

Introducción
En todas las aplicaciones que desplegamos nos interesa tener una serie de métricas y logs para poder realizar diferentes análisis como pueden ser de rendimiento, a nivel de red o también gestionar las excepciones de nuestra aplicación.
En tutoriales pasados se ha explicado cómo configurar CloudWatch en el servicio de EC2. En este tutorial se va a explicar cómo exprimir la capa gratuita “para siempre” (es decir, no hablamos sólo del primer año de creación de la cuenta, sino lo que podremos seguir haciendo una vez pase este primer periodo de gracia) de CloudWatch y limitar al máximo los recursos de pago, en el caso de que nuestra aplicación esté corriendo en AWS EKS.
Se obtendrá información a nivel de la propia aplicación, del estado del cluster y sus nodos hasta el nivel de pod.
Entorno
- Hardware: MacBook Pro (Intel Core i7, 16 GB DDR4)
- MacOs BigSur v11.2.3
- Terraform v0.14.8
- Kubernetes v1.20.4
Requisitos
Para seguir este tutorial, se debe tener instalado Terraform en el equipo y disponer de una cuenta de AWS activa, tal y como se explica en el tutorial de primeros pasos con Terraform y en esta guía sobre crear una cuenta de AWS. También debemos tener instalado el cliente de kubernetes, por ejemplo kubectl, para poder aplicar la configuración que hagamos en el cluster.
También es necesario disponer de un cluster operativo para poder desplegar los pods necesarios para obtener los logs y las métricas. Si eres nuevo en esto y no sabes como hacerlo, este es un enlace al repositorio de este tutorial y con clonarlo y ejecutar los siguientes comandos podrás tener un cluster con un nodo funcionando.
terraform plan -out tfplan.out
terraform apply "tfplan.out"
Recuerda que el servicio EKS de Amazon es de pago, y se te va a cobrar por tener el cluster funcionando así que ten cuidado y cuando acabes este tutorial que no se te olvide desactivarlo con un terraform destroy para no tener sustos innecesarios.
Si ya tienes un cluster levantado, deberás añadir una política que permita a los nodos enviar los logs a CloudWatch. Lo puedes hacer a través de la consola web de AWS en la sección de IAM o mejor aún, si estás usando Terraform con añadir estas líneas tendrás el proceso automatizado:
resource "aws_iam_role_policy_attachment" "CloudWatchAgentServerPolicy" {
policy_arn = "arn:aws:iam::aws:policy/CloudWatchAgentServerPolicy"
role = aws_iam_role.eks_nodes.name
}
resource "aws_eks_node_group" "node" {
. . .
depends_on = [
. . .,
aws_iam_role_policy_attachment.CloudWatchAgentServerPolicy,
]
}Configuración de los pods
Ya tenemos nuestra infraestructura lista, ¿como hacemos para obtener los logs? En primer lugar me gustaría destacar que cuando queremos usar CloudWatch debemos de tener en cuenta la capacidad de nuestros nodos. Esto se debe a que si tenemos instancias con recursos muy limitados es posible que no podamos disfrutar de esta funcionalidad de AWS. Por eso, debemos analizar cuantos pods es capaz de soportar el nodo ya que para la configuración de CloudWatch vamos a necesitar tener al menos capacidad para desplegar 2 pods adicionales.
Vamos a crear un namespace para centralizar la información de los pods que nos interesa en base al namespace creado y que nos resulta más sencillo para después hacer el proceso de monitorización. También generamos los service account correspondientes para que los procesos dentro de los pods puedan hacer las llamadas a la API.
Necesitamos también especificar qué pueden hacer los service account definidos anteriormente.
En el primer rol definimos qué acciones puede hacer CloudWatch en nuestro cluster y el role binding se encarga de vincular el rol con el service account especificado anteriormente. CloudWatch se va a encargar de ofrecer métricas de performance, tales como, uso de CPU y memoria, utilización del disco o carga en la red.
# create amazon-cloudwatch namespace
apiVersion: v1
kind: Namespace
metadata:
name: amazon-cloudwatch
labels:
name: amazon-cloudwatch
# create CWAgent service account
apiVersion: v1
kind: ServiceAccount
metadata:
name: cloudwatch-agent
namespace: amazon-cloudwatch
# Create FluentD service account
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: amazon-cloudwatchEn el segundo rol se especifica las acciones que puede tomar FluentD. Y como en el caso anterior, tiene su role binding para asociarse con el service account.
# CWAgent Cluster Role and Role Binding
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cloudwatch-agent-role
rules:
- apiGroups: [""]
resources: ["pods", "nodes", "endpoints"]
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources: ["replicasets"]
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources: ["jobs"]
verbs: ["list", "watch"]
- apiGroups: [""]
resources: ["nodes/proxy"]
verbs: ["get"]
- apiGroups: [""]
resources: ["nodes/stats", "configmaps", "events"]
verbs: ["create"]
- apiGroups: [""]
resources: ["configmaps"]
resourceNames: ["cwagent-clusterleader"]
verbs: ["get","update"]
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cloudwatch-agent-role-binding
subjects:
- kind: ServiceAccount
name: cloudwatch-agent
namespace: amazon-cloudwatch
roleRef:
kind: ClusterRole
name: cloudwatch-agent-role
apiGroup: rbac.authorization.k8s.io
# FluentD Cluster Role and Role Binding
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd-role
rules:
- apiGroups: [""]
resources:
- namespaces
- pods
- pods/logs
verbs: ["get", "list", "watch"]
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: fluentd-role-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: fluentd-role
subjects:
- kind: ServiceAccount
name: fluentd
namespace: amazon-cloudwatchEl siguiente paso es definir los ConfigMap para poder configurar los directorios que los pods van a usar para almacenar los logs. Una vez configurados, sólo nos queda poner nuestros pods a funcionar. El primero de ellos será el de CloudWatch Agent, que se trata de un DaemonSet para, en el caso de tener varios nodos en ejecución en el cluster, puedan enviar las métricas de performance a Container Insights.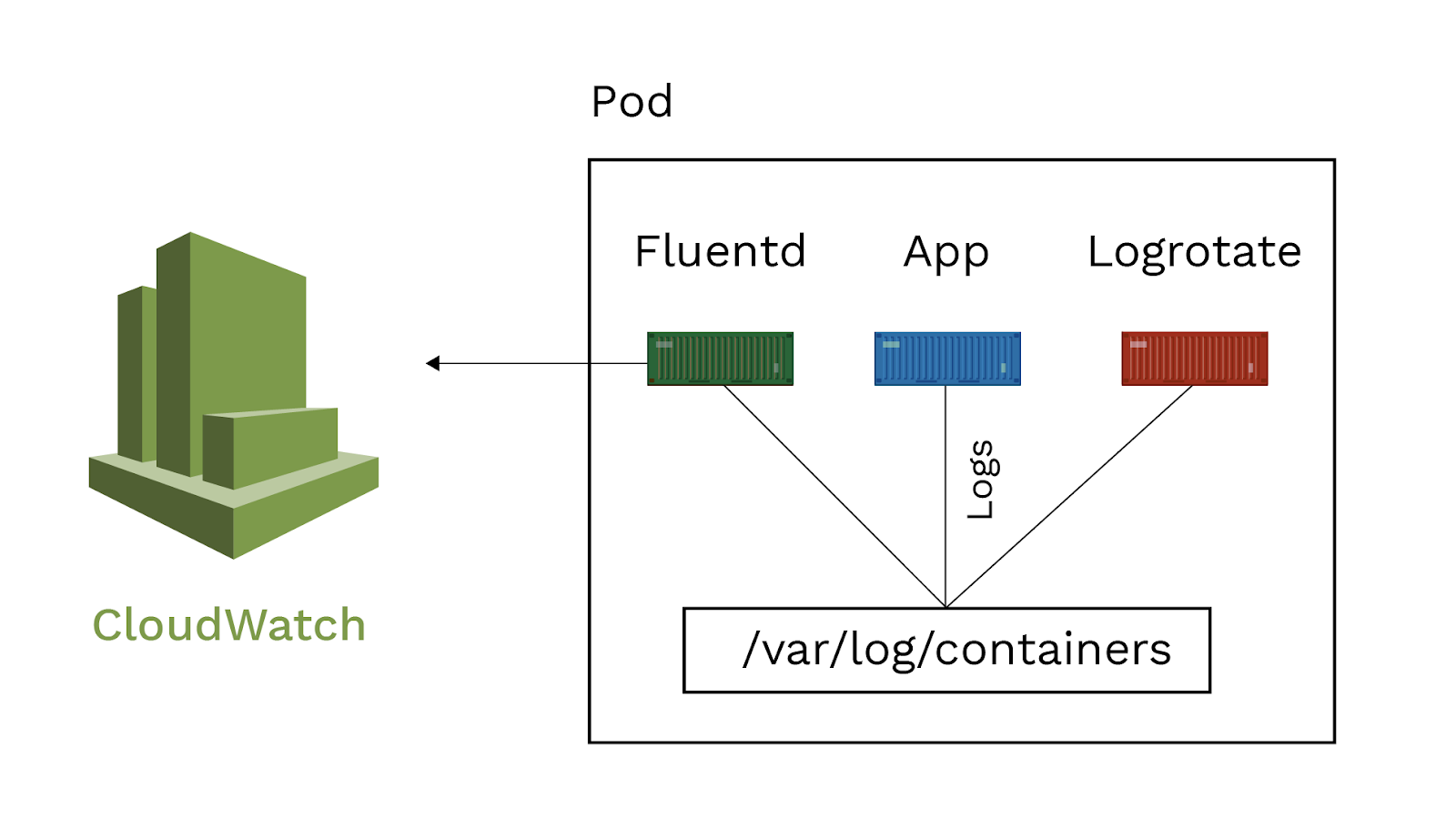 Como vemos en la imagen, el segundo pod y el tercero estarán compuestos por tres contenedores:
Como vemos en la imagen, el segundo pod y el tercero estarán compuestos por tres contenedores:
- El primero de ellos será la aplicación que usaremos de ejemplo. Mediante un “echo” escribimos en la ruta /var/log/container una línea. Para ilustrar las posibilidades a la hora de consolidar logs de distintas aplicaciones vamos a realizar dos despliegues de esta aplicación, que por simplicidad, únicamente varían en la cadena “Application A / Application B” y el propio nombre de los pods.
- El segundo contenedor es Fluentd configurado para observar la ruta anterior y enviar los logs a CloudWatch.
- Y por último un contenedor sidecar logrotate, simulando el rotado de logs que haría nuestra aplicación y que en este caso empleamos para que los logs del contenedor no ocupen demasiado espacio en disco y evitar costes adicionales. En este tutorial, “cron” activa logrotate cada 15 minutos como tarea programada pero se puede personalizar el comportamiento de logrotate utilizando las variables de entorno.
containers:
- name: app
image: busybox
command: ['sh', '-c']
args:
- >
while true;
do echo "Time: $(date) Application A -
$(cat /dev/urandom | tr -dc a-zA-Z0-9 | fold -w 1024 | head -n 1)" | tee -a /var/log/containers/application.log;
sleep 1;
done;
imagePullPolicy: Always
volumeMounts:
- mountPath: /var/log/containers
name: app-logs
resources:
requests:
cpu: 200m
memory: 0.5Gi
limits:
cpu: 400m
memory: 1Gi
securityContext:
privileged: false
readOnlyRootFilesystem: false
allowPrivilegeEscalation: falseComo hemos dicho, queremos mantenernos lo más posible dentro de la capa gratuita de AWS. Para ello tenemos que ser conscientes de las limitaciones que nos aplican. En nuestro caso, la capa gratuita solo permite 5GB de almacenamiento para los logs en la modalidad de “Gratis para siempre” según las condiciones de Amazon. A la hora de gestionar los límites de capacidad, tened en cuenta que CloudWatch Logs no tiene limitación a la hora de ingestar datos, y tendremos que gestionar por otras vías cuánto enviamos para no superar el límite.
Si nuestra aplicación genera muchos logs y queremos mantenernos en la capa gratuita, se deberá controlar qué logs queremos que FluentD envíe, ya que se puede dar el caso de que superemos los límites establecidos muy rápidamente.
Si hacemos un estudio de volumetría de nuestros logs, podemos ajustar la política de retención en CloudWatch Logs para evitar superarlo. Es complicado dar una estimación, ya que en esas 5GB cuentan no sólo los datos que almacenamos, sino los que se analizan al lanzar consultas. Recomendamos hacer una estimación de los costes potenciales que podríamos alcanzar con los volúmenes de logs con los Precios de Amazon CloudWatch – Amazon Web Services, ya que además las tarifas varían según la región.
Como medida adicional podemos configurar un presupuesto y alarmas que nos avisen de que estamos próximos a superar ese límite para evitar sorpresas desagradables, tal y como aparecen en el tutorial La configuración de AWS Cloudwatch con EC2 en la sección Los presupuestos.
Si aún nos quedan dudas de qué es gratis y durante cuánto tiempo, existe la posibilidad de consultar qué servicios y en qué modalidad son gratuitos en el enlace Capa gratuita de AWS | Cloud computing gratis.
Por si fuera poco y para darle más emoción, ¡el tamaño de ficheros consultados al realizar búsquedas también cuenta! Por eso, es casi imprescindible configurar presupuestos y alertas.
En el repositorio que he compartido al inicio, tenemos toda la configuración separada en distintos ficheros en función de su responsabilidad. Para que dicha configuración tenga efecto en el cluster debemos ejecutar el comando kubectl apply -f file_name.yaml, siendo file_name.yaml cada uno de los ficheros descritos a lo largo de este tutorial.
¿Qué hacer cuando salte la alarma de presupuesto?
Si pese a tomar todas las precauciones tenemos un consumo excesivo de recursos y nos vamos a pasar de los límites, la alarma de presupuesto nos enviará un mensaje advirtiéndonos. En este momento podemos tomar dos caminos. El primero y más claro es tener en cuenta la previsión de coste de AWS, ya que aunque nos cobren más allá del límite no es un servicio caro y por muy poco podremos trabajar con volúmenes de información muy superiores. El hecho de eliminar logs antiguos no va a suponer ninguna diferencia, ya que ese espacio ya se ha consumido y no resetea el contador a 0. El único momento en el que el contador vuelve a 0 es al inicio de un nuevo mes, por lo tanto, lo que hemos gastado, gastado está y no hay forma de recuperar ese espacio.
Si en nuestro caso no queremos o no podemos incurrir en esos gastos, lo único que podemos hacer es “sacar” los pods de trazado de la ecuación. De esa forma, al dejar de enviar información dejaremos de consumir, y cuando el límite se restablezca al inicio del próximo mes, podemos volver a desplegarlos.
Como este proceso es bastante farragoso, podríamos simplificar bastante la gestión mediante charts de Helm, que nos permitirían incluir o sacar de forma dinámica los pods necesarios para enviar los logs.
Por supuesto, la opción se tiene que valorar teniendo en cuenta el entorno en el que trabajamos. Jugar con los elementos que desplegamos es mucho más sencillo en entornos no productivos, donde podemos hacer despliegues bajo demanda y mucho más crítico en sistemas productivos donde el beneficio de centralizar los logs para hacer frente a un problema o incidencia puede ser suficiente para justificar el coste.
Tampoco hay que olvidar que todas las consultas que lancemos con Log Insights cuentan a la hora de calcular el uso, como veremos más adelante.
Container Insights
En este punto ya tenemos toda la configuración desplegada en el cluster, los pods arrancados y estamos generando trazas que se envían a CloudWatch. Ahora podemos ir a la consola web que ofrece AWS para la sección de CloudWatch. En el apartado de logs/logs-groups podemos ver tanto los logs que está generando nuestra aplicación como los logs de performance relativos a la infraestructura que hemos levantado.
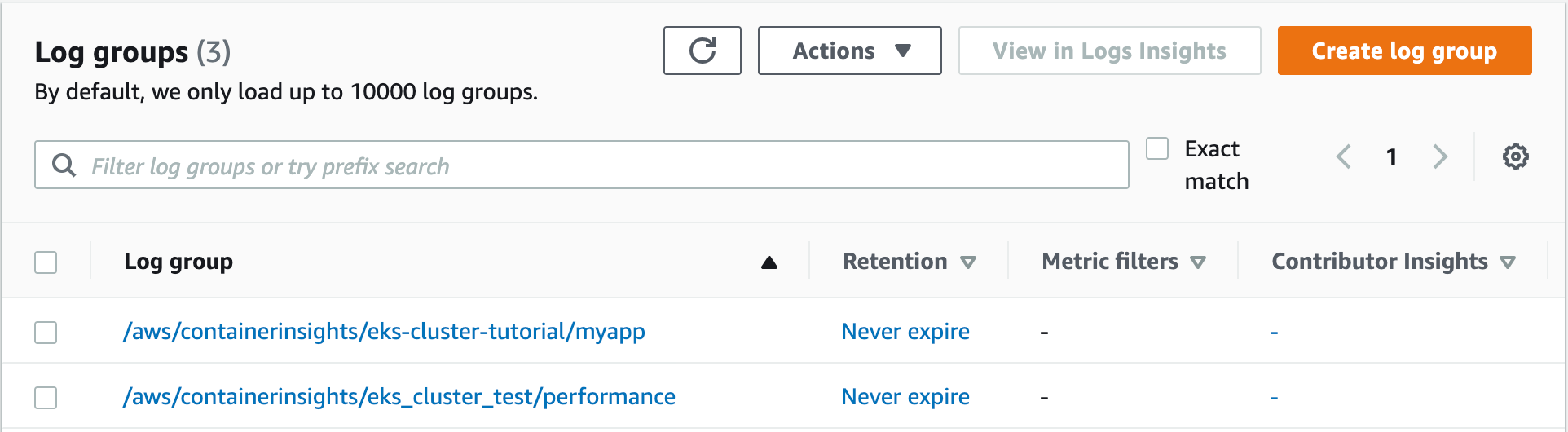
Si entramos en el log group podemos ver los logs unificados que están generando las aplicaciones. Como vemos en la siguiente imagen, desde el log group definido, somos capaces de consultar la información que generan las distintas aplicaciones para poder realizar análisis más eficientes y rápidos, sin tener que recorrer cada uno de los pods.
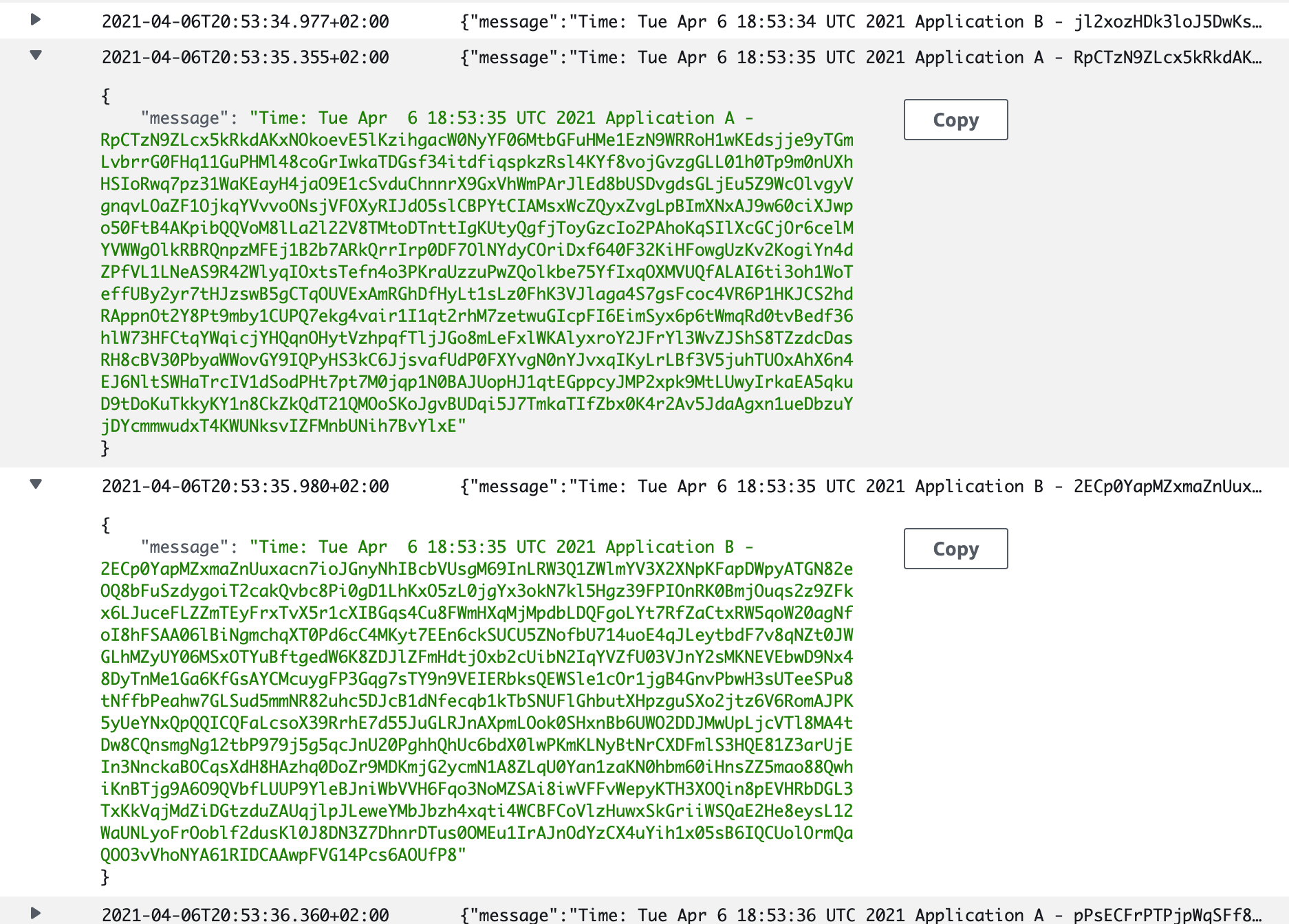
Aunque consolidar los logs ya es una gran ventaja por sí misma, el verdadero potencial de esta herramienta es que nos permite realizar consultas con una sintaxis propia similar a la que usamos en base de datos, que podemos consultar en CloudWatch Logs Insights Query Syntax – Amazon CloudWatch Logs.
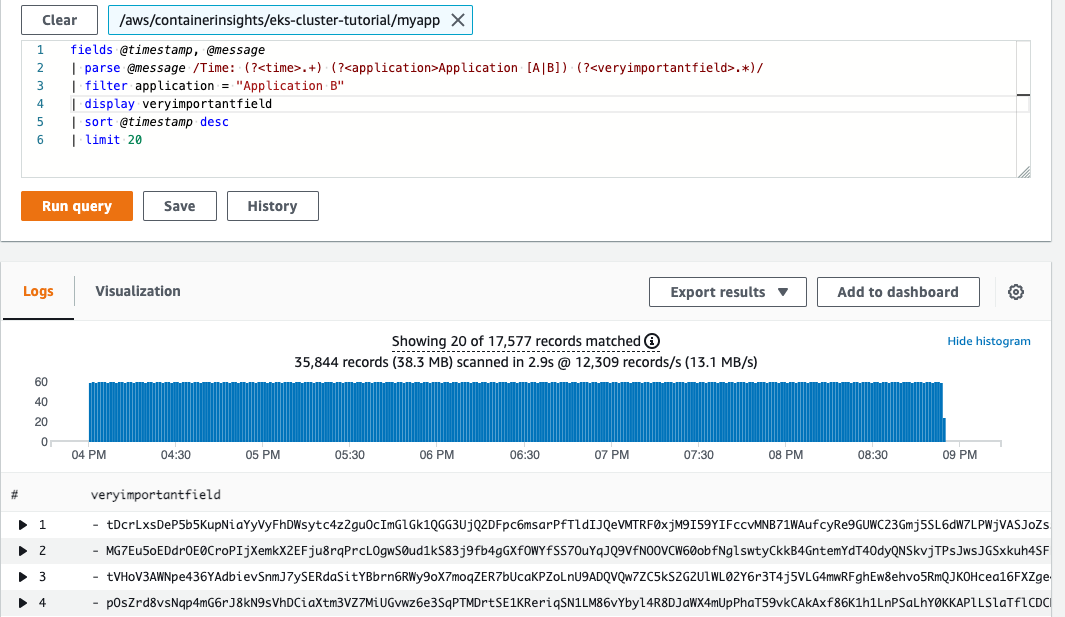
En la siguiente imagen mostramos cómo por medio de una expresión regular somos capaces de crear unos campos efímeros en base a grupos de captura para utilizarlos en filtros y seleccionar aquellos registros que nos interesen para los análisis. Permiten incluso el uso de funciones de agregación para calcular medias, máximos y mínimos, etc, tan útiles a la hora de evaluar tiempos de respuesta o procesamiento. Además, la propia herramienta de escaneado de registros muestra el volumen de datos que ha analizado, puesto que se tiene en cuenta a la hora de calcular el uso. En este caso, vemos que hay 1928 registros que ocupan 2,1MB.
Por otro lado, podemos ver en un dashboard las métricas de rendimiento que están generando nuestro cluster. Con ellos, somos capaces de analizar los datos a nivel de cluster, de namespaces, de servicios o incluso de los pods. Para eso, tenemos que dirigirnos a la sección de Container Insights para poder verlo.
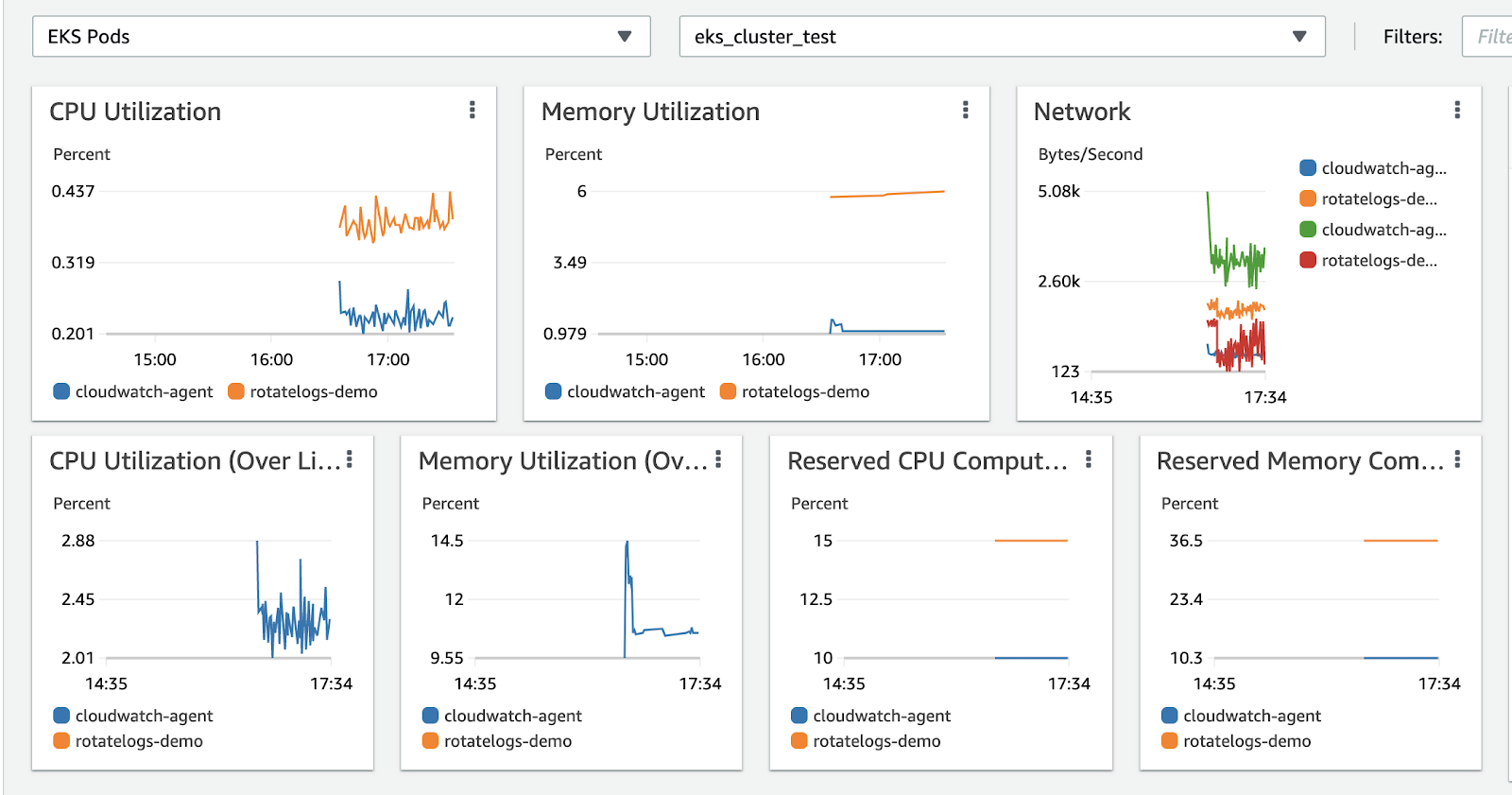
Recomendaciones y buenas prácticas
Con todo lo que hemos visto hasta ahora ya tenemos una idea del potencial de la herramienta. En base a la experiencia, os contamos las piedras del camino para que no os tropecéis.
No queráis correr a la hora de querer procesar todos los logs de vuestro sistema. Es preferible ir poco a poco, sobre todo al principio, hasta que os familiaricéis con la herramienta. Así podréis ser conscientes de cómo buscar y qué podéis encontrar en vuestros logs. De esta forma será más fácil evaluar cuáles son los logs que queréis tratar.
Utilizad los filtros temporales, que por algo los han incluido. Cuanto más pequeña sea la franja en la que busquemos, menos documentos se analizan y por lo tanto, menos repercute en el coste.
Ya estéis montando un sistema desde 0, migrando uno existente o lo tengáis en funcionamiento, invertid en normalizar lo más posible la estructura de los logs que vayan a depositarse en el mismo log group. Las queries que se lancen serán más sencillas, los filtros más efectivos, la información obtenida de mayor valor, y además las podemos guardar para reutilizarlas.
Para reducir al máximo el desperdicio y evitar sobrecostes, enviar únicamente los logs que sean útiles y que sea necesario explotar de esta manera. Por ejemplo, se puede configurar un appender específico para enviar únicamente las trazas de error, mientras que el resto de trazas operacionales o de menor valor se pueden recopilar por otros medios.
Conclusiones
Cuando usamos Kubernetes para desplegar las aplicaciones a veces resulta muy complicado localizar un log en concreto o incluso lo perdemos porque el pod se ha reiniciado en otro nodo, etc. Cuando tenemos que diagnosticar algún problema supone dedicar más tiempo a la detección de aquellos errores que están ocasionando anomalías en el sistema, por ejemplo.
Hemos visto que con CloudWatch somos capaces de centralizar toda esa información y explotarla para obtener de forma más rápida los registros que estamos buscando.
En general, es una buena herramienta normalmente infrautilizada que puede ayudarnos a gestionar de una manera eficiente toda la información producida por nuestras aplicaciones. Pero hay que tener cuidado si sólo queremos disfrutar de la capa gratuita, ya que si nos despistamos y hacemos mal el cálculo de la estimación del volumen de datos que van a generar las aplicaciones Amazon comenzará a cobrar por exceder los límites establecidos. Aunque el precio sea muy bajo, ya no es gratis, avisados estáis, y seguramente llegados a ese punto os compense coste/beneficio.

