

Índice de contenidos
1. Introducción
En este tutorial veremos qué es y cómo utilizar Google Colab, la herramienta de Google en la nube para ejecutar código Python y crear modelos de Machine Learning a través de la nube de Google y con la posibilidad de hacer uso de sus GPU . Sí, has leído bien: con sus GPU y en la nube.
La principal ventaja que ofrece esta herramienta es que libera a nuestra máquina de tener que llevar a cabo un trabajo demasiado costoso tanto en tiempo como en potencia o incluso nos permite realizar ese trabajo si nuestra máquina no cuenta con recursos suficientemente potentes. Y todo de forma gratuita.
Otro de los beneficios que tiene lo indica el propio nombre, «Colaboratory», es decir, colaborativo, nos permite realizar tareas en la nube y compartir nuestros cuadernos si necesitamos trabajar en equipo.
2. Entorno
Este tutorial se ha escrito usando el siguiente entorno:
- Hardware: Portátil MacBook Pro de 15′ (2,2 GHz Intel Core i7, 16GB DDR3).
- Sistema Operativo: macOS Mojave 10.14.2
- Software: Google Colab
3. ¿Qué es Google Colab?
«Google Colaboratory es un entorno gratuito de Jupyter Notebook que no requiere configuración y que se ejecuta completamente en la nube».
Esa es la definición «oficial», pero me gustaría ahondar un poco más para todo el que no esté familizarizado con Jupyter o Python.
Python permite su utilización para diversos paradigmas de programación, como programación orientada a objetos o programación funcional, pero quizá las características más importantes en este contexto sean que también se usa como lenguaje de scripting y que es un lenguaje interpretado.
Python trae consigo un «modo interactivo» que con un intérprete de línea de comandos permite lanzar sentencias y obtener los resultados, pero sus funcionalidades se quedaron cortas para los desarrolladores, por lo que surgió IPython, que más tarde evolucionaría en Jupyter.
Jupyter (sobre el que Gwydion hizo un tutorial de introducción) es un entorno interactivo que permite desarrollar código Python de manera dinámica. Jupyter se ejecuta en local como una aplicación cliente-servidor y posibilita tanto la ejecución de código como la escritura de texto, favoreciendo así la «interactividad» del entorno y que se pueda entender el código como la lectura de un documento.
En el siguiente apartado explicaré los componentes básicos, que son los mismos tanto para Jupyter como para Colab.
4. Funcionamiento y componentes básicos
Como ya he comentado, Colab es gratuito y forma parte de la suite de aplicaciones de Google en la nube. Por ello, para utilizarlo basta con acceder a nuestra cuenta de Google y, o bien entrar directamente al enlace de Google Colab o ir a nuestro Google Drive, pulsar el botón de «Nuevo» y desplegar el menú de «Más» para seleccionar «Colaboratory», lo que creará un nuevo cuaderno (notebook).
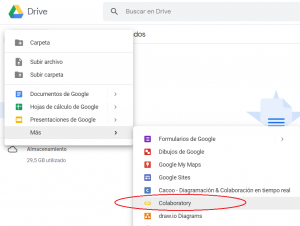
Ahora bien, ¿qué es un cuaderno? Un cuaderno es un documento que contiene código ejecutable (por ejemplo, Python) y también elementos de texto enriquecido (links, figuras, etc.). Es nuestro «entorno de trabajo» en Colab y tiene la siguiente pinta nada más crearlo:
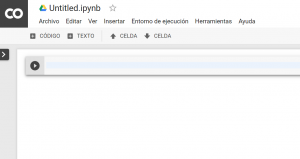
En la parte superior se encuentra el nombre del cuaderno (pudiendo cambiarlo) y su formato .ipynb, que viene de IPython Notebook y es un formato que nos permite ejecutar cuadernos tanto en IPython, como en Jupyter y Colab. El fichero .ipynb contiene en formato JSON cada celda y su contenido.
Un cuaderno está compuesto por celdas. Una celda es la unidad mínima de ejecución dentro de un cuaderno, es decir, es donde incluimos nuestro código y lo ejecutamos. Para ejecutar una celda podemos pulsar el botón con el icono de Play que se encuentra a la izquierda o pulsando Ctrl+Enter (ejecutar celda) o Shift+Enter (ejecutar celda y saltar a la siguiente). Tras la ejecución, debajo de la celda encontramos el resultado (si lo tiene).
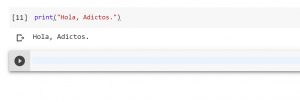
En la parte izquierda de una celda ejecutada se puede observar un número entre corchetes. Este número indica el orden en el que se ha ejecutado cada celda. En la imagen, por ejemplo, se puede ver un 11 porque he ejecutado 11 veces la misma celda. Si tuviésemos dos celdas y ejecutásemos la primera y después la segunda, en la primera aparecería un 1 y en la segunda un 2. Si pasamos el cursor por esta parte izquierda de la celda también podemos ver información sobre quién ejecutó la celda, en qué momento y cuánto tardó la ejecución.
Podemos cambiar el orden de las celdas con las flechas de la parte superior, hacia arriba (también con el atajo Ctrl+M K) o hacia abajo (Ctrl+M J), o modificarlas con el menú desplegable de la parte derecha de cada celda, borrándolas (Ctrl+M D) o añadiendo comentarios y enlaces.
Desde los botones de la parte superior o en el menú «Insertar» podemos añadir nuevas celdas, tanto específicas para código como para texto. La distinción que hace Colab sobre ellas es que las celdas de código son ejecutables, mientras que las de texto muestran directamente el texto que incluyamos y además incluyen un pequeño editor de texto.
4.1. El entorno de ejecución
Cada celda es independiente, pero todas las celdas en un cuaderno utilizan el mismo kernel. El kernel es el motor de computación que está por debajo y que se encarga de ejecutar nuestro código y devolver el resultado para mostrarlo en la celda. El estado del kernel persiste durante el tiempo, con lo que, aunque cada celda sea independiente, las variables declaradas en una celda se pueden utilizar en las demás celdas.
Normalmente, el flujo de ejecución de las celdas será de abajo hacia arriba, el orden natural en el que están creadas, pero es posible que en algún momento queramos ejecutar o cambiar algo en una celda anterior. Por ello es útil el número que aparece a la izquierda que, como hemos comentado antes, indica el orden de ejecución.
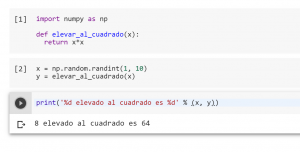
En este cuaderno, primero importo la librería numpy y luego declaro una función para elevar números al cuadrado. En celdas siguientes, utilizo esa función y la librería para elevar al cuadrado números aleatorios.
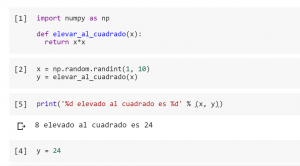
Ahora se puede ver como, en la siguiente celda cambio el valor de «y» y vuelvo a ejecutar la celda que imprime, por lo que la frase que se imprime no tiene sentido pero gracias a los números de orden puedo ver qué ha ocurrido.
Todo esto facilita mucho el separar nuestro código en bloques lógicos sin la necesidad de volver a importar librerías, o recrear variables o funciones.
Desde el menú de «Entorno de ejecución» se puede reiniciar el estado del entorno de ejecución (Ctrl+M .) para liberar toda la memoria que hayamos utilizado (ojo, perdiendo variables y demás), interrumpir cualquier ejecución lanzada (Ctrl+M I), y lanzar ejecuciones sobre las celdas: Ctrl+F9 para ejecutar todo el cuaderno, Ctrl+F8 para ejecutar las celdas anteriores, Ctrl+Shift+Enter para ejecutar las celdas seleccionadas o Ctrl+F10 para ejecutar la siguiente celda.
Cuando creamos un nuevo cuaderno, este es «estático», es decir, vemos su contenido, pero no estamos conectados a ningún entorno de ejecución. Nuestro cuaderno se conecta a una VM de Google Compute Engine (la infraestructura de máquinas virtuales de Google en la nube) cuando ejecutamos una celda o pulsamos sobre el botón de «Conectar». Al hacerlo, el cuaderno toma un momento en conectarse y después muestra, de ahí en adelante, el espacio de RAM y disco que estamos consumiendo. La máquina en un inicio cuenta con 12 GB de RAM y 50 GB de almancenamiento en disco disponibles para el uso.

La duración de la máquina virtual a la que nos conectamos, es decir, el tiempo máximo que podemos estar conectados a una misma máquina desde un cuaderno es de 12 horas. Aquí hay que tener cuidado, sobre todo si estamos llevando a cabo ejecuciones que toman mucho tiempo: si pasamos más de 90 minutos sin utilizar un cuaderno, el entorno se desconecta. Para que no se desconecte basta con dejar la ventana del navegador abierta o celdas ejecutándose. La ventaja que tiene para estos casos es que, si dejamos una celda ejecutándose y cerramos el navegador, la ejecución continuará y si posteriormente abrimos el navegador tendremos nuestro resultado.
4.2. Cómo utilizar un entorno con GPU o cambiar la versión de Python
Por defecto, el entorno al que se conecta Colab utiliza un kernel con Python 3 y no permite la ejecución con GPU. En un inicio, Colab utilizaba Python 2, pero ahora permite crear nuevos cuadernos tanto en Python 3 como en Python 2, desde el menú de «Archivo».
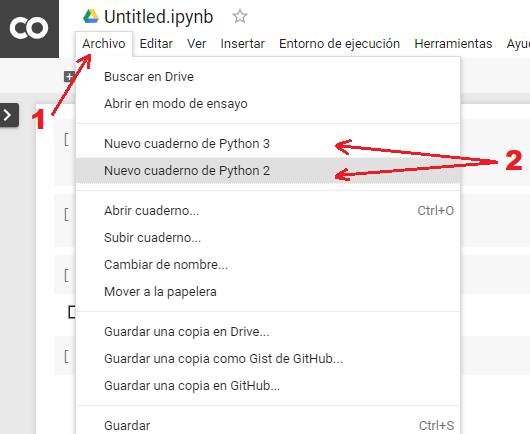
De esta forma, crearíamos un cuaderno utilizando la versión de Python que deseemos. No obstante, podría ocurrir que querramos cambiar la versión de Python una vez creado el cuaderno o utilizar la GPU en lugar de la CPU (que es la que se usa por defecto) para realizar ejecuciones más ponentes, como la creación de modelos de aprendizaje profundo. Colab nos permite cambiar los ajustes del entorno para utilizar una GPU de forma gratuita. Para ello, vamos al desplegable de «Entorno de ejecución» y seleccionamos «Cambiar tipo de entorno de ejecución».
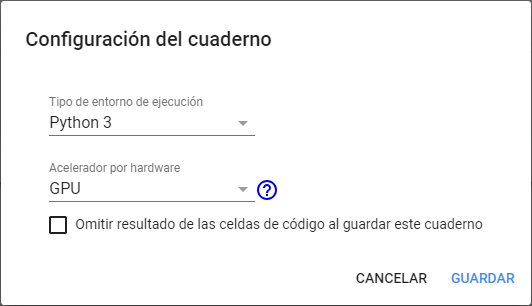
Aquí podemos cambiar la versión entre Python 3 o Python 2 y, lo más importante, cambiar el «Acelerador por hardware» de «None» a «GPU». La otra opción es «TPU», que son unidades de procesamiento de tensores, específicas de Google para ejecutar modelos de machine learning.
Cuando pulsamos «Guardar», Colab guarda nuestros ajustes y cambia de entorno de ejecución para darnos una máquina con esos ajustes. Es posible que por temas de limitación de recursos no nos podamos conectar a una máquina con GPU. Esto puede ocurrir si hay demasiados usuarios al mismo tiempo y, además, Google limita el uso que podemos hacer de estas GPU para evitar que, por ejemplo, se minen criptomonedas. Por esto, puede pasar que si estamos realizando una ejecución muy prolongada y muy potente, el entorno se desconecte.
Si, por alguno de estos u otros motivos, no podemos conectarnos a un entorno, Colab nos dará un aviso diciendo que no hay entornos con GPU disponibles.
Para comprobar si estamos conectados al entorno de GPU, podemos chequear que el botón de «Conectar» en la parte superior tenga un tick verde y podemos ejecutar el siguiente código:
import tensorflow as tf
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU no encontrada')
print('Encontrada GPU: {}'.format(device_name))Si el resultado es un error, no estamos conectados a una GPU. Si estamos conectados, la respuesta debería ser «Encontrada GPU: /device:GPU:0».
Puede darse la situación que se ha comentado de que no podamos conectarnos a un entorno con GPU, que la ejecución que queramos hacer sea más pesada de lo que permite Google y nos esté tirando la conexión al entorno, o que queramos utilizar una versión distinta a las que vienen de Python 3 o Python 2.
Colab nos permite conectarnos a un servidor de Jupyter que tengamos configurado en local si vamos al botón de «Conectar» y «Conectar a un entorno de ejecución local». Esto permite acceder a nuestro sistema de archivos local, con las versiones que queramos y tengamos instaladas en local. La desventaja es que el hardware que estaríamos utilizando es el de nuestra máquina local y perderíamos la capacidad de ejecutar el código sobre una GPU de Google y perderiámos también el uso compartido del cuaderno, pues si un usuario se conecta a local con un cuaderno, el resto de usuarios se conectarían a un entorno en la nube.
5. Funciones útiles
5.1. Las celdas de texto
Cuando entramos en la página de inicio de Google Colab, , lo que nos encontramos es un cuaderno a modo de guía introductoria. En este cuaderno se pueden encontrar algunas directrices y enlaces de interés, pero ahora nos va a servir para ilustrar un poco el tema de las celdas de texto enriquecido.
Si echamos un vistazo a las dos primeras celdas, nos encontramos lo siguiente:
Lo único que se ve en estas celdas es puro texto y un vídeo incrustado. Fijándonos, la primera celda es una celda de texto, mientras que la segunda es una celda de código (ejecutable). Hacemos doble clic en ambas para ver su contenido:
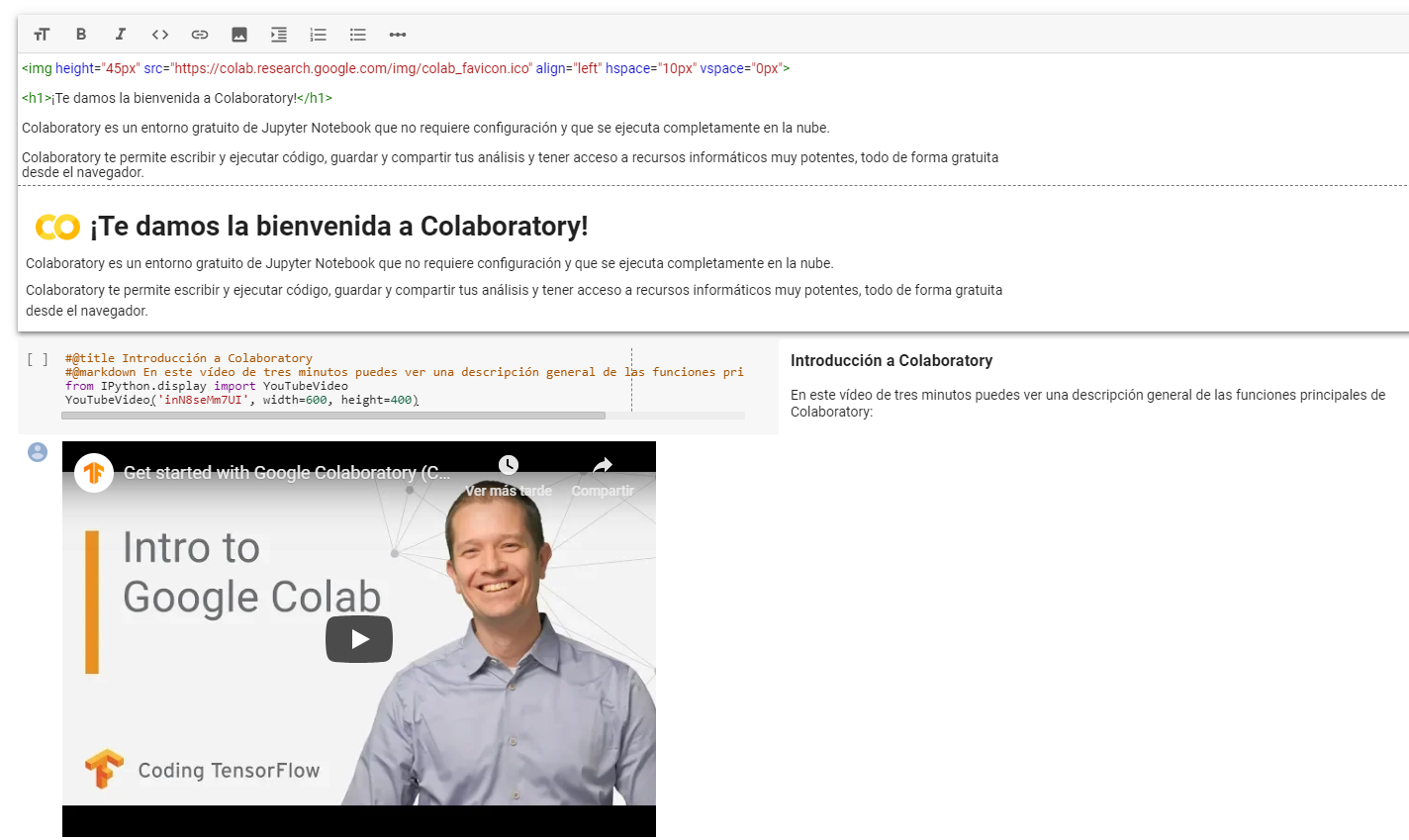
Viendo la primera, el contenido está escrito en HTML, el icono de Colab está incrustado mediante la etiqueta img y el encabezado con la etiqueta h1. Esto no es porque en Colab el texto se escriba en HTML para que lo interprete y lo pinte correctamente en la celda. Colab utiliza Markdown como lenguaje de marcado para las celdas de texto, solo que este lenguaje es un superset de HTML, así que es capaz de interpretar sus etiquetas. Aquí podeís encontrar un cuaderno de Colab con una guía de referencia sobre Markdown.
La celda siguiente es más curiosa, porque incluye texto pero es una celda ejecutable. Esto lo hace gracias a las etiquetas @title y @markdown, que, respectivamente, le da un título a la celda en formato Markdown y permite incluir texto en Markdown. Además, vemos que utiliza YoutubeVideo de la librería de IPython display para incrustar un vídeo de Youtube. Las celdas también admiten formato LaTeX.
Hemos visto así como se puede hacer de los cuadernos no sólo un script ejecutable sino también una conjunción de texto y código que permita acompañar a los bloques de código con fórmulas, guías, tutoriales o comentarios.
5.2. El menú lateral
En la parte lateral izquierda encontramos un menú bastante útil que tiene tres pestañas: Índice, Fragmentos de código y Archivos.
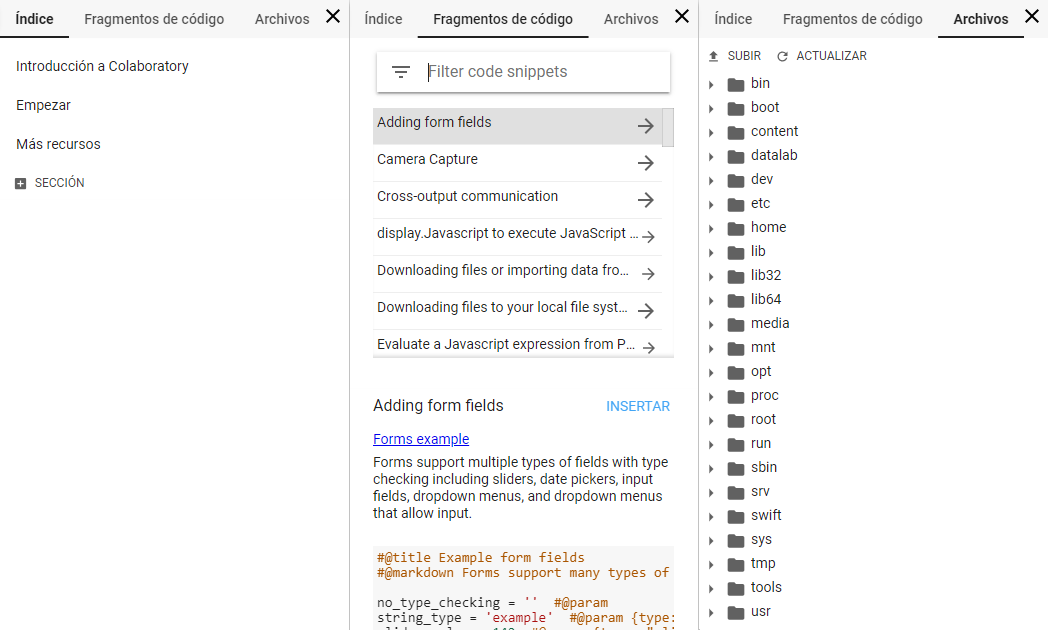
La primera pestaña, de Índice, sirve como tal para los cuadernos que tengan capítulos y secciones, dado que, como hemos comentado antes, las celdas de texto permiten convertir nuestro cuaderno en una especie de documento legible.
La pestaña de Fragmentos de código es muy útil, porque contiene muchos ejemplos de código que nos pueden servir para trabajar con Colab (por ejemplo, cómo capturar contenido de una webcam y tratarlo en tiempo de ejecución). Además, permite tanto ver el código en un cuaderno separado como insertar los fragmentos en nuestro propio cuaderno.
Y por último, la pestaña de Archivos, que tiene la función de permitirnos acceder al sistema de archivos de la máquina que estamos usando.
5.3. Ejecutando comandos bash
¿Y si vamos a utilizar nuestro entorno de ejecución en la nube, con nuestra GPU gratuita, y resulta que nos falta alguna librería? ¿Y si el proyecto que vamos a tocar está alojado en un remoto de un sistema de control de versiones? Ningún problema, porque Colab nos permite ejecutar comandos bash en nuestro entorno de ejecución como si estuviésemos lanzando comandos desde la consola de la máquina.
Para ello, basta con añadir el signo de exclamación «!» delante del comando que queramos ejecutar y Colab entenderá que queremos ejecutar un comando. Así, si queremos traernos nuestro proyecto al entorno podríamos clonarlo haciendo
!git cloneSi necesitasemos alguna librería (lo cual es raro que ocurra porque Colab viene con las librerías comunes ya instaladas), podemos ejecutar el mítico gestor de paquetes de Python con
!pip installEsta función es muy interesante porque nos permite manipular hasta cierto punto el entorno en la nube para que se ajuste a nuestras necesidades. Siempre hay que tener en cuenta que todo lo que instalemos en nuestra máquina es volátil y que si nos conectamos a otro entorno posteriormente tenemos que instalarlo de nuevo.
5.4. Importación y exportación
Otra función bastante obvia pero útil es la importación y exportación de cuadernos.
Al abrir Colab aparece un diálogo con múltiples opciones para abrir un cuaderno. Este mismo diálogo aparece si vamos al menú «Archivo» y pulsamos «Abrir cuaderno…» (Ctrl+O).
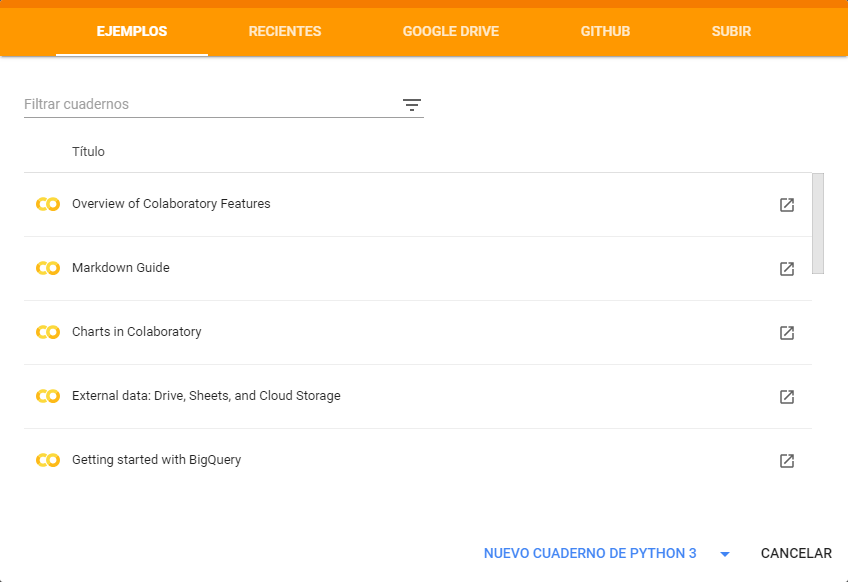
En este diálogo tenemos la opción de abrir un cuaderno de entre los ejemplos que pone Google a nuestra disposición, abrir un cuaderno reciente, abrir un cuaderno que tengamos almacenado en Drive, y las dos más útiles: importar un cuaderno desde un repositorio de GitHub o subir un cuaderno que tenemos en local (de IPython o Jupyter).
Por el otro lado, nos da bastantes opciones para exportar/guardar nuestros cuadernos.
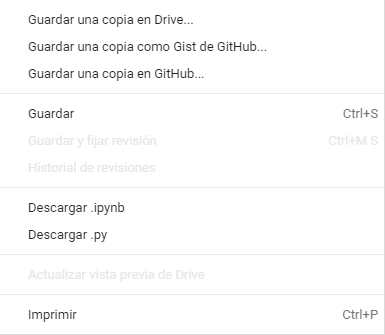
Así, desde el menú «Archivo» tenemos estas opciones, que nos permiten guardar el cuaderno en Drive, GitHub, como gist de GitHub e incluso descargar el .ipynb o el .py si queremos tener directamente un fichero ejecutable de Python.
6. Cómo subir y utilizar archivos locales o externos
Una de las cosas que más me chocó cuando me puse a usar Colab es que no encontraba una manera directa o «a simple vista» para subir archivos que necesitemos para nuestros cuadernos. Por suerte, existen varias maneras de hacerlo así que quiero exponerlas aquí.
6.1. Desde local
Para subir un archivo desde local basta con ejecutar el siguiente fragmento de código:
from google.colab import files
files.upload() Al ejecutarlo, aparecerá el típico botón de subida de archivos que abrirá una ventana para seleccionar los archivos que queramos subir de nuestro sistema. También tenemos la opción de ir al menú lateral y en la pestaña de «Archivos» pulsar el botón de «Subir».
El directorio raíz de Colab es /content. Por tanto, es el directorio que aparece abierto cuando abrimos la pestaña de «Archivos» y es el directorio donde se guardan todos los ficheros que subamos. Por ejemplo, si subiéramos un archivo llamado ejemplo.csv, el path para acceder a este sería /content/ejemplo.csv.
De la misma forma que subimos archivos, podemos descargarlos de la máquina remota con
files.download(), por lo que podríamos descargar el fichero que hemos subido ejecutando
files.download("ejemplo.csv")6.2. Desde Google Drive
Esta opción nos permite utilizar archivos que tengamos almacenados en Google Drive. Existen varias opciones, cómo utilizar la API REST de Drive o la librería de Python PyDrive, pero sin duda la que más nos facilita la vida es montar nuestro Google Drive localmente en la máquina.
La ventaja de usar esta opción no es únicamente que podemos tener nuestros archivos alojados en Google Drive y acceder fácilmente a ellos. Cuando trabajamos con machine learning o ciencia de datos, en la mayoría de ocasiones contamos con archivos enormes de datos. Si cada vez que nos conectamos a un entorno distinto tenemos que subir estos archivos, perdemos demasiado tiempo. Por ello, si tenemos estos archivos alojados en Drive y montamos Drive en la máquina, podemos acceder a ellos como si estuvieran en local.
Para montar nuestro Drive en la máquina lanzamos el siguiente código:
from google.colab import drive
drive.mount('/content/drive') Esto nos abre una URL que nos pide un código para autorizar a Colab a utilizar nuestro Drive y lo tenemos que pegar en el input que aparece.
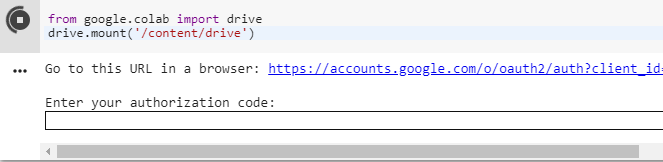
Una vez el proceso termina, nuestro Drive se ha montado dónde le hemos indicado (/content/drive) y podemos acceder tranquilamente a nuestros archivos.
7. Conclusiones
Hemos visto qué es Colab, cómo funciona y algunas de sus funciones más útiles, lo que nos da la oportunidad de poder trabajar con Python en la nube y llevar a cabo tareas de machine learning, análisis de datos y demás de forma colaborativa, pudiendo compartir nuestro trabajo y aprovechando la potencia que nos da Google.
Ahora ya podéis lanzaros a probar con vuestros notebooks en la nube.
Cualquier pregunta o sugerencia, no dudes en dejar un comentario.


Interesante artículo, Oscar. Muchas gracias
Magnífico resumen. Muchas gracias, me ha resuelto algunas dudas dudas básicas.
Que crack, muchas gracias
Tengo una pregunta: porque no puedo acceder a Google Colab desde Google Drive? He visto tutoriales en YouTube que muestran como se consigue, pero la verdad es que a mí no me aparece esa opción, que puedo hacer?
Buenas Tardes Uso Colab con sheets compartidos en drive, pero cada que le doy ejecutar al programa que realice o algun otro usuario del drive siempre pide atorizacion para ingresar al drive y al sheet.
Esto se vuelve tedioso y demorado para ejecutar el programa, me puede ayudar para que no me siga pidiendo autorizacion, ni credenciales.
Muchas Gracias
[…] De la Fuente, O. M. (2019, 6 4). Tutoriales Google Colab: Python y Machine Learning en la nube. Visitado el 7 21, 2021, en https://www.adictosaltrabajo.com/2019/06/04/google-colab-python-y-machine-learning-en-la-nube […]
Conhecendo Colab hoje. E noto já as atualizações e até mesmo de layout.
Fiz o processo e deu GPU não encontrada, mas ao longo do curso entenderei melhor.
Assim como import drive, abriu mas no final trouxe o erro: Error: credential propagation was unsuccessful
Seguindo e avançando para complementar informações.
Obrigada