

En este tutorial vamos a ver maneras de medir el rendimiento de tus queries en Postgres. También hablaremos sobre las fases por las que pasa una query antes de ser ejecutada.
Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Preparando la base datos
- 4. ¿Qué pasa antes de ejecutar una query?
- 5. Maneras de medir el rendimiento de tus queries
- 6. Las mediciones de EXPLAIN y estadísticas no coinciden
- 7. Conclusiones
- 8. Referencias
1. Introducción
Muchas veces pensamos que el mal rendimiento en base de datos viene dado porque se ha hecho un mal diseño, una mala configuración o faltan recursos como memoria o capacidad de procesamiento. En este tutorial explicaremos maneras de cómo medir el rendimiento de tus queries.
2. Entorno
El tutorial está escrito usando el siguiente entorno:
- Hardware: MacBook Pro Retina 15′ (2,5 Ghz Intel Core i7, 16GB DDR3).
- Base de datos Postgres 12
- Python 3.
- Sistema Operativo: Mac OS Catalina 10.15.4.
- Docker versión 18.06.1-ce, build e68fc7a
3. Preparando la base datos
Este tutorial utilizaremos un contenedor de Docker con PostgreSQL 12. Utilizaremos una base de datos importada sobre películas lo suficientemente grande como para ver cambios en el rendimiento de las queries que se hagan.
Para ello utilizaremos el loader de este repo para cargar un dataset de Kaggle. Para la instalación de la base de datos y ejecución del loader hay que realizar los siguientes pasos:
- Nos descarga el dataset de Kaggle (900 MB aprox) y extremos los CSVs. Hemos incluido los CSVs en una carpeta llamada dataset.
- Ejecutamos la siguiente sentencia para instanciar la base de datos de Postgres en Docker.
docker run
--name db-tuto
-p 5432:5432
-e POSTGRES_PASSWORD=postgres
-e POSTGRES_DB=test_db
-e POSTGRES_USER=postgres
-d postgres- Nos clonamos el repo de github con el dataset y el loader.
git clone https://github.com/guenthermi/the-movie-database-import- En mi caso, he tenido que instalar unos módulos de python, ya que me dio error al ejecutar el loader. Instalamos los módulos pandas y psycopg2 usando pip.
pip install pandas
pip install psycopg2-binary- Ejecutamos el loader. Os podéis ir a tomar un café, ya que el proceso tarda bastante tiempo debido a la cantidad de datos a importar. Hemos elegido un dataset grande para que sean visibles los cambios en el rendimiento para este y futuros tutoriales sobre el tema.
python3 loader.py dataset- Una vez terminada la ejecución del loader vemos que la base de datos cargada queda de la siguiente manera.
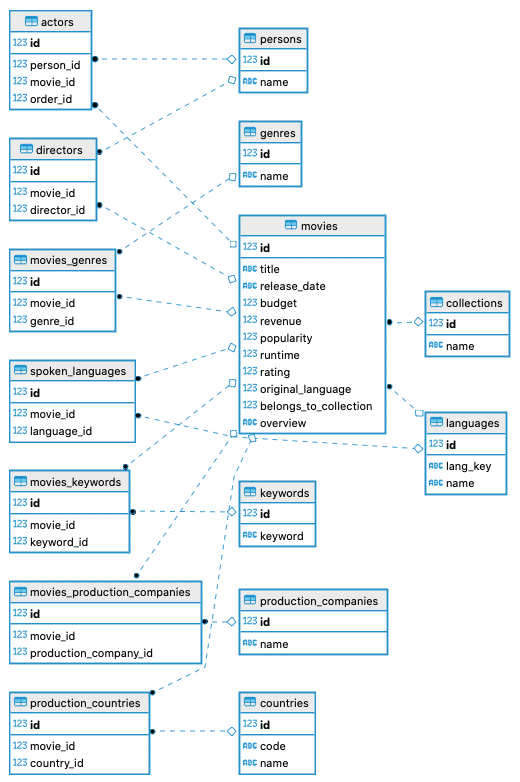
A la vista de este esquema, si quisiéramos obtener las películas en español lanzadas después del 2000 con una puntuación mayor de 4 estrellas. La query resultante sería algo así:
<pre class="lang:pgsql decode:true " title="películas de los 20s con una calificación mayor a 4 estrellas">SELECT m.title,
m.release_date,
m.rating,
String_agg(g.name, ', ') AS genre
FROM movies_genres mg
inner join genres g
ON mg.genre_id = g.id
inner join movies m
ON mg.movie_id = m.id
inner join spoken_languages sp
ON mg.movie_id = sp.movie_id
inner join languages l
ON l.id = sp.language_id
AND l.lang_key = 'es'
WHERE m.rating > 4
AND release_date ~ '^d{4}-d{2}-d{2}$'
AND Date_part('year', To_timestamp(release_date, 'YYYY-MM-DD')) >= 2000
GROUP BY m.title,
m.release_date,
m.rating
ORDER BY m.rating DESC,
To_timestamp(release_date, 'YYYY-MM-DD') DESC;Hemos tenido que validar con una expresión regular las fechas de lanzamiento de las películas, ya que existen fechas que no cumplen el formato al ser de tipo varchar.
Pero a la vista de la query, me surgen varias preguntas, ¿Qué coste tiene la ejecución de la query? ¿Cómo lo puede obtener?. Vamos a intentar responderlas.
4. ¿Qué pasa antes de ejecutar una query?
Postgres realiza 4 fases cuando solicitamos la ejecución de una query:
- Parser: En esta fase se divide la query en varios tokens (componentes léxicos que significan algo) quitando espacios o comentarios que pueda tener. Algunos de los token extraídos son identificadores, palabras reservadas (keywords), operadores, símbolos, constantes, etc). Devolviendo una lista enlazada de árboles con los tokens encontrados, tal y como aparece en la imagen:
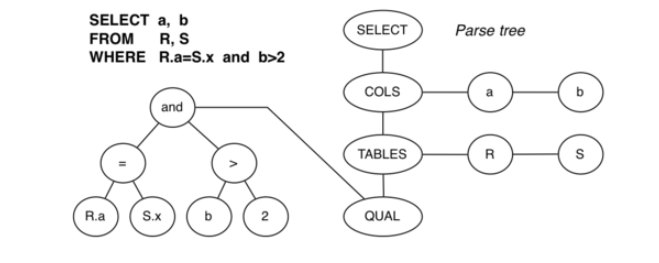
- Analyze and Rewrite: Convierte los árboles del paso anterior, en una lista de nodos de estructura Query. La estructura Query agrega información (el tipo de sentencia que es, si usa subselect, si tiene recursividad, etc) tal como podemos ver en la imagen.
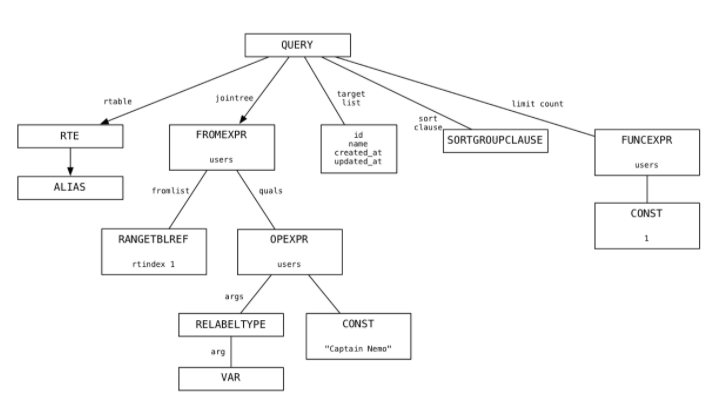
A esta nueva lista, le aplica una serie de algoritmos y heurísticas para tratar de optimizar y simplificar la query haciendo que se ejecute más rápido.
- Plan: Crea un plan de ejecución generando un tercer árbol de nodos que forman una lista de instrucciones para que Postgres las siga. En la siguiente imagen se muestra el árbol generado para una query:
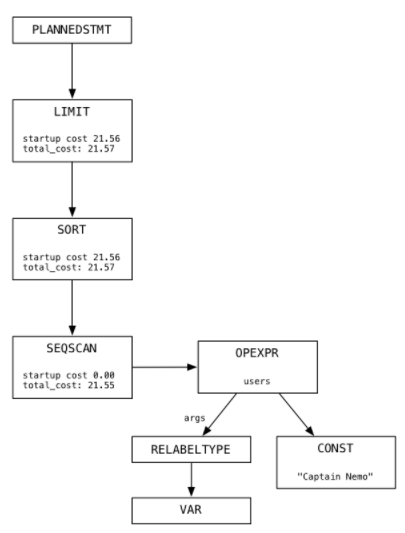
A la hora de construir la lista de instrucciones a ejecutar, el planificador toma una serie de decisiones sobre las estrategias a tomar antes de ejecutar las queries.

En el siguiente apartado veremos cómo obtener información sobre las decisiones tomadas por el planificador. Algunas de las estrategias que aplica el planificador son las siguientes:
- De acceso: (Sequential Scan,Index scan,Bitmap Index Scan).
- Cláusulas JOIN: (nested loop, merge join, hash join).
- Cláusulas de agrupación: (Plain,sorted,hashed).
4. Execute: Simplemente ejecuta el plan obtenido en la fase anterior.
5. Maneras de medir el rendimiento de tus queries
5.1. Las estadísticas. Encontrar las consultas lentas
Si queremos medir el rendimiento de las queries ejecutadas en la base de datos utilizaremos el módulo de Postgres pg_stat_statements capaz de almacenar el coste, tiempo, filas devueltas, etc.
Para activar el módulo tenemos que añadir un par de líneas al fichero postgresql.conf. Para ello realizamos los siguientes pasos:
- Entramos en el contenedor de Postgres (Recuerda que podemos obtener el identificador del contenedor ejecutando un docker ps).
docker exec -it 6cce8f6676a3 /bin/bash- El fichero de configuración se encuentra en /var/lib/postgresql/data/postgresql.conf. Para modificarlo necesitamos instalar un editor, en mi caso he escogido nano.
apt-get update && apt-get install nano
nano /var/lib/postgresql/data/postgresql.conf- Añadimos las siguientes líneas al final de fichero postgresql.conf:
# En esta propiedad podemos añadir una lista de librerías compartidas
# (separadas por comas) que se cargarán al inicio de todas las sesiones.
shared_preload_libraries = 'pg_stat_statements'
# Incrementamos el tamaño máximo que puede tener una query para ser monitorizada
track_activity_query_size = 2048
# El nivel de tracking de sentencias. Esta propiedad puede tomar los siguiente valores
# - all: Todo, incluido las sentencias anidadas
# - top: Las sentencias ejecutadas por el cliente
# - none: Deshabilita las estadísticas
pg_stat_statements.track = all- Una vez guardado el fichero de configuración, reiniciamos el servicio:
- Reiniciando el servicio de Postgres.
service postgresql restart-
- O bien, saliendo del contenedor y reiniciar el contenedor.
docker restart 6cce8f6676a3- Conectamos con la base de datos y habilitamos la extensión pg_stat_statements :
-- Habilitamos la extension
CREATE EXTENSION pg_stat_statements;
-- Comprobamos que la extensión se ha instalado correctamente
select * from pg_extension where extname='pg_stat_statements';
-- Listado de extensiones disponibles
SELECT * FROM pg_available_extensions ORDER BY name;- Con esta query obtendremos el top 3 de las queries más lentas ordenadas por tiempo medio de ejecución. También recuperamos datos como la query, las filas que devuelve o el porcentaje de acierto al ir a buscar a cache.
-- Reseteo de las tablas de estadísticas
SELECT pg_stat_statements_reset();
-- Las 3 queries más lentas ordenadas por el tiempo medio de ejecución
SELECT query,
calls,
total_time,
( total_time / calls )
AS average_time,
rows,
100.0 * shared_blks_hit / Nullif(shared_blks_hit + shared_blks_read, 0)
AS
hit_percent
FROM pg_stat_statements
ORDER BY total_time DESC
LIMIT 3 5.2. EXPLAIN. Plan de ejecución.
Esta sentencia nos permite extraer información sobre el plan de ejecución generado para una query por el planificador. Al ejecutar EXPLAIN podemos obtener lo siguiente:
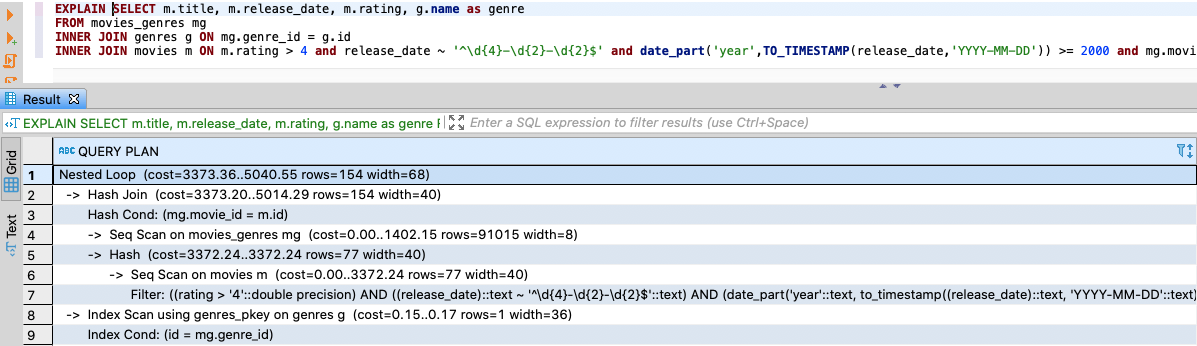
- Coste inicial: Es el primer valor que aparece en el coste (3373.36) y presenta el coste antes de realizar la fase de salida.
- Coste estimado: Es el coste de realizar la ejecución de la planificación hasta el final. El coste se mide en unidades arbitrarias determinadas por los parámetros de coste del planificador como son el coste por página, coste de cpu por tupla, coste de cpu por filtro, etc. Teniendo en cuenta estos costes y conociendo el número de registros y bloques de la tabla, podemos calcular el coste de la siguiente manera (esta fórmula se aplica para una sentencia select de una sola tabla).
cost = blocks * seq_page_cost + number_of_records * (cpu_tuple_cost + cpu_filter_cost).Como podemos ver en el cálculo del coste se relaciona el número de registros que recupera la query, su coste computacional y el espacio en disco.
- Filas estimadas: Número de filas que se obtendrán como salida si se finaliza el plan de ejecución.
También podemos ver los distintos nodos o instrucciones que ejecuta el planificador (comentados en el apartado anterior), así como las estrategias escogidas para el acceso a los datos, para hacer lo joins, etc.
Para calcular el tiempo que tarda la query, lo podemos hacer usando el historial haciendo una select a pg_stat_statements como hemos visto antes, o añadir a la sentencia EXPLAIN la palabra reservada ANALYZE.
ADVERTENCIA: Si se hace un EXPLAIN ANALYZE se ejecutará la sentencia a analizar, por lo que si analizamos un DELETE, UPDATE, INSERT se aplicarán los cambios si no se hace un rollback. Aquí podemos ver un ejemplo.
BEGIN;
EXPLAIN ANALYZE
DELETE FROM users WHERE id = 1;
ROLLBACK;Al ejecutar esta sentencia podemos ver el tiempo que tardó la sentencia, el número de registro que devolvió, así como las veces que se ejecutó el nodo en la planificación. Durante la planificación, hay nodos que se ejecutan más de una vez como es el caso en las agrupaciones o escaneos haciendo usos de índices.

Cuando tengamos mucha diferencia entre las filas estimadas por el planificador y las filas reales al ejecutar la query, se recomienda ejecutar VACUUM ANALYZE para que se actualicen las estadísticas y se mejore la estimación.
Una forma gráfica de ver los datos devueltos por la sentencia EXPLAIN ANALYZE puede ser utilizando https://explain.depesz.com/.

Y desglosar de una forma más amigable las estadísticas.
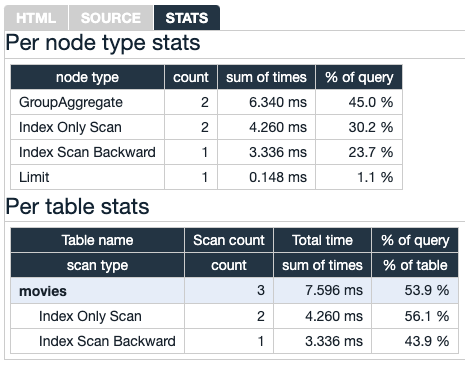
6. Las mediciones de EXPLAIN y estadísticas no coinciden
Al realizar mediciones para otro tutorial que estoy preparando sobre optimización de queries correladas, me di cuenta de que los tiempos obtenidos en las estadísticas y ejecutar la planificación con EXPLAIN no coinciden.
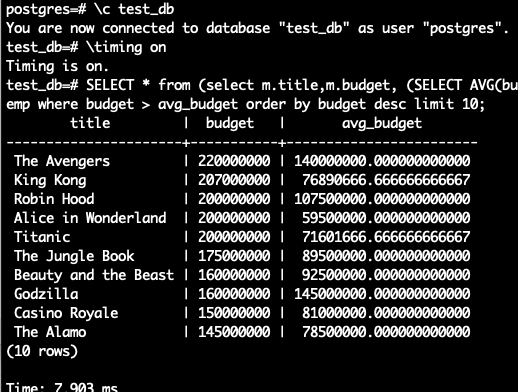
Si nos piden que listemos las 10 películas que superan la media en presupuesto, podíamos hacer algo así (soy consciente de que se podría calcular de forma más sencilla, pero es un ejemplo extraído para optimizar subqueries).
SELECT *
FROM (SELECT m.title,
m.budget,
(SELECT Avg(budget)
FROM movies
WHERE budget IS NOT NULL
AND m.title = title
GROUP BY title) AS avg_budget
FROM movies m
WHERE m.budget IS NOT NULL) AS temp
WHERE budget > avg_budget
ORDER BY budget DESC
LIMIT 10;Y si realizamos mediciones con los distintos métodos obtenemos lo siguiente:
- Timing (ejecutando dentro del contenedor)
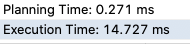
- EXPLAIN ANALYZE
- pg_stat_statements

Podemos ver que las mediciones no son iguales, haciendo una medición por diferentes métodos. En el caso de pg_stat_statements bastante diferentes pero puede ser que se encuentre cacheada.
Las diferencias podrían ser mayores en queries más pesadas, así que aconsejamos que los valores obtenidos tanto del coste como del tiempo se tomen de forma orientativa para detectar fallos de implementación o cuellos de botella pero no como una medición absoluta.
En este hilo de github se explica la razón de porqué se producen grandes diferencias entre EXPLAIN y las estadísticas para un Postgres dockerizado en Mac (nuestro entorno), dando detalles de implementación.
7. Conclusiones
Como hemos visto en el tutorial, hay diferentes formas de medir el rendimiento de tus queries. Esto nos será útil para detectar posibles cuellos de botellas o defectos de implementación en las queries. Como conclusión final sobre la importancia de monitorizar y medir, me quedo con una frase de Peter Drucker
Lo que no se mide, no se controla, y lo que no se controla, no se puede mejorar.
En el siguiente tutorial utilizaremos la base de datos y los métodos de medición de este tutorial para explicar cómo afecta en el rendimiento la manera en la que implementamos queries correladas.
8. Referencias
- Documentación oficial de PostgreSQL
- ¿Alguna vez has notado que EXPLAIN ANALYZE ralentiza tus consultas como 60 veces?
- Cálculo del coste para medir el rendimiento de tus queries
- Aprendizaje recopilado sobre Postgresql al investigar las unas queries lentas.
- Repositorio de la BBDD
- Following a Select Statement Through Postgres Internals

