

Aprenderemos a construir un dataFrame, a obtener datos con R a través de la librería RCurl, a leer un fichero de formato de ancho fijado (FWF), tablas HTML y a parsear XMLs. También presentaremos la sintaxis del $, y comenzaremos a hacer nuestros primeros pinitos con gráficos,
Índice de contenidos
- 1. Introducción
- 2. Construir un DataFrame
- 3. Leer un fichero de ancho fijo
- 4. Leer una tabla HTML de la Web
- 5. Leer un XML de la Web
- 6. La sintaxis del $
- 7. Primeros gráficos con R
- 8. Conclusiones
- Enlaces y referencias
1. Introducción
Este artículo está enmarcado dentro de una serie de tutoriales sobre R y RStudio. En capítulos anteriores se vio cámo leer un archivo CSV con RStudio, y cómo cargar un JSON desde internet en un dataFrame con el que poder trabajar. Tuvimos una primera toma de contacto con las librerías jsonlite y curl, y aprendimos algunas funciones básicas como es concatenar cadenas de texto y escapar caracteres de una URI. También aprenderemos a mezclar dos dataFrames por un índice y a verificar que son idénticos.
El objetivo de este tercer post es ir acabando la parte introductoria, que la verdad, ya se está haciendo larga. Pero primero aún tenemos que aprender unas pocas cositas más antes de dar el siguiente paso.
2. Construir un DataFrame
En alguna ocasión, nos puede interesar construir nuestro propio DataFrame en base a datos que ya tengamos, o que nosotros mismos fabriquemos. Es muy fácil, pero lo cierto es que aún no lo he explicado en ninguno de los post anteriores.
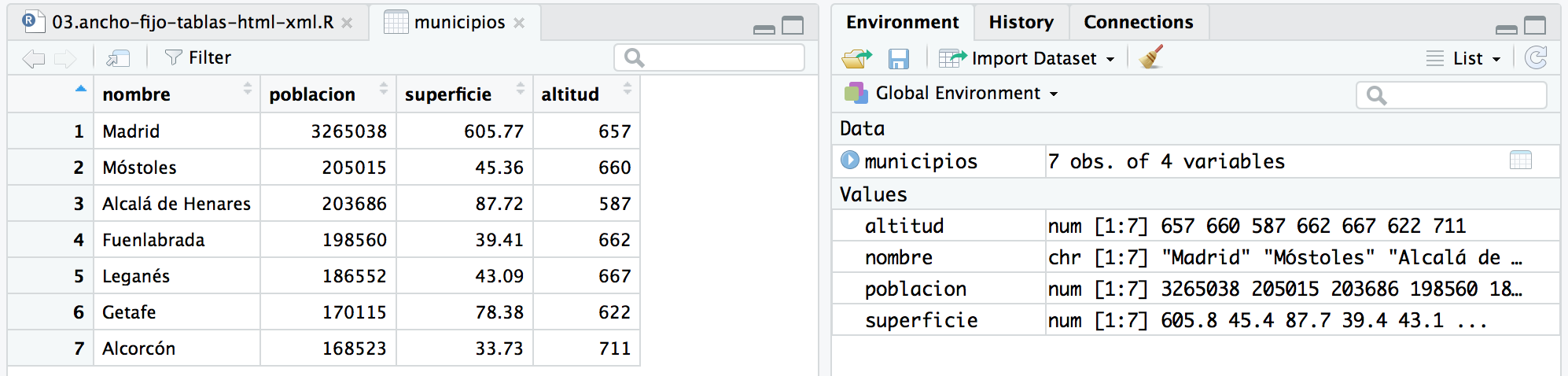
Para ejemplificar como crear un dataFrame, vamos a construir uno muy sencillo con algunos datos reseñables de los municipios de Madrid con más de 150.000 habitantes.
Lo primero que haremos será definir el conjunto de nombres de esos municipios. Recordemos que para definir un conjunto se usa la función c() pasándole por parámetros los elementos de dicho conjunto.
nombre <- c("Madrid","Móstoles","Alcalá de Henares","Fuenlabrada","Leganés","Getafe","Alcorcón")
El siguiente paso será declararemos una variable que guarde un conjunto con la población de cada municipio. Esto es un conjunto con el número de habitantes de cada ciudad.
poblacion <- c(3265038,205015,203686,198560,186552,170115,168523)
Repetiremos la operación con la superficie en Km2 y la altitud en metros sobre el nivel del mar.
superficie <- c(605.77, 45.36, 87.72, 39.41, 43.09, 78.38, 33.73) altitud <- c(657, 660, 587, 662, 667, 622, 711)
Y por fin, ya estamos es disposición de construir el dataFrame municipios como la combinación de todas estas variables.
municipios <- data.frame(nombre, poblacion, superficie, altitud)
3. Leer un fichero de ancho fijo
Sin embargo, hay ocasiones en que la estructura de la información no viene de una forma tan intuitiva, y los campos de cada fila vienen definidos en base a su longitud, y a la posición que ocupa en la línea. Por ejemplo
12345678FManolito Gafotas Gafotas 915555555MADRID
Donde la posición:
- [1 – 9] es el DNI
- [10 – 40] el nombre
- [41 – 49] el teléfono
- [50 – 65] la localidad
He buscado y buscado ejemplos de ficheros de este tipo en Internet sin demasiado éxito. Sin embargo, me consta que se siguen usando una barbaridad, pero se suelen consumir de forma interna, entre sistemas middleware y no es habitual que se expongan públicamente en ninguna web. He encontrado uno que puede servir a nuestros fines. Vamos a ver como leer un fichero de este tipo, que llamaremos FWF – Fixed Width Format.
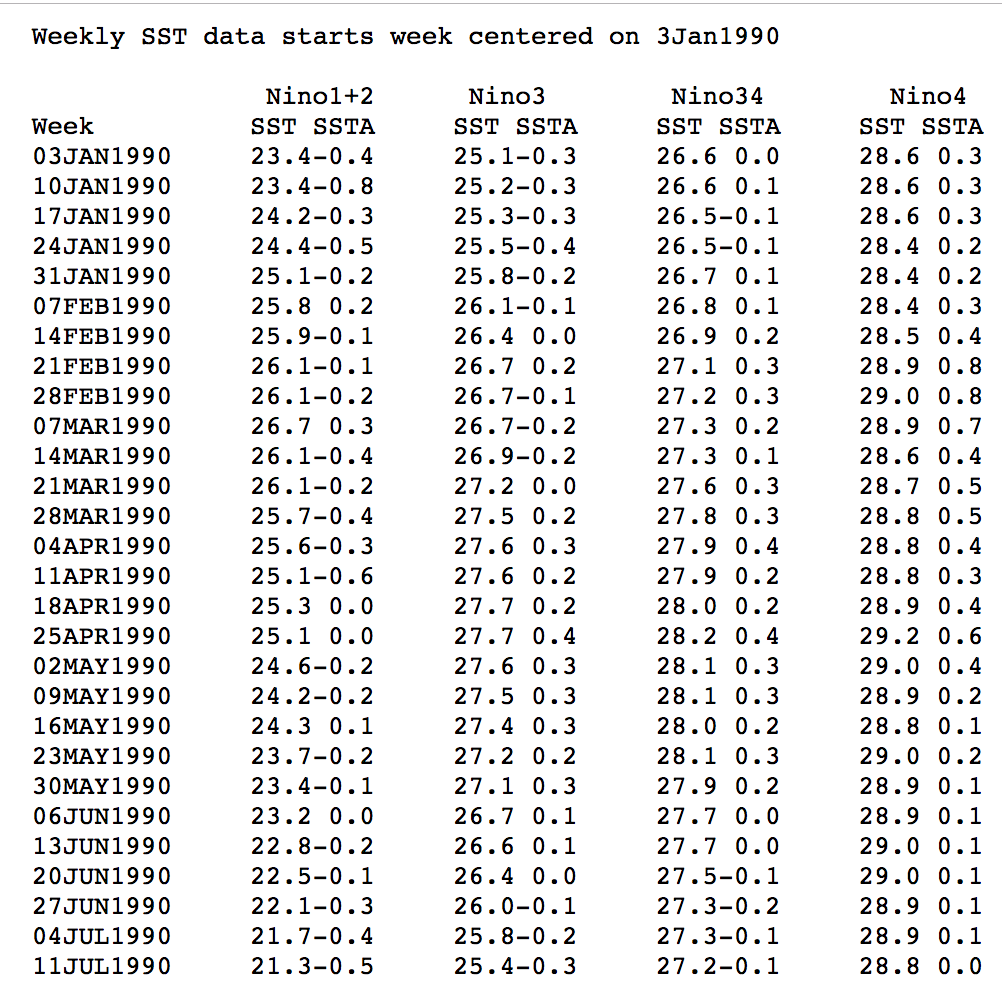
En esta ocasión se ve claramente que la información está dispuesta en 5 columnas. Que las 4 primeras filas las podríamos saltar, pues no nos aportan información a los datos. Usamos una función para leer los ficheros de tipo Fixed Width Format, e indicamos la longitud de las columnas:
data <- read.fwf("https://www.cpc.ncep.noaa.gov/data/indices/wksst8110.for",
widths=c(15, 13, 13, 13, 8),
skip=4,
col.names = c("Week", "Nino1+2", "Nino 3", "Nino 34", "Nino 4"))
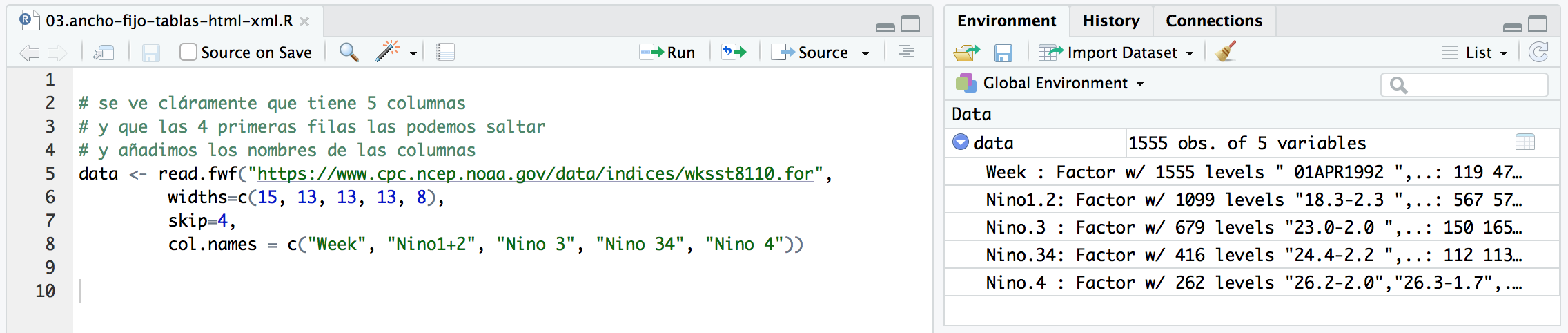
El resultado se acerca a lo que queremos, pero hay algunos matices que nos convendría reseñar. Démonos cuenta que los valores de las columnas tienen espacios a izquierda y derecha. Además la función los ha cargado como factores en lugar de strings. Quizás sería interesante hacer el trim y convertirlos a strings.
# los valores contienen espacios delante y detrás.
# con el simbolo menos, indicamos el ancho, pero que no queremos la columna
# y además indicamos que los strings no son factores
data <- read.fwf("https://www.cpc.ncep.noaa.gov/data/indices/wksst8110.for",
widths=c(-1, 9, -5, 8, -5, 8, -5, 8, -5, 8),
skip=4,
col.names = c("Week", "Nino1+2", "Nino3", "Nino34", "Nino4"),
stringsAsFactors = F
)
De esta forma, el resultado sí es como deseamos.
4. Leer una tabla HTML de la Web
Con frecuencia las fuentes de datos están incrustadas en una web y necesitamos adquirir dicha información para trabajar con ella en un dataFrame.
En este ejemplo, vamos a conectarnos a la página de cotizaciones de El País, para coger los valores del Ibex 35. Para ello utilizaremos la librería XML.
install.packages("XML")
library(XML)
urlDeEjemplo <- "https://cincodias.elpais.com/mercados/bolsa/ibex_35/582/"
doc <- readHTMLTable(urlDeEjemplo)
La petición anterior nos ha devuelto un error: # Warning message: XML content does not seem to be XML:.
Esto error ocurre porque la función readHTMLTable no es capaz de leer HTTPS. Para eso usaremos la librería RCurl, que nos permite obtener datos con R y guardarlos en un objeto en memoria, aunque el contenido esté en una URL segura.
install.packages("RCurl")
library(RCurl)
# y obtenemos el HTML y lo guardamos en una variable de R
htmlData <- getURL(urlDeEjemplo)
# ahora buscamos las tablas existentes en el HTML
tables <- readHTMLTable(htmlData)
# tables es una lista de dos dataFrames (hay dos tablas)
# nos quedamos con el que se llama indice_valores
ibex35 <- tables[["indice_valores"]]
# visualizamos los datos que hemos obtenido
View(ibex35)
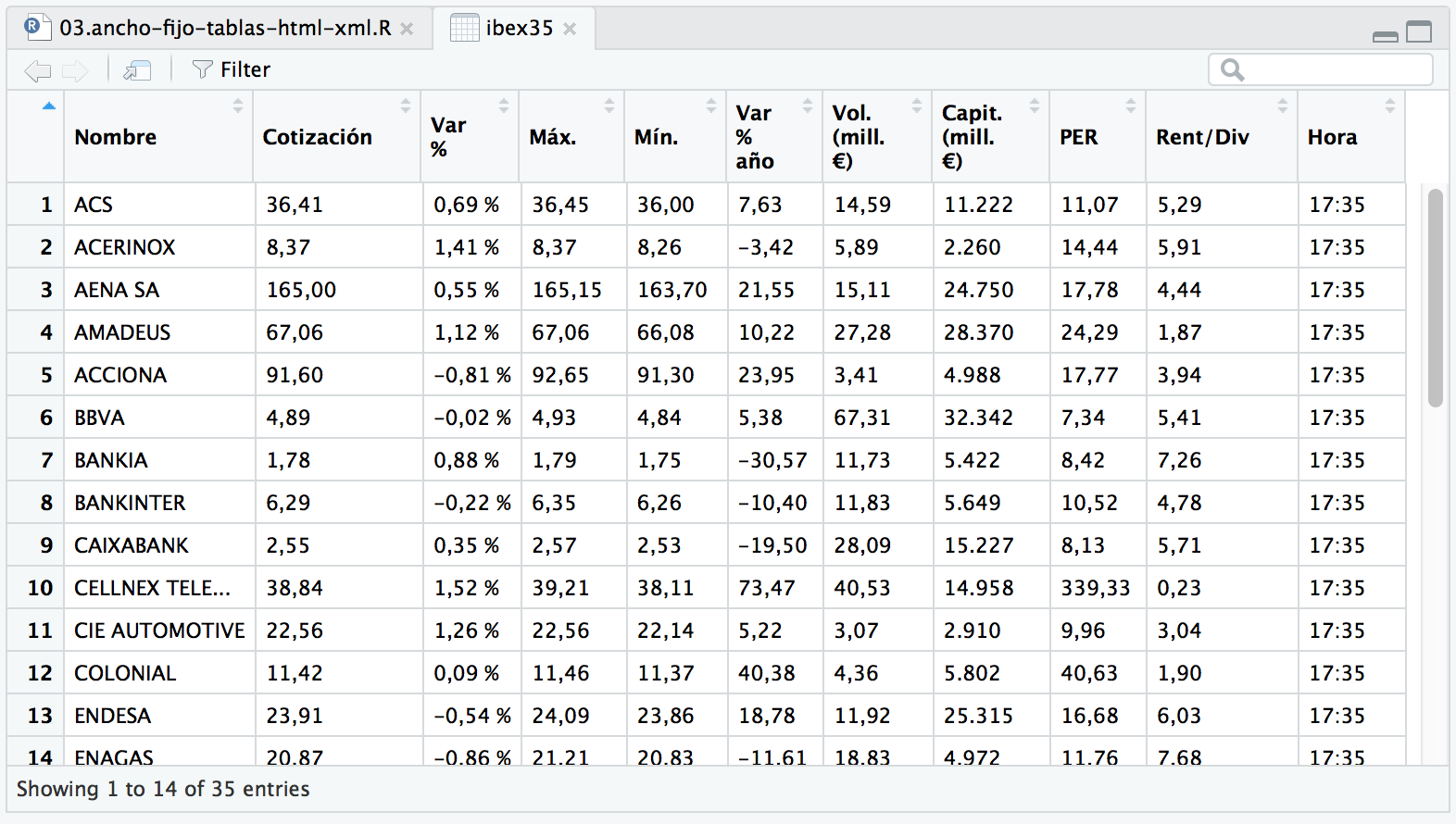
Con RCurl, podemos obtener datos con R, ya sean XML, HTML, FWF o cualquier otro tipo de formato. Merece la pena echar un vistazo a la documentación de RCurl para comprender sus posibilidades.
5. Leer un XML de la Web
Otro ejemplo habitual que nos quedaría tratar es el de leer un XML de la WEB. El ejemplo que hemos elegido es un XML de la Biblioteca Nacional.
# instalamos/actualizamos la librería y la cargamos
install.packages("XML")
library(XML)
# Número de registros de autoridad en el catálogo de la BNE en 2018
# http://www.bne.es/media/datosgob/estadisticas/autoridades/Autoridades_2018.xml
urlBNE2018 <- "http://www.bne.es/media/datosgob/estadisticas/autoridades/Autoridades_2018.xml"
xmlDocument <- xmlParse(urlBNE2018)
rootNode <- xmlRoot(xmlDocument)
# es un XML muy sencillo que no tiene atributos y sólo tiene valores
# Lo que queremos hacer es por cada ITEM extraer los pares clave-valor
# usamos xmlSApply que a cada elemento le aplica una función.
catalogo <- xmlSApply(rootNode, function(x) {
xmlSApply(x, xmlValue)
})
# la hemos aplicado dos veces. Vemos la pinta que tiene
View(catalogo)
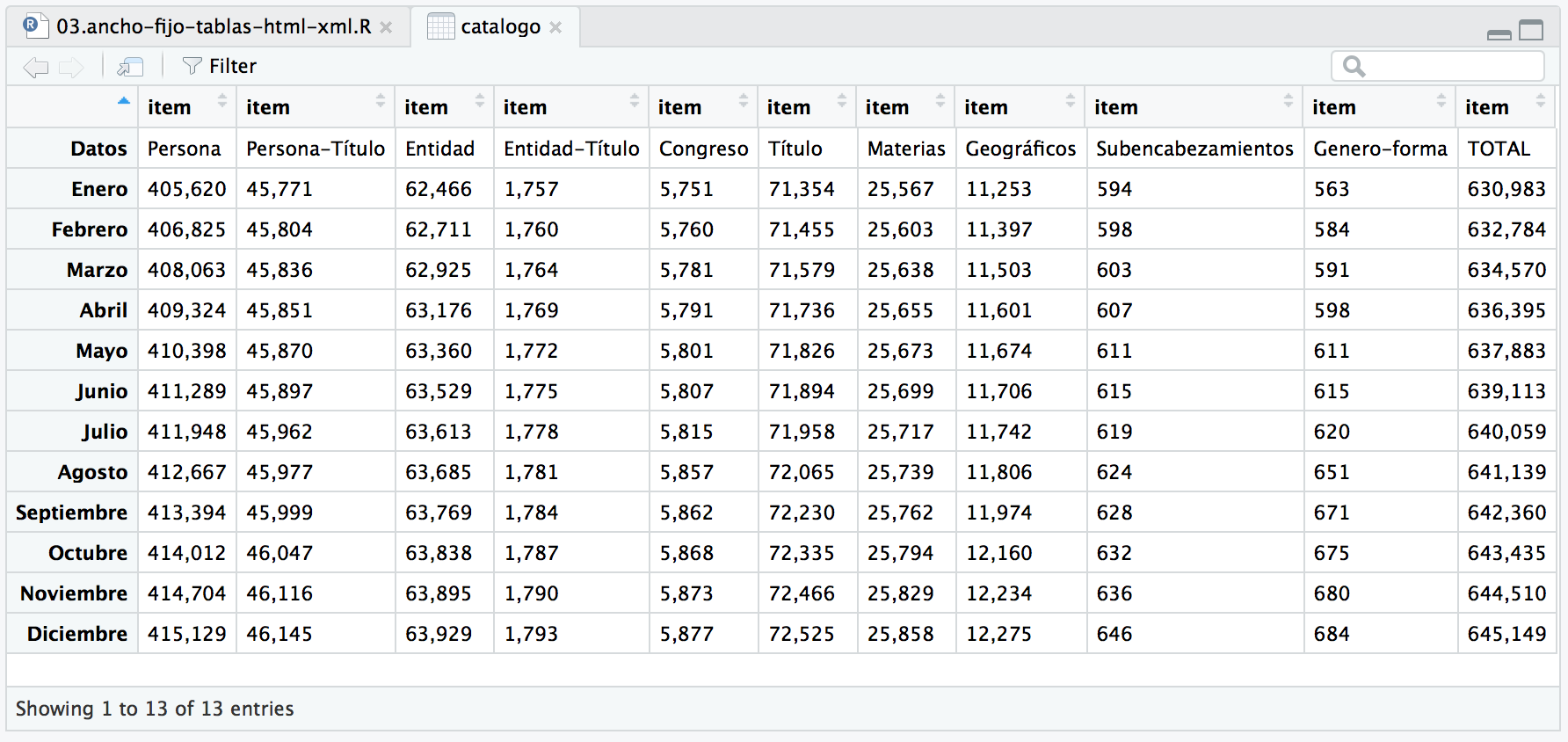
# Se observa que las filas están cambiadas por columna. # transponemos la matriz catalogo y la guardamos en la misma variable catalogo <- t(catalogo) # y lo convertimos en un dataFrame catalogo <- data.frame(catalogo)
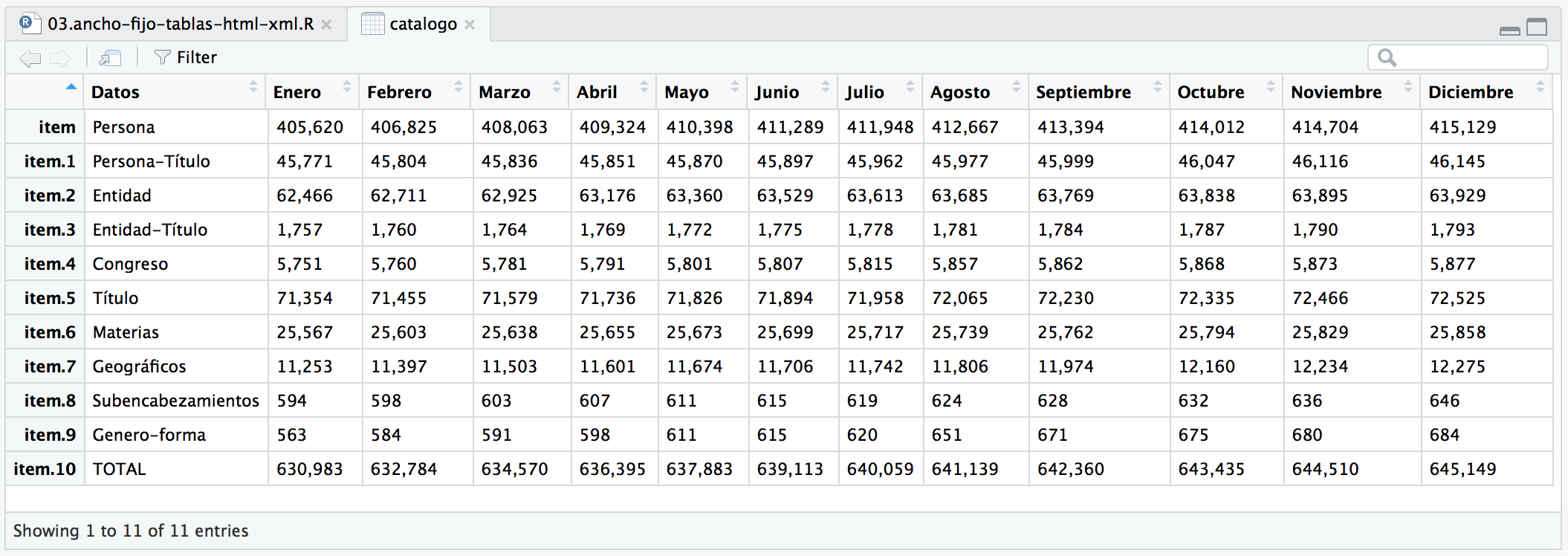
# pero los nombres de las filas son item.1 ... item.10. # podemos solventarlo poniéndolos a NULL y será 1 ... 10 row.names(catalogo) <- NULL # pero a lo mejor preferimos usar como rowNames el valor de la columna "Datos" # y quitar dicha columna que no aporta información numérica row.names(catalogo) <- catalogo$Datos catalogo$Datos <- NULL
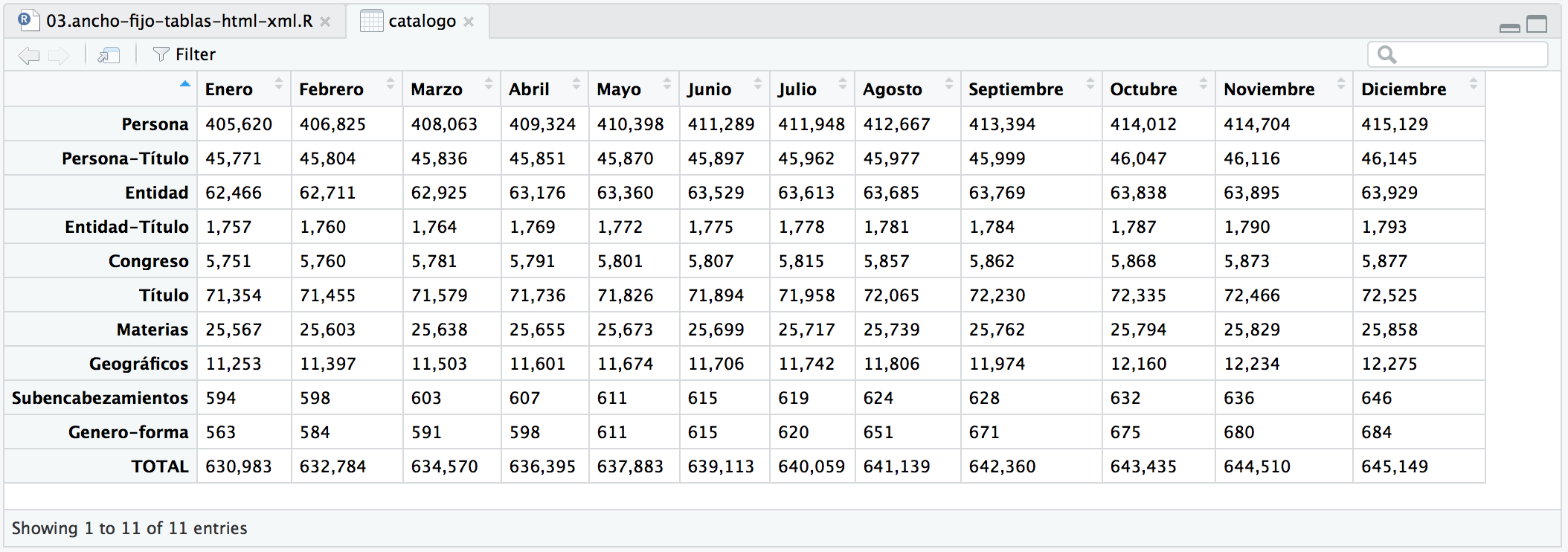
6. La sintaxis del $
Sin apenas darnos cuenta me temo que ya hemos utilizado la sintaxis del dólar. Lo hemos hecho de una forma intuitiva para acceder a valores de columnas.
# por ejemplo row.names(catalogo) <- catalogo$Datos
Como muestra, utilizaremos una página con algunos datos de Alcorcón y me voy a fijar en la población.
install.packages("jsonlite")
library(jsonlite)
poblacion_alcorcon <- fromJSON("poblacion_alcorcon.json")
# La variable es una "List of 5". Veamos que aspecto tiene la lista
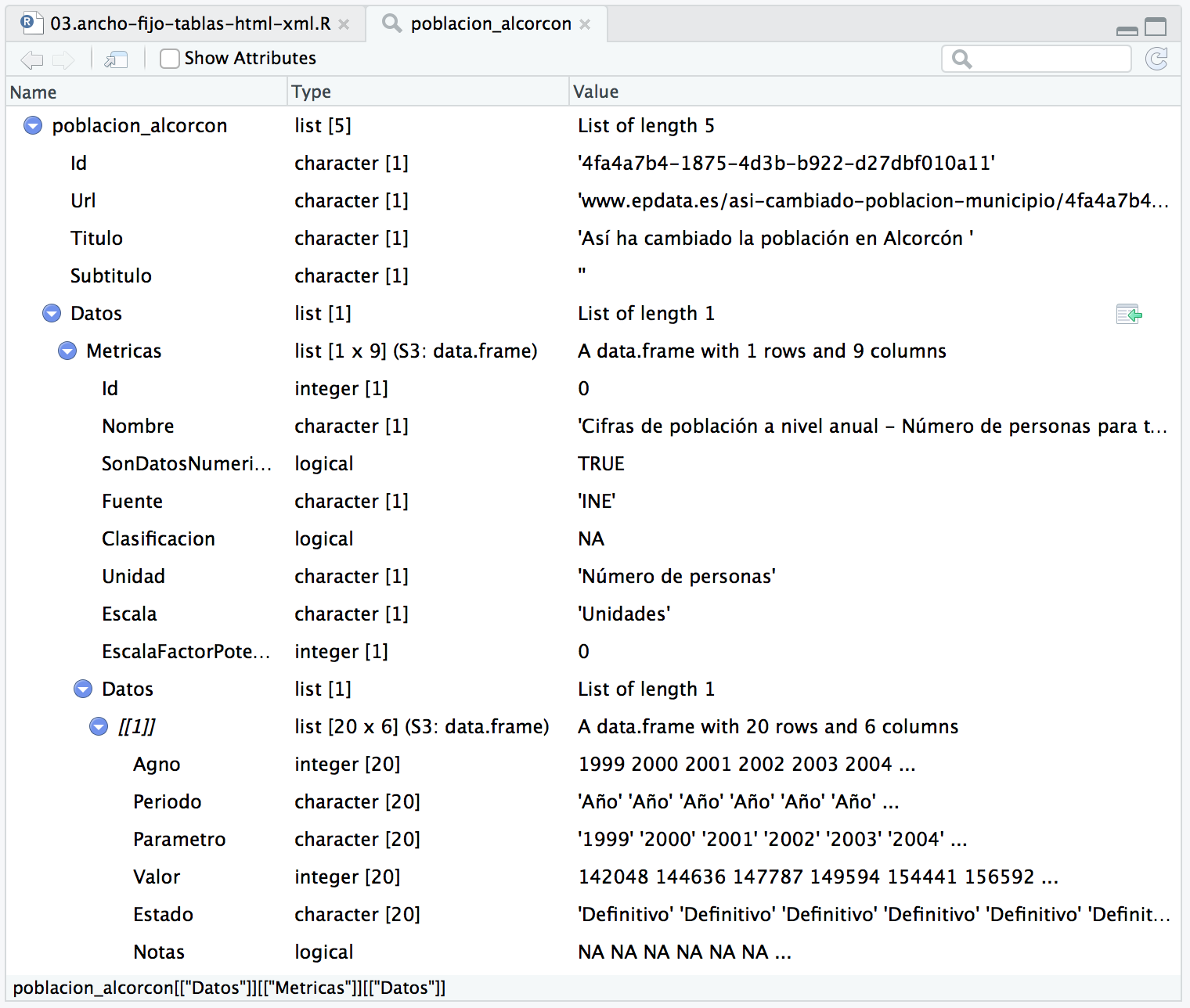
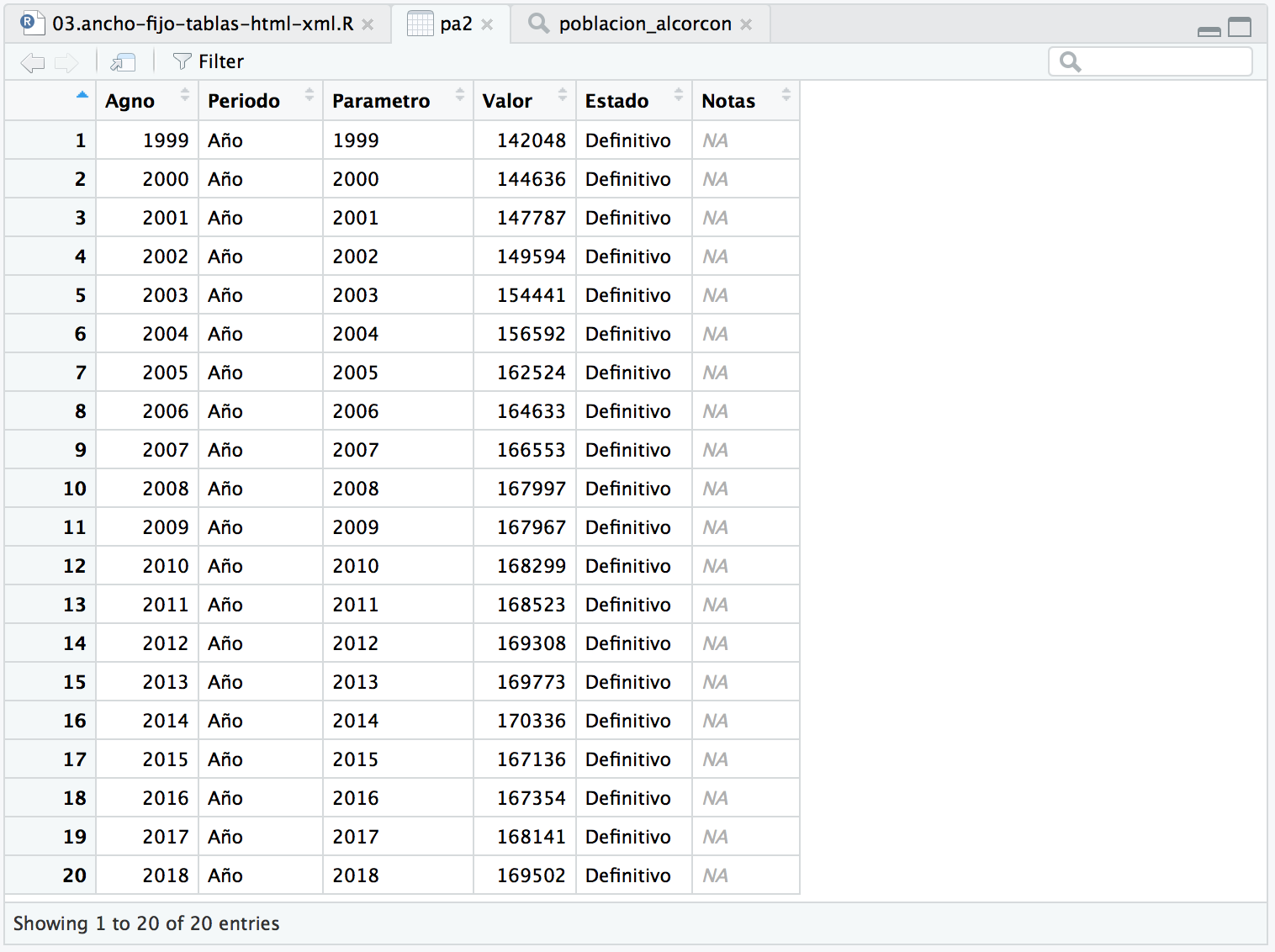
En la parte inferior de la imagen se nos indica la ruta hasta llegar a esa variable en forma de array asociativo.
# Al ser una lista podemos recorrerla como array asociativo pa1 <- poblacion_alcorcon[["Datos"]][["Metricas"]][["Datos"]][[1]]
Pero es mucho más cómodo acceder por nombre de variable al interior de cada uno de los objetos usando el operador $.
# pero podemos usar la potencia del operador $ (RStudio nos autocompleta) pa2 <- poblacion_alcorcon$Datos$Metricas$Datos[[1]]
Comprobemos que ambos dataFrames son idénticos.
identical(pa1,pa2)
Y es mucho más cómodo recorrer la estructura anidada mediante el operador $ que como array asociativo.
7. Primeros gráficos con R
R trae de serie un buen conjunto de dataSets para que podamos hacer nuestras pruebas, y muchos de los ejemplos que encontraréis en internet usan estos dataSets, que se encuentran en el package:dataSets
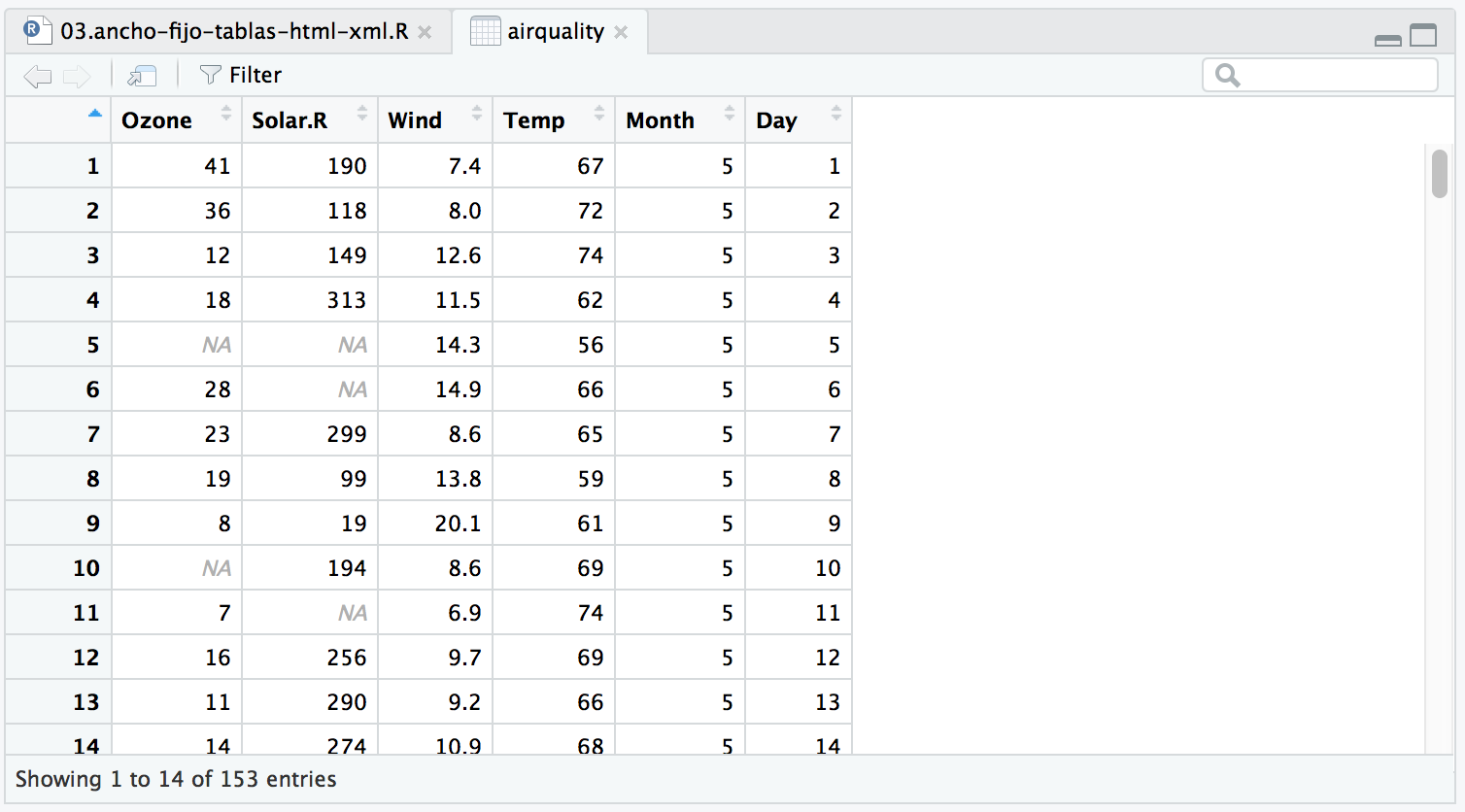
Elijo el dataSet airquality que nos dice la calidad del aire en New York de mayo a septiembre de 1973. Echemos un vistazo a este dataSet.
View(airquality)
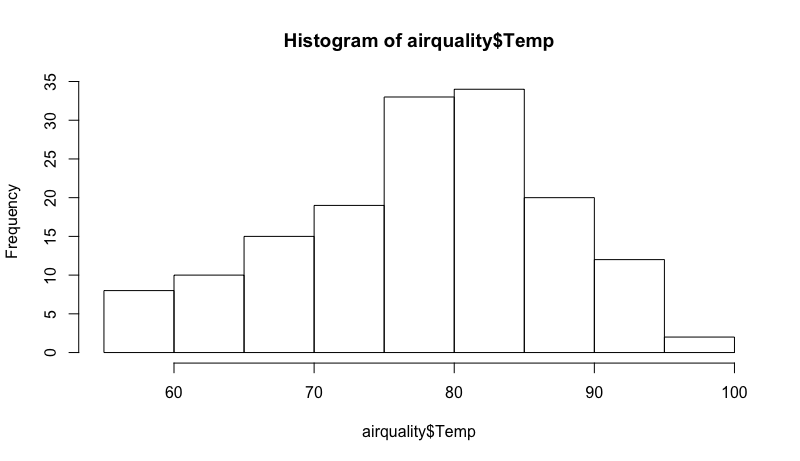
Si queremos un histograma con la densidad de frecuencias de temperatura sería:
hist(airquality$Temp)
Se observa que el gráfico es bastante simple, y que no hemos podido indicar el número de barras que queremos. En el eje Y aparece la frecuencia de cada rango de temperaturas, y en el eje X unas franjas de temperatura.
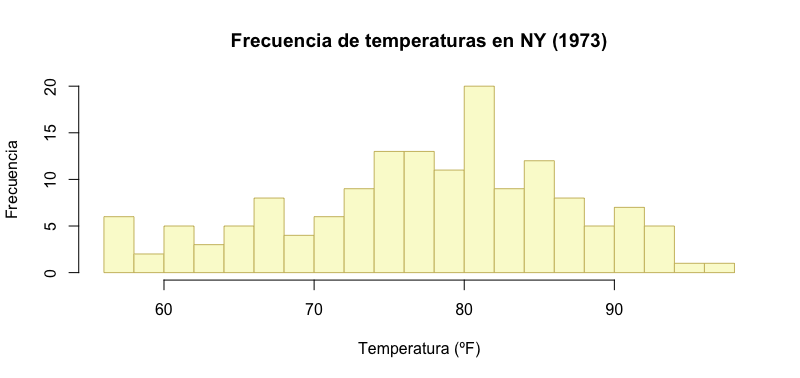
Sin duda, podemos mejorarlo. Lo primero de todo es indicar el número de barras que queremos. Entre la temperatura mínima y la máxima hay 41 ºF de diferencia. Podemos usar esta medida como punto de partida para establecer el número de barras. Le podemos añadir un título con el parámetro main, y las etiquetas que deberán tener el eje X e Y. Además de jugar un poquito con los colores de relleno y de las líneas.
numsaltos <- max(airquality$Temp) - min(airquality$Temp)
hist(airquality$Temp,
breaks = numsaltos/2,
col = "lightgoldenrodyellow",
border = "lightgoldenrod3",
xlab = "Temperatura (ºF)",
ylab = "Frecuencia",
main = "Frecuencia de temperaturas en NY (1973)"
)
# para conocer el nombre de los colores podemos usar
colors()
8. Conclusiones
Aún no hemos hecho grandes cosas. Estamos asentando los cimientos con los que trabajaremos en R. Pero no es baladí lo aprendido en este artículo:
- hemos aprendido a construir un dataFrame a mano
- ya sabemos como obtener datos con R
- somos capaces de leer ficheros con formateo de ancho fijo (fixed width format)
- podemos leer una tabla HTML de la Web, que nos introduce en el Web Scraping
- hemos usado la librería RCurl para obtener ficheros a través de HTTPS
- aprendimos a leer XML de la Web y parsear documentos XML
- hicimos un acercamiento a la función xmlSApply
- aprendimos a obtener la transformada de una matriz
- conocimos la sintaxis del dolar ($)
- y tuvimos un primer acercamiento a los gráficos en R, en concreto con el histograma
Enlaces y Referencias
- El código fuente de este tutorial en GitHub
https://github.com/eContento/rstudio


Hola
Gracias por el artículo
¿Hay alguna manera de trabajar archivos HTML en R? ¿Quiero importar archivos HTML a R para poder trabajarlos, como puedo hacer eso? Ya tengo los archivos guardados
Gracias de antemano
Hola María,
Precisamente en el punto 4 de este artículo, se lee una página web y se carga una tabla HTML en un dataFrame mediante la función readHTMLTable().
Si lo que te refieres, es a leer un fichero HTML sin que esté subido a un servidor web, es decir, en local, puedas usar la misma función según la documentación, aunque no lo he probado, pero usando una ruta local relativa a a tu working directory (acuérdate que lo primero que hacemos es setear el working directory mediante setwd().
En cualquier caso, si tienes acceso al fichero original, es mucho más fácil duplicarlo, quedarte sólo con la información que te interesa, y mediante transformaciones no te costaría mucho convertirlo a un CSV.
Espero haberte ayudado