
Índice de contenidos
1. Introducción
Apache Spark es una herramienta para procesamiento en memoria de grandes cantidades de datos.
Suele ejecutarse sobre una arquitectura Hadoop y es muy útil que sea así sobre todo si el origen de datos está también en Hadoop como por ejemplo con HDFS o HBase.
En este tutorial vamos a ver cómo Spark ofrece un mecanismo de ejecución alternativo para que el procesamiento de los jobs se lance sobre PODs/contenedores de Kubernetes.
Este mecanismo creará dinámicamente los contenedores necesarios para la ejecución de los jobs y luego los destruirá.
Se puede beneficiar así de un gran ahorro de costes haciendo uso de un clúster de Kubernetes con autoescalado.
Para seguir este tutorial se recomienzan conocimientos básicos sobre Kubernetes y al menos saber la teoría básica sobre Apache Spark y para qué sirve.
Para aprender un poco de Kubernetes podéis seguir este tutorial.
Para aprender un poco de Apache Spark podéis seguir este otro tutorial.
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 15′ (2,2 GHz Intel Core i7, 16GB DDR3).
- Sistema Operativo: Mac OS High Sierra
- Entorno de desarrollo: Visual Studio Code
- Software: Apache Spark 2.3.1 y Minikube 0.28.0
3. Contexto
Vamos a utilizar el script de Spark «spark-submit» para lanzar los jobs de Spark. En este caso utilizaremos una opción que tiene para que el destino de ejecución sea un clúster de Kubernetes. Indicaremos al script la URL del API de Kubernetes y así dará la orden de crear un POD que será el «driver» de Spark. Este driver se encargará de crear los PODs executors y de sincronizar su trabajo. Una vez finalizado el trabajo el driver borrará los PODs executors y finalizará su ejecución correctamente.
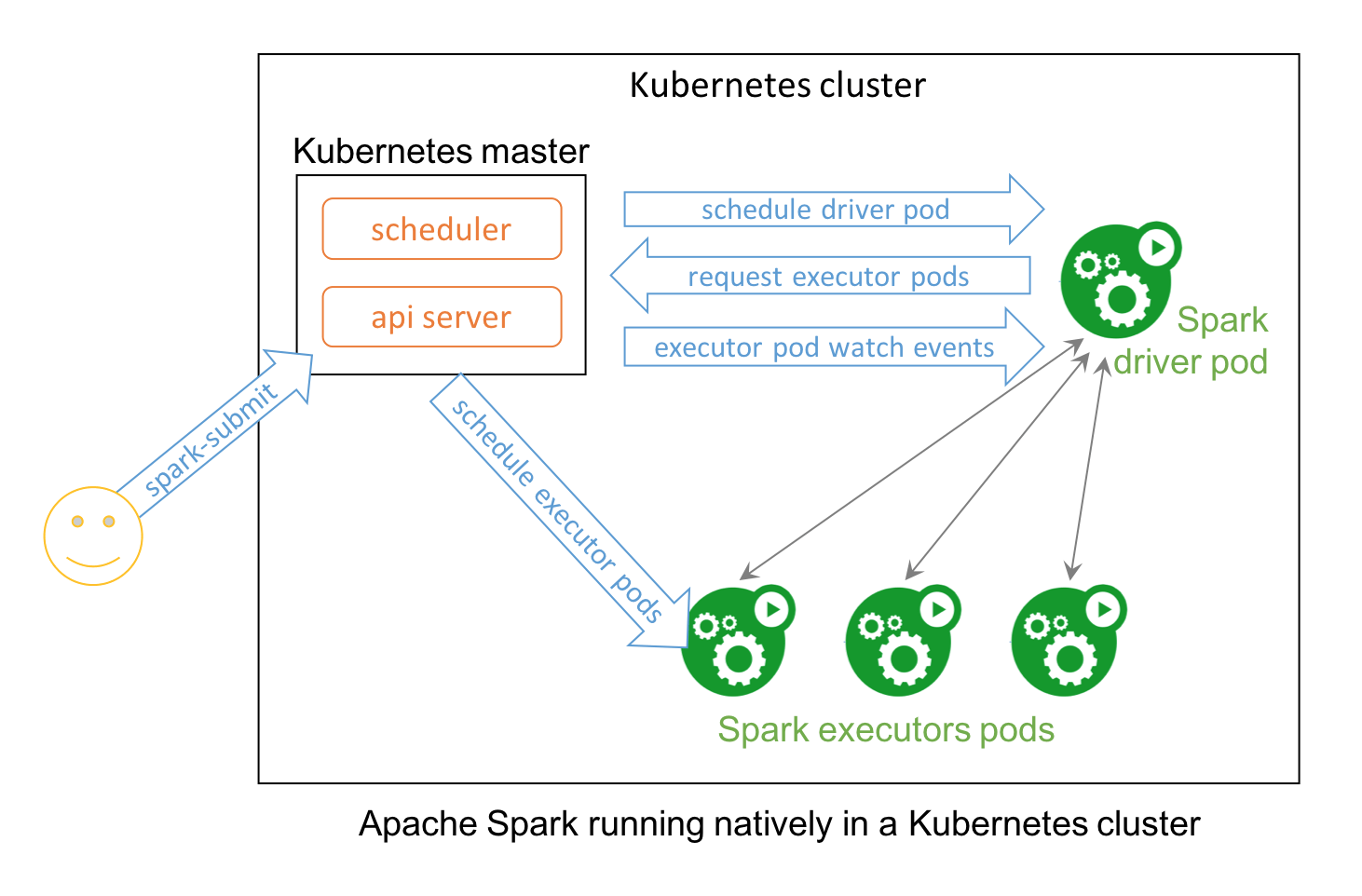
4. Instalación
Minikube
Necesitamos un clúster de Kubernetes con kubectl configurado para conectarse. En nuestro caso vamos a utilizar «minikube» para correr Kubernetes localmente sobre una máquina virtual.
Podéis ver más documentación sobra la instalación y uso de minikube en https://kubernetes.io/docs/setup/minikube/.
Una vez instalado lo arrancamos con:
> minikube start
Ahora tenemos la máquina virtual con Minikube arrancada y kubectl configurado para conectar con este clúster de Kubernetes.
Se puede, y es recomendable, incrementar desde VirtualBox algunos recursos de la máquina de minikube como procesador y memoria RAM.
Podemos ejecutar el comando «kubectl proxy» para habilitar el acceso desde la url http://localhost:8001/ui/ al dashboard de nuestro clúster.
En el clúster de Kubernetes deberá estar activo «kube-dns» y tener permisos para crear y listar PODs, configMaps y secrets. No deberías tener problemas con tu Minikube de serie.
Apache Spark
Si aún no tienes instalado Apache Spark tendrás que instalarlo. Este proceso dependerá de tu sistema operativo. Para MacOS suele utilizarse brew:
> brew install java scala apache-spark
No es objetivo de este tutorial centrarse en la instalación y utilización de Spark en general. Podéis encontrar mucha información en la documentación oficial https://spark.apache.org/docs/latest/
Preparación de la imagen de Docker
Primero vamos al directorio de instalación de Spark. Por ejemplo en mi caso es «/usr/local/Cellar/apache-spark/2.3.1/libexec».
Aquí tenemos las utilidades para crear nuestro contenedor de ejecución de Spark. El ejecutable de utilidad está en «bin/docker-image-tool.sh» y el dockerfile base en «kubernetes/dockerfiles/spark/Dockerfile».
Este Docker incluirá en su directorio /opt/spark/jars todos los jars de la carpeta «jars».
Vamos a modificar este fichero para incluir un jar de job de ejemplo, aunque este se podría también subir a un repositorio maven o pasárselo directamente con una url http. Para ello modificamos el dockerfile añadiendo la línea:
COPY examples/jars/*.jar /opt/spark/jars-examples/
Estando logados con Docker en un repositorio remoto (puede ser uno público como DockerHub) ejecutamos:
> docker-image-tool.sh -r mirepo -t latest build > docker-image-tool.sh -r mirepo -t latest push
Esto nos construirá y publicará una imagen con el nombre mirepo/spark:latest.
Si durante el proceso nos da el error ‘“docker build” requires exactly 1 argument’. Están solucionándolo pero si no tenéis la versión de Spark con el arreglo solo hay que modificar el fichero docker-image-tool.sh y añadir en la línea 59 «BUILD_ARGS=()».
5. Lanzando jobs
Spark Submit
Vamos a enviar a Kubernetes la orden de ejecutar un job para calcular un valor aproximado de PI (típico ejemplo que se usa para Spark).
Ejecutamos el siguiente comando:
spark-submit --deploy-mode cluster --name spark-pi --class org.apache.spark.examples.SparkPi --master k8s://http://localhost:8001 --conf spark.kubernetes.namespace=default --conf spark.executor.instances=2 --conf spark.kubernetes.container.image=mirepo/spark:1.0 local:///opt/spark/jars-examples/spark-examples_2.11-2.3.1.jar
Como vemos le hemos indicado el jar que está incluido en el Docker «local:///opt/spark/jars-examples/spark-examples_2.11-2.3.1.jar», pero esto podría haber sido una ruta http a un jar subido a algún servidor o un repositorio maven.
También le indicamos a Spark datos como:
- El nombre del job: –name spark-pi
- El nombre de la clase a ejecutar: –class «org.apache.spark.examples.SparkPi»
- La ruta del API del clúster de Kubernetes: –master «k8s://http://localhost:8001»
- El número de instancias a crear para la ejecución: «spark.executor.instances=2»
- La imagen de Docker a utilizar: –conf spark.kubernetes.container.image=mirepo/spark:1.0
¿Y qué está pasando ahora?. Spark ha creado un Docker de tipo «driver» como un POD de Kubernetes.
Este driver ha creado los executors indicados como PODs de Kubernetes y se ha conectado a ellos para ejecutar el código.

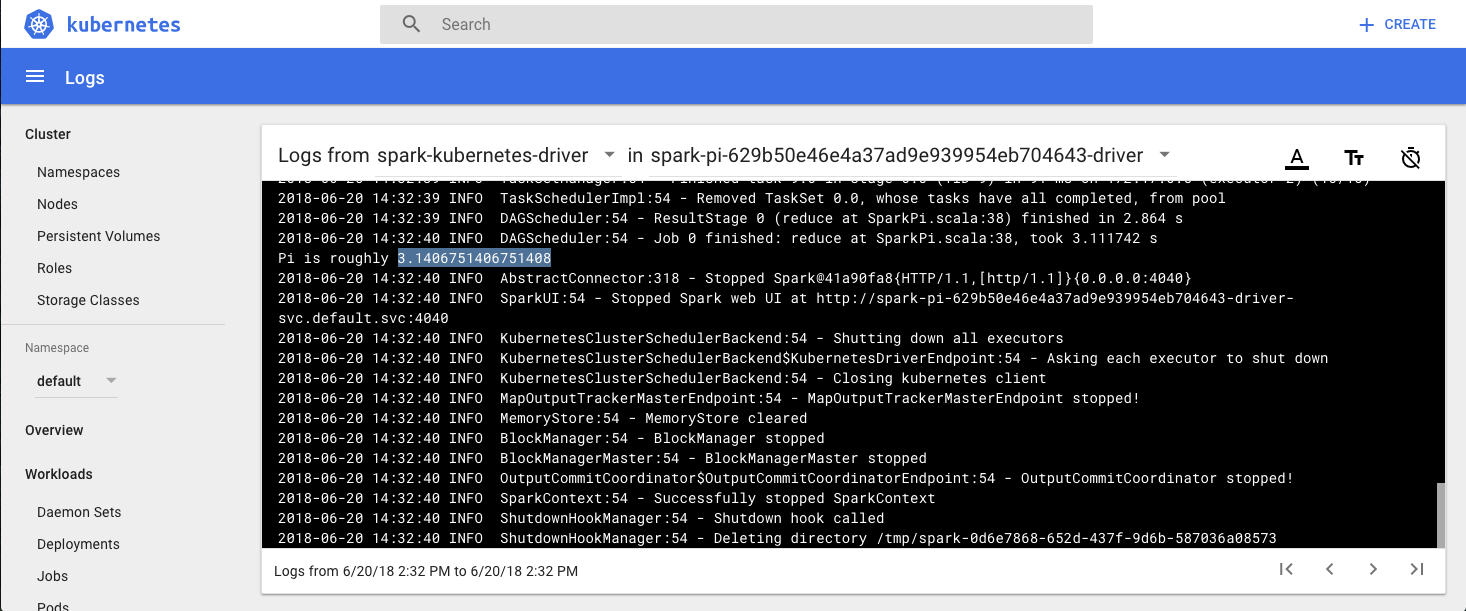
Cuando la ejecución del job se ha completado, el drive termina y limpia todo, pero el driver del POD en sí permanece en estado «Terminated: Completed» con los logs accesibles.

Podemos ver ahora los logs de esta tarea terminada y observaremos el cálculo que ha realizado el job para el valor de PI:
6. Conclusiones
Hemos visto como Spark permite aprovechar la potencia de procesamiento de un clúster de Kubernetes y puede ser una buena alternativa para ejecutar cargas de trabajo de Apache Spark.
Es muy útil si ya se cuenta con un la instalación de un clúster de Kubernetes y no se quiere instalar una nueva infraestructura distinta para Spark.

