
En este post exponemos una serie de alternativas al problema de compartir modelo de datos de las peticiones entre microservicios productores y consumidores.
Índice de contenidos
- 1. Introducción
- 2. Llamadas entre servicios: el caso de los microservicios
- 3. ¿Qué hacemos?
- 4. ¿Qué alternativa elegir?
- 5. Conclusión
- 6. Referencias
1. Introducción
Una de las tendencias más de moda en las arquitecturas backend a día de hoy son los microservicios. Básicamente donde antes teníamos una (o pocas) grandes aplicaciones que hacían de todo, llamadas monolitos, ahora tenemos varias (o muchas) pequeñas aplicaciones especializadas en un área específica de dominio, normalmente especificado según DDD (Domain Drive Design).
Como consecuencia de esta partición en pequeños microservicios, estamos sustituyendo las llamadas clásicas entre clases de Java en la misma JVM (si estás trabajando con Java, ¡que no es obligatorio!) por llamadas entre microservicios a través de sus APIs públicas. Por ejemplo:
- Microservicio de compras recibe una petición de compra del producto 123 por parte del usuario 987.
- El microservicio de compras llama a:
- microservicio de catálogo para saber los detalles del producto 123
- microservicio de usuarios para conocer los detalles del usuario 987.
- microservicio de medios de pago disponible y de descuentos con el importe.
En un monolito se hacen llamadas a los métodos correspondientes de clases que actúan como servicios. Son llamadas a nivel de código Java (o el lenguaje que sea), y no suele haber problemas por compartir o no las clases de modelo, ya que conforman un todo.
2. Llamadas entre servicios: el caso de los microservicios
Un microservicio sólo se puede comunicar con el exterior a través de su interfaz API pública. Si usamos cualquier otro medio no estamos independizando bien el diseño y no estamos haciendo microservicios correctamente.
Por centrar la explicación con el modelo típico y no atender a exotismos: la interfaz API pública típica es una interfaz REST con JSON. La situación habitual es que un microservicio reciba una petición REST a una URL que está publicando, lea el JSON de entrada (si es un POST, por ejemplo) y lo convierta a una estructura entendible por el lenguaje en el que está programando.
Si usamos Java, lo habitual será usar Jackson o Gson para parsear el texto en JSON y convertirlo en una serie de DTOs que contienen esa información, que posteriormente son consumidos por las capas inferiores. El mecanismo de emisión de la respuesta es el contrario: el core de la aplicación genera unos DTOs y con un parser son convertidos a una cadena JSON entendible por el cliente.
Cuando un microservicio de compras hace una petición al microservicio de catálogo para preguntar por un producto, lo hace a través de una interfaz REST, intercambiándose un JSON de este tipo:
{
"id":"123",
"marca":"Phillyps",
"modelo":"Jander",
"precio":"213€"
}
Para producir este JSON, debería tener un DTO para que el parser actuase. Este DTOs sería algo así:
public class Producto{
private int id;
private String marca;
private String modelo;
private float precio;
public Producto(int id, String marga, String modelo, float precio){
//Típico constructor
}
//Típicos getters
}
Tenemos claro, por diseño DDD,que esta información y por tanto este DTO debe residir en el microservicio de catálogo. Hasta aquí todo normal… Veamos ahora el "problema":
El microservicio que lee del microservicio de catálogo es el de compras. Y como mensaje recibe el JSON antes citado, y por tanto necesita de un DTO para interpretar estos datos en su lado. Recuerda que son dos microservicios independientes uno del otro, se decir, un .war cada uno, y por tanto de primeras no podemos hacer un "import" del DTOs del servicio que lo emite… ¿Qué hacemos con el DTO?¿Lo escribimos de nuevo en el cliente?¿Lo compartimos?¿Lo generamos automáticamente?
La cuestión no es baladí, y es posible que las primeras veces que trabajes con microservicios la intentes resolver de un modo tradicional, pero luego, a medio plazo puede que te hagas preguntas que te hagan plantearte el diseño y maldecir el momento en el que tomaste la decisión sin reflexionar mucho acerca del futuro.
3. ¿Qué hacemos?
Después de leer unos cuantos artículos y ver puntos de vista (algunos en las referencias), aún no tengo claro qué alternativa debería ser la protagonista: cada una tiene sus ventajas y desventajas, aunque tampoco querría poner todas al mismo nivel, porque sí que me parece que unas son mejores que otras.
Con la intención de intentar ver qué opinaba la comunidad, lancé una encuesta en Twitter con 4 alternativas, y que contestaron 38 personas, a buen seguro la mayoría con mayor capacidad que la mía:
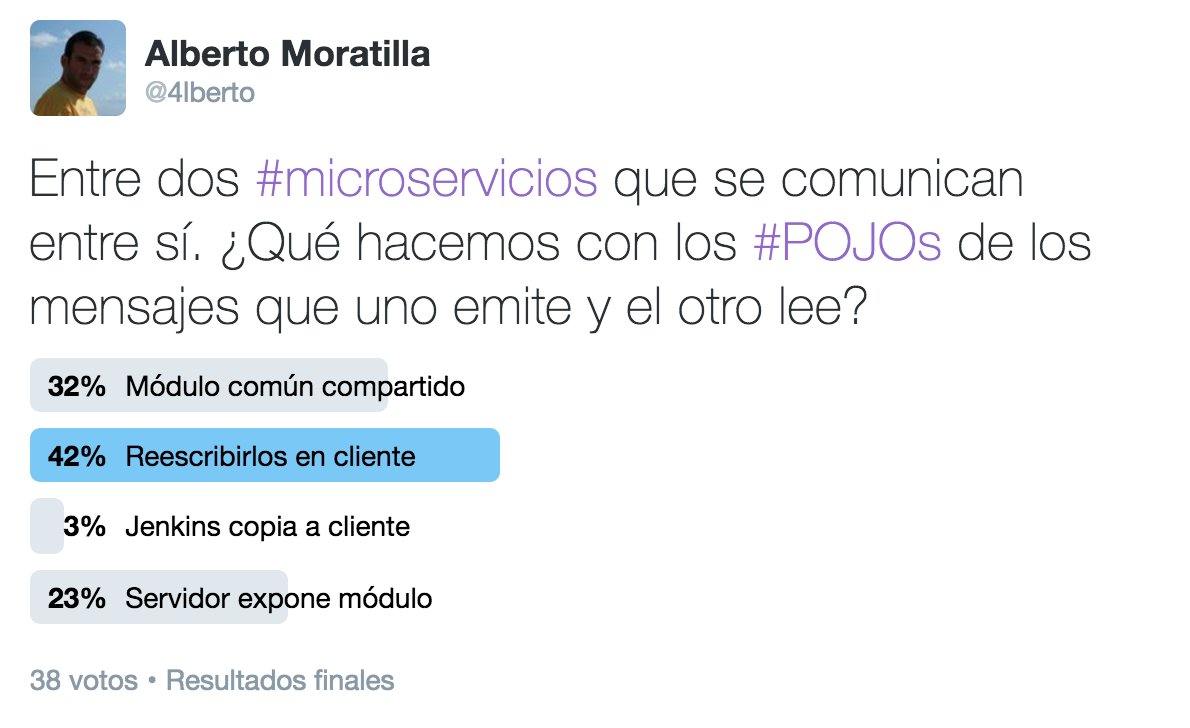
(Des)Afortunadamente, el resultado tampoco pareció concluyente bajo mi punto de vista, así que voy a intentar exponer las alternativas que he encontrado, con lo que creo que son sus puntos positivos y negativos para que puedas tomar una opinión:
Alternativa 1: No compartir nada.
Es la opción más purista y desde el punto de vista de los microservicios la que creo más correcta. Consiste en que cada microservicio se considera aislado de los demás (como debe ser) y no comparte los DTOs de la interfaz del API.
La consecuencia es que cada microservicio que acceda al microservicio de catálogo para obtener los datos del producto deberá implementar el DTO para así poder mapear el JSON a algo legible por las capas inferiores.
Pros:
- Independencia total entre microservicios. La situación ideal y que menos nos va a condicionar en el futuro.
- Es lo que haremos si no compartimos lenguajes entre microservicio productor y microservicio consumidor.
- Cada cliente puede consumir sólo la información que necesita, no toda.
Contras:
- Deberemos repetir la implementación en cada microservicio. Si comparten lenguaje, deberemos escribir (copiar el fichero está permitido ^_^) de nuevo el mismo DTOs n veces para los n clientes de ese microservicio.
- Un cambio en el DTO del productor obliga a editar n DTOs de los clientes (aunque debería ser una versión nueva del API). Pero quizá en realidad no todos porque alguno puede que no se vea afectado por el cambio al consumir estrictamente lo necesario (esto iría a los pros).
- No existe comprobación por parte del compilador ante un cambio del productor (nueva versión de API).
Dentro de esta alternativa, como opción exótica y un tanto descabellada, se podría incluir el proceso de copia desde los DTOs del servidor a los clientes a través de algún tipo de automatización en el sistema de integración contínua. Ya puestos a no escribir y copiar, que lo haga una máquina. Obviamente, esto no permitiría, al menos de forma sencilla, elegir qué atributos de los DTOs nos quedaríamos en cada servicio.
Alternativa 2: Que el servicio comparta en forma de paquete independiente su capa de DTOs de interfaz
Esta alternativa consiste en que el servidor separa en un subproyecto específico los paquetes de DTOs que forman la interfaz REST. Al final este subproyecto genera un archivo empaquetado que puede ser además utilizado por los clientes, por lo que se puede distribuir y establecer una dependencia.
Pros:
- Sólo se desarrolla una única vez los DTOs del servidor.
- No hay duplicidad de código: más fácil de mantener, especialmente los cambios.
- Nos aseguramos la perfecta coordinación con los clientes de los mensajes (versionado?).
- Podemos beneficiarnos de ciertos checks en tiempo de compilación al estar ligados servidores y clientes.
Contras:
- Existe un acoplamiento con el microservicio servidor más claro, ya que existe una dependencia específica sobre él (sobre el paquete de DTOs). Nos puede perjudicar en el futuro.
- Usamos un mismo paquete para dos propósitos: el del servidor y el del cliente, esto nos puede llevar a problemas.
- No se puede reutilizar si se emplean otros lenguajes en los clientes que no soportan el empaquetado que ha generado el servidor.
- Los clientes pueden estar accediendo a información que no les interesa, como atributos que forman parte del mensaje recibido pero que no utilizan.
Alternativa 3: El servidor publica un SDK/API para los cliente.
De este modo los microservicios de consumo incorporan esta API publicada por el servidor para acceder a sus servicios. Es parecida a la alternativa anterior, pero con la diferencia de que el servidor no utiliza en su implementación esta API, que además puede incluir más cosas además de los simples DTOs. Ya había pensado en una solución similar, pero que José Moreno me lo sugiriese como alternativa le da más validez a la alternativa 🙂
Pros:
- No duplicamos apenas código.
- Cierta independencia entre clientes y servidores al no acoplarse con un componente específico del servidor, sino a una especia de "Driver".
- Mantenemos los checks de compilació si hay algún cambio en la especificación del cliente.
- Podemos incluir ciertos aspectos específicos en el API cliente, como por ejemplo conectores o transformaciones específicas del mensaje si fuera necesario.
Contras:
- Debemos mantener una versión diferente por cada lenguaje que empleen los microservicios clientes. No es tan común cambiar de lenguaje de microservicios dentro de una misma arquitectura.
- Posible mayor desarrollo al poder incluir más que los DTOs y tener que pensar que es un SDK.
- Sigue sin ser una solución completamente desacoplada.
Alternativa 4: Usar algún tipo de IDL (Interfaz de definición de language)
Este concepto se daba de forma parecida en la época (¿pasada?) de las arquitecturas SOA y el SOAP, bueno, y de XML en general. Gracias a XML, Schemas y WSDL (WADL), son los propios servicios los que hacen una publicación del formato de mensajes que emitían los servicios, e incluso qué servicios estaban soportados. Gracias a ello, mediante herramientas automáticas de generación de código, como por ejemplo JAXB en Java, era posible generar los DTOs que podían manejar ese mensaje.
Cuando pensamos en términos de microservicios, solemos pensar en REST con JSON, aunque cada uno es libre de emplear el protocolo/tipo de mensaje que quiera (XML. Frente a los mensajes SOAP, REST con JSON es menos formal y más directo, por lo que no suele ser una prioridad contar con un esquema sobre el que validar la información transmitida.
No obstante esto no quiere decir que no existan iniciativas para poder describir un esquema de JSON sobre el que se pueda, además de validar y poder documentar el API, crear clientes de forma más o menos automática. Algunas de las opciones más importantes:
- JSON Schema para establecer un esquema de mensajes JSON que se puede utilizar para crear clases en el cliente usando por ejemplo: http://www.jsonschema2DTOs.org/ . Está respaldado por la IETF.
- Open API (antes Swagger) para la documentación de las API, en cuyos mensajes, además de metadatos, paths, o descripciones, se usa JSON Schema para especificar los mensajes JSON esperados. Es posible generar código a partir de la especificación usando herramientas como https://github.com/swagger-api/swagger-codegen
- RAML para la deescripcion de API que también tiene la capacidad de soportar los JSON Schema para la definición de mensajes, además de una nueva especificación en formato YAML. Podemos usar múltiples herramientas para generar código a partir de RAML, como https://github.com/mulesoft/raml-for-jax-rs
- API BluePrint: similar a las anteriores, también dispone de un ecosistema de herramientas como https://github.com/pksunkara/alpaca
Y en general cualquier otro sistema que aparezca para la documentación de API en el que se pueda llegar a generar código a partir de una especifcación.
Pros:
- Si tenemos (o estamos obligados) que documentar un API con alguna de estas herramientas, tenemos gran parte del trabajo hecho.
- De paso tendremos acceso a múltiples funcionalidades de estas herramientas, como la creacion de API mocks, facilidades para documentación, suites de test, validadores…
- Es independiente del lenguage del cliente: no es necesario "picar" unas clases por cada tipo de lenguage de cliente usado.
Contras:
- ¿A quién le gusta documentar API?
- ¿A quién le gusta mantener actualizada la documentación de las API?
4. ¿Qué alternativa elegir?
Si soy sincero no tengo claro cuál elegir, por eso he expuesto lo que creo que son los pros y los contras de cada una de las soluciones. Ya es cuestión tuya evaluar cuál es la que mejor se adapta a las circunstancias de tu proyecto de microservicios.
No obstante voy a mojarme y voy a dar mi punto de vista, seguramente equivocado sobre mis preferencias. Yo me quedaría con alguna de estas dos opciones:
- Alternativa 1: no compartir nada, es la que más beneficios nos va a aportar a medio y largo plazo, ya que es la que fuerza a una menor dependencia entre clientes y servidores. Pero en el día a día resulta bastante costosa.
- Alternativa 3: El servidor publica un API cliente, parece tener un cierto compromiso entre independencia y costes. Es reutilizable entre clientes y no establecer una dependencia explícita con el servidor, al no ser utilizado por este (al contrario que la Alternativa 2 de contar con un paquete común entre servidor y cliente).
Pero siempre tienes que tener en la cabeza las características del proyecto y sus posibilidades de evolución (que si usas microservicios será porque esperas que evolucione mucho ¿no?). La experiencia me indica que este tipo de decisiones se toman pensando en el próximo commit, pero luego se pagan dentro de 3 o 4 sprints.
5. Conclusión
Los microservicios presentan nuevos retos que no se daban en las arquitecturas monolíticas. Ahora las llamadas entre diferentes ámbitos de la aplicación transcienden más allá de la máquina virtual en la que se ejecuta el cliente, produciéndose llamadas entre API de diferentes microservicios. Esto obliga a que seamos cuidadosos a la hora de compartir código entre diferentes servicios que comparten algunos elementos del modelo de datos.
En este post hemos expuesto una serie de alternativas al problema de compartir modelo de datos de las peticiones entre microservicios productores y consumidores, exponiendo sus puntos fuertes y débiles para que el lector pueda tomar una decisión por sus propios medios, ya que parece que no existe un consenso establecido sobre cómo hacerlo.
6. Referencias:
Algunos artículos que considero interesantes sobre esta temática
- Don’t Share Code Between Microservices: https://www.infoq.com/news/2015/01/microservices-sharing-code
- Building Microservices: Inter-Process Communication in a Microservices Architecture: https://www.nginx.com/blog/building-microservices-inter-process-communication/
- CODE REUSE IN MICROSERVICES ARCHITECTURE – WITH SPRING BOOT: http://blog.scottlogic.com/2016/06/13/code-reuse-in-microservices-architecture.html
- The perils of shared code: https://www.innoq.com/en/blog/the-perils-of-shared-code/
- Sharing code and schema between microservices:
http://stackoverflow.com/questions/25600580/sharing-code-and-schema-between-microservices - Thoughts on Software Development Micro Services: The curse of code ‘duplication’. Muy interesantes los comentarios del debate, incluído el primero de Martin Fowler: http://www.markhneedham.com/blog/2012/11/28/micro-services-the-curse-of-code-duplication/


Creo que yo voté por la 2 :/ , será por que en mi antiguo trabajo teniamos un JAR con nuestra unidad de persistencia como dependencía de varios proyectos y funcionaba bien(¿?), obvio no eran microservicios y siempre pense que todo iba a ser en Java, por ahora estoy comenzando con los microservicios y recomende mucho que se desarrollara utilizando swagger por que vi que la documentación se generaba por arte de magia xD, pero parece ser que por el momento la documentación no es prioridad.
Excelente encuesta.
En el último Q&A de Adam Bien realicé exactamente la misma pregunta a lo que respondió tajantemente que los microservicios no deben jamás compartir DTOs entre si. Dejo el enlace (min 31:10):
https://youtu.be/O1VTx0psUgo
Alberto. Muy buen artículo. Pero como la respuesta me quedó un poco larga escribí esto: https://medium.com/@jomoespe/comunicaci%C3%B3n-entre-%C2%B5servicios-eab0cf134f8d#.sepc7owkh
🙂 OK !
GraphQL en toda llamada de los POJOs, de ese modo el cliente decide que campos quiere.
Para procesos mas estandar y con menos varianza, como por ejemplo un pago, Api rest con JSON
y para la consumir los microservicios deberían hacerse desde la UI, si es una operación transaccional y que debe manejar cierta lógica para controlar la transacción esa lógica seria un nuevo microservicios tipo hub o algo así, o queda en la UI
Buen artículo . Saludos
Buen artículo,
Pienso igual en las alternativas que has expuesto, pero hay un punto importante que es la que te hará decidir rápidamente y es que cuando el cliente dice que el tiempo de desarrollo del proyecto es corto, entonces tomarías la primera opción y replicar los DTOs de cada MS que use.
Creo que es la más acertada independiente de lo que expongo ya que el mismo JSON te aporta la estructura que necesitas. También es reponsabilidad del propietario del MS si hay cambios en el mismo, «deberá» crear versiones para no romper nada de los que ya implementan el MS y no necesitan cambios.
Gracias