

Aprenderemos a representar gráficos de judías como alternativa a los boxplot, funciones de densidad sobre histogramas, matrices de scatterplots y a representar datos numéricos sobre mapas.
Índice de contenidos
- 1. Introducción
- 2. Gráficos de judías
- 3. Histograma con función de densidad
- 4. Matriz de ScatterPlots
- 5. Datos sobre mapas
- 6. Conclusiones
- Enlaces y referencias
1. Introducción
En artículos anteriores hemos visto como pintar un histograma para ver la calidad del aire a lo largo de los meses, o diagramas de caja y bigotes para ver la actividad de cada anciano y detectar outliers a simple vista con la función boxplot().
Pero es verdad que los gráficos aportan mucha información de un vistazo. Nos indican tendencias, vemos desviaciones, intuimos relaciones de causalidad… es el equivalente estadístico del refrán «una imagen vale más que mil palabras».
Vamos a ver algunos tipos de gráficos más.
2. Gráficos de Judías
Los gráficos de judías se llaman así porque su imagen nos recuerda muchas veces a estas leguminosas. En el eje vertical tenemos el recorrido de la variable principal. Desde su valor mínimo hasta el máximo. Y el ancho representa la frecuencia con que se da ese valor. Cuanto más ancho, más veces ha aparcido. Aparece una línea horizontal, pero no recuerdo si es la media o la mediana.
En el artículo anterior, referente a los outliers, vimos que había un anciano que nos estropeaba todos los muestreos. Concretamente el usuario 10041. Mientras que la media de todos los usuarios era 1687.3 pasos, este usuario, tenía días que llegaba a dar 35000 pasos. 35 veces la media. Y nos distorsionaba el resto. Vamos a estudiarlo.
Lo primero es definir nuestro espacio de trabajo y cargar los datos originales
#seteamos el directorio de trabajo
setwd("/lab/adictosaltrabajo/rstudio/05")
# Vamos a leer un CSV del proyecto GeriaTIC
# https://www.geriatic.udc.es/el-proyecto/datos-abiertos-open-data-del-proyecto-geria-tic/
user_activity <- read.csv("./user_activity.csv", stringsAsFactors = F)
#para convertir string a fechas
user_activity$registerStartDate <- as.Date(user_activity$registerStartDate, format="%Y/%m/%d")
#nos quedamos con una version simplificada
activity <- user_activity[, c("userId","registerStartDate","steps","distance","calories")]
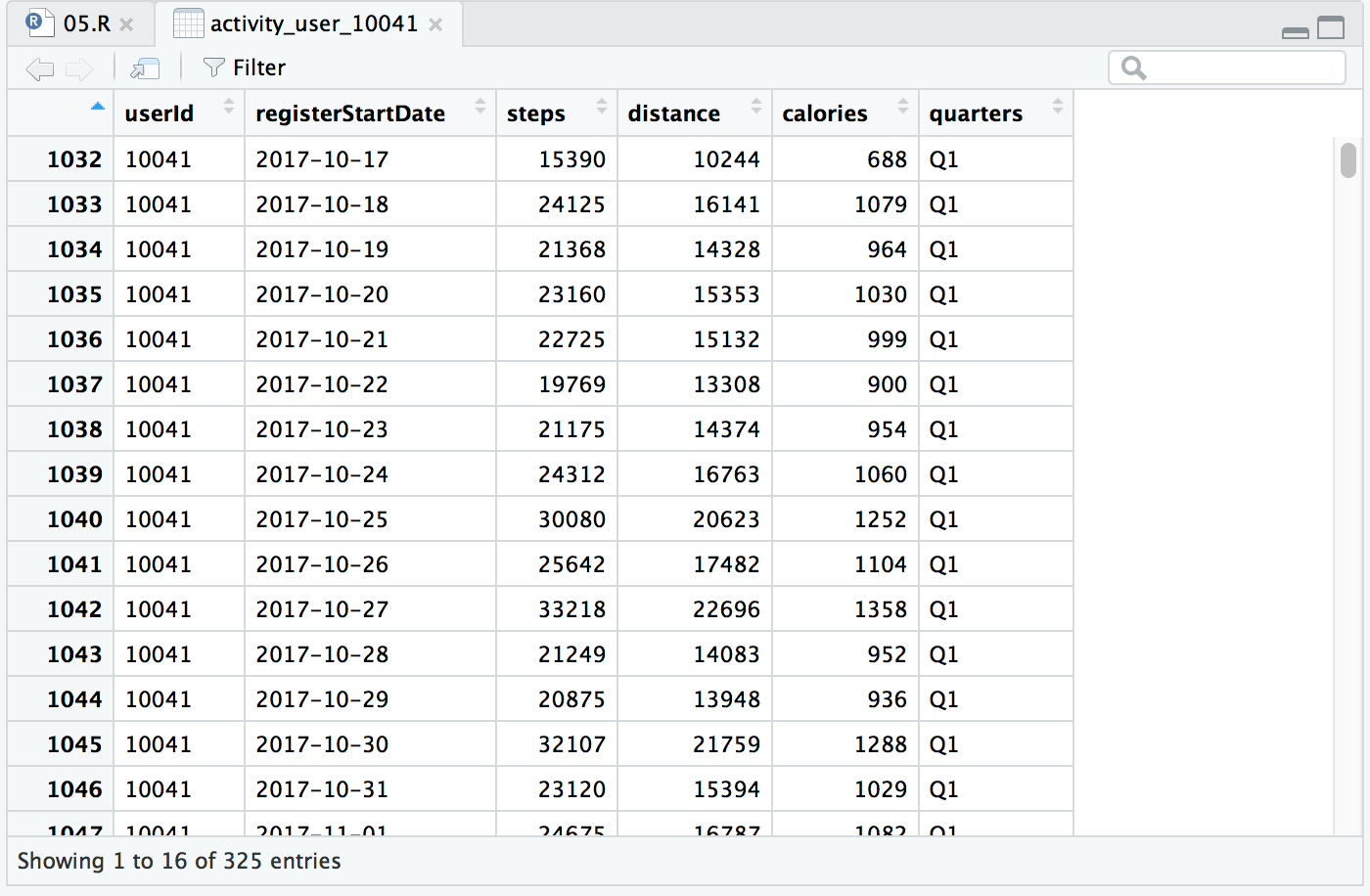
De todos estos usuarios, nos queremos fijar sólo en el usuario «andarín», concretamente en el usuario 10041. Así que seleccionamos sólo las filas con este usuario, y todas las columnas. El muestreo abarca prácticamente un año: del 17-10-2017 al 08-10-2018. Lo dividimos en cuartos.
#nos fijamos en en usuario andarin
activity_user_10041 <- activity[activity$userId == 10041,]
# dividimos el año de muestreo en cuartos
activity_user_10041$quarters <- cut(activity_user_10041$registerStartDate, breaks = 4, labels= c("Q1", "Q2", "Q3", "Q4"))
View(activity_user_10041)
Vemos el resultado
Ahora vamos a importarnos el paquete beanplot. Si quieres ver una comparación de la gráfica beanplot respecto a boxplot te recomiendo el PDF «Beanplot: A Boxplot Alternative for Visual Comparison of Distributions»
Como otras veces, instalamos el paquete, lo importamos, y hacemos buen uso de él, representando el número de pasos en cada cuarto en qué hemos dividido el año.
install.packages("beanplot")
library(beanplot)
beanplot(activity_user_10041$steps ~ activity_user_10041$quarters, col = c("red","yellow","green"))
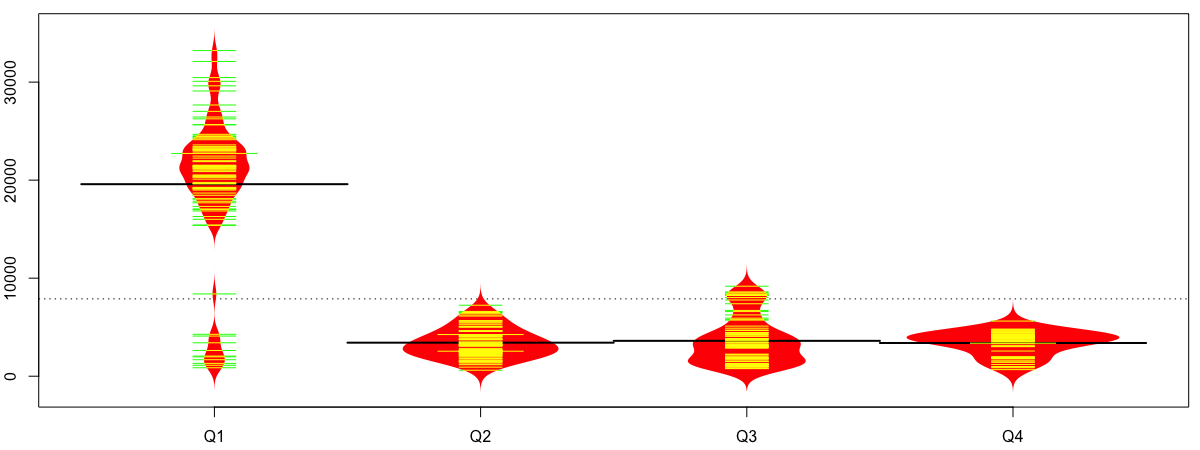
Podemos modificar algunos parámetros como los colores, indicar que no queremos bordes con border = NA o que las judías no sean simétricas y usar ambos lados para mostrar menos verticales con side=»both». Puedes consultar el resto de parámetros en la documentación de beanplot
3. Histograma con función de densidad
Ya hemos visto los histogramas, pero vamos a profundizar en ellos.
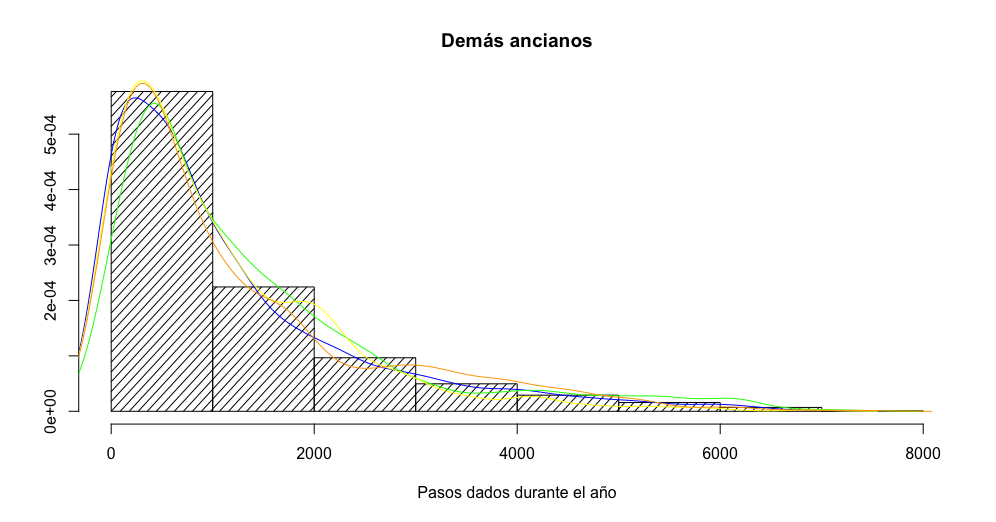
Para ellos vamos a fijarnos en el resto de ancianos. Podría pensarse que con buen tiempo andarán mucho más que con mal tiempo. Y que las estaciones de primavera y verano andan más pasos. Veremos como eso no es así. Seguro que el hecho de que el muestreo de datos esté hecho entre gallegos, algo influye, pero veremos que las curvas de frecuencias son casi calcadas independientemente de la estación.
#ahora vamos a fijarnos en el resto de ancianos que no son en 10041
demas_ancianos <- activity[activity$userId != 10041,]
# y dividimos el muestreo por las estacioens del año
breakpoints <- c(as.Date('2017-01-01'), as.Date('2017-12-21'), as.Date('2018-03-21'), as.Date('2018-06-21'), as.Date('2018-09-21'), as.Date('2018-12-31'))
demas_ancianos$seasons <- cut(
demas_ancianos$registerStartDate,
breaks = breakpoints,
labels = c('Otoño', 'Invierno' , 'Primavera' , 'Verano', 'Otoño')
)
Ahora pintamos el histograma con todo el periodo de estudio, y las líneas con la función de densidad por estación. Para pintar el histograma así, en lugar de pintar el número de repeticiones en el eje Y, lo que pintamos es la probabilidad entre 0 y 1. Esto se indica con el atributo probability = T o freq = F
#queremos ver si hay alguna relación entre el número de pasos y la estación del año hist(demas_ancianos$steps, freq = F, xlab = "Pasos dados durante el año", ylab = NA, main = "Demás ancianos", breaks = 10 , density = 21) invierno <- demas_ancianos[demas_ancianos$seasons == "Invierno","steps"] lines(density(invierno), col = "blue") primavera <- demas_ancianos[demas_ancianos$seasons == "Primavera","steps"] lines(density(primavera), col = "green") verano <- demas_ancianos[demas_ancianos$seasons == "Verano","steps"] lines(density(verano), col = "yellow") otoño <- demas_ancianos[demas_ancianos$seasons == "Otoño","steps"] lines(density(otoño), col = "orange")
Veremos que las curvas que representan la función de densidad son prácticamente iguales estación a estación.
4. Matriz de ScatterPlots
A veces nos interesa comparar una serie de variables unas con otras para ver si son directamente proporcionales o como se relacionan. Para esto, suele ser muy útil una matriz de scatterplots.
Por ejemplo, queremos ver como están relacionadas las variables steps, distance y calories
#vemos como estan relacionadas las principales variables
pairs(demas_ancianos[,c("steps","distance","calories")], pch = 19)
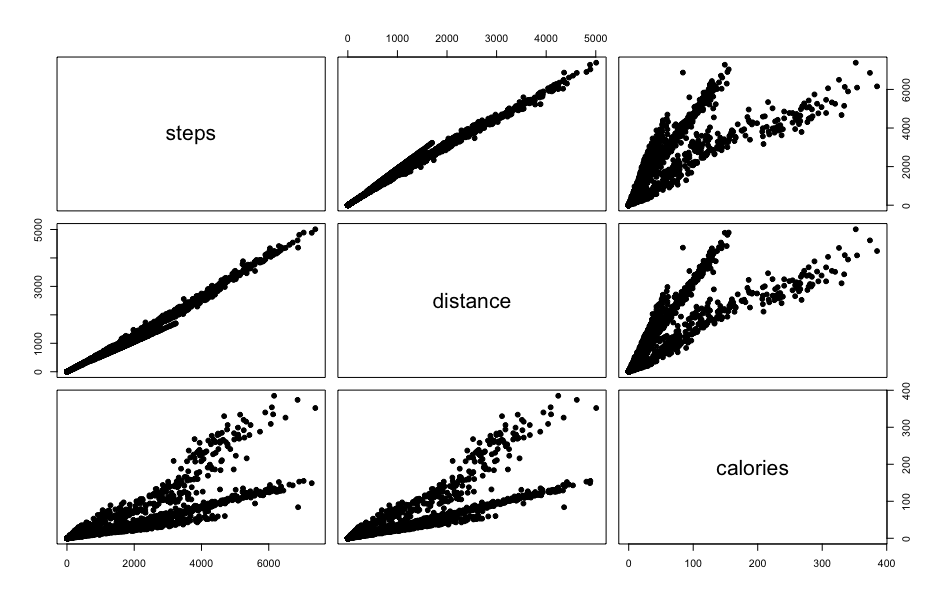
Aquí se ve claramente que hay una relación directa entre el número de pasos y la distancia recorrida como no podía ser de otra forma.
También vemos que hay una relación directa entre el número de pasos y las calorías consumidas, pero ahí se ve algo raro. Parece que se subdivide en dos rectas de regresión. Podría pensarse que hay otro factor a tener en cuenta. En unos casos a mismos pasos se consumen más calorías y en otros menos. Y parece que ambas proyecciones son lineales. Ese factor podría ser según el sexo del muestreo. Es un dato que en este dataSet no tenemos. Podría ser la velocidad a la que se dan el paseo. A lo mejor en una estación del año está más desapacible y el paseo lo dan más deprisa.
#colores para otoño, invierno, primavera, verano
colores <- c("#9F5020", "#20379F", "#209F37", "#EAD332")
pairs(demas_ancianos[,c("steps","distance","calories")], pch = 19, cex = 0.5,
col = colores[demas_ancianos$seasons])
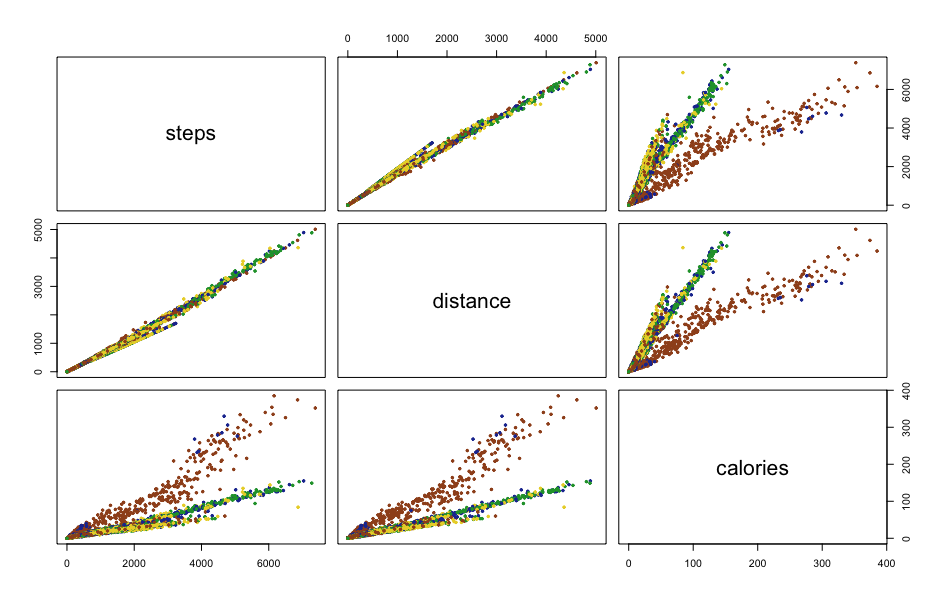
Se ve que en otoño e inviernos, para 6000 pasos los usuarios gastan más del doble de calorías que en primavera y verano
5. Datos sobre mapas
Con R podemos también disponer datos sobre mapas. Para ello usaremos la librería GGPlot2 que permite añadir información por capas antes de rasterizar la imagen.
Por otro lado, como dataset vamos a utilizar el que ya vimos en el segundo artículo sobre R Studio donde veiamos el precio medio de venta y de alquilar a menos de 500 metros de una estación de metro. Entonces sacamos una función de densidad con la rentabilidad de comprar un piso para alquilar. Vamos a retomar aquel ejercicio.
# leemos los precios que vimos en el ejemplo 02
precios <- readRDS("./precios.rds")
preciosL10 <- precios[precios$line == "L10",]
#creamos la columna con el rendimiento anualizado
preciosL10$rendimiento <- (12 * preciosL10$rental)/preciosL10$sale
# creamos un factor con la rentabilidad de 1 a 5 donde 1 es la mas baja y 5 la mas alta
preciosL10$rentabilidad <- cut(preciosL10$rendimiento, breaks = 5, labels = c(1,2,3,4,5))
# lo convertimos a número porque lo vamos a usar como el tamaño de un punto
preciosL10$rentabilidad <- as.integer(preciosL10$rentabilidad)
Lo cierto es que podemos usar cualquier fuente de datos para pintar mapas, pero yo os animo a probar Open Street Map, una alternativa abierta a Google Maps.
# instalamos y cargamos las librerías de Open Street Map
install.packages("osmdata")
library(osmdata)
# y la librería de GGPlot2 para pintar mapas
install.packages("ggmap")
library(ggmap)
Lo cierto es que OSMdata tiene muchas más cosas que «mapas». Ofrece una interfaz para interrogar a OSM sobre el tipo de elementos del mapa. Vamos, que puedes interrogar a la Base de Datos de OSM. Muy interesante, la verdad.
#obtenemos una caja cuadrada con los limites de Madrid
bbox <- getbb("Madrid")
# obtenemos el mapa, indicando que la fuente es el OpenStreetMap
madrid.map <- get_map(bbox, source="osm")
# y lo pintamos con la librería GGPlot2
ggmap(madrid.map)
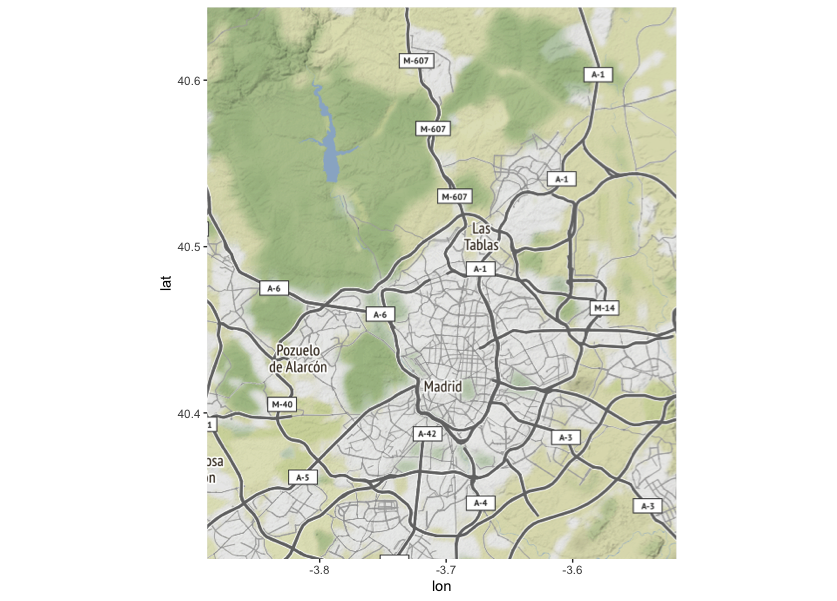
Si vemos el contenido de bbox es un rectangulo de coordenadas. Pero podemos afinar un poco más si tenemos en cuenta las posiciones de las estaciones de Metro de la Línea 10
# ahora vamos a usar las coordenadas de las estaciones de Metro
bbox[1] <- min(preciosL10$lng) - 0.1
bbox[2] <- min(preciosL10$lat) - 0.01
bbox[3] <- max(preciosL10$lng) + 0.1
bbox[4] <- max(preciosL10$lat) + 0.01
madrid.map <- get_map(bbox, source="osm")
# y pintamos las estaciones, pero más grandes aquellas que tienen mayor rentabilidad
ggmap(madrid.map) +
ggtitle("Mapa de rentabilidad de pisos para alquiler de Linea 10") +
geom_point(data=preciosL10,
aes(x=lng,y=lat),
color="DB9000",
fill="#DB9000",
size= preciosL10$rentabilidad * 3,
shape=21,
alpha= 0.7) +
labs(x = "Longitud", y = "Latitud")
Que nos muestra algo que ya sabíamos: que es más rentable comprar para alquilar por la zona de Batán hasta Ciudad Jardín, más que por el centro o el norte.
6. Conclusiones
Que una imagen vale más de mil palabras es evidente. Y sólo hemos rascado la superficie. La librería GGPlot2 nos permite hacer gráficos espectaculares, pero requerirían un curso dedicado.
En este artículo hemos aprendido:
- algunas formas nuevas de representar gráficos
- beanplot (gráficos de judías) como alternativa a los diagramas de caja y bigotes
- a pintar funciones de densidad sobre histogramas
- a representar datos sobre mapas.
Son los rudimentos necesarios para poder tirar de la cuerda y profundizar donde sea necesario.
Enlaces y referencias
- El código fuente de este tutorial en GitHub
https://github.com/eContento/rstudio - Beanplot: A Boxplot Alternative for Visual Comparison of Distributions
- R graphics with ggplot2
- Acceso a la base de datos de OpenStreetMaps desde R

