
Introducción a Spring Data: soporte para JPA.
0. Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Configuración.
- 4. De los DAOs de antaño.. .
- 5. …a los nuevos repositorios.
- 6. Referencias.
- 7. Conclusiones.
1. Introducción
Spring Data es un proyecto de SpringSource cuyo propósito es unificar y facilitar el acceso a distintos tipos de tecnologías de persistencia, tanto a bases de datos relacionales
como a las del tipo NoSQL.
Spring ya proporcionaba soporte para JDBC, Hibernate, JPA, JDO o Mybatis, simplificando la implementación de la capa de acceso a datos, unificando la configuración y creando una jerarquía de excepciones común para todas ellas.
Y ahora, Spring Data viene a cubrir el soporte necesario para distintas tecnologías de bases de datos NoSQL y, además, integra las tecnologías de acceso a datos tradicionales, simplificando el trabajo a la hora de crear las implementaciones concretas.
Con cada tipo de tecnología de persistencia los DAOs (Data Access Objects) ofrecen las funcionalidades típicas de un CRUD (Create-Read-Update-Delete ) para objetos de dominio propios, métodos de busqueda, ordenación y paginación. Spring Data proporciona interfaces genéricas para estos aspectos (CrudRepository, PagingAndSortingRepository) e implementaciones específicas para cada tipo de tecnología de persistencia.
A día de hoy, Spring Data proporciona soporte para las siguientes tecnologías de persistencia:
- JPA y JDBC
- Apache Hadoop
- GemFire
- Redis
- MongoDB
- Neo4j
- HBase
En este tutorial vamos a analizar, a través de un ejemplo, el soporte que nos proporciona Spring Data para JPA, haciendo uso de la implementación de referencia, el entityManager de Hibernate.
2. Entorno.
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 15′ (2.4 GHz Intel Core i7, 8GB DDR3 SDRAM).
- Sistema Operativo: Mac OS X Lion 10.7.4
- Spring 3.1.1.RELEASE
- Spring Data JPA 1.1.0.RELEASE
3. Configuración.
Lo primero, como de costumbre haciendo uso de maven, es incluir las dependencias de las librerías con las que vamos a trabajar:
<dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-jpa</artifactId> <version>1.1.0.RELEASE</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-orm</artifactId> <version>3.1.1.RELEASE</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-core</artifactId> <version>3.1.1.RELEASE</version> </dependency> <dependency> <groupId>org.hibernate.javax.persistence</groupId> <artifactId>hibernate-jpa-2.0-api</artifactId> <version>1.0.0.Final</version> </dependency> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-entitymanager</artifactId> <version>4.1.4.Final</version> </dependency>
4. De los DAOs de antaño…
Tomando como base el siguiente objeto de dominio:
@Entity
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String email;
private String firstname;
private String lastname;
// setters & getters;
Con el soporte de Spring podríamos crear un DAO definiendo una interfaz como sigue:
public interface CustomerService {
Customer findById(Long id);
Customer save(Customer customer);
List<Customer> findAll();
List<Customer> findAll(int page, int pageSize);
}
Y la siguiente clase de implementación con el soporte de Spring
@Repository
public class CustomerServiceImpl extends JpaDaoSupport implements CustomerService {
@Autowired
public CustomerServiceImpl(EntityManagerFactory entityManagerFactory) {
super.setEntityManagerFactory(entityManagerFactory);
}
public Customer findById(Long id){
return getJpaTemplate().find(Customer.class, id);
}
public Customer save(Customer customer){
Customer result = customer;
if (customer.getId() == null) {
getJpaTemplate().persist(customer);
} else {
if (!getJpaTemplate().contains(customer)) {
result = getJpaTemplate().merge(customer);
}
}
return result;
}
...
}
A partir de la versión 3.1. la clase JPADaoSupport está marcada como deprecada y se recomienda hacer uso directamente de la inyección del EntityManager con la anotación estándar @PersistenceContext:
@Repository
public class CustomerServiceImpl implements CustomerService {
@PersistenceContext
private EntityManager entityManager;
public Customer findById(Long id){
return entityManager.find(Customer.class, id);
}
public Customer save(Customer customer){
Customer result = customer;
if (customer.getId() == null) {
entityManager.persist(customer);
} else {
if (!entityManager.contains(customer)) {
result = entityManager.merge(customer);
}
}
return result;
}
...
}
Y la interfaz y la clase de implementación será la misma para todas las entidades, salvo que trabajará con la clase de dominio propia del DAO específico.
De ahí que en muchos proyectos nos encontremos con un GenericDao<T extends AbstractEntity, ID extends Serializable> como intento de reutilización de código basado en la herencia. Ahora, con Spring Data, esos GenericDao son los nuevos Repository.
5. …a los nuevos repositorios.
Con el soporte de Spring Data, la tarea repetitiva de crear las implementaciones concretas de DAO para nuestras clases de negocio se simplifica porque solo vamos a necesitar definir la interfaz; no más!
import org.springframework.data.repository.CrudRepository;
public interface CustomerRepository extends CrudRepository<Customer, Long> {
}
Necesariamente hay que declarar la clase de entidad con la que trabajará el repositorio y el tipo de dato del campo de identidad.
Para activar la configuración de repositorios solo hay que indicar el paquete a partir del cuál Spring debe buscar clases que extiendan de Repository:
<?xml version="1.0" encoding="UTF-8"?>
<beans:beans xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/jpa
http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<jpa:repositories base-package="com.acme.**.repository" />
</beans>
Aunque también se pueden configurar haciendo uso de JavaConfig del siguiente modo:
@Configuration
@EnableJpaRepositories
class ApplicationConfig {
}
Por si solo, la interfaz CrudRepository nos va a proporcionar los siguientes métodos genéricos:
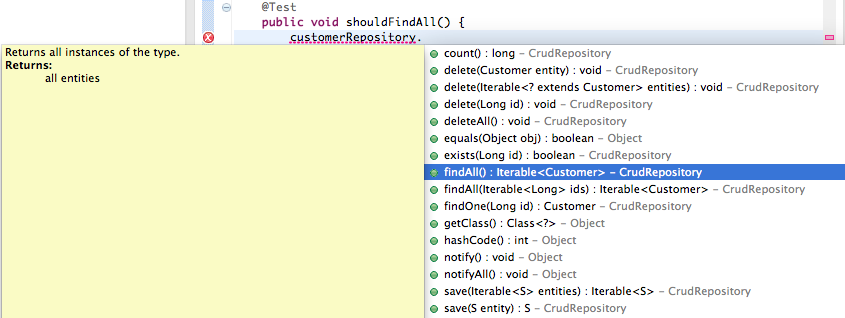
Si, en vez de extender de CrudRepository, extendemos de PagingAndSortingRepository, además tendremos disponibles estos otros:

Si, con los métodos anteriores no nos bastan, para declarar métodos de búsqueda propios en la interfaz, siguiendo una convención de nomenclatura podremos realizar el siguiente tipo de consultas:
public interface CustomerRepository extends CrudRepository<Customer, Long> {
Customer findByEmail(String email);
}
Sin más, en el arranque del contexto de Spring se creará una clase de implementación con la funcionalidad necesaria para cubrir los métodos base de Repository, más aquellos que vayamos añadiendo.
A parte de lo anterior, también se pueden definir las consultas que debe lanzar un método a través de la anotación Query,
bien con parámetros posicionales:
public interface CustomerRepository extends CrudRepository<Customer, Long> {
@Query("select c from Customer c where c.email = ?1")
Customer findByEmail(String email);
}
O con parámetros nombrados, haciendo uso de la anotación @Param:
public interface CustomerRepository extends CrudRepository<Customer, Long> {
@Query("select c from Customer c where c.email = :email")
Customer findByEmail(String email);
}
Si queremos añadir paginación a la consulta, han pensado en todo:
public interface CustomerRepository extends CrudRepository<Customer, Long>{
@Query("select c from Customer c where c.email = :email")
Page<Customer> findByEmail(@Param("email") String email, Pageable pageable);
}
Los métodos de los repositorios son, por defecto, transaccionales y, en el caso de los métodos de consulta, marcan la transacción como readOnly.
Claro, que aún no hemos visto las clases de implementación ¿no?, ya hemos dicho que no hay!, Spring Data las crea por nosotros!!!
6. Referencias.
- http://www.springsource.org/spring-data/jpa
- https://github.com/SpringSource/spring-data-jpa-examples/tree/master/spring-data-jpa-showcase
7. Conclusiones.
Quien venga de Grails todos estos conceptos le sonarán de GORM (Grails Object Relational Mapper), efectivamente y si 😉
El incoveniente es que no soporta Hibernate, aunque sí la implementación de JPA de Hibernate.
Un saludo.
Jose


Esta muy bien, pero me hubiese gustado que estubiesa como queda al final y poder probarlo ya corriendo
Solo falto indicar como crear el archivo PersistenceContext.xml y en el contexo crear el bean de la clase EntityManager.
Cual es el archivo de configuración que estas modificando después de que implementas CrudRepository ??
saludos perdón pero trato de saber en donde modificar .
Muchas gracias por el tutorial.
Hola.
Acabo de toparme con este post. Me parece muy interesante e instructivo. Pero me temo que llego tarde.
¿Recomiendas algún otro tutorial que esté actualizado? ¿O piensas que este todavía vale?
Simplemente quiero asegurarme antes de empezar a usarlo
qué mal explicado! faltan imports para gente que estamos empezando y no poner trozos de código solamente… pérdida de tiempo, gracias
Excelente entrada y bien explicada. Comentaros que he realizado un enlace a vuestra pagina desde mi blog personal,, donde desarrollo la misma idea, actualizandola (http://www.profesor-p.com/2018/08/25/jpa-hibernate-en-spring/). Espero que no os importe.