

En este tutorial vamos a realizar tests de aceptación en un entorno spring usando cucumber y junit5.
Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Tests de aceptación
- 4. Gherkin
- 5. Cucumber
- 6. La aplicación
- 7. Conclusiones
- 8. Referencias
1. Introducción
Tenemos tutoriales de TDD, BDD y Test de aceptación aquí, BDD con Cucumber aquí, ejemplos de Serenity y Cucumber aquí y un excelente tutorial de BDD y microservicios con Spring Boot aquí. En este nuevo tutorial intentaremos actualizar los anteriores para tener tests de aceptación con Cucumber y Junit 5, no centrándonos en la metodología BDD y dar un enfoque distinto.
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil Lenovo t480 (1.80 GHz intel i7-8550U, 32GB DDR4)
- Sistema Operativo: elementary OS 6.1 Jólnir base: Ubuntu 20.04.3 LTS Kernel: Linux 5.15.0-46-generic x86_64 bits
- Entorno de desarrollo: IntelliJ IDEA 2022.2 (Ultimate Edition)
- Apache Maven 3.8.6
- Java version: 17.0.4, vendor: Eclipse Adoptium
3. Tests de aceptación
El testing es algo que me gusta porque me ayuda a dormir mejor por las noches, si bien los tests no son garantía de que algo funciona, nos dan una sensación (más o menos real) de seguridad. Los tests de aceptación es algo que me parece muy idealista, ya que implican a los desarrolladores y a negocio. Los desarrolladores tienen que estar siempre ahí, porque son los que hacen el software, producto suele estar a más cosas y no suele involucrarse en escribir tests, pero, si tenemos la suerte de que se involucra, nos viene bien conocer este tipo de testing y sacarle el máximo partido.
3.1 Definición
Según la Agile Alliance, una prueba de aceptación es una descripción formal del comportamiento de un software usando un ejemplo o escenario. Para esta descripción formal lo más habitual es usar Gherkin, lo importante es que sea de alto nivel, lo menos técnico posible para poder involucrar a negocio, pero que se puedan ejecutar para que las podamos automatizar e integrarlas con nuestros lenguajes de programación. Si vemos el ejemplo que se propone en la página de Cucumber:
Feature: Guess the word
# The first example has two steps
Scenario: Maker starts a game
When the Maker starts a game
Then the Maker waits for a Breaker to join
# The second example has three steps
Scenario: Breaker joins a game
Given the Maker has started a game with the word "silky"
When the Breaker joins the Maker's game
Then the Breaker must guess a word with 5 characters
En este ejemplo podemos ver que estamos usando un lenguaje natural muy cercano al inglés donde describimos que es lo que tiene que pasar en el juego de adivina la palabra.
3.2 Beneficios
Al empezar el artículo, me mostraba un poco escéptico con esta técnica, pero sin duda tiene beneficios, ya que fomenta la colaboración entre desarrolladores, usuarios, clientes o expertos del dominio porque los requisitos se deben expresar como un contrato no ambiguo. Cuanto más involucradas estén todas las partes, más probabilidades de éxito tendremos en el proyecto. También podemos dar por hecho que un producto que pasa las pruebas de aceptación será dado por bueno, aunque las partes involucradas pueden refinar estas pruebas o añadir nuevas. Por último al tener estas pruebas de alto nivel se limitan los nuevos defectos y regresiones.
3.3 Errores comunes
A la hora de hacer estas pruebas de aceptación se suelen cometer errores como pueden ser incluir demasiadas definiciones técnicas en los escenarios. Los usuarios y expertos del dominio no tienen por qué entender tecnicismos, lo que hacen estos tecnicismos es que entiendan peor las pruebas de aceptación. Para evitarlo, lo ideal es que los propios usuarios y expertos sean los que escriban las pruebas de aceptación. Como vemos, lo más complicado aquí es conseguir la colaboración entre todas las partes para aprovechar las sinergias.
4. Gherkin
No vamos a extendernos mucho en Gherkin, solo dar unas pinceladas para que todo se entienda mejor. Gherkin es un lenguaje específico del dominio (DSL), que tiene como propósito que sea entendible por negocio y describir el comportamiento del software sin detallar cómo se implementa. Al final, como los propios tests tiene dos propósitos: documentar y automatizar las pruebas. Se puede usar en cualquier idioma (aquí la usaremos en inglés y sería lo recomendable, ya que es el idioma de facto). Los ficheros Gherkin tienen extensión .feature. Cada fichero .feature contiene una única funcionalidad, pero dentro de esa funcionalidad se pueden en tener varias especificaciones. Por ejemplo dentro de la funcionalidad de login podemos tener una especificación para el login correcto, login incorrecto y logout.
La sintaxis esta basada en la indentación de las líneas al igual que otros lenguajes como Python o YAML. Para los comentarios se usa la almohadilla (#)
4.1 Definición de pasos
Los pasos se definen como Given, When, Then que son:
- Given: Dada una situación donde hacemos una configuración del test.
- When: Cuando hago algo o un evento llega
- Then: Entonces espero que suceda algo o una interacción entre colaboradores que puedo comprobar.
Esta forma de organizar los tests es similar a Arrange, Act, Assert.
4.2 Pasos adicionales And y But
Gherkin también cuenta con dos pasos adicionales que son And y But. Estos pasos se usan para mejorar la legibilidad de las especificaciones y añadir más casos al Given y al Then. Un ejemplo donde se todo esto seria:
Example: Multiple Givens Given one thing And another thing And yet another thing When I open my eyes Then I should see something But I shouldn't see something else
Tenemos la posibilidad de usar el asterisco (*) para reemplazar cualquier palabra reservada. Esto puede ser útil si tenemos una lista de cosas, reemplazamos la palabra reservada por el asterisco.
Si nos encontramos repitiendo muchas veces el mismo Given, puede significar que no es información necesaria para ese escenario. Para estos casos podemos usar un background. El background nos permite añadir algo de contexto a los escenarios que le siguen. Puede contener uno o más Given, que se ejecutan antes de cada escenario, pero después de Before. Un Background se coloca antes del primer Escenario/Ejemplo, en el mismo nivel de indentación.
4.3 Rule
Desde la versión 6, se soporta la palabra reservada Rule. El propósito de Rule es representar una regla de negocio que debe ser implementada. Proporciona información adicional para una funcionalidad. Rule se utiliza para agrupar varios escenarios que pertenecen a esta regla de negocio. Rule debe contener uno o más escenarios que ilustren la regla en particular.
Feature: Overdue tasks
Let users know when tasks are overdue, even when using other
features of the app
Rule: Users are notified about overdue tasks on first use of the day
Background:
Given I have overdue tasks
Example: First use of the day
Given I last used the app yesterday
When I use the app
Then I am notified about overdue tasks
Example: Already used today
Given I last used the app earlier today
When I use the app
Then I am not notified about overdue tasks
4.4 Scenario outlines
Cuando los escenarios son parecidos, se pueden usar plantillas y los datos en tablas, de esta forma nos evitamos repetir escenarios.
Scenario Outline: eating
Given there are cucumbers
When I eat cucumbers
Then I should have cucumbers
Examples:
| start | eat | left |
| 12 | 5 | 7 |
| 20 | 5 | 15 |
Esto es solo un repaso de Gherkin, para profundizar se puede consultar la documentación oficial que está en las referencias.
5. Cucumber
Ahora vamos a hablar de la otra pieza que necesitamos: Cucumber. Cucumber es un framework para ejecutar especificaciones Gherkin. Fue escrito originalmente en Ruby, pero actualmente tiene versiones para Java (de la que vamos a hablar) y múltiples lenguajes.
Aunque las especificaciones deberían escribirlas las personas de negocio, para ejecutar una funcionalidad Gherkin (feature) es necesario implementar código Java de pegamento (glue code) que interprete los pasos usando clases del código que es escrito por los desarrolladores.
Ese código Java implementará lo escrito en los ficheros .feature para cargar los valores y los ejemplos de las plantillas. En esos ficheros java tiene que haber correspondencia con los ficheros feature.
Las especificaciones se ejecutan como tests de Junit que pasarán solo si se cumple todo lo que está descrito en la especificación.
6. La aplicación
Para los ejemplos vamos a usar una sencilla aplicación de Spring Boot que tiene un controlador y un DTO para la request de login.
El controlador:
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Objects;
@RestController
@RequestMapping("/api/auth")
public class AuthController {
@PostMapping("/signin")
public ResponseEntity signIn(@RequestBody LoginDto loginDto){
if (Objects.equals(loginDto.username(), "admin")) {
return new ResponseEntity("Come in", HttpStatus.OK);
} else {
return new ResponseEntity("Not allowed", HttpStatus.FORBIDDEN);
}
}
}
Y el DTO
public record LoginDto(String username, String password) {
}
Para probarlo desde IntelliJ las requests de ejemplo
POST http://localhost:8080/api/auth/signin
Content-Type: application/json
{
"username": "admin",
"password": "fake"
}
###
POST http://localhost:8080/api/auth/signin
Content-Type: application/json
{
"username": "user",
"password": "fake"
}
###
Vemos que con la primera nos da un 200 y nos devuelve el mensaje Come in
http://localhost:8080/api/auth/signin HTTP/1.1 200 Content-Type: text/plain;charset=UTF-8 Content-Length: 7 Date: Fri, 19 Aug 2022 10:59:05 GMT Keep-Alive: timeout=60 Connection: keep-alive Come in Response code: 200; Time: 1604ms (1 s 604 ms); Content length: 7 bytes (7 B)
Y la segunda nos devuelve un 403 y el mensaje Not allowed
http://localhost:8080/api/auth/signin HTTP/1.1 403 Content-Type: text/plain;charset=UTF-8 Content-Length: 11 Date: Fri, 19 Aug 2022 10:59:12 GMT Keep-Alive: timeout=60 Connection: keep-alive Not allowed Response code: 403; Time: 26ms (26 ms); Content length: 11 bytes (11 B)
A partir de aquí tenemos varias opciones
6.1. Usando Spring
Ya que estamos usando spring, una opción es integrar los tests de aceptación con spring. Veamos a alto nivel como seria (nos vale para los siguientes apartados).
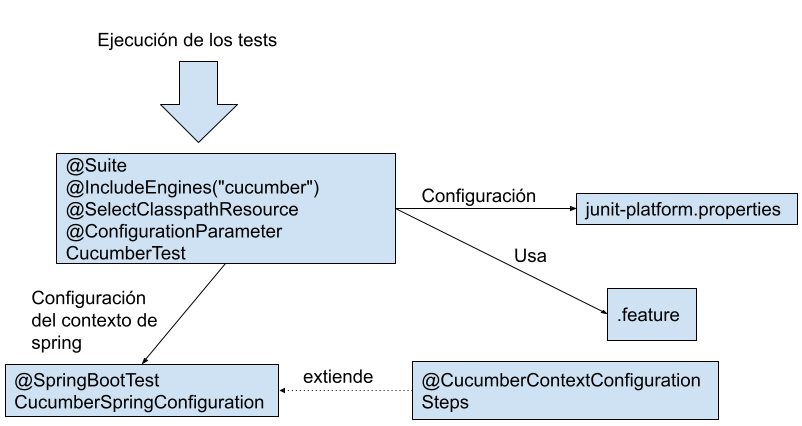
Lo primero que tenemos que hacer es añadir las dependencias que necesitamos que serian: cucumber-java, cucumber-spring y cucumber-junit-platform-engine. Aquí hay que tener cuidado y usar cucumber-junit-platform-engine y no cucumber-junit, ya que cucumber-junit-platform-engine ejecuta los escenarios como tests de Junit 5 y cucumber-junit los ejecuta como tests de Junit 4. También se necesita junit-platform-suite para hacer el punto de entrada de cucumber, ya que se marcó como obsoleta la anotación @Cucumber en favor de @Suite
Después de esto el pom.xml queda así:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>es.dionisiocortes</groupId>
<artifactId>cucumberjunit</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>cucumberjunit</name>
<description>cucumberjunit</description>
<properties>
<java.version>17</java.version>
<cucumber.version>7.6.0</cucumber.version>
<junit.platform.version>1.9.0</junit.platform.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-suite</artifactId>
<version>${junit.platform.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-java</artifactId>
<version>${cucumber.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-spring</artifactId>
<version>${cucumber.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-junit-platform-engine</artifactId>
<version>${cucumber.version}</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Ya que teneos todas las dependencias vamos a crear los tests.
6.1.1 Punto de entrada
La siguiente clase sirve como punto de entrada para cucumber. Esta clase se puede llamar de cualquier forma, pero siempre teniendo en cuenta las convenciones para que sea reconocida como test (normalmente tiene que acabar en test o It dependiendo si queremos que sea unitario o de integración), de lo contrario, maven no encontrará los tests de Cucumber.
package es.dionisiocortes.cucumberjunit.bdd;
import org.junit.platform.suite.api.ConfigurationParameter;
import org.junit.platform.suite.api.IncludeEngines;
import org.junit.platform.suite.api.SelectClasspathResource;
import org.junit.platform.suite.api.Suite;
import static io.cucumber.junit.platform.engine.Constants.GLUE_PROPERTY_NAME;
@Suite
@IncludeEngines("cucumber")
@SelectClasspathResource("es/dionisiocortes/cucumberjunit/bdd")
@ConfigurationParameter(key = GLUE_PROPERTY_NAME, value = "es.dionisiocortes.cucumberjunit.bdd")
public class CucumberTest {
}
Las dos anotaciones @Suite y @IncludeEngines("cucumber") son el equivalente a la antigua @Cucumber, pero que con la versión 7 de cucumber quedó obsoleta. En JUnit 5, podemos definir las opciones de cucumber en el fichero junit-platform.properties, en la carpeta resources de tests. La anotación @SelectClasspathResource("es/dionisiocortes/cucumberjunit/bdd") nos dice dentro de la carpeta resources donde tenemos los ficheros .feature y en @ConfigurationParameter(key = GLUE_PROPERTY_NAME, value = "es.dionisiocortes.cucumberjunit.bdd") le decimos donde están las clases de pegamento, es decir, los steps.
cucumber.publish.quiet=true cucumber.publish.enabled=false cucumber.plugin=pretty, html:target/cucumber-reports/Cucumber.html, json:target/cucumber-reports/Cucumber.json, junit:target/cucumber-reports/Cucumber.xml
En el ejemplo anterior, estamos quitando el banner que aparece al ejecutar cucumber y le decimos que no publique los resultados en su servicio. También estamos generando los informes localmente en formato html, json y xml en el directorio target/cucumber-reports.
6.1.2 Configurando spring
Al estar en spring, vamos a configurar cucumber para que pueda hacer uso del contexto de spring. Lo primero seria poner @SpringBootTest.
Vamos a inyectarnos también TestRestTemplate para poder hacer llamadas al api que antes hemos creado.
package es.dionisiocortes.cucumberjunit.bdd;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.boot.test.web.client.TestRestTemplate;
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class CucumberSpringConfiguration {
@Autowired
protected TestRestTemplate testRestTemplate;
}
Ya que tenemos todo configurado, vamos a añadir las pruebas. Un archivo .feature contiene uno o varios escenarios que deben probarse para esa funcionalidad. Cada escenario representa un caso de prueba. Es una parte esencial para Cucumber, ya que es un script que nos automatiza las pruebas, así como documentación.
6.1.3 Ficheros .feature
Vamos a definir nuestro primer fichero .feature:
Feature: Login
Scenario: Admin login
Given admin user wants to login
When the user tries to login as admin
Then the user is allowed to use the app.
Scenario: Other user login login
Given other user wants to login
When the user tries to login
Then the user is not allowed to use the app.
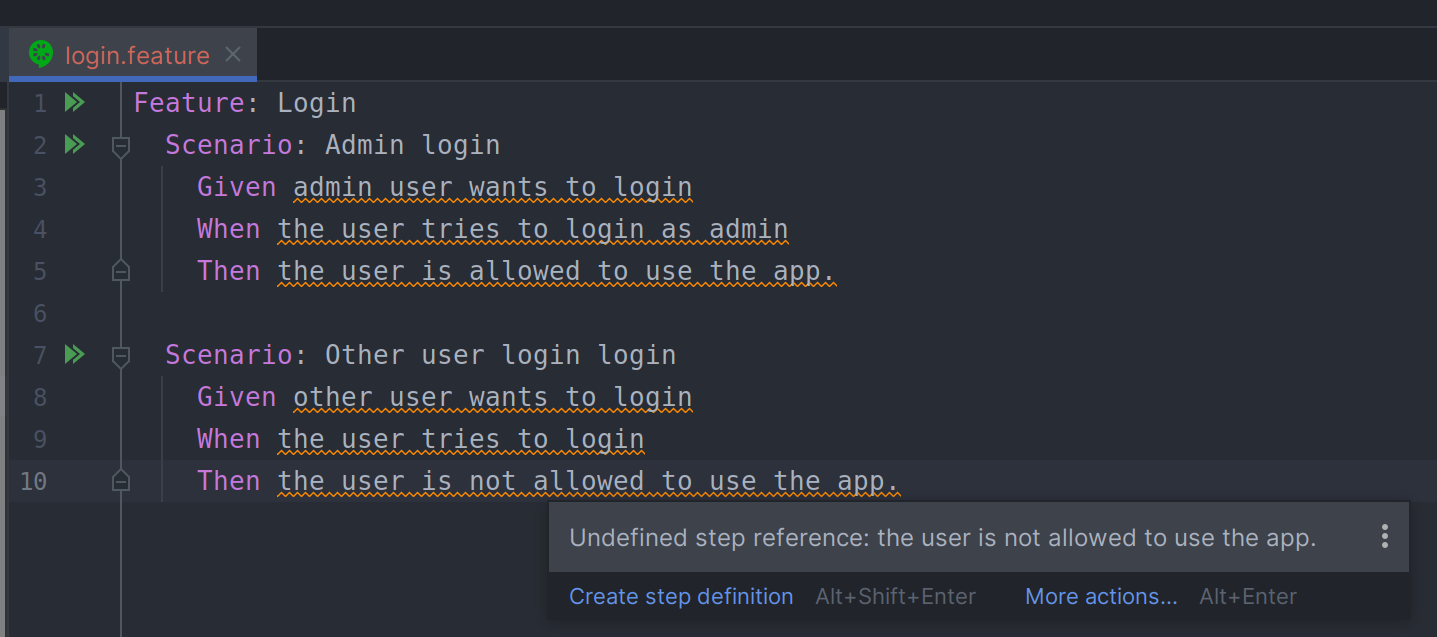
Como podemos observar en la imagen, cuando definimos los ficheros .feature, el IDE, en este caso IntelliJ nos dice que nos faltan los pasos para ese fichero, así que vamos a implementarlos.
6.1.4 Definición de los steps
La clase de definición de pasos es el mapeo (o el glue code) entre cada paso del escenario definido en el archivo .feature con un código que implementa esos tests. Cuando Cucumber ejecuta un paso del escenario mencionado en el archivo .feature, escanea el archivo de definición de pasos y averigua qué función será llamada. Esta clase tiene la anotación @CucumberContextConfiguration que hace que Cucumber use esta clase como la configuración del contexto de test para Spring. Si ponemos esta anotación en CucumberSpringConfiguration nos va a dar un error diciendo que hay beans duplicados.
package es.dionisiocortes.cucumberjunit.bdd.steps;
import es.dionisiocortes.cucumberjunit.bdd.CucumberSpringConfiguration;
import es.dionisiocortes.cucumberjunit.controller.LoginDto;
import io.cucumber.java.en.Given;
import io.cucumber.java.en.Then;
import io.cucumber.java.en.When;
import io.cucumber.spring.CucumberContextConfiguration;
import org.junit.jupiter.api.Assertions;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
@CucumberContextConfiguration
public class LoginSteps extends CucumberSpringConfiguration {
private String username;
private ResponseEntity response;
@Given("admin user wants to login")
public void adminUserWantsToLogin() {
username = "admin";
}
@When("the user tries to login as admin")
public void theUserTriesToLoginAsAdmin() {
response = testRestTemplate.postForEntity(
"/api/auth/signin", new LoginDto(username, "anything"), String.class);
}
@Then("the user is allowed to use the app.")
public void theUserIsAllowedToUseTheApp() {
Assertions.assertEquals("Come in", response.getBody());
Assertions.assertEquals(HttpStatus.OK, response.getStatusCode());
}
@Given("other user wants to login")
public void otherUserWantsToLogin() {
username = "otherUser";
}
@When("the user tries to login")
public void theUserTriesToLogin() {
response = testRestTemplate.postForEntity(
"/api/auth/signin", new LoginDto(username, "anything"), String.class);
}
@Then("the user is not allowed to use the app.")
public void theUserIsNotAllowedToUseTheApp() {
Assertions.assertEquals("Not allowed", response.getBody());
Assertions.assertEquals(HttpStatus.FORBIDDEN, response.getStatusCode());
}
}
6.1.5 Organización de la aplicación
La estructura de la aplicación queda así:
├── src │ ├── main │ │ ├── java │ │ │ └── es │ │ │ └── dionisiocortes │ │ │ └── cucumberjunit │ │ │ ├── controller │ │ │ │ ├── AuthController.java │ │ │ │ └── LoginDto.java │ │ │ └── CucumberjunitApplication.java │ │ └── resources │ │ ├── application.properties │ │ ├── static │ │ └── templates │ └── test │ ├── java │ │ └── es │ │ └── dionisiocortes │ │ └── cucumberjunit │ │ └── bdd │ │ ├── CucumberSpringConfiguration.java │ │ ├── CucumberTest.java │ │ └── steps │ │ └── LoginSteps.java │ └── resources │ ├── es │ │ └── dionisiocortes │ │ └── cucumberjunit │ │ └── bdd │ │ └── login.feature │ └── junit-platform.properties
6.2. Sin usar Spring
En muchas ocasiones queremos que nuestros tests sean lo más agnósticos posibles, no dependan de un framewrok o que estén en otro proyecto o modulo independiente para tener más versatilidad. Aquí vamos a ejemplificar un proyecto multimodulo. El ciclo de vida va a ser, hacer una imagen docker en el proyecto que contiene la aplicación y luego en el otro módulo lanzar los tests.
6.2.1 Haciendo el proyecto multimodulo
Lo primero es el pom.xml padre en el que se han puesto dos módulos (api y acceptance-test), las versiones de todo lo que se usa en el proyecto y todas las dependencias dentro del dependency management. Se queda así:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>es.dionisiocortes</groupId>
<artifactId>cucumber-junit-multimodule</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>cucumber-junit-multimodule</name>
<description>cucumberjunit</description>
<packaging>pom</packaging>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<modules>
<module>api</module>
<module>acceptance-tests</module>
</modules>
<properties>
<java.version>17</java.version>
<cucumber.version>7.6.0</cucumber.version>
<junit-platform.version>1.9.0</junit-platform.version>
<spring-boot.version>2.7.3</spring-boot.version>
<jib-maven-plugin.version>3.2.1</jib-maven-plugin.version>
<rest-assured.version>5.1.1</rest-assured.version>
<commons-logging.version>1.2</commons-logging.version>
<jackson-datatype-jdk8.version>2.13.3</jackson-datatype-jdk8.version>
<docker-maven-plugin.version>0.40.2</docker-maven-plugin.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-suite</artifactId>
<version>${junit-platform.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-java</artifactId>
<version>${cucumber.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-junit-platform-engine</artifactId>
<version>${cucumber.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured</artifactId>
<version>${rest-assured.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>json-schema-validator</artifactId>
<version>${rest-assured.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>${commons-logging.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jdk8</artifactId>
<version>${jackson-datatype-jdk8.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
</project>
El proyecto que contiene el API lo hemos cambiado para que solo tenga las dependencias de spring para hacer el API además de actuator para poder ver cuando la aplicación ha terminado de levantar y, como vemos, hemos puesto el plugin de JIB para generar la imagen de docker en la fase de verificación, una vez que ya se han pasado todos los tests y vemos que nuestra aplicación es correcta.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>es.dionisiocortes</groupId>
<artifactId>cucumber-junit-multimodule</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>api</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>api</name>
<description>api</description>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>com.google.cloud.tools</groupId>
<artifactId>jib-maven-plugin</artifactId>
<version>${jib-maven-plugin.version}</version>
<configuration>
<from>
<image>openjdk:17</image>
</from>
<to>
<image>${project.name}:${project.version}</image>
</to>
</configuration>
<executions>
<execution>
<phase>verify</phase>
<goals>
<goal>dockerBuild</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Por último, tenemos el pom del módulo que tiene los test de aceptación. Este módulo solo tiene las dependencias de test. Al no tener spring, usamos rest asured para hacer las llamadas rest, pero no habría problema en usar cualquier librería para hacer las llamadas rest, incluso resttemplate de spring. Tenemos que excluir la dependencia de Groovy porque si no da un error al tener versiones de Groovy distintas, lo cual está descrito en las FAQ de rest-asured. El modulo también tiene el plugin de fabric8 para levantar la imagen que hemos generado anteriormente.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>es.dionisiocortes</groupId>
<artifactId>cucumber-junit-multimodule</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>acceptance-tests</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>acceptance-tests</name>
<description>acceptance-tests</description>
<dependencies>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-suite</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-java</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.cucumber</groupId>
<artifactId>cucumber-junit-platform-engine</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.groovy</groupId>
<artifactId>groovy</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.groovy</groupId>
<artifactId>groovy-xml</artifactId>
</exclusion>
</exclusions>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>json-schema-validator</artifactId>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jdk8</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>io.fabric8</groupId>
<artifactId>docker-maven-plugin</artifactId>
<version>${docker-maven-plugin.version}</version>
<configuration>
<images>
<image>
<name>api:0.0.1-SNAPSHOT</name>
<run>
<ports>
<port>8080:8080</port>
</ports>
<wait>
<http>
<url>http://localhost:8080/actuator/health</url>
<status>200</status>
</http>
</wait>
</run>
</image>
</images>
</configuration>
<executions>
<execution>
<id>start</id>
<phase>pre-integration-test</phase>
<goals>
<goal>start</goal>
</goals>
</execution>
<execution>
<id>stop</id>
<phase>post-integration-test</phase>
<goals>
<goal>stop</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.0.0-M7</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
<goal>verify</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Con todo esto lo que tenemos es un ciclo que la aplicación pasaría sus tests, generaría una imagen y ya el modulo de tests de aceptación levanta la imagen y lanza los tests.
6.2.2 La aplicación
La aplicación no ha cambiado, lo único que se ha hecho es quitar todos los tests de aceptación para que no sean ejecutados. La creación de la imagen docker lo hace el plugin que hemos visto anteriormente en el pom.xml de la aplicación. Lo demás es igual, ya que los endpoints a testear son los mismos. Debemos darnos cuenta que la aplicación ya no tiene dependencias de cucumber porque ya no las necesita y no sabe nada de ese framework.
6.2.3 Los tests
Lo primero de lo que debemos darnos cuenta es que hemos eliminado las dependencias de spring, y la de cucumber relacionada con spring. Se ha añadido rest-assured para hacer las llamadas rest y ya no tenemos la configuración de spring. Si vemos un diagrama quedaría así:
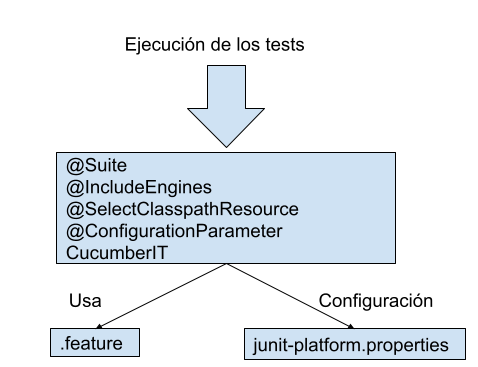
Si vemos la clase cucumberIt es igual a la que teníamos, quedando así:
package es.dionisiocortes.cucumberjunit.bdd;
import org.junit.platform.suite.api.ConfigurationParameter;
import org.junit.platform.suite.api.IncludeEngines;
import org.junit.platform.suite.api.SelectClasspathResource;
import org.junit.platform.suite.api.Suite;
import static io.cucumber.junit.platform.engine.Constants.GLUE_PROPERTY_NAME;
@Suite
@IncludeEngines("cucumber")
@SelectClasspathResource("es/dionisiocortes/cucumberjunit/bdd")
@ConfigurationParameter(key = GLUE_PROPERTY_NAME, value = "es.dionisiocortes.cucumberjunit.bdd")
public class CucumberIT {
}
Se llama CucumberIT para que el plugin de failsafe la ejecute durante la fase de integración, y si revisamos el plugin de fabric8, para cuando llegamos a esa fase, ya tenemos el contenedor levantado, por lo que ya tenemos un sitio al que hacer nuestras peticiones rest.
Los steps tampoco cambian como tal, lo que cambia es su implementación. Vemos que ahora tenemos una configuración de rest-assured para indicarle contra que url base y puerto tiene que ejecutar. Nos guardamos la response en un objeto de tipo Response que luego verificamos con la fluent api que nos proporciona.
package es.dionisiocortes.cucumberjunit.bdd.steps;
import io.cucumber.java.en.Given;
import io.cucumber.java.en.Then;
import io.cucumber.java.en.When;
import io.restassured.RestAssured;
import io.restassured.http.ContentType;
import io.restassured.response.Response;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import java.util.Map;
import static io.restassured.RestAssured.given;
import static org.hamcrest.Matchers.equalTo;
public class LoginSteps {
private String username;
private Response response;
@BeforeAll
public static void setup() {
RestAssured.baseURI = "http://localhost";
RestAssured.port = 8080;
}
@AfterAll
public static void tearDown() {
RestAssured.reset();
}
@Given("admin user wants to login")
public void adminUserWantsToLogin() {
username = "admin";
}
@When("the user tries to login as admin")
public void theUserTriesToLoginAsAdmin() {
response = given().request()
.contentType(ContentType.JSON)
.body(Map.of("username", username, "password", "anything"))
.when().post("/api/auth/signin");
}
@Then("the user is allowed to use the app.")
public void theUserIsAllowedToUseTheApp() {
response.then().assertThat()
.statusCode(200)
.body(equalTo("Come in"));
}
@Given("other user wants to login")
public void otherUserWantsToLogin() {
username = "otherUser";
}
@When("the user tries to login")
public void theUserTriesToLogin() {
response = given().request()
.contentType(ContentType.JSON)
.body(Map.of("username", username, "password", "anything"))
.when().post("/api/auth/signin");
}
@Then("the user is not allowed to use the app.")
public void theUserIsNotAllowedToUseTheApp() {
response.then().assertThat()
.statusCode(403)
.body(equalTo("Not allowed"));
}
}
6.2.4 La ejecución
Una vez tenemos todo montado, si hacemos mvn clean verify tenemos lo siguiente.
[INFO] Scanning for projects... [INFO] ------------------------------------------------------------------------ [INFO] Reactor Build Order: [INFO] [INFO] cucumber-junit-multimodule [pom] [INFO] api [jar] [INFO] acceptance-tests [jar] [INFO] [INFO] ------------< es.dionisiocortes:cucumber-junit-multimodule >------------ [INFO] Building cucumber-junit-multimodule 0.0.1-SNAPSHOT [1/3] [INFO] --------------------------------[ pom ]---------------------------------
Vemos que nos está diciendo que tenemos 3 proyectos. Luego se pone a compilar y vemos que nos genera la imagen de docker
[INFO] --- jib-maven-plugin:3.2.1:dockerBuild (default) @ api ---
[WARNING] 'mainClass' configured in 'maven-jar-plugin' is not a valid Java class: ${start-class}
[INFO]
[INFO] Containerizing application to Docker daemon as api:0.0.1-SNAPSHOT...
[WARNING] Base image 'openjdk:17' does not use a specific image digest - build may not be reproducible
.................
[INFO] Loading to Docker daemon...
[INFO]
[INFO] Built image to Docker daemon as api:0.0.1-SNAPSHOT
Ya tenemos la imagen de docker, perfecto. Ahora vamos a levantar esa imagen.
[INFO] --- docker-maven-plugin:0.40.2:start (start) @ acceptance-tests --- [INFO] DOCKER> [api:0.0.1-SNAPSHOT]: Start container 15b2e2f17bdb [INFO] DOCKER> [api:0.0.1-SNAPSHOT]: Waiting on url http://localhost:8080/actuator/health with method HEAD for status 200. [INFO] DOCKER> [api:0.0.1-SNAPSHOT]: Waited on url http://localhost:8080/actuator/health 3236 ms [INFO] [INFO] --- maven-failsafe-plugin:3.0.0-M7:integration-test (default) @ acceptance-tests --- [INFO] Using auto detected provider org.apache.maven.surefire.junitplatform.JUnitPlatformProvider
Por último vemos que se ejecutan los tests.
[INFO] ------------------------------------------------------- [INFO] T E S T S [INFO] ------------------------------------------------------- [INFO] Running es.dionisiocortes.cucumberjunit.bdd.CucumberIT Scenario: Admin login # es/dionisiocortes/cucumberjunit/bdd/login.feature:2 Given admin user wants to login # es.dionisiocortes.cucumberjunit.bdd.steps.LoginSteps.adminUserWantsToLogin() When the user tries to login as admin # es.dionisiocortes.cucumberjunit.bdd.steps.LoginSteps.theUserTriesToLoginAsAdmin() Then the user is allowed to use the app. # es.dionisiocortes.cucumberjunit.bdd.steps.LoginSteps.theUserIsAllowedToUseTheApp() Scenario: Other user login login # es/dionisiocortes/cucumberjunit/bdd/login.feature:7 Given other user wants to login # es.dionisiocortes.cucumberjunit.bdd.steps.LoginSteps.otherUserWantsToLogin() When the user tries to login # es.dionisiocortes.cucumberjunit.bdd.steps.LoginSteps.theUserTriesToLogin() Then the user is not allowed to use the app. # es.dionisiocortes.cucumberjunit.bdd.steps.LoginSteps.theUserIsNotAllowedToUseTheApp() [INFO] Tests run: 2, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 2.216 s - in es.dionisiocortes.cucumberjunit.bdd.CucumberIT
y ya lo tenemos todo.
[INFO] Reactor Summary for cucumber-junit-multimodule 0.0.1-SNAPSHOT: [INFO] [INFO] cucumber-junit-multimodule ......................... SUCCESS [ 0.093 s] [INFO] api ................................................ SUCCESS [ 8.055 s] [INFO] acceptance-tests ................................... SUCCESS [ 8.696 s] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------
Por ser maliciosos y confirmar que todo es correcto, si cambiamos el último paso para que espere un 404
@Then("the user is not allowed to use the app.")
public void theUserIsNotAllowedToUseTheApp() {
response.then().assertThat()
.statusCode(404)
.body(equalTo("Not allowed"));
}
Vemos que los tests y la build fallan.
Scenario: Other user login login # es/dionisiocortes/cucumberjunit/bdd/login.feature:7
Given other user wants to login # es.dionisiocortes.cucumberjunit.bdd.steps.LoginSteps.otherUserWantsToLogin()
When the user tries to login # es.dionisiocortes.cucumberjunit.bdd.steps.LoginSteps.theUserTriesToLogin()
Then the user is not allowed to use the app. # es.dionisiocortes.cucumberjunit.bdd.steps.LoginSteps.theUserIsNotAllowedToUseTheApp()
java.lang.AssertionError: 1 expectation failed.
Expected status code <404> but was <403>.
...........................
[INFO] cucumber-junit-multimodule ......................... SUCCESS [ 0.092 s]
[INFO] api ................................................ SUCCESS [ 7.785 s]
[INFO] acceptance-tests ................................... FAILURE [ 7.752 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
Por último mencionar que dependiendo de la configuración, puede que sea necesario usar el runner de ant si no somos capaces de detectar los tests. Esto está detallado aquí junto con otras configuraciones avanzadas que pueden ser de utilidad.
7. Conclusiones
En este tutorial hemos querido mostrar la importancia de hacer tests de integración y hemos puesto ejemplos con dos escenarios, uno con un framework y otro sin él. Los dos tienen ventajas e inconvenientes. Por ejemplo con un framework podemos acceder a todo el contexto y podríamos tener acceso a más bajo nivel a las cosas. Si tenemos un módulo aparte, es más fácil de portarlo a otro repositorio y que sea más independiente, no dependemos del framework y nos permite ser más puristas, pero puede hacerse algo más engorroso. En definitiva, conviene analizar cada caso, ver lo más conveniente y aplicarlo, cada proyecto es un mundo.
7. Referencias
- GLOSSARY Acceptance Testing. Agile Alliance.
- Gherkin Reference. Cucumber.
- rest-assured. rest-assured.
- Foto de Sabrina Wendl en Unsplash


Muy buen articulo.
En las dependencias falta un $ para el número de versión del artifactId cucumber-java pero salvo esa nadería es un excelente documento. Muchas gracias.
Hola
Dejo por aquí el repositorio con las dos soluciones ya que no se porque no renderiza bien el pom.xml
acceptance tests with cucumber and junit 5
Aprovechando he actualizado las dependencias
<cucumber.version>7.6.0</cucumber.version> -> <cucumber.version>7.12.0</cucumber.version>
<junit-platform.version>1.9.0</junit-platform.version> -> <junit-platform.version>1.9.3</junit-platform.version>
<spring-boot.version>2.7.3</spring-boot.version> -> <spring-boot.version>3.0.6</spring-boot.version>
<jib-maven-plugin.version>3.2.1</jib-maven-plugin.version> -> <jib-maven-plugin.version>3.3.2</jib-maven-plugin.version>
<rest-assured.version>5.1.1</rest-assured.version> -> <rest-assured.version>5.3.0</rest-assured.version>
<jackson-datatype-jdk8.version>2.13.3</jackson-datatype-jdk8.version> -> (se elimina)
<docker-maven-plugin.version>0.40.2</docker-maven-plugin.version> -> <docker-maven-plugin.version>0.42.1</docker-maven-plugin.version>
En el pom.xml de acceptamce-tests de la solución multimodulo no es necesario
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.groovy</groupId>
<artifactId>groovy</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.groovy</groupId>
<artifactId>groovy-xml</artifactId>
</exclusion>
</exclusions>
<scope>test</scope>
</dependency>
Ha sido excelente explicacion. Me sirvio micho para un proyecto que ya tenia cucumber y que no lograba entenderlo