
Guía para entender y usar expresiones regulares
Índice de contenidos.
Introducción
Las expresiones regulares son las grandes olvidadas, no se utilizan mucho, pero cuando te toca utilizarlas lamentas no conocerlas más. Casi toda la gente que conozco dice conocerlas «más o menos», pero cuando le preguntas por un problema concreto no sabe resolverlo.
Permiten filtrar textos para encontrar coincidencias, comprobar la validez de fechas, documentos de identidad o contraseñas, se pueden utilizar para reemplazar texto con unas características concretas por otro, y muchos más usos.
El problema es que no son intuitivas a primera vista, por lo que la solución a la que llegan muchos programadores con experiencia que no quieren aprenderse la sintaxis a fondo es tener un conjunto de soluciones que le han servido en el pasado y partir de alguna que se parezca.
Lo que voy a intentar con este tutorial es por una parte, dar una base a la gente que esté empezando, y por otra, servir de referencia para la gente que tiene una idea general pero necesita algo específico.
Lo básico es conocer la sintaxis
Es una pena repetir trabajo que otra gente ha hecho ya antes que nosotros, por lo que voy a poneros dos listas de elementos básicos para crear expresiones regulares que creo que os resultarán muy útiles.

Fuente:
http://www.cheatography.com/davechild/cheat-sheets/regular-expressions/pdf/
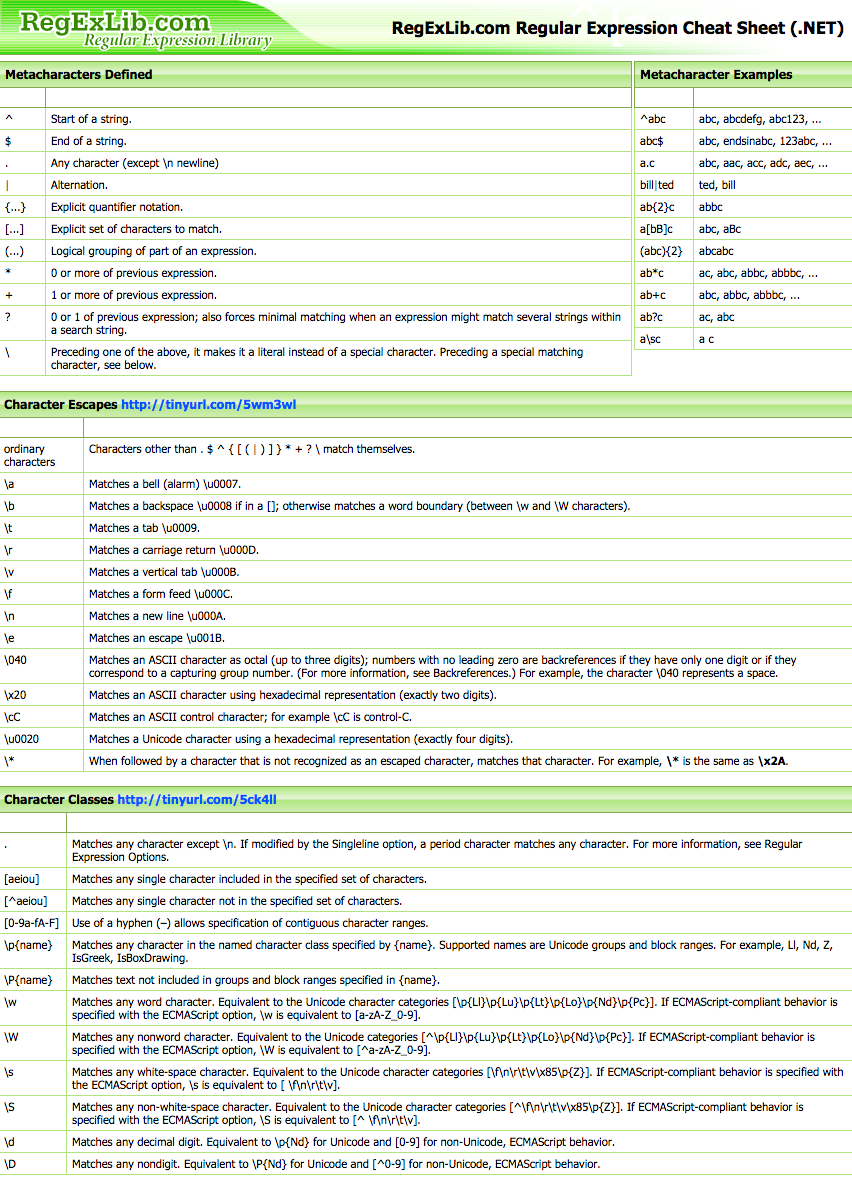
Fuente:
Una breve lista de los más utilizados:
- ^ Indica el principio de una cadena
- $ Indica el final de una cadena
- () Un agrupamiento de parte de una expresión
- [] Un conjunto de caracteres de la expresión
- {} Indica un número o intervalo de longitud de la expresión
- . Cualquier caracter salvo el salto de línea
- ? 0-1 ocurrencias de la expresión
- + 1-n ocurrencias de la expresión
- * 0-n ocurrencias de la expresión
- \ Para escribir un caracter especial como los anteriores y que sea tratado como un literal
- | Para indicar una disyunción lógica (para elegir entre dos valores: a|b se tiene que cumplir al menos uno de los dos)
Aprendiendo con ejemplos
La forma más rápida para aprender a hacer expresiones regulares es mediante ejemplos, en el link de abajo tenéis una página para ir probando combinaciones y comprobar en tiempo real el resultado.
Os recomiendo que si tenéis interés vayáis probando las expresiones aquí, así podéis probar variaciones.
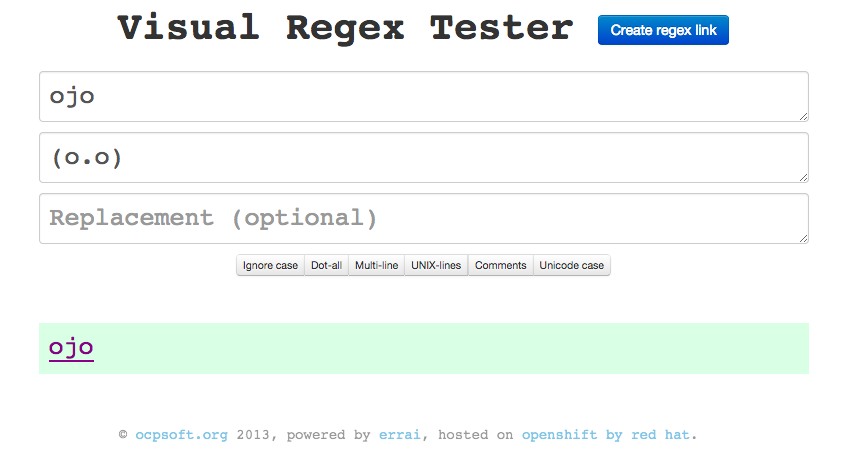
El primer campo de texto es para la frase que comprueba la validez de la expresión y el segundo campo es para nuestra expresión.
Necesitamos una cadena de texto que pueda tener una o más «a», que puedan existir «e» o no existir y que pueda haber una única «i».
a+e*i?
Necesitamos una cadena de texto que este formada por la letra «o» intercalada por la letra «a» pero tiene que haber un número par de «o» y de «a», o si no no será válida.
((oo)+(aa)+)
Vamos a permitir que esta cadena pueda ser más larga intercalando las «o» y las «a».
((oo)+(aa)+)*
Necesitamos que el usuario tenga un límite en el número de «o» que escribe, porque hemos detectado que tiene mucho tiempo libre.
((oo)+(aa)+)*{3,6}
Con esta expresión podéis ver además que la longitud no es del total de caracteres, si no del numero de subexpresiones formadas por «o» y por «a».
Necesitamos encontrar todas las palabras de tres letras que empiecen y acaben por «o», como oso, ojo u oro.
(o.o)
Los usuarios se divierten con caracteres especiales intentando hacer caritas o.o o metiendo numeros o1o, vamos a restringir el caracter central a una letra.
o[a-zA-Z]o
Lo que hace esta expresión es pedir primero una «o», después un carácter que pertenecerá al intervalo de mayúsculas o minúsculas y al final pedir una «o».
Necesitamos saber si en una frase se encuentra la palabra violencia para ayudar a la policía (cambiar violencia por lo que queráis).
.*(violencia).*
Necesitamos encontrar faltas de ortografía para un profesor de lengua, vamos a buscar palabras que contengan hiatos.
Una versión simple en la que no tenemos en cuenta las tildes sería
.*(a(e|o)|e(a|o)|o(a|e)).*
Hay tres opciones básicas dependiendo de por que vocal fuerte (a,e,o) empiece el hiato, y luego en cada caso hay subcasos para ver si está seguido de otra vocal fuerte. Las combinaciones posibles son ae, ao, ea, eo, oa, oe.
Al profesor le ha gustado nuestra expresión y nos ha pedido que hagamos una para filtrar textos que no contengan el típico error de n seguida de b, o m seguida de v.
(?!.*(mv|nb)).*
Una solución mas completa es en la que se comprueba además que si existan combinaciones de mb o de nv.
(?!.*(mv|nb)).*(mb|nv).*
Esta tiene infinidad de usos, podeis buscar gente por apellido pero que su nombre sea distinto de alguno, podeis filtrar una lista para que no contenga algunas nacionalidades pero requiera otro dato, etc.
Ahora queremos un filtro para fechas con dos dígitos para dia y mes, y dos o cuatro dígitos para el año. Además queremos que sea posible utilizar tanto barras «/» como guiones «-» como carácter separador.
[0-9]{2}[/-][0-9]{2}[/-]([0-9]{2}|[0-9]{4})
No está mal como aproximación, pero estaría bien que el usuario no pudiera poner como día el 99 y como mes el 13, una solución parcial para que el día maximo fuera 31 sería que tratariamos cada dígito por separado, siendo el primero entre 0 y 3, y el segundo entre 0 y 9.
El problema es para meses como febrero que no llegan a los 30 días.
Mi opinión personal es que no os metais en estos problemas con expresiones regulares, porque ya existen otras soluciónes mas sencillas.
Dicho esto, si aún así tenéis curiosidad, por ejemplo el usuario Arthur Lorent en Stackoverflow.com ha propuesto esta solución para fechas con formato YYYY-MM-DD y YYYY/MM/DD
(((19|20)([2468][048]|[13579][26]|0[48])|2000)[/-]02[/-]29|((19|20)[0-9]{2}[/-]
(0[4678]|1[02])[/-](0[1-9]|[12][0-9]|30)|(19|20)[0-9]{2}[/-](0[1359]|11)[/-]
(0[1-9]|[12][0-9]|3[01])|(19|20)[0-9]{2}[/-]02[/-](0[1-9]|1[0-9]|2[0-8])))
¿Qué pensáis que hace la siguiente expresión?
(?=.*[0-9]{2})[0-9a-zA-Z]{8,12}
Vamos a verlo por partes:
- ?= Va a buscar que la siguiente expresión se encuentre en el texto
- .*[0-9] Un texto que contenga al menos un número
- [0-9]{2} El número debe ser de dos dígitos
- (?=.*[0-9]{2}) En lo que siga a esta expresión, se va a validar que exista un número de al menos dos dígitos
- [0-9a-zA-Z] Un carácter entre números y letras mayúsculas o minúsculas
- [0-9a-zA-Z]{8,12} Será una cadena de longitud mínima 8 y máxima 12
Por tanto, en una cadena de 8 a 12 caracteres alfanuméricos, se va a requerir que exista un número de al menos dos dígitos.
Para finalizar, le he pedido a un amigo que me ponga un caso real para probar.
Él trabaja en una aplicación con compras, y tiene una funcionalidad para introducir tarjetas de crédito. La funcionalidad que necesitan es la siguiente:
«Necesito comprobar que en una cadena de texto existan al menos dos palabras (nombre y apellido), que no existan números y que cada palabra tenga al menos dos caracteres.»
Si trabajamos en UTF8 y se incluyen tildes de forma automática en \w, o en caso contrario no necesitamos tildes ni «ñ» nos vale con esto.
(?!.*[0-9])(?=.*\s.+)(?!\w\s)(?!.*\s\w\s)(?!.*\s\w$).[\w\s]+
El caso general con tildes y la ñ, que es el más completo es este.
(?=.*\s.+)(?![a-zA-Zñáéíóúü]\s)(?!.*\s[a-zA-Zñáéíóúü]\s)(?!.*\s[a-zA-Zñáéíóúü]$).[a-zA-Zñáéíóúü\s]+
Podrían agruparse muchas condiciones con un «|», pero lo prefiero dejar así para que lo veáis más claro.
Voy a explicar las partes que os puedan resultar más confusas
Voy a usar la versión corta con \w, pero el funcionamiento lógico es el mismo.
- (?!.*[0-9]) Que no existan números, es importante el detalle de que en la segunda versión esto no es necesario porque especificamos el rango de caracteres que queremos.
- (?=.*\s.+) Que exista al menos un espacio, y que no sea el ultimo caracter de la frase si solo existe uno
- (?!\w\s) Que no exista un sólo caracter al principio de la cadena seguido de un espacio
- (?!.*\s\w\s) Que no exista un único carácter separado por espacios
- (?!.*\s\w$) Que no exista un caracter solo al final de la frase ($) precedido de un espacio
- .[\w\s]+ La propia cadena, que puede tener uno o más caracteres y espacios
Conclusiones
No hay una solución única en cada caso, mi método personal de resolver las expresiónes complejas es mediante la técnica de divide y vencerás, extraigo cada subfuncionalidad y la pongo por separado, pero vosotros podéis optar por soluciones más compactas.
Hay un detalle a tener en cuenta si las utilizáis en Java. En Java, como el caracter de escape es la «\», cuando la utilicéis en una cadena, tendréis que duplicarla, convirtiendose por ejemplo \w en \\w.
Espero que este tutorial os haya servido o bien para resolver algún problema puntual, o que os haya adentrado un poco en las RegEx. Con cualquiera me doy por satisfecho.


gracias por el aporte, realmente e aprendido hacer expresiones regulares con este articulo.
lo recomendaré!
Buenas tardes.
Excelente tutorial, saludos desde Costa Rica.
Hola
Muy bueno, me inicio en esto apenas y tengo dudas.
permiteme preguntarte lo siguiente:
Si tengo una expresión cualquiera por ejemplo ^w+$ y necesito solo tomar lo que coincide con (w+) ¿lo puedo hacer con la api de regex o en su defecto tocaría tomar la expresión y aplicar un substring
Gracias por el tutorial.
Saludos.
muy bueno
Cordial Saludo.
Agradezco el tutorial, el cual me fue de mucha ayuda para iniciarme en las expresiones regulares. Sin embargo, al evaluar la expresión sugerida para la evaluación de las fechas, encontré los siguientes puntos:
1. Se consideran los meses 7, 8, 10 y 12 como de 30 días y los meses 9 y 11 como de 31, lo que es un error
2. Encontré una evaluación innecesaria al considerar el año 2000 de manera independiente, ya que se puede considerar dentro del grupo de décadas pares en los años bisiestos
3. Ya que todos los meses, a excepción de Febrero tienen 30 días, tomé a los meses de 31, también como una excepción.
Adjunto la expresión mejorada:
((((19|20)([02468][048]|[13579][26]))[/-]02[/-]29)|((19|20)[0-9]{2}[/-](02[/-](0[1-9]|1[0-9]|2[0-8]))|((0[13578]|1[02])[/-]31((0[1-9]|1[02])[/-](0[1-9]|[12][0-9]|30))))
Y su debida explicación:
( –Evaluación del día adicional para el mes de Febrero en los años bisiestos
( ( (19|20) –Se evalúa que los dos primeros dígitos del año sean 19 ó 20 (Siglos XX y XXI)
( [02468][048] –Se avalúa si el 3er dígito del año es par ó 0, el 4to dígito configura el año bisiesto con 0, 4 u 8
| –O
[13579][26] –Se avalúa si el 3er dígito del año es impar, el 4to dígito configura el año bisiesto con 0 ó 8
)
)
[/-] –Se evalúa que el separador de la fecha sólo sea / ó –
02 –Se evalúa que sea el mes es Febrero
[/-] –Se evalúa que el separador de la fecha sólo sea / ó –
29 –Se avalúa que admita el día 29 para Febrero de los años bisiesto
)
| –O
–Evaluación del calendario para el resto de años
( (19|20) –Se evalúa que los dos primeros dígitos del año sean 19 ó 20 (Siglos XX y XXI)
[0-9]{2} –Se evalúa que el 3er y 4to dígitos del año deben estar entre 0 y 9
[/-] –Se evalúa que el separador de la fecha sólo sea / ó –
( –Evaluación de las fechas válidas para el mes de Febrero
02 –Se evalúa que sea el mes es Febrero
[/-] –Se evalúa que el separador de la fecha sólo sea / ó –
( 0[1-9] –Se evalúa si el día comienza por 0, está seguido por un dígito entre 1 y 9
| –O
1[0-9] –Se evalúa si el día comienza por 1, está seguido por un dígito entre 0 y 9
| –O
2[0-8] –Se evalúa si el día comienza por 2, está seguido por un dígito entre 0 y 8
)
)
| –O
( –Evaluación de los meses de 31 días
( 0[13578] –Se evalúa si son los meses 1, 3, 5, 7 u 8
| –O
1[02] –Se evalúa si son los meses 10 ó 12
)
[/-] –Se evalúa que el separador de la fecha sólo sea / ó –
31 –Se avalúa que admita los día 31 para los meses 1, 3, 5, 7, 8, 10 ó 12
( –Evaluación de los meses de 30 días
( 0[1-9] –Se evalúa si son los meses 4, 6 ó 9
| –O
1[02] –Se evalúa si es el mes 11
)
[/-] –Se evalúa que el separador de la fecha sólo sea / ó –
( 0[1-9] –Se evalúa si el día comienza por 0, está seguido por un dígito entre 1 y 9
| –O
[12][0-9] –Se evalúa si el día comienza por 1 ó 2, está seguido por un dígito entre 0 y 9
| –O
30 –Se avalúa que admita el día 30 para los meses 4, 6, 9 u 11
)
)
)
)
Espero sea de su ayuda para la comprensión del tema anteriormente tratado.
Con respecto a su explicación sigo sin saber cómo sería la fórmula en Notepad++ para buscar en un texto en inglés todos los verbos formados por “to” + infinitive y todos los verbos acabados en -ing. Si me pudiese ayudar se lo agradecería muchísimo. Gracias de antemano.
Hola,
Gracias, por este completo tutorial
Se pueden hacer cálculos como resultado de reemplazo con Notepad++?
Me explico:
Necesito hacer algo que a priori parece muy simple pero no encuentro la forma.
En un código Html tengo un texto escrito que se repite muy continuamente y que representa un inicio y final entre dos años:
ejemplo : 1950-2023
Buscarlos todos y cada uno de ellos es la parte fácil :(\d+)-(\d+)
El problema viene cuando quiero que se substituyan todos por diferencia entre el último i el primero con la edad como resultado de restarlos.
Si pongo REMPLAZAR por la expresión regular \2-\1 lógica y simplemente me substituye por : 2023-1950
Como puedo hacer un remplazo de forma que entienda «-» como resto un operador de resto y me de como resultado el calculo entre los años: 73
Muchas gracias!!