
En este tutorial veremos las alternativas de configuración de Elasticsearch a través del plantillado de índices y el tipado de documentos de forma externa.
0. Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Instalación y ejecución de Elasticsearch
- 4. Preparación del proyecto Maven para tests de integración
- 4.1 Estructura general del proyecto
- 4.2 Fichero pom.xml
- 4.3 Fichero elasticsearch-context.xml
- 4.4 IndexedDocument.java
- 4.5 Fichero IndexedDocumentTest_IT
- 5. Plantillado de índices
- 6. Tipado de documentos de un índice
- 7. Limitaciones en configuración programática con Spring Data Elasticsearch
- 8. Referencias
- 9. Conclusiones
1. Introducción
Elasticsearch es un servidor de búsqueda basado en Apache Lucene.
Provee un motor de búsqueda de texto completo, distribuido y con
capacidad de multitenencia con una interfaz web RESTful y con
documentos JSON. Elasticsearch está desarrollado en Java y está
publicado como código abierto bajo las condiciones de la licencia
Apache.
Los motores de búsqueda nos permiten la búsqueda y acceso a
información indexada de forma instantánea, que de otra forma supondría una gran penalización en tiempo y en rendimiento.
Un ejemplo típico de uso sería la búsqueda de artículos en un
blog utilizando como patrón de búsqueda alguna frase significativa que
pudiera aparecer con alta probabilidad en artículo que se pretende
encontrar.
2. Entorno
El tutorial está escrito utilizando el siguiente entorno:
- Hardware: MacBook Pro 15′ (2 Ghz Intel Core i7, 8GB DDR3 1333
Mhz) - Sistema operativo: Mac OS X Yosemite 10.10.3
- Software
- Java JDK 1.8
- Maven 3
3. Instalación y ejecución de Elasticsearch
Podemos encontrar la información de instalación y ejecución de Elasticsearch cubierta en este otro tutorial: Integración de Elasticsearch con Spring + MySQL
4. Preparación del proyecto Maven con Spring Data Elasticsearch
Con el fin de poder realizar las pruebas necesarias de plantillado y tipado externo de este tutorial, vamos a preparar un proyecto Maven que utilizaremos más adelante para realizar nuestros tests de integración que pruebe la configuración que estamos indicándole al motor de Elasticsearch.
4.1 Estructura general del proyecto
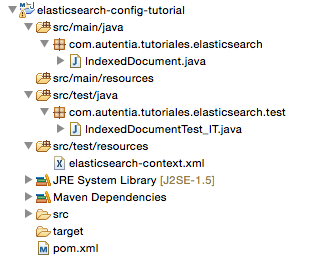
4.2 Fichero pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.autentia.tutoriales</groupId> <artifactId>elasticsearch-config-tutorial</artifactId> <version>0.0.1-SNAPSHOT</version> <name>Elasticsearch Config Tutorial</name> <dependencies> <!-- Spring Data Elasticsearch --> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-elasticsearch</artifactId> <version>1.2.0.RELEASE</version> </dependency> <!-- Spring --> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-test</artifactId> <version>4.1.7.RELEASE</version> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>4.1.7.RELEASE</version> </dependency> <!-- Tests --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>org.hamcrest</groupId> <artifactId>hamcrest-all</artifactId> <version>1.3</version> <scope>test</scope> </dependency> <dependency> <groupId>org.mockito</groupId> <artifactId>mockito-all</artifactId> <version>1.10.19</version> <scope>test</scope> </dependency> </dependencies> </project>
4.3 Fichero elasticsearch-context.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch"
xsi:schemaLocation="http://www.springframework.org/schema/data/elasticsearch http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch-1.0.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd">
<elasticsearch:transport-client id="client" cluster-name="elasticsearch" cluster-nodes="127.0.0.1:9300"/>
<bean name="elasticsearchTemplate" class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="client"/>
</bean>
4.4 IndexedDocument.java
package com.autentia.tutoriales.elasticsearch;
import org.springframework.data.annotation.*;
import org.springframework.data.elasticsearch.annotations.*;
import com.fasterxml.jackson.annotation.*;
import com.fasterxml.jackson.annotation.JsonCreator.Mode;
@Document(indexName = "indice_prueba", type = "documento_indexado_type")
public class IndexedDocument {
@Id
private final String id;
private final String title;
private final String description;
private final String notStored;
@JsonCreator(mode = Mode.PROPERTIES)
public IndexedDocument(@JsonProperty("id")
final String id, @JsonProperty("title")
final String title, @JsonProperty("description")
final String description, @JsonProperty("notStored")
final String notStored) {
super();
this.id = id;
this.title = title;
this.description = description;
this.notStored = notStored;
}
public String getId() {
return id;
}
public String getTitle() {
return title;
}
public String getDescription() {
return description;
}
public String getNotStored() {
return notStored;
}
}
4.5 Fichero IndexedDocumentTest_IT
package com.autentia.tutoriales.elasticsearch.test;
import static org.hamcrest.MatcherAssert.*;
import static org.hamcrest.Matchers.*;
import java.util.*;
import org.elasticsearch.index.query.*;
import org.junit.*;
import org.junit.runner.*;
import org.springframework.beans.factory.annotation.*;
import org.springframework.data.elasticsearch.core.*;
import org.springframework.data.elasticsearch.core.query.*;
import org.springframework.test.context.*;
import org.springframework.test.context.junit4.*;
import com.autentia.tutoriales.elasticsearch.*;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:/elasticsearch-context.xml")
public class IndexedDocumentTest_IT {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Before
public void setUp() {
elasticsearchTemplate.deleteIndex(IndexedDocument.class);
}
}
5. Plantillado de índices
Una vez disponemos de nuestro proyecto para codificar los tests, pasamos a configurar el Elasticsearch.
Podemos aplicar un sistema de plantillado de índices, el cual nos permitirá establecer parámetros de configuración de los futuros índices que se creen en el motor de búsqueda.
Para ello, deberemos acceder a la carpeta de configuración de Elasticsearch $ELASTICSEARCH_HOME/config, y crear una nueva carpeta llamada ‘templates’.
La carpeta ‘templates’ es la carpeta por defecto donde nuestro Elasticsearch buscará las posibles plantillas que puede aplicar a nuestros índices en el momento de su creación. Las plantillas de índices deben ser creadas en formato JSON.
En nuestro tutorial, vamos a crear una plantilla de índice que aplique a cualquier índice que vaya a ser creado nuevo, y lo que va a hacer es desactivar el campo «_source» de los documentos indexados de dicho índice.
Para ello, sobre $ELASTICSEARCH_HOME/config/templates creamos, por ejemplo, el fichero ‘default_template.json’ (El nombre no es determinante).

En dicho fichero, vamos a almacenar el siguiente contenido:
{
"template" :"*",
"mappings":{
"_default_":{
"_source":{
"enabled" : false
}
}
}
}
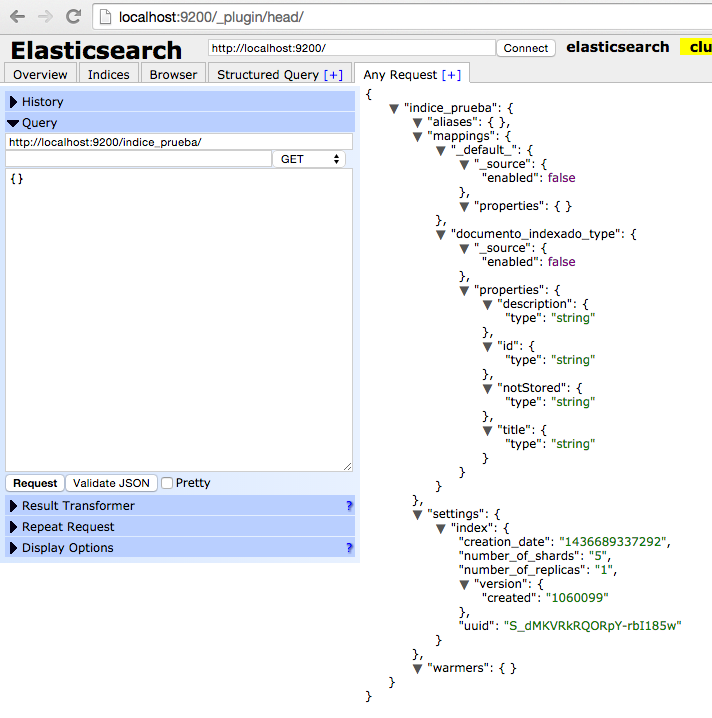
Con esta configuración, le estamos indicando al Elasticsearch que cualquier índice que cumpla con el nombre «cualquiera» (el asterisco es el caractér wildcard de Elasticsearch), y que además no importa en qué tipado se esté creando el documento (mappings->_default_), se deberá establecer el campo «_source» a «enabled:false». Lo que quiere decir, que para cualquier documento, sin importar el índice o su tipado, se desactivará el campo «_source».
5.1 Test de Integración del campo «_source» desactivado
Para poder verificar que el motor de Elasticsearch utiliza nuestra configuración de plantillado de índices, vamos a realizar un pequeño test de integración en el que indexemos un documento e inmediatamente después lo busquemos en Elasticsearch, y comprobemos que, efectivamente, el documento que recuperamos nos viene de vuelta con todos los atributos a null. Es decir, que como no hemos definido (todavía) ningún atributo a almacenar explícitamente, y hemos eliminado el campo «_source», Elasticsearch indexará pero NO almacenará ningún campo.
Para nuestro test, vamos a verificar unicamente que el campo «notStored» viene a null. Recordad que debemos de tener corriendo el servidor de Elasticsearch en la IP y puerto que hemos indicado en el ‘elasticsearch-context.xml’.
@Test
public void givenIndexedDocumentWithNoSourceWhenRetriveNotStoredFieldThenReturnedNull() {
// given
final IndexQuery indexQuery = new IndexQuery();
indexQuery.setObject(new IndexedDocument("1", "Documento indexado",
"Esto es una prueba de indexación de contenido", "Este contenido no se deberia guardar."));
elasticsearchTemplate.index(indexQuery);
elasticsearchTemplate.refresh(IndexedDocument.class, true);
// when
final QueryBuilder queryBuilder = QueryBuilders.boolQuery().must(QueryBuilders.matchAllQuery());
final SearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(queryBuilder).withFields("notStored")
.build();
final List indexedDocuments = elasticsearchTemplate.queryForList(searchQuery,
IndexedDocument.class);
// then
assertThat(indexedDocuments.size(), is(equalTo(1)));
assertThat(indexedDocuments.get(0).getNotStored(), is(nullValue()));
}
Lanzamos el test y verificamos que todo ha ido correctamente.

Además de ello, podemos ir a la página de administración del motor Elasticsearch y verificar la configuración del índice de forma empírica. Aquí podemos observar que el campo «_source» está desactivado para el índice que estamos testeando. (Para poder acceder a está página de administración, es necesario haber instalado previamente el plugin HEAD de Elasticsearch).
6. Tipado de documentos de un índice
Una vez visto como podemos configurar un índice de manera global, vamos a ver como configurar el tipado de un documento a través de ficheros JSON.
Para poder configurar el tipado de un documento indexado mediante configuración JSON, deberemos acceder a la carpeta ‘config’ del $ELASTICSEARCH_HOME, y allí crear la carpeta ‘mappings’. Debería quedar así: $ELASTICSEARCH_HOME/config/mappings.
En esta carpeta debemos crear todos los índices que queramos configurar en forma de carpeta, y posteriormente en el interior de las carpetas recien creadas, deberemos crear nuestros ficheros JSON con el mismo nombre del tipo del documento que vayamos a indexar.
Para nuestro ejemplo, tenemos que tener encuenta que nuestro índice se llama «indice_prueba», y que nuestro tipo de documento se llama «documento_indexado_type». Por lo tanto, dentro de la carpeta ‘mappings’, creamos la carpeta ‘indice_prueba’, y en el interior de ésta, creamos el fichero ‘documento_indexado_type.json’.

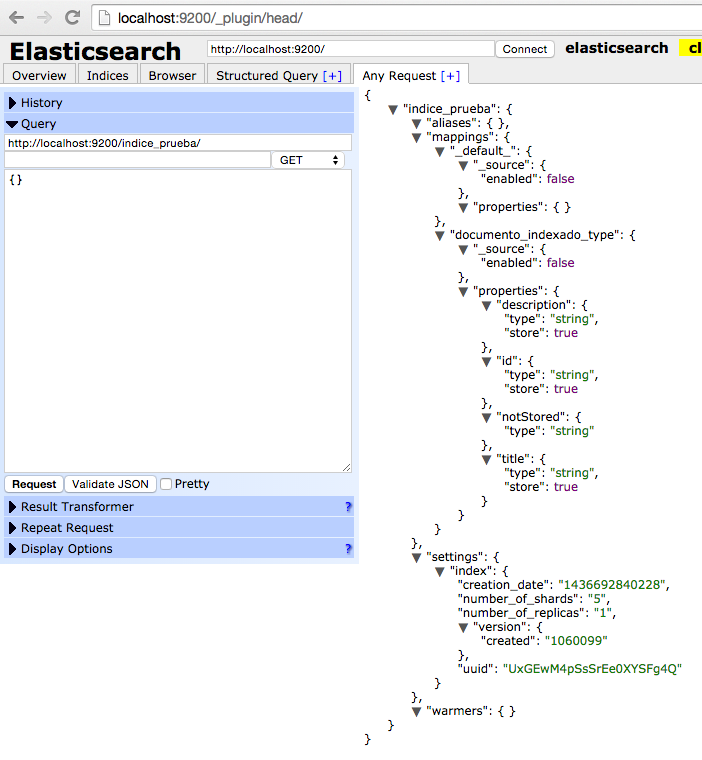
En el interior del fichero ‘documento_indexado_type.json’, escribimos el tipado de los documentos indexados que se basen en dicho tipo. Para nuestro ejemplo, vamos a indicar que se almacenen todos los contenidos indexados menos precisamente nuestro atributo ‘notStored’.
{
"documento_indexado_type":{
"properties":{
"description":{
"type":"string",
"store":true
},
"id":{
"type":"string",
"store":true
},
"notStored":{
"type":"string"
},
"title":{
"type":"string",
"store":true
}
}
}
}
6.1 Test de integración de los campos ‘store’:true
Del mimso modo que la vez anterior, vamos a codificar un test de integración para verificar que el motor de Elasticsearch ya almacena los campos que hemos marcado como ‘store:true’. Para ello, indexaremos un documento y posteriormente realizaremos una búsqueda sobre él recuperando aquellos campos que deberían haber sido almacenados para ver si nos devuelve el contenido correcto.
@Test
public void givenIndexedDocumentWithNoSourceWhenRetrieveStoredTitleAndStoredDescriptionThenReturnTheTitleAndDescription() {
// given
final IndexQuery indexQuery = new IndexQuery();
indexQuery.setObject(new IndexedDocument("1", "Documento indexado",
"Esto es una prueba de indexación de contenido", "Este contenido no se deberia guardar."));
elasticsearchTemplate.index(indexQuery);
elasticsearchTemplate.refresh(IndexedDocument.class, true);
// when
final QueryBuilder queryBuilder = QueryBuilders.boolQuery().must(QueryBuilders.matchAllQuery());
final SearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(queryBuilder)
.withFields("title", "description").build();
final List indexedDocuments = elasticsearchTemplate.queryForList(searchQuery,
IndexedDocument.class);
// then
assertThat(indexedDocuments.size(), is(equalTo(1)));
assertThat(indexedDocuments.get(0).getTitle(), is(equalTo("Documento indexado")));
assertThat(indexedDocuments.get(0).getDescription(),
is(equalTo("Esto es una prueba de indexación de contenido")));
}
Lanzamos los tests y verificamos que todo ha ido correctamente.

Por último, verificamos visualmente que el tipado del contenido ha cambiado en la pantalla de administración del motor Elasticsearch.
7. Limitaciones en configuración programática con Spring Data Elasticsearch
Como hemos podido comprobar, hemos configurado índices y tipados a través de ficheros de configuración externos almacenados directamente en el directorio de instalación del Elasticsearch.
Pero, ¿qué pasa si queremos configurarlo en un entorno de desarrollo y queremos almacenar los ficheros de configuración dentro de un JAR para poder lanzar test de integración de manera que los ficheros estén autocontenidos en la configuración del propio test? Pues lo cierto es que existe una limitación a la hora de indicarle la ruta de los ficheros de configuración que queramos que el motor de búsqueda utilice para tal fin, ya que debemos indicarle la ubicación absoluta del mismo.
En el caso de que estemos realizando tests de integración y los ficheros se encuentren dentro de la misma librería, no habría ningún problema.
Pero este escenario es poco realista, y normalmente nuestras aplicaciones se despliegan en algún servidor de aplicaciones o contenedor de servlets empaquetadas como .war, y dentro estarían contenidas todas las librerías .jar. En este caso, al estar los ficheros de configuración dentro del .jar, no se le puede indicar una ruta absoluta al Elasticsearch en el test, puesto que la ruta absoluta física no existe.
Por esta razón, si quisieramos disponer de un entorno de desarrollo para poder lanzar test de integración separados del propio entorno de integración, deberíamos disponer de una instancia de Elasticsearch a utilizar en desarrollo y configurar mediante ficheros externos (como hemos visto en este tutorial) las correspondientes configuraciones que queramos aplicar.
8. Referencias
8. Conclusiones
En este tutorial hemos visto como poder realizar plantillas de índices y tipado de documentos a través de ficheros de configuración externos almacenados en la propia instalación del Elasticsearch.
Espero que este tutorial os haya servido de ayuda. Un saludo.
Daniel Rodríguez
Twitter: @DaniRguezHdez
GitHub: dani-r-h

