

En este artículo aprenderemos cómo leer un JSON con R usando RStudio. Trataremos un JSON desde internet y lo cargaremos en un dataFrame con el que poder trabajar. Conoceremos la librería jsonlite y curl, además de aprender cómo escapar caracteres de una URI, y cómo concatenar cadenas de texto. También aprenderemos a mezclar dos dataFrames y a verificar que son idénticos o no.
Índice de contenidos
- 1. Introducción
- 2. Leer un JSON con R desde una URI
- 3. Cargar estaciones de Metro desde R
- 4. Cargar precios de la vivienda por estaciones de Metro desde R
- 5. Dando una vuelta de tuerca a la API
- 6. Decidiendo donde invertir
- 7. Conclusiones
- Enlaces y referencias
1. Introducción
En el artículo anterior vimos cómo leer un archivo CSV con RStudio y a cargar los datos en un dataFrame. También aprendimos a filtrar estos datos por filas y columnas. A limpiar los datos de valores extraños y a guardar un objeto, normalmente un dataFrame, en un fichero entendible luego por R.
Antes de meternos en harina, creo que debemos seguir aprendiendo los rudimentos de R y aprender cómo leer un JSON con R y tratarlo.
2. Leer un JSON con R desde una URI
Desgraciadamente no siempre tendremos un fichero con el que trabajar, si no que tendremos que cargar la información directamente de internet. Hay multitud de formatos, pero sin duda el más extendido es JSON.
Para trabajar este ejemplo nos vamos a basar en una página web que expone públicamente un dataset con la información de las paradas de metro de Madrid
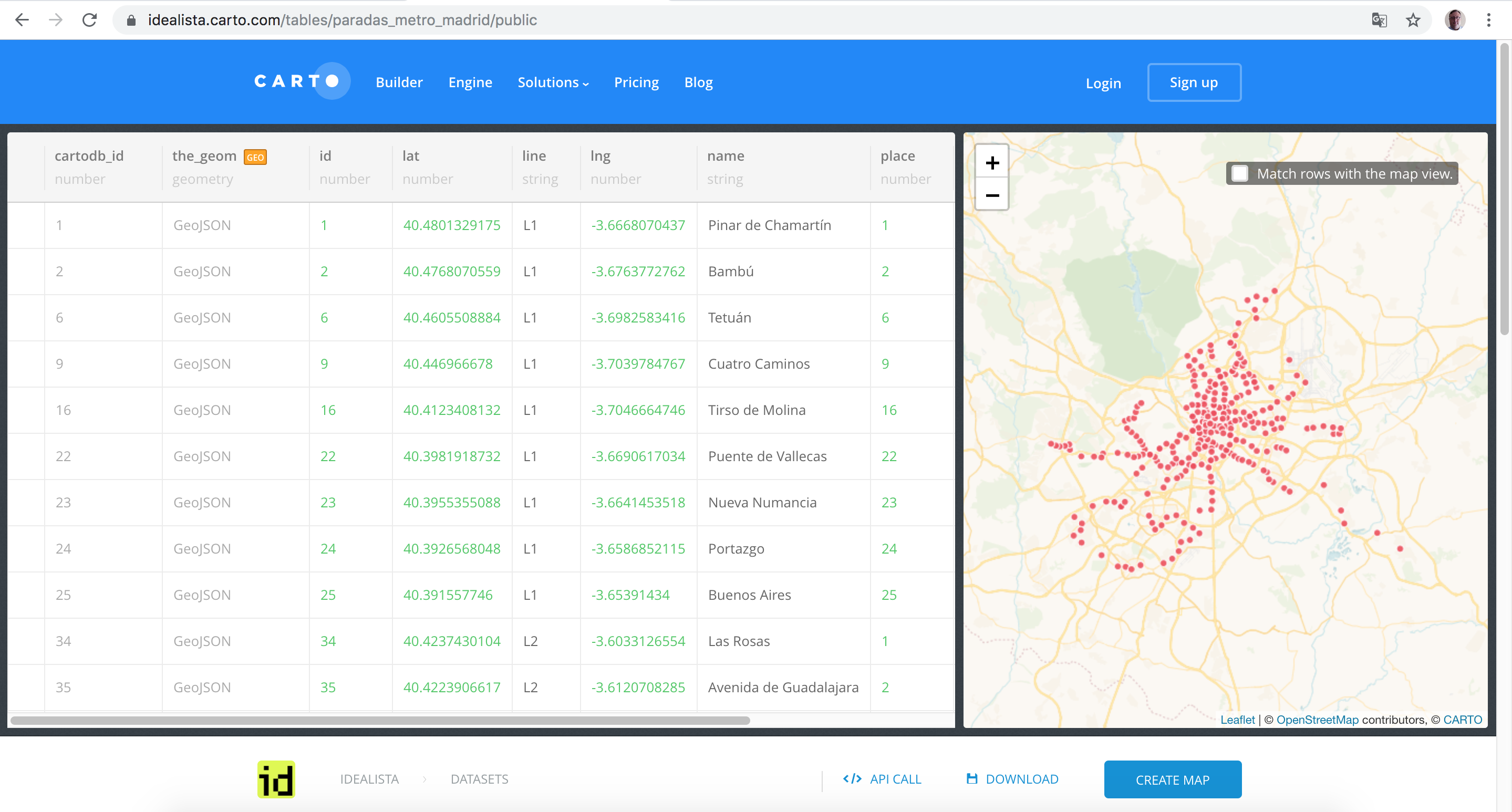
Y nos ofrece una API para consultarla:
https://idealista.carto.com:443/api/v2/sql?q=select * from public.paradas_metro_madrid
Por otro lado, hay otro dataSet que nos dice el precio por m2 de compra y alquiler a 500m de dichas paradas de metro (datos de mayo de 2016).
https://idealista.carto.com:443/api/v2/sql?q=select * from public.precio_metro_201605
Si echamos un vistazo a lo que nos devuelven estas peticiones vemos que de las paradas de metro nos interesan sólo algunos campos. Fijémonos en la primera fila
{
"cartodb_id":1,
"the_geom":"0101000020E610000073F38DE89E550DC07D5D86FF743D4440",
"the_geom_webmercator":"0101000020110F00008DE9305AECE918C1D9818D4B46D45241",
"place":1,
"id":1,
"name":"Pinar de Chamartín",
"line":"L1",
"lat":40.4801329175,
"lng":-3.6668070437
}
- cartodb_id: es la PK o un índice númerico propio de la BBDD.
- the_geom y the_geom_webmercator son campos propios de un estándar GIS llamado GeoJSON (ver https://es.wikipedia.org/wiki/GeoJSON)
- place: es el lugar que ocupa la estación en la línea. Esta es la primera estación
- id: huele a identificador único de todas las estaciones
- line: Línea de metro.
- lat y lng: son coordenadas terrestres (latitud y longitud)
De estos campos, yo creo que para trabajar nos vamos a quedar sólo con ID, NAME, LINE, PLACE, LAT y LNG
https://idealista.carto.com:443/api/v2/sql?q=select ID, NAME, LINE, PLACE, LAT, LNG from public.paradas_metro_madrid
3. Cargar estaciones de Metro desde R
Lo primero que haremos será crearnos un script de R y definir nuestro directorio de trabajo. Luego instalaremos y cargaremos alguna librería que nos permita leer un JSON con R. Yo he elegido jsonlite. Como en lugar de trabajar con un fichero, yo quiero consultar directamente de internet, instalo una librería que me permita trabajar con URLs y la cargo en memoria. Después de esto ya estaremos en condiciones de cargar un JSON en un dataFrame.
#seteamos el directorio de trabajo
setwd("/lab/adictosaltrabajo/rstudio/02")
# como vamos a trabajar con JSON me instalo la librería
# y la cargo en memoria
install.packages("jsonlite")
library(jsonlite)
# vamos a trabajar con URLs en lugar de ficheros, así que cargamos la libreria
# y la cargamos en memoria
install.packages("curl")
library(curl)
Definimos una variable con la URI que queremos consultar y llamamos a la funcion de la librería jsonlite
uri_paradas_metro <- "https://idealista.carto.com/api/v2/sql?q=select ID, NAME, LINE, PLACE, LAT, LNG from public.paradas_metro_madrid" paradas_metro <- fromJSON(uri_paradas_metro)
Y vemos que la consola nos da el siguiente error:
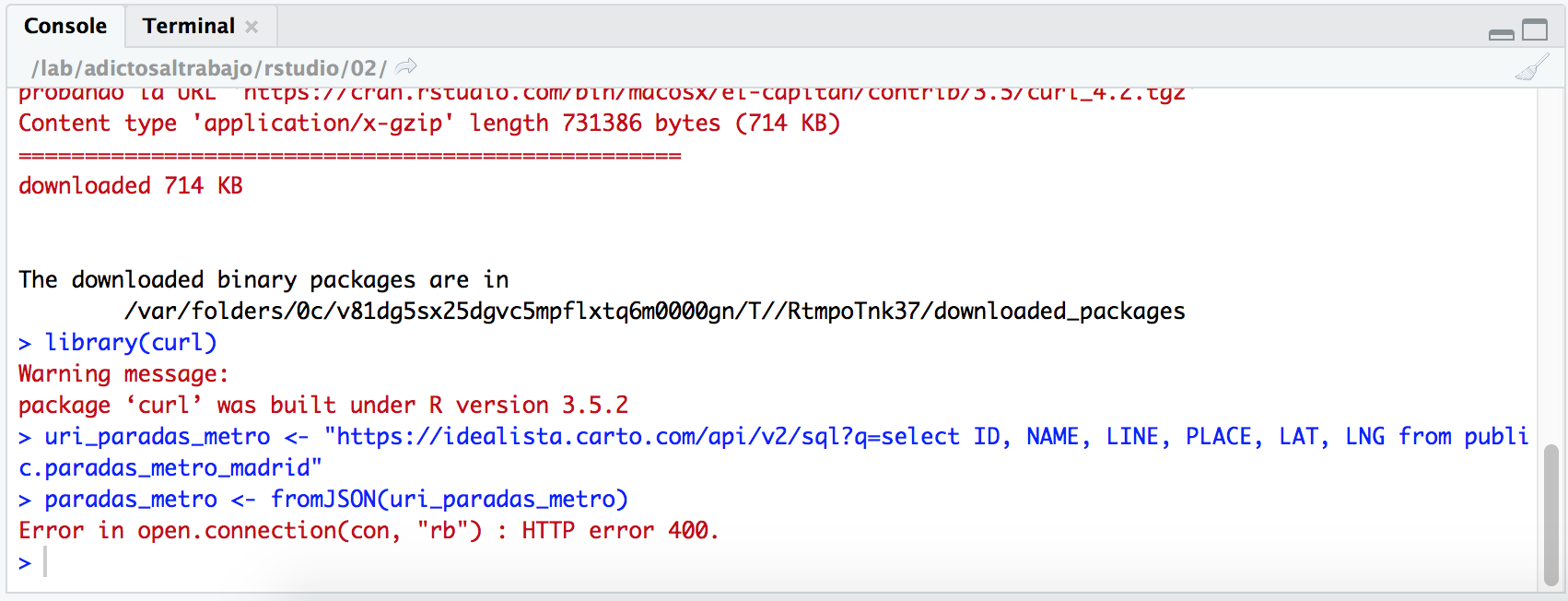
Nos ha dado un error de tipo 400. Si nos fijamos, nos damos cuenta, que en el navegador, al pegar la URI, los espacios en blanco de la query se reemplazan por «%20». Lo que tendremos que hacer es escapar la URL. Seguro que la librería curl nos proporciona alguna función que lo haga.
q <- curl_escape("select ID, NAME, LINE, PLACE, LAT, LNG from public.paradas_metro_madrid")
uri_paradas_metro <- paste("https://idealista.carto.com/api/v2/sql?q=",q, sep="")
paradas_metro <- fromJSON(uri_paradas_metro)
En el bloque anterior vemos dos funciones nuevas. Por un lado curl_escape que hace un encoding y escapa los caracteres de la URL dada, y por otro paste, que nos sirve para concatenar cadenas indicándole un separador.
Y efectivamente, vemos que tenemos un nuevo objeto que es una Lista de 4 elementos, del cual nos interesa rows que es un dataFrame.

paradas_metro <- paradas_metro[["rows"]]
¿Y las paradas que son transbordos? ¿Cómo salen? ¿aparece una única fila con dos datos en el campo línea? ¿o son dos filas? ¿una fila con una línea y otra fila con otra?
Vamos a verlo fijándonos en un transbordo, que no deja de ser una estación que sabemos que está en dos líneas.
View(paradas_metro[paradas_metro$name == "Puerta del Sur",])

4. Cargar precios de la vivienda por estaciones de Metro desde R
Al principio referimos otra URL que nos muestra los precios por m2 para alquilar o comprar a 500 metros de distancia de las estaciones de Metro. Nuestro objetivo ahora es cargar en otro dataFrame esos precios de las viviendas cercanas a las estaciones de metro. Lo mismo que antes, sólo que ahora nos interesa ID, NAME, SALE y RENTAL
p <- curl_escape("select ID, SALE, RENTAL from public.precio_metro_201605")
uri_precios_estaciones <- paste("https://idealista.carto.com/api/v2/sql?q=",p, sep="")
precios_estaciones <- fromJSON(uri_precios_estaciones)
precios_estaciones <- precios_estaciones[["rows"]]
Lo primero que nos damos cuenta es que en el dataframe de precios hay una observación más que en el de paradas de metro. Luego no coinciden exactamente: hay una parada de metro que está en uno y no está en el otro. Sería interesante descubrir qué parada es.

Por otro lado deberíamos tener la información de ambos dataframes, el de paradas de metro y el de precios, unificada en un único dataframe.
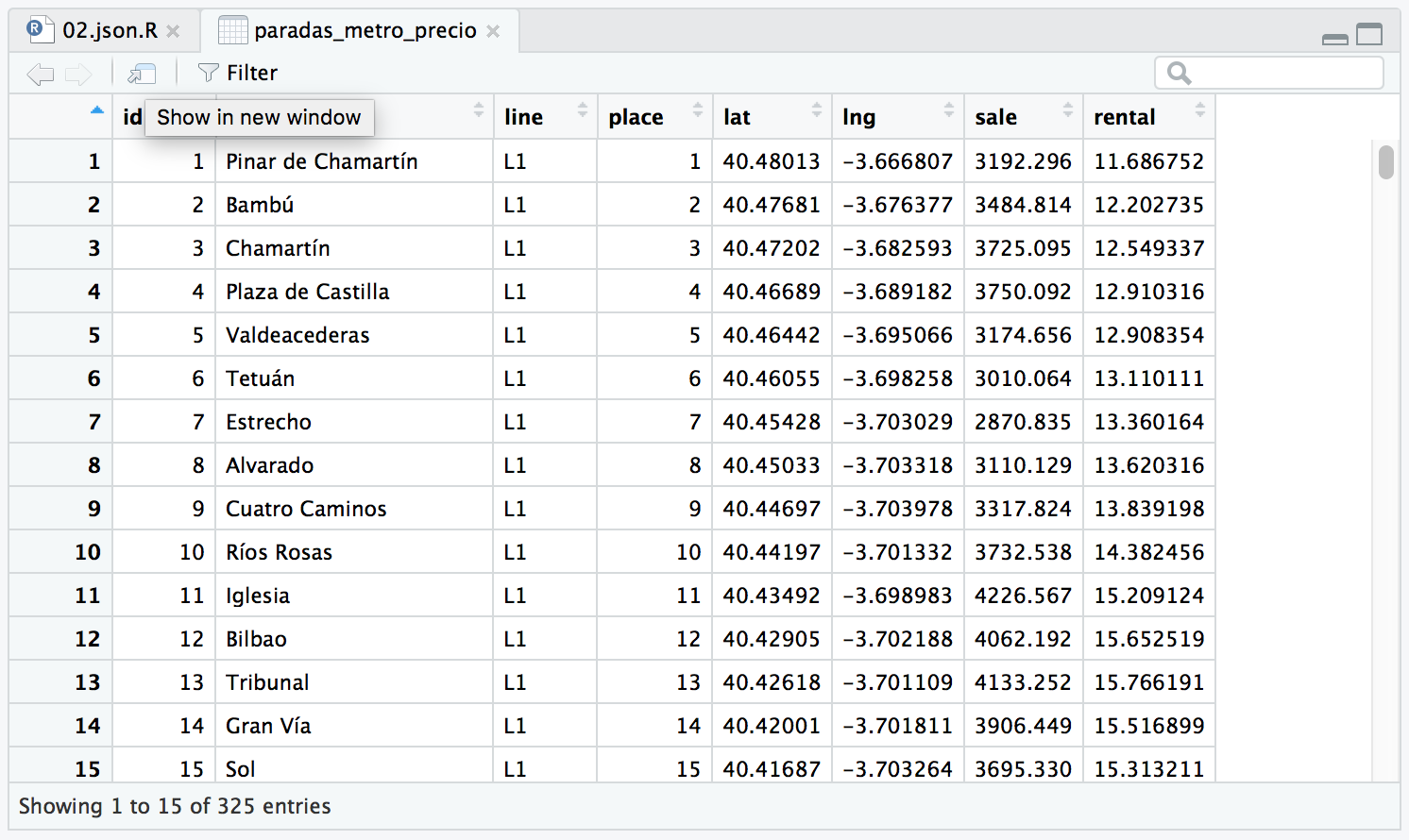
paradas_metro_precio <- merge(paradas_metro, precios_estaciones)
Esto va a mezclar ambos dataframes haciendo un matching por los campos que se llaman igual, en este caso «id». Vemos que hay 325 observaciones.
5. Dando una vuelta de tuerca a la API
He querido hacerlo así para mostrar como mezclar dos dataframes, pero lo cierto es que podíamos haber obtenido directamente esta información ya unificada desde la propia API, con un INNER JOIN entre las dos tablas.
query <- paste("select ",
"pmm.ID, pmm.NAME, pmm.LINE, pmm.PLACE, pmm.LAT, pmm.LNG, pr.SALE, pr.RENTAL ",
"from ",
"public.paradas_metro_madrid pmm ",
"inner join public.precio_metro_201605 pr ",
" on pmm.id = pr.id ",
"order by pmm.ID",
sep="")
uri <- paste("https://idealista.carto.com/api/v2/sql?q=",curl_escape(query), sep="")
precios <- fromJSON(uri)
precios <- precios[["rows"]]
Y si usamos la función identical() del paquete base que nos compara dos dataframes veremos que
identical(paradas_metro_precio,precios)
por la consola nos devuelve TRUE
Voy a categorizar el dataframe por lineas, así que las convierto a factores. Y como es posible que use este objeto más adelante, lo guardo a un fichero.
precios$line <- as.factor(precios$line) saveRDS(precios, file = "precios.rds")
6. Decidiendo dónde invertir
La motivación para hacer este estudio desde luego es aprender, pero supongamos por un momento que la pregunta que nos estamos haciendo es dónde invertir nuestro dinero adquiriendo una vivienda donde maximicemos su rentabilidad a la hora de alquilar.
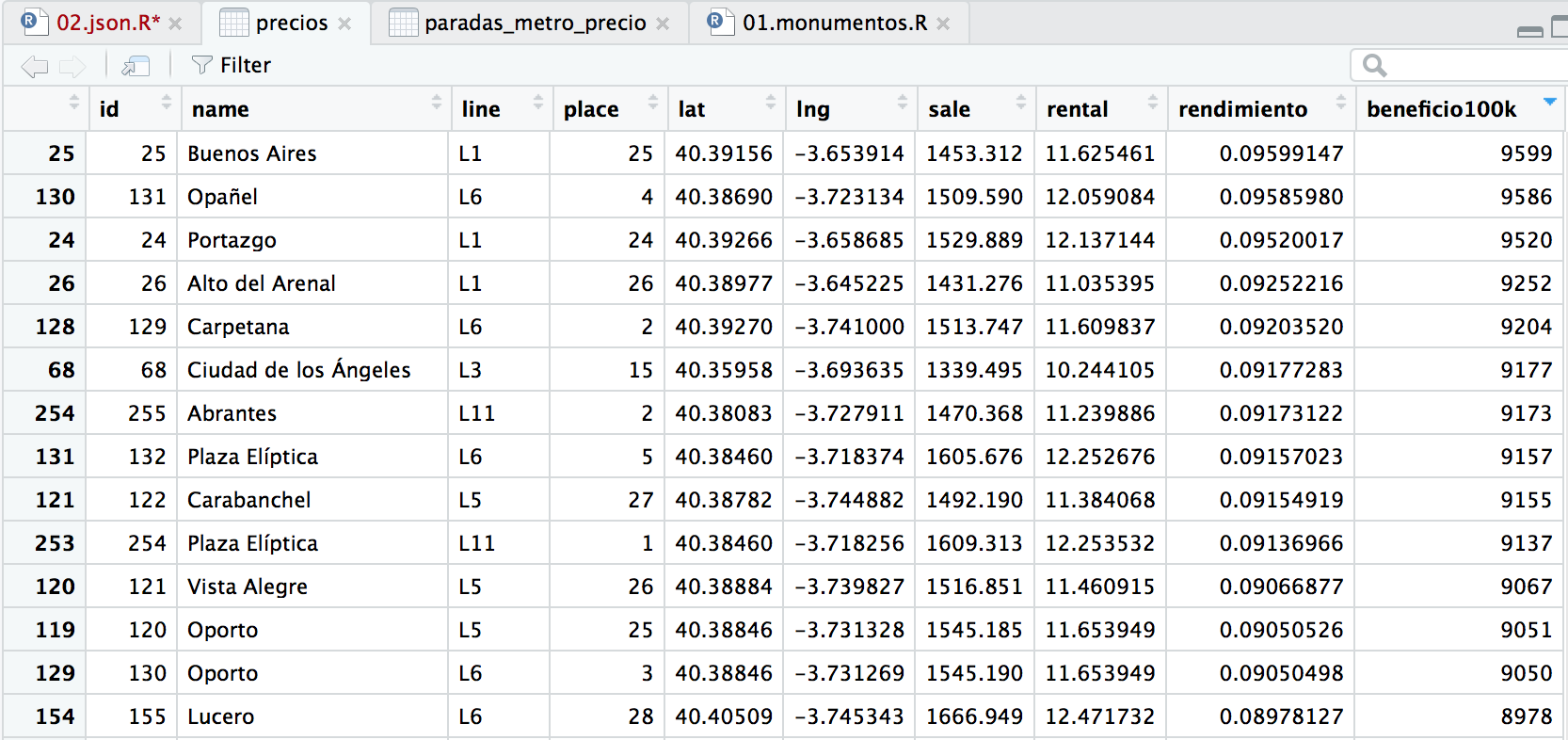
Vamos a limpiar todas las variables y nos quedamos solo con el dataframe de precios. Y nos fijamos un poco en los datos del dataframe. Vemos que en la columna SALE tenemos el precio del m2 si deseamos adquirir la vivienda. Y en RENTAL cuanto costaría el m2 en la opción del alquiler. Supongamos que tenemos un dinero ahorrado y quiséramos comprar un piso para invertir en él. En este caso querríamos un piso que nos costara lo mínimo posible pero que pudiéramos alquilarlo por lo máximo. Aunque intervienen otros valores, como los gastos fijos de un piso que tendría que pagar el propietario (IBI, seguro, comunidad de propietarios, etc…) vamos a obviarlos en aras de obtener un modelo más simple.
Se observa que hay una función de densidad entre el precio para vender y el de alquiler. Si lo queremos anualizar, para ver el rendimiento anual sería:
(12 meses * precio menusla/m2 del alquiler) / (precio/m2 de compra)
Creamos una columna con el rendimiento anualizado
precios$rendimiento <- (12 * precios$rental)/precios$sale
Creamos otra columna con los beneficios anuales brutos por cada 100.000 euros invertidos
precios$beneficio100k <- round(precios$rendimiento * 100000,0)
Con esta información ya sabríamos dónde nos cunde más el dinero para invertir.
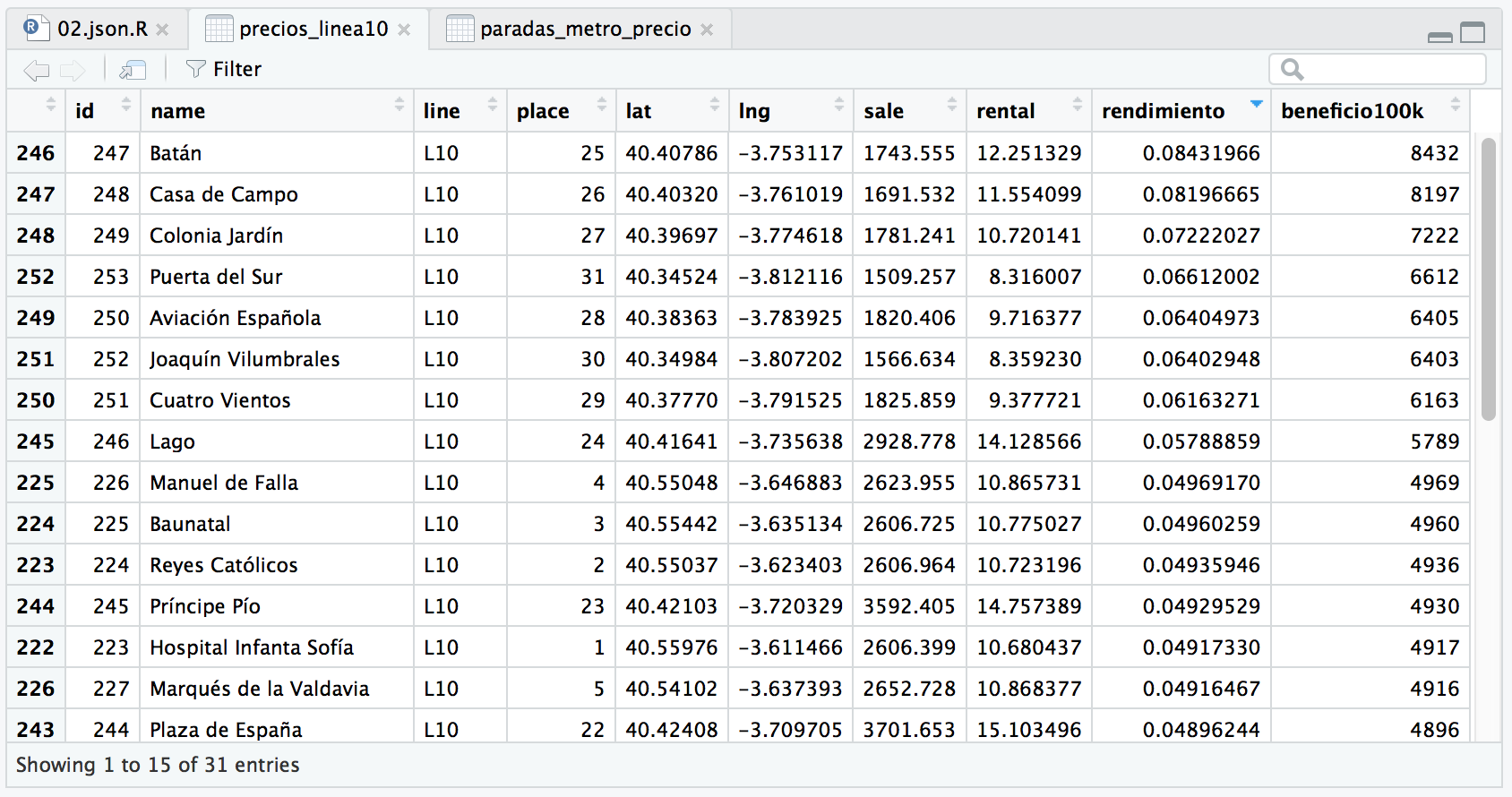
Supongamos que queremos restringir la búsqueda sólo a la línea 10 de metro, por la razón que sea.
precios_linea10 <- precios[precios$line == "L10",]
Vemos que sólo hay 31 observaciones que se corresponden con las estaciones de metro de la Línea 10.
Si ordenamos por beneficio vemos que Batán, Casa de Campo, Colonia Jardín y Puerta del Sur son los más rentables.
7. Conclusiones
En este ejercicio:
- hemos aprendido a leer un JSON con R
- hemos conocido la librería jsonlite y curl
- ahora sabemos cómo escapar caracteres para una URL
- y cómo concatenar cadenas de texto
- hemos aprendido a mezclar dos dataFrames
- y a verificar que dos dataFrames son idénticos
Por otro lado, los datos en que nos hemos basados para este ejercicio no están actualizados. Espero que nadie tome una decisión real basándose en este ejercicio.
Enlaces y Referencias
- El código fuente de este tutorial en GitHub
https://github.com/eContento/rstudio - Cómo leer un CSV con R y RStudio
- Los datasets de este ejemplo han salido del CartoDB de Idealista
- Me ha encantado Carto. Ha sido un descubrimiento y estoy deseando aprender más. https://carto.com/
- Carto es una startup española con proyección internacional Carto en Wikipedia

