
StAX (Xml Pull Parser): Streaming API para XML
Introducción.
Desde hace años los documentos XML han dominado como formato de intercambio de información, creándose a su alrededor infinidad de tecnologías y lenguajes.
En la actualidad las dos formas más extendidas de leer documentos XML son DOM y SAX, ambas son especificaciones con numerosas implementaciones y sobre las que se apoyan otras tecnologías como XSLT, XPath, etc..
Ahora bien, estas dos tecnologías no siempre son apropiadas para todos los problemas. Por ejemplo, imagine que tenemos un XML de muchos megabytes con el siguiente formato y
queremos saber cuál de entre los 100 primeros libros es el más caro:
Libro 1
drama
35
400
Libro 10000000
Ciencia
55
200
Pues bien, para este tipo de tareas ni DOM ni SAX son adecuadas, pues:
- Con SAX tendríamos que parsear todo el archivo.
- Con DOM tendríamos que tener previamente toda la información en memoria para recorrerla » OutOfMemoryException
Si te pones a pensar, te das cuenta de que ninguna de las dos tecnologías es apropiada por que el programador pierde el control del proceso de parseo.
En este tipo de problemas encajan los parsers XML conocidos como Pull Parsers en donde el programador toma el control del proceso de parseo.
StAX
Algunas frases sobre StAX:
- StAX son las siglas de Streaming API for XML.
- Es una especificación cuyas clases e interfaces están ubicadas en el paquete
javax.xml.stream. - Java 6 incluye una implementación de referencia. [Ver implementaciones]
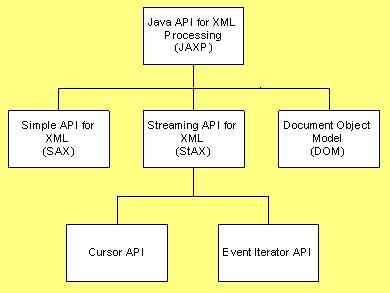
- Streaming API for XML consiste en dos estilos de parseo (ambos sencillisimos de usar): Cursor API y Event Iterator API.
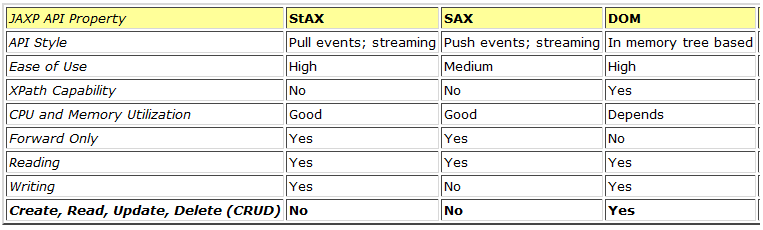
Excelente tabla comparativa de características: [Fuente]
Familias de parsers: [Fuente]
Estilo Cursor API
Para hacer uso de este estilo usaremos el interface XMLStreamReader.
Es la forma más eficiente de leer el XML pues nos movernos a bajo nivel.
Con este estilo el XML se recorre iterando ha través de los métodos:
public boolean hasNext():
Devuelve un booleano indicando si hay más elementos que iterar.public int next():
Devuelve el código del evento en el que estamos posicionados y cuyos valores están definidos como constantes en la interfazjavax.xml.stream.XMLStreamConstants.XMLStreamConstants.START_DOCUMENT: Principio del documento.XMLStreamConstants.START_ELEMENT: Principio de un elemento o tag.XMLStreamConstants.END_ELEMENT: Fin de un elemento o tag.XMLStreamConstants.START_ELEMENT: Fin del documento.- etc. (consultar documentación oficial)
public String getLocalName(): Para al nombre del tag cuando el evento es:CHARACTERSpublic String getElementText(): Para acceder a los datos cuando el tipo de evento es alguno de los siguientes:START_ELEMENT, END_ELEMENT o ENTITY_REFERENCE.- etc. (consultar documentación oficial)
Resolución con Cursor API: ¿Cuál de entre los 100 primeros libros es el más caro?:
package com.autentia.tutoriales.axiom;
import javax.xml.stream.*;
import java.io.*;
/**
* Ejemplo de lectura de datos con StAX a través del método: cursor API
* @author Carlos García. Autentia.
*/
public class StaxXMLStreamReaderApp {
/**
* Imprime por la salida estandar el título del libro más caro de entre los 100 primeros libros
*/
public static void main(String[] args) {
FileReader reader = null;
XMLStreamReader parser = null;
int precioMasCaro = Integer.MIN_VALUE;
String tituloMasCaro = null;
int currentPrecio = 0;
String currentTitle = null;
int currentPositon = 0;
int eventCode;
String tag;
try {
reader = new FileReader("c:/xml_muy_grande.xml");
parser = XMLInputFactory.newInstance().createXMLStreamReader(reader);
while (parser.hasNext() && (currentPositon != 100)){
eventCode = parser.next();
if (eventCode == XMLStreamConstants.START_ELEMENT){
tag = parser.getLocalName();
if ("libro".equals(tag)){
currentPositon++;
} else if ("titulo".equals(tag)){
currentTitle = parser.getElementText();
} else if ("precio".equals(tag)){
currentPrecio = Integer.valueOf(parser.getElementText());
if (currentPrecio > precioMasCaro){
precioMasCaro = currentPrecio;
tituloMasCaro = currentTitle;
}
}
}
}
System.out.println("El libro más caro es: " + tituloMasCaro);
} catch (Exception ex) {
// Para este tutorial no hacemos nada más que imprimir la excepción
System.out.println(ex);
} finally {
try {
reader.close();
} catch (Exception ex){}
try {
parser.close();
} catch (Exception ex){}
}
}
}
Estilo Event Iterator API
En este estilo de parseo se crean objetos intermedios que pueden ser pasados como parámetros a otros métodos de tu lógica de negocio.
Se encuentra ubicado como una capa por encima del estilo cursor API.
Los métodos son muy parecidos al Cursor API, consulte la documentación para profundizar más al respecto.
Resolución con Event Iterator API: ¿Cuál de entre los 100 primeros libros es el más caro?:
package com.autentia.tutoriales.axiom;
import javax.xml.stream.*;
import javax.xml.stream.events.XMLEvent;
import java.io.*;
/**
* Ejemplo de lectura de datos con StAX a través del método: Event Iterator API
* @author Carlos García. Autentia.
*/
public class StaxXMLEventReadeApp {
/**
* Imprime por la salida estandar el título del libro más caro de entre los 100 primeros libros
*/
public static void main(String[] args) {
FileReader reader = null;
XMLEventReader parser = null;
int precioMasCaro = Integer.MIN_VALUE;
String tituloMasCaro = null;
int currentPrecio = 0;
String currentTitle = null;
int currentPositon = 0;
XMLEvent evt = null;
String tag = null;
try {
reader = new FileReader("c:/xml_muy_grande.xml");
parser = XMLInputFactory.newInstance().createXMLEventReader(reader);
while (parser.hasNext() && (currentPositon != 100)){
evt = parser.nextEvent();
if (evt.isStartElement()){
tag = evt.asStartElement().getName().getLocalPart();
if ("libro".equals(tag)){
currentPositon++;
} else if ("titulo".equals(tag)){
currentTitle = parser.getElementText();
} else if ("precio".equals(tag)){
currentPrecio = Integer.valueOf(parser.getElementText());
if (currentPrecio > precioMasCaro){
precioMasCaro = currentPrecio;
tituloMasCaro = currentTitle;
}
}
}
}
System.out.println("El libro más caro es: " + tituloMasCaro);
} catch (Exception ex) {
// Para este tutorial no hacemos nada más que imprimir la excepción
System.out.println(ex);
} finally {
try {
reader.close();
} catch (Exception ex){}
try {
parser.close();
} catch (Exception ex){}
}
}
}
Referencias
- An introduction to Streaming API for XML (StAX).
- JSR 173: Streaming API for XML.
- Implementaciones de StAX.
- Does StAX Belong in Your XML Toolbox?.
Conclusiones
En muchas ocasiones la falta de formación, de tiempo, o de ganas, hacen que los proyectos usen parsers que no son los más adecuados para el problema a resolver y esto hace que los sistemas consuman muchos más recursos de los necesarios, generandose problemas del tipo OutOfMemoryException…
La tecnología está, ahora sólo hace falta conocerla y saber cuando usarla.
Como cuña para terminar, decir que este tipo de parsers (Pull Parser) se suelen usar en aplicaciones para dispositivos de recursos limitados (PDA, móviles, etc). En este tipo de proyectos cada byte consumido importa.
Carlos García Pérez. Creador de MobileTest, un complemento educativo para los profesores y sus alumnos.
cgpcosmad@gmail.com


Muy buen tutorial señor Carlos.
Excelente articulo!.
Un proceso que demoraba una hora con XPath, a parte de consumir mucha memoria, con StAX demora ahora 4 minutos. He quedado sorprendida.
Muchas gracias por el aporte!!!!!!!