LocalDateTime.now()).lines(lines).build();
}
}
Una vez hecho esto vamos a comprobar que realmente se envía escribiendo el siguiente test de integración:
package com.autentia.training.microservices.spring.cloud.service;
import static org.junit.Assert.assertThat;
import static org.junit.Assert.assertTrue;
import java.util.concurrent.BlockingQueue;
import org.hamcrest.Matchers;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Sink;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.cloud.stream.test.binder.MessageCollector;
import org.springframework.messaging.Message;
import org.springframework.test.annotation.DirtiesContext;
import org.springframework.test.context.ActiveProfiles;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import com.autentia.training.microservices.spring.cloud.OrdersApplication;
import com.autentia.training.microservices.spring.cloud.event.OrderCreationEvent;
import com.autentia.training.microservices.spring.cloud.order.domain.Order;
import com.autentia.training.microservices.spring.cloud.order.vo.OrderResource;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = OrdersApplication.class, webEnvironment = SpringBootTest.WebEnvironment.NONE)
@DirtiesContext
@ActiveProfiles("development")
public class OrderResourceServiceIT {
@Autowired
private Source channels;
@Autowired
private MessageCollector collector;
@Autowired
private OrderResourceService orderService;
@Test
public void shouldPropagateOrderCreationEvents() {
// given
final BlockingQueue> messages = this.collector.forChannel(channels.output());
// when
final Order order = orderService.create(OrderResource.builder().build());
// then
assertThat(messages, Matchers.hasSize(1));
assertTrue(messages.stream().filter(o -> ( (OrderCreationEvent) o.getPayload()).getOrder().getId() == order.getId()).findFirst().isPresent());
}
}
Declaramos por inyección de dependencias un recolector de mensajes y el canal fuente definido en el binder; con este
último configuramos el recolector y comprobamos que una vez invocado el servicio de negocio podemos consumir un evento
almacenado en el recolector que tiene como payload la estructura de datos del evento enviado.
En este punto deberíamos estar en verde.
5. Consumo de un evento (query).
Consumir el evento desde un test de integración esta más que bien, pero el objetivo es consumirlo desde
otro microservicio, para lo cuál debemos realizar la misma configuración en cuanto a dependencias de maven
en nuestro segundo microservicio y crear la estructura de datos a la que se mapeará la recepción del evento.
Lo siguiente es configurar el binder y un método de listener que escuchará los eventos:
package com.autentia.training.microservices.spring.cloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.circuitbreaker.EnableCircuitBreaker;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.feign.EnableFeignClients;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Processor;
import org.springframework.cloud.stream.messaging.Sink;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.autentia.training.microservices.spring.cloud.event.OrderCreationEvent;
import lombok.extern.slf4j.Slf4j;
@SpringBootApplication
@EnableDiscoveryClient
@EnableCircuitBreaker
@EnableFeignClients
@Configuration
@EnableBinding(Sink.class)
@Slf4j
public class OrdersApplication {
public static void main(String[] args) {
SpringApplication.run(OrdersApplication.class, args);
}
@StreamListener(Processor.INPUT)
public void transform(OrderCreationEvent playload) {
log.info("order received {}", playload.getOrder().getId());
}
}
El listener solo traza la recepción del evento con el sistema de logging estándar (Simple Logging Facade For Java).
Y, como no, vamos a probar el envío y la recepción con un test de integración dentro del contexto del propio
microservicio:
package com.autentia.training.microservices.spring.cloud.service;
import static org.awaitility.Awaitility.await;
import static org.hamcrest.CoreMatchers.containsString;
import java.time.LocalDateTime;
import java.util.concurrent.Callable;
import java.util.concurrent.TimeUnit;
import org.junit.Before;
import org.junit.Rule;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.rule.OutputCapture;
import org.springframework.cloud.stream.messaging.Sink;
import org.springframework.integration.support.MessageBuilder;
import org.springframework.test.annotation.DirtiesContext;
import org.springframework.test.context.ActiveProfiles;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import com.autentia.training.microservices.spring.cloud.OrdersApplication;
import com.autentia.training.microservices.spring.cloud.event.OrderCreationEvent;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = OrdersApplication.class, webEnvironment = SpringBootTest.WebEnvironment.NONE)
@DirtiesContext
@ActiveProfiles("development")
public class OrderCreationEventIT {
@Rule
public OutputCapture capture = new OutputCapture();
@Autowired
private Sink channels;
@Before
public void setup() {
capture.flush();
}
@Test
public void shouldConsumeOrderCreationEvents() {
// when
channels.input().send(MessageBuilder.withPayload(OrderCreationEvent.builder().id(1L).createdAt(LocalDateTime.now()).build()).build());
// then
await().atMost(10, TimeUnit.SECONDS).until(getCapturedContentAsString(), containsString("order received 1"));
}
private Callable getCapturedContentAsString() {
return new Callable() {
public String call() throws Exception {
return capture.toString();
}
};
}
}
Simulamos el servicio que emite un evento generándolo nosotros manualmente y como el listener simplemente traza un
mensaje y en el entorno de test la salida es por consola, la capturamos y esperamos 10 segundos a que se imprima.
En este punto deberíamos estar también en verde.
6. Integración del productor (command) y el consumidor (query).
Tenemos ambos tests de integación funcionando y ahora vamos a realizar una prueba integrada de los dos microservicios
para lo cuál necesariamente tendremos que levantar el broker de mensajería en local para comprobar el envío y la recepción.
Para levantar en local un Rabbit MQ, que mejor que docker y con el siguiente comando lo tendremos funcionando en un solo
paso, exponiendo los mismos puertos que ya tenemos configurados en el application.yml de ambos microservicios
(en entornos productivos en nuestro servicio de configuración centralizada).
docker run -d --hostname localrabbit --name demo-rmq -p 15672:15672 -p 5672:5672 rabbitmq:3.6.11-management
Al finalizar el comando anterior, con el siguiente docker ps deberíamos tener un contenedor levantado como el que se muestra a continuación:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ad2002c9ca3c rabbitmq:3.6.11-management "docker-entrypoint.s…" 16 seconds ago Up 16 seconds 4369/tcp, 5671/tcp, 0.0.0.0:5672->5672/tcp, 15671/tcp, 25672/tcp, 0.0.0.0:15672->15672/tcp demo-rmq
Si levantamos los dos microservicios con un perfil de desarrollo, sin necesidad de depender de los servicios
estructurales de Spring Cloud y probamos a lanzar una operación contra el API que termina generando un pedido
podremos comprobar como se emite el evento desde el microservicio de command y podemos
consumirlo desde el microservicio de query.
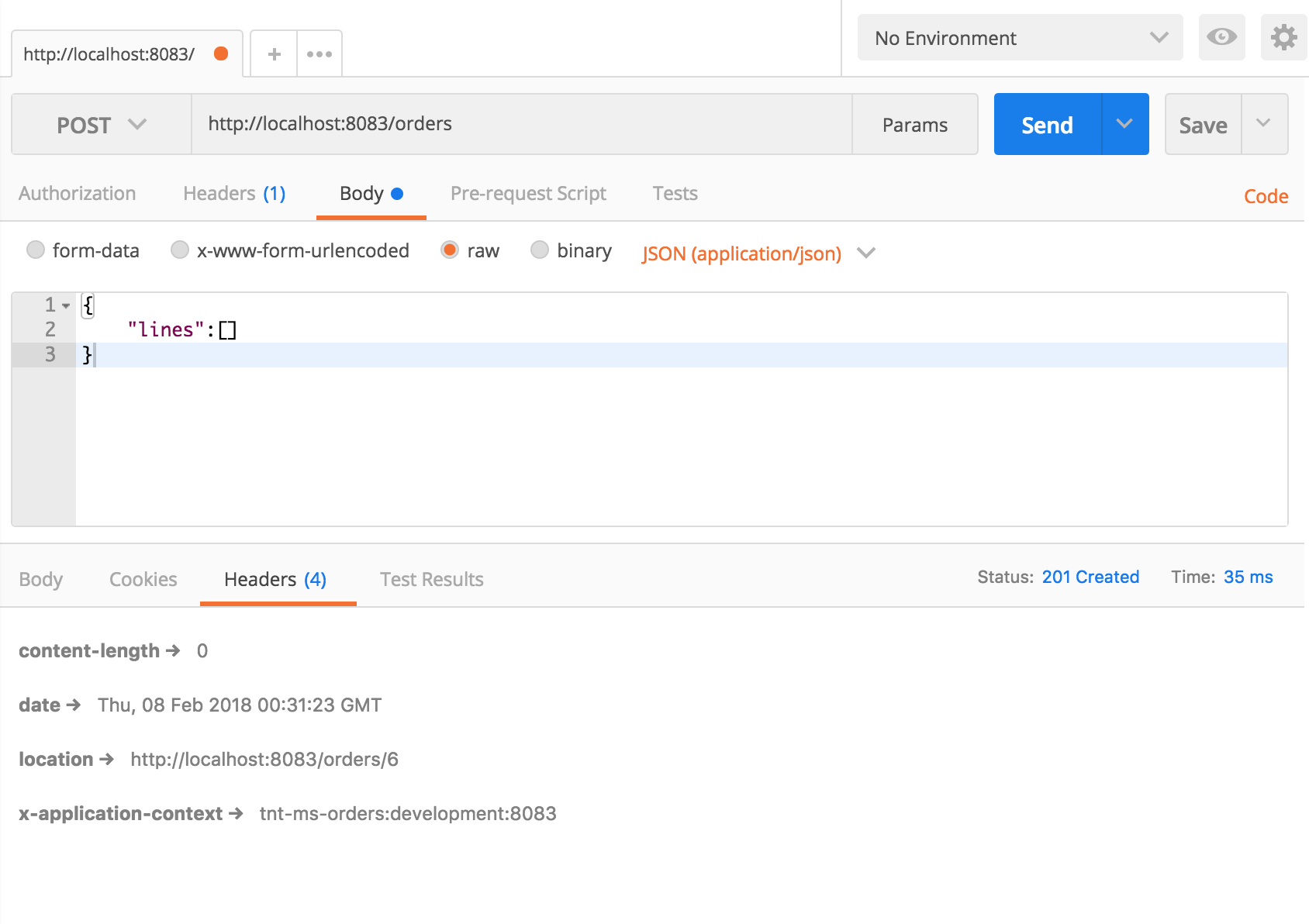
A continuación os muestro un ejemplo de invocación desde postman con la confirmación de la creación del recurso
con la cabecera de location:
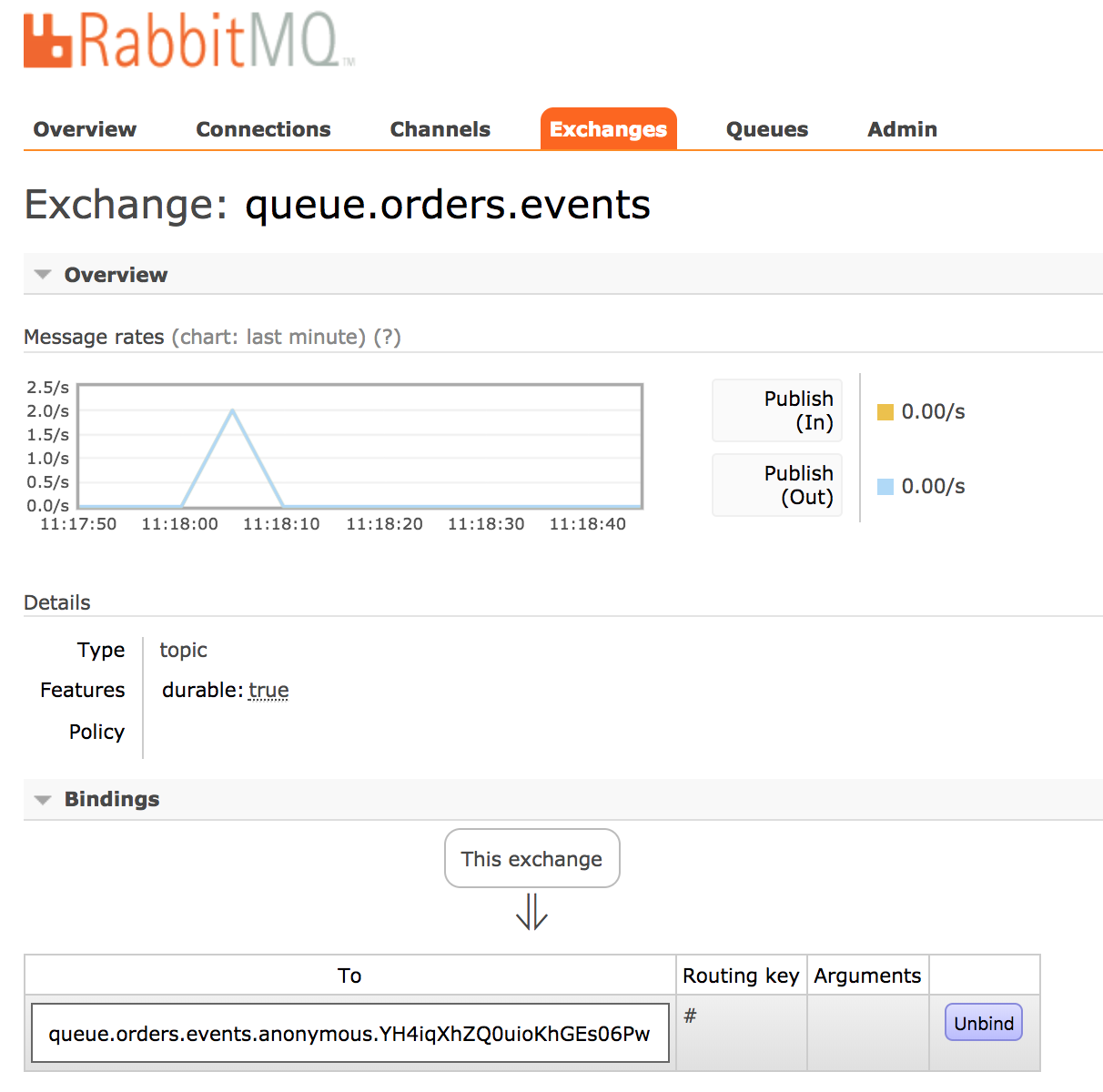
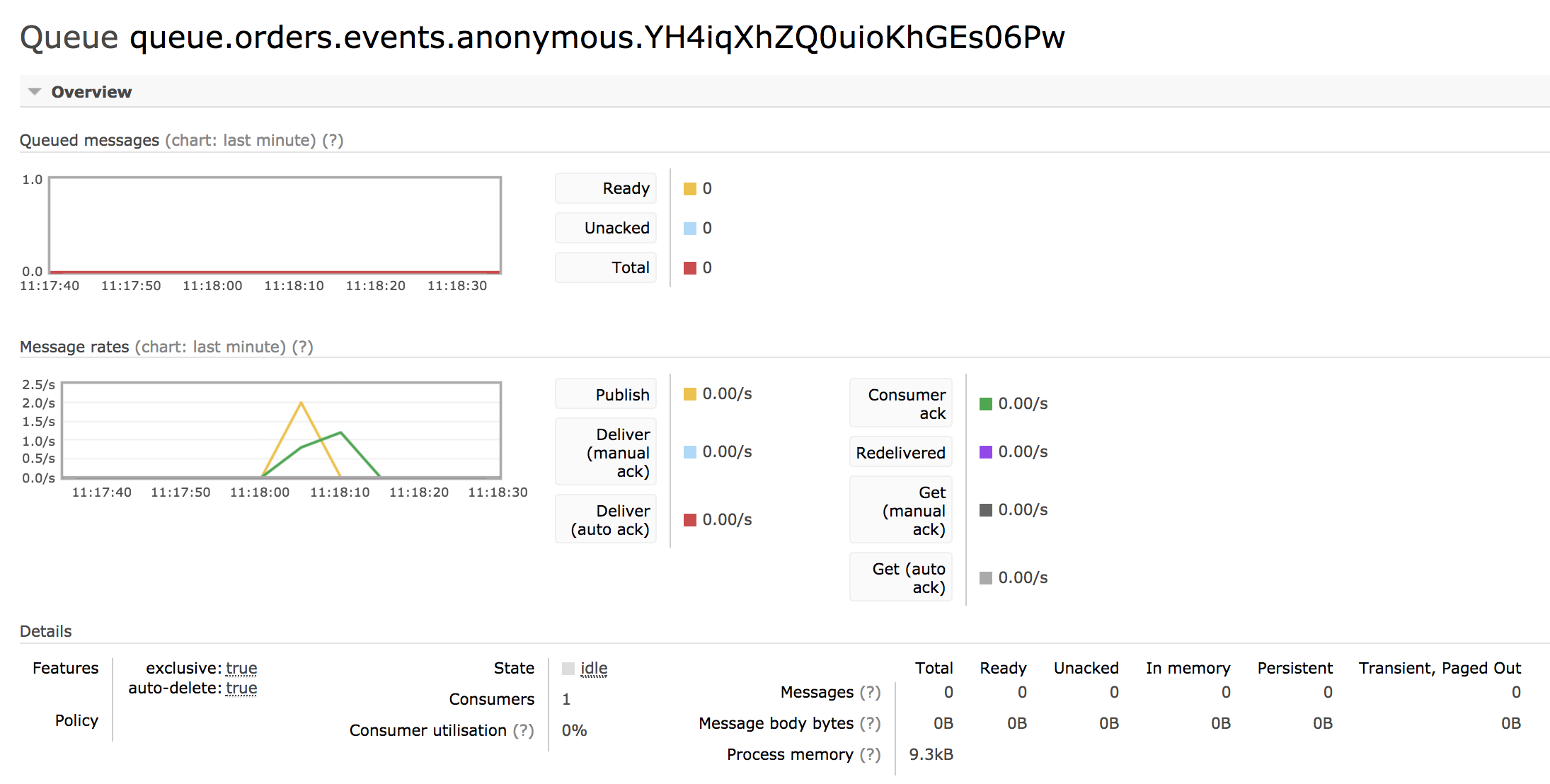
Si accedemos a la consola del segundo microservicio podremos comprobar cómo se imprime por consola la traza del
evento aunque también podemos comprobar, desde la consola de administración del propio Rabbit MQ, las estadísticas
de envío de mensajes en el canal que hemos definido.
Para ello no tenemos más que acceder a través de un navegador a http://localhost:15672/
7. Referencias.
- http://projects.spring.io/spring-cloud/
- https://cloud.spring.io/spring-cloud-stream/
- http://martinfowler.com/eaaDev/EventSourcing.html
- http://martinfowler.com/bliki/CQRS.html
8. Conclusiones.
Continuamos explotando las posibilidades del stack de Spring Cloud y nos sorprendemos de la sencillez;
cada vez más nos olvidamos de la configuración y uso de plantillas para acercarnos a los conceptos de los
patrones que queremos implementar.
Un saludo.
Jose


Muy interensante. Gracias por compartirlo…Podrían subir también el código fuente??
Thanks for the article post.Really thank you! Great.
Podéis encontrar el código fuente aquí:
https://github.com/jmsanchez/tnt-ms-architecture/tree/feature/messaging
Un saludo.
Jose.
Hola, excelente aporte,
Una pregunta realice un ejemplo en donde publico el mensaje en la cola sin ninguna aplicación que consuma este mensaje, al iniciar la aplicación para consumir al parecer entiende que no hay nada pendiente y no hace nada, pero si el consumidor esta arriba cuando publico el mensaje si que lo recupero. hay una manera de que este mensaje quede encolado mientras alguien lo recupera? o si pasa algún error que lo ponga de nuevo en la cosa para que sea procesado después?
Gracias