

0. Índice de contenidos.
- 1. Introducción
- 2. Usando @GenerationType
- 3. Usando @GenericGenerator
- 4. Las diferencias entre la estrategia de identidad y nativa
- 5. Anular partes de su mapeo
- 6. Conclusiones
1. Introducción.
Cuando creamos las clases(POJOs) para mapear las tablas en la base de datos necesitamos usar anotaciones de hibernate, como se ve en la imagen 1. Claro que en este tutorial, nos enfocaremos en las usadas para la generación de id(PK).
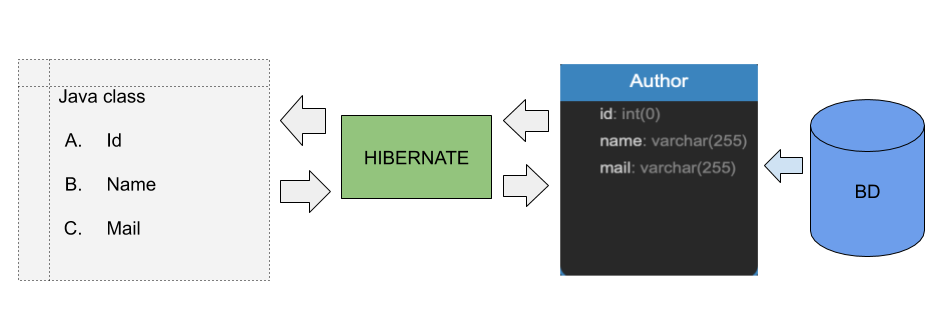
Imagen 1 esquema hibernate
Requisitos previos.
El lector de este tutorial deberá tener conocimientos de:
2. Usando @GeneratedValue.
Aquí los imports necesarios para usar la anotación.
import javax.persistence.*;
import javax.persistence.Entity;
import java.io.Serializable;
@Entity
public class Course implements Serializable {}
Para GenerationType hay varias opciones que se describirán a continuación.
2.1. GenerationType.TABLE.
Simula una secuencia almacenando y actualizando su valor actual en una tabla de base de datos que requiere el uso de bloqueos pesimistas que colocan todas las transacciones en un orden secuencial . Esto ralentiza su aplicación.
@Id @GeneratedValue(strategy= GenerationType.TABLE) private Long id;
2.2. GenerationType.AUTO.
El GenerationType.AUTO es el tipo de generación por defecto y permite que el proveedor de persistencia elegir la estrategia de generación.
Si usa Hibernate como su proveedor de persistencia, selecciona una estrategia de generación basada en el dialecto específico de la base de datos.
@Id @GeneratedValue(strategy= GenerationType.AUTO) private Long id;
2.3. GenerationType.IDENTITY.
Se basa en una columna de base de datos con incremento automático y permite que la base de datos genere un nuevo valor con cada operación de inserción. Desde el punto de vista de la base de datos, esto es muy eficiente porque las columnas de incremento automático están altamente optimizadas y no requiere ninguna declaración adicional.
Este enfoque tiene un inconveniente importante si usa Hibernate, ya que requiere un valor de clave principal para cada entidad administrada y, por lo tanto, debe realizar la instrucción de inserción de inmediato. Esto evita que utilice diferentes técnicas de optimización como el procesamiento por lotes JDBC.
@Id @GeneratedValue(strategy= GenerationType.IDENTITY) private Long id;
2.4. GenerationType.SEQUENCE.
El GenerationType.SEQUENCE utiliza una secuencia de bases de datos para generar valores únicos.
Requiere sentencias select adicionales para obtener el siguiente valor de una secuencia de base de datos. Pero esto no tiene impacto en el rendimiento para la mayoría de las aplicaciones. Y si su aplicación tiene que persistir una gran cantidad de nuevas entidades, puede usar algunas optimizaciones especificas de hibernate para reducir la cantidad de declaraciones.
@Id @GeneratedValue(strategy= GenerationType.SEQUENCE) private Long id;
Si no proporciona ninguna información adicional, Hibernate solicitará el siguiente valor de su secuencia predeterminada. Puede cambiar eso haciendo referencia al nombre de un @SequenceGenerator en el atributo generador de la anotación @GeneratedValue . La anotación @SequenceGenerator le permite definir el nombre del generador, el nombre y el esquema de la secuencia de la base de datos y el tamaño de asignación de la secuencia.
@GeneratedValue(generator="sequenciaDePrueba") @SequenceGenerator(name="sequenciaDePrueba",sequenceName="DB_SEQUENCIA", allocationSize=1)
SEQUENCE permite que Hibernate use el procesamiento por lotes JDBC y otras estrategias de optimización que requieren la ejecución retrasada de las instrucciones SQL INSERT.
Pero no puede usar esta estrategia con una base de datos MySQL. Requiere una secuencia de base de datos, y MySQL no admite esta función.
Por lo tanto, debe elegir entre IDENTITY y TABLE . Esa es una decisión fácil considerando los problemas de rendimiento y escalabilidad de la estrategia TABLE .
Si está trabajando con una base de datos MySQL, siempre debe usar GenerationType.IDENTITY . Utiliza una columna de base de datos auto_increment y es el enfoque más eficiente disponible. Puede hacerlo anotando su atributo de clave principal con @GeneratedValue (estrategia = GenerationType.IDENTITY).
3. Usando @GenericGenerator.
permite la integración de cualquier org.hibernate.id.IdentifierGenerator implementación de Hibernate entre ellos: native,foreign,select pulse aquí para saber más.
@Id
@GeneratedValue(strategy= GenerationType.AUTO,
generator= "native"
)
@GenericGenerator(
name = "native",
strategy = "native"
)
private Long id;
Cuando usa un @GenericGenerator que hace referencia a la estrategia nativa , Hibernate usa la estrategia soportada de forma nativa por el Dialecto configurado . Puede encontrar el código correspondiente en la clase Dialecto . Aquí está el código que se usa en Hibernate 5.4.
public String getNativeIdentifierGeneratorStrategy() {
if ( getIdentityColumnSupport().supportsIdentityColumns() ) {
return "identity";
}
else {
return "sequence";
}
}
Para todas las bases de datos de uso común, excepto MySQL, este método devuelve la «secuencia» de String . Si está utilizando un dialecto MySQL, devuelve «identidad».
4. Las diferencias entre la estrategia de identidad y nativa.
Siempre que use ambas asignaciones con una base de datos MySQL.
- El comportamiento de la estrategia nativa cambia si el dialecto de la base de datos devuelve una estrategia diferente a la nativa. Eso podría suceder porque ahora usa un dialecto de base de datos diferente o la implementación interna del dialecto cambió.
- El mapeo @GenericGenerator es mucho más difícil de leer porque depende de la implementación del dialecto de la base de datos.
- La anotación @GenericGenerator es específica de Hibernate. Por lo tanto, no puede usar esta asignación con ninguna otra implementación de JPA.
5. Anular partes de su mapeo.
- Y con una base de datos MySQL, podrías anular la estrategia de generación con un archivo de mapeo adicional.
- De manera predeterminada, JPA e Hibernate verifican si existe un archivo orm.xml en el directorio META-INF y lo utilizan para anular las asignaciones definidas por las anotaciones. Por lo tanto, sólo necesita proporcionar las asignaciones que desea cambiar.
- En este caso, es solo la estrategia de generación para el atributo id de la entidad Autor.
<entity-mappings>
<entity class="yourpackage.java.model.Author" name="Author">
<attributes>
<id name="id">
<generated-value strategy="identity"/>
</id>
</attributes>
</entity>
</entity-mappings>
6. Conclusiones.
Hibernate ofrece características sólidas y sobre todo pensadas para el buen funcionamiento de tu motor de base de datos, así que elegir bien la estrategia es un paso importante que tendrá impacto positivo o negativo en tu proyecto.
Para ampliar tu conocimiento.
https://www.adictosaltrabajo.com/2008/06/14/hibernate-validator/

