
Partiremos de un ejemplo sencillo, importación de un fichero CSV, al que iremos completando y añadiendo funcionalidad a medida que nos hacemos preguntas: política de omisión, listeners, validaciones, registros múltiples.
Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. ¿Qué vamos a hacer?
- 4. Ejemplo básico: Importación fichero CSV
- 5. Esteroides: Mejorando el ejemplo
- 6. Conclusiones
- 7. Referencias
1. Introducción
Spring Batch provee funcionalidades esenciales para el procesamiento de grandes volúmenes de registros, logs, transacciones, procesamiento de estadisticas, omisiones, reinicio de procesos, etc. Los procesos por lotes, o batch processing requieren normalmente grandes cantidades de recursos. Son procesos costosos. Enfocaré este tutorial a la parte de procesado de ficheros, veremos qué se puede hacer y en gran parte cómo hacerlo.
El código de este artículo se puede encontrar en mi repositorio de GitHub.
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 15 (2 Ghz Intel Core I7, 8GB DDR3)
- Sistema Operativo: Mac OS El Capitan 10.11
- Entorno de desarrollo: Eclipse Mars
- Spring Batch 3.0.6
- Spring 4.2.5
3. ¿Qué vamos a hacer?
Partiremos de un ejemplo básico de importación de un fichero CSV al que iremos añadiendo funcionalidad poco a poco.
En primer lugar, resolveremos el asunto de la configuración de spring batch para esta importación sencilla, que va a extraer los datos de un CSV para posteriormente escribirlos por salida estándar.
Posteriormente, se introducirá una política de omisión de cara a ser más permisivo con los errores. Trataremos esos errores y diseñaremos algunas validaciones. Estas validaciones no serán de formato sino de lógica de negocio.
Finalmente, comentaremos algunos aspectos más que podemos tener en cuenta sobre formato del archivo a importar.
4. Ejemplo básico: Importación fichero CSV
4.1. Dependencias de Maven
pom.xml
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.2.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
<version>3.0.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<version>3.0.6.RELEASE</version>
</dependency>
</dependencies>
Necesitamos las clases de Spring Batch, la de contexto de Spring, y lo suficiente para ejecutar nuestros tests y probar rápidamente lo que vamos desarrollando.
4.2. Teoría rápida
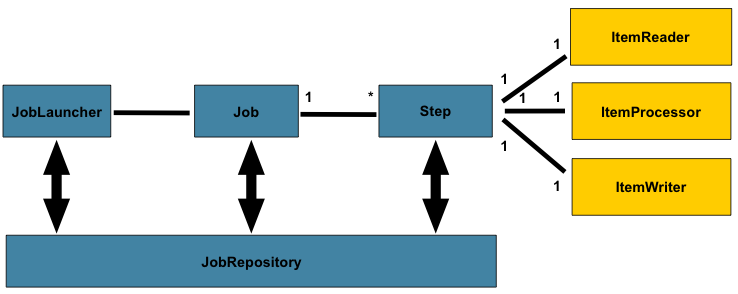
Antes de empezar con todo vamos a ver de forma muy general cómo funciona Spring Batch. Los Jobs son los bloques de trabajo, los procesos que se ejecutan. Como se puede apreciar en el diagrama de más arriba, un job puede tener uno o varios Steps o pasos, que contienen cada uno un único ItemReader, ItemProcessor e ItemWriter. Un Job necesita ser ejecutado o lanzado por un JobLauncher (el que usamos en los tests para probarlo por ejemplo). Los metadatos del proceso en ejecución necesitan guardarse en algún sitio, este lugar es el JobRepository. Demás conceptos los veremos sobre la marcha.
4.3. Fichero de contexto de Spring y Job
En el fichero de contexto vamos a declarar únicamente lo que necesitamos. Crearemos clases propias, por lo que tendremos que indicarle donde escanear nuestras clases. Usaremos un fichero de propiedades para indicar el fichero que usaremos.
Para poder probar de forma sencilla nuestro Job, declaramos como bean la clase JobLauncherTestUtils, que nos proporciona las herramientas para lanzar el Job rápidamente. Finalmente, declaramos el JobRepository y el JobLauncher lo más sencillos
posibles. En caso de querer usar una base de datos, por ejemplo para escribir en una base de datos en lugar de por pantalla los ficheros que importamos, se declararía en el transactionManager con la propiedad dataSource.
spring-batch-context.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.2.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.0.xsd">
<context:component-scan base-package="com.autentia.tutoriales.springbatch" />
<context:property-placeholder location="classpath:/config.properties" />
<bean class="org.springframework.batch.test.JobLauncherTestUtils" />
<bean id="jobRepository"
class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean">
<property name="transactionManager" ref="transactionManager" />
</bean>
<bean id="transactionManager"
class="org.springframework.batch.support.transaction.ResourcelessTransactionManager"/>
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>
</beans>
Lo siguiente es lo importante: concretar cómo vamos a importar los datos del fichero CSV.
job.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:batch="http://www.springframework.org/schema/batch"
xsi:schemaLocation="http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<batch:job id="importFileJob" job-repository="jobRepository">
<batch:step id="importFileStep">
<batch:tasklet>
<batch:chunk reader="employeeImporterReader"
writer="employeeImporterWriter"
commit-interval="5">
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>
<!-- Reader, destacar que se salta la línea de las cabeceras -->
<bean id="employeeImporterReader" class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="${file}" />
<property name="encoding" value="utf8" />
<property name="lineMapper" ref="employeeImporterMapper" />
<property name="linesToSkip" value="1" />
</bean>
<!-- Mapeo de cada fila del fichero -->
<bean id="employeeImporterMapper"
class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="fieldSetMapper" ref="employeeAutoFieldSetMapper" />
<property name="lineTokenizer">
<bean
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<property name="names"
value="name, lastName, age" />
</bean>
</property>
</bean>
<!-- Mapeo de campos y objeto a mapear -->
<bean id="employeeAutoFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper">
<property name="prototypeBeanName" value="employeeBean" />
</bean>
<bean id="employeeBean" class="com.autentia.tutoriales.springbatch.model.Employee"
scope="prototype" />
<!-- Writer -->
<bean id="employeeImporterWriter"
class="com.autentia.tutoriales.springbatch.writer.EmployeeImporterWriter" />
</beans>
En primer lugar declaramos el Job en sí, la importación. Sólo tiene un Step (un paso), el cuál únicamente tiene un chunk. Muy sencillo. En éste, declaramos que se va a usar un reader (el que lee el fichero) y un writer (el que maneja los datos que
hemos leído y procesado).
Como reader vamos a usar uno de los que proporciona Spring Batch para ficheros en texto plano, FlatItemReader, pero indicándole varios parámetros de configuración para adaptarlo a nuestras necesidades. Estos parámetros son: con qué recurso o fichero
va a trabajar, cuyo valor le indicamos mediante el fichero de propiedades. Usamos un encoding estándar, UTF-8, y mapearemos las líneas con el Mapper que indicamos un poco más abajo, pero saltándonos la primera línea del fichero (linesToSkip = 1), en
la que pondremos las cabeceras para hacer el fichero algo más legible.
Para el mapper (el encargado de convertir en objeto el String que lea) usamos uno por defecto, el DefaultLineMapper. Este se encarga de descomponer cada linea en los distintos campos(tokens) de los que está compuesto a través del Tokenizer. Estos
campos se delegan al FieldSetMapper.
Sabiendo esto, debemos indicar qué Tokenizer usar: como sabemos qué atributos va a tener nuestro CSV, le pasamos los campos directamente al DelimitedLineTokenizer (name, lastName y age). Para el FieldSetMapper, usamos uno genérico
(BeanWrapperFieldSetMapper) al que tendremos que indicar el tipo de objeto que queremos que nos rellene. En este caso la clase Employee. Un bean muy sencillo con 3 atributos, constructor y un método toString para la hora de pintarlo.
Para terminar con esta primera configuración del Job, indicamos cuál es el writer (que al principio hemos referenciado desde el chuck del step del job). Hemos creado una clase muy sencilla que implementa la interfaz ItemWriter para escribir los
objetos leídos por pantalla.
EmployeeImporterWriter.java
package com.autentia.tutoriales.springbatch.writer;
import java.util.List;
import org.springframework.batch.item.ItemWriter;
import com.autentia.tutoriales.springbatch.model.Employee;
public class EmployeeImporterWriter implements ItemWriter<Employee> {
@Override
public void write(List<? extends Employee> items) throws Exception {
for (Employee employee : items) {
System.out.println(employee.toString());
}
}
}
Para comprobar si hemos configurado todo correctamente, escribimos un test ayudándonos de la clase de utilidades que nos ofrece Spring Batch: JobLauncherTestUtils. A continuación podemos ver cómo:
JobLauncherIT.java
package com.autentia.tutoriales.springbatch.launcher;
import org.junit.Assert;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.test.JobLauncherTestUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = {"classpath:spring-batch-context.xml", "classpath:job.xml" })
public class JobLauncherIT {
@Autowired
JobLauncherTestUtils jobLauncherTestUtils;
@Test
public void shouldRunJob() throws Exception {
JobExecution jobExecution = jobLauncherTestUtils.launchJob();
Assert.assertEquals("COMPLETED", jobExecution.getExitStatus().getExitCode());
}
}
Si tenemos todo configurado correctamente, al ejecutar el test para los datos de prueba que indicamos a continuación, la salida por consola debería asemejarse a la siguiente.

Nuestros datos de prueba son los siguientes:
file.csv
Nombre,Apellidos,Edad Paco,Porras,15 Jesús,López,25 Eustaquio,Habichuela,56
Esto funciona muy bien incluso para cantidades grandes de registros. Sin embargo, ¿qué ocurre cuando un registro no está formateado correctamente? ¿Y si para el campo edad introduzco una letra? Cambiamos uno de los datos de nuestro CSV: «Jesús,
López,
a25«. Si ejecutamos el test veremos el temido color rojo, debido a un error al convertir ese campo.
Caused by: org.springframework.validation.BindException:
org.springframework.validation.BeanPropertyBindingResult: 1 errors
Field error in object ‘target’ on field ‘age’: rejected value [a25];
Lo peor es el momento en el que se nos informa de que el trabajo terminó con estado FAILED. Es decir, no terminó el Job, falló una vez se lanzó la excepción. En este momento es en el que conviene preguntarse si queremos que el Job siga trabajando.
Preguntarse si nuestro Job se puede permitir tolerar algún fallo, o incluso tratar ese fallo por otros medios.
5. Esteroides: Mejorando el ejemplo
5.1. Politica de omisión
Para los casos en los que queramos que el Job siga trabajando aun después de un fallo de ese calibre, podemos definir una política de omisión o SkipPolicy. Esta política se declara a nivel de Step, e indica si ante una determinada excepción el Job
puede seguir ejecutándose o, por el contrario, debe terminar. La forma rápida de configurar este tipo de política es mediante nuestro XML. Así pues, nuestro job va a aumentar en configuración de la siguiente forma:
<batch:job id="importFileJob" job-repository="jobRepository"> <batch:step id="importFileStep"> <batch:tasklet> <batch:chunk reader="employeeDataImporterReader" processor="employeeDataImporterProcessor" writer="employeeDataImporterWriter" commit-interval="5" skip-limit="2"> <batch:skippable-exception-classes> <batch:include class="org.springframework.batch.item.file.FlatFileParseException" /> </batch:skippable-exception-classes> </batch:chunk> </batch:tasklet> </batch:step> </batch:job>
Hemos establecido un límite de omisiones de forma que si falla más de 2 veces el Job termine, y que se omitan cualquier fila que produzca una excepción del tipo FlatFileParseException. La misma que tuvimos la última vez.
Si volvemos a ejecutar nuestro test para los mismos datos comprobaremos que sólo se muestran dos de nuestros tres registros del fichero CSV. ¿Qué pasa con el registro que ha fallado? ¿Nos olvidamos de él? ¿Le dejamos partir al monte del destino?
Deberíamos investigar la posibilidad de informar que, aunque se ha completado el Job, hay registros que se han quedado fuera. Entran en juego los listener
5.2. Listeners
Spring Batch nos permite acoplar listeners a diversos componentes en la aplicación, como a un Job, un Reader, Writer, Processor, o el caso que nos ocupa, un Skip (omisión). Viendo cómo hemos actuado en los casos anteriores, podéis deducir dónde vamos
a establecer los listeners: en el XML.
... <batch:chunk reader="employeeDataImporterReader" processor="employeeDataImporterProcessor" writer="employeeDataImporterWriter" commit-interval="5" skip-limit="20"> <batch:skippable-exception-classes> <batch:include class="org.springframework.batch.item.file.FlatFileParseException" /> <batch:include class="java.lang.IllegalArgumentException" /> </batch:skippable-exception-classes> <batch:listeners> <batch:listener ref="customSkipListener" /> </batch:listeners> </batch:chunk> ... <bean id="customSkipListener" class="com.autentia.kn.formacion.listener.CustomSkipListener" />
De esta forma asociamos un listener que nos hemos creado para aplicarle la lógica que deseamos al tratamiento de esas omisiones. Veremos a continuación que es muy fácil implementarlo. Es necesario implementar la interfaz SkipListener.
package com.autentia.tutoriales.springbatch.listener;
import org.springframework.batch.core.SkipListener;
import org.springframework.batch.item.file.FlatFileParseException;
public class CustomSkipListener implements SkipListener<Object, Object> {
@Override
public void onSkipInRead(Throwable t) {
StringBuilder message = new StringBuilder("ERROR en LECTURA: ");
if (t instanceof FlatFileParseException) {
message.append("Line ")
.append(((FlatFileParseException)t).getLineNumber())
.append(": Error de formato para la siguiente entrada: ")
.append(((FlatFileParseException)t).getInput());
} else {
message.append(t.getMessage());
}
System.out.println(message.toString());
}
@Override
public void onSkipInWrite(Object item, Throwable t) {
StringBuilder message = new StringBuilder("ERROR en ESCRITURA: ").append(t.getMessage());
System.out.println(message.toString());
}
@Override
public void onSkipInProcess(Object item, Throwable t) {
}
}
Usamos el listener únicamente para dejar constancia por consola de qué registros nos estamos saltando. Destacar que no usamos el método onSkipInProcess porque no usamos (aún) ningún processor.

De forma similar, podemos acoplar entre otros un listener a un Job implementando la interfaz JobExecutionListener. Esta interfaz nos permite introducir nuestra lógica antes o después de la ejecución del Job. Recordar que éstos son sólo algunos de los
listeners que ofrece Spring Batch.
La ejecución de un Job con un listener asociado sería algo así:

La siguiente mejora está relacionada con la integridad de nuestros datos. Ahora mismo, si dejamos el nombre en blanco, el Reader nos asignará al nombre del empleado NULL. La pregunta llegados a este punto es: ¿permitimos valores nulos? ¿hay algún
campo que sea obligatorio?
5.3. Procesado: Validaciones
Mediante la adición de un processor en nuestro Job, agregaremos un paso más que se encargará de procesar los datos una vez han sido leído, pero antes de ser escritos. El processor se dedica a dictaminar qué registros son aptos de los que, a priori,
no tienen ningún fallo de formato.
Para este menester, vamos a crearnos nuestro propio processor, que implementará la interfaz ItemProcessor, en la que se especifica qué objeto entra y qué objeto sale. Como no vamos a transformar nuestro objeto sino sólo validarlo, en este caso será
el mismo.
En el procesado validamos el objeto que nos llega del reader. Si el objeto es válido, se lo pasamos al Writer. Si no es válido, tenemos que descartarlo. Queremos que nuestro empleado siempre tenga nombre y apellidos, así que vamos a asegurarnos de
que siempre nos lleguen esos dos parámetros. De lo contrario descartaremos u omitiremos ese registro.
Para descartar u omitir un objeto tenemos dos posibilidades. La primera es retornar NULL como valor, de tal forma que no se le llega a pasar al Writer. La otra opción es lanzar la excepción que creamos conveniente y la consideremos en nuestra
política de omisión como excepción que desencadene una omisión.
package com.autentia.tutoriales.springbatch.processor;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.util.Assert;
import com.autentia.tutoriales.springbatch.model.Employee;
public class EmployeeImporterProcessor implements ItemProcessor<Employee, Employee>{
private static final String NAME_MESSAGE = "el NOMBRE";
private static final String LAST_NAME_MESSAGE = "los APELLIDOS";
@Override
public Employee process(Employee readEmployee) throws Exception {
checkRequiredFields(readEmployee);
return readEmployee;
}
private void checkRequiredFields(Employee employee) {
Assert.hasLength(employee.getName(), requiredFieldError(NAME_MESSAGE, employee));
Assert.hasLength(employee.getLastName(), requiredFieldError(LAST_NAME_MESSAGE, employee));
}
private String requiredFieldError(String requiredFieldText, Employee employee) {
StringBuilder sb = new StringBuilder();
sb.append(": Es necesario %s en empleado. ");
sb.append(employee.toString());
return String.format(sb.toString(), requiredFieldText);
}
}
Como veis, en ese caso hemos optado por lanzar excepciones, concretamente IllegalArgumentException, que es la que lanza el Assert que nos proporciona Spring. Por ello debemos incorporar esa excepción a las que provocan una omisión en la configuración
XML del Job. Además, deberemos definir el bean del processor y asignarlo al chuck del Job de la misma forma que asignamos el reader y el writer. El XML quedaría así:
<batch:job id="importFileJob" job-repository="jobRepository"> <batch:step id="importFileStep"> <batch:tasklet> <batch:chunk reader="employeeImporterReader" processor="employeeImporterProcessor" writer="employeeImporterWriter" commit-interval="5" skip-limit="2"> <batch:skippable-exception-classes> <batch:include class="org.springframework.batch.item.file.FlatFileParseException" /> <batch:include class="java.lang.IllegalArgumentException" /> </batch:skippable-exception-classes> <batch:listeners> <batch:listener ref="customSkipListener" /> </batch:listeners> </batch:chunk> </batch:tasklet> </batch:step> <batch:listeners> <batch:listener ref="customJobListener" /> </batch:listeners> </batch:job> ... <bean id="employeeImporterProcessor" class="com.autentia.tutoriales.springbatch.processor.EmployeeImporterProcessor" />
Con eso terminado, si hacemos una prueba con nuestro CSV quitando uno de los nombres de empleado, nos sucederá algo parecido a lo siguiente si añadimos en nuestro SkipListener onProcess la impresión del error por consola:

Lógicamente, las validaciones que hagamos pueden ser todo lo complejas que la lógica de la aplicación requiera. En este caso el comprobar si el campo está o no ilustra bien las validaciones.
Si bien, algo chirría un poco. El mensaje de procesado sería mucho más legible si se indicase el número de línea en el que nos está faltando el nombre por ejemplo. Una forma de solucionarlo es implementar nuestro propio FieldSetMapper extendiendo de
alguno de Spring Batch, como el BeanWrapperFieldSetMapper que estamos usando, y añadir de alguna forma el número de línea en el método mapFieldSet. En mi caso añadía el propio número al objeto empleado.
5.4. Líneas en blanco y últimos comentarios
Otro posible cambio que nos podemos proponer tiene sentido si queremos flexibilizar aún más el formato. ¿Los registros van a ir una linea tras otra o vamos a encontrarnos líneas en blanco? Tal y como está ahora, una línea en blanco se puede considerar un error de formato, de lectura.
Para atajar esta problemática debemos adaptar otra de las políticas configurables en Spring Batch. La política de separación de registros (RecordSeparatorPolicy), que es la que indica cuándo termina un registro. La política que estamos usando es la más simple que hay: cada línea es un registro. Modificando levemente esta conducta conseguimos extender un registro si hay una linea en blanco. Dicho de otro modo, un registro no acaba si una hay una línea en blanco después. Resolvemos esto extendiendo de la clase SimpleRecordSeparatorPolicy, que implementa la interfaz RecordSeparatorPolicy. En nuestra clase le vamos a indicar lo que hemos comentado: si hay una línea en blanco no se termina el registro.
ackage com.autentia.kn.formacion.separator;
import org.springframework.batch.item.file.separator.SimpleRecordSeparatorPolicy;
public class SkipBlankLinePolicy extends SimpleRecordSeparatorPolicy {
@Override
public boolean isEndOfRecord(String line) {
if (line.trim().length() == 0) {
return false;
}
return super.isEndOfRecord(line);
}
@Override
public String postProcess(String record) {
if (record == null || record.trim().length() == 0) {
return null;
}
return super.postProcess(record);
}
}
En el postprocesado descartamos la línea. Después de tener nuestra política implementada, la asociamos a nuestro reader para que éste la tenga en cuenta y ¡a probar!
<bean id="employeeDataImporterReader" class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="${bulkload.input.file}" />
<property name="encoding" value="utf8" />
<property name="lineMapper" ref="employeeDataImporterMapper" />
<property name="linesToSkip" value="1" />
<property name="recordSeparatorPolicy" ref="skipBlankLineRecordSeparatorPolicy" />
</bean>
<bean id="skipBlankLineRecordSeparatorPolicy"
class="com.autentia.kn.formacion.separator.SkipBlankLinePolicy"/>
Esta última apreciación abre la puerta a los registros que ocupan varias líneas o incluso registros compuestos de varios objetos que se tienen que mapear de forma independiente. Con el fin de solucionar esto último, Spring Batch proporciona PatternMatchingCompositeLineMapper. La clase mapea las líneas en función de patrones que nosotros le indiquemos, de tal forma que si el formato de nuestro fichero es una línea empleado y la inmediata el puesto que ocupa junto a otros datos, así se lo indicamos a este LineMapper. El LineMapper detectará este patrón e insertará esos registros en objetos diferentes según corresponda.
6. Conclusiones
Nos encontramos ante un framework con muchas posibilidades, la mayoría de ellas sin explorar en este tutorial. Un buen ejemplo de ello lo tenemos en la forma de tratar la información que importamos del fichero CSV. En vez de mostrarla por pantalla, podemos guardarla a través de un Logger. Incluso la podemos guardar en una base de datos llamando al repositorio correspondiente, que sería lo normal en caso de un Writer para una importación masiva de datos: según va leyendo va insertando en base de datos, etc.
No temáis en hincarle el diente, su documentación es estupenda.


Como ejecutas el Test Para JobLauncherTestIT?