
Creación: 09-05-2008
Índice de contenidos
1.Introducción
2. Entorno
3.La aplicación
4.La capa de persistencia
4.1.Las entidades
4.2.El DAO
5.La capa de negocio
6.La capa de control
7.La capa de presentación
8.Los ficheros de configuración
8.1.hibernate.cfg.xml (configuración de Hibernate)
8.2.applicationContext.xml (configuración de Spring)
8.3.faces-config.xml (configuración de JSF)
9.Diferencia entre las anotaciones @Repository, @Service,@Controller
10.Conclusiones
11.Sobre el autor
12.Colaboraciones
1. Introducción
Uno de los grandes problemas que tiene hoy en día el desarrollo de aplicaciones Web en Java es que el ciclo de desarrollo es, en muchas ocasiones, demasiado largo (o por lo menos más largo de lo que nos gustaría ;).
Debido a este problema han surgido alternativas del estilo de Ruby on Rails (http://www.rubyonrails.org/) o incluso Google App Engine (http://code.google.com/appengine/) una alternativa que propone Google, basada en el lenguaje Python.
Todas estas alternativas pueden resultar muy interesantes, pero suelen estar basadas en lenguajes con chequeo de tipos débil, o trasladando el chequeo de tipos a tiempo de ejecución (como Python), lo que provoca que puedan ser muy útiles para hacer rápidamente pequeñas aplicaciones o prototipos, pero que se pueden convertir en un gran problema cuando queremos construir aplicaciones medianas o grandes donde intervienen varias personas o incluso equipos en el proceso de desarrollo. Para este caso de aplicaciones medianas o grandes y grupos de desarrollo colaborativos, se hace necesario un lenguaje fuertemente tipado, donde podamos definir jerarquías de tipos (clases o interfaces) en las que el resto del equipo se pueda apoyar para desarrollar sin riesgos.
En este tutorial veremos como gracias a Spring + Hibernate + Anotaciones podemos conseguir un desarrollo tan rápido como el que podemos conseguir con las alternativas antes mencionadas.
Ya hemos visto en otros tutoriales el uso de Spring o Hibernate, pero en este tutorial vamos a intentar sacar todo el partido a las Anotaciones de Java 5 para, basándonos en el concepto de «convención frente a configuración», centrarnos en el código, olvidarnos de
la base de de datos y de esos tediosos ficheros de configuración en XML.
Con esto no quiero decir que debamos olvidarnos por completo de esos ficheros XML, sino que debemos centrarnos a resolver el problema que nos ocupa, de forma rápida y con un buen diseño, consiguiendo un código legible y mantenible. Si luego queremos hacer ciertos
refinamientos, o virguerías, los XML siempre estarán esperándonos para poder sobreescribir el comportamiento establecido con las anotaciones.
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil Asus G1 (Core 2 Duo a 2.1 GHz, 2048 MB RAM, 120 GB HD).
- Nvidia GEFORCE GO 7700
- Sistema Operativo: GNU / Linux, Debian (unstable), Kernel 2.6.24, KDE 3.5
- Java Sun 1.6.0_06
- Spring 2.5.4
- Hibernate 3.2.6
- JSF (RI 1.2) + Facelets 1.1.14 + ICEfaces 1.7
3. La aplicación
Vamos a hacer una pequeña aplicación donde se muestre un listado de productos. Podría quedar algo como:
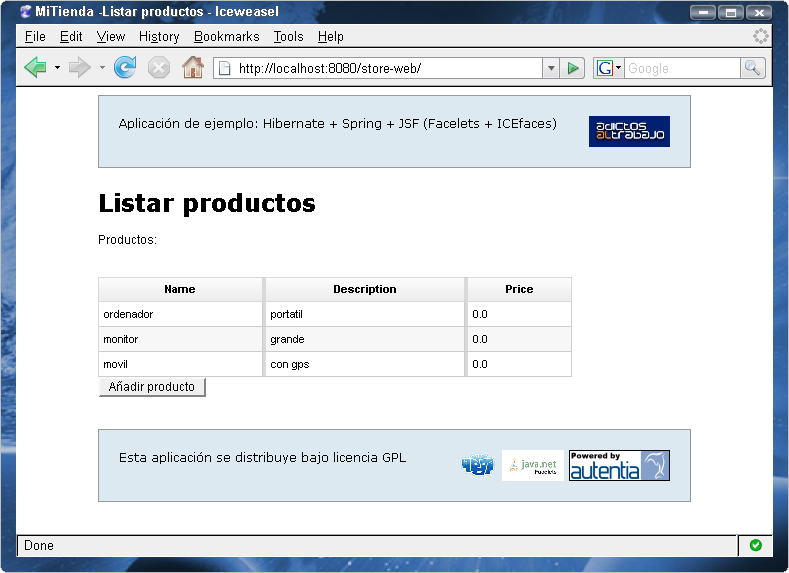
Y la pantalla de edición de productos:
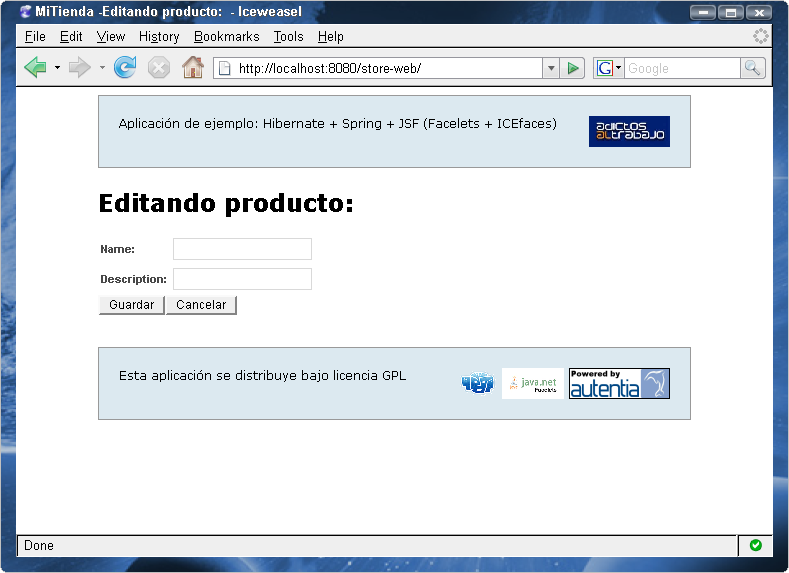
4. La capa de persistencia
Vamos a empezar «de abajo a arriba», es decir, partiremos definiendo nuestras entidades persistentes con Hibernate, e iremos «subiendo» hasta la capa de presentación y control con JSF, pasando antes por el negocio (el modelo) con Spring.
4.1. Las entidades
En nuestro ejemplo sólo tenemos la entidad producto, con los atributos nombre, descripción y precio.
Veamos como nos quedaría la clase:
@Entity
public class Product {
@Id
@GeneratedValue
private Integer id;
private String name;
private String description;
private float price;
Product() {
// Sólo el manager puede construir nuevas instancias
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
}
Podemos ver como se trata de una clase totalmente normal, donde en la línea 1 anotamos que se trata de una entidad, y en las líneas 3 y 4 indicamos cual es el id de la entidad y que este id será generado por la base de datos.
Cabe destacar dos cosas:
- Todas las notaciones usadas pertenecen al estándar de JPA por lo que son válidas tanto para Hibernate como para EJB3.0.
- Hemos anotado un atributo privado que no se usa en ningún sitio, ni siquiera tenemos getter o setter. Esto lo hacemos a posta ya que es algo que gestionará internamente Hibernate, y queremos condicionar lo menos posible nuestro diseño (nuestro negocio).
4.2. El DAO
El DAO es el Data Access Object, es decir, será la clase donde resida la lógica de manejo de Hibernate (o JDO o JDB o JPA o …).
De esta forma conseguimos que nuestra lógica de negocio no sepa nada de Hibernate, y siempre que quiera acceder a los datos lo hará usando esta clase.
Veamos un ejemplo sencillo: Primero definimos una interfaz, así podemos intercambiar la implementación fácilmente si algún día nos cansamos de Hibernate (no lo creo ;):
public interface Dao {
public void persist(Object entity);
public void persist(Object[] entities);
public <T> List<T> find(Class<T> entityClass);
public <T> T load(Class<T> entityClass, Serializable id);
public <T> List<T> find(String hql);
}
Para el ejemplo sólo hemos definido algunas operaciones simples. Ahora veamos una posible implementación usando las facilidades que nos proporciona Spring + Hibernate:
@Repository
public class SpringHibernateDao extends HibernateDaoSupport implements Dao {
@Autowired
public SpringHibernateDao(SessionFactory sessionFactory) {
super.setSessionFactory(sessionFactory);
}
@Transactional
public void persist(Object entity) {
getHibernateTemplate().saveOrUpdate(entity);
}
@Transactional
public void persist(Object[] entities) {
for (int i = 0; i < entities.length; i++) {
persist(entities[i]);
}
}
@Transactional(readOnly = true)
public <T> List<T> find(Class<T> entityClass) {
final List<T> entities = getHibernateTemplate().loadAll(entityClass);
return entities;
}
@Transactional(readOnly = true)
public <T> T load(Class<T> entityClass, Serializable id) {
final T entity = (T)getHibernateTemplate().load(entityClass, id);
return entity;
}
@Transactional(readOnly = true)
public <T> List<T> find(String hql) {
final List<T> entities = getHibernateTemplate().find(hql);
return entities;
}
}
No es el ámbito de este tutorial estudiar la implementación de los métodos, para más información sugiero al lector repasar otros tutoriales relacionados o acudir a la documentación de Spring e Hibernate y la documentación sobre Generics de Java.
Aunque el lector en un principio no entienda la implementación lo que creo que queda claro es que es sencilla, puesto que se limita a unas pocas líneas (de nuevo sugiero repasar la documentación).
Donde si vamos a hacer especial hincapié es en las nuevas anotaciones que nos han aparecido:
- En la línea 1 nos encontramos con
@Repository.
Esta es una anotación de Spring. Estamos indicando que esta es una clase relacionada con la capa de persistencia, y que debe ser un Singleton (sólo habrá una instancia de la claseHibernateDaoSupport, y todos los Threads de la aplicación la compartirán). - En la línea 4 nos encontramos con
@Autowired.
Esta es una anotación de Spring. Sirve para indicarle a Spring que cuando vaya a crear la instancia de HibernateDaoSupport debe «inyectarle» (pasarle) en el constructor una referencia al SessionFactory (el SessionFactory sí lo configuraremos mediante XML, lo veremos más adelante). - Por último, en la línea 9, 14, 20, … nos encontramos con la anotación
@Transactional. Esta es una anotación de Spring. Estamos indicando que el método en cuestión es transaccional. Lo que hará Spring es comprobar si ya existe una transacción abierta, si existe se unirá a ella, y si no existe, abrirá una nueva transacción (este comportamiento es configurable). De esta forma nos aseguramos que toda operación de la base de datos se realiza dentro de una transacción. Además si durante la ejecución del método se produce alguna excepción de Runtime, se hará automáticamente rollback de la transacción (este comportamiento también es configurable).
Ya hemos terminado con la capa de persistencia. Rápido ¿verdad?. En ningún momento hemos visto sentencias SQL, ni siquiera para crear las tablas de la base de datos. Más adelante veremos como configuramos Hibernate para que se encargue de crearnos las tablas automáticamente (Los ficheros de configuración los veremos todos al final, por ahora sigamos con el código Java).
5. La capa de negocio
En esta aplicación el negocio no es gran cosa, poco más que obtener los productos o guardarlos, así que la clase nos va a quedar muy sencillita:
@Service
public class ProductMgr {
@Resource
private Dao dao;
public Product newProduct() {
return new Product();
}
public void persist(Product product) {
dao.persist(product);
}
public List<Product> getProducts() {
final List<Product> list = dao.find(Product.class);
return list;
}
}
Haciendo una clase tan sencilla y que lo único que hace es delegar en el DAO, hay quien me podría acusar de estar cayendo en el antipatrón «Poltergeist», ya que desde control podríamos usar directamente el DAO para recuperar o guardar los productos, y quitarnos esta clase de enmedio. Pero no creo que este sea el caso ya que prima el MVC y el bajo acoplamiento.
Siempre debemos intentar que la capa de control y presentación sean lo más tontas posibles. Pensar por un momento que no usamos esta clase «manager» y que usamos el DAO desde las clases de control de JSF (los managed-beans), si ahora quisiéramos montar un web service para aprovechar esta aplicación desde otras aplicaciones ¿cuanto código que ya habríamos escrito en el managed-bean tendríamos que repetir en el web service?
Pero vamos al lío, que hemos venido a hablar de las anotaciones 😉
- En la línea 1 nos encontramos con
@Service.
Esta es una anotación de Spring, similar a@Repositoryque ya habíamos visto antes. Estamos indicando que esta es una clase relacionada con la capa de servicio (clases de negocio), y que debe ser un Singleton. - En la línea 4 nos encontramos con
@Resoruce.
Esta anotación es del estándar, por lo que es válida tanto con Spring como con EJB3.0. Esta indicando que al crear la instancia de esta clase se debe «inyectar» (inicializar) en este atributo una referencia a la instancia del Dao (es la instancia que habíamos
declarado anteriormente con@Repository).
Se acabo ¡¡¡ Ya hemos terminado con negocio !!!
6. La capa de control
Vamos a implementar el control con los managed-beans de JSF. Como tenemos dos pantallas podemos hacer dos managed-bean.
El de la pantalla con el listado de productos nos podría quedar algo como:
@Controller
@Scope("session")
public class ListProduct {
@Resource
private ProductMgr productMgr;
@Resource
private EditProduct editProduct;
private UIData productsDataTable;
public String editProduct() {
Product product;
try {
product = (Product)productsDataTable.getRowData();
} catch (IllegalArgumentException e) {
// No se ha seleccionado ninguna fila; se está añadiendo un nuevo elemento.
product = productMgr.newProduct();
}
editProduct.setProduct(product);
return "editProduct";
}
public List<Product> getProducts() {
return productMgr.getProducts();
}
public UIData getProductsDataTable() {
return productsDataTable;
}
public void setProductsDataTable(UIData productsDataTable) {
this.productsDataTable = productsDataTable;
}
}
La clase para la edición de los productos:
@Controller
@Scope("session")
public class EditProduct {
@Resource
private ProductMgr productMgr;
private Product product;
public String save() {
productMgr.persist(product);
return "home";
}
public Product getProduct() {
return product;
}
public void setProduct(Product product) {
this.product = product;
}
}
Fijándonos en la clase de listado, las nuevas anotaciones que
aparecen son:
- En la línea 1 nos encontramos con
@Controller.
Esta es una anotación de Spring, similar a@Repositoryo@Serviceque ya habíamos visto antes. Estamos indicando que esta es una clase relacionada con la capa de control. - En la línea 2 nos encontramos con
@Scope("session").
Esta es una anotación de Spring. Con ella estamos sobreescribiendo el comportamiento por defecto de Spring, que es hacer Singletons, y le estamos diciendo que nos cree una instancia diferente de esta clase por cada sesión Http. Es decir, cada usuario tendrá su
propio managed-bean. - También cabe destacar desde la línea 5 hasta la 9. La anotación @Resource ya la hemos comentado antes, pero quiero recalcar como se está «inyectando» la referencia al manager (la clase de negocio) y la referencia a otro managed-bean de la capa de
control de JSF, es decir, Spring es capaz de gestionar las dependencias entre los diferentes managed-beans de JSF.
7. La capa de presentación
Está implementada con JSF + Facelets + ICEfaces, pero no tiene nada de especial. Es decir la construiremos como habitualmente se trabaja con estas tecnologías.
Cuando queramos acceder a los managed-beans desde el Expression Language simplemente lo haremos. Por ejemplo:
-
<ice:commandButton value="Añadir producto" action="#{listProduct.editProduct}" /> -
<tnt:inputText entity="#{editProduct.product}" field="name" required="true" /> -
<ice:commandButton value="Guardar" action="#{editProduct.save}" />
8. Los ficheros de configuración
8.1. hibernate.cfg.xml (configuración de Hibernate)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name="hibernate.hbm2ddl.auto">create</property>
<property name="hibernate.show_sql">true</property>
<mapping class="com.autentia.store.product.Product"/>
</session-factory>
</hibernate-configuration>
En la línea 9 es donde le estamos diciendo a Hiberante que queremos que nos cree las tablas al arrancar la aplicación. Ojo porque si las tablas ya existen las borra primero, es decir, esto puede ser muy conveniente para desarrollo o pruebas, pero no para producción !!! Lo que podemos hacer es, una vez están creadas, hacer un «export» de la base de datos para obtener los scripts de creación que podemos retocar para dejarlos listos para producción (pero nos ahorramos lo gordo).
8.2. applicationContext.xml (configuración de Spring)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util" xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util-2.5.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.5.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.5.xsd">
<context:annotation-config />
<context:component-scan base-package="com.autentia.store" />
<aop:aspectj-autoproxy />
<tx:annotation-driven transaction-manager="transacctionManager"/>
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>classpath:jdbc.properties</value>
</list>
</property>
</bean>
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="${jdbc.driverClassName}" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
</bean>
<bean id="sessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="configurationClass" value="org.hibernate.cfg.AnnotationConfiguration"/>
<property name="configLocation">
<value>classpath:${hibernate.cfg.file}</value>
</property>
</bean>
<bean id="transactionManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory" />
</bean>
</beans>
Puede parecer que hay mucho pero en realidad sólo hay 4 cosas: configuración de Spring para que haga caso a las anotaciones, definir el datasource (de hibernate, del servidor por jndi, …), definir el sessionFactory de Hibernate, y definir el transactionManager (el de Hibernate, JTA, …).
Si os fijáis no hay ni una sola definición de bean de clases que hayamos escrito nosotros, de forma que este fichero se mantendrá constante con independencia de los beans que tenga nuestra aplicación.
8.3. faces-config.xml (configuración de JSF)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE faces-config PUBLIC "-//Sun Microsystems, Inc.//DTD
JavaServer Faces Config 1.1//EN" "http://java.sun.com/dtd/web-facesconfig_1_1.dtd">
<faces-config xmlns="http://java.sun.com/JSF/Configuration">
<application>
<locale-config>
<default-locale>es</default-locale>
<supported-locale>en</supported-locale>
</locale-config>
<view-handler>com.icesoft.faces.facelets.D2DFaceletViewHandler</view-handler>
<variable-resolver>org.springframework.web.jsf.DelegatingVariableResolver</variable-resolver>
</application>
<!--
| ================= Navigation rules =================
-->
<navigation-rule>
<navigation-case>
<from-outcome>home</from-outcome>
<to-view-id>/listProduct.jspx</to-view-id>
</navigation-case>
</navigation-rule>
<navigation-rule>
<from-view-id>/listProduct.jspx</from-view-id>
<navigation-case>
<from-outcome>editProduct</from-outcome>
<to-view-id>/editProduct.jspx</to-view-id>
</navigation-case>
</navigation-rule>
</faces-config>
Se puede apreciar como sólo hay configuración general de JSF y reglas de navegación. Pero no declaramos ningún managed-bean. Esto funciona gracias a la línea 13 donde se le indica a JSF que debe delegar en Spring para buscar los managed-beans. Es decir, JSF los buscará entre los que declaremos en el fichero (si es que declaramos alguno, que no es nuestro caso), y si no lo encuentra, lo buscará en Spring.
Como se puede comprobar, también nos ahorramos escribir cantidad de código en ese XML.
9. Diferencia entre las anotaciones @Repository,
@Service, @Controller
La diferencia es básicamente semántica, es decir, cada una denota perfectamente a que «capa» corresponde la clase anotada. Pero todas se comportan de igual manera (por ejemplo en todas nuestras clases podríamos haber usado la anotación @Service y
hubiera funcionado igual).
Esto se consigue porque las tres anotaciones extienden la anotación @Component.
El hecho de usar anotaciones diferentes puede ser muy interesante si luego queremos aplicar aspectos (AOP = Aspect Oriented Programming) a todas las clases de una misma capa. Es decir, por ejemplo, puedo hacer una regla para aplicar cierto advice a todas las clases con la anotación @Controller.
10. Conclusiones
Gracias a Spring + Hibernate + Anotaciones podemos conseguir reducir los tiempos de desarrollo con Java.
Ya existen otro tipo de frameworks similares como EJB3.0 o Seam (de JBoss) que también se basan en anotaciones, pero podemos ver algunas ventajas de usar Spring + Hibernate:
- Con Spring + Hibernate podemos usar contenedores ligeros como Tomcat, mientras que con EJB3.0 o Seam estamos condenados a usar un servidor de aplicaciones como JBoss. El tener que usar por obligación un servidor de aplicaciones aumenta los tiempos de desarrollo ya que se tarda más en desplegar en un servidor de aplicaciones que en un Tomcat. Además necesitaremos más recursos.
- Con Spring + Hibernate podemos hacer todo el desarrollo en un Tomcat, aunque finalmente acabemos instalando en producción en un servidor de aplicaciones.
- Con Spring + Hibernate podemos escribir aplicaciones normales de escritorio o línea de comandos, mientras que con EJB3.0 o Seam no, es decir con Spring + Hibernate, no es que nos valga con un contenedor ligero, es que no tenemos porque usar un contenedor en absoluto.
- Spring da cantidad de facilidades, como Seam, y posiblemente más que EJB3.0 (ya que se integra con gran cantidad de otros frameworks). Aunque no hay que olvidar que EJB3.0 permite transacciones distribuidas (Spring + Hibernate no lo permiten, aunque se pueden unir a una transacción JTA gestionada por un servidor de aplicaciones), y además los EJBs son por si mismos objetos distribuidos (muy fáciles de localizar y usar desde cualquier punto de nuestra red).
Al final ni todo es absolutamente bueno ni todo es absolutamente malo. Por eso debemos conocer opciones, evitar el «Golden Hammer», y quedarnos con lo mejor de cada casa 😉
11. Sobre el autor
Alejandro Pérez García, Ingeniero en Informática (especialidad de Ingeniería del Software)
Socio fundador de Autentia (Formación, Consultoría, Desarrollo de sistemas transaccionales)
mailto:alejandropg@autentia.com
Autentia Real Business Solutions S.L. – «Soporte a Desarrollo»
12. Colaboraciones
Antonio Martínez, uno de vosotros, nos ha mandado el pom.xml que él está usando para este tutorial.
Muchas gracias Antonio !!!


Muy buen Articulo. Pero estaría mucho mejor si incluyeran alguna forma de acceder al codigo.
Animando a los lectores.
Da gusto seguiros el hilo en las evoluciones tecnológicas que existen. Espero que este año sigáis un buena línea, os seguiré leyendo.
Cuando seais abueletes y no podáis pensar, os relevaremos en el cargo 🙂
Muy buen tutorial pero me encantaria que pudieran poner el codigo para descargar, asi comparar y encontrar mis errores al configurar los frameworks
Genial este sitio, os he seguido en muchas ocaciones 🙂
La capa de control no me queda del todo clara, relamente no la entiendo, ¿podeís subir un war con el poryecto? os lo agradecería muchísimo¡¡
Gracias por el tutorial, es excelente y jes usto lo que estaba buscando 🙂
Buen tutorial, sin embargo tengo una sugerencia. Apenas estoy conociendo Spring y estoy un poco \\\»verde\\\», podrian explicar un poco más sobre como configurar las herramientas como:
Faceletes
ICEFaces y
JSF
gracias por el aporte
¿No debería haber en la interfaz Dao hay un método remove?
Muchas gracias.
Muy buen artículo. Es justo lo que necesitaba, porque es fiel a todos los consejos dados en el manual de referencia de Spring, pero a través de un ejemplo completamente funcional y sencillo.
l tutorial está muy bueno, se parece mucho a lo que necesito aprender, pero como soy nuevo en esto tengo algunos problemas con las librerías de spring, estoy probando esto en una aplicación que ya usa esta formula(Spring+hibernate+anotations) pero al parecer no tengo la librería org.springframework.stereotype.Repository necesaria para el uso de @Repository será que alguien puede ayudarme? estoy usando netbeans 7.0.1 sobre windows 7 y el error que me da es:\\\»Package org.springframework.stereotype.Repository does not exist\\\»
Saludos. Buen tutorial para empezar con Spring. Tutoriales más extendos terminan por desanimar.
Tengo de 2 a 5 clientes Desktop diferentes pero que comparten un modelo de negocios en común. Entiendo que en un servidor de aplicaciones puedo colocar JavaBeans Enterprise que me sirvirían como el modelo de negocios a donde se conectarían las aplicaciones desktop utilizando RMI.
Luego, leo que Spring ofrece una mejor forma de usar los JavaBeans; sin emabargo, todos los ejemplos que me topo (como el actual) usan clientes Web y no Desktop.
Entonces, ¿es posible usar Spring para hacer el modelo de negocios y que dicho modelo sea accesado desde uno o varios clientes Desktop?
Se agradece si me dan el norte o indican algún ejemplo o tutorial.
JJ
buenas tardes. gracias por compartir estos super tutoriales. yo soy novato en la programacion java, apenas comence un curso basico, y ahorita quisiera hacer un proyecto muy parecido con spring-hibernate-xmlbeans. tengo mi base de datos en postgres, ya tambien tengo mi archivo dto, y quisiera hacer altas, bajas, consultas y borrar registros, teniendo un from de administracion. como le podria hacer.ya tambien cree mi proyecto de spring. saludos cordiales y les agradeceria su ayuda.
Muy buen post!! Groso!! =)
Cordial saludo,
Ante todo quiero felicitar el autor, excelente tutorial.
Quisiera saber si alguien tiene el fuente de la capa de presentación de este tutorial, o tiene idea de como crear el componente que maneja la entidad producto y se encarga de leer los datos del la pagina.
Agradezco su colaboracio.
Con mucha experiencia en Java me han plantado delante un proyecto bastante grande hecho con Spring (e Hibernate + Anotaciones) cuando nunca había trabajado con este framework. Sobresaliente artículo que me ha ahorrado unas buenas horas de investigación por mi cuenta.
Muchas veces una explicación somera que deje claro dónde está cada cosa y cómo se organiza es más productiva que el mejor de los manuales.
Enhorabuena.
Buenas, estoy comenzando en Spring, y seria bueno que pusieran un ejemplo con Spring + JDBC en Java EE. He intentado hacer este ejemplo, pero me da errores… lo que creo que no se haer es configurar la conexion a la bd y Spring. El datasource va declarado en el archivo ApplicationContext, pero me da error.
eso de que es un desarrollo rapido y agil es la mentira mas grande del mundo de java. Puedo diseñar e implementar una BBDD y sus clases en java en la mitad de tiempo que tardas en configurar todo el proyecto para hacerlo compatible con las librerias y versiones de Hibernate+spring… y si ademas añadimos que las anotaciones te obligan a declarar muchisimas mas clases de las que necesitas realmente y te hacen el codigo un caos organizativo… ya me dirás donde está la mejoría. Para el desarrollador de Hibernate y de Spring seguro… pero para una empresa ya te digo yo que no…