
En este tutorial vamos a desarrollar un API Rest usando Spark Framework y Spring para implementar el acceso a toda la capa de persistencia de datos.
Índice de contenidos.
- 1. Introducción.
- 2. Entorno.
- 3. Definición de la aplicación.
- 4. Creando el proyecto.
- 5. Levantando el contexto de Spring en nuestra aplicación.
- 6. Creando la capa de acceso a datos.
- 7. Configurando nuestros recursos REST con Spark.
- 8. Probando la aplicación.
- 9. Conclusiones.
1. Introducción
En el anterior tutorial Spark Framework, os presenté un nuevo framework Java con el poder desarrollar vuestras aplicaciones web de una manera sencilla y rápida.
Pues siguiendo con el anterior tutorial, en éste, os voy a enseñar cómo poder desarrollar un API Rest usando Spark y a su vez aprenderemos a inyectar el contexto de Spring dentro de nuestra aplicación y así implementar toda la capa de persistencia de la misma.
Puedes bajarte el código fuente de la aplicación que vamos a desarrollar pinchando aquí.
2. Entorno
El tutorial se ha llevado a cabo con el siguiente entorno:
- Hardware: MacBook Pro 15 pulgadas (2 Ghz Intel Core i7, 8GB DDR3)
- Sistema Operativo: macOS Sierra 10.12
- Java: Java 8
- Spark: Version 2.5.4
- IDE: Eclipse Neon
3. Definición de la aplicación
Para el este tutorial, lo que queremos es desarrollar una aplicación que consistirá en un API Rest que servirá para gestionar información sobre películas. De modo que tendremos 5 entradas en nuestro API:
- GET /movie – Consultar las películas de la base de datos.
- GET /movie/:id – Consultar una película. El ID de la misma vendrá informado dentro de la URL de la petición.
- POST /movie – Alta de una película. Los datos de la misma viajarán en formato json en el body de la petición.
- PUT /movie/:id – Modificación de una película. El ID de la misma vendrá informado dentro de la URL de la petición.
- DELETE /movie/:id – Borrado de una película. El ID de la misma vendrá informado dentro de la URL de la petición.
El estándar de intercambio de datos que vamos a usar será JSON. Por lo que será necesario usar algún provider para el mapping de datos. Para este ejemplo usaremos Jackson.
También queremos que los datos que maneja la aplicación se queden almacenados en una base de datos. Para ello vamos a embeber una base de datos HSQLDB en donde almacenar los datos de cada una de las películas.
Para el acceso a datos usaremos spring-jdbc por lo que será necesario inyectar el contexto de Spring en la aplicación desarrollada con Spark.
4. Creando el proyecto
Para la creación del proyecto usaremos maven. Si no lo tienes instalado o no sabes usarlo, es un buen momento para hacerlo.
Lo primero de todo será crear un proyecto vacío y después configurar el fichero pom.xml con todas las dependencias del proyecto. A continuación te dejo un fragmento del fichero pom.xml con las dependencias:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>2.5.4</spark.version>
<jackson.version>2.3.3</jackson.version>
<spring.version>4.2.0.RELEASE</spring.version>
<spring.data>1.10.5.RELEASE</spring.data>
<hsqldb.version>2.3.3</hsqldb.version>
</properties>
<dependencies>
<!-- spark -->
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-core</artifactId>
<version>2.5.4</version>
</dependency>
<!-- Jackson -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.5</version>
</dependency>
<!-- Spring Core -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- Spring Context -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- Spring JDBC -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- HyperSQL DB -->
<dependency>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
<version>${hsqldb.version}</version>
</dependency>
<!-- logging -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.21</version>
</dependency>
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.8.2</version>
<scope>test</scope>
</dependency>
</dependencies>
Como podéis ver, las dependencias a tener en cuenta en el proyecto serán las siguientes:
- spark-core: spark framework
- jackson: usado para el mapping de objetos json
- spring: dar soporte a acceso a la base de datos
- hsqldb: base de datos que vamos a embeber en nuestra aplicación
- slf4j: soporte para logging
- junit: desarrollo de test unitarios
Llegados a este punto, ya podemos empezar a desarrollar nuestra aplicación.
5. Levantando el contexto de Spring en nuestra aplicación
Como vamos usar Spring para poder acceder a base de datos, tenemos que configurar de alguna manera nuestra aplicación para que sea capaz de usar el contexto de Spring y de esa manera levantar los beans que nos permitirán acceder a la base de datos.
Como vimos en el anterior tutorial, Spark Framework, Spark se arranca a través del main() de nuestra aplicación. Al querer inyectar Spring en nuestra aplicación vamos a tener que cambiar un poco la forma de arrancarlo, de forma que sea Spring quien se encargue de arrancar Spark pasándole los beans que serán necesarios para poder acceder a la capa de datos.
Con Spring podemos crear beans mediante su definición en ficheros XML o a través de anotaciones en las clases Java. En el siguiente trozo de código usaremos @Configuration para indicar que la clase que contiene dicha anotación forma parte de la configuración de Spring.
Del mismo modo activaremos el escaneo de beans de la aplicación, para que Spring los instancie, a través de la anotación @ComponentScan.
Por últimno, la configuración de la aplicación es cargada por la clase AnnotationConfigApplicationContext que se encargará de levantar el contexto de Spring en nuestra aplicación. Dicha clase recibe por parámetro la/s clase/s que contiene/n la configuración de la aplicación.
@Configuration
@ComponentScan({"com.adictos.spark.movies"})
public class Application {
public static void main(String[] args) {
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(Application.class, DataBaseConfig.class);
new MoviesApplication(ctx.getBean(MoviesService.class));
ctx.registerShutdownHook();
}
}
Como podéis ver, será Spring quien arranque la aplicación desarrollada con Spark (MoviesApplication.java), pasándole al constructor de la misma la instancia del bean de la capa de servicios que desarrollaremos, que le permitirá acceder a la capa de datos.
Qué duda cabe, que para que podamos obtener la instancia del bean de servicio (MoviesService.class), la clase que lo implementa debe estar anotada con @Service para que Spring pueda instanciarla en el arranque de la aplicación y la añada al contexto.
@Service
public class MoviesServiceImpl implements MoviesService {
@Autowired
private MoviesRespository moviesRepository;
public Movie addMovie(Movie movie) {
return moviesRepository.addMovie(movie);
}
public void deleteMovie(Long id) {
moviesRepository.deleteMovie(id);
}
public Movie updateMovie(Movie movie) {
return moviesRepository.updateMovie(movie);
}
public Movie getMovie(Long id) {
return moviesRepository.getMovie(id);
}
public List getMovies() {
return moviesRepository.getMovies();
}
}
6. Creando la capa de acceso a datos
Como hemos dicho al principio, usaremos spring-jdbc para acceder a la base de datos. Para ello, primero será necesario configurar el DataSource que usaremos para crear la conexión con la base de datos.
Para crear el DataSource de la base de datos vamos a crear una clase anotada con @Configuration para indicarle a Spring la configuración.
Mediante la clase EmbeddedDatabaseBuilder podremos crear una base de datos embebida en memoria, en este caso HSQLDB. Y con @Bean inyectaremos el Datasource en el contexto de Spring para tenerlo disponible y accesible desde otros beans.
@Configuration
public class DatabaseConfig {
@Bean
public DataSource dataSource() {
EmbeddedDatabaseBuilder builder = new EmbeddedDatabaseBuilder();
EmbeddedDatabase db = builder.setType(EmbeddedDatabaseType.HSQL).setName("movies").addScript("ddl.sql").addScript("dml.sql").build();
return db;
}
}
Como se puede ver en el código fuente, el builder nos permite lanzar scripts tras la creación de la misma. En nuestro caso, vamos a crear la tabla MOVIE y vamos a cargarla con unos registros de ejemplo.
CREATE TABLE MOVIE(
ID INT PRIMARY KEY,
TITLE VARCHAR(255),
DIRECTOR VARCHAR(255),
YEAR INT,
SYNOPSIS VARCHAR(1024)
);
INSERT INTO MOVIE(ID, TITLE, DIRECTOR, YEAR, SYNOPSIS)
VALUES(1, 'How to train your dragon', 'Dean DeBlois, Chris Sanders', 2010, 'Hiccup (Jay Baruchel) is a Norse teenager ...');
INSERT INTO MOVIE(ID, TITLE, DIRECTOR, YEAR, SYNOPSIS)
VALUES(2, 'Interstellar', 'Christopher Nolan', 2014, 'In Earth''s future, a global crop blight and second Dust Bowl are...');
INSERT INTO MOVIE(ID, TITLE, DIRECTOR, YEAR, SYNOPSIS)
VALUES(3, 'Star Wars: The Force Awakens', 'J.J.Abrams', 2015, 'Thirty years after the defeat of the Galactic Empire, Han ...');
INSERT INTO MOVIE(ID, TITLE, DIRECTOR, YEAR, SYNOPSIS)
VALUES(4, 'The revenant', 'Alejandro González Iñárritu', 2016, 'While exploring the uncharted wilderness in 1823, ...');
Llegados a este punto, ya podemos crear nuestro repositorio, el cual se encargará de acceder a la base de datos. Para ello definiremos la interfaz del repositorio y anotaremos su implementación con @Repository para indicar a Spring que esa clase es la que se va a encargar de realizar el acceso a la base de datos.
Bastará con usar JdbcTemplate de Spring para poder acceder a la base de datos. Para ello, será necesario pasar en el constructor del repositorio la instancia del DataSource que acabamos de crear:
@Repository
public class MoviesRepositoryImpl implements MoviesRespository {
private static final String SYNOPSIS = "synopsis";
private static final String DIRECTOR = "director";
private static final String TITLE = "title";
private static final String YEAR = "year";
private static final String ID = "id";
private JdbcTemplate template;
@Autowired
public MoviesRepositoryImpl(DataSource ds) {
template = new JdbcTemplate(ds);
}
@Override
public Movie addMovie(Movie movie) {
final String query = "insert into movie(id, title, director, year, synopsis) values(:id, :title, :director, :year, :synopsis)";
final Map params = new HashMap();
params.put(ID, movie.getId());
params.put(TITLE, movie.getTitle());
params.put(DIRECTOR, movie.getDirector());
params.put(YEAR, movie.getYear());
params.put(SYNOPSIS, movie.getSynopsis());
template.update(query, params);
return movie;
}
@Override
public void deleteMovie(Long id) {
final String query = "delete from movie where id = :id";
final Map params = new HashMap();
params.put(ID, id);
template.update(query, params);
}
@Override
public Movie updateMovie(Movie movie) {
...
}
@Override
public Movie getMovie(Long id) {
...
}
@Override
public List getMovies() {
...
}
}
7. Configurando nuestros recursos REST con Spark
Hasta ahora no hemos hecho nada más que configurar Spring e implementar la capa de servicio y de datos. Lo que ahora toca es definir los distintos recursos REST y su implementación. Para ello vamos a usar Spark Framework.
Las recursos a definir serán los siguientes:
- GET /movie – Consultar las películas de la base de datos.
- GET /movie/:id – Consultar una película. El ID de la misma vendrá informado dentro de la URL de la petición.
- POST /movie – Alta de una película. Los datos de la misma viajarán en formato json en el body de la petición.
- PUT /movie/:id – Modificación de una película. El ID de la misma vendrá informado dentro de la URL de la petición.
- DELETE /movie/:id – Borrado de una película. El ID de la misma vendrá informado dentro de la URL de la petición.
public class MoviesApplication {
private static final String ID_PARAMETER = "id";
private MoviesService moviesService;
public MoviesApplication(final MoviesService moviesService) {
this.moviesService = moviesService;
initializeRoutes();
}
private void initializeRoutes() {
port(8080);
get("/movie", (req, res) -> {
return moviesService.getMovies();
}, new JsonTransformer());
get("/movie/:id", (req, res) -> {
final String id = req.params(ID_PARAMETER);
return moviesService.getMovie(Long.valueOf(id));
}, new JsonTransformer());
post("/movie", (req, res) -> {
final Movie movie = readBody(req.body());
return moviesService.addMovie(movie);
}, new JsonTransformer());
delete("/movie/:id", (req, res) -> {
final String id = req.params(ID_PARAMETER);
moviesService.deleteMovie(Long.valueOf(id));
return "";
});
put("/movie/:id", (req, res) -> {
final Movie movie = readBody(req.body());
return moviesService.updateMovie(movie);
}, new JsonTransformer());
}
private Movie readBody(final String jsonData) throws JsonParseException, JsonMappingException, IOException {
final ObjectMapper objectMapper = new ObjectMapper();
return objectMapper.readValue(jsonData, Movie.class);
}
}
¿Y ya está? Pues sí, con el código anterior acabamos de montar nuestro API REST en cuestión de 5 minutos. No tenemos que preocuparnos por el servidor, por la configuración de los servicios o por tener que definir ningún tedioso fichero XML. Spark lleva embebido un servidor Jetty que levantará en cuanto arranquemos la aplicación y de lo único que tendremos que preocuparnos es de probar nuestra aplicación 😉
Como el estándar de intercambio de datos debe de ser JSON, se hace uso de Jackson para la conversión de los objetos JSON a clases Java. Para ello, cada vez que el endpoint reciba datos JSON en el body de la petición, se hará una conversión a través de la clase ObjectMapper que nos proporciona Jackson.
private Movie readBody(final String jsonData) throws JsonParseException, JsonMappingException, IOException {
final ObjectMapper objectMapper = new ObjectMapper();
return objectMapper.readValue(jsonData, Movie.class);
}
Del mismo modo, las respuestas que debe dar nuestra aplicación deben ser de tipo JSON. Para ello, Spark nos permite indicar el tipo de conversor que se va a usar para para transformar los datos. Para ello será necesario implementar la interfaz ResponseTransformer en la cual se hará la conversión de datos:
public class JsonTransformer implements ResponseTransformer {
public String render(Object model) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
return objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(model);
}
}
8. Probando la aplicación
Para probar la aplicación, la arrancaremos a través del main() de la clase Application.java. Esta clase levantará el contexto de Spring y arrancará nuestro API REST en el puerto 8080.
Una vez hemos arrancado la aplicación, instalaremos un cliente REST en nuestro navegador para poder hacer pruebas. Yo tengo instalado en Chrome DHC, pero cualquier otro te servirá para hacer las pruebas.
Vamos a recuperar el listado de películas. Para ello introduce la siguiente URL ‘http://localhost:8080/movie’ y lanza una petición de tipo GET:

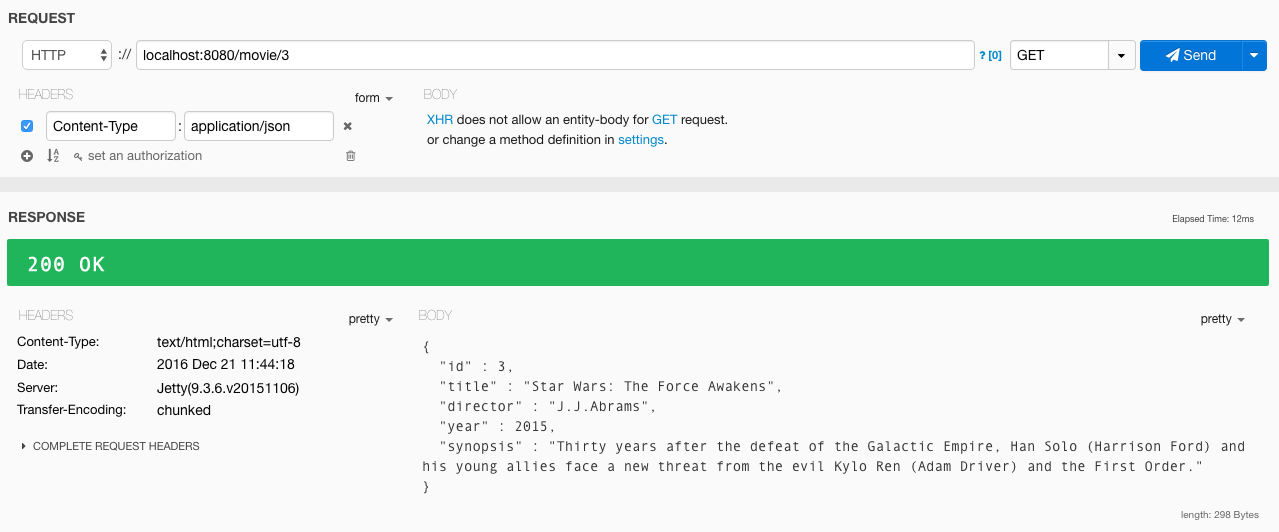
Vamos a probar a recuperar la película cuyo ID es el 3. Para ello lanza una petición de tipo GET a la siguiente URL: ‘http://localhost:8080/movie/3’
Probemos a actualizar una película. Bastará con lanzar una petición de tipo PUT a ‘http://localhost:8080/movie/1’, enviando en el body el json con los datos de la película:

9. Conclusiones
En este tutorial hemos visto cómo montar un API Rest es muy sencillo gracias a Spark. Gracias a que está basado en Java 8 y se apoya en el desarrollo de funciones Lambda, el código fuente es muy limpio, claro y conciso.
En este tutorial he querido ir un poco más allá e integrarlo con Spring para que veáis que el desarrollo no tiene porque estar 100% hecho con Spark. Podemos aprovechar las potencia de ambos frameworks y combinar su uso a nuestro gusto y necesidad.
Aunque el objetivo no era hablar de Spring, este ejemplo también te servirá para ver cómo inyectar el contexto de Spring dentro de una aplicación que no está 100% desarrollada con Spring y levantar el contexto sin ningún tipo de fichero XML basando la configuración en clases Java anotadas.
Espero que el tutorial os haya sido de utilidad.
Un saludo.


Excelente, pero creo que en Java las consultas nativas son malvadas y quiza se hubiera extendido un poco mas de haber utilizado algun ORM o mejor aun JPA
Algo raro, si estoy usando Spring para que me sirve Spark? podría tener el mismo resultado con rest template sin necesidad de mezclar framwork…
Seguir la línea de proyectos de Spring me parece más conveniente, lo digo por su popularidad y por la extensa documentación que existe en interne.
Hola Byron, gracias por tu comentario.
Por supuesto. Al fin y al cabo este es un artículo en el que os doy a conocer otros frameworks a parte de Spring.
Está claro que podemos hacerlo todo con Spring, todo sin Spring o mezclando frameworks. Eso ya depende de cada desarrollador y de las necesidades de cada uno.
Spark lo puedes ocupar como servidor