

Os recuerdo que este tutorial forma parte de una colección de apuntes personales que estoy tomando de auto-formación en aprendizaje automático (no es una conclusión sino un camino).
- Instalación de TensorFlow y entorno de desarrollo Python en Mac.
- Revisión de ejemplos de TensorFlow.
- Principios de aprendizaje automático supervisado.
- Primeros pasos con Python: los tipos de datos básicos.
- Entendiendo un modelo de regresión lineal con TensorBoard.
En el anterior tutorial os presentaba cómo funciona TensorFlow y TensorBoard a través de un ejemplo muy simple de regresión lineal.
Ahora es el momento de empezar a complicar un poquito la cosa y hacer mis propios ejemplos para sacar conclusiones propias (y os quedaré agradecidos por la crítica constructiva).
Os recuerdo que partiremos de este tutorial y que no tenéis que instalar nada para poder utilizar estos ejemplos: Simplemente, ir a Colab y partiendo del ejemplo base, ir cambiando lo que os interese.
Vamos a mostrar poco a poco el código. Lo primero que hacemos es inicializar TensorFlow y TensorBoard. Esto no tiene nada de particular.
Y ahora vamos a hacer una pequeña variación. En vez de generar datos de una recta vamos a generar dos rectas, con pendientes distintas, y ver cómo se comporta en modelo de entrenamiento, para posteriormente tratar de realizar modificaciones y conseguir que las predicciones cuadren con lo esperado.
data_size = 1000
train_pct = 0.8
train_size = int(data_size * train_pct)
# Creamos un espacio lineal de datos entre -3 y 3
x = np.linspace(-3, 3, data_size)
#creamos una array vacio donde asignar los calores de Y
y = np.array([])
#desordenamos los valores de X para que la muestra tenga de las dos gráficas no consecutivas
np.random.shuffle(x)
from numpy import random
valor = 0
#Si el valor de X es 1 usamos una ecuación para Y y sino usamos otra
for elemento in x:
ruido = random.uniform(0, 0.05)
if elemento <= 1:
valor = 0.5 * elemento + 2 + ruido
else:
valor = 2 * elemento + 4 + ruido
y = np.append (y,valor)
# Generamos los juegos de datos de entrenamiento y prueba
x_train, y_train = x[:train_size], y[:train_size]
x_test, y_test = x[train_size:], y[train_size:]
# Importamos la librería de gráficos
import matplotlib.pyplot as plt
#plt.hist (y_test)
# Mostramos los datos
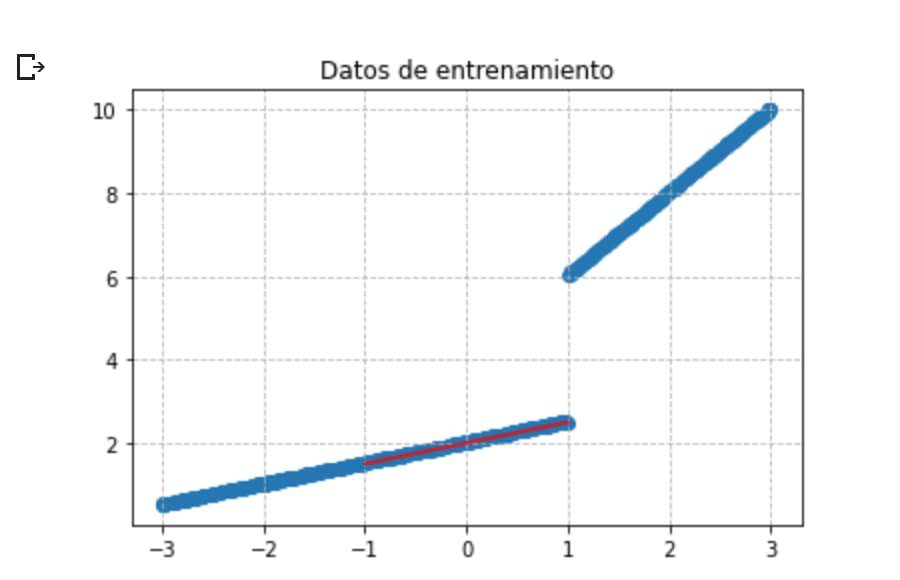
plt.scatter(x_train,y_train)
plt.title('Datos de entrenamiento')
plt.grid(alpha =.9, linestyle ='--')
plt.plot([-1, 1], [0.5 * -1 + 2 , 0.5 * 1 + 2],color ='red')
plt.show()
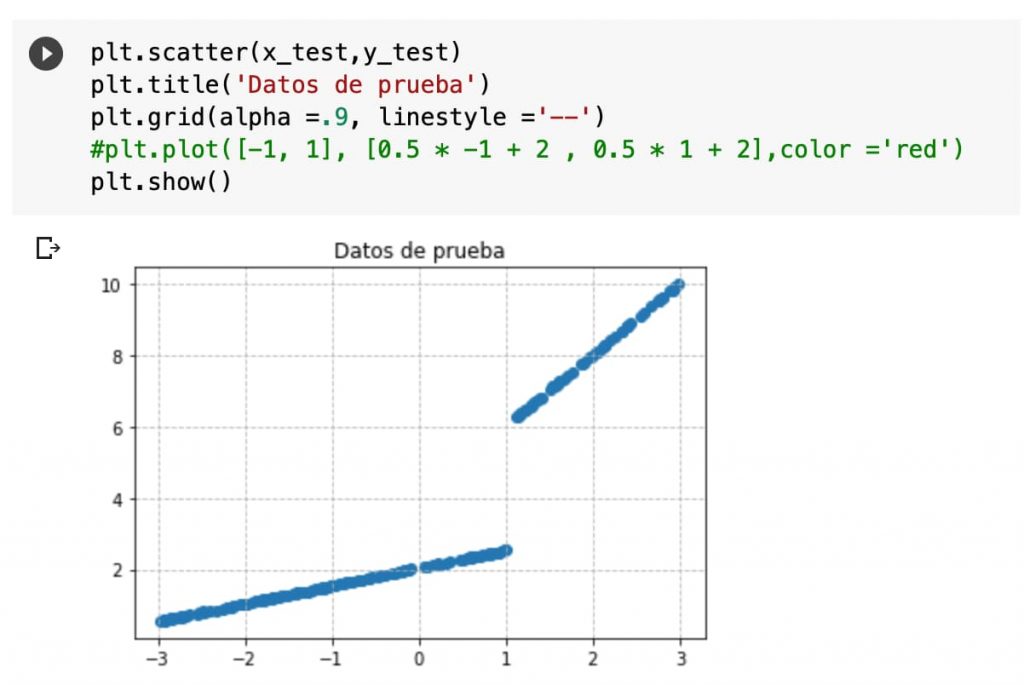
Y vemos los datos de Test también:
Voy a hacer un pequeño lapsus de teoría aquí.
Os invito a revisar este enlace sobre regresión polinómica en TensorFlow para entender los grados.
En el siguiente enlace podéis ver la representación de múltiples ecuaciones (que muchos hemos estudiado pero a ver quién se acuerda).
Y utilizamos el mismo código para hacer el entrenamiento:
# Configuramos los logs para poderlos utilizar en TensorBoard mediante callbacks
logdir = "logs/scalars/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir)
# Revisar los tipos de callbacks https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/
Ahora sería buen momento para estudiar cómo construir un modelo secuencial.

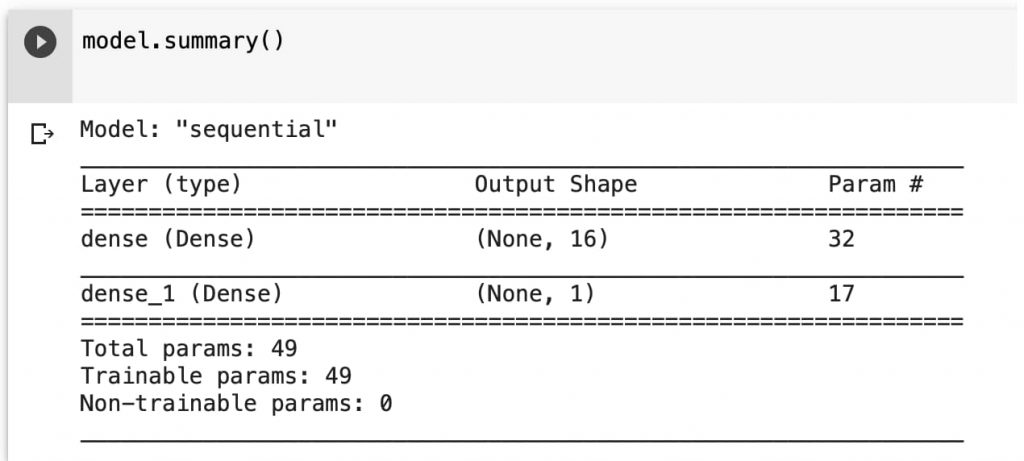
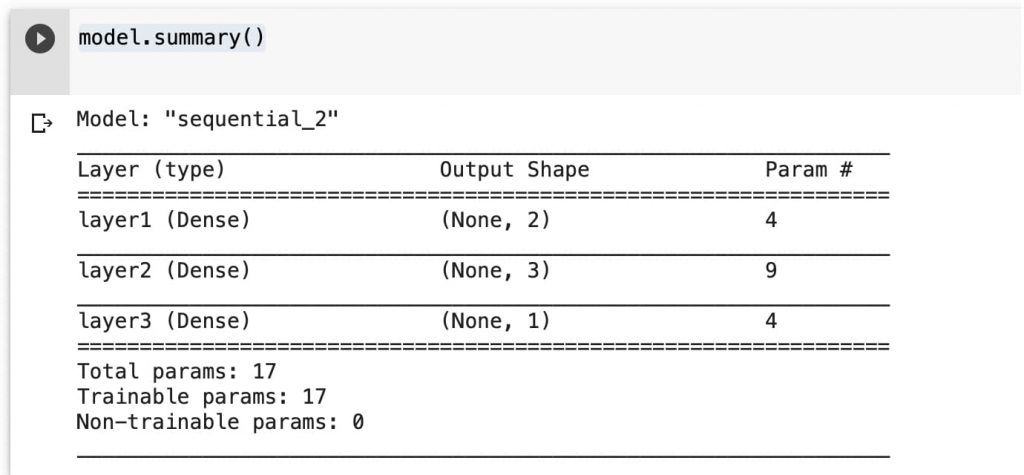
# Configuramos un modelo secuencia básico model = keras.models.Sequential([ keras.layers.Dense(16, input_dim=1), keras.layers.Dense(1), ]) model.summary()
Podemos visualizar el sumario de la red que tenemos:
Y también podemos visualizar el modelo gráficamente.
keras.utils.plot_model(model, 'representacion.png', show_shapes=True)

Ahora compilamos el modelo y lo entrenamos.
# Configuramos y establecemos un modelo de regresión lineal con un salto de 0.2
model.compile(
loss='mse', # keras.losses.mean_squared_error
optimizer=keras.optimizers.SGD(lr=0.02), )
# Configuramos y entrenamos el modelo
training_history = model.fit(
x_train, # input
y_train, # output
batch_size=train_size,
verbose=2, # Suppress chatty output; use Tensorboard instead
epochs=10,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback], )
# Mostramos la perdida media
print("Average test loss: ", np.average(training_history.history['loss']))
# Visualizamos el error
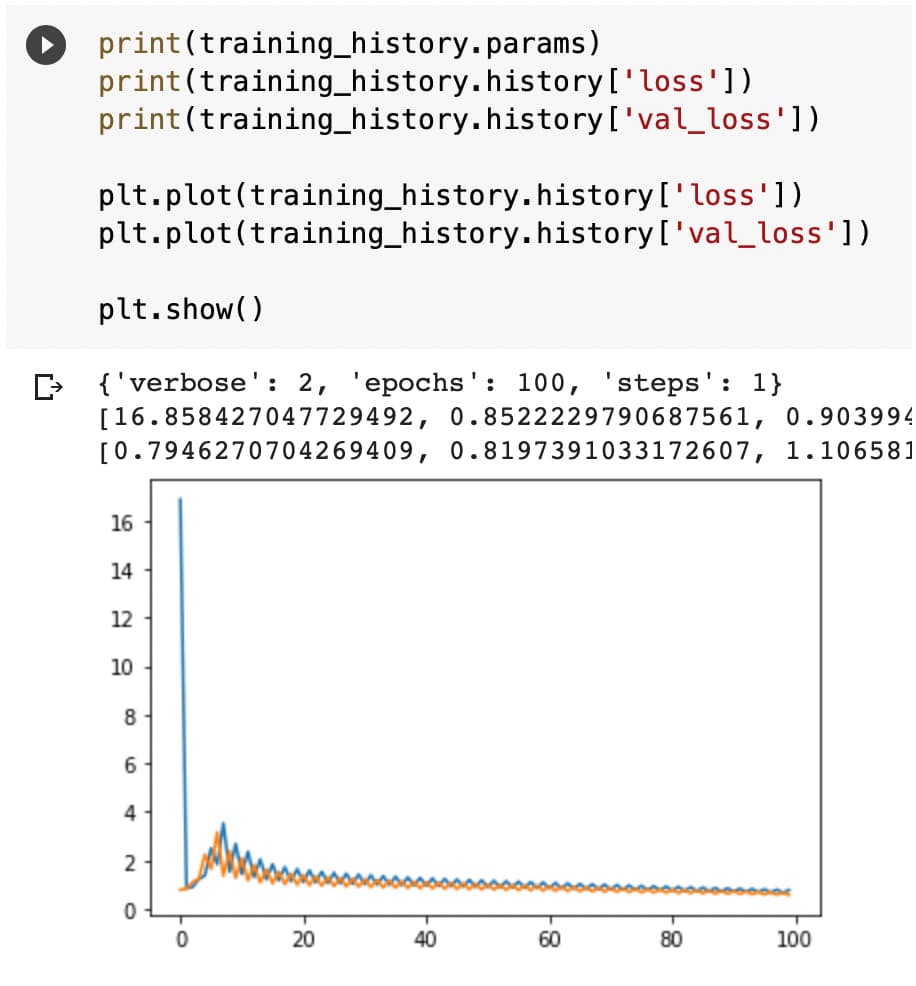
print(training_history.params)
print(training_history.history['loss'])
print(training_history.history['val_loss'])
plt.plot(training_history.history['loss'])
plt.plot(training_history.history['val_loss'])
# Pintamos la gráfica
plt.show()
Vemos las gráficas sobre cómo funciona la pérdida… que se nos va.
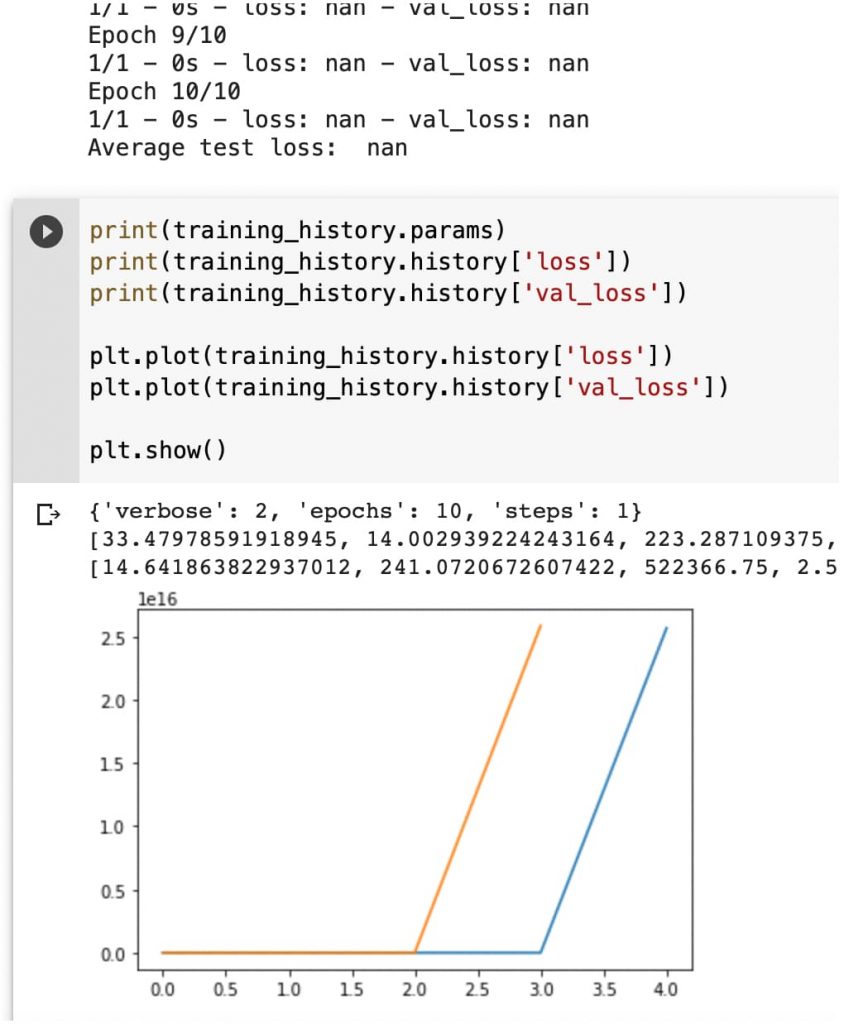
Y podemos ver que algo no funciona demasiado bien porque el error tiende a infinito.
Por tanto, los parámetros de configuración que podemos manejar hasta ahora no son satisfactorios.
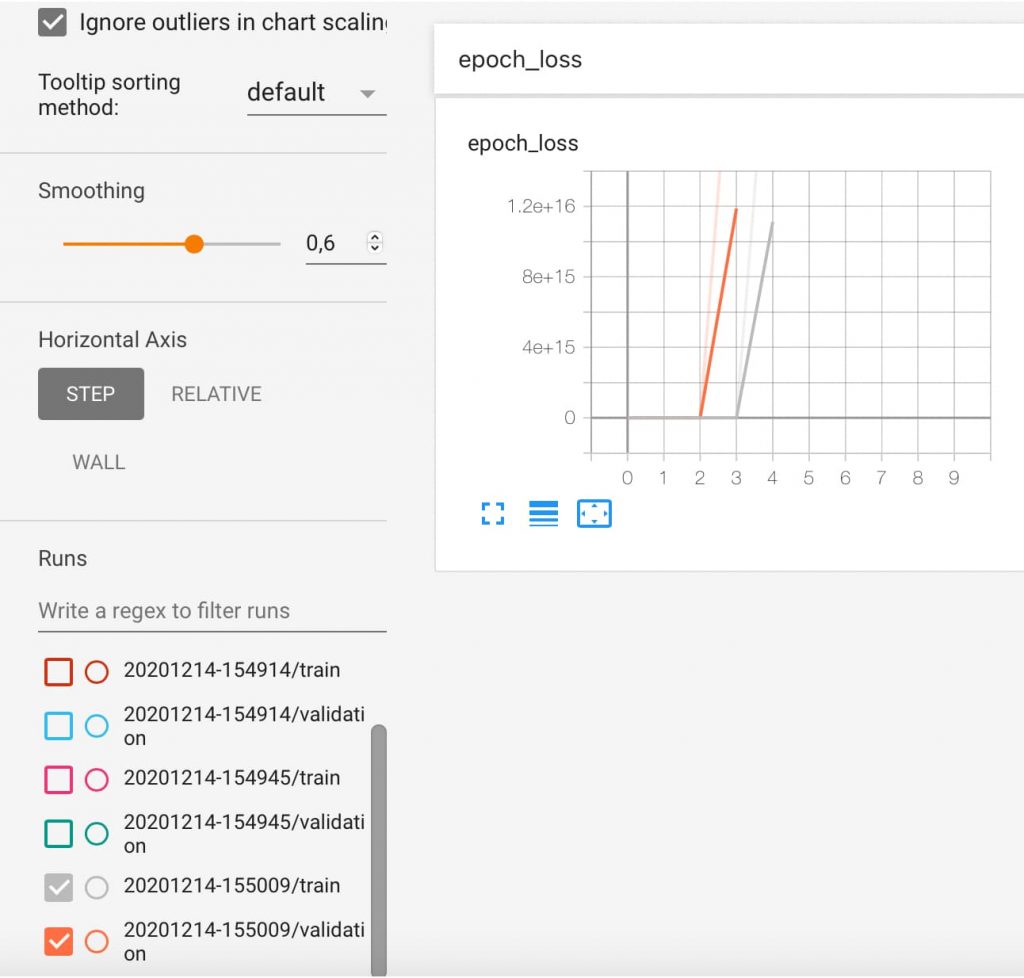
El sistema no es capaz de predecir los resultados.
Podemos actuar por ahora en varios puntos:
- El coeficiente de aprendizaje.
- Las capas de la red.
- La ecuación de activación.
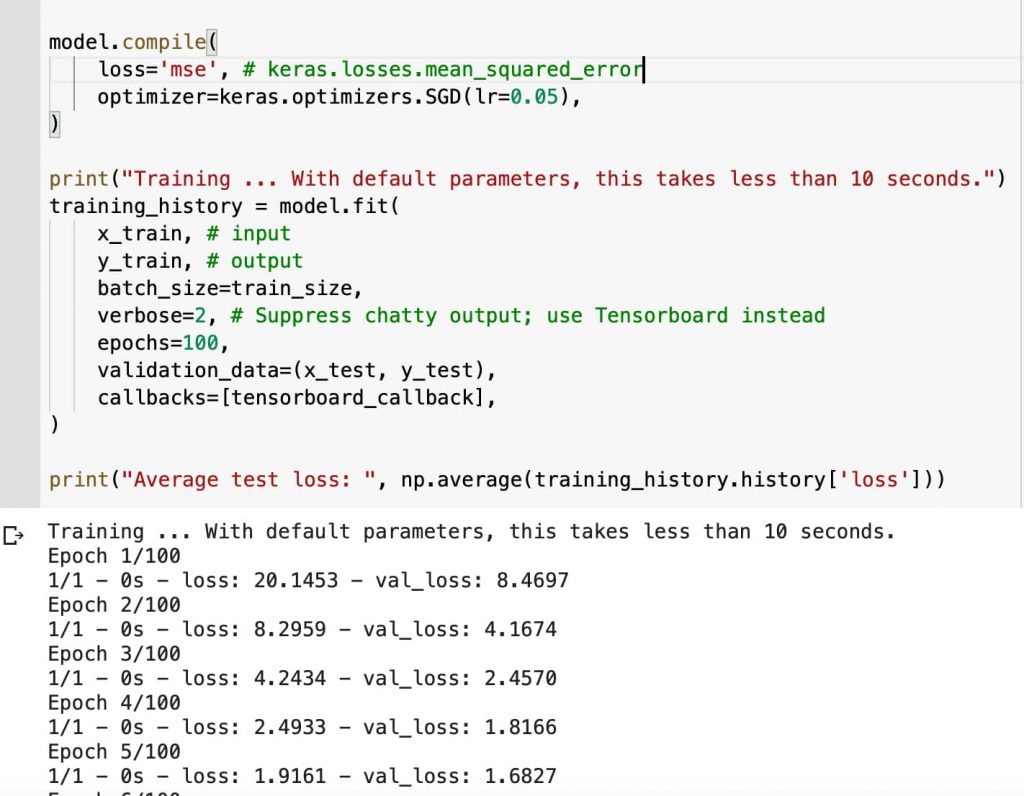
Vamos a empezar a actuar en el coeficiente de aprendizaje que nos hace sospechar que es muy grande y lo podemos intentar bajar.
Se pueden hacer varias pruebas: bajándolo una dimensión y luego ir incrementándolo contrastando resultados de pérdida.

Y obtenemos el siguiente resultado:
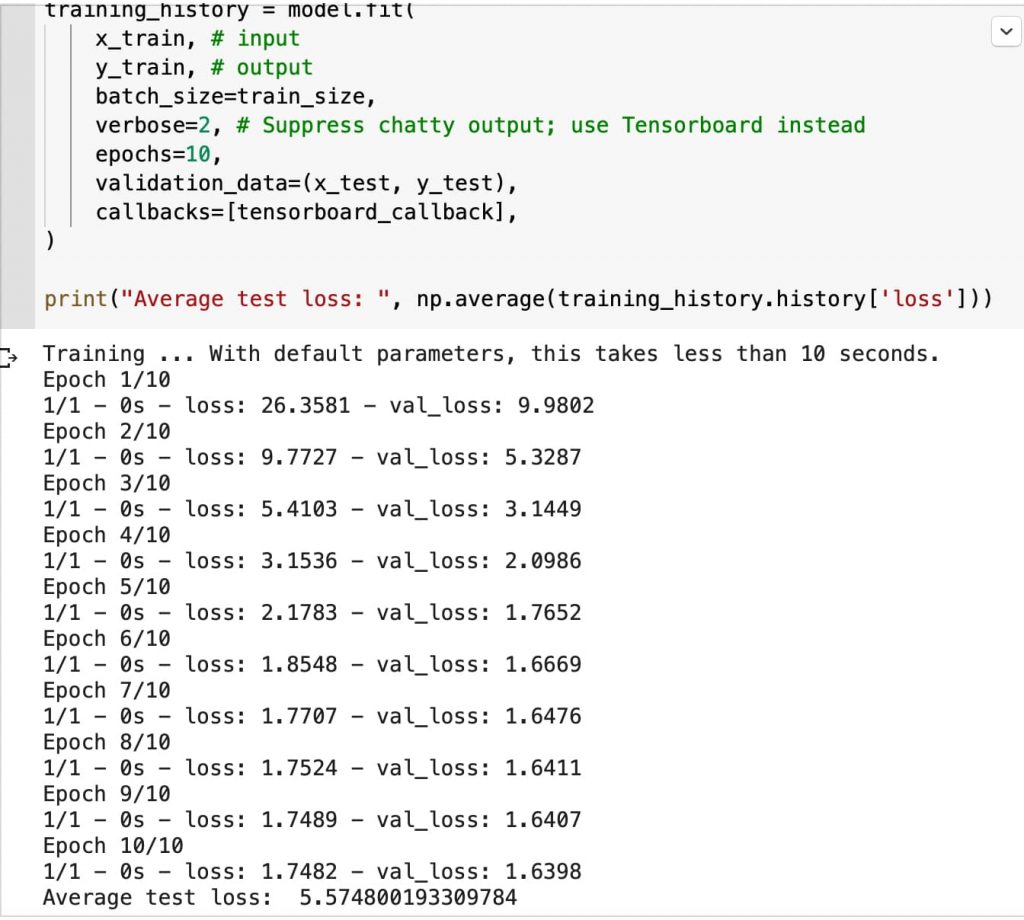
Superados ciertos intentos la cosa no mejora y la perdida total media es de 5.5.
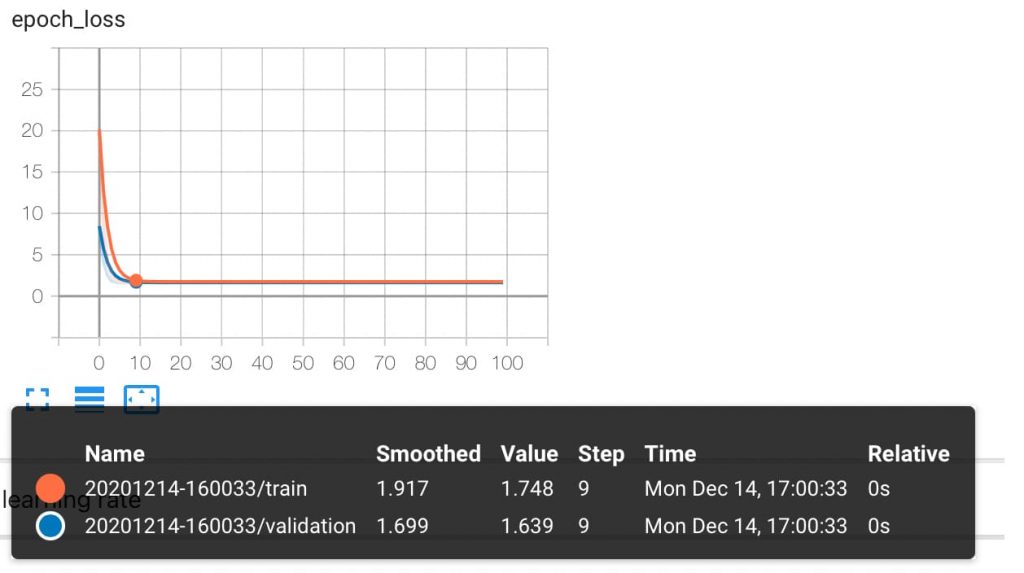
Vemos los valores que obtenemos de la predicción.

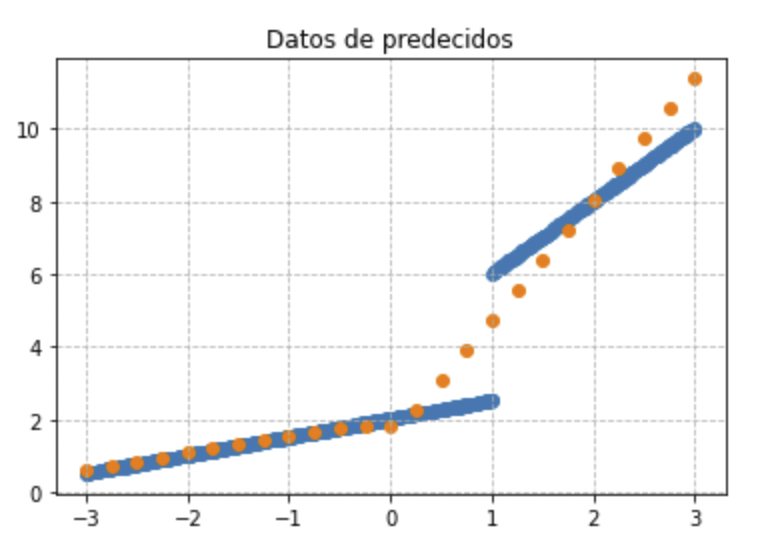
Vamos a buscar un método simple para pintar un espacio vectorial de 25 puntos y calcular su predicción, para ver visualmente la relación que hay entre los datos iniciales de entrenamiento y predicciones.
datosPrediccion = np.linspace(-3, 3, 25)
resPrediccion = model.predict(datosPrediccion)
print("x",datosPrediccion)
print("y",resPrediccion)
plt.title('Datos de predecidos')
plt.grid(alpha =.9, linestyle ='--')
plt.scatter(x_train,y_train)
plt.scatter(datosPrediccion,resPrediccion)
plt.show()
Esta gráfica nos va a permitir hacernos una mejor idea de lo que está pasando:
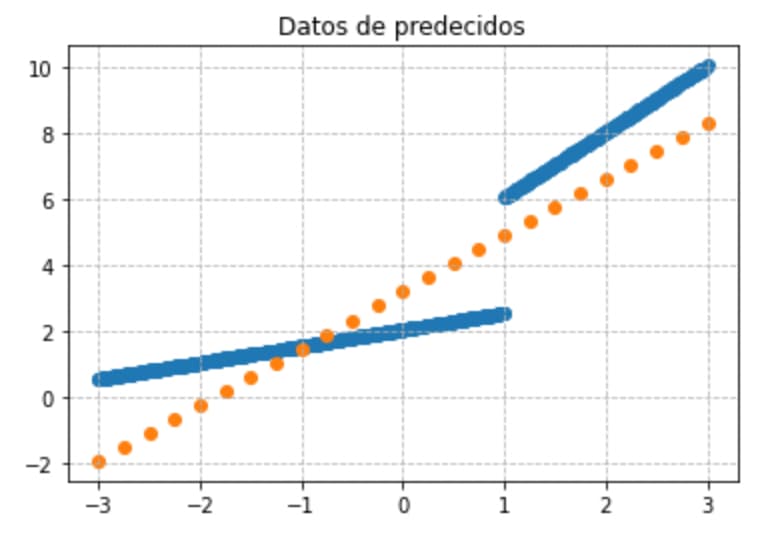
Podemos continuar con el ejemplo cambiando los coeficientes de entrenamiento a mano subiéndolos y bajándolos un poco. También podemos cambiar el ratio de entrenamiento dinámicamente.
logdir = "logs/scalars/" + datetime.now().strftime("%Y%m%d-%H%M%S")
file_writer = tf.summary.create_file_writer(logdir + "/metrics")
file_writer.set_as_default()
def lr_schedule(epoch):
"""
Returns a custom learning rate that decreases as epochs progress.
"""
learning_rate = 0.05
if epoch > 10:
learning_rate = 0.02
if epoch > 20:
learning_rate = 0.001
if epoch > 50:
learning_rate = 0.001
tf.summary.scalar('learning rate', data=learning_rate, step=epoch)
return learning_rate
lr_callback = keras.callbacks.LearningRateScheduler(lr_schedule)
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir)
model = keras.models.Sequential([
keras.layers.Dense(16, input_dim=1),
keras.layers.Dense(1),
])
model.compile(
loss='mse', # keras.losses.mean_squared_error
optimizer=keras.optimizers.SGD(),
)
training_history = model.fit(
x_train, # input
y_train, # output
batch_size=train_size,
verbose=2, # Suppress chatty output; use Tensorboard instead
epochs=100,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback, lr_callback],
)
Y comprobamos que hemos mejorado la pérdida media.

Por lo que parece que modificando el ratio de aprendizaje, solamente obtenemos una mejora parcial. Ahora vamos a modificar la complejidad de la red para ver si mejoramos.
Intuitivamente si añadimos una capa más se produce una “multiplicación de una transformación por otra” lo que provocará una adaptación a las rectas con una curva más compleja”.
Os invito a que re-visitéis ahora el entrenador de TensorFlow para comprender mejor cómo afecta introducir complejidad en la red neuronal y modificar la función de activación y ratio de aprendizaje.
Modificamos la red.
logdir = "logs/scalars/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=logdir)
from tensorflow.keras import layers
# Define Sequential model with 3 layers model = keras.Sequential(
[
layers.Dense(2, activation="relu", name="layer1"),
layers.Dense(3, activation="relu", name="layer2"),
layers.Dense(1, name="layer3"),
]
)
Comprobamos la nueva red montada.
Compilamos y revisamos.
model.compile(
loss='mse', # keras.losses.mean_squared_error
optimizer=keras.optimizers.SGD(lr=0.04),
)
training_history = model.fit(
x_train, # input y_train, # output
batch_size=train_size,
verbose=2, # Suppress chatty output; use Tensorboard instead
epochs=100, validation_data=(x_test, y_test),
callbacks=[tensorboard_callback], )
print("Average test loss: ", np.average(training_history.history['loss']))
Y vemos que la curva tiene otra pinta.
Y esta es la adaptación entre la predicción y las muestras, que va teniendo ya mejor aspecto (considerando que siempre hará un error o sobre-adaptación).
Ahora vamos a aumentar en número de núcleos a 16 en la segunda capa.

Visualizando la nueva red.
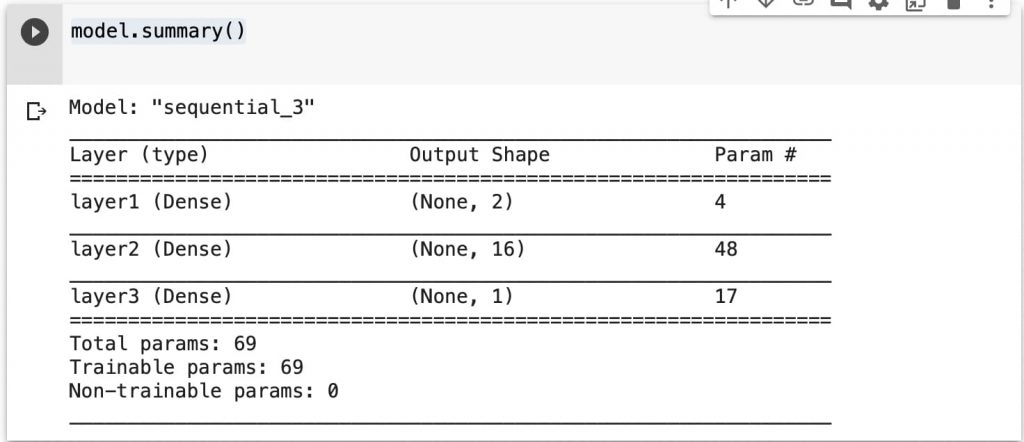
Y comprovamos que se suaviza la curva anterior.
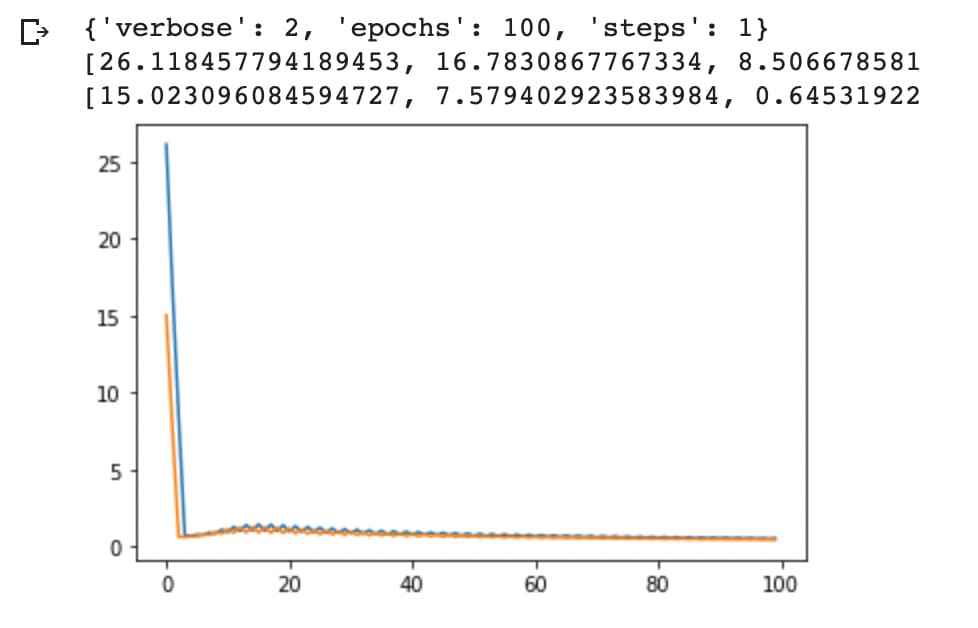
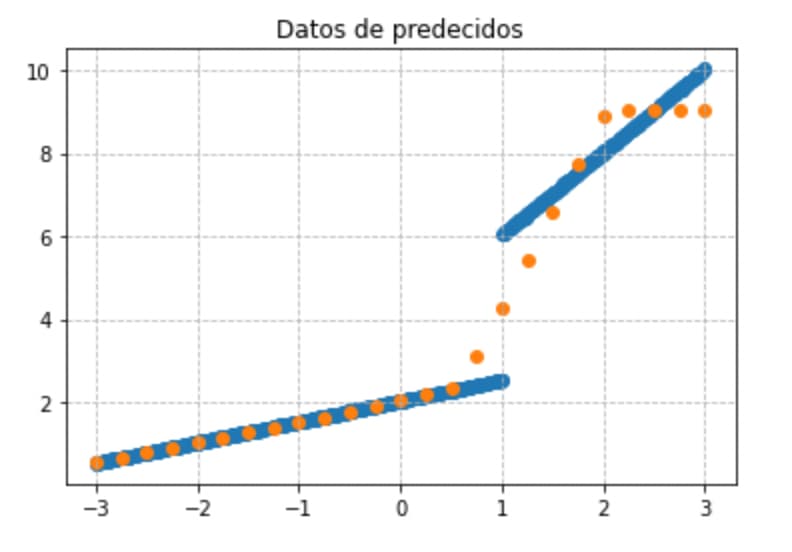
Aunque la adaptación no es la más satisfactoria.
Pero ahora vamos a hacer un pequeño cambio, modificar la función de activación de la segunda capa a “selu”.
from tensorflow.keras import layers
# Define Sequential model with 3 layers
model = keras.Sequential(
[
layers.Dense(4, activation="relu", name="layer1"),
layers.Dense(16, activation="selu", name="layer2"),
layers.Dense(1, name="layer3"),
]
)
model.compile(
loss='mse', # keras.losses.mean_squared_error
optimizer=keras.optimizers.SGD(lr=0.04),
)
Os invito ahora a visitar este enlace donde podéis ver ejemplos de código con regresión polinomial.
Podemos ver la función de activación selu en el siguiente enlace.

Y podemos comprobar con TensorBoard la pérdida, que es la mejor que hemos podido obtener hasta ahora.
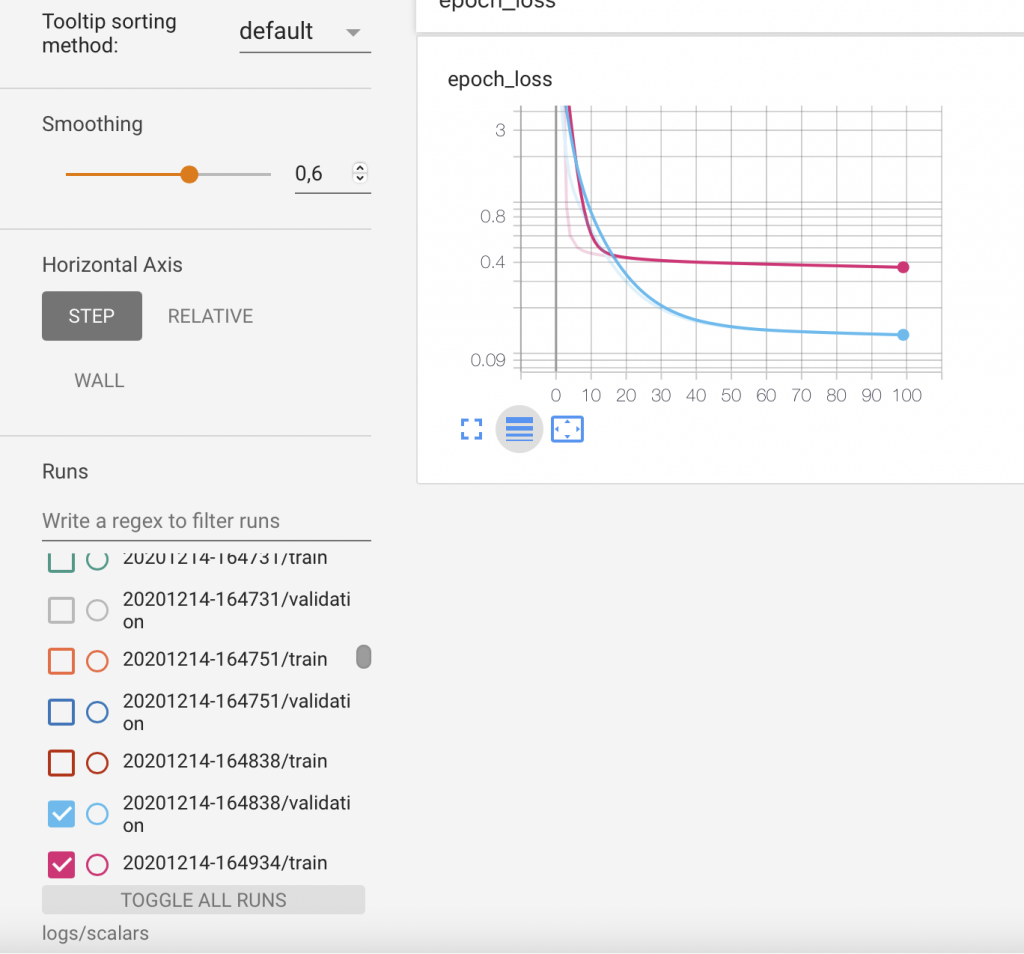
Y esta es la adaptación de la curva a las rectas.
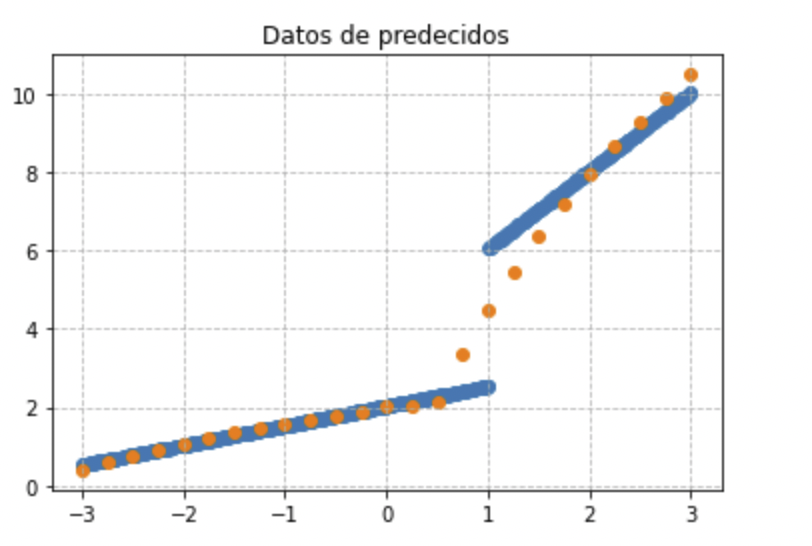
Con el nivel de conocimiento que tengo hasta ahora, es lo mejor que he podido conseguir. Tendremos que seguir investigando sobre los posibles parámetros a actuar y posibles soluciones a un mismo problema.
Os invito a tocar y proponerme mejoras sobre el modelo que es cómo se aprende.

