
0. Índice de
contenidos.
- 1. Entorno.
- 2. Introducción.
- 3. Descargar el software.
- 4. Configurar variables de entorno.
- 5. Crear directorio de base de datos.
- 6. Arrancar la base de datos.
- 7. Instalación de entornos visuales: Robomongo.
- 8. Agrupación de resultados y MadReduce.
- 9. MapReduce.
1. Entorno
Este tutorial está escrito usando el siguiente entorno:
- Hardware: Ordenador iMac 27″ (3.2 GHz Intel Core i5, 8 GB DDR3)
- Sistema Operativo: Mac OS X Mavericks 10.9
2. Introducción.
Una de las cosas más graves que suele suceder en el mundo de la informática es que los responsables de equipos, directivos de empresas de tecnología, CIOs, mandos intermedios, etc. se enajenan del conocimiento técnico simplificando los conceptos porque ya alguien técnico le dará la solución. Con esta comoditización del conocimiento se degrada una profesión con rapidez convirtiéndola en un mercadeo de carne barata por horas: cosa con la que todos los que vivimos del sector deberíamos luchar: ¡esta profesión cada vez es más amplia, difícil y especializada!
Cuando visito a CIOs muchas veces les suelto una pregunta: ¿dónde encajas tú en el modelo que estás contribuyendo a crear? Se suelen quedar con caras ceji-altas… porque en un modelo de regateo por horas, contratando a empresas lo más grandes posibles para que nadie les pueda acusar de equivocarse… ellos tampoco tienen buen hueco (excepto siendo el que compra o vende).
Como no quiero que me pase, convertirme en un comercial cada vez más desarraigado del conocimiento real, me gusta periódicamente arañar en la tecnología base y probar en carne propia la madurez real de las tecnologías más de moda. Obviamente en mi contexto hay gente que sabe más que yo: adictos.
Hoy me he planteado cacharrear con una base de datos documental. En su momento, cuando trabajaba en Software AG ya hace como 13 años, usaba una base de datos nativa XML llamada Tamino y los conceptos son fácilmente transladables (salvando claramente las distancias se parecen, el interfaz era http, se podían guardar documentos sin esquema definido (XML), se consultaba con XQuery, se extraía la información con XPath, etc.).
3. Descargar el software.
Lo primero que vamos a hacer es descargar MongoDB de www.mongodb.org.
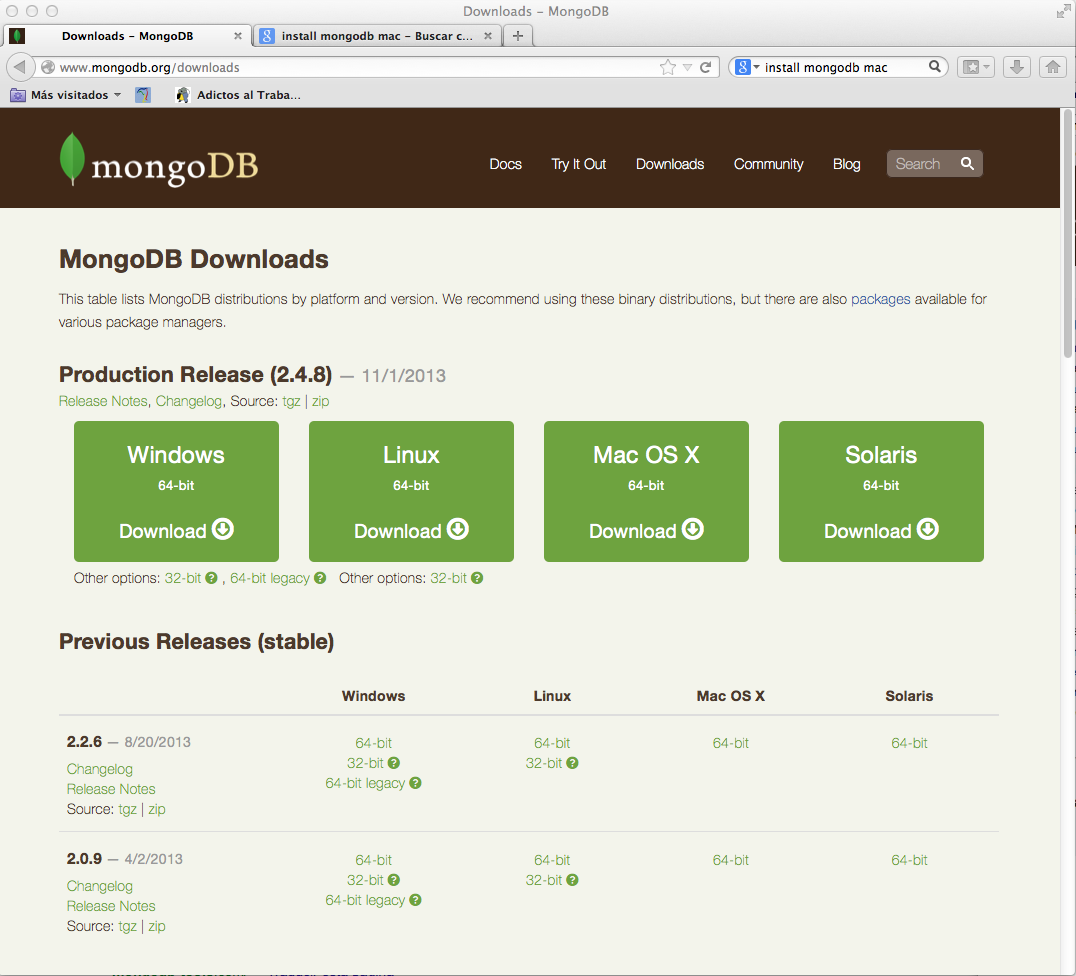
En mi capeta de usuario descomprimo el fichero y me fijo en el trayecto de los binarios.
4. Configurar variables de entorno.
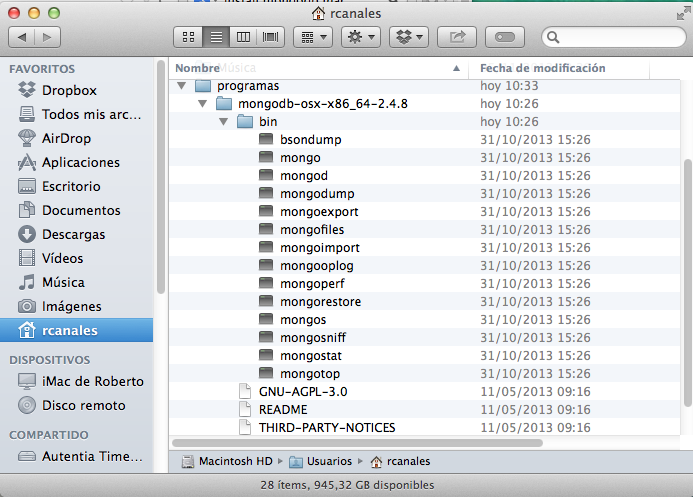
Añado a la variable de entorno PATH el trayecto del directorio bin de MongoDB. Esto se puede hacer de varios modos pero lo voy a hacer del que creo menos cutre, que es añadiendo una entrada (un fichero) con el trayecto en el directorio /etc/paths.d/.
Esto lo tenemos que hacer con la aplicación Terminal.
Creo con vi un fichero (se puede llamar como queráis) que he denominado mongodb y escribo el trayecto (a ver observadores en las capturas de panel).
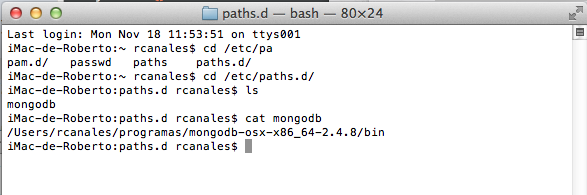
Ojito con el tema de permisos en Mac. Para proteger al sistema no puedes escribir sin más en algunas carpetas y tienes que cambiar a administrador (comando sudo su + contraseña).
El fichero ya lo puedes crear con Vi (lo pongo sencillo).
vi mingodb + ESC + i (de insertar) Escribir el path + wq (escribir y salir)
Si te apañas bien con entornos Unix hay modos hasta más sencillo como usando simplemente el comando echo y redirigiendo a un fichero
echo "trayecto" > ficherodestino
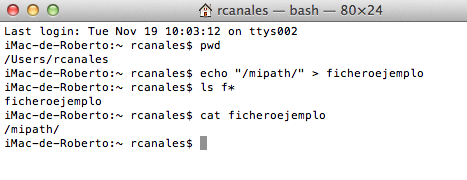
Una vez que lo tenemos, al reinciar el equipo podremos ver con el comando echo $PATH si está y no tenemos ningún error.
5. Crear directorio de base de datos.
Ahora, tenemos que crear el directorio de la base de datos. Como está en el directorio data, tendremos que crearlo también como administrador.
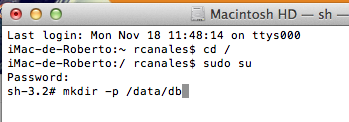
Aunque como arrancaremos la aplicación con el usuario interactivo, cambiaremos el propietario (estando como «su»)
Usaremos el comando chown.
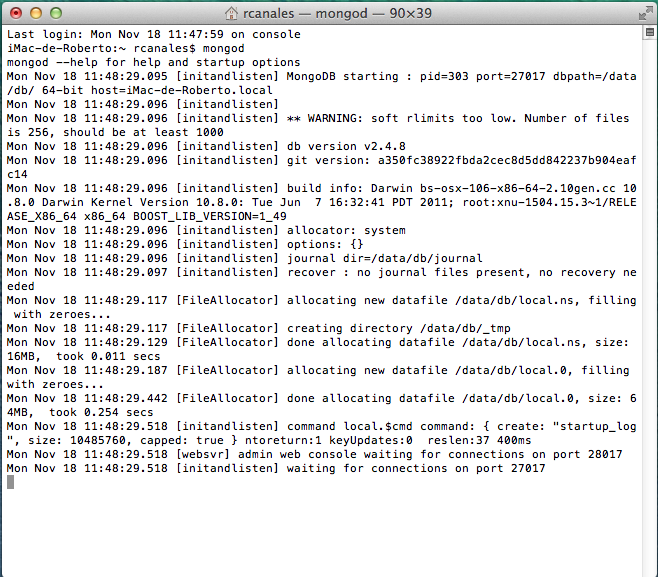
6. Arrancar la base de datos.
Ahora, solo tenemos que arrancar la base de datos con el comando mongod desde otra ventana de terminal.
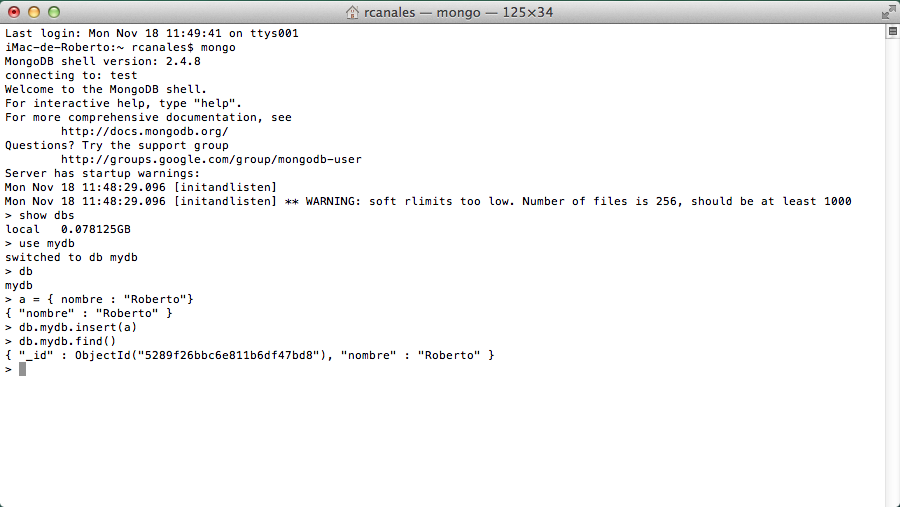
Arrancamos el cliente, desde otra ventana de terminal, usando el comando mongo.
Jugamos un poco con los comandos.
Si escribo use mydb estoy especificando que voy a trabajar con una nueva base de datos. Hasta que no haga la inserción del primer documento no se creará.
Para insertar un documento solo tengo que usar el comando insert con un comando parecido a este, como podéis ver en las capturas.
db.mydb.insert ({ nombre: «Roberto»})
7. Instalación de entornos visuales: Robomongo.
Esto de usar la línea de comando es curioso pero supongo que hay mejores modos de hacerlo con herramientas visuales. Si vais a la siguiente página veréis que hay un montón de herramientas para ayudaros con MongoDB.
Aunque hay muchas utilidades potencialmente interesantes voy a empezar con Robomongo.
Nos lo descargamos desde http://robomongo.org/ (como siempre aviso, sois vosotros los que tenéis que evaluar el riesgo de descargar software a los equipos, que yo lo haga no significa que a priori sea porque yo he validado que sea confiable.. cada uno que asuma su responsabilidad ;-).
Básicamente es un entorno para gestionar los comandos y representar de un modo más estructurado las respuestas.
Pulsado el botón derecho somos capaces de dar de alta una conexión. Como no he activado seguridad con esto es suficiente.
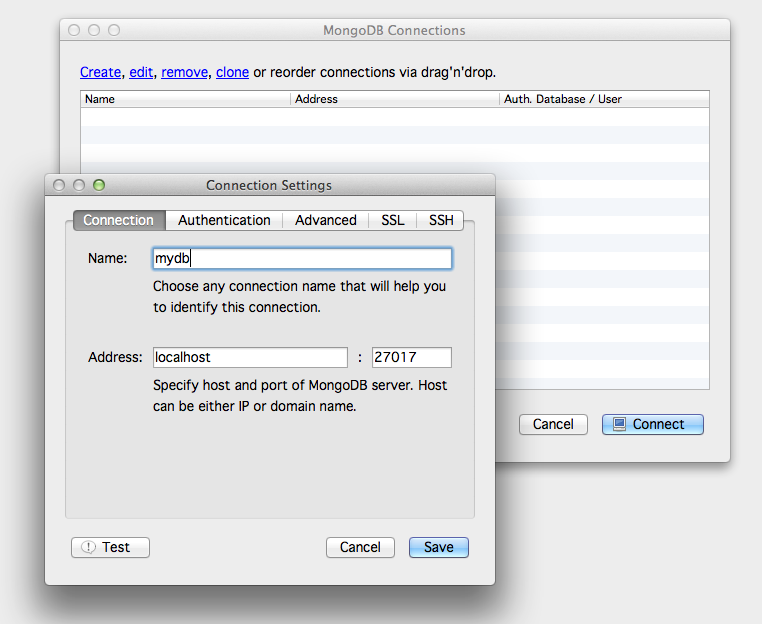
Vemos ya la estructura de mi nodo con las bases de datos y colecciones dentro de ella.
A medida que vamos navegando por la estructura nos muestra el comando que está ejecutando y la respuesta.
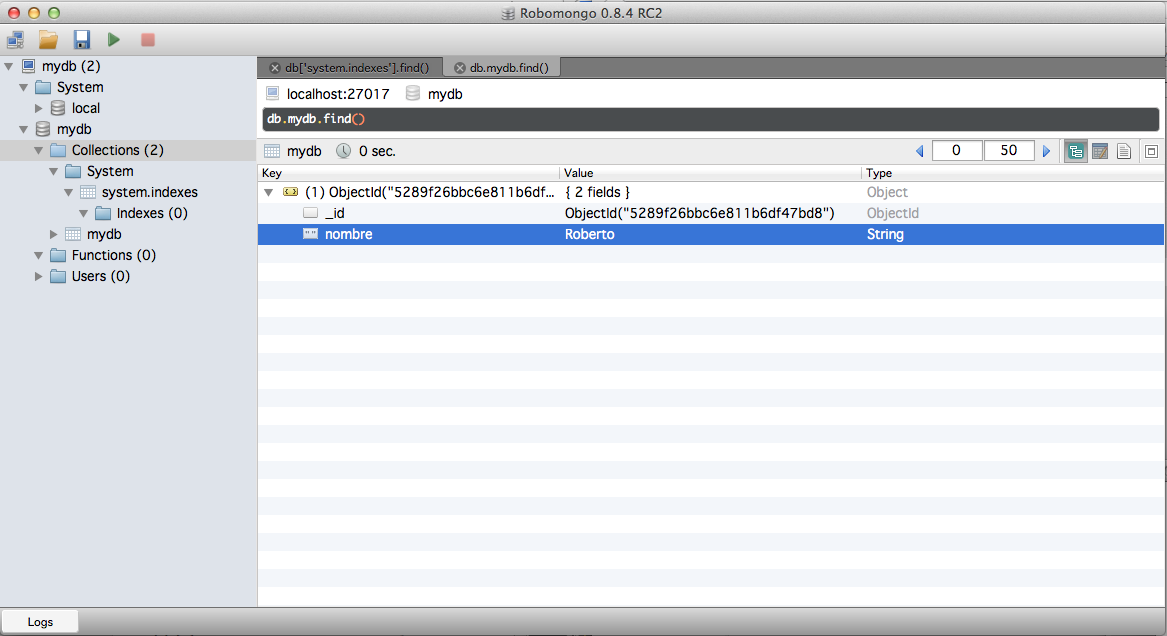
Podemos directamente insertar/editar un documento pulsando el botón derecho e insert.
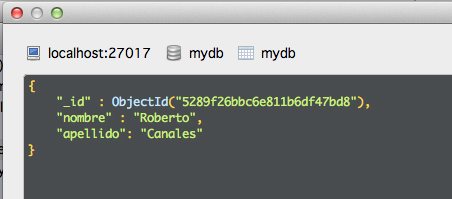
Verificamos que la edición se ha ejecutado correctamente.
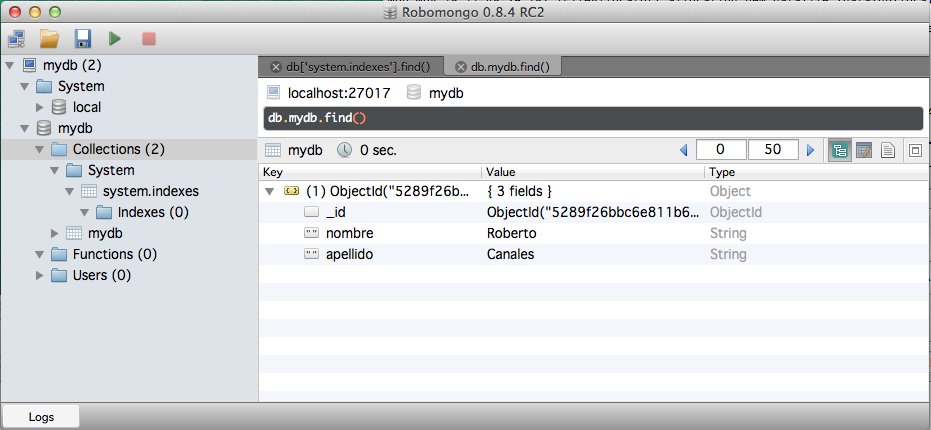
Insertamos más registros para jugar.
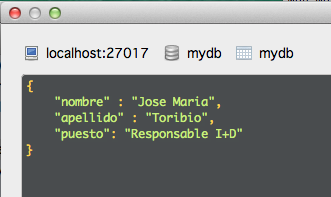
Y podemos verificar el resultado en modo tabla. Fijaos bien que no hay que definir primero el esquema o estructura de la tabla sino que se van insertando «columnas» a medida que insertamos elementos.
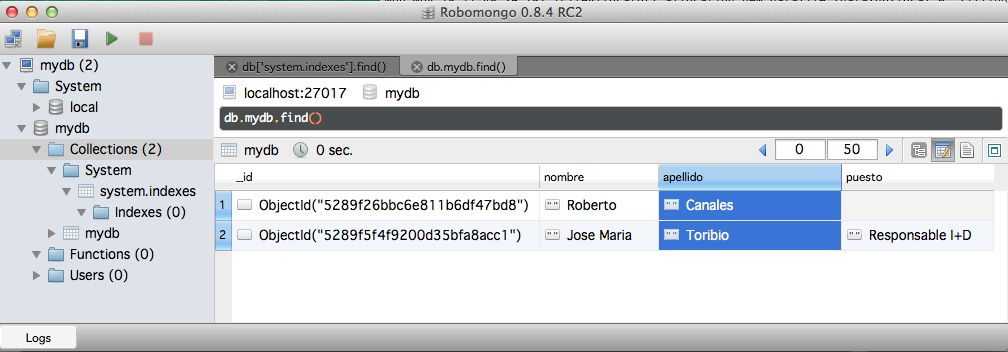
La gracia de este tipo de bases de datos NoSQL, orientadas a documentos, es que podemos almacenar y consultar estructuras complejas de un modo sencillo.
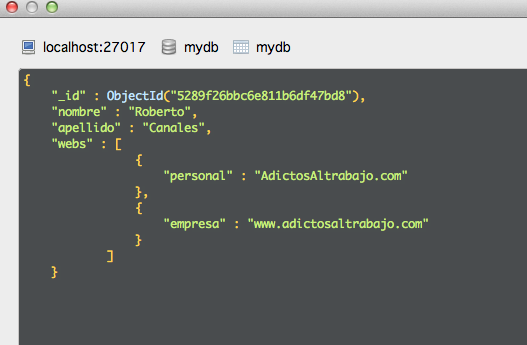
En el ejemplo estamos añadiendo un nivel de anudamiento más (conceptualmente un array) editando mi entrada:
{
"_id" : ObjectId("5289f26bbc6e811b6df47bd8"),
"nombre" : "Roberto",
"apellido" : "Canales",
"webs" : [
{
"personal" : "AdictosAltrabajo.com"
},
{
"empresa" : "www.adictosaltrabajo.com"
}
]
}
Verificamos las respuestas:
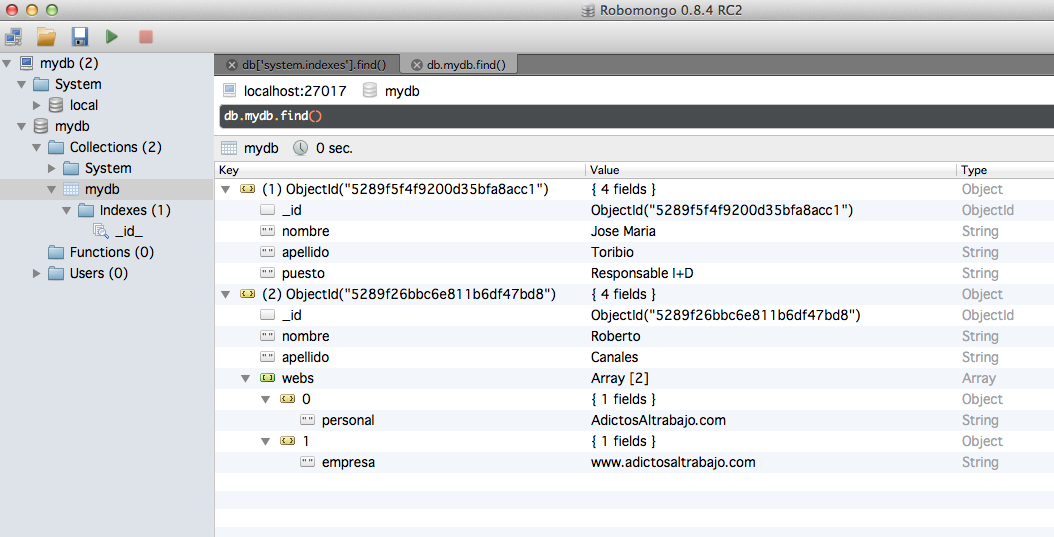
Directamente podemos empezar a hacer consultas desde la línea de ordenes con el comando find.
Hacemos una consulta básica por «etiqueta»:
db.mydb.find ({ nombre: «Roberto»})
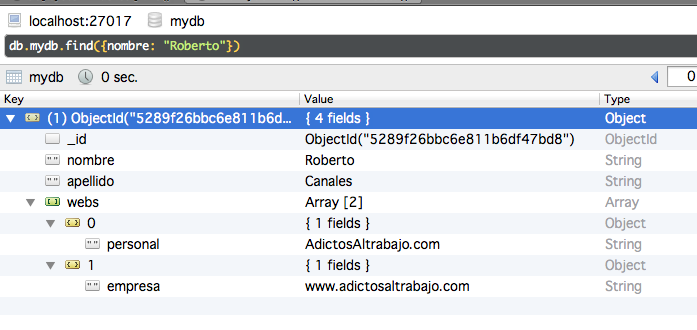
Podemos hacer búsqueda de documentos en base a atributos anidados, usando el operador punto.
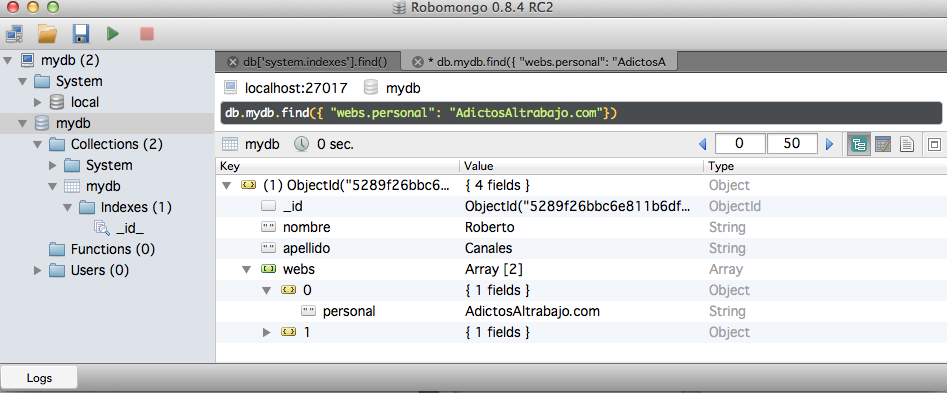
También podemos recuperar solo un campo, pasando un parámetro adicional (nombre del campo y 1). Podríamos hacer los contrario, devolver todos menos eso desde 0.
Concatenando en comando find con sort podemos ordenar las respuestas:
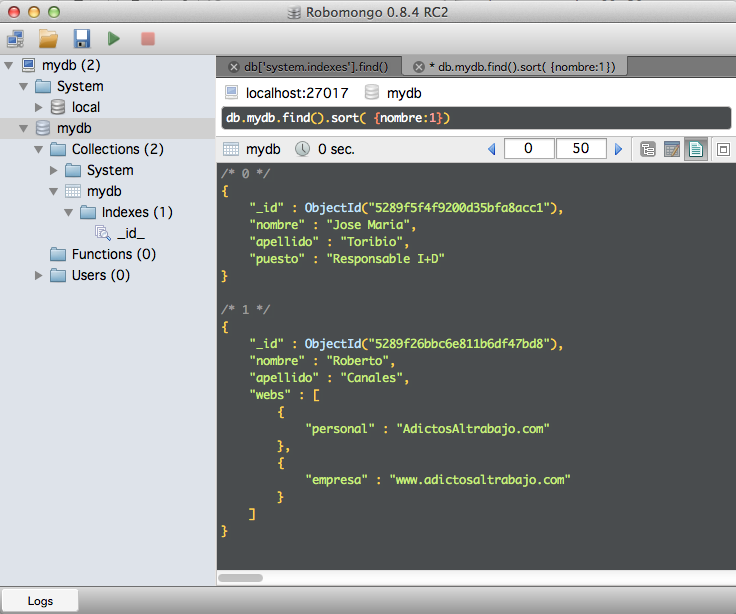
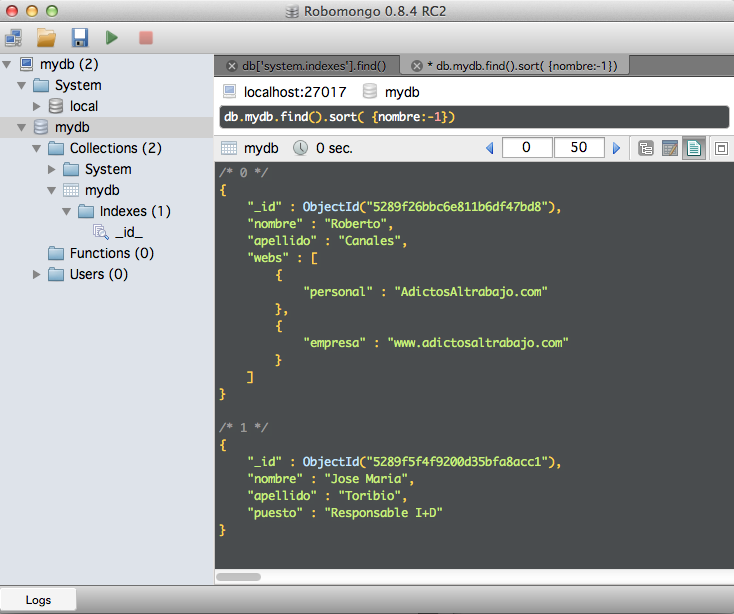
Las ordenaciones, como es obvio, se pueden hacer tantos ascendente como descendentemente.
Cacharreando es fácil encontrar otros comando útiles: ordenar en el orden en que se han insertado: db.mydb.find().sort( {$natural:1}).
Solo el primer resultado: db.mydb.findOne().
Retornar el número de elementos que cumplen una condición: db.mydb.find().count().
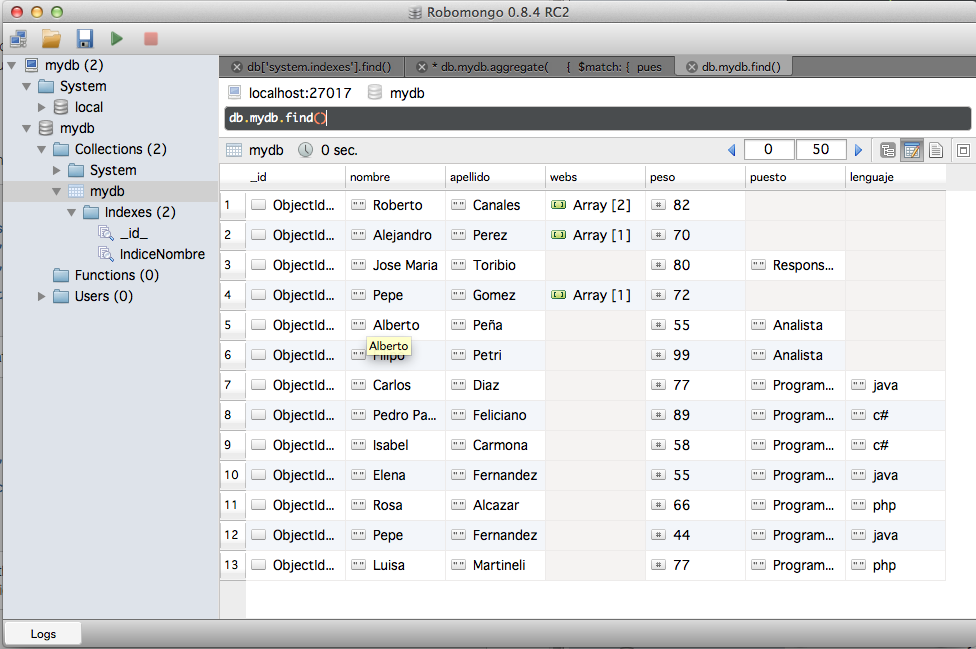
Poblamos un poquito la base de datos para ir dando juego a las consultas y ver el partido que se puede sacar a estas herramientas. He añadido la columna peso (no tiene por que ser real :-p)
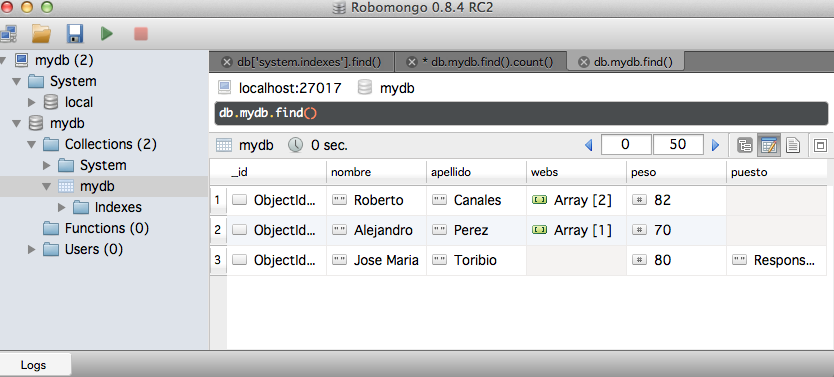
Y hacemos una consulta para encontrar los valores distintos:
> db.mydb.distinct("peso")
[ 82, 70, 80 ]
Como en todas las bases de datos, parece lógico crear índices para mejorar los tiempos de acceso y no tener que recorrer físicamente toda la base de datos para encontrar subconjuntos de elementos de uso frecuente.
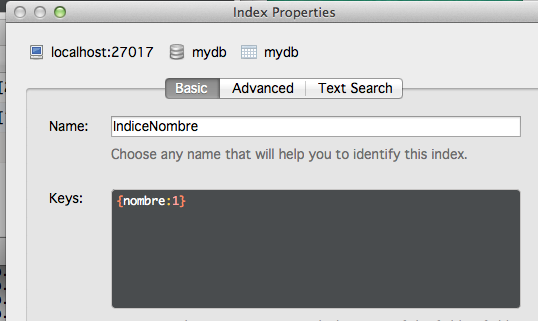
8. Agrupación de resultados y MadReduce.
Una de las claves de este tipo de bases de datos es almacenar millones de datos, en múltiples nodos distribuidos y, en el momento necesario, hacer consultas que involucren a estos datos y nos den valor de negocio.
Para hacer esto se puede utilizar una técnica denominada MapReduce. La idea fundamental es seleccionar un subconjunto de datos, agruparlos o reducirlos y cargarlos en otra colección.
Lo lógico es que los programas de negocio no consultan los millones de datos que se van incorporando interactivamente sino que haya una visión agrupada y algo retardado de instante real; llamémoslo datawarehause. De hecho, se suelen montar en cascada estos tipos de productos (que ya contaremos en otros tutoriales)
Poblamos la base de datos un poco más y vamos a ver comandos agrupadores:
Lo primero que vamos a hacer es obtener un subconjunto de datos que queremos procesar.
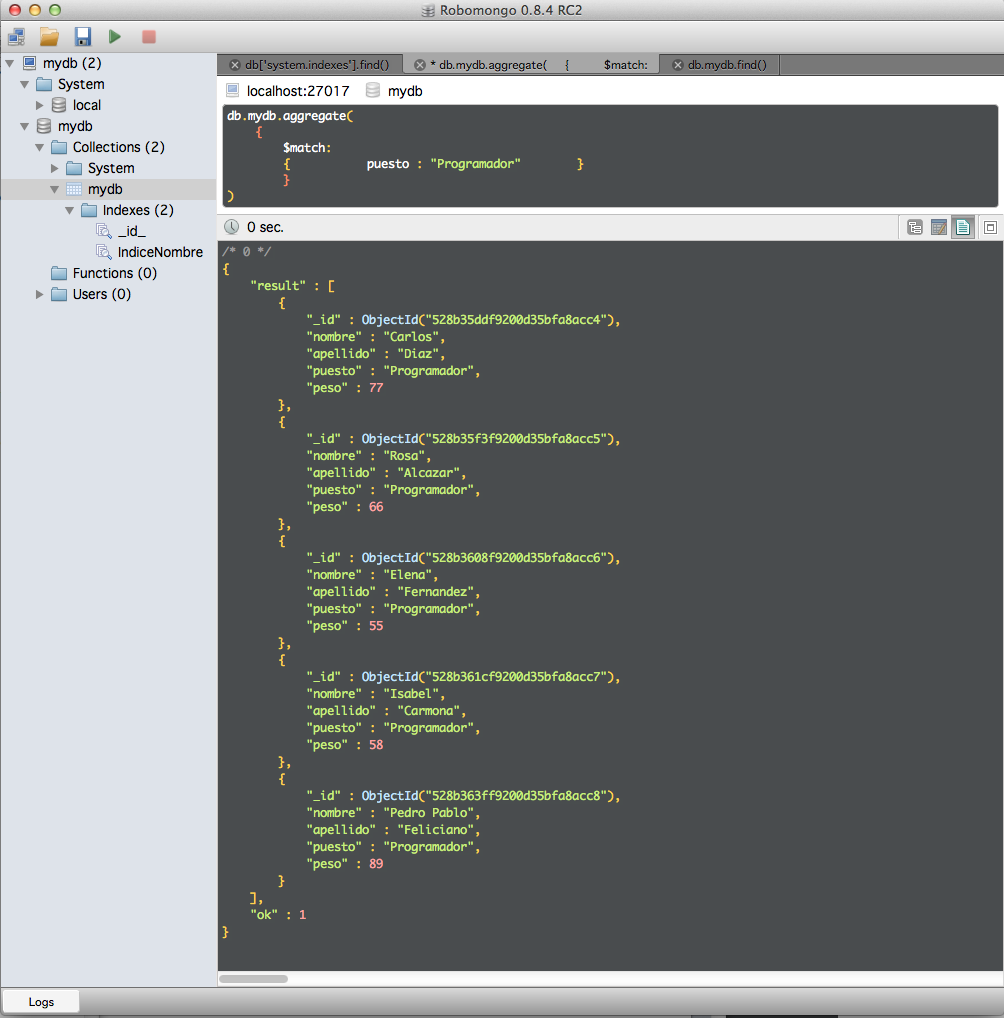
Y ahora, vamos a combinarlo con la agrupación de la respuesta:
db.mydb.aggregate(
{ $match: { puesto : "Programador" } },
{ $group: { _id:0, mediaPeso: { $avg : "$peso" } } }
)
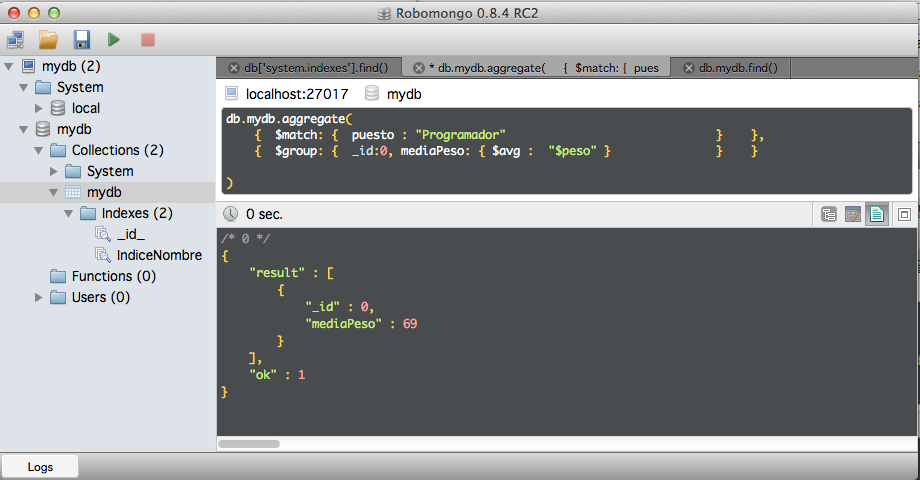
Poblamos un poquito más el conjunto de datos para obtener una agrupación más rica, añadiendo el lenguaje de programación en que trabajan:
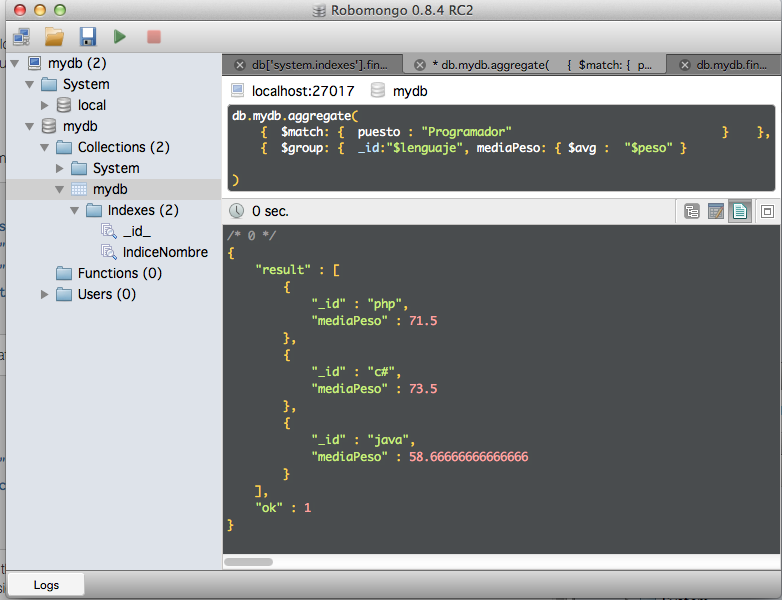
Y agrupamos el peso medio por lenguaje:
db.mydb.aggregate(
{ $match: { puesto : "Programador" } },
{ $group: { _id:"$lenguaje", mediaPeso: { $avg : "$peso" } } }
)
9. MadReduce.
Para usar MapReduce, os recomiendo leer antes la referencia: http://docs.mongodb.org/manual/core/map-reduce/
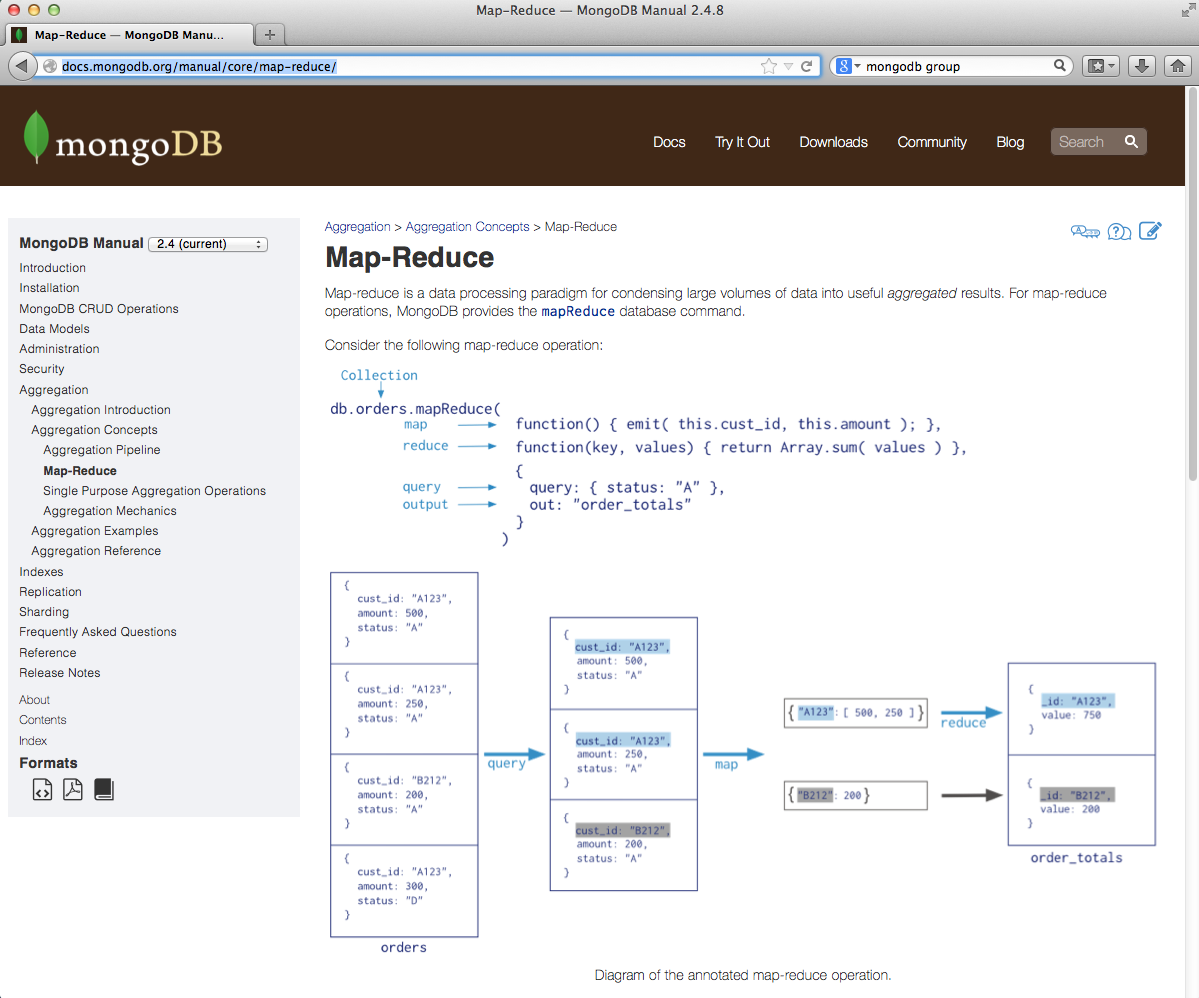
Si miramos el esquema anterior veremos que tenemos un primer filtro de consulta que genera un mapa donde el segundo valor es un array que se reduce a un valor y se guarda en una nueva colección.
El primer filtro, el de consulta, extrae los elementos. En mi caso los programadores.
db.mydb.mapReduce(
function() { emit ( this.lenguaje, this.peso); }, // map
function (clave,valor) { return Array.avg(valor) } , // reduce
{
query: { puesto : "Programador" } ,
out: "pesoProgramador"
}
)
Y obtenemos el siguiente resultado:
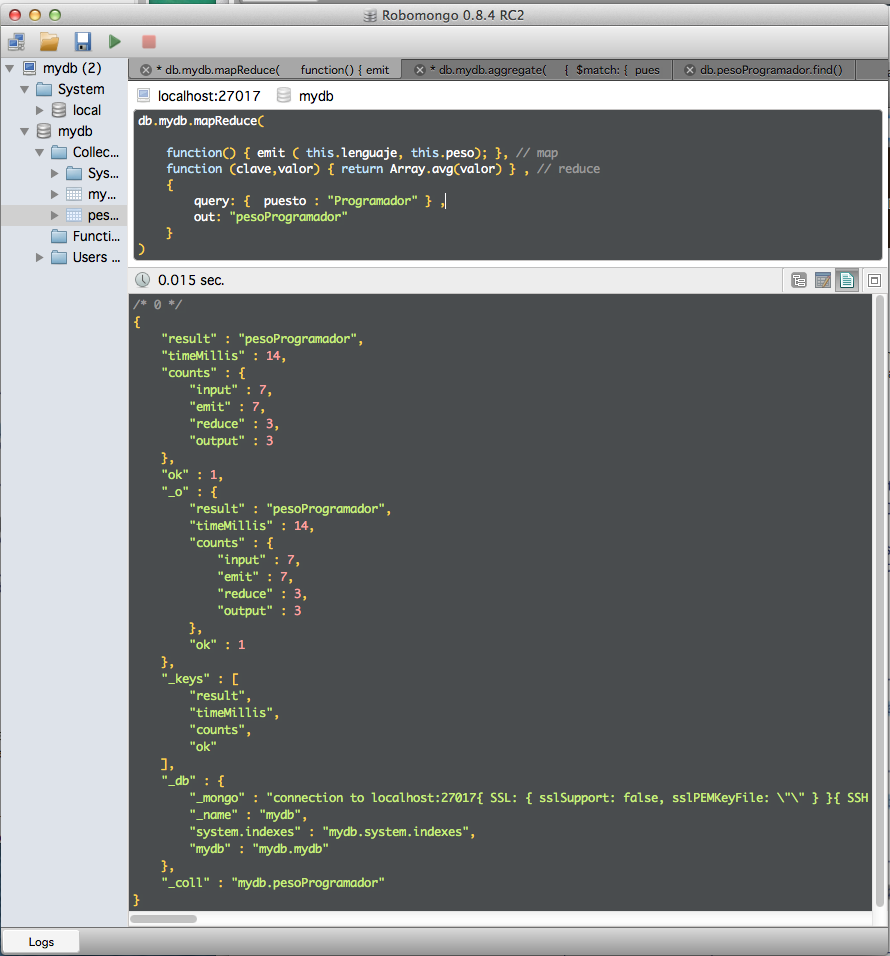
Y vemos como se crea una nueva colección llamada pesoProgramador, que tiene los datos deseados.
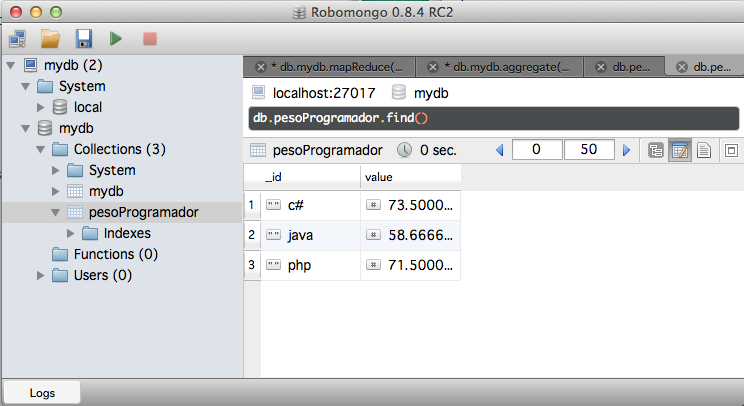
Bueno, para un primer tutorial creo que está bien. Podemos leer entre líneas la potencia de este tipo de bases de datos aunque, para continuar con el mensaje del principio, no le restemos complejidad… queda mucho por estudiar y ver cuándo y cómo se debe aplicar a problemas reales.
Los conceptos BigData y CloudComputing han llegado para quedarse … así que va siendo buena hora de meter estas herramientas y conceptos en nuestra navaja suiza.


Buenas Roberto,
Desde mi punto de vista es un error generalizado el asociar MongoDB al concepto de BigData. MongoDB encaja perfectamente en casi el 90% de aplicaciones de Internet (con independencia de si se manejan muchos datos o no), reduciéndose el esfuerzo de desarrollo enormemente. (Eso de las cientos tablas para almacenar datos estructurados aunque luego no se consulte por ellos es un engorro cuando conoces estas tecnologías.)
Desde mi punto de vista, MongoDB y el resto de bases de datos documentales, es una evolución natural de las BD.. os recomiendo el libro MongoDB Applied Design Patterns.
Saludos
Carlos, no diría que es una evolución, es una alternativa (por eso decía lo de la navaja Suiza).
MongoDB y otras bases de datos NoSQL, tiene sus ventajas e inconvenientes.
Como inconvenientes (que es también su ventaja) podemos ver que la falta de esquema fijo, y su creación dinámica al insertar, hace que un fallo de programación cree esquemas paralelos; el que no haya transacciones (aparte de unitarias) restringe su uso en entornos no tan optimistas o de transaccionabilidad declarativa; los administradores pueden no disponer de mecanismos estandar para introducir datos de auditoría (ajenas a desarrollo); las funciones (operaciones) grabadas en el servidor son evaluadas dinámicamente (con eval) los que implica un riesgo, etc.
Una de las ventajas más importantes de las bases de datos NoSql es su escalabilidad horizontal e incluso toletancia a fallos (dependiendo del tipo), por eso su interes para BigData (y como dices puede simplificar muchos desarrollos). Incluso en este caso hay que tener en cuenta el teorema CAP http://es.wikipedia.org/wiki/Teorema_CAP
Una moto no es una evolución de un coche.. se pueden usar para lo mismo en algunos casos pero cada uno con sus pros y sus contras, en base al escenario 😛
Hola Roberto,
Sí, mejor la palabra alternativa que evolución. Aunque me refería más bien a la forma de como encajan la gran mayoría de las aplicaciones web tradicionales en dónde no se requiere un alto nivel de transaccionalidad y son datos explotados por una única aplicación (o varias a través de un API..)
Desde luego que una BD explotada por distintas aplicaciones y que se requiere una transaccionabilidad debida a N operaciones o N aplicaciones (no insert s a varias tablas para persistir un objeto) este modelo no encaja.
Las herramientas de explotación/administración están ya a la altura de las de MySQL.
Saludos
Estimado Roberto:
Estoy probando el concepto de mongoDB pasando desde 25 bases de datos MySQL datos de taxonomia vegetal, que son una verdadera complicacion por lo intrincado en lo relacional, el problema que tengo es que no doy con la idea de realizar un disctinct y que me arroje un listado.
El distinct se hace sobre familias botanicas, la salida seria con familia, genero, especie; ya que la idea es reducir de 21 mil taxones a solamente esas caracteristicas para luego poder consultar cada grupo de familia, genero y especie por separado. Agradeceria tu guia al respecto.
Cordialmente
Edwin