
Introducción a Apache Hive, el datawarehouse de Hadoop
0. Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Instalación.
- 4. Tipos de datos.
- 5. Cargar los datos en HDFS.
- 6. Procesar los datos en Hive.
- 7. Conclusiones.
1. Introducción.
Apache Hive es un framework originalmente creado por Facebook que sirve para trabajar con el HDFS – Hadoop Distributed File System que nos facilita enormemente el trabajo a la hora de trabajar con los datos. Su funcionamiento es sencillo, a través de querys SQL (HiveQL) podemos lanzar consultas que serán traducidas a trabajos MapReduce. Ya vimos en otro tutorial que resulta laborioso programar algoritmos MapReduce, sobre todo si el problema de datos es complejo. Hive nos facilita enormemente este trabajo ya que traduce consultas tipo SQL a trabajos MapReduce paralelizables contra el dataset en un entorno completamente distribuido.
Aunque Hive no es una base de datos lo cierto es que sí lo parece ya que para trabajar con los datos debemos crearnos un esquema, definir la tabla con sus columnas y tipo de dato de cada una de ellas, hacer la carga de los datos inicial y posteriormente realizar las consultas para recoger lo que nos interese. Por todo ello se conoce como el componente datawarehouse de Hadoop.
Tiene como inconveniente que al necesitar procesar la query y traducirla a lenguaje Java para crear el job MapReduce, la latencia de respuesta es alta. Tampoco soporta todo el lenguaje SQL, transacciones ni índices.
En este tutorial vamos a ver unos primeros pasos para ver cómo trabajar con Hive trabajando con un dataset de datos públicos lanzando algunas queries y mostranso los resultados.
2. Entorno.
El tutorial se ha realizado con el siguiente entorno:
- MacBook Pro 15′ (2.4 GHz Intel Core i5, 8GB DDR3 SDRAM).
- VirtualBox
- Sandbox HDP Hortonworks Data Platform
3. Instalación
Si utilizas la máquina virtual de Hortonworks HDP ya viene instalada una versión de Hive. Si decides instalarlo en tu máqina tendrás que descargar el binario de hive de la web oficial, descomprimir y crear la variable de entorno HIVE_HOME en el .bashrc apuntando al directorio de instalación. Añadir también la variable creada al PATH.
tar -xzvf apache-hive-0.14.0-bin
export HIVE_HOME=/usr/local/hive export PATH:$PATH:$HIVE_HOME/bin
4. Tipos de datos.
En Hive los datos se pueden representar de diferentes tipos, muy similar a un motor de base de datos:
Tipos simples:
- TINYINT: 1 byte para números enteros con signo.
- SMALLINT: 2 bytes para números enteros con signo.
- INT: 4 bytes para números enteros con signo.
- BIGINT: 8 bytes para números enteros con signo.
- FLOAT: 4 bytes para números en coma flotante.
- DOUBLE: 8 bytes para números en coma flotante.
- TIMESTAMP: almacenar fecha y hora
- DATE: almacenar fechas
- STRING
- VARCHAR
- CHAR
- BOOLEAN
- BINARY
Tipos complejos: muy útiles para almacenar colecciones de datos de tipos simples.
- ARRAY
- MAP
- STRUCT
- UNIONTYPE
Hive proporciona una funcionalidad básica de SQL estándar. Una vez escrita la query es traducida a un proceso MapReduce que será ejecutado sobre el clúster HDFS. Para nosotros esto será transparente, ahora nos debemos centrar en los datos disponibles y de la información que queremos sacar. La sintáxis básica que acepta Hive comprende lo siguiente:
- INSERT INTO SELECT
- FROM … JOIN … ON WHERE
- GROUP BY
- HAVING
- ORDER BY
- LIMIT
- CREATE/ALTER/DROP TABLE/DATABASE
5. Cargar los datos en HDFS.
Como decíamos en la introducción, Hive posee un lenguaje para la definición de de datos llamado Hive QL. Es muy similar al SQL estándar y con él podemos crearnos el schema con el que trabajar, crear/borrar las distintas tablas, columnas, tipos de datos de las columnas, vistas, particiones, funciones, permisos y muchas cosas más.
Vamos a ir viendo todo esto de forma práctica con una fuente de datos que he descargado del Portal de Datos Abiertos del Ayuntamiento de Madrid. Concretamente voy a utilizar un dataset que muestra los presupuestos municipales para el año 2015. Puedes descargarlo de aquí. El fichero está en formato .xls. Lo primero que haremos será convertirlo a fichero de texto .csv para poder trabajar mejor con él.
Este dataset contiene unas 5000 líneas con los apuntes económicos clasificados por categorías, descripción, importe, etc. Abrirlo directamente no dice gran cosa por lo que vamos a procesarlo con Hive para extraer la información más relevante.
Una vez descargado el dataset, debemos importarlo a la sandbox. Para ello entramos con el navegador a la interfaz del ‘Hue’ que nos habilita varias herramientas disponibles en la URL http://127.0.0.1:8000/. Concretamente accedemos a la opción ‘File browser’.
Dentro de la ventana del ‘File browser’ a la derecha aparece la opción ‘Upload’ y al desplegar seleccionamos ‘Files’
Desde esa opción podemos subir el archivos .csv de los datos de los presupuestos. Una vez subidos nos aparecerán en la tabla con el nombre gastos_v40_2015.csv.
Si todo ha ido bien tendremos los datos subidos al filesystem de Hadoop. Pinchando en el enlace de la tabla accedemos a los datos.
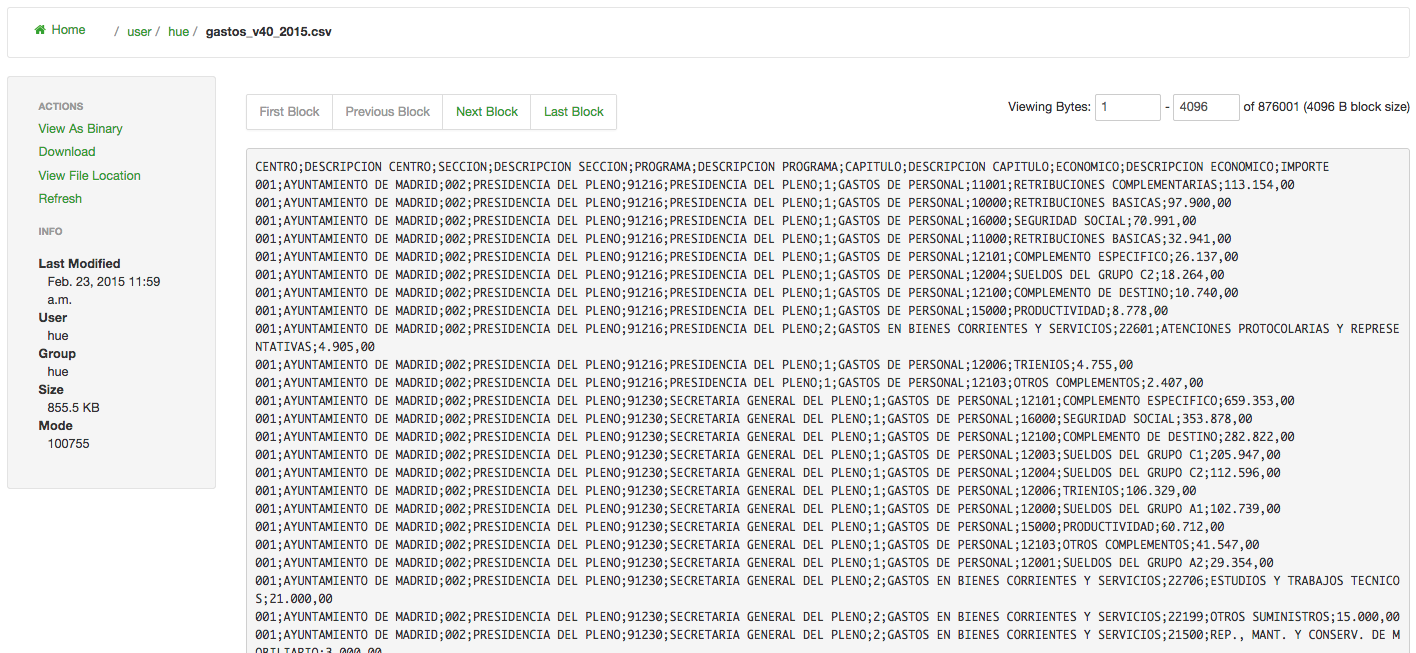
6. Procesar los datos en Hive.
Para sacarle partido a los datos de los que disponemos vamos a crear una base de datos en Hive con una tabla presupuestos, posteriormente cargaremos los datos del archivo. Aunque todas las sentencias se pueden ejecutar por línea de comandos resulta muy cómodo utilizar el interfaz web del Query Editor de Hive.
Crear la base de datos
Lo primero será crear la base de datos donde almacenar los datos del fichero.
create database if not exists presupuestos_madrid_2015;
Podemos comprobar si se ha creado correctamente:
show databases;
Crear la tabla
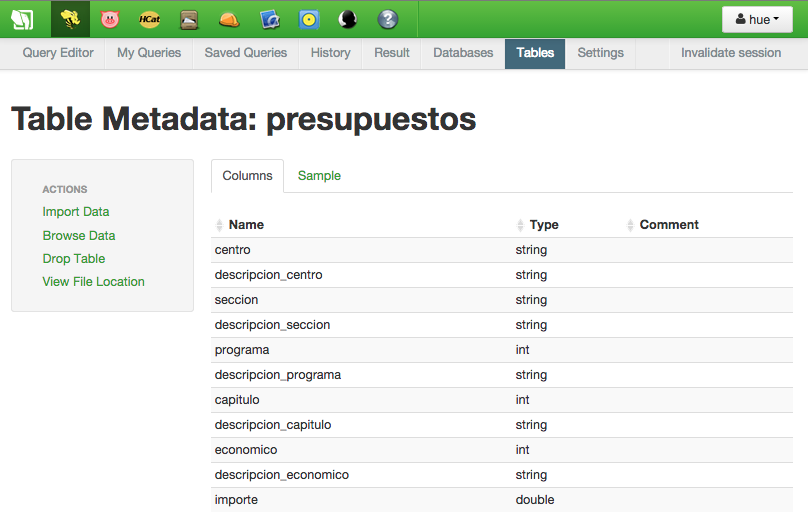
Ahora vamos a crear una tabla para proporcionar estructura a los datos del fichero. La sintaxis es muy parecida a la de SQL, se le indica el nombre de la columna y el tipo de datos. Para este ejemplo sólo voy a crear una tabla pero viendo los datos se podría normalizar y sacar varias tablas que clasificaran aún más los datos de los que disponemos.
create table if not exists presupuestos ( centro string, descripcion_centro string, seccion string, descripcion_seccion string, programa int, descripcion_programa string, capitulo int, descripcion_capitulo string, economico int, descripcion_economico string, importe string ) row format delimited fields terminated by ';'
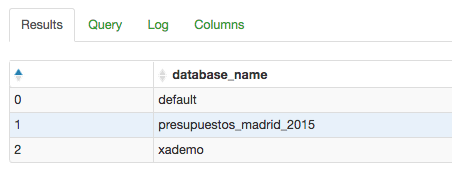
Una vez ejecutada podemos comprobar si la ha creado desde la pestaña ‘Tables’:
Cargar los datos
Ya sólo nos queda añadir los datos del fichero a la tabla. Lo hacemos de la siguiente forma:
load data inpath '/user/hue/gastos_v40_2015.csv' overwrite into table presupuestos;
Ejecutamos la query y vamos a la opción ‘Tables’ seleccionamos la tabla ‘presupuestos’ y luego a la pestaña ‘Sample’
Consultar los datos
Una vez que tenemos los datos de nuestro fichero cargados en la tabla de Hive podemos ejecutar las queries que se nos ocurran.
Sacar la partida del ayuntamiento que más presupuesto se lleva:
select descripcion_centro, descripcion_seccion, descripcion_capitulo, descripcion_economico, importe from presupuestos order by importe
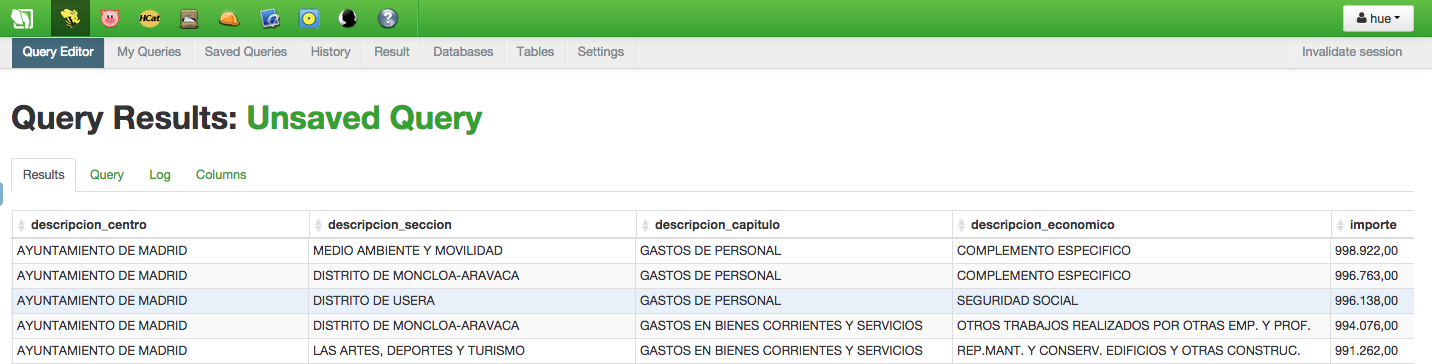
Vemos que el departamento con una partida más alta es el de MEDIO AMBIENTE Y MOVILIDAD para GASTOS DE PERSONAL de COMPLEMENTO ESPECíFICO.
Por ejemplo si queremos saber que otros gastos tiene el mismo departamento:
select descripcion_centro, descripcion_seccion, descripcion_capitulo, descripcion_economico, importe from presupuestos where descripcion_seccion = 'MEDIO AMBIENTE Y MOVILIDAD'
Como véis una vez que tenemos los datos de un fichero cargados en la tabla podemos a través de queries SQL recuperar los datos que queramos. Desde la pestaña ‘log’ se puede ver cómo las queries son traducidas a jobs MapReduce. Algunas queries complejas tardan bastante sobre todo en hacer los Reduce debido a que se ejecuta todo en la misma máquina virtual.
7. Conclusiones.
Si trabajas con un gran volúmen de datos en un clúster de Hadoop y no dispones de suficientes conocimientos o tiempo para programar los algoritmos MapReduce, Hive es una excelente herramienta para sacar los datos que te puedan interesar.
Imagina tener cientos de pesados fichero de log de un servidor, lo difícil que es bucear por ellos. Con Hive resultaría sencillo crear una tabla a partir de los datos del fichero y filtrar por ejemplo las líneas que contengan errores. Es un ejemplo de uso pero utilidades hay muchas.
Espero que te haya sido de ayuda.
Un saludo.
Juan


Buena explicacion, puedes realizar un ejemplo con hcatalog?
Hola Juan.
Muchas gracias por hacernos la vida más fácil, y por este trabajo gratuito que realizas. Un saludo.
Gracias Juan , excelente , me gustaria saber si se puede explicar bien cual es la diferencia de hive con hive2.
y cual es la diferencia principal que tiene con sql?
Hive solo se instala sobre Linux? porque toda la ayuda de instalación que publicas esta en eso
Un favor se requiere tener instalado hadoop o este producto funciona solo?