

- Introducción
- Entorno
- Configurar una cuenta de AWS
- Instalar Terraform
- Configurar Terraform
- Configurar el bucket de S3
- Configurar el servidor SFTP en EC2
- Conclusiones
- Recursos
Introducción
En este tutorial vamos a construir un servidor SFTP utilizando los servicios de AWS (Amazon Web Services) para dar soporte a la infraestructura y Terraform para automatizar la creación de la misma.
Por un lado, vamos a iniciar una instancia de Amazon EC2 (Elastic Compute Cloud) donde se va a configurar el servidor SFTP.
Por otro lado, vamos a crear un bucket en Amazon S3 (Simple Storage Service) donde se van a almacenar los datos a los que accedamos desde el servidor SFTP. Para ello, tendremos que montar el bucket S3 dentro de nuestra instancia de EC2. Es cierto que Amazon ofrece un servicio para acceder a S3 mediante SFTP llamado Transfer Family pero si vemos el precio nos damos cuenta de que es bastante más caro de lo que puede costar esta solución con EC2 (evidentemente no tendremos exactamente el mismo servicio, pero si algo sólido con lo empezar).
Vamos a automatizar la creación de esta infraestructura utilizando Terraform, un software desarrollado por HashiCorp que nos permite escribir infraestructura como código.
Antes de comenzar con el tutorial, quiero recordar que los servicios de AWS no son completamente gratuitos y que estas pruebas pueden generar gastos. Se puede consultar lo que incluye la capa gratuita (https://aws.amazon.com/es/free/) pero, aún así, cualquier recurso que se salga de esta capa será cobrado.
Todo el código del tutorial se puede encontrar en el siguiente repositorio en GitHub: https://github.com/julenminer/aws_terraform_micronaut.
Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro 14 (2,2 GHz Intel Core i7, 16GB 1600 MHz DDR3, 500GB Flash Storage)
- AWS CLI versión 2
- Amazon EC2
- Amazon S3
- S3FS-Fuse versión 1.87
- VSFTPD versión 3.0.3
- Terraform versión 0.13.5
Configurar una cuenta de Amazon Web Services
El primer paso de este tutorial es crear una cuenta de Amazon Web Services (AWS) y configurarla en nuestro ordenador, lo que nos permitirá probar las especificaciones que vayamos escribiendo en Terraform. Los pasos para crear una cuenta, así como otras recomendaciones de seguridad los podemos encontrar en otro tutorial de este blog. Una vez hayamos terminado, tenemos que generar las claves que darán acceso a Terraform para configurar los servicios necesarios. Estas claves las encontraremos en la consola de AWS, pulsando sobre nuestro nombre en la barra superior y pulsando sobre “Mis credenciales de seguridad”.

Después abrimos el apartado de “Claves de acceso” y pulsamos sobre “Crear una clave de acceso”. Cuando la hayamos, debemos guardar el identificador y la clave secreta.
A continuación debemos instalar AWS CLI, que permitirá a Terraform hacer los cambios. Los pasos para la instalación se pueden encontrar en la guía oficial de AWS para diferentes sistemas operativos (https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2.html). Para instalarlo en macOS, basta con hacerlo con Homebrew con el siguiente comando:
brew install awscli
Una vez hemos terminado de instalar AWS CLI, debemos configurarlo con el siguiente comando:
aws configure
Nos pedirá los datos de configuración. El primero es el identificador de la clave de acceso que hemos generado. El segundo es la clave secreta. El tercero es el nombre de la región de AWS que queramos establecer por defecto, en este tutorial será “eu-west-1” que corresponde a la región de Irlanda. Finalmente, el último dato es el formato en el que queramos los outputs de AWS CLI, pondremos “json”.
Instalar Terraform
Para instalar Terraform, podemos seguir los pasos de su guía oficial. En este caso, se van a seguir los pasos para instalarlo en macOS utilizando Homebrew.
El primer paso es instalar el repositorio de HashiCorp con el siguiente comando:
brew tap hashicorp/tap
Después podemos instalar Terraform:
brew install hashicorp/tap/terraform
Con esto ya debería estar instalado. Lo podemos comprobar accediendo a la ayuda de Terraform con el siguiente comando:
terraform -help
Configurar Terraform
Antes de empezar a crear los ficheros Terraform, vamos a crear un directorio de trabajo para tener todos los archivos en un mismo lugar. Una vez lo hayamos creado, el primer archivo será el de configuración de AWS, le llamaremos setup.tf (el nombre puede ser distinto). Cuando tengamos el archivo creado en el directorio, debemos especificar el provider que vamos a utilizar, en este caso AWS, y el perfil de la cuenta de AWS, en este caso con el nombre “default”, aunque se podría poner uno diferente y hasta tener en nuestro ordenador varios perfiles configurándolos con AWS CLI. También podemos especificar las claves de acceso en este fichero en vez de configurarlas en AWS CLI. El contenido de setup.tf es el siguiente:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 2.70"
}
}
}
# Configure AWS account settings
provider "aws" {
profile = "default"
region = var.region
}
Como vemos, también se especifica la región haciendo uso de una variable. Para ello, vamos crear un fichero con variables al que llamaremos variables.tf. En este fichero añadimos la variable con la región:
variable "region" {
default = "eu-west-1"
}
Una vez hemos añadido estos dos ficheros, debemos ejecutar el comando de inicialización de Terraform para que descargue el proveedor de AWS. Esto generará una carpeta .terraform en el directorio de trabajo. El comando es el siguiente:
terraform init
Configurar el bucket de S3
Para configurar el bucket creamos un fichero llamado S3_bucket_config.tf y comenzamos su configuración. Lo primero que añadimos al fichero es el recurso de S3:
resource "aws_s3_bucket" "test_bucket" {
bucket = var.bucket_name
}
A la hora de generar un recurso, se debe especificar el recurso que queremos, que es el primer parámetro (“aws_s3_bucket”) y después el identificador para que podamos hacer referencia a este recurso (“test_bucket”). Como vemos, estamos haciendo uso de otra variable, por lo que debemos ir al fichero variables.tf que hemos creado anteriormente y añadir la siguiente variable, cambiando <BUCKET_NAME> por el nombre que queramos que tenga nuestro bucket:
variable "bucket_name" {
default = "<BUCKET_NAME>"
}
A la hora de elegir el nombre del bucket, es importante recordar que debe ser único en todo AWS, es decir, nadie debe haber creado antes un bucket con el mismo nombre. Si elegimos un nombre que ya existe, nos puede dar problemas a la hora de aplicar el código de Terraform en AWS.
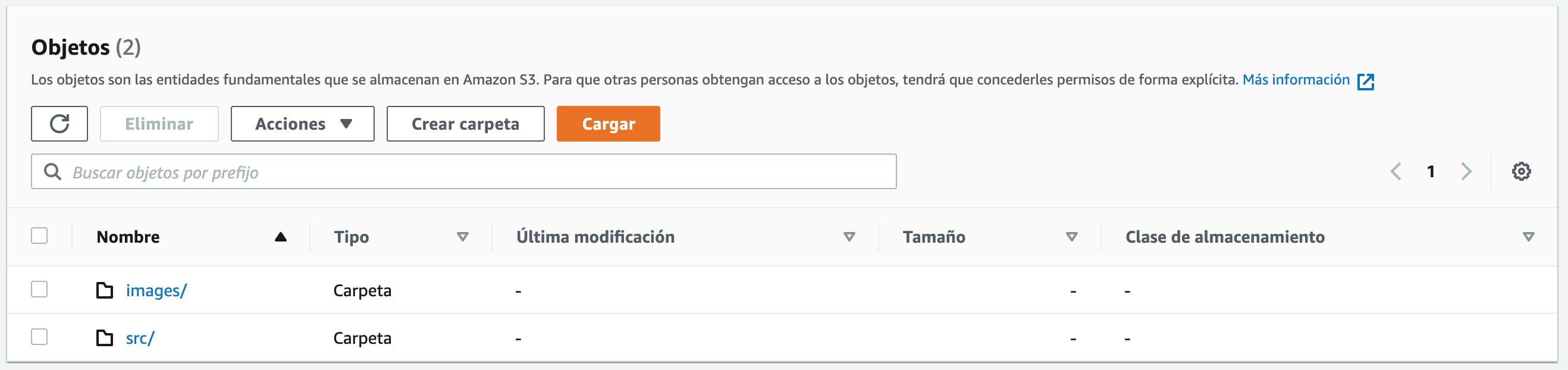
Con esta configuración ya podríamos crear el bucket pero a modo de ejemplo vamos a crear dos carpetas dentro de nuestro bucket. Para ello, volvemos al fichero de configuración de S3 (S3_bucket_config.tf) y añadimos los siguientes recursos:
resource "aws_s3_bucket_object" "src_folder" {
bucket = aws_s3_bucket.images_bucket.id
key = "src-images/"
}
resource "aws_s3_bucket_object" "images_folder" {
bucket = aws_s3_bucket.images_bucket.id
key = "images/"
}
Con esto hemos creado dentro de nuestro bucket (podemos ver que hacemos referencia a él) una carpeta src y otra carpeta images.
En el ejemplo se hace referencia a otro recurso en Terraform, lo que nos permite enlazar diferentes servicios. Es importante saber que las configuraciones de Terraform, al hacerse de forma declarativa, hacen que el orden en el que se especifican las cosas no sea importante, es decir, podemos especificar primero los objetos de S3 (las dos carpetas) y después el bucket de S3, aunque los objetos hagan referencia al bucket. Esto también nos permite configurar los diferentes servicios en diferentes ficheros y hacer referencia entre los diferentes recursos sin que tengamos que preocuparnos por el orden en el que se vayan a generar.
Una vez hemos especificado la configuración anterior, podemos probar los cambios y verlos en nuestra consola de AWS. Los comandos de Terraform son los siguientes:
- terraform fmt: nos formatea los ficheros del directorio a su estilo predeterminado.
- terraform validate: nos dice si los ficheros del directorio son válidos (no significa que la configuración esté bien, sino que tienen un formato correcto y entendible por Terraform).
- terraform plan: muestra los servicios que se crearían o modificarían si los aplicamos con el siguiente comando.
- terraform apply: nos muestra los cambios que se van a realizar y luego pregunta si los queremos aplicar. Si escribimos “yes” dichos cambios se aplican en el entorno, en este caso AWS. Este comando genera archivos con el estado de la infraestructura.
- terraform destroy: destruye todos los recursos que se hayan generado con apply. Los recursos que destruye son los que están en los ficheros de estado, así que estos ficheros no deben ser modificados.
Terraform ofrece más comandos que podemos revisar en su guía oficial pero estos son los básicos que vamos a utilizar.
Podemos utilizar el comando para formatear los ficheros y validar la sintaxis. Después vamos a ejecutar terraform apply y escribiremos “yes” para ver que la configuración es correcta. Cuando termine, podemos ir a la consola de Amazon S3 y ver que se ha creado el bucket con los objetos.
Si ahora ejecutamos terraform destroy, todo lo que hemos creado en AWS desaparecerá. Si en algún momento se ha añadido algo más al bucket de S3, Terraform no podrá destruirlo, así que es posible que tengamos que vaciar el bucket antes de destruir los recursos.
Configurar el servidor SFTP en EC2
Configurar la instancia de EC2
De la misma forma que con S3, crearemos un fichero de configuración de EC2 al que vamos a llamar EC2_config.tf. Primero vamos a crear la política y el rol que permitirá a EC2 acceder a S3. También vamos a crear un perfil con el rol creado, que será el que asocie el rol a la instancia.
# Policy for EC2 Role
resource "aws_iam_role_policy" "ec2_policy" {
name = "ec2_policy"
role = aws_iam_role.ec2_role.id
policy = <<-EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::${var.bucket_name}"]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": ["arn:aws:s3:::${var.bucket_name}/*"]
}
]
}
EOF
}
# EC2 Role
resource "aws_iam_role" "ec2_role" {
name = "ec2_role"
assume_role_policy = <<-EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "ec2.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
}
resource "aws_iam_instance_profile" "ec2_profile" {
name = "ec2_profile"
role = aws_iam_role.ec2_role.name
}
El siguiente paso es generar un par de claves para realizar las conexiones SSH a la instancia. Desde macOS o Linux lo haremos con el siguiente comando:
ssh-keygen -t rsa
Tenemos que recordar dónde los hemos guardado. Una vez generados, debemos añadir los siguientes valores al fichero de variables (variables.tf):
variable "ec2_key_name" {
default = "<KEY_NAME>"
}
variable "ec2_public_key" {
default = "<PUBLIC_KEY>"
}
variable "ec2_private_key_file_path" {
default = "<PATH_TO_PRIVATE_KEY>"
}
Debemos cambiar <KEY_NAME> por el nombre de la clave (en este caso “id_rsa”), <PUBLIC_KEY> por el contenido del fichero con la clave pública (en este caso el contenido del fichero id_rsa.pub) y <PATH_TO_PRIVATE_KEY> por la ruta de la clave privada (en este caso “~/.ssh/id_rsa”).
A continuación, volvemos al fichero EC2_config.tf y añadimos el recurso de par de claves:
resource "aws_key_pair" "deployer_key" {
key_name = var.ec2_key_name
public_key = var.ec2_public_key
}
El siguiente recurso que vamos a crear es el grupo de seguridad que permitirá únicamente el acceso SSH a la instancia EC2. Si quisiéramos realizar otro tipo de conexiones a la instancia, se pueden añadir más reglas al grupo de seguridad. Añadimos lo siguiente al fichero EC2_config.tf, permitiendo las peticiones tcp al puerto 22 desde cualquier IP (versión 4):
resource "aws_security_group" "allow_ssh" {
name = "allow_ssh"
description = "Allow SSH inbound traffic"
ingress {
description = "SSH from outside"
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
tags = {
Name = "allow_ssh"
}
}
Finalmente, ya podemos crear la instancia de EC2 añadiendo lo siguiente al fichero EC2_config.tf:
resource "aws_instance" "ec2_sftp_server" {
ami = "ami-0bb3fad3c0286ebd5"
instance_type = "t2.micro"
associate_public_ip_address = true
iam_instance_profile = aws_iam_instance_profile.ec2_profile.name
tags = {
Name = "s3fs-instance"
}
volume_tags = {
Name = "s3fs-volume"
}
key_name = var.ec2_key_name
security_groups = ["allow_ssh"]
}
En este recurso hay más parámetros de configuración que debemos tener en cuenta. Primero está el identificador de la imagen (ami, Amazon Machine Image). El identificador del ejemplo corresponde a “Amazon Linux 2 AMI (HVM), SSD Volume Type” en la región de Irlanda (los identificadores son dependientes de la región, así que en otra región será un ami diferente). Después tenemos el tipo de instancia, en este caso se ha seleccionado “t2.micro” porque entra dentro de la capa gratuita (el tráfico de datos no es gratuito, así que aunque mantener la instancia sea gratuito durante un tiempo, no lo serán las conexiones SFTP que hagamos con el servidor). También hemos especificado que queremos que se asigne una IP pública para así poder acceder a la instancia desde fuera de la red privada en Amazon. Finalmente, se asocian los recursos generados anteriormente con la instancia.
Si ahora escribimos el comando terraform apply, se generará el bucket S3 y la instancia de EC2 con los parámetros que hemos especificado, pero no se podrán subir archivos mediante SFTP ya que aún no se ha configurado el servidor.
Configurar el servidor SFTP y montar S3
Una vez hemos creado el recurso de EC2, es momento de configurar el servidor SFTP instalando las librerías necesarias. Para ello, Terraform ofrece provisioners que nos permiten subir archivos y ejecutar comandos en la instancia. Como todas las configuraciones se realizan ejecutando comandos, se pueden escribir directamente en el provisioner, pero se va a separar en diferentes scripts para ejecutar todo de forma ordenada.
Vamos a usar dos tipos de provisioner, “file” para subir los archivos a EC2 y “remote-exec” para ejecutar los comandos en la instancia.
El primer paso va a ser crear un directorio donde guardaremos los archivos de configuración y scripts, dentro del directorio de trabajo. En este ejemplo la hemos llamado init_scripts. Dentro de este directorio vamos a crear los siguientes scripts.
Instalar librerías necesarias
El primer script va a ser el encargado de instalar las librerías necesarias para configurar el servidor y le hemos llamado 1_update_and_install.sh con el siguiente contenido:
#!/bin/bash echo "1. Updating and installing libraries..." sudo yum -y update && sudo yum -y install jq automake openssl-devel git gcc libstdc++-devel gcc-c++ fuse fuse-devel curl-devel libxml2-devel
Configurar S3FS Fuse
El segundo script será el encargado de descargar e instalar S3FS para poder montar S3 como un directorio dentro de la instancia. Hemos llamado al fichero 2_install_s3fs.sh:
#!/bin/bash echo "2. Downloading and installing S3FS Fuse..." cd ~ git clone https://github.com/s3fs-fuse/s3fs-fuse.git cd s3fs-fuse ./autogen.sh ./configure make sudo make install
Configurar VSFTPD
El tercer script se va a encargar de instalar y configurar VSFTPD. La configuración requiere que editemos el fichero vsftpd.conf que ya existe, pero en vez de realizar una edición, vamos a crear el fichero modificado en el directorio init_scripts, para poder copiarlo en la instancia. Creamos un fichero llamado vsftpd.conf (este nombre no se puede cambiar) y añadimos el siguiente contenido:
anonymous_enable=NO local_enable=YES write_enable=YES local_umask=022 dirmessage_enable=YES xferlog_enable=YES connect_from_port_20=YES xferlog_std_format=YES chroot_local_user=YES listen=NO listen_ipv6=YES pam_service_name=vsftpd userlist_enable=YES tcp_wrappers=YES allow_writeable_chroot=YES pasv_enable=YES pasv_min_port=40000 pasv_max_port=40100
Los cambios respecto al fichero original son los siguientes:
- se cambia anonymous_enable a NO
- se descomenta la línea chroot_local_user=YES
- se añaden al final del fichero las siguientes líneas:
allow_writeable_chroot=YES pasv_enable=YES pasv_min_port=40000 pasv_max_port=40100
Después de tener el fichero vsftp.conf, debemos crear el script que instale y configure VSFTPD. Lo llamaremos 3_install_vsftpd.sh y tendrá el siguiente contenido:
#!/bin/bash echo "3. Installing VSFTPD and OpenSSH Server..." sudo yum -y install vsftpd sudo yum -y install openssh-server sudo mv /etc/vsftpd/vsftpd.conf /etc/vsftpd/vsftpd.conf.bak sudo mv /tmp/init_scripts/vsftpd.conf /etc/vsftpd/vsftpd.conf sudo systemctl restart vsftpd.service
Configurar SSH
A continuación, debemos configurar SSH para SFTP modificando el fichero sshd_config. De la misma forma que con la configuración de VSFTPD, creamos un archivo llamado sshd_config (tampoco se le puede cambiar el nombre) en el directorio init_scripts con el siguiente contenido:
HostKey /etc/ssh/ssh_host_rsa_key HostKey /etc/ssh/ssh_host_ecdsa_key HostKey /etc/ssh/ssh_host_ed25519_key SyslogFacility AUTHPRIV AuthorizedKeysFile .ssh/authorized_keys PasswordAuthentication yes ChallengeResponseAuthentication no GSSAPIAuthentication yes GSSAPICleanupCredentials no UsePAM yes X11Forwarding yes AcceptEnv LANG LC_CTYPE LC_NUMERIC LC_TIME LC_COLLATE LC_MONETARY LC_MESSAGES AcceptEnv LC_PAPER LC_NAME LC_ADDRESS LC_TELEPHONE LC_MEASUREMENT AcceptEnv LC_IDENTIFICATION LC_ALL LANGUAGE AcceptEnv XMODIFIERS Subsystem sftp internal-sftp Match group sftp ChrootDirectory /home/%u X11Forwarding no AllowTcpForwarding no ForceCommand internal-sftp AuthorizedKeysCommand /opt/aws/bin/eic_run_authorized_keys %u %f AuthorizedKeysCommandUser ec2-instance-connect
Los cambios realizados respecto al fichero original son los siguientes:
- Se cambia el valor de PasswordAuthentication a yes
- Se elimina la línea Subsystem sftp /usr/libexec/openssh/sftp-server
- Se añade donde estaba la línea anterior lo siguiente:
Subsystem sftp internal-sftp Match group sftp ChrootDirectory /home/%u X11Forwarding no AllowTcpForwarding no ForceCommand internal-sftp
Ahora debemos crear el script que realice el cambio del fichero y aplique los cambios. Llamaremos al script 4_configure_ssh.sh:
#!/bin/bash echo "Configuring SSH..." sudo mv /etc/ssh/sshd_config /etc/ssh/sshd_config.bak sudo mv /tmp/init_scripts/sshd_config /etc/ssh/sshd_config sudo systemctl restart sshd
Crear el usuario SFTP
Este paso consiste en crear un grupo de usuarios llamado sftp y un usuario con una contraseña para poder acceder al usuario. El script se va a llamar 5_create_sftp_user.sh y va a tener el siguiente contenido:
#!/bin/bash echo "Creating SFTP user..." sudo groupadd sftp sudo useradd -m sftpuser -s /sbin/nologin -g sftp sudo echo "<PASSWORD>" | passwd sftpuser --stdin sudo chown root /home/sftpuser sudo chmod 755 /home/sftpuser sudo mkdir /home/sftpuser/s3 sudo chown sftpuser:sftp /home/sftpuser/s3
Debemos cambiar el atributo <PASSWORD> por la contraseña que queramos darle al usuario. Vemos también que se cambian los permisos de los directorios y se añade un nuevo directorio llamado s3 dentro de la home del usuario, que será donde se va a montar el bucket S3 en el siguiente paso.
Montar el bucket S3
Vamos a montar S3 dentro de nuestra instancia de EC2, en el directorio que hemos creado para ello. Vamos a crear el script llamado 6_mount_s3.sh que tendrá los comandos necesarios:
#!/bin/bash echo "Mounting S3..." EC2METALATEST=http://169.254.169.254/latest && EC2METAURL=$EC2METALATEST/meta-data/iam/security-credentials/ && EC2ROLE=`curl -s $EC2METAURL` && S3BUCKETNAME=<BUCKET_NAME> && DOC=`curl -s $EC2METALATEST/dynamic/instance-identity/document` && REGION=`jq -r .region <<< $DOC` sudo /usr/local/bin/s3fs $S3BUCKETNAME -o use_cache=/tmp,iam_role="$EC2ROLE",allow_other /home/sftpuser/s3 -o url="https://s3-$REGION.amazonaws.com" -o nonempty sudo chmod -R 777 /home/sftpuser/s3/*
Debemos cambiar <BUCKET_NAME> por el nombre de nuestro bucket. Se especifica la ruta donde vamos a montarlo, en este ejemplo /home/sftpuser/s3, que también podemos cambiar. Finalmente, se da permiso total de acceso a las carpetas del bucket, para así poder leer y escribir en ellas.
Configurar EC2
Una vez tenemos todos los scripts necesarios, debemos ejecutarlos todos en nuestra instancia. En vez de escribir todos los ficheros a ejecutar como comandos en el provisioner “remote-exec” (lo veremos a continuación), vamos a crear un último script en init_scripts llamado configure.sh que lo único que hace es llamar en orden a todos los ficheros que hemos creado en los pasos anteriores:
#!/bin/bash echo "Configuring system" sudo sh /tmp/init_scripts/1_update_and_install.sh sudo sh /tmp/init_scripts/2_install_s3fs.sh sudo sh /tmp/init_scripts/3_install_vsftpd.sh sudo sh /tmp/init_scripts/4_configure_ssh.sh sudo sh /tmp/init_scripts/5_create_sftp_user.sh sudo sh /tmp/init_scripts/6_mount_s3.sh
Ahora sí, es el momento de subir los ficheros y ejecutarlos en nuestra instancia. Para ello debemos modificar el recurso “aws_instance” y añadir los provisioners. La definición del recurso quedará de la siguiente manera:
resource "aws_instance" "ec2_sftp_server" {
ami = "ami-0bb3fad3c0286ebd5"
instance_type = "t2.micro"
associate_public_ip_address = true
iam_instance_profile = aws_iam_instance_profile.ec2_profile.name
tags = {
Name = "s3fs-instance"
}
volume_tags = {
Name = "s3fs-volume"
}
key_name = var.ec2_key_name
security_groups = ["allow_ssh"]
provisioner "remote-exec" {
inline = [
"sudo mkdir /tmp/init_scripts",
"sudo chmod -R 777 /tmp/init_scripts"
]
connection {
host = self.public_ip
type = "ssh"
agent = false
private_key = file(var.ec2_private_key_file_path)
user = "ec2-user"
}
}
provisioner "file" {
source = "init_scripts/"
destination = "/tmp/init_scripts"
connection {
host = self.public_ip
type = "ssh"
agent = false
private_key = file(var.ec2_private_key_file_path)
user = "ec2-user"
}
}
provisioner "remote-exec" {
inline = [
"sudo sh /tmp/init_scripts/configure.sh",
]
connection {
host = self.public_ip
type = "ssh"
agent = false
private_key = file(var.ec2_private_key_file_path)
user = "ec2-user"
}
}
}
Estos provisioners, dentro del recurso EC2, lo que hacen es crear un directorio donde se van a subir todos los ficheros de init_scripts, después suben los ficheros con el provisioner “file” y finalmente ejecuta el fichero de configuración que se encarga de llamar a todos los scripts.
Una vez hemos añadido esto, podemos ejecutar el comando terraform apply y ver cómo se generan todos los recursos. También veremos todos los logs de la consola de EC2, así que podemos ver el progreso de la instalación y configuración del servidor.
Conclusiones
Este tutorial explica cómo hacer un servidor SFTP utilizando EC2 y montando un bucket de S3 dentro de la instancia. Sin embargo, esto no impide que se utilicen otras tecnologías, ya que considero que la configuración es modular. Por ejemplo, si no necesitamos que los ficheros se almacenen en S3, podemos usar el servicio EBS o EFS para almacenar los ficheros. También podríamos optar por otro software para configurar el servidor SFTP en vez de VSFTPD.
Por lo tanto espero que este tutorial haya servido de ayuda para entender cómo se configura Terraform para trabajar con AWS y que podáis hacer vuestras soluciones concretas adaptándolas a otras necesidades.
Recursos
- Repositorio con todo el código: https://github.com/julenminer/aws_terraform_micronaut
- Cómo se cargan los ficheros: https://www.terraform.io/docs/configuration-0-11/load.html
- Instalación de Terraform: https://learn.hashicorp.com/tutorials/terraform/install-cli
- S3 en Terraform: https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/s3_bucket
- EC2 en Terraform: https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/instance

