

Índice de contenidos
- 1. Introducción
- 2. Entorno
- 3. Multiples buckets
- 4. Mapeo de fechas
- 5. Implementación de repositorios personalizados
- 6. Auditoría
- 7. Conclusiones
- 8. Referencias
Introducción
En el tutorial Spring Data Couchbase se creó una aplicación de ejemplo con mapeo de entidad, consultas y caso de creación para empezar a jugar un poco con el soporte que da Spring Data sobre Couchbase. Ahora vamos a profundizar un poco más sobre las posibilidades que nos ofrece el framework para esta base de datos noSQL.
Para seguir los ejemplos de este tutorial se da por hecho que se tiene ya instalado el servidor de Couchbase con el bucket travel-sample y todos los cambios que se le añadieron en el tutorial anterior.
El código de este tutorial se encuentra en el mismo repositorio, pero en la rama more_couchbase:
git clone https://github.com/diyipol/couch_base_example.git
git checkout more_couchbaseEntorno
Este tutorial está escrito usando el siguiente entorno:
- Hardware: MacBook Pro Retina 15’ (2,5 GHz Intel Core i7, 16GB DDR3)
- Sistema operativo: macOS Mojave 10.14.2
- Versiones del software:
- Docker: 18.09.0
- Couchbase Server: 5.0.1
- Java: 8
- Spring Boot: 2.1.1.RELEASE
Multiples buckets
Lo primero que vamos a hacer es añadir otro bucket al servidor de Couchbase. Para ello vamos a «Settings» y en la pestaña «Sample Buckets» instalamos «beer-sample». A continuación en «Security» creamos un usuario «beer-sample» con permisos sobre el bucket.
En el proyecto vamos a modelar la entidad Beer.
@Document
public class Beer {
@Id
private String id;
@Field
private BigDecimal abv;
@Field
private String brewery_id;
@Field
private String category;
...
@Field
private LocalDateTime updated;
...
}Al igual que en el ejemplo de los aeropuertos, añadimos en base de datos el campo «_class» para que Spring discrimine los registros de la entidad e indexamos.
UPDATE `beer-sample` SET _class = 'com.autentia.democouchbase.beers.entity.Beer'
where type = 'beer';
CREATE INDEX beer_class_idx ON `beer-sample`(_class);Tras crear el repositorio BeerRepository, extendiendo a la interfaz PagingAndSortingRepository, podemos pasar a configurar la referencia al nuevo bucket en la clase de configuración CouchbaseConfig.
@Bean
public Bucket beerSampleBucket() throws Exception {
return couchbaseCluster().openBucket("beer-sample", "beer-sample1234");
}Luego creamos el CouchbaseTemplate que usará el nuevo bucket.
@Bean
public CouchbaseTemplate beerSampleTemplate() throws Exception {
CouchbaseTemplate template = new CouchbaseTemplate(couchbaseClusterInfo(), beerSampleBucket(), mappingCouchbaseConverter(), translationService());
template.setDefaultConsistency(getDefaultConsistency());
return template;
}Por último ya podemos mapear el repositorio creado de forma que la entidad Beer use la template beerSampleTemplate con el bucket creado, mientras que las demás entidades seguirán usando la template por defecto couchbaseTemplate.
@Override
public void configureRepositoryOperationsMapping(RepositoryOperationsMapping baseMapping) {
try {
baseMapping.mapEntity(Beer.class, beerSampleTemplate());
} catch (Exception e) {
throw new RuntimeException(e);
}
}Mapeo de fechas
El ejemplo anterior todavía no va a funcionar tal cual lo tenemos, ya que Spring Data Couchbase no va a saber convertir de String a fecha. Por defecto si sabrá convertir los Date, Calendar y JodaTime (si se encuentra en el classpath) a un timestamp. También es capaz de convertir desde Date a String y viceversa en formato ISO-8601 estableciendo en application.properties:
org.springframework.data.couchbase.useISOStringConverterForDate=trueEn nuestro caso, para mapear un LocalDateTime de Java, vamos a tener que configurar nuestros propios conversores. Por lo que creamos dos conversores, uno de String a LocalDateTime y viceversa:
@WritingConverter
public class LocalDateTimeToStringConverter implements Converter {
private final static DateTimeFormatter FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
@Override
public String convert(LocalDateTime source) {
return source.format(FORMATTER);
}
}
@ReadingConverter
public class StringToLocalDateTimeConverter implements Converter {
private final static DateTimeFormatter FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
@Override
public LocalDateTime convert(String source) {
return LocalDateTime.parse(source, FORMATTER);
}
}Para hacer los conversores sin ambigüedades se utilizan las anotaciones @WritingConverter y @ReadingConverter. En el caso del BigDecimal también necesitaremos un conversor. Al leer los datos no habrá problemas, pero si hiciéramos el caso de creación veríamos que si fallaría.
@WritingConverter
public class BigDecimalToStringConverter implements Converter {
@Override
public String convert(BigDecimal source) {
return source.toString();
}
}
@ReadingConverter
public class StringToBigDecimalConverter implements Converter {
@Override
public BigDecimal convert(String source) {
return new BigDecimal(source);
}
}Finalmente registramos los conversores en CouchbaseConfig sobrescribiendo el método customConversions():
@Bean
public LocalDateTimeToStringConverter localDateTimeToStringConverter() {
return new LocalDateTimeToStringConverter();
}
@Bean
public StringToLocalDateTimeConverter stringToLocalDateTimeConverter() {
return new StringToLocalDateTimeConverter();
}
@Bean
public BigDecimalToStringConverter bigDecimalToStringConverter() {
return new BigDecimalToStringConverter();
}
@Bean
public StringToBigDecimalConverter stringToBigDecimalConverter() {
return new StringToBigDecimalConverter();
}
@Override
public CustomConversions customConversions() {
List conversions = Arrays.asList(stringToLocalDateTimeConverter(), localDateTimeToStringConverter(), stringToBigDecimalConverter(), bigDecimalToStringConverter());
return new CouchbaseCustomConversions(conversions);
}Ahora sí podemos hacer el servicio y el controlador para mostrar las cervezas 🍻😋.
@Service
public class BeerService {
private final BeerRepository beerRepository;
public BeerService(BeerRepository beerRepository) {
this.beerRepository = beerRepository;
}
public List list(int pageNumber, int pageSize) {
PageRequest pageRequest = PageRequest.of(pageNumber, pageSize);
Page beers = beerRepository.findAll(pageRequest);
return beers.getContent();
}
}@RestController
public class BeerController {
private final BeerService beerService;
public BeerController(BeerService beerService) {
this.beerService = beerService;
}
@GetMapping("/beer")
public List list(@RequestParam int pageNumber, @RequestParam int pageSize) {
return beerService.list(pageNumber, pageSize);
}
}Implementación de repositorios personalizados
Para nuestro caso en particular con la entidad Beer no nos va a servir la autogeneración de identificadores de Spring, ya que éste no persiste los campos de prefijos y sufijos, en nuestro caso los campos «name» y «brewery_id», campos que seguramente no queramos perder. Hasta que Spring nos de una alternativa tendremos que crear el identificador nosotros mismos.
Prefix and suffix for the key can be provided as part of the entity itself, these values are not persisted, they are only used for key generation.
Aprovecharemos la necesidad de crear un identificador antes de insertar la entidad para probar la implementación de repositorios personalizados. Para ello vamos a sobrescribir la implementación del método «save» del CrudRepository de Spring Data.
Como por defecto Spring va a usar la convención por nombres, a partir de aquí, los nombres que elijamos van a tener mucha importancia.
Para reimplementar el método save vamos a crear una nueva interfaz para definirlo sólo a él y no tener que reimplementar todos los métodos de PagingAndSortingRepository.
public interface CustomSaveRepository {
<S> S save(S beer);
}A continuación creamos la implementación para la entidad Beer que implemente esta nueva interfaz.
public class BeerRepositoryImpl implements CustomSaveRepository {
private final CouchbaseOperations beerSampleTemplate;
public BeerRepositoryImpl(CouchbaseOperations beerSampleTemplate) {
this.beerSampleTemplate = beerSampleTemplate;
}
@Override
public Beer save(Beer beer) {
String id = generateId(beer);
beer.setId(id);
beerSampleTemplate.save(beer);
return beer;
}
private String generateId(Beer beer) {
String idPrefix = StringUtils.replace(beer.getBreweryId(), " ", "_");
idPrefix = StringUtils.lowerCase(idPrefix);
String idSuffix = StringUtils.replace(beer.getName(), " ", "_");
idSuffix = StringUtils.lowerCase(idSuffix);
return new StringBuilder(idPrefix).append("_").append(idSuffix).toString();
}
}Lo siguiente es hacer que la interfaz del repositorio original BeerRepository también extienda a la nueva interfaz que acabamos de crear.
public interface BeerRepository extends PagingAndSortingRepository, CustomSaveRepository {
}Los repositorios pueden estar compuestos de múltiples implementaciones personalizadas que serán importadas en el orden de su declaración. Las implementaciones personalizadas tendrán más prioridad que las implementaciones bases y que los aspectos de los repositorios. Además, como ya habíamos advertido, la elección de nombres aquí es muy importante. Las implementaciones deben seguir la convención de nombres y acabar en «Impl», como siempre Spring nos dejará cambiar esto por configuración. Para resolver la ambigüedad de múltiples implementaciones del mismo método, Spring usará el nombre de las clases. Debido a todo esto, por ejemplo, si tuviéramos una tercera implementación del método save en una clase llamada CustomSaveRepositoryImpl, Spring usará ésta y no la que tenemos implementada dentro de BeerRepositoryImpl. Y si ninguna de nuestras implementaciones casa con el «nombre de la interfaz + Impl» Spring usará la suya por defecto.
Auditoría
Lo siguiente que vamos a hacer es que la entidad Beer se audite automáticamente.
Antes que nada hay que tener en cuenta que sólo las entidades que poseen un campo con @Version pueden ser auditadas para la creación, si no lo tiene, el framework interpretará la creación como una actualización.
Para auditar una entidad tenemos las siguientes anotaciones:
- @CreatedBy
- @CreatedDate
- @LastModifiedBy
- @LastModifiedDate
Spring inyectará automáticamente estos valores cuando se persistan las entidades. Los campos anotados con «@xxxDate» deben tener un tipo de fecha compatible, mientras que los anotados con «@xxxBy» pueden ser de cualquier tipo T (pero ambos campos deben ser del mismo tipo).
@Document
public class Beer {
@Id
private String id;
@NotNull
@Min(0)
@Field
private BigDecimal abv;
@NotNull
@Size(min = 3)
@Field("brewery_id")
private String breweryId;
@NotNull
@Size(min = 5)
@Field
private String category;
// ...
@CreatedDate
private LocalDateTime created;
@CreatedBy
private String createdBy;
@LastModifiedDate
private LocalDateTime updated;
@LastModifiedBy
private String lastModifiedBy;
@Version
private Long version;
// ... getters y setters
}Ya con la entidad anotada, comenzamos a configurar. Lo primero que debemos crear es un componente AuditorAware que será el que obtenga el valor a inyectar en @LastModifiedBy y @CreatedBy, por ejemplo obtener el usuario del contexto de seguridad que está realizando la operación. Como en la entidad estos campos son String, nuestro AuditorAware trabajará con String.
public class EntityAuditorAware implements AuditorAware {
private final static String AUDITOR = "Pablo Betancor";
@Override
public Optional getCurrentAuditor() {
return Optional.of(AUDITOR);
}
}A continuación debemos de ir a la configuración para declarar este componente y activar la auditoría:
@Configuration
@EnableCouchbaseRepositories(basePackages = {"com.autentia.democouchbase.airports.dao", "com.autentia.democouchbase.beers.dao"})
@EnableCouchbaseAuditing // activamos auditoría
public class CouchbaseConfig extends AbstractCouchbaseConfiguration {
// ... Todos los demás métodos de configuración
@Bean
public AuditorAware auditorAware() {
return new EntityAuditorAware();
}
}Por último implementamos un pequeño caso de creación, donde lógicamente no añadiremos estos campos al comando para ver cómo el framework nos los rellena.
public class CreateBeerCommand {
private BigDecimal abv;
private String brewery_id;
private String category;
private String description;
private Long ibu;
private String name;
private Long srm;
private String style;
private Long upc;
// ... getters y setters
}@Service
public class BeerService {
// ...
public Beer create(CreateBeerCommand command) {
BigDecimal abv = command.getAbv();
String breweryId = command.getBreweryId();
String category = command.getCategory();
String description = command.getDescription();
Long ibu = command.getIbu();
String name = command.getName();
Long srm = command.getSrm();
String style = command.getStyle();
Long upc = command.getUpc();
Beer beer = new Beer(abv, breweryId, category, description, ibu, name, srm, style, upc);
beerRepository.save(beer);
return beer;
}
}@RestController
public class BeerController {
// ...
@PostMapping("/beer")
public Beer create(@RequestBody CreateBeerCommand command) {
return beerService.create(command);
}
}Ya podemos crear una cerveza haciendo POST a «/beer» y vemos como en la respuesta vienen todos los campos de auditoría rellenos y el identificador generado:
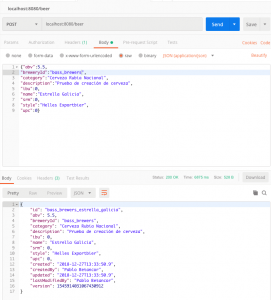
Conclusiones
Hemos podido avanzar un poco más con Spring Data Couchbase ampliando su configuración y posibilidades. Todo dentro de las convenciones y prácticas a las que Spring siempre nos tiene acostumbrados, por lo que la curva de aprendizaje del framework es muy sencilla.
Referencias
- https://www.baeldung.com/spring-data-couchbase-buckets-and-spatial-view-queries
- https://docs.spring.io/spring-data/couchbase/docs/current/reference/html

