
Lectura y tratamiento de ficheros Excel con Talend (II): filtros y splits
0. Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Fuente de datos.
- 4. Diseño del Job de Talend.
- 5. Referencias.
- 6. Conclusiones.
1. Introducción
Siguiendo el hilo argumental del tutorial sobre indexación de documentos en Solr con el soporte de Talend, y tomando como referencia el tutorial sobre Lectura y tratamiento de ficheros Excel con Talend (I): nociones básicas, supongamos ahora que no solo disponemos de la información sobre el catálogo de libros en un formato estandar xml, si no que, además, existe información dispersa en documentos Excel, como, por ejemplo, las editoriales o el número de ejemplares en stock de los libros. Por lo que sea, esa información no existe en xml y se ha ido almacenando en ficheros Excel. Cierto es que cuando no se dispone del software adecuado las hojas de cálculo son el comodín perfecto, la de departamentos y unidades de negocio que basan su día a día en la elaboración, envío y análisis de hojas Excel.
Sobre las nociones básicas comentadas por Dani en el tutorial sobre Excel con Talend, en este tutorial vamos a ver como analizar, de una manera muy simple, el contenido de una hoja Excel, para darle, por ejemplo, una salida a una tabla de base de datos, aunque no lo veremos explícitamente en este tutorial, con lo que la salida podría ser cualquiera.
Dentro de ese análisis haremos un filtro y un split de una columna para tratar la información de una manera normalizada.
2. Entorno.
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 15′ (2.4 GHz Intel Core i7, 8GB DDR3 SDRAM).
- Sistema Operativo: Mac OS X Lion 10.7.4
- Talend Open Studio 5.1.1.
3. Fuente de datos.
Supongamos que disponemos de la información estructurada en las siguientes columnas de una hoja Excel:

Disponemos información sobre el número de ejemplares en stock y las editoriales asociadas a un libro se encuentran en una única columna separadas por comas.
4. Diseño del Job de Talend.
La parte de lectura del fichero Excel y normalización de su información podría tener, en la vista de diseño, un aspecto similar al siguiente:
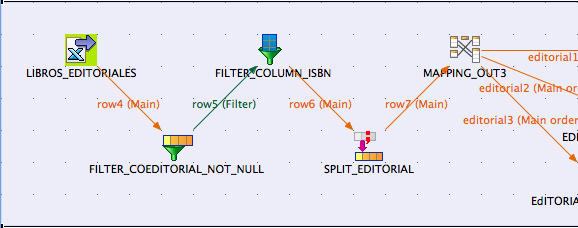
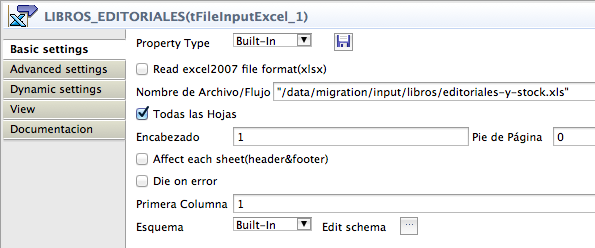
La configuración de la lectura del Excel se basa en la asignación de un fichero de entrada y una serie de parámetros, como por ejemplo, que empiece a procesar el fichero a partir de una columna específica para escapar la típica fila de cabeceras de las columnas.
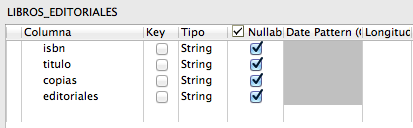
Pulsando sobre «Edit schema» podemos establecer, por orden, las columnas a leer del fichero asignando un nombre. Aunque no nos interese el contenido de una columna debemos mapearlo si se encuentra antes de otra interesante, esto es, no nos podemos saltar columnas.
Con ello se realizará una lectura secuencial de las filas del fichero Excel almacenando el valor de las columnas para su tratamiento.
Lo siguiente podría ser introducir un filtro para que, en función del valor de una columna, se continúe con el tratamiento de la fila o no. En nuestro caso hemos establecido un filtro para que no procese los libros sin stock, usando una función de longitud de cadena.

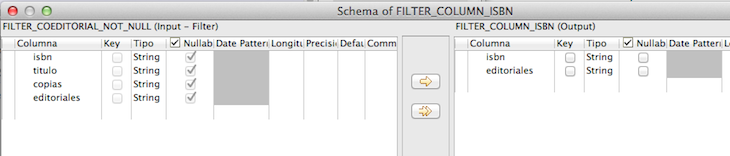
A continuación, filtramos las columnas para continuar el procesamiento solo de aquellas que nos interesan, el stock lo hemos usado como filtro, pero no nos interesa seguir procesándolo, de hecho, solo nos sigue interesando el isbn y las editoriales. Para ello, incluimos un tFilterColumns.

Y pulsando sobre «Edit schema», a la derecha nos quedamos con las filas que nos interesan:
El siguiente paso es incluir un componente de tipo tExtractDelimitedFields que permite indicar una columna para realizar un split del valor de la misma, en función de un carácter de separación. En nuestro caso la columna es la de editoriales y el separador la coma.
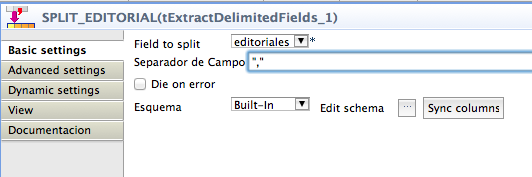
Pulsando sobre «Edit schema» establecemos la salida del componente como sigue, de modo que, hasta tres editoriales, produciría un split del valor de la columna en los campos editoriales_1, editoriales_2 y editoriales_3. El número de campos de salida dependerá del número de ocurrencias máximo en cada caso.

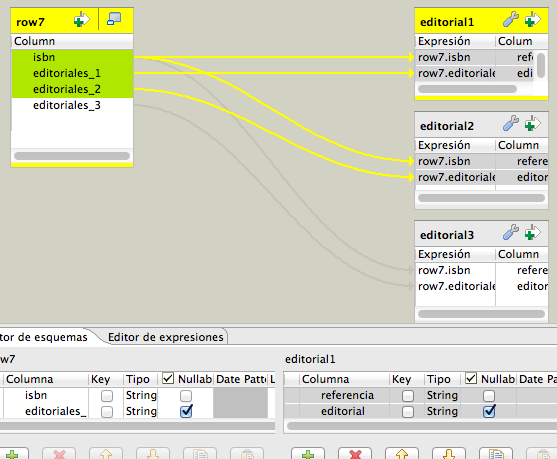
En el siguiente componente, en nuestro caso un tMap, podríamos trabajar sobre esos campos de salida para dar un tratamiento individualizado a cada una de las ocurrencias en el split para las editoriales; recibiendo el isbn y cada una de ellas, nos serviría para añadir la relación entre libro y editorial en la tabla correspondiente.
5. Referencias.
- http://www.talend.com/resources/documentation.php
- Lectura y tratamiento de ficheros Excel con Talend (I): nociones básicas
6. Conclusiones.
Llegar a un Job de estas carcterísticas cuesta, la documentación sobre Talend es bastante «parca en palabras», aunque los foros sí son bastante activos; no es simple y requiere de muchas pruebas y componentes de debug, pero una vez dispones de una variedad de casos de uso y vas conociendo los componentes, vas reafirmándote en el juicio de que es infinitamente más productivo trabajar así que hacer la tarea de migración
«a mano», tirando líneas de código.
Espero que os sirva de referencia.
Un saludo.
Jose


Hola, he estado usando Talend por algún tiempo y se me acaba de presentar un problema con la lectura de un archivo de Excell, este archivo contiene alrededor de 200.000 registros (tamaño 100MB) y cuando lo voy a leer tengo problemas con la memoria, te quiero preguntar si conoces alguna manera de configurar la lectura del archivo por lotes para la ejecución del job… en mi caso, no es una opción dividir el archivo en varios archivos para su lectura, ni tampoco ejecutar varias veces el job configurando los campos Header y Limit (la cual es una posibilidad que encontré en el foro de Talend)… si tienes alguna idea, me sería de mucha ayuda. Gracias.
Para Luciferian J: Un archivo asi de grande en excel tanto humanamente como computacionalmente esta ya en el limite de manejable. Yo convertiria ese archivo a una tabla de Access o SQL Server y despues procesaria la tabñla y eliminaria el archivo de excel. Si es un proceso de facturacion o algo similarte recomendaria una estrategia diferente para el procesamiento de los datos. Espero te sirva esta informacion. No dudes en contactarme, tengo casi 15 años de experiencia con herramientas EAI y varias implementacions exitosas. Saludos
Con la aproximación que enfoquéis el problema podíais hacer un tutorial para adictos y compartilo con todos.
Un saludo.
Jose.