
0. Índice de contenidos.
1. Entorno
Este tutorial está escrito usando el siguiente entorno:
- Hardware: Ordenador iMac 27″ (3.2 GHz Intel Core i5, 8 GB DDR3)
- Sistema Operativo: Mac OS X Mavericks 10.9
2. Agrupación de datos con MongoDB.
Siempre que se realizan tutoriales introductorios en cualquier tecnología, como en un HOLA MUNDO!, todo parece muy sencillo. Ahora bien, cuando queremos que el sistema se comporte como deseamos, comprobamos que es algo más complicado.
¡No trivialicemos el conocimiento! que todo es difícil e incluso debemos considerar que encontrando una rápida solución es muy posible que no sea el modo más adecuado de resolver un problema por escalabilidad o rendimiento.
Hoy me he puesto a manipular estructuras algo más complejas en MongoDB y tratando de obtener conocimiento útil "para negocio" de toda la información que vayamos almacenando. Este tutorial no es más que una bitácora de los ejemplos y conclusiones que he ido sacando según lo hacía. Repito muchas veces que el estudio sin tangibles es tiempo tirado … por lo menos gran parte.
Antes de mirar este tutorial os recomendaría visitar el anterior que hice de MongoDB (PrimerosPasosMongoDB), donde ayuda a instalar el sistema e introduce a Robomongo, que es en entorno de trabajo que estoy usando.
Vamos a poblar una base de datos con un esquema un poquito más complicado:
- Supongamos que tenemos la ficha de una persona donde vamos a ir introduciendo los gastos que tiene.
- Cada gasto es una entrada en un array donde se identifica la fecha (lo he simplificado por mes) y un comercio donde comprar.
- El detalle del gasto lo vamos a llamar Compra y es un array de elementos que tiene un concepto y un importe.
No lo vamos a complicar más para que se vea fácilmente el objetivo. Aquí tenéis visualmente el esquema con el primer ejemplo de datos.
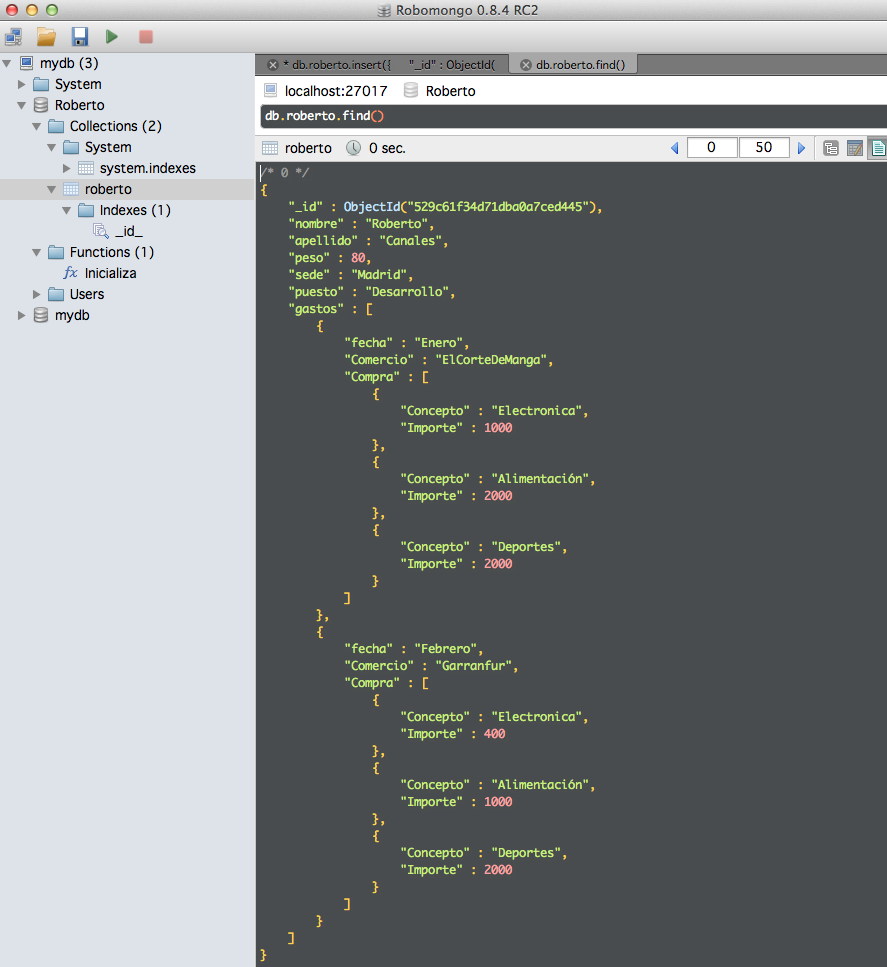
Por si lo queréis reproducir, aquí está el comando de inserción. Antes que nada disculparme por lo estúpido de poner sin criterio algunos nombre con mayúsculas y otros con minúsculas. Repetire 100 veces "el namming es importante hasta para juguetear".
Basta con quitar el _id del siguiente bloque y cambiar un poco los datos para poblar de nuevo contenido la base de datos lo que nos permitirá verificar que las cosas funcionan correctamente.
db.roberto.insert({
"_id" : ObjectId("529c61f34d71dba0a7ced445"),
"nombre" : "Roberto",
"apellido" : "Canales",
"peso" : 80,
"sede" : "Madrid",
"puesto" : "Desarrollo",
"gastos" : [
{
"fecha" : "Enero",
"Comercio" : "ElCorteDeManga",
"Compra" : [
{
"Concepto" : "Electronica",
"Importe" : 1000
},
{
"Concepto" : "Alimentación",
"Importe" : 2000
},
{
"Concepto" : "Deportes",
"Importe" : 2000
}
]
},
{
"fecha" : "Febrero",
"Comercio" : "Garranfur",
"Compra" : [
{
"Concepto" : "Electronica",
"Importe" : 400
},
{
"Concepto" : "Alimentación",
"Importe" : 1000
},
{
"Concepto" : "Deportes",
"Importe" : 2000
}
]
}
]
})
Si queréis luego añadir uno de gasto adicional podéis usar.
db.roberto.update (
{ "_id" : ObjectId("529c61f34d71dba0a7ced445") },
{ $push: { "gastos" : {
"fecha" : "Mayo",
"Comercio" : "INTERNES",
"Compra" : [{
"Concepto" : "Electronica",
"Importe" : 23
},
{
"Concepto" : "Alimentacion",
"Importe" : 44
},
]
}
}
}
)
En juego de datos de partida que voy a utilizar es el siguiente:
/* 0 */
{
"_id" : ObjectId("529c61f34d71dba0a7ced445"),
"nombre" : "Roberto",
"apellido" : "Canales",
"peso" : 80,
"sede" : "Madrid",
"puesto" : "Desarrollo",
"gastos" : [
{
"fecha" : "Enero",
"Comercio" : "ElCorteDeManga",
"Compra" : [
{
"Concepto" : "Electronica",
"Importe" : 1000
},
{
"Concepto" : "Alimentación",
"Importe" : 2000
},
{
"Concepto" : "Deportes",
"Importe" : 2000
}
]
},
{
"fecha" : "Febrero",
"Comercio" : "Garranfur",
"Compra" : [
{
"Concepto" : "Electronica",
"Importe" : 400
},
{
"Concepto" : "Alimentación",
"Importe" : 1000
},
{
"Concepto" : "Deportes",
"Importe" : 2000
}
]
}
]
}
/* 1 */
{
"_id" : ObjectId("529c666e7aed267edfe72636"),
"nombre" : "Jose Maria",
"apellido" : "Toribio",
"peso" : 78,
"sede" : "Madrid",
"puesto" : "Operaciones",
"gastos" : [
{
"fecha" : "Enero",
"Comercio" : "EFVNAF",
"Compra" : [
{
"Concepto" : "Electronica",
"Importe" : 1000
},
{
"Concepto" : "Deportes",
"Importe" : 2000
}
]
},
{
"fecha" : "Febrero",
"Comercio" : "Garranfur",
"Compra" : [
{
"Concepto" : "Electronica",
"Importe" : 400
},
{
"Concepto" : "Alimentación",
"Importe" : 1000
}
]
}
]
}
/* 2 */
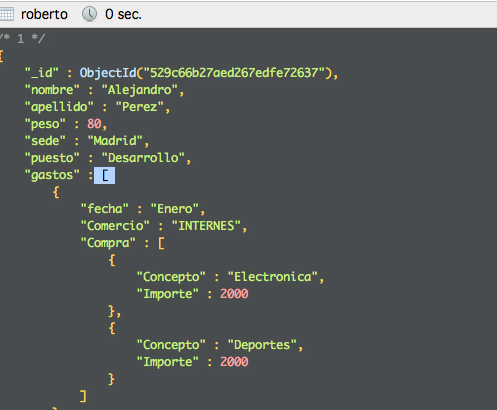
{
"_id" : ObjectId("529c66b27aed267edfe72637"),
"nombre" : "Alejandro",
"apellido" : "Perez",
"peso" : 80,
"sede" : "Madrid",
"puesto" : "Desarrollo",
"gastos" : [
{
"fecha" : "Enero",
"Comercio" : "INTERNES",
"Compra" : [
{
"Concepto" : "Electronica",
"Importe" : 2000
},
{
"Concepto" : "Deportes",
"Importe" : 2000
}
]
},
{
"fecha" : "Febrero",
"Comercio" : "Garranfur",
"Compra" : [
{
"Concepto" : "Alimentación",
"Importe" : 1000
},
{
"Concepto" : "Deportes",
"Importe" : 2000
}
]
}
]
}
Todo esfuerzo técnico debería ir guiado por una necesidad de negocio por lo que vamos a hacernos una serie de preguntas.
- Distintos comercios en los que hemos realizado compras.
- Compras que ha realizado cada persona.
- Compras por sede.
- Compras por puesto y sede.
- Importe de compras que hemos realizado en cada comercio. Esto mismo por fechas.
- Importe de compras que hemos realizado en cada departamento.
Como podemos ver, esto suena a agrupaciones de datos.
Vamos a comprobar la versión de MongoDB con la que trabajamos, no vaya a ser que la documentación de los comandos que miremos no coincida con los que podemos usar 😉

Estamos por tanto en 2.4.8.
Uno de los primeros comandos que podemos usar es distinct. Seleccionar distintos comercios donde hemos realizado compras
db.roberto.distinct("gastos.Comercio");
La respuesta es la que esperamos.
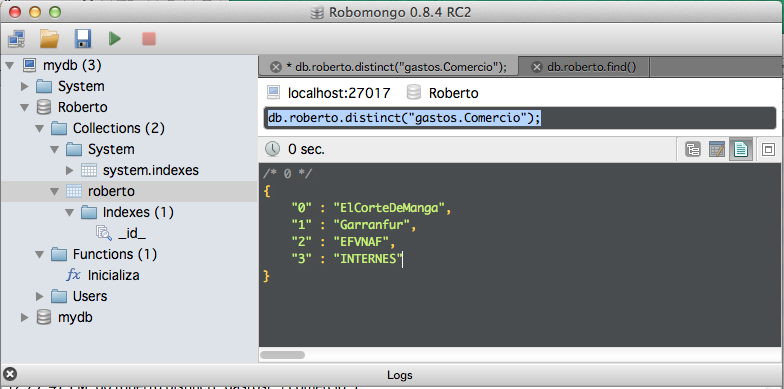
Funciona muy bien sobre estructuras anidadas. Ojo que estamos consultando por los elementos de un objeto dentro de un array dentro de otro dentro de un documento.
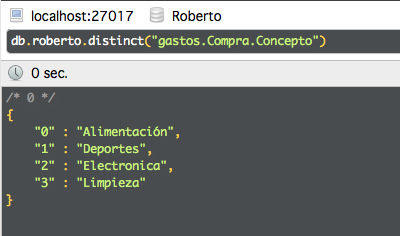
Para obtención de datos agrupados vamos a utilizar Group.
Aquí empieza un pequeño problema. Es que no me permite hacer las agrupaciones por elementos dentro de un array.
Un modo bastante sencillo de verlo es con Robomongo en base a los tipos de datos base. En verde se puede ver que gastos es un array.
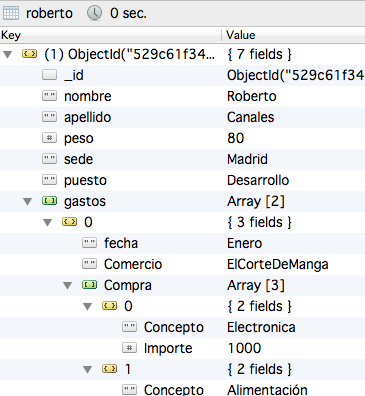
Por tanto, si quiero llegar hasta las compras que ha realizado cada persona tenemos que hacer una función particular.
Para entender lo que sale tenemos que interpretar las siguientes lineas:
En initial definimos variables que serán atributos dentro de un resultado y que se mostrarán en la respuesta.
initial: { rtotal:0, rgastos : 0}
key, es la clave/s por la que queremos agrupar. Puedo poner más de una.
key: { nombre :1 },
reduce recibe como entrada cada documento (con cond podemos acotar los que queremos usar) y lo procesa. El parámetro result es la referencia que se va arrastrando de llamada en llamada y donde acumulamos los valores. Los que definimos en initial son atributos del objeto result.
db.roberto.group (
{
key: { nombre :1 },
reduce: function ( curr , result )
{
for (var idx = 0; idx
Lo que hacemos es ir recorriendo cada array y añadiendo a rtotal el valor.
En rgastos apuntamos los documentos procesados.
Este es el resultado que obtenemos de la agrupación por nombre.
/* 0 */
{
"0" : {
"nombre" : "Roberto",
"rtotal" : 8400,
"rgastos" : 2
},
"1" : {
"nombre" : "Alejandro",
"rtotal" : 7000,
"rgastos" : 2
},
"2" : {
"nombre" : "Jose Maria",
"rtotal" : 4400,
"rgastos" : 2
}
}
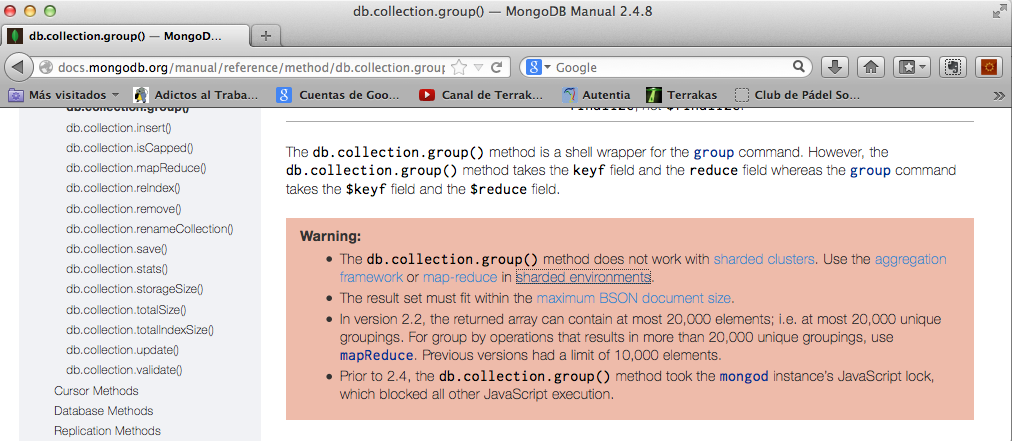
Antes de seguir estudiando, sería interesante leer los comentarios en rojo en la documentación (the method does not work with sharded enviroments 😉
Esto significa que no deberíamos hacer demasiados esfuerzos en utilizar este sistema de agrupamiento en grandes infraestructuras porque no funciona en entornos distribuidos. Puede ser interesante si utilizamos un único nodo a modo de base de datos sustitutiva de una relacional.
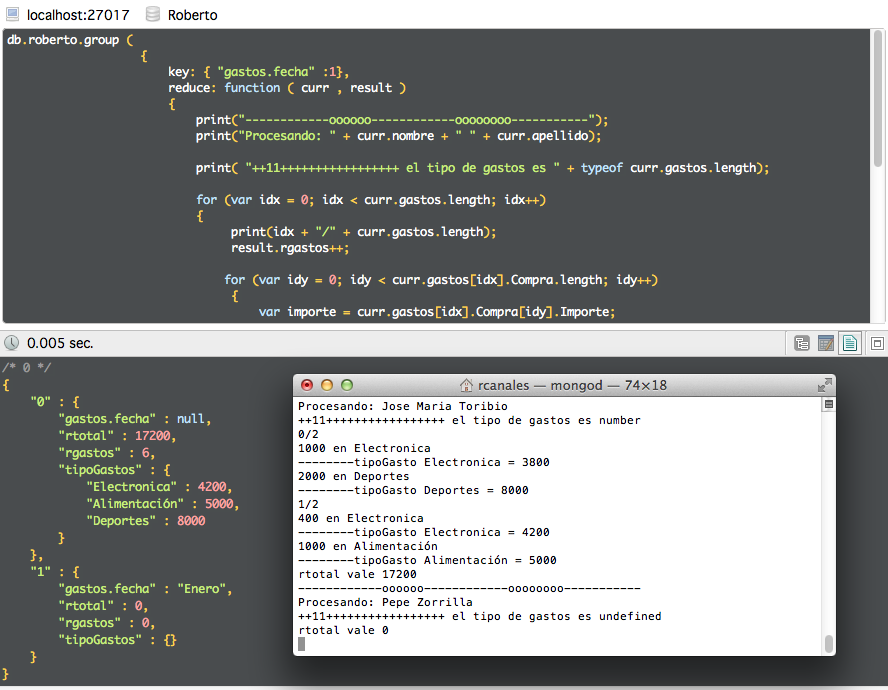
Aun así, vamos a hacer una cosita un poco más compleja. Tratar de obtener en las agrupaciones los gastos en distintos conceptos.
Lo que vamos a hacer es añadir un mapa donde por cada documento que procesemos iremos acumulando en un array de respuesta el concepto de gasto (como clave) y el valor del importe.
He añadido impresiones por pantalla para ir viendo qué pasa. Obviamente esto jamás debe realizarse en el entorno real (los mensajes volcados comprometerán el rendimiento del sistema críticamente).
db.roberto.group (
{
key: { puesto :1},
reduce: function ( curr , result )
{
print("------------ooooooooooooooooo-----------");
print("Procesando: " + curr.nombre + " " + curr.apellido);
for (var idx = 0; idx
El resultado obtenido será el siguiente agrupando la consulta por puesto.
/* 0 */
{
"0" : {
"puesto" : "Desarrollo",
"rtotal" : 15400,
"rgastos" : 4,
"tipoGastos" : {
"Electronica" : 3400,
"Alimentación" : 4000,
"Deportes" : 8000
}
},
"1" : {
"puesto" : "Operaciones",
"rtotal" : 4400,
"rgastos" : 2,
"tipoGastos" : {
"Electronica" : 1400,
"Deportes" : 2000,
"Alimentación" : 1000
}
}
}
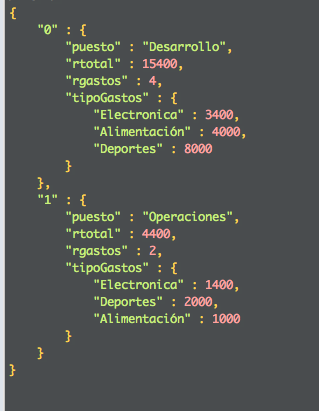
Si hacemos la agrupación por nombre.
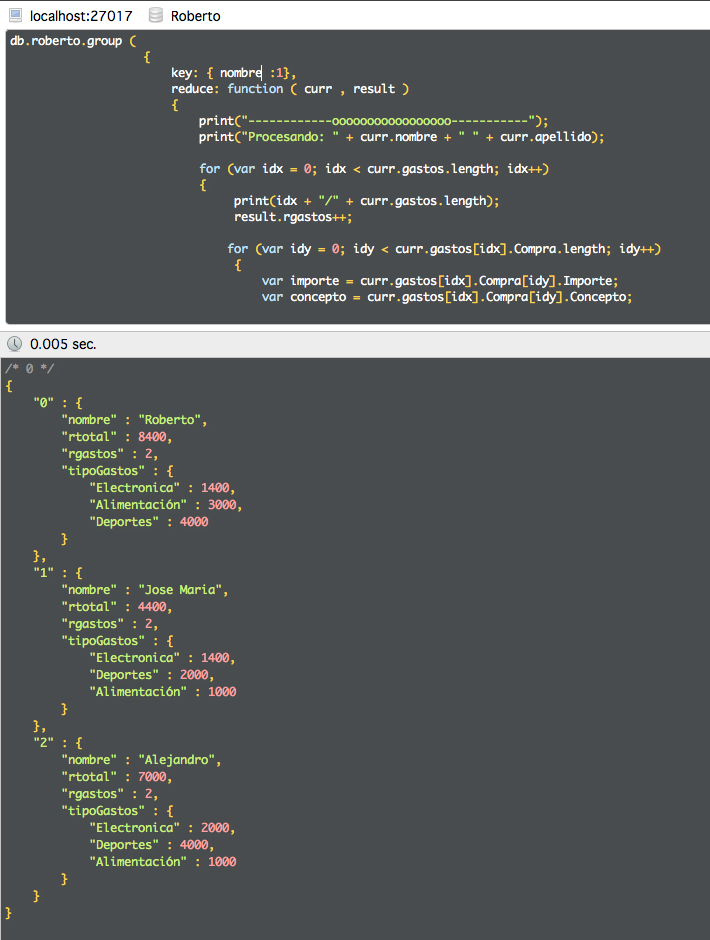
O por tipo de gasto, podemos comprobar que funciona correctamente la agrupación.
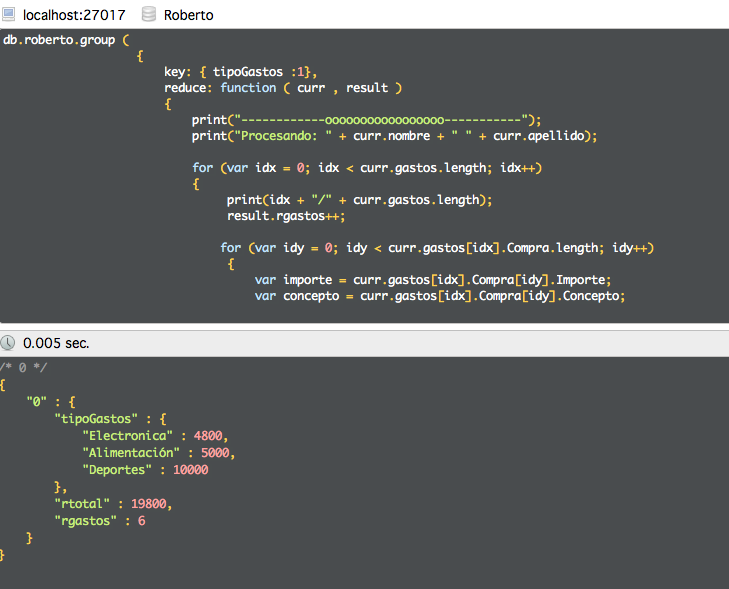
Para hacer agrupaciones por más de un campo vamos a añadir algún dato más, como la sede (para que sea tanto Madrid como Barcelona).
{
"nombre" : "Juan",
"apellido" : "Perez",
"peso" : 80,
"sede" : "Barcelona",
"puesto" : "Desarrollo",
"gastos" : [
{
"fecha" : "Enero",
"Comercio" : "INTERNES",
"Compra" : [
{
"Concepto" : "Electronica",
"Importe" : 20
},
{
"Concepto" : "Limpieza",
"Importe" : 10
},
{
"Concepto" : "Deportes",
"Importe" : 30
}
]
},
{
"fecha" : "Febrero",
"Comercio" : "Garranfur",
"Compra" : [
{
"Concepto" : "Alimentación",
"Importe" : 50
},
{
"Concepto" : "Deportes",
"Importe" : 60
}
]
},
{
"fecha" : "Marzo",
"Comercio" : "INTERNES",
"Compra" : [
{
"Concepto" : "Limpieza",
"Importe" : 5
},
{
"Concepto" : "Deportes",
"Importe" : 6
}
]
}
]
}
Si agrupamos por sede, obtendremos el siguiente resultado.
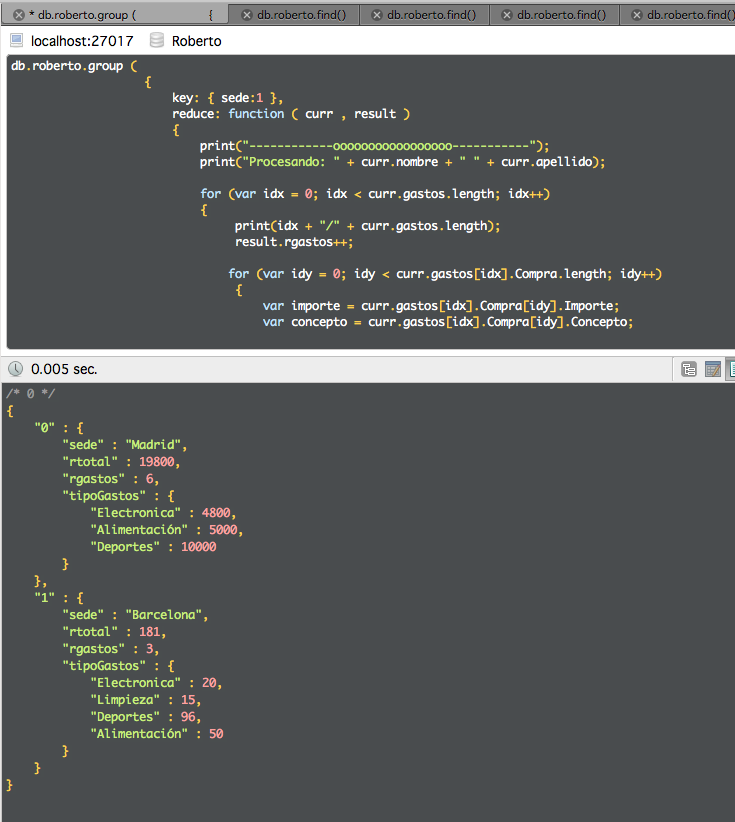
Si lo hacemos por sede y puesto vamos viendo que tenemos agrupaciones con datos válidos en cualquier caso.
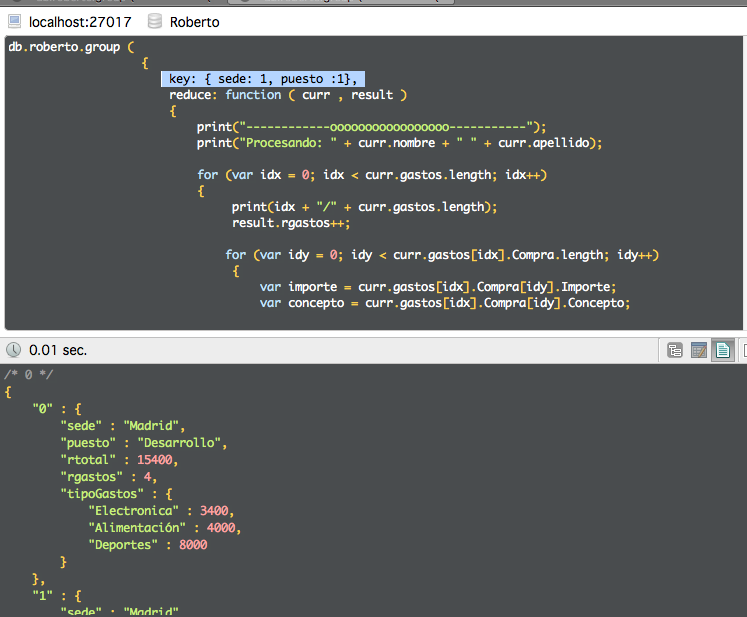
Y el resultado de la consola:

Adicionalmente, voy a compartir con vosotros un tema que me ha estado volviendo loco.
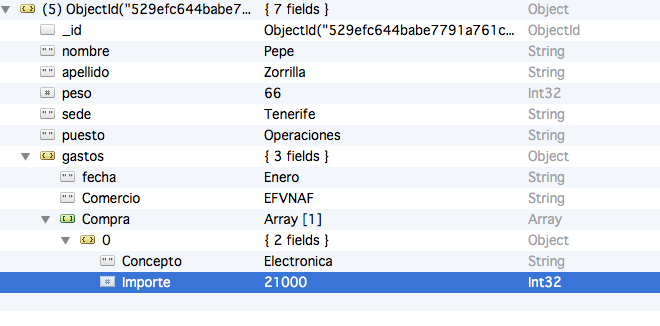
Hay una diferencia considerable a la hora de definir un elemento como un objeto o como un array. Me explico: si cuando insertamos un documento y solo tenemos un gasto, lo hacemos así: fijémonos en esta línea "gastos" : {
{
"_id" : ObjectId("529efc644babe7791a761c30"),
"nombre" : "Pepe",
"apellido" : "Zorrilla",
"peso" : 66,
"sede" : "Tenerife",
"puesto" : "Operaciones",
"gastos" : {
"fecha" : "Enero",
"Comercio" : "EFVNAF",
"Compra" : [
{
"Concepto" : "Electronica",
"Importe" : 21000
}
]
}
}
Estamos diciendo que para este esquema, en ese documento en concreto, los gastos es un objeto y no un array.
Si queremos hacer una inserción de otro gasto nos dirá que no es un array.
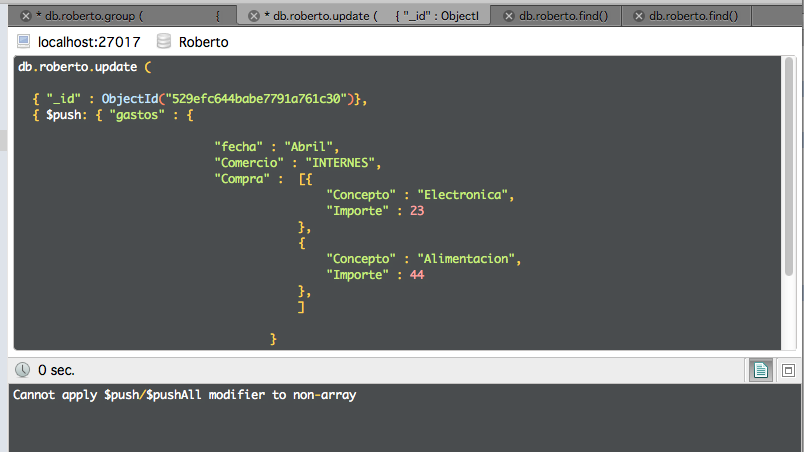
Por tanto, si queremos poder añadir más de un elemento en el futuro, su esquema en ese documento concreto tiene que estar configurado como un array y ser inicializado con corchetes aunque sólo insertemos un elemento. (bueno, esto se podría cambiar en el futuro).
En Robomongo visualmente se nota la diferencia porque el objeto aparece en amarillo y el array en verde.
Alguien podría decir que no tiene importancia y que posteriormente se podría cambiar el objeto por una array, pero tiene más importancia de lo que parece para nuestra funciones de reducción dentro de Group.
Si os fijáis en el algoritmo, damos por echo que gastos es una array y pedimos su longitud. Esto significa que como en los documentos donde está definido como objeto esa condición no se da, los resultados serán erráticos.
3. Conclusiones.
Bueno, espero que este tutorial os haya servido como a mí para entender las sutilezas de MongoDB a la hora de crear elementos como objetos y arrays, a usar el comando group con valores anidados y a añadir elementos en arrays .
Ahora bien, no hemos conseguido todos los objetivos de negocio con las consultas que nos habíamos puesto ¿qué hacemos si queremos conseguir los datos agrupados por fecha? Pues tendremos que rehacer la función de reducción.
Por tanto podemos ver que aunque el esquema en MongoDB es teóricamente "libre", las consultas o agrupaciones vienen muy condicionadas por esas estructuras.
Tendremos también que considerar: qué índices tendríamos que crear para que sea rápido acceder a la información, si es conveniente tener todos los datos anidados que hemos visto en un solo esquema o en dos (o más) esquemas distintos con referencias (más cercano a planteamientos no tan anidados y cercanos al de bases de datos columnares como vimos con Cassandra, etc. )
Como decía al principio… parece fácil pero creo que estas preguntas no tiene respuestas tan sencillas (sin hacer pruebas de rendimiento con miles de datos).

