
Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Instalación
- 4. Creación de la configuración de Hibernate
- 5. Hibernate Console
- 6. Generando código a partir de la base de datos
- 7. revenge.xml el fichero de la “venganza” 😉
- 8. Conclusiones
- 9. Sobre el autor
1. Introducción
Hibernate (http://www.hibernate.org/) es una potente herramienta de persistencia que nos permite mapear clases en una base de datos relacional.
Hibernate Tools (http://tools.hibernate.org/) es un conjunto de utilidades para Ant (http://ant.apache.org/) y para Eclipse (http://www.eclipse.org/), que nos facilitan el uso de Hibernate.
En este tutorial vamos a ver como usar estas herramientas para hacer el esqueleto de una pequeña aplicación, de manera muy sencilla, generando código a partir de las tablas creadas en la base de datos. Gracias a esto podremos ahorrar bastante tiempo de desarrollo 😀
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil Asus G1 (Core 2 Duo a 2.1 GHz, 2048 MB RAM, 120 GB HD).
- Sistema Operativo: GNU / Linux, Debian (unstable), Kernel 2.6.21, KDE 3.5
- Máquina Virtual Java: JDK 1.6.0-b105 de Sun Microsystems
- Eclipse 3.2.2
- Hibernate 3.2.2.ga
- Hibernate Tools 3.2.0 Beta9
- MySql 5.0.41-2
3. Instalación
Para instalar las Hibernate Tools basta con ir a la página de descargas: http://www.hibernate.org/6.html y pinchar sobre el enlace “Download” de “Hibernate Tools”
Una vez descargado basta con descomprimirlo en el directorio del Eclipse (el mismo directorio donde se encuentra el ejecutable de Eclipse, por ejemplo, en Windows, eclipse.exe).
Si ahora arrancamos el Eclipse podemos comprobar, por ejemplo, que tenemos nuevas opciones en el asistente de creación (File -> New -> Other…)
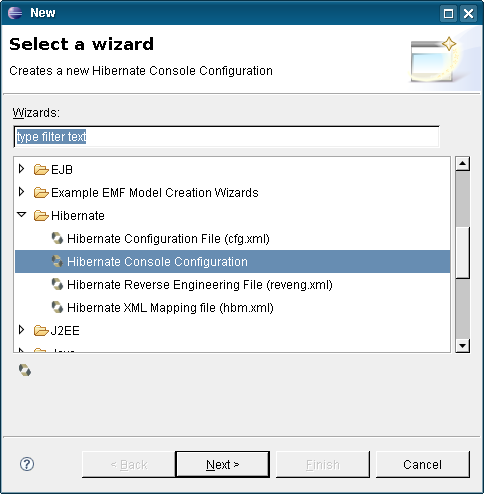
4. Creación de la configuración de Hibernate
Las Hibernate Tools nos proporcionan un asistente para crear el fichero de configuración de Hibernate (normalmentehibernate.cfg.xml).
En este fichero es donde describiremos como se debe conectar Hibernate a la base de datos, cuales son los ficheros xml que describen los mapeos entre las clases y las tablas de la base de datos, …
Para crearlo haremos: File -> New -> Other… -> Hibernate -> Hibernate Configuration File (cfg.xml)
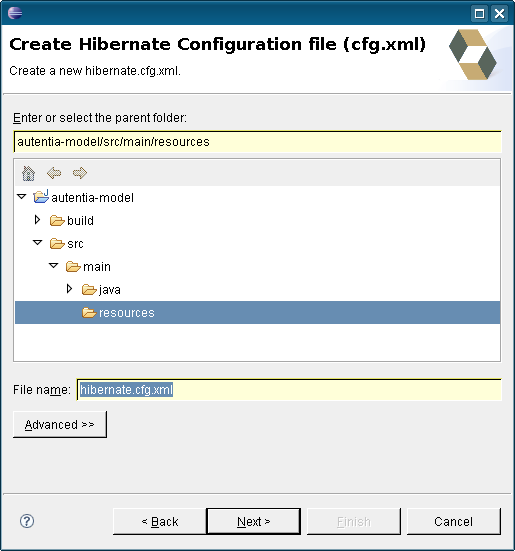
Le damos el nombre al fichero de configuración (normalmente hibernate.cfg.xml), e indicamos donde debe guardarlo. Deberá ser un directorio que en ejecución forme parte del classpath, para que la aplicación lo pueda localizar (si usamos Maven será el directorio src/main/resources).
Ahora indicamos el dialecto que debe usar Hibernate. El dialecto, básicamente, es el idioma que ha de hablar Hibernate con nuestra base de datos. También indicamos la clase del driver de acceso a la base de datos, la URL de conexión, el usuario y la password, … y en definitiva toda la información para que Hibernate se pueda concatenar correctamente a nuestra base de datos.
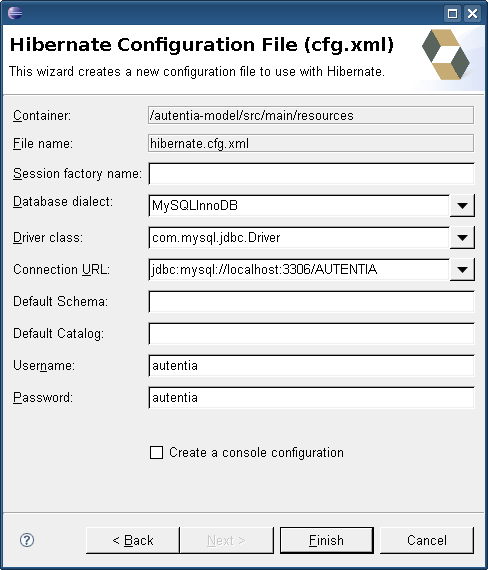
Cuando demos a “Finish” se creará el fichero, que tendrá un aspecto similar (según los datos introducidos en la pantalla anterior) a:
com.mysql.jdbc.Driver jdbc:mysql://localhost:3306/AUTENTIA autentia autentia org.hibernate.dialect.MySQLInnoDBDialect
5. Hibernate Console
Ahora vamos a crear la consola de Hibernate. La consola es el eje central de las Hibernate Tools, ya que cualquier otra operación que queramos hacer (generar código, lanzar sentencias HQL, …) dependerán de la configuración de la consola.
Para crear una nueva configuración de la consola de Hibernate hacemos: File -> New -> Other… -> Hibernate -> Hibernate Console
Indicamos el nombre que le damos a esta configuración, el proyecto asociado, y el fichero de configuración donde está configurada nuestra conexión. Este fichero es el típico fichero “hibernate.cfg.xml” de configuración de Hibernate. Indicaremos el fichero de configuración que hemos creado en el punto anterior:
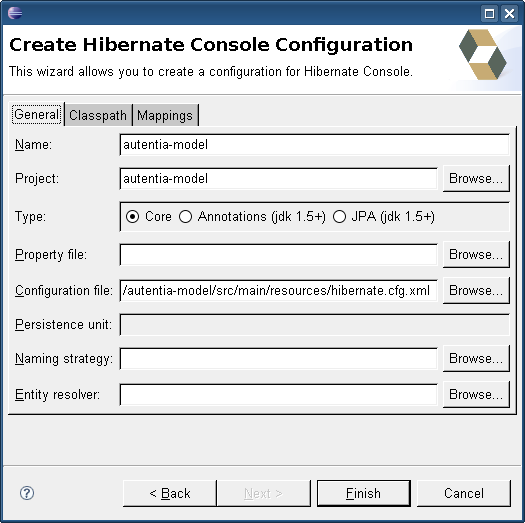
Antes de pulsar el botón “Finish”, pincharemos sobre la pestaña “Classpath”. Aquí vamos a indicar donde se encuentra el driver de la base de datos. Esto es muy importante, ya que de lo contrario las Hibernate Tools serán incapaces de conectarse con la base de datos.
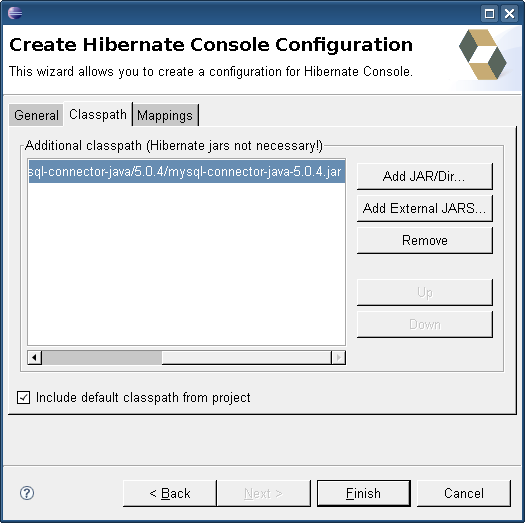
Nótese que también tenemos activado “Include default classpath project”. Esto es necesario para que las Hibernate Tools sean capaces de encontrar nuestros .class, por ejemplo para poder lanzar sentencias HQL.
Ahora ya podemos pulsar el botón de “Finish”.
6. Generando código a partir de la base de datos
Ya estamos preparados para generar código a partir de las tablas creadas en nuestra base de datos. Para ello pulsamos sobre el nuevo icono (apareció al instalar las Hibernate Tools) que tenemos en la barra de herramientas (en la imagen aparece enmarcado en un rectángulo rojo):
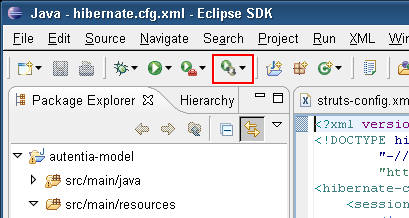
Al pulsar sobre el icono, deberemos seleccionar la opción “Hibernate Code Generation……”
Nos aparece una ventana, donde en su lado izquierda aparece una zona en blanco. Sobre ella hay una barra de herramientas, pulsamos sobre el primer icono “New launch configuration”. Y ahora rellenamos los datos de la zona de la derecha:
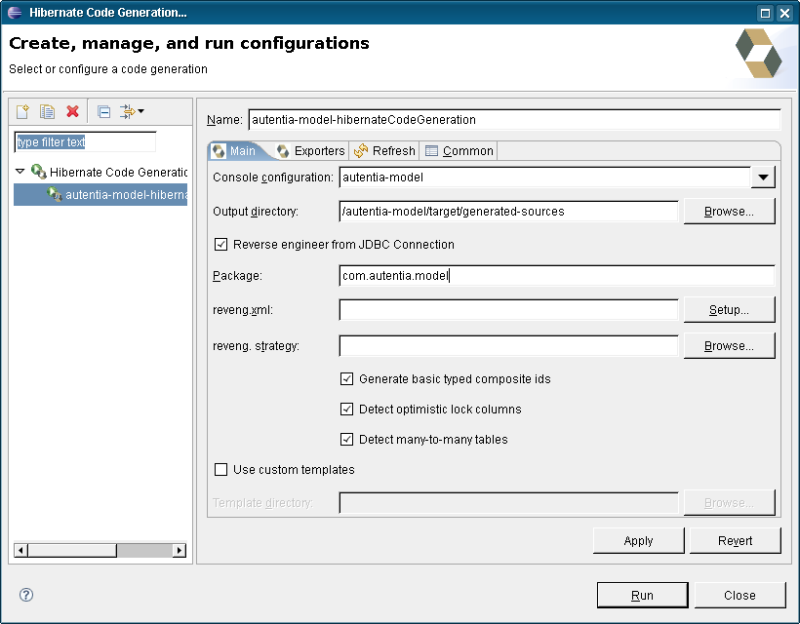
Lo que hemos hecho sobre la pantalla anterior:
- Le hemos puesto un nombre a esta nueva “launch configuration”.
- Hemos indicado el nombre de la configuración de consola que se debe utilizar (la que hemos creado en el punto anterior).
- Hemos indicado el directorio de salida para el código generado. Os recomiendo usar un directorio fuera de vuestro directorio de fuentes, para que no perdamos código por error (sobreescribamos algún fichero).
- Hemos marcado la casilla “Reverse engineer from JDBC Connection”. Esto es para generar las clases a partir de la información que tenemos en la base de datos. Ojo, si queremos que genera las relaciones entre las clases es imprescindible que la base de datos esté configurada con integridad referencial. Otro ojo, porque si usamos MySql las tablas deben estar creadas con InnoDB, si están creadas como MySam la información de integridad referencial entre las tablas no se tiene en cuenta.
- Y en general marcamos los check que nos interesan.
Ahora pasamos a la pestaña de “Exporters”. Cada “exporter” es capaz de generar algo diferente (clases java, ficheros de configuración, documentación, …). Marcaremos los que nos interesen. En la imagen de ejemplo se puede ver que hemos marcado “Domain code (java)” para generar los POJOs e “Hibernate XML Mappings (.hbm.xml)” para generar los ficheros de configuración xml donde se describe el mapeo entre las clases y las tablas de la base de datos.
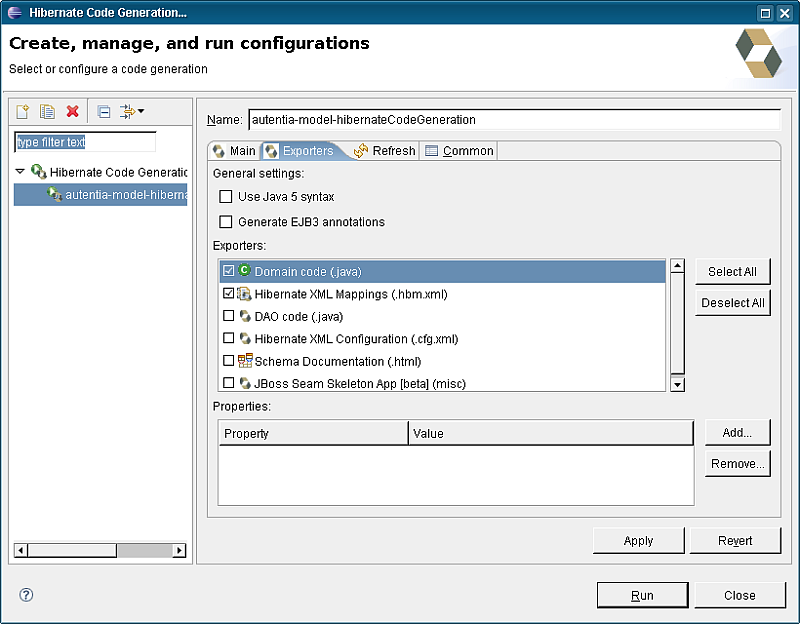
En esta misma pantalla de los “Exportes” tenemos otra dos opciones:
- Use Java 5 syntax: el código java generado usará la sintaxis List<Clase> para indicar el tipo de las colecciones.
- Generate EJB3 annotations: Genera POJOs anotados según el estándar de EJB3. Esto es una alternativa a los ficheros xml de mapeo, de forma que, mediantes estas anotaciones, en el mismo POJO es donde se indica como se debe mapear con la base de datos. Estas anotaciones además de evitarnos mantener esos xml, tienen la ventaja de que son compatibles con las anoraciones de la nueva especificación 3 de EJBs (podríamos convertir nuestros POJOs en EJBs de forma casi directa, o usar nuestros POJOs con la capa de persistencia de EJB3 en vez de con Hibernate).
Sólo podemos usar estas opciones si tenemos una máquina virtual 5 o superior. Si es el caso, os lo recomiendo, la primera para detectar en compilación posibles problemas de tipos, y el segundo sobre todo por escribir y mantener menos ficheros.
Ahora ya podemos al botón “Run” para generar el código.
7. revenge.xml el fichero de la “venganza” 😉
Si observamos el código generado en el punto anterior podemos ver dos cosas:
- Si nuestros identificadores en la base de datos son numéricos, los atributos correspondientes de los POJOs son tipos básicos (short, int, long).
- Las relaciones de integridad referencial en la base de datos se han convertido en asociaciones bidireccionales en las clases (es decir, si tengo una relación 1:n tendré una clase “foo” con un atributo que hace referencia a la clase “bar”, y en la clase “bar” tendré una lista de objetos de “foo”).
Estas dos situaciones no son siempre recomendables:
- En el caso de los identificadores es recomendable que siempre sean atributos nulables, de esta forma Hibernate es capaz de distinguir si la entidad ya existe en la base de datos o si se trata de una nueva entidad que habrá que añadir.
- En el caso de las relaciones, no siempre es necesaria esa bidirecccionalidad, de hecho, estas asociaciones bidireccionales son el caso menos frecuente, ya que solemos hacer la navegación siempre en un sentido (por ejemplo de un pedido saco la lista de productos, pero de un producto no saco la lista de todos los pedidos donde aparece).
Para refinar este tipo de cosas podemos hacerlo a mano o usar el fichero revenge.xml. El uso de este fichero es recomendable ya que nos permite regenerar las clases sin perder los cambios.
Para crear este fichero, sobre la primera pantalla que veíamos al configurar el “launch configuration” vemos que hay un campo “revenge.xml” con un botón “Setup…”. Pulsamos este botón.
Le decimos que queremos crear un nuevo fichero “Create new…”.
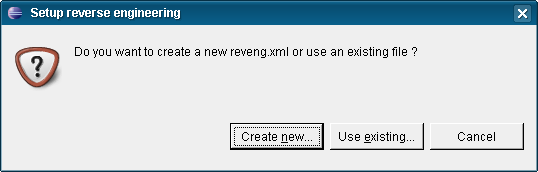
Indicamos donde se debe guardar el fichero (debería ser un directorio que luego quede fuera de nuestra distribución).
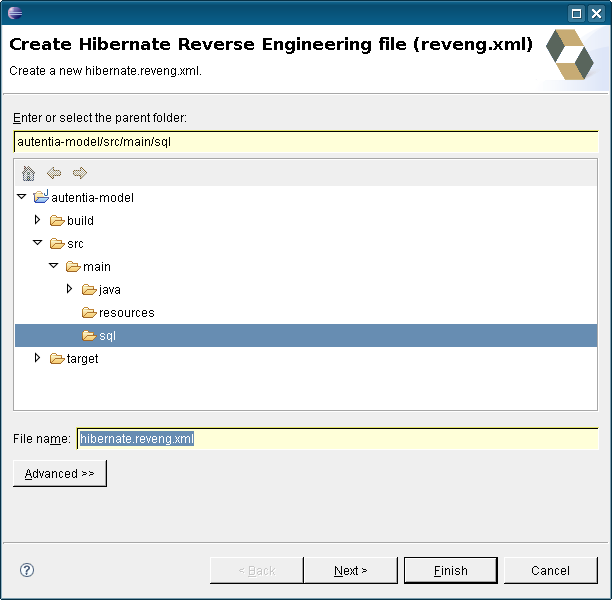
Ahora seleccionamos la configuración de consola que creamos anteriormente y pulsamos sobre el botón “Refresh”. Con esto nos aparecerá a la izquierda nuestro esquema de la base de datos con las tablas, esto nos permite seleccionar las tablas de las que queremos generar código (por defecto lo que hicimos en el punto anterior genera código para todas las tablas del esquema).
Marcamos las que nos interesan y pulsamos sobre “Include…”. Veremos como pasan al lado de la derecha.
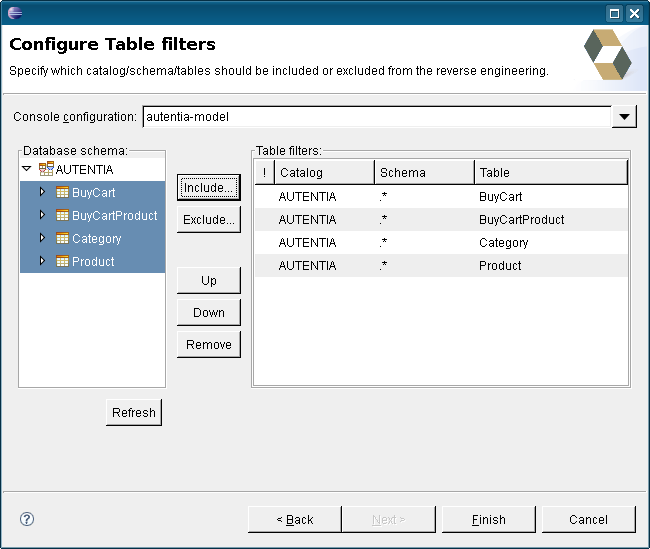
Pulsamos sobre “Finish” y volvemos a la pantalla de configuración de “launch configuration”. Podemos ver como ya aparece el nombre del fichero que acabamos de crear.
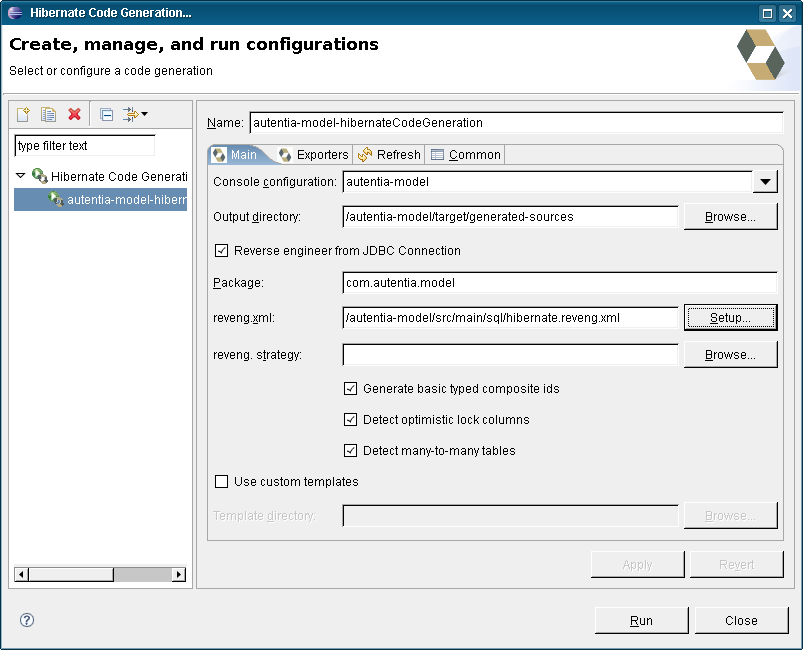
Ahora podemos localizar el fichero en nuestro explorador de paquetes de Eclipse y abrirlo. Veremos que nos aparece un editor específico, que nos permite, de forma más menos visual, modificar este fichero.
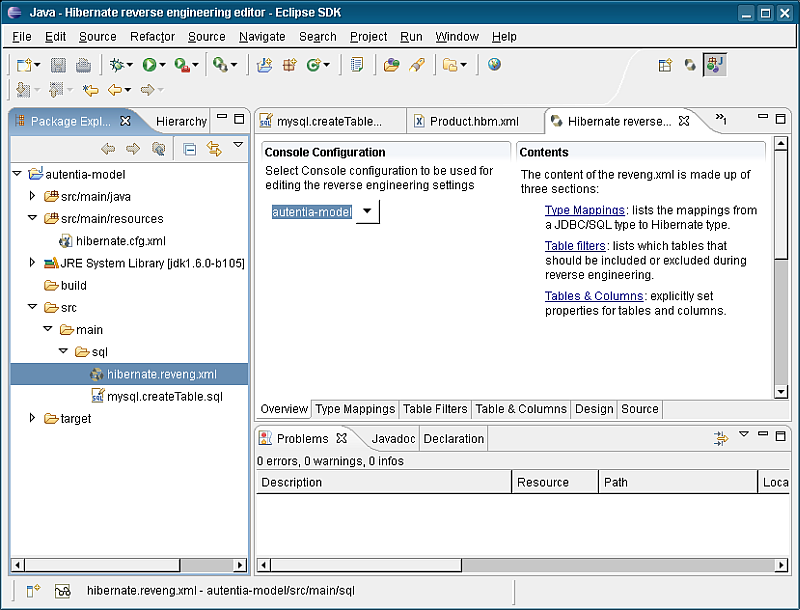
En la pestaña “Type Mappings” podemos indicar como se deben mapear las tipos de la base de datos con los tipos de Java. Por ejemplo, en esta sección podemos añadir un mapeo del tipo INTEGER de JDBC al tipo Java.lang.Integer de Java. Con esto solucionamos el tema de los identificadores numéricos, consiguiendo que sean nulables.
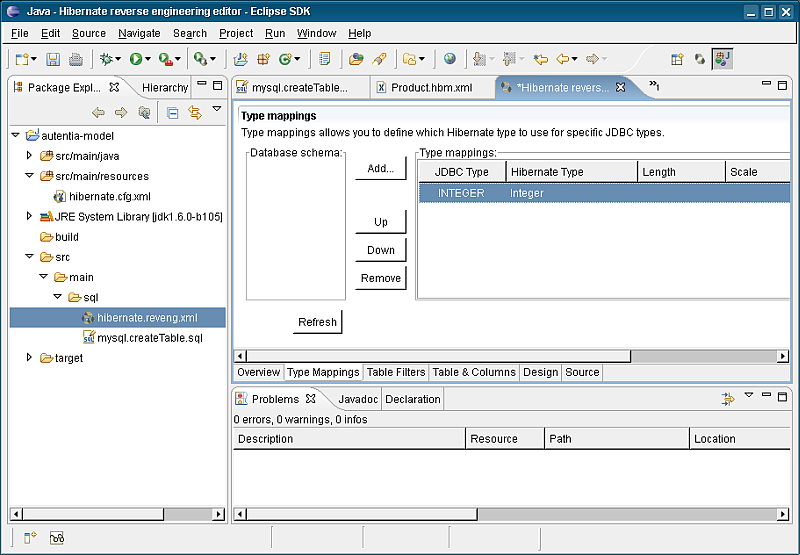
Si queremos que las relaciones de la base de datos no se conviertan en asociaciones bidireccionales, tendremos que modificar a mano fuente del fichero revenge.xml (lamentablemente las Hibernate Tools todavía no soportan hacer esto de forma visual). Para ello podemos pinchar sobre la pestaña “Source”.
Un ejemplo de fichero sería el siguiente:
Vemos como tenemos los mapeos de los tipos de datos, las tablas que se tienen que usar al hacer la ingeniería inversa, y luego como se tienen que hacer las asociaciones.
En el ejemplo hay una relación 1:n entre la tabla “Category” y “Product”. De forma que por defecto se nos creará un atributo en la clase “Product” que apunta a la categoría correspondiente, y en la clase “Category” tendremos una lista de todos los productos que tienen esa categoría. Lo que estamos haciendo en el ejemplo es que esta asociación sea unidireccional de forma que desde la clase “Product” podremos acceder a su categoría, pero desde la clase “Category” no podremos acceder a todos los productos.
Nótese que “fk_category_id” es el nombre de la “constraint” que hay en el campo de la tabla “Product” donde se guarda la clave ajena de la tabla “Category”. Mostramos el script de creación para aclarar este párrafo:
CREATE TABLE Category (id INTEGER UNSIGNED NOT NULL AUTO_INCREMENT,name VARCHAR(45) NOT NULL,description VARCHAR(255) NULL,PRIMARY KEY(id))engine=innodb default charset=utf8 collate=utf8_spanish_ci;CREATE TABLE Product (id INTEGER UNSIGNED NOT NULL AUTO_INCREMENT,categoryId INTEGER UNSIGNED NOT NULL,name VARCHAR(45) NULL,description VARCHAR(255) NULL,price INTEGER UNSIGNED NOT NULL,PRIMARY KEY(id),constraintfk_category_idforeign key (categoryId) references Category (id))engine=innodb default charset=utf8 collate=utf8_spanish_ci;
Ahora, gracias al fichero revenge.xml podemos volver a generar las clases, pero esta vez el resultado obtenido se ajustará mucho más a nuestras necesidades.
8. Conclusiones
En este tutorial hemos visto como podemos ahorrar tiempo de desarrollo gracias a las Hibernate Tools, ya que nos permiten generar gran parte del código necesario para el acceso a datos: los POJOs, los ficheros de configuración, …
El uso de Hibernate es muy recomendable para aislarnos de la base de datos y facilitarnos el acceso a la misma. Con herramientas como Hibernate Tools conseguimos facilitar mucho más el trabajo.
9. Sobre el autor
Alejandro Pérez García, Ingeniero en Informática (especialidad de Ingeniería del Software)
Socio fundador de Autentia (Formación, Consultoría, Desarrollo de sistemas transaccionales)
mailto:alejandropg@autentia.com
Autentia Real Business Solutions S.L. – “Soporte a Desarrollo”


En una segunda pasada, veo este enlace más interesante, especialmente el concepto de revenge.xml, que en el pasado no logré entender.
Esta muy bueno el tutorial, es puntual y practico, felicitaciones.
http://docs.jboss.org/tools/3.1.0.GA/en/hibernatetools/pdf/Hibernatetools_Reference_Guide.pdf Geniall Hibernate Tools para atacar a BD ya existentes. En mi opinión, muy útil.
Hola muy buenas, tengo un problema con el generador de tablas desde el eclipse, resulta que tengo en mi clase java(POJO) 4 campos (id, nombre, direccion, email) y cuando genero la tabla en MySQL me las genera ordenadas alfabéticamente (id, direccion, email, nombre) hay alguna anotación o alguna propiedad hibernate, que me mantenga la misma estructura de la clase java en la tabla de MySQL.
Excelente tutorial, me ha servido muchisimo!! Tengo una duda. ENtiendo muy bien lo de los POJO\\\’S, pero quisiera informacion sobre los siguiente: el mapeo de las tablas en la base de datos me genera lor archivos .java respectivos, las entidades, es decir los POJOS, con sus metodos getter y setter respectivos. Lo que deseo saber es… a estas clases basicas se les puede agregar algun otro metodo funcional. En mi caso por ejemplo deseo guardar los datos basicos sobre una entidad vehiculo y ya tengo el POJO generado para actualizar sus atributos basicos en la base de datos, pero obviamente esta clase necesita hacer algo, por ejemplo, moverse() o aumentar_velocidad(). Donde implemento estos metodos?. Si lo hago dentro del POJO, no representa ningun conflicto con Hibernate? . Tengo que utilizar herencia en mi codigo? Gracias
Muchas gracias; me ha resultado muy útil
hola buen tutorial
tengo una duda, yo tengo la version Hibernate Tools 3.5.1 en eclipse RCP, uso mysql como DBMS, lo que no se, es como veo si hibernate cuando genera el codigo a partir de la BD esta generando indices tambien?? por que veo mis archivos de POJO y xml y no veo por ningun lado anotaciones de index y no se si realmente hibernate esta usando los indices creados en las tablas??? aunque no esten las anotaciones, aun asi hibernate usa los indices de la BD??? soy nuevo en esto ayuda porfavor!!!!
Hola Arturo.
Digamos que las HibernteTools no son el Santo Grial ni el Bálsamo de Fierabrás. Es decir, pueden estar bien para hacerte el grueso del trabajo, pero mi recomendación sería que el ajuste fino lo hicieras tu personalmente. Es decir no puedes delegar la responsabilidad de tu aplicación en una herramienta de generación de código. Tienes que ajustarlo tu.
En cuanto a si Hibernate usa los índices de la BD, diría que no (por lo menos no en las consultas que lanza por defecto), es decir es la BD en función de la consulta que haces la que decide usar los índices (si estos están correctamente creados). Por eso de nuevo es importante que tengas claro como funciona tu app, que consultas haces, que índices son importantes, …
Siento no ser más concreto pero nadie dijo que esto fuera fácil.
En cualquier caso no te desanimes y estudia el comportamiento de tu app para afinarla (pruebas de rendimiento, análisis de las queries, … )
Hola.
He seguido tu tutorial, es muy práctico y muy bueno, pero he llegado a un caso al que no encuentro solución por ningún lugar.
Tengo un conjunto de 4 tablas, PRU1, y PRU2 tienen una relación N:N, con lo que tengo una tabla PRU3 con las claves de ambas tablas. Si luego quiero llevarme las claves de esta PRU3 hacia una PRU4, ¿Que manera sería la más óptima para que el hibernate tools me generase las entities? ¿Sería buena idea aplicar lo que explicabas sobre el fichero reveng.xml para deshacer la relación N:N entre esas dos tablas?
Un saludo
La verdad es que no sabría decirte ya que hace mucho que no uso esa herramienta así que no sé qué capacidades u opciones permite ahora.
Como recomendación general (hay que ver cada caso) te diría que aunque es posible no generes código a partir de las tablas. Hay que tener cuidado con estas cosas porque aunque en el corto plazo pueden suponer un ahorro de tiempo, se puede complicar la cosa en el medio largo plazo porque acoplamos mucho las capas. Si sólo estás usando este código generado en la capa de persistencia y siempre detrás de un «Repository» entonces no deberías tener mucho problema.
Suerte!