

Índice de contenidos
- Introducción
- Entorno
- Instalar eksctl
- Instalar kubectl
- Crear el clúster Amazon EKS
- Configurar clúster
- Container Insights en Amazon EKS
- Automatizando la retención del grupo de registros
- Eliminación del clúster
- Conclusiones
Introducción
En este tutorial vamos a construir un clúster de Kubernetes con el objetivo de monitorizar y observar datos e información procesable de nuestra aplicación, utilizando los servicios de AWS (Amazon Web Services), en concreto Amazon CloudWatch, para así recopilar datos de monitorización y operaciones en formato de registros, métricas y eventos.
Por un lado, vamos a crear un clúster de Kubernetes mediante eksctl.
Por otro lado, vamos a implementar el servicio de CloudWatch Container Insights en dicho clúster para realizar tareas de monitorización, resolución de problemas y configuración de alarmas relacionadas con los microservicios y orquestadores. Además, Container Insights provee información de servicios de administración de contenedores, como Amazon ECS para Kubernetes (EKS), Amazon Elastic Container Service (ECS), AWS Fargate y Kubernetes (k8s).
Para el clúster de Amazon EKS, vamos a utilizar un agente FluentD preconfigurado para recopilar los registros de CloudWatch, los cuáles se pueden analizar en mayor profundidad con el lenguaje de consulta avanzado de CloudWatch Logs Insights.
También recordar que los servicios de AWS no son del todo gratuitos y que esta implementación puede generar costes adicionales. Influirá el tipo de instancia de Amazon EC2 y no salirse de los límites de la capa gratuita de Amazon CloudWatch.
Aún así, para evitar generar cargos inesperados, al finalizar eliminaremos las políticas asociadas de CloudWatch para forzar a que el sistema falle y, por último, eliminar el clúster.
Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 14 (2,2 GHz Intel Core i7, 16GB RAM).
- AWS CLI.
- eksctl.
- Amazon EC2.
- Amazon EKS.
- CloudWatch de Amazon.
- AWS Lambda.
- AWS CloudTrail.
Instalar eksctl
Antes de nada debemos saber que tanto eksctl como el AWS CLI requieren que tenga las credenciales de AWS configuradas en su entorno. Los pasos para crear una cuenta así como otras especificaciones de seguridad se pueden encontrar en este tutorial. Luego, debemos generar las claves para configurar los servicios necesarios de AWS CLI, esto lo puedes encontrar en otro tutorial de este blog.
Una vez hayamos terminado de configurar AWS, pasamos a crear el clúster de Amazon EKS mediante eksctl.
A continuación debemos instalar eksctl, una herramienta que nos permite automatizar muchas tareas individuales con los clusters de EKS. Los pasos para la instalación se pueden encontrar en la guía oficial de AWS para diferentes sistemas operativos (). En este caso, para instalarlo en macOS, basta con hacerlo mediante Homebrew con los siguientes comandos:
brew tap weaveworks/tap
Una vez terminado de instalar Weaveworks, debemos instalar eksctl mediante el siguiente comando:
brew install weaveworks/tap/eksctl
Por último, comprobamos su correcto funcionamiento mediante:
eksctl version
Instalar kubectl
Debes saber que Kubernetes utiliza una utilidad llamada kubectl para trabajar con los clusters de Kubernetes. De nuevo, los pasos para la instalación en diferentes sistemas operativos los puedes encontrar en la guía oficial, para instalarlo en macOS con la versión Kubernetes 1.18 debemos ejecutar el siguiente comando:
curl -o kubectl https://amazon-eks.s3.us-west-2.amazonaws.com/1.18.9/2020-11-02/bin/darwin/amd64/kubectl
Le damos permisos al binario:
chmod +x ./kubectl
Copiamos el binario a una carpeta en nuestro PATH:
mkdir -p $HOME/bin && cp ./kubectl $HOME/bin/kubectl && export PATH=$PATH:$HOME/bin
Por último, tras instalar kubectl, comprobamos que todo ha salido según lo esperado:
kubectl version --short --client
Crear el clúster Amazon EKS
Es necesario tener una versión de eksctl 0.33.0 o superior. Podemos crear el clúster usando un fichero de configuración yaml, pero para simplificar el proceso se hace uso de eksctl. ¡Al lío!, debemos modificar los siguientes parámetros:
eksctl create cluster --name <my-cluster> --version 1.18 --region <my-region> --nodegroup-name standard-workers --node-type <node-type> --nodes 2 --nodes-min 1 --nodes-max 2
Como vemos, establecemos el nombre del clúster (testeks) y en la región (eu-west-1), especificamos con nodegroup-name donde residen los pods. También indicamos el tipo de nodo t2.micro (este tipo de instancia no se recomienda en entornos productivos por su bajo rendimiento). Con nodes min y max se registran el número de nodos mínimo y máximo en caso de habilitar el autoescalado. Y en este ejemplo, no nos interesa configurar el ssh para el worker node.
Una vez modificado, ejecutamos el siguiente comando:
eksctl create cluster --name testeks --version 1.18 --region eu-west-1 --nodegroup-name standard-workers --node-type t2.micro --nodes 2 --nodes-min 1 --nodes-max 2
Comentar que tardará en torno a 15 minutos. Cuando el clúster esté listo, comprobaremos mediante kubectl si la configuración es correcta:
kubectl get svc
Si todo ha salido bien, veremos la siguiente salida:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 1m
Configurar clúster
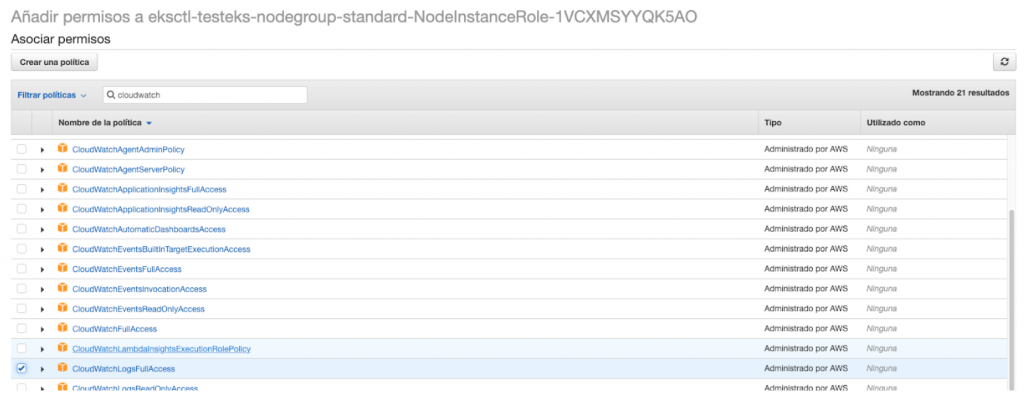
Tenemos un rol de IAM que fue creado por el eksctl pero no tiene las políticas de CloudWatch, tenemos que asociar la política para que los nodos puedan empezar a enviar logs a CloudWatch. Nos dirigimos al panel de instancias EC2 y añadimos el permiso CloudWatchLogsFullAccess a eksctl-testeks-nodegroup-standard-*.
Container Insights en Amazon EKS
Ya que está disponible para EKS, vamos a utilizar Container Insights para recopilar, resumir las métricas y registros de nuestra aplicación. También se puede establecer alarmas de CloudWatch en las métricas que recopila Container Insights.
Estos eventos de registro de rendimiento son entradas que utilizan un esquema JSON estructurado que permite incorporar y almacenar datos. A partir de estos datos, CloudWatch crea métricas agregadas a nivel de clúster, nodo, pod y servicio.
Debemos tener cuidado ya que las métricas recopiladas por Container Insights se cobran como métricas personalizadas. Para obtener más información acerca de los precios de CloudWatch puedes consultar aquí.
Para implementar Container Insights en Amazon EKS debemos ejecutar el siguiente comando:
curl https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluentd-quickstart.yaml | sed "s/{{cluster_name}}/cluster-name/;s/{{region_name}}/cluster-region/" | kubectl apply -f -
En este comando, cluster-name es el nombre de nuestro clúster EKS y, cluster-region el nombre de la región donde los logs son publicados. Modificamos los parámetros quedando así:
curl https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluentd-quickstart.yaml | sed "s/{{cluster_name}}/testeks/;s/{{region_name}}/eu-west-1/" | kubectl apply -f -
Si todo ha salido bien, se puede observar cómo se ha configurado el agente de Cloudwatch como un DaemonSet para enviar las métricas y, FluentD para enviar registros a CloudWatch Logs.
En este punto nos dirigimos al panel de navegación de Container Insights, elija Performance Monitoring. Podemos ver una serie de recursos específicos o seleccionar el tipo de recurso que deseas ver.
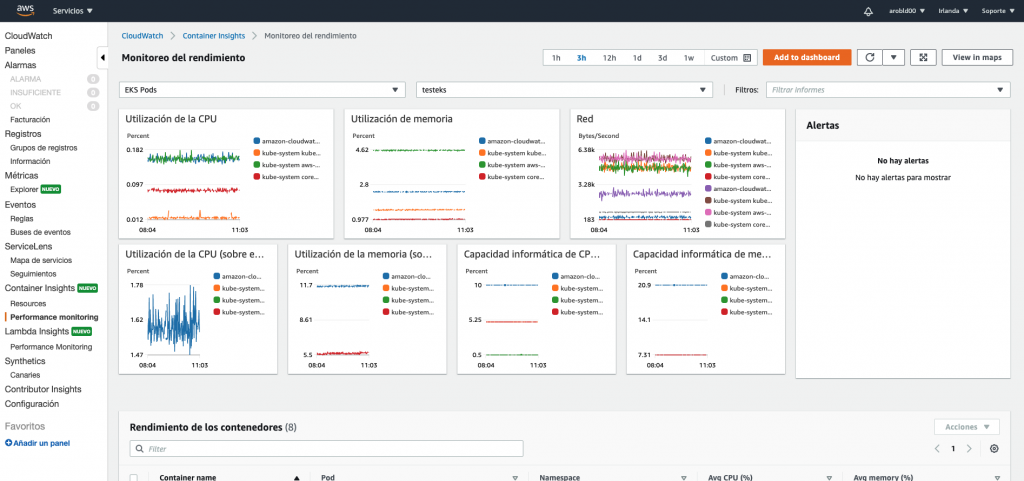
Las métricas que CloudWatch establece en EKS con Container Insight se pueden consultar aquí.
También podemos consultar los logs enviados mediante FluentD. Para ello nos dirigimos a Registros → Grupo de registros y en este caso, seleccionamos:
/aws/containerinsights/testeks/performance
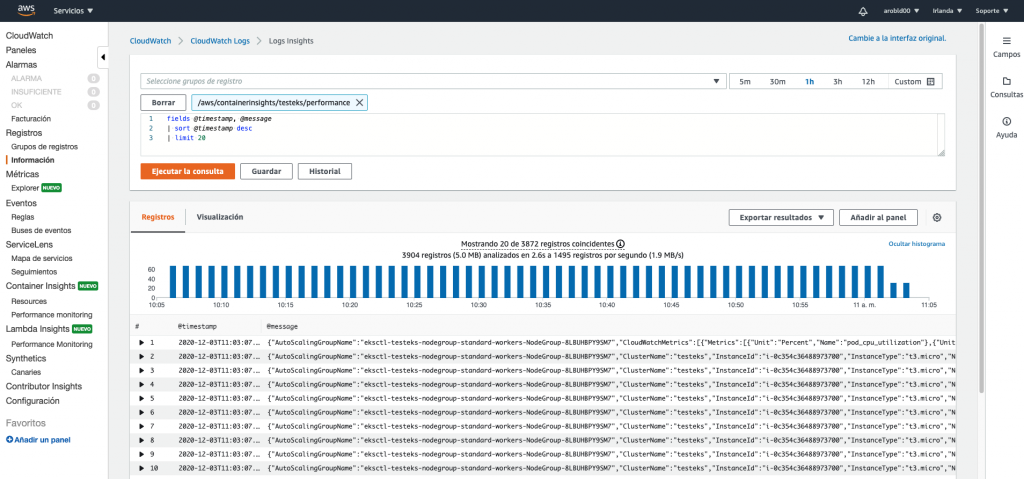
Además, CloudWatch no crea automáticamente todas las métricas posibles a partir de los datos de registro, podemos ver métricas adicionales y niveles adicionales de granularidad haciendo uso de CloudWatch Logs Insights para analizar los eventos de registro de rendimiento sin procesar.
Automatizando la retención del grupo de registros
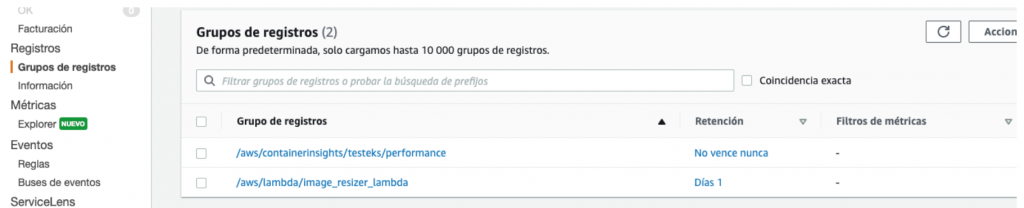
Podemos observar que los registros de CloudWatch se clasifican como “hot storage”, esto viene a decir que son mucho más costosos que otras opciones de almacenamiento como el S3.
Así que para obtener el máximo rendimiento de los registros de CloudWatch a un bajo coste, lo ideal es mover los registros más antiguos a S3 para una retención a largo plazo.
CloudWatch organiza los registros en un grupo de registros y cuando un nuevo grupo de registros es creado, su período de retención se establece a Never expire (No vence nunca), lo que significa que los registros se almacenan de forma indefinida.
Esto resulta un poco tedioso ya que uno de los principales objetivos es ahorrar costes. Para ello, una de las posibles soluciones es automatizar el proceso de creación de la infraestructura mediante Terraform, otra alternativa es hacer uso de CloudTrail. Para este tutorial nos apoyaremos en esta última alternativa.
Lo que logramos con esta automatización es que cuando se crea un nuevo grupo de registros de CloudWatch, se establece por defecto un tiempo de retención deseable para dicho grupo de registro. Después de ese tiempo de retención, todos los datos del flujo de registro del grupo serán eliminados automáticamente.
Cuando se crea un nuevo grupo de registro de CloudWatch, una regla de eventos dispara una función Lambda. Entonces, esta función establece un tiempo de retención para el grupo de registro de CloudWatch.
Lo primero que necesitamos es crear un rol IAM, así la Lambda tendrá acceso a otros recursos de AWS. Crea un rol IAM y asociarle la política de un servicio.
Ahora, creamos una función AWS Lambda, en el runtime establecemos Node.js 12.x como el lenguaje que quiere utilizar esta función y, cambiamos el rol de ejecución al previamente creado. Llegados a este punto debemos reemplazar el código de la función por este:
const AWS = require('aws-sdk');
const cloudwatchLogs = new AWS.CloudWatchLogs();
function setRetentionOfCloudwatchLogGroup(logGroupName, duration) {
let params = {
logGroupName : logGroupName,
retentionInDays: duration
};
return cloudwatchLogs.putRetentionPolicy(params).promise();
}
exports.handler = async (event) => {
const logGroupName = event.logGroupName ? event.logGroupName : event.detail.requestParameters.logGroupName;
try {
await setRetentionOfCloudwatchLogGroup(logGroupName, 14);
console.log('Retention has been set to ' + logGroupName + 'for 2 weeks');
return;
} catch(error) {
console.error(error);
throw error;
}
};
El siguiente paso es crear una regla de eventos de CloudWatch.
- Servicios de AWS → CloudWatch → Reglas → Crear una regla.
- En Origen del evento, elegimos Patrón de eventos y en nombre del servicio seleccionamos CloudWatch Logs. Como tipo de evento establecemos AWS API Call via CloudTrail (en caso de no tener configurado CloudTrail, debemos hacerlo). https://eu-west-1.console.aws.amazon.com/cloudtrail/home?region=eu-west-1#/
Aquí voy a hacer un pequeño paréntesis ya que te estarás preguntando el por qué del uso de CloudTrail. Básicamente, necesitamos detectar cuándo se crea un nuevo servicio en el historial de los eventos de actividad de la cuenta de AWS para así poder lanzar la Lambda y que modifique el periodo de retención. Con Cloudtrail se puede registrar, monitorear de manera continua y retener la actividad de la cuenta relacionada con acciones en toda su infraestructura de AWS.
- Una vez creado el trail, continuamos con la configuración. En operaciones específicas indicamos CreateLogGroup. En Destinos, seleccionamos Función Lambda y la función Lambda previamente creada.
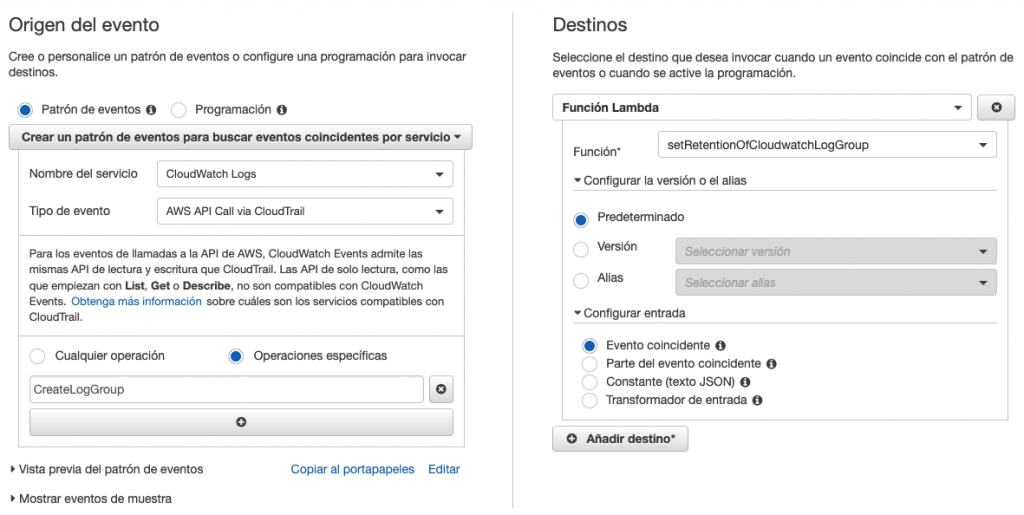
- Por último, damos un nombre, descripción (opcional) y estado (habilitado) y, le damos a crear regla.
Eliminación del clúster
Algunos de los servicios de AWS no son del todo gratuitos, recordar crear un presupuesto para la cuenta y activar una alerta para evitar que le cobren una cantidad de dinero no deseada.
Después, nos debemos dirigir a la consola del IAM y se deben eliminar las políticas de Cloudwatch asociadas para que el sistema falle.
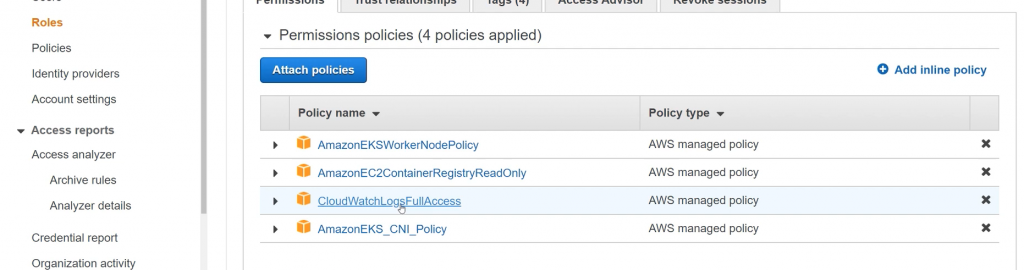
Por último, eliminamos el clúster.
eksctl delete cluster --name testeks
Conclusiones
Disponemos de un clúster de Kubernetes que está listo para algunos propósitos de prueba, investigación y aprendizaje. Hemos visto parte del ecosistema que envuelve a CloudWatch y cómo configurarlo, y cómo recopilar y resumir métricas mediante Container Insights.
Además, hemos visto la posibilidad de crear estructuras más complejas, por ejemplo, se hace uso de CloudTrail para monitorizar los eventos de la actividad de los usuarios y el uso de las API.
Por último, hemos automatizado la retención del grupo de registros de AWS CloudWatch para reducir sobrecostes. Ahora, lo ideal es mover los registros que se van a eliminar a S3 para una retención a largo plazo, pero eso es otra historia.

