
En este tutorial veremos los pasos a seguir para ver cómo podemos
integrar Elasticsearch en un proyecto con Spring + MySQL.
0. Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Preparación de la base de datos MySQL con
datos de prueba - 4. Instalación y ejecución de Elasticsearch
- 5. Importación de datos a Elasticsearch
- 6. Integración con Spring
- 7. Conclusiones
1. Introducción
Elasticsearch es un servidor de búsqueda basado en Apache Lucene.
Provee un motor de búsqueda de texto completo, distribuido y con
capacidad de multitenencia con una interfaz web RESTful y con
documentos JSON. Elasticsearch está desarrollado en Java y está
publicado como código abierto bajo las condiciones de la licencia
Apache.
Los motores de búsqueda nos permiten la búsqueda y acceso a
información indexada de forma instantánea, que de otra forma supondría una gran penalización en tiempo y en rendimiento.
Un ejemplo típico de uso sería la búsqueda de artículos en un
blog utilizando como patrón de búsqueda alguna frase significativa que
pudiera aparecer con alta probabilidad en artículo que se pretende
encontrar.
2. Entorno
El tutorial está escrito utilizando el siguiente entorno:
- Hardware: MacBook Pro 15′ (2 Ghz Intel Core i7, 8GB DDR3 1333
Mhz) - Sistema operativo: Mac OS X Yosemite 10.10.3
- Software
- Java JDK 1.8
- Maven 3
- MySQL Server 5.6
3. Preparación de la MySQL con datos de prueba.
Para nuestro tutorial, vamos a utilizar la base de datos de
pruebas de MySQL Sakila.
Accedemos a la web de descarga de MySQL Sakila a través del
siguiente enlace y nos descargamos el ZIP de la base de datos sakila.
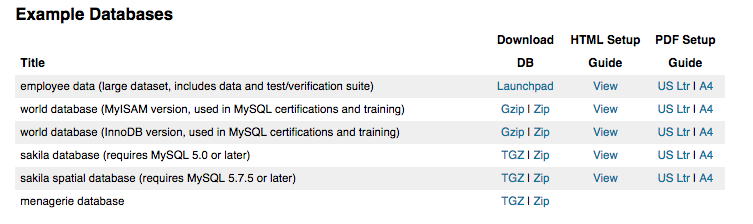
Descomprimimos el zip donde deseemos. Se nos habrá creado una
carpeta ‘sakila-db’ que contendrá los ficheros ‘sakila-schema.sql’, y
‘sakila-data.sql’.
Abrimos un terminal y nos conectamos al servidor de MySQL con nuestras credenciales.
shell> mysql -u root -p
Ejecutamos el script ‘sakila-schema.sql’.
mysql> SOURCE $DownloadFolder/sakila-db/sakila-schema.sql;
Ejecutamos el script ‘sakila-data.sql’.
mysql> SOURCE $DownloadFolder/sakila-db/sakila-data.sql;
Confirmamos que la base de datos se ha creado y poblado correctamente.
mysql> USE sakila; Database changed mysql> SHOW TABLES; +----------------------------+ | Tables_in_sakila | +----------------------------+ | actor | | address | | category | | city | | country | | customer | | customer_list | | film | | film_actor | | film_category | | film_list | | film_text | | inventory | | language | | nicer_but_slower_film_list | | payment | | rental | | sales_by_film_category | | sales_by_store | | staff | | staff_list | | store | +----------------------------+ 22 rows in set (0.00 sec) mysql> SELECT COUNT(*) FROM film; +----------+ | COUNT(*) | +----------+ | 1000 | +----------+ 1 row in set (0.02 sec) mysql> SELECT COUNT(*) FROM film_text; +----------+ | COUNT(*) | +----------+ | 1000 | +----------+ 1 row in set (0.00 sec)
4. Instalación y ejecución de Elasticsearch
El único requerimiento necesario para poder utilizar
Elasticsearch es una versión reciente de Java, preferiblemente,
utilizando su ultima versión oficial liberada disponible en www.java.com.
Accedemos a la página de descarga y nos descargamos el .zip con las
versión más actual. Después la descomprimimos en la ubicación que más nos
guste (a partir de ahora $ELASTICSEARCH_HOME).
A continuación vamos a instalar el plugin «head» de
Elasticsearch, el cual nos proporcionará una interfaz gráfica web del
ecosistema Elasticsearch que hayamos arrancado.
shell> $ELASTICSEARCH_HOME/bin/plugin -install mobz/elasticsearch-head
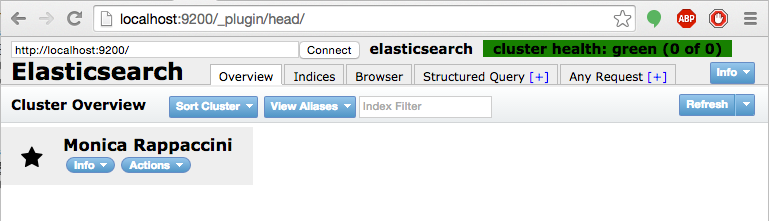
Por último, arrancamos el Elasticsearch y verificamos que está
arriba haciendo de nuestro plugin «head».
shell> $ELASTICSEARCH_HOME/bin/.elasticsearch
Accedemos a http://localhost:9200/_plugin/head/
y vemos que está levantado.
5. Importación de datos a Elasticsearch
Para la importanción de los datos utilizaremos Elasticsearch
JDBC Importer, el cual nos permite traernos todos los datos a través
de conexiones JDBC a nuestra base de datos. Esto nos da la potencia de
qué podremos recolectar datos de cualquier base de datos siempre y
cuando tengamos nuestro conector JDBC.
5.1 Para la instalación
Descargamos el .zip con el Elasticsearch JDBC Importer.
wget http://xbib.org/repository/org/xbib/elasticsearch/importer/elasticsearch-jdbc/1.6.0.0/elasticsearch-jdbc-1.6.0.0-dist.zip
Descomprimimos.
unzip elasticsearch-jdbc-1.6.0.0-dist.zip
Nos dirigimos al directorio descomprimido (a partir de ahora $JDBC_IMPORTER_HOME).
cd elasticsearch-jdbc-1.6.0.0
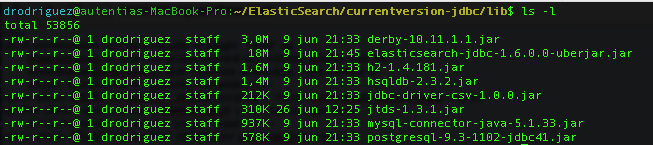
Verificamos que la versión descargada tenga nuestro conector JDBC para MySQL en la carpeta «$JDBC_IMPORTER_HOME/lib». Si no lo tuviera, se lo añadimos descargándonoslo de
la comunidad oficial de MySQL.
Con esto concluirían los pasos para la instalación del Elasticsearch JDBC Importer. Vamos a ver la ejecución.
5.2. Para la ejecución
Antes de ejecutar la importanción, debemos tener definida la query que lanzara el JDBC Importer para extraer los datos.
Para nuestro ejemplo, vamos a indexar la información para que se pueda buscar por título del film y descripción del film.
Para ello, debemos construir la siguiente query:
mysql> SELECT film.title as 'filmTitle', film.description as 'filmDescription' FROM film
Con ella, vamos a construir el script de importación.
shell> vim $JDBC_IMPORTER/bin/mysql-sakila-films-importer.sh
y lo editamos para que quede de la siguiente forma:
#!/bin/sh
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
bin=${DIR}/../bin
lib=${DIR}/../lib
echo '{
"type" : "jdbc",
"jdbc" : {
"url" : "jdbc:mysql://localhost:3306/sakila",
"user" : "root",
"password" : "",
"sql" : "SELECT film.film_id as '_id', film.title as 'filmTitle', film.description as 'filmDescription' FROM film",
"index" : "sakila_index_demo",
"type" : "film_type"
}
}'| java \
-cp "${lib}/*" \
-Dlog4j.configurationFile=${bin}/log4j2.xml \
org.xbib.tools.Runner \
org.xbib.tools.JDBCImporter
Atendiendo especialmente a la salida del comando ‘echo’.
{
"type" : "jdbc",
"jdbc" : {
"url" : "jdbc:mysql://localhost:3306/sakila",
"user" : "root",
"password" : "",
"sql" : "SELECT film.film_id as '_id', film.title as 'filmTitle', film.description as 'filmDescription' FROM film",
"index" : "sakila_index_demo",
"type" : "film_type"
}
- type: Tipo de conexion.
- dbc.url: URL de conexión JDBC.
- jdbc.user: Usuario de la conexión JDBC.
- jdbc.password: Password de la conexión JDBC.
- jdbc.sql: Query SQL utilizada para la extracción de datos.
- jdbc.index: Nombre del índice donde se indexará la información. Puede estar definido previamente en Elasticsearch.
- jdbc.type: Nombre del mapping que tendrán los documentos indexados a través de la query construida.
Salvamos el documento, y le damos permisos de ejecución.
shell> chmod 755 mysql-sakila-films-importer.sh
Por último ejecutamos el script teniendo en cuenta que el proceso de Elasticsearch ya tiene que estar arrancado previamente.
shell> ./mysql-sakila-films-importer.sh
Accedemos a la web del plugin head, para verificar que se ha creado el índice.
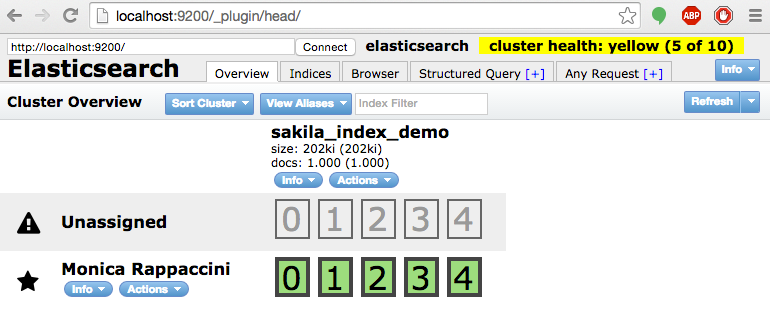
6. Integración con Spring
Para la integración con Spring se utilizará la librería Spring Data Elasticsearch, disponible en el repositorio central de Maven.
<dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-elasticsearch</artifactId> <version>1.2.0.RELEASE</version> </dependency>
6.1 Estructura general del proyecto
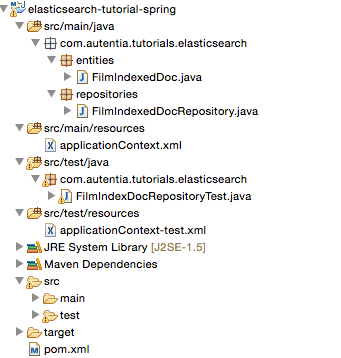
6.2 pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.foo.bar</groupId>
<artifactId>elasticsearch-tutorial-spring</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>elasticsearch-tutorial-spring</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<junit.version>4.11</junit.version>
<spring.version>4.0.0.RELEASE</spring.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>1.2.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
<exclusions>
<exclusion>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>${spring.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
6.3 applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch"
xsi:schemaLocation="http://www.springframework.org/schema/data/elasticsearch http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch-1.0.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd">
<elasticsearch:transport-client id="client" cluster-name="elasticsearch" cluster-nodes="127.0.0.1:9300"/>
<bean name="elasticsearchTemplate" class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="client"/>
</bean>
<elasticsearch:repositories base-package="com.autentia.tutorials.elasticsearch.repositories" />
</beans>
6.4 FilmIndexedDoc.java
A destacar, que el nombre de los atributos de clase deben coincidir con los nombres de las propiedades del mapping de los films indexados.
Debemos atender a los alias explicitados en la query de importacion: «filmTitle», «filmDescription». Además, el nombre del índice y el nombre del tipo también deben coincidir con el del script de importación
(«index» : «sakila_index_demo», «type» : «film_type»).
package com.autentia.tutorials.elasticsearch.entities;
import org.springframework.data.annotation.*;
import org.springframework.data.elasticsearch.annotations.*;
@Document(indexName = "sakila_index_demo", type = "film_type", indexStoreType = "memory", shards = 1, replicas = 0, refreshInterval = "-1")
public class FilmIndexedDoc {
@Id
private String id;
private String filmTitle;
private String filmDescription;
public FilmIndexedDoc() {
};
public FilmIndexedDoc(String id, String filmTitle, String filmDescription) {
super();
this.id = id;
this.filmTitle = filmTitle;
this.filmDescription = filmDescription;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getFilmTitle() {
return filmTitle;
}
public void setFilmTitle(String filmTitle) {
this.filmTitle = filmTitle;
}
public String getFilmDescription() {
return filmDescription;
}
public void setFilmDescription(String filmDescription) {
this.filmDescription = filmDescription;
}
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("FilmIndexedDoc [id=");
builder.append(id);
builder.append(", filmTitle=");
builder.append(filmTitle);
builder.append(", filmDescription=");
builder.append(filmDescription);
builder.append("]");
return builder.toString();
}
}
6.5 FilmIndexedDocRepository.java
Definimos una interfaz que extienda de la interfaz ‘ElasticsearchRepository’ indicándole el objeto y el tipo del campo ‘_id’. Esta interfaz contendrá las firmas de los métodos que Spring Data Elasticsearch utilizará para construir las queries de forma transparente utilizando la notación CamelCase para los atributos ‘filmTitle’ y ‘filmDescription’.
package com.autentia.tutorials.elasticsearch.repositories;
import java.util.*;
import org.springframework.data.elasticsearch.repository.*;
import com.autentia.tutorials.elasticsearch.entities.*;
public interface FilmIndexedDocRepository extends ElasticsearchRepository<FilmIndexedDoc, String> {
List<FilmIndexedDoc> findByFilmTitle(String filmTitle);
List<FilmIndexedDoc> findByFilmDescription(String filmDescription);
}
6.6. FilmIndexedDocRepositoryTest.java
Por último, definimos un test de integración para ver que todo funciona correctamente.
package com.autentia.tutorials.elasticsearch;
import java.util.*;
import javax.annotation.*;
import org.junit.*;
import org.junit.runner.*;
import org.springframework.test.context.*;
import org.springframework.test.context.junit4.*;
import com.autentia.tutorials.elasticsearch.entities.*;
import com.autentia.tutorials.elasticsearch.repositories.*;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:/applicationContext-test.xml")
public class FilmIndexDocRepositoryTest {
@Resource
private FilmIndexedDocRepository filmIndexedDocRepository;
@Test
public void shouldReturnListOfFilmsByTitle() {
List<FilmIndexedDoc> films = filmIndexedDocRepository.findByFilmTitle("casper");
Assert.assertTrue(films.size() > 0);
}
@Test
public void shouldReturnListOfFilmsByDescription() {
List<FilmIndexedDoc> films = filmIndexedDocRepository.findByFilmDescription("robot and a boy");
Assert.assertTrue(films.size() > 0);
}
}
7. Conclusiones
En este tutorial hemos visto la integración de Elasticsearch con Spring + MySQL. Para ello, nos hemos servido de la herramienta Elasticsearch Importer JDBC con la que hemos podido importar los datos de manera sencilla utilizando una query customizada a nuestras necesidades, y con la posibilidad de poder importar datos de cualquier fabricante de base de datos, siempre y cuando tengamos su conector JDBC. Para la integración con Spring, hemos utilizado la librería Spring Data Elasticsearch, la cual nos proporciona una serie de clases e interfaces templates para poder dedicar nuestro tiempo únicamente a los procesos de negocio de búsqueda en Elasticsearch.
Espero que este tutorial os haya servido de ayuda. Un saludo.
Daniel Rodríguez
Twitter: @DaniRguezHdez

