

En esta entrada analizaremos algunas de las arquitecturas que se utilizan hoy en día a la hora de montar un sistema backend relativamente complejo, las diferencias y similitudes que tienen y si pueden llegar a complementarse o son excluyentes.
Índice de contenidos.
- ¿Y tú qué arquitectura utilizas?
- Arquitecturas multicapas: tiers y layers
- Onion architecture
- Puertos y adaptadores: una arquitectura hexagonal
- Clean architecture
- ¿Y qué pinta tiene todo esto?
- Conclusiones
- Referencias
¿Y tú qué arquitectura utilizas?
Lo primero que tenemos que dejar claro es qué entendemos por arquitectura. La arquitectura de un sistema software es la definición de qué componentes constituyen ese sistema, sus responsabilidades y las relaciones de uso y dependencia entre ellos. Es, por tanto, completamente independiente de la tecnología que se utilice y no debería representar en ningún momento el framework, la base de datos o la forma de interactuar con el usuario.
Arquitecturas multicapas: tiers y layers
La primera de las arquitecturas que vamos a ver es la multicapa. En inglés tenemos los conceptos de multitier y mutilayer architectures. En español la traducción para ambos es arquitectura multicapa, pero es importante conocer la diferencia entre ambos.
Una arquitectura multitier (o n-tier) hace referencia a una arquitectura en la que se expone la separación de sistema en varias capas físicas. Es decir, los distintos componentes están en máquinas separadas. En este tipo de arquitectura tenemos por ejemplo la de [cliente – servidor] o la de [presentación – negocio – datos]. Sin embargo, al referirse más a la distribución física del código ejecutable que a la relación lógica de sus componentes se aleja de lo que estamos tratando en aquí.
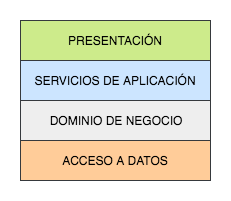
Por su parte una arquitectura multilayer (o n-layer) refleja la separación lógica en capas de un sistema software. En este contexto una capa es simplemente un conjunto de clases, paquetes o subsistemas que tienen unas responsabilidades relacionadas dentro del funcionamiento del sistema. Estas capas están organizadas de forma jerárquica unas encima de otras y las dependencias siempre van hacia abajo. Es decir, que una capa concreta dependerá solamente de las capas inferiores, pero nunca de las superiores. En backend lo más común suele ser tener [servicio – negocio – acceso a datos], aunque a veces podríamos también encontrarnos una capa superior de presentación si esta se está manejando también a nivel de backend o una capa con controladores REST.
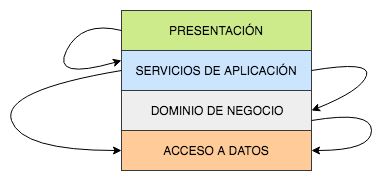
Al hablar de arquitectura multilayer podemos diferenciar además entre sistemas estrictos (strict layered systems) y relajados (relaxed layered systems) en función de las relaciones de dependencia con las capas inferiores. Un sistema estricto es aquel en el que una capa solo depende directamente de la capa inmediatamente inferior, mientras que en un sistema relajado puede hacerlo de todas las que hay por debajo aunque no sean contiguas. Más adelante veremos para qué es esto útil.
Ya simplemente como apunte, hemos visto que las dependencias siempre van de arriba a abajo pero hay ocasiones en las que, dependiendo del funcionamiento del sistema y cómo se hayan ideado las capas, es necesario que haya una comunicación de abajo a arriba. Un ejemplo es cuando la interfaz gráfica tiene que actualizarse con cambios que se producen en los datos. Mecanismos como el patrón Observer permiten a capas inferiores transmitir información por su cuenta y riesgo a otra superior pero abstrayéndose por completo de quien es el observador concreto y, de esta forma, no rompiendo las reglas de dirección de dependencia.
La principal desventaja de este planteamiento es que la última capa es la de acceso a datos. Esto implica que todas las demás capas, incluyendo una posible de interfaz de usuario, acaba dependiendo de ella bien de forma directa o de forma transitiva.
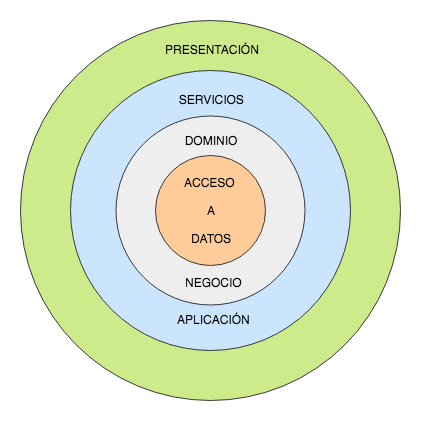
Al final lo que estamos logrando es algo como lo que se muestra en la figura de arriba, que el centro de toda nuestra aplicación sea la persistencia de datos. Es cierto que para algunos sistemas puede llegar a cuadrar o a no ser una desventaja demasiado importante como para tenerla en cuenta, pero aún así es algo a tener en cuenta.
Para sistemas más grandes puede llegar a ser un problema y por eso han surgido otras arquitecturas que intentan solucionarlo, aunque no dejan de ser una versión ligeramente distinta y con un nombre llamativo de las arquitecturas multicapas ligeramente modificadas para implementar adecuadamente el principio de inversión de dependencia (la D de SOLID). Según este principio debemos depender de las abstracciones en lugar de hacerlo de las clases concretas. En breve vemos cómo hacen esto y como al final todo sigue siendo una arquitectura multicapa bien diseñada.
Onion architecture
Teniendo lo que hemos visto arriba en mente, se empezaron a crear arquitecturas multicapa que sí seguían el principio de inversión de dependencias (DIP por sus siglas en inglés) y que, por tanto, solucionaban el problema que comentábamos. Con el tiempo Jeffrey Palermo decidió darle un nombre a este tipo de arquitecturas e intentar estandarizarla para que la gente tuviera una forma común de referirse a ella. Pero no es algo que crease él mismo desde cero. Está es la forma en la que se suele representar la arquitectura onion.
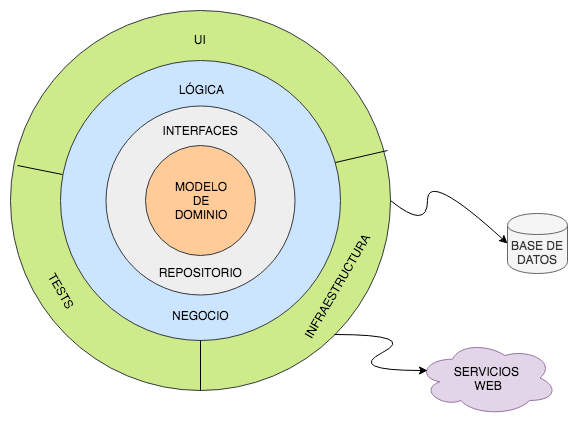
A grandes rasgos se trata de una arquitectura multicapa construida en torno a un modelo de dominio independiente de todo lo demás. Las dependencias van hacia el centro, por lo que todo depende de ese modelo de dominio. A su alrededor se organizan varias capas, estando en las más cercanas las interfaces de repositorio, es decir, las que definen el comportamiento del almacenamiento de los datos pero no lo implementan. En las capas siguientes está la lógica de negocio que usa estas interfaces y que en tiempo de ejecución tendrá las implementaciones apropiadas. Alrededor del núcleo de modelo puede haber un número variable de capas, pero siempre debe cumplirse que las interfaces estén más cerca que las clases que las utilizan. Con esto ya tenemos creado el core lógico de nuestra aplicación, que no tiene absolutamente ningún detalle de infraestructura.
Por último, en la capa más exterior es donde estarán todos los detalles de comunicación con el exterior (tanto de interfaz con el usuario como el almacenamiento) y los tests de integración. Las clases que se presentan aquí implementarán las interfaces que se definen en las capas inferiores, pudiendo cambiar por tanto las implementaciones dependientes de la tecnología sin que las capas inferiores se enteren. Lo que conseguimos de esta manera es una arquitectura que habla de cómo está montado el sistema y no de los terceros que se comunican con él.
Disclaimer: aunque la arquitectura como tal esté desligada de la forma en la que se va a comunicar con el exterior no quiere decir que la implementación lo esté también al 100%. Obviamente hay que tener en cuenta el tipo de uso que se va a dar a nuestro sistema, pues si se va exponer en una web y ser accesible por varios usuarios a la vez tendremos que poner mecanismos para evitar problemas de paralelismo mientras que no sería necesario si va a ser una aplicación de escritorio que solo usará una persona a la vez. El uso que se le va a dar a nuestro sistema (que se acceda en paralelo) sí afectará al core de la aplicación, pues es parte de la identidad del sistema. Mientras el cómo se ejerce este uso (mediante una API REST) no lo es, y es de esto de lo que nos desligamos mediante estas abstracciones.
Además también tiene otra ventaja importante a nivel de pruebas. Igual que se pueden sustituir partes de la capa externa sin problemas también pueden omitirse según necesitemos. Así la lógica de nuestra aplicación es mucho más fácil de testear si podemos quitarnos de enmedio toda esta complejidad o sustituirla por otra que sea más conveniente a la hora de probar el sistema.
Lo único que queda por ver entonces es cómo se logra esto. Para ello vamos a representar esta misma arquitectura como una multicapa relajada (aunque no pondremos todas las flechas de dependencia de ahora en adelante):
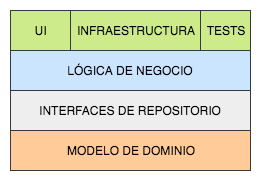
De esta forma creo que se ve claramente cómo el sistema que hemos construido ahora se ha hecho sobre el modelo de dominio, que sí es crucial para nosotros, en lugar de sobre detalles de persistencia que podríamos llegar a querer cambiar. Esto parece tener mucho más sentido y según crezca la aplicación seguirá siendo mantenible.
Sin embargo, si miramos la arquitectura que acabamos de plantear podemos observar algo que es posible que necesitemos aclarar. Según lo estamos viendo, en la capa superior tenemos los detalles de la implementación de los repositorios, cerca del dominio las interfaces y en medio de ambas las clases de lógica de la aplicación. En principio esto parecía lógico, ¿pero cómo puede usar la capa intermedia las implementaciones de la capa superior sin depender de ella? Pues con la inyección de dependencias. Este mecanismo permite seleccionar por configuración qué implementación concreta se usará en cada caso, pero se hará en tiempo de ejecución. De esta forma todo el core está abstraído de tal manera que solo está programado contra las interfaces y en ningún momento es dependiente de cómo esté funcionando por debajo la implementación elegida. Esto nos permite, además, tocar la configuración de qué se está inyectando y así elegir la implementación que queremos sin que nada por debajo cambie en lo más mínimo.
Esto es exactamente lo que comentamos en la sección anterior sobre seguir el principio de inversión de dependencias. Como vemos, en el diagrama estamos poniendo en el nivel superior siempre las implementaciones y en el inferior las interfaces y siempre estamos accediendo a las implementaciones concretas mediante las interfaces. Al final no es otra cosa que diseñar una arquitectura multicapa que sigue correctamente el DIP.
Puertos y adaptadores: una arquitectura hexagonal
Unos años antes de que Jeffrey Palermo acuñase la arquitectura onion, Alistair Cockburn (uno de los firmantes del manifiesto ágil) definió la arquitectura de Ports and Adapters o arquitectura hexagonal. Aunque se crease antes la voy a explicar después porque casi todos los conceptos importantes aplican también a onion y si lo ponía después no quedaba demasiado que decir.
El objetivo de la arquitectura hexagonal es poner, una vez más, en el centro del sistema toda la lógica propia del dominio y definir unas fronteras muy claras y unos mecanismos de transformación con el exterior. Así se consigue que el core lógico no se contamine ni dependa en ningún momento de los detalles concretos del acceso a los datos, la comunicación con terceros o la interacción del usuario. Más o menos es lo mismo que busca onion, como habréis observado.
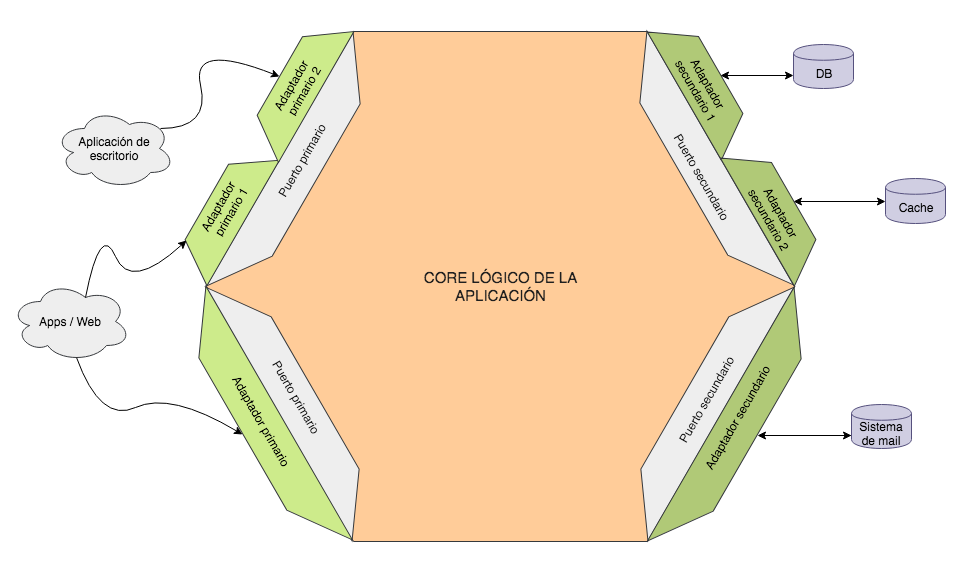
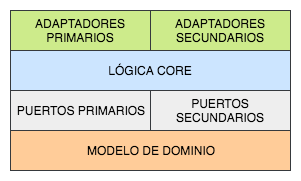
Partiendo de esta imagen está claro que nuestro sistema se compondrá de 3 partes bien diferenciadas: la lógica core de la aplicación, los puertos y los adaptadores. Cualquier comunicación con el exterior se hará única y exclusivamente a través de los puertos y adaptadores, que se encargarán de la conversión de datos para que dentro de las fronteras todo esté en nuestro idioma. Pero, ¿qué función hacen exactamente estos componentes?
Los puertos son las interfaces que definen la interacción con el exterior y exponen únicamente datos de nuestro dominio, dejando que toda la lógica de transformación esté de puertas afuera y no se contamine el interior. Y los adaptadores son precisamente la forma de conectar el exterior con los puertos, implementando la comunicación y la conversión de datos entre el dominio y lo que se necesite fuera. Los adaptadores no pertenecen al core como tal y podrían implementarse cada uno completamente por separado si quisiésemos mientras dependan del puerto que usan/implementan.
Una cosa importante a tener en cuenta (tal y como se ve en la imagen de arriba) es que un único puerto puede tener más de un adaptador asociado. Pongamos el ejemplo de un puerto de entrada que expone una funcionalidad que hace nuestro sistema. El puerto sería la interfaz de dicha funcionalidad: la entrada y salida del método expresada en objetos del dominio. Y ese servicio podría exponerse, por decir dos, como un servicio REST o con una interfaz por terminal; en cuyo caso tendríamos un puerto y dos adaptadores. Y esto también es aplicable al acceso a datos, que podría ser desde una caché, una base de datos, un servicio de un tercero o cualquier otro sistema.
Como vemos, gracias a la definición de estas fronteras nuestro core queda completamente desvinculado del exterior. Es más, se abstrae incluso de si estamos estamos haciendo un backend para una aplicación web, de escritorio o un web service que se expondrá en un bus; pues al final no dejan de ser formas de comunicarnos con el usuario y no deberían afectar a la lógica. Simplemente se añadirá un nuevo adaptador para la funcionalidad que se quiera exponer por una vía concreta y ya está. Eso sí, no olvidéis el disclaimer que puse en la arquitectura onion, pues es igualmente aplicable aquí.
Además, en la imagen habréis visto que tanto puertos como adaptadores están divididos en primarios y secundarios (también llamados driving y driven respectivamente). Los primarios definen el comportamiento que expone nuestro sistema al exterior, la comunicación con el usuario (sea este una persona, otra aplicación…). Por su parte los secundarios definen la interacción que necesita nuestro sistema con terceros (base de datos, cachés, otros sistemas) para ejecutar correctamente sus funcionalidades de principio a fin. A grandes rasgos podríamos decir que los primarios son de entrada y los secundarios son de salida en el sentido de la dirección en la que viajan las peticiones.
Y muchas veces surge una pregunta, especialmente en este caso por la terminología que se usa. ¿Cuántos puertos debemos definir? ¿Hay que limitarse a 6? La respuesta es que no. Como todo en esta vida depende del caso concreto. Los extremos están en tener un único puerto para todo el sistema o tener uno por cada funcionalidad concreta, y por lo general el término medio suele ser lo óptimo. En mi experiencia solo he usado este tipo de arquitectura una vez y teníamos prácticamente un puerto ya no solo por funcionalidad sino por fuente de datos que se usaba en cada una. Sin embargo, era un caso muy concreto en los que cada dato se obtenía de un servicio web distinto, que puede llegar a cambiar independientemente en el futuro, y de esta forma podemos modificar cualquiera de ellos rápidamente sin afectar al resto. Pero, una vez más, depende del caso. El hecho de que se llame arquitectura hexagonal se debe simplemente a que gráficamente suele representarse con un hexágono para dejar claro que puede hacer varios puertos y que son independientes los unos de los otros. Pero no es más que una ayuda visual para entenderlo mejor y no implica que 6 sea el número idóneo para nada.
Pero una vez entendida la teoría siempre queda la duda de cómo se implementa esto. Lo primero que tenemos que decir es que en la arquitectura hexagonal (al menos originalmente) no se habla de cómo debe implementarse la lógica de negocio como tal, sino que se entiende todo como solo dos capas: los adaptadores que están fuera del hexágono por una parte y los puertos y la lógica de negocio como otra. La capa superior será lo que está fuera y la capa inferior lo que está dentro del hexágono, yendo la dependencia de arriba a abajo.

Lo que sí se define es qué relación tienen los puertos y los adaptadores y quién implementa cada una de las interfaces.
- Los puertos primarios son interfaces de funcionalidad del sistema, por lo que estarán implementadas por la capa de servicios dentro del hexágono. Los adaptadores primarios usan, y no implementan, dichos puertos para comunicarse como necesiten con el interior.
- Los puertos secundarios, por su parte, sirven de interfaz de salida para que el interior se comunique con sistemas externos. En este sentido el core utilizará los puertos secundarios, que esta vez serán implementados por los adaptadores secundarios.
Si detallamos esto un poco más y lo desarrollamos para entender bien dónde debería estar nuestro modelo y dónde las interfaces para hacer posible el planteamiento de esta arquitectura nos quedaría algo como esto:
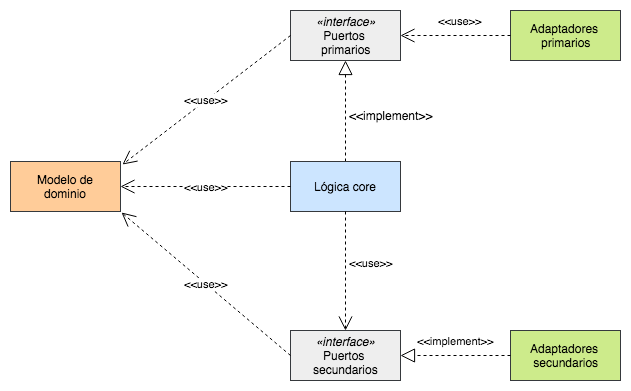
De aquí destacar que los adaptadores solo dependen de la interfaz y del dominio, pero no del resto de la aplicación. Así pues no hay nada que dependa de los adaptadores ni estos dependen de nada que no sean las interfaces. Ya hemos visto que con esto seguimos el DIP y se logra normalmente usando la inyección de dependencias. Sin embargo, lo que nos interesa es que al ponerlo en forma de una arquitectura multicapa relajada obtenemos esto:
Antes hemos dicho que la arquitectura de Ports and Adapters no especifica en ningún momento la estructura que debe tener la parte core dentro del hexágono (mientras que por ejemplo onion sí lo hace), pero lo mostrado arriba parece la manera más natural de implementar lo que se expone manteniendo las menores dependencias posibles. Así pues se ve de forma clara que lo que logramos es construir todo nuestro sistema alrededor del modelo de dominio y minimizando las dependencias con el exterior. Además en esencia es lo mismo que teníamos en la arquitectura onion pero cambiando el nombre a algunos componentes para dar más importancia a las fronteras con el exterior.
Clean architecture
Ya hemos visto que ha habido más de un tipo de arquitectura que busca exactamente lo mismo: abstraer la lógica esencial y la propia arquitectura de los detalles de comunicación con el usuario u otros sistemas. En algún momento Uncle Bob decidió crear una que las unificara todas (incluida la screaming architecture que él mismo propuso) y la llamó, en un alarde de originalidad, clean architecture.
El objetivo es el mismo que hemos estado persiguiendo hasta ahora, y la implementación es a grandes rasgos una hexagonal aunque cambiando algunos nombres y definiendo mínimamente la estructura interna. Como ya hemos visto los conceptos no me pararé a explicarla demasiado. En este caso utilizaré la imagen que él mismo tiene en su entrada de Clean Coder, que es bastante explicativa:
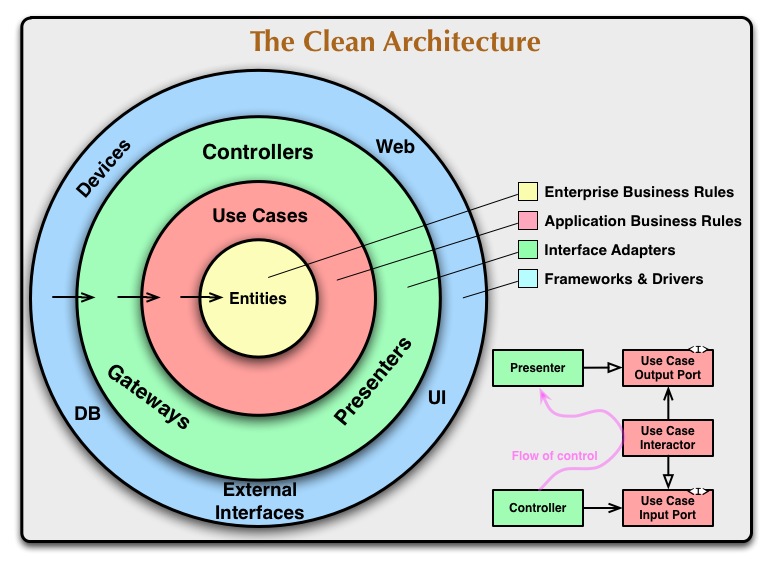
A partir de este esquema se ve que hay 4 capas, aunque internamente cada una podría dividirse en todas las que puede ser necesario. En la capa interna tenemos las entidades, que vendría a ser el modelo de negocio, las funciones básicas o lo que sea que represente la lógica del negocio (el dominio, vaya). En la capa inmediatamente superior están los casos de uso, que no es otra cosa que la lógica propia de la aplicación. Aquí también están lo que serían los puertos en una arquitectura hexagonal, que en este caso se llaman Use Case Input Port (si son primarios) y Use Case Output Port (si son secundarios), y la implementación de los de entrada está en lo que se denomina Use Case Interactor. Por encima de esto tenemos la capa de lo que serían los adaptadores: controladores, presentadores, acceso a terceros… Y por encima está una última capa que ya no forma parte del sistema backend como tal y que son los dispositivos con los que nos comunicamos, la base de datos, la interfaz de usuario que nos llama, etc.
Como vemos, nada nuevo bajo el sol. Simplemente es una arquitectura hexagonal con otros nombres y en la que se ha definido un poco más la separación interna en, al menos, dos capas. Sin embargo, aunque no se haga de manera explícita este mismo planteamiento de separar el dominio y construir sobre él emana de forma natural de Ports and Adapters si queremos implementarlo como hemos comentado arriba.
¿Y qué pinta tiene todo esto?
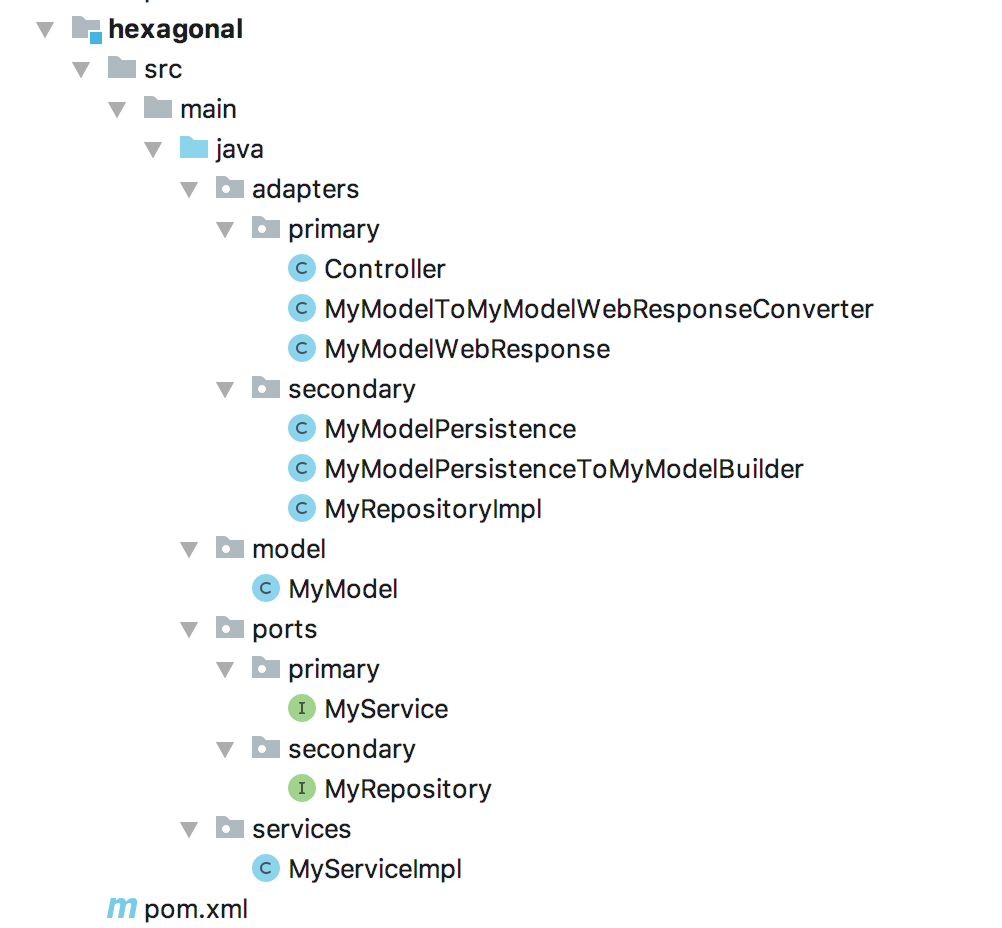
Por último quería mostraros una serie de esqueletos muy muy básicos de las arquitecturas que hemos comentado. Son proyectos Java creados con Maven, pero no deberíais tener ningún tipo de dificultad para entenderlos puestos que lo que nos interesa es la estructura.
Por supuesto en un sistema real más grande es posible que adopten otra forma y tengan más paqueterías o niveles. O que se esté siguiendo DDD (Domain Driven Development) para construirlo y sea dentro de cada dominio donde se pueda observar el tipo de arquitectura que sigue. Esto último es, al menos en mi opinión, muy recomendable y lo más difícil será aplicar DDD, pero lo que es la arquitectura será muy sencillo de aplicar.
En cualquier caso lo que quiero es afianzar lo que hemos visto arriba y que veáis que en esencia todas son iguales. El código, por si queréis echarle un vistazo y ver la relación entre cada clase/interfaz, está subido a mi repositorio.
Arquitectura multicapa sin seguir el DIP

Onion (arquitectura multicapa que sigue el DIP)

Arquitectura hexagonal
Clean architecture
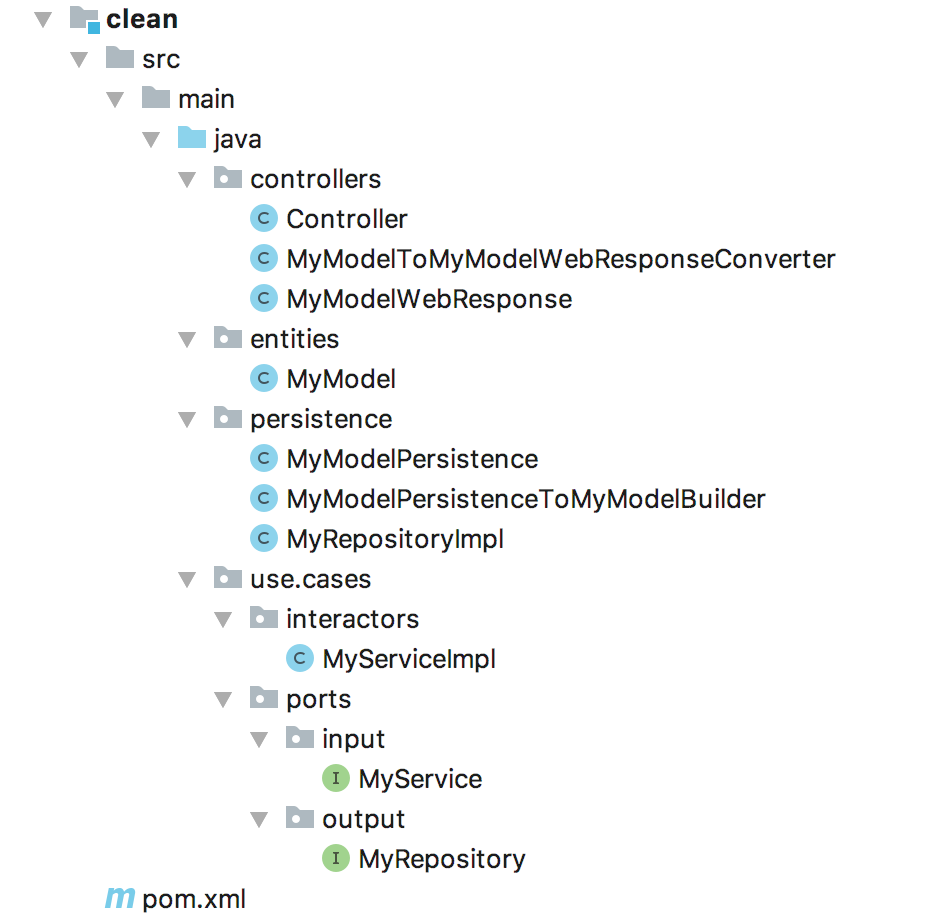
El primer ejemplo es un caso aparte porque no está siguiendo el mismo principio que las demás. Pero dejando ese aparte podéis ver que realmente no son tan distintas unas arquitecturas de otras. En las tres la conversión entre MyModel y MyModelPersistence se hace en el propio repositorio para que no afecte al resto de la aplicación. Y lo mismo ocurre en el controlador al transformar a MyModelWebResponse. Además en los tres también estamos programando contra interfaces y luego inyectando la implementación (excepto en el caso de la llamada al servicio en onion, que como no lo indica expresamente la arquitectura he preferido ceñirme a ella). Lo único que cambia realmente son los nombres de la paquetería y, ligeramente, dónde está cada uno.
Conclusiones
La entrada que hemos hecho ha sido un poco densa, pero al menos espero que se acaben entendiendo los conceptos, de qué se está hablando (o de qué se debería estar haciendo) al usar estos términos y cómo están relacionados entre ellos. Al menos mi objetivo era ese, que no pongáis caras raras cuando escuchéis estas palabrejas.
Como habréis visto, al final solo hemos hablado sobre cómo separar nuestro software por capas que el desarrollo sea más organizado, sencillo y, principalmente, mantenible. Inicialmente sin preocuparnos excesivamente de las dependencias. Esto tiene perfecto sentido para aplicaciones pequeñas que implementan un CRUD y poco más. Si al final todo lo que haces es consumir un dato, mostrarlo por pantalla y encima el sistema no tiene un volumen inmenso, ¿para qué vamos a complicarnos la vida montando algo que no nos va a aportar demasiado pero que puede ser más difícil de entender? Cada herramienta tiene su uso, y estas arquitecturas no son una excepción.
Posteriormente hemos dado varias alternativas para además construir toda la aplicación sobre nuestro dominio, lo cual tiene bastante más sentido y es conveniente si estamos en un desarrollo medianamente grande. Realmente no creo que os haya contado nada nuevo. Seguramente ya estéis usando estas arquitecturas en vuestro día a día, aunque a veces no conozcáis el nombre, porque desde hace tiempo se han empezado a convertir en un estándar. Lo que es importante, y a mi me interesa, es que entendáis el motivo de lo que estáis haciendo y las ventajas que aporta. Que no lo sigáis a pies juntillas simplemente porque alguien os lo ha dicho sin saber para qué sirve lo que hacéis. Y además que notéis que todas ellas esencialmente son lo mismo pero con distinto nombre. En cualquier caso, yo particularmente de todas ellas prefiero la arquitectura hexagonal. Creo que aporta un plus de semántica a toda esta nube de capas y ayuda a que en la arquitectura y la paquetería queden muy remarcadas las fronteras de nuestro sistema con el exterior. Y además los nombres me gustan sensiblemente más que en clean architecture, aunque para gustos colores.
Eso es todo por hoy. Y recordad que la arquitectura es cómo vuestro sistema se compone de partes más pequeñas que se relacionan entre sí y dependen unas de otras. Así que cuando alguien os pregunte cuál es la de vuestra aplicación no les mencionéis el framework, la base de datos y demás, al menos hasta la segunda frase.
Referencias
- Arquitecturas multitier
- Arquitecturas multilayer
- Presentación de Jeffrey Palermo de la arquitectura Onion [1] [2] [3] [4]
- Comparativa entre multilayer sin DPI y onion
- Explicación de la arquitectura hexagonal
- Post de Uncle Bob explicando Clean Architecture
- Comparativa entre los distintos tipos de arquitecturas
- Aplicación de varias arquitecturas y principios de diseño todos juntos (muy interesante)


Hola buenas, tengo una duda, estuve revisando esta pagina, https://www.adictosaltrabajo.com/2019/07/02/capas-cebollas-y-colmenas-arquitecturas-en-el-backend/ y mi pregunta es, se puede ocultar los componentes de la pagina web con algunos de estos modelos?
Como lo hace Facebook para ocultar la navegación en sus directorios: facebook -> inspeccionar elemento -> sources
Hola Sebastián.
La verdad es que no tengo mucha idea. Lo que me estás preguntando está más orientado a frontend que a backend, que es en lo que yo tengo más experiencia y sobre lo que trata esta entrada.
No obstante, intentaré darte una respuesta lo más correcta posible. A nivel de arquitectura como tal no estoy seguro de si pueden ocultarse los componentes que está usando tu página web. Al fin y al cabo lo que se muestra en la pestaña de sources son todos lo recursos que se descarga el navegador para poder renderizar correctamente la página. Si no apareciesen ahí no podría saber qué tiene que mostrar en pantalla, por lo que a priori me parece difícil esconderlos.
Sin embargo, si no me equivoco Facebook y algunas otras web utilizan lo que se conoce como Server Side Rendering. A grandes rasgos consiste en que sea el servidor el que construye el html que se tiene que mostrar y el explorador simplemente lo recibe y lo pinta. De esta forma no le sería necesario descargarse los componentes y en cierto modo quedarían ocultos. Creo que por aquí podrías tirar del hilo para ver si es lo que estás buscando.
Espero que te sea de ayuda.